Introduction
Let’s say you’re interacting with an AI that not solely solutions your questions however understands the nuances of your intent. It crafts tailor-made, coherent responses that nearly really feel human. How does this occur? Most individuals don’t even understand the key lies in LLM parameters.
If you happen to’ve ever puzzled how AI fashions like ChatGPT generate remarkably lifelike textual content, you’re in the precise place. These fashions don’t simply magically know what to say subsequent. As a substitute, they depend on key parameters to find out every thing from creativity to accuracy to coherence. Whether or not you’re a curious newbie or a seasoned developer, understanding these parameters can unlock new ranges of AI potential in your tasks.
This text will focus on the 7 important technology parameters that form how massive language fashions (LLMs) like GPT-4o function. From temperature settings to top-k sampling, these parameters act because the dials you may alter to regulate the AI’s output. Mastering them is like gaining the steering wheel to navigate the huge world of AI textual content technology.
Overview
- Learn the way key parameters like temperature, max_tokens, and top-p form AI-generated textual content.
- Uncover how adjusting LLM parameters can improve creativity, accuracy, and coherence in AI outputs.
- Grasp the 7 important LLM parameters to customise textual content technology for any software.
- Wonderful-tune AI responses by controlling output size, range, and factual accuracy with these parameters.
- Keep away from repetitive and incoherent AI outputs by tweaking frequency and presence penalties.
- Unlock the total potential of AI textual content technology by understanding and optimizing these essential LLM settings.
What are LLM Technology Parameters?
Within the context of Giant Language Fashions (LLMs) like GPT-o1, technology parameters are settings or configurations that affect how the mannequin generates its responses. These parameters assist decide numerous elements of the output, reminiscent of creativity, coherence, accuracy, and even size.
Consider technology parameters because the “management knobs” of the mannequin. By adjusting them, you may change how the AI behaves when producing textual content. These parameters information the mannequin in navigating the huge house of attainable phrase mixtures to pick probably the most appropriate response primarily based on the person’s enter.
With out these parameters, the AI can be much less versatile and infrequently unpredictable in its behaviour. By fine-tuning them, customers can both make the mannequin extra centered and factual or permit it to discover extra inventive and various responses.
Key Facets Influenced by LLM Technology Parameters:
- Creativity vs. Accuracy: Some parameters management how “inventive” or “predictable” the mannequin’s responses are. Would you like a protected and factual response or search one thing extra imaginative?
- Response Size: These settings can affect how a lot or how little the mannequin generates in a single response.
- Variety of Output: The mannequin can both deal with the probably subsequent phrases or discover a broader vary of potentialities.
- Threat of Hallucination: Overly inventive settings could lead the mannequin to generate “hallucinations” or plausible-sounding however factually incorrect responses. The parameters assist stability that threat.
Every LLM technology parameter performs a singular function in shaping the ultimate output, and by understanding them, you may customise the AI to satisfy your particular wants or objectives higher.
Sensible Implementation of seven LLM Parameters
Set up Essential Libraries
Earlier than utilizing the OpenAI API to regulate parameters like max_tokens, temperature, and so forth., it is advisable to set up the OpenAI Python consumer library. You are able to do this utilizing pip:
!pip set up openaiAs soon as the library is put in, you should utilize the next code snippets for every parameter. Make sure that to switch your_openai_api_key together with your precise OpenAI API key.
Fundamental Setup for All Code Snippets
This setup will stay fixed in all examples. You’ll be able to reuse this part as your base setup for interacting with OpenAI’s GPT-3 (or GPT-4) API.
import openai
# Set your OpenAI API key
openai.api_key = 'your_openai_api_key'
# Outline a easy immediate that we will reuse in examples
immediate = "Clarify the idea of synthetic intelligence in easy phrases"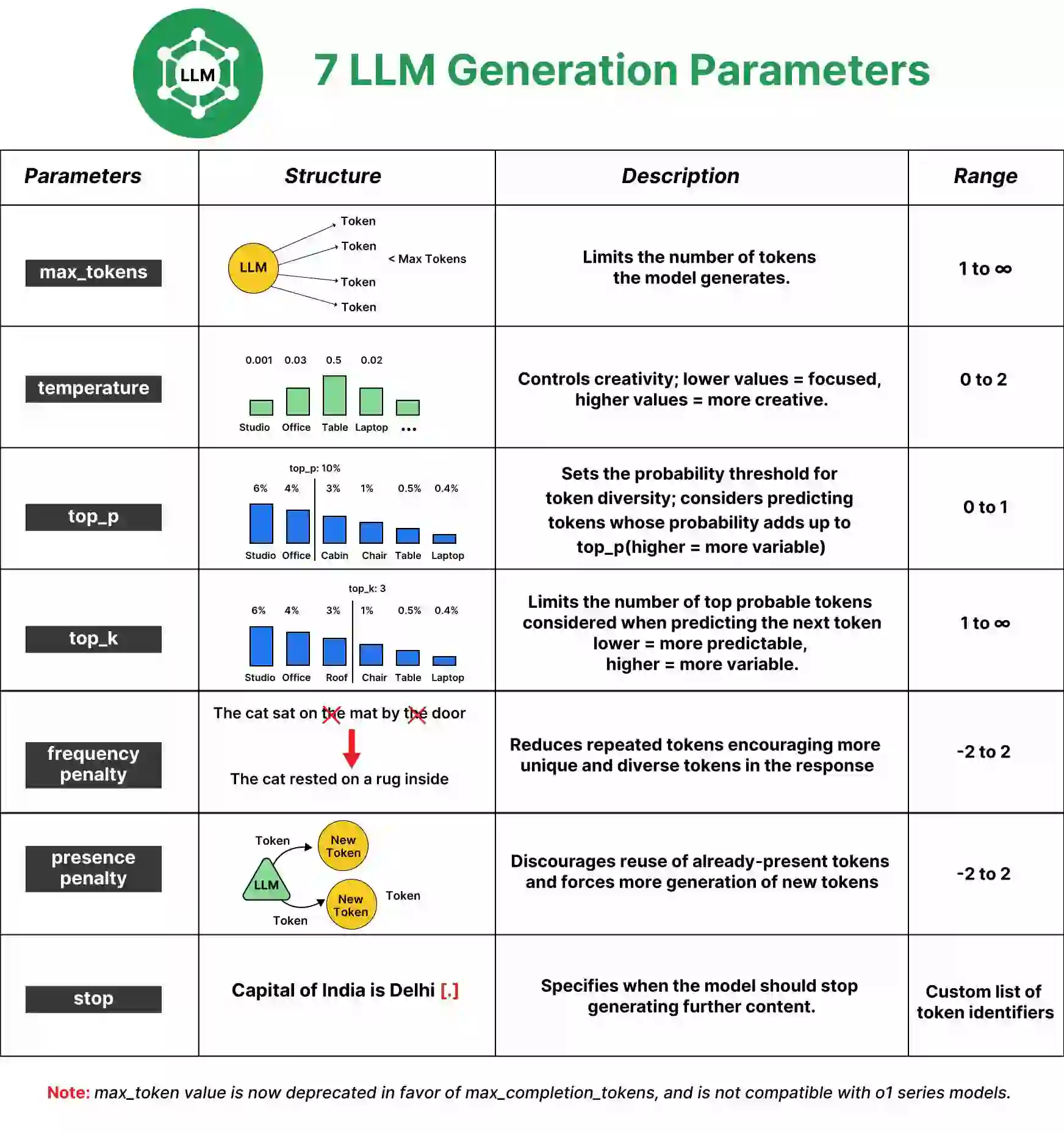
1. Max Tokens
The max_tokens parameter controls the size of the output generated by the mannequin. A “token” will be as brief as one character or so long as one phrase, relying on the complexity of the textual content.
- Low Worth (e.g., 10): Produces shorter responses.
- Excessive Worth (e.g., 1000): Generates longer, extra detailed responses.
Why is it Necessary?
By setting an acceptable max_tokens worth, you may management whether or not the response is a fast snippet or an in-depth clarification. That is particularly essential for functions the place brevity is essential, like textual content summarization, or the place detailed solutions are wanted, like in knowledge-intensive dialogues.
Notice: Max_token worth is now deprecated in favor of max_completion_tokens and isn’t suitable with o1 collection fashions.
Implementation
Right here’s how one can management the size of the generated output through the use of the max_tokens parameter with the OpenAI mannequin:
import openai
consumer = openai.OpenAI(api_key='Your_api_key')
max_tokens=10
temperature=0.5
response = consumer.chat.completions.create(
mannequin="gpt-4 turbo",
messages=[
{"role": "user",
"content": "What is the capital of India? Give 7 places to Visit"}
],
max_tokens=max_tokens,
temperature=temperature,
n=1,
)
print(response.selections[0].message.content material)Output
max_tokens = 10
- Output: ‘The capital of India is New Delhi. Listed here are’
- The response could be very temporary and incomplete, lower off because of the token restrict. It offers primary data however doesn’t elaborate. The sentence begins however doesn’t end, chopping off simply earlier than itemizing locations to go to.
max_tokens = 20
- Output: ‘The capital of India is New Delhi. Listed here are seven locations to go to in New Delhi:n1.’
- With a barely larger token restrict, the response begins to listing locations however solely manages to begin the primary merchandise earlier than being lower off once more. It’s nonetheless too brief to supply helpful element and even end a single place description.
max_tokens = 50
- Output: ‘The capital of India is New Delhi. Listed here are seven locations to go to in New Delhi:n1. **India Gate**: This iconic monument is a warfare memorial positioned alongside the Rajpath in New Delhi. It’s devoted to the troopers who died throughout World’
- Right here, the response is extra detailed, providing an entire introduction and the start of an outline for the primary location, India Gate. Nonetheless, it’s lower off mid-sentence, which suggests the 50-token restrict isn’t sufficient for a full listing however may give extra context and clarification for at the very least one or two objects.
max_tokens = 500
- Output: (Full detailed response with seven locations)
- With this bigger token restrict, the response is full and offers an in depth listing of seven locations to go to in New Delhi. Every place features a temporary however informative description, providing context about its significance and historic significance. The response is absolutely articulated and permits for extra advanced and descriptive textual content.
2. Temperature
The temperature parameter influences how random or inventive the mannequin’s responses are. It’s primarily a measure of how deterministic the responses ought to be:
- Low Temperature (e.g., 0.1): The mannequin will produce extra centered and predictable responses.
- Excessive Temperature (e.g., 0.9): The mannequin will produce extra inventive, diversified, and even “wild” responses.
Why is it Necessary?
That is good for controlling the tone. Use low temperatures for duties like producing technical solutions, the place precision issues, and better temperatures for inventive writing duties, reminiscent of storytelling or poetry.
Implementation
The temperature parameter controls the randomness or creativity of the output. Right here’s how you can use it with the newer mannequin:
import openai
consumer = openai.OpenAI(api_key=api_key)
max_tokens=500
temperature=0.1
response = consumer.chat.completions.create(
mannequin="gpt-4",
messages=[
{"role": "user",
"content": "What is the capital of India? Give 7 places to Visit"}
],
max_tokens=max_tokens,
temperature=temperature,
n=1,
cease=None
)
print(response.selections[0].message.content material)Output
temperature=0.1
The output is strictly factual and formal, offering concise, easy data with minimal variation or embellishment. It reads like an encyclopedia entry, prioritizing readability and precision.

temperature=0.5
This output retains factual accuracy however introduces extra variability in sentence construction. It provides a bit extra description, providing a barely extra participating and inventive tone, but nonetheless grounded in information. There’s a little bit extra room for slight rewording and extra element in comparison with the 0.1 output.

temperature=0.9
Essentially the most inventive model, with descriptive and vivid language. It provides subjective components and vibrant particulars, making it really feel extra like a journey narrative or information, emphasizing environment, cultural significance, and information.

3. Prime-p (Nucleus Sampling)
The top_p parameter, also called nucleus sampling, helps management the range of responses. It units a threshold for the cumulative likelihood distribution of token selections:
- Low Worth (e.g., 0.1): The mannequin will solely contemplate the highest 10% of attainable responses, limiting variation.
- Excessive Worth (e.g., 0.9): The mannequin considers a wider vary of attainable responses, rising variability.
Why is it Necessary?
This parameter helps stability creativity and precision. When paired with temperature, it could produce various and coherent responses. It’s nice for functions the place you need inventive flexibility however nonetheless want some degree of management.
Implementation
The top_p parameter, also called nucleus sampling, controls the range of the responses. Right here’s how you can use it:
import openai
consumer = openai.OpenAI(api_key=api_key)
max_tokens=500
temperature=0.1
top_p=0.5
response = consumer.chat.completions.create(
mannequin="gpt-4-turbo",
messages=[
{"role": "user",
"content": "What is the capital of India? Give 7 places to Visit"}
],
max_tokens=max_tokens,
temperature=temperature,
n=1,
top_p=top_p,
cease=None
)
print(response.selections[0].message.content material)Output
temperature=0.1
top_p=0.25

Extremely deterministic and fact-driven: At this low top_p worth, the mannequin selects phrases from a slender pool of extremely possible choices, resulting in concise and correct responses with minimal variability. Every location is described with strict adherence to core information, leaving little room for creativity or added particulars.
As an example, the point out of India Gate focuses purely on its function as a warfare memorial and its historic significance, with out extra particulars just like the design or environment. The language stays easy and formal, guaranteeing readability with out distractions. This makes the output splendid for conditions requiring precision and an absence of ambiguity.
temperature=0.1
top_p=0.5
Balanced between creativity and factual accuracy: With top_p = 0.5, the mannequin opens up barely to extra diversified phrasing whereas nonetheless sustaining a robust deal with factual content material. This degree introduces further contextual data that gives a richer narrative with out drifting too removed from the principle information.
For instance, within the description of Pink Fort, this output contains the element concerning the Prime Minister hoisting the flag on Independence Day—some extent that provides extra cultural significance however isn’t strictly vital for the placement’s historic description. The output is barely extra conversational and interesting, interesting to readers who need each information and a little bit of context.
- Extra relaxed however nonetheless factual in nature, permitting for slight variability in phrasing however nonetheless fairly structured.
- The sentences are much less inflexible, and there’s a wider vary of information included, reminiscent of mentioning the hoisting of the nationwide flag at Pink Fort on Independence Day and the design of India Gate by Sir Edwin Lutyens.
- The wording is barely extra fluid in comparison with top_p = 0.1, although it stays fairly factual and concise.

temperature = 0.5
top_p=1
Most various and creatively expansive output: At top_p = 1, the mannequin permits for max selection, providing a extra versatile and expansive description. This model contains richer language and extra, generally much less anticipated, content material.
For instance, the inclusion of Raj Ghat within the listing of notable locations deviates from the usual historic or architectural landmarks and provides a human contact by highlighting its significance as a memorial to Mahatma Gandhi. Descriptions might also embrace sensory or emotional language, like how Lotus Temple has a serene atmosphere that pulls guests. This setting is good for producing content material that isn’t solely factually right but in addition participating and interesting to a broader viewers.

4. Prime-k (Token Sampling)
The top_k parameter limits the mannequin to solely contemplating the highest ok most possible subsequent tokens when predicting (producing) the following phrase.
- Low Worth (e.g., 50): Limits the mannequin to extra predictable and constrained responses.
- Excessive Worth (e.g., 500): Permits the mannequin to think about a bigger variety of tokens, rising the number of responses.
Why is it Necessary?
Whereas much like top_p, top_k explicitly limits the variety of tokens the mannequin can select from, making it helpful for functions that require tight management over output variability. If you wish to generate formal, structured responses, utilizing a decrease top_k might help.
Implementation
The top_k parameter isn’t straight obtainable within the OpenAI API like top_p, however top_p affords an analogous solution to restrict token selections. Nonetheless, you may nonetheless management the randomness of tokens utilizing the top_p parameter as a proxy.
import openai
# Initialize the OpenAI consumer together with your API key
consumer = openai.OpenAI(api_key=api_key)
max_tokens = 500
temperature = 0.1
top_p = 0.9
response = consumer.chat.completions.create(
mannequin="gpt-4-turbo",
messages=[
{"role": "user", "content": "What is the capital of India? Give 7 places to Visit"}
],
max_tokens=max_tokens,
temperature=temperature,
n=1,
top_p=top_p,
cease=None
)
print("Prime-k Instance Output (Utilizing top_p as proxy):")
print(response.selections[0].message.content material)Output
Prime-k Instance Output (Utilizing top_p as proxy):The capital of India is New Delhi. Listed here are seven notable locations to go to in
New Delhi:1. **India Gate** - It is a warfare memorial positioned astride the Rajpath, on
the japanese fringe of the ceremonial axis of New Delhi, India, previously referred to as
Kingsway. It's a tribute to the troopers who died throughout World Battle I and
the Third Anglo-Afghan Battle.2. **Pink Fort (Lal Qila)** - A historic fort within the metropolis of Delhi in India,
which served as the principle residence of the Mughal Emperors. Yearly on
India's Independence Day (August 15), the Prime Minister hoists the nationwide
flag on the important gate of the fort and delivers a nationally broadcast speech
from its ramparts.3. **Qutub Minar** - A UNESCO World Heritage Web site positioned within the Mehrauli
space of Delhi, Qutub Minar is a 73-meter-tall tapering tower of 5
storeys, with a 14.3 meters base diameter, lowering to 2.7 meters on the prime
of the height. It was constructed in 1193 by Qutb-ud-din Aibak, founding father of the
Delhi Sultanate after the defeat of Delhi's final Hindu kingdom.4. **Lotus Temple** - Notable for its flowerlike form, it has develop into a
outstanding attraction within the metropolis. Open to all, no matter faith or any
different qualification, the Lotus Temple is a wonderful place for meditation
and acquiring peace.5. **Humayun's Tomb** - One other UNESCO World Heritage Web site, that is the tomb
of the Mughal Emperor Humayun. It was commissioned by Humayun's first spouse
and chief consort, Empress Bega Begum, in 1569-70, and designed by Mirak
Mirza Ghiyas and his son, Sayyid Muhammad.6. **Akshardham Temple** - A Hindu temple, and a spiritual-cultural campus in
Delhi, India. Additionally known as Akshardham Mandir, it shows millennia
of conventional Hindu and Indian tradition, spirituality, and structure.7. **Rashtrapati Bhavan** - The official residence of the President of India.
Situated on the Western finish of Rajpath in New Delhi, the Rashtrapati Bhavan
is an enormous mansion and its structure is breathtaking. It incorporates
numerous kinds, together with Mughal and European, and is a
5. Frequency Penalty
The frequency_penalty parameter discourages the mannequin from repeating beforehand used phrases. It reduces the likelihood of tokens which have already appeared within the output.
- Low Worth (e.g., 0.0): The mannequin received’t penalize for repetition.
- Excessive Worth (e.g., 2.0): The mannequin will closely penalize repeated phrases, encouraging the technology of latest content material.
Why is it Importnt?
That is helpful while you need the mannequin to keep away from repetitive outputs, like in inventive writing, the place redundancy may diminish high quality. On the flip facet, you may want decrease penalties in technical writing, the place repeated terminology may very well be helpful for readability.
Implementation
The frequency_penalty parameter helps management repetitive phrase utilization within the generated output. Right here’s how you can use it with GPT-4-turbo:
import openai
# Initialize the OpenAI consumer together with your API key
consumer = openai.OpenAI(api_key='Your_api_key')
max_tokens = 500
temperature = 0.1
top_p=0.25
frequency_penalty=1
response = consumer.chat.completions.create(
mannequin="gpt-4-turbo",
messages=[
{"role": "user", "content": "What is the capital of India? Give 7 places to Visit"}
],
max_tokens=max_tokens,
temperature=temperature,
n=1,
top_p=top_p,
frequency_penalty=frequency_penalty,
cease=None
)
print(response.selections[0].message.content material)Output
frequency_penalty=1
Balanced output with some repetition, sustaining pure circulation. Very best for contexts like inventive writing the place some repetition is suitable. The descriptions are clear and cohesive, permitting for straightforward readability with out extreme redundancy. Helpful when each readability and circulation are required.

frequency_penalty=1.5
Extra diversified phrasing with lowered repetition. Appropriate for contexts the place linguistic range enhances readability, reminiscent of experiences or articles. The textual content maintains readability whereas introducing extra dynamic sentence constructions. Useful in technical writing to keep away from extreme repetition with out dropping coherence.

frequency_penalty=2
Maximizes range however could sacrifice fluency and cohesion. The output turns into much less uniform, introducing extra selection however generally dropping smoothness. Appropriate for inventive duties that profit from excessive variation, although it could scale back readability in additional formal or technical contexts on account of inconsistency.

6. Presence Penalty
The presence_penalty parameter is much like the frequency penalty, however as a substitute of penalizing primarily based on how usually a phrase is used, it penalizes primarily based on whether or not a phrase has appeared in any respect within the response to date.
- Low Worth (e.g., 0.0): The mannequin received’t penalize for reusing phrases.
- Excessive Worth (e.g., 2.0): The mannequin will keep away from utilizing any phrase that has already appeared.
Why is it Necessary?
Presence penalties assist encourage extra various content material technology. It’s particularly helpful while you need the mannequin to repeatedly introduce new concepts, as in brainstorming classes.
Implementation
The presence_penalty discourages the mannequin from repeating concepts or phrases it has already launched. Right here’s how you can apply it:
import openai
# Initialize the OpenAI consumer together with your API key
consumer = openai.OpenAI(api_key='Your_api_key')
# Outline parameters for the chat request
response = consumer.chat.completions.create(
mannequin="gpt-4-turbo",
messages=[
{
"role": "user",
"content": "What is the capital of India? Give 7 places to visit."
}
],
max_tokens=500, # Max tokens for the response
temperature=0.1, # Controls randomness
top_p=0.1, # Controls range of responses
presence_penalty=0.5, # Encourages the introduction of latest concepts
n=1, # Generate only one completion
cease=None # Cease sequence, none on this case
)
print(response.selections[0].message.content material)Output
presence_penalty=0.5
The output is informative however considerably repetitive, because it offers well-known information about every website, emphasizing particulars which will already be acquainted to the reader. As an example, the descriptions of India Gate and Qutub Minar don’t diverge a lot from widespread information, sticking carefully to standard summaries. This demonstrates how a decrease presence penalty encourages the mannequin to stay inside acquainted and already established content material patterns.

presence_penalty=1
The output is extra diversified in the way it presents particulars, with the mannequin introducing extra nuanced data and restating information in a much less formulaic method. For instance, the outline of Akshardham Temple provides an extra sentence about millennia of Hindu tradition, signaling that the upper presence penalty pushes the mannequin towards introducing barely totally different phrasing and particulars to keep away from redundancy, fostering range in content material.

7. Cease Sequence
The cease parameter enables you to outline a sequence of characters or phrases that can sign the mannequin to cease producing additional content material. This lets you cleanly finish the technology at a particular level.
- Instance Cease Sequences: Might be durations (.), newlines (n), or particular phrases like “The tip”.
Why is it Necessary?
This parameter is very helpful when engaged on functions the place you need the mannequin to cease as soon as it has reached a logical conclusion or after offering a sure variety of concepts, reminiscent of in Q&A or dialogue-based fashions.
Implementation
The cease parameter permits you to outline a stopping level for the mannequin when producing textual content. For instance, you may cease it after producing a listing of things.
import openai
# Initialize the OpenAI consumer together with your API key
consumer = openai.OpenAI(api_key='Your_api_key')
max_tokens = 500
temperature = 0.1
top_p = 0.1
response = consumer.chat.completions.create(
mannequin="gpt-4-turbo",
messages=[
{"role": "user", "content": "What is the capital of India? Give 7 places to Visit"}
],
max_tokens=max_tokens,
temperature=temperature,
n=1,
top_p=top_p,
cease=[".", "End of list"] # Outline cease sequences
)
print(response.selections[0].message.content material)Output
The capital of India is New Delhi
How do These LLM Parameters Work Collectively?
Now, the true magic occurs while you begin combining these parameters. For instance:
- Use temperature and top_p collectively to fine-tune inventive duties.
- Pair max_tokens with cease to restrict long-form responses successfully.
- Leverage frequency_penalty and presence_penalty to keep away from repetitive textual content, which is especially helpful for duties like poetry technology or brainstorming classes.
Conclusion
Understanding these LLM parameters can considerably enhance the way you work together with language fashions. Whether or not you’re growing an AI-based assistant, producing inventive content material, or performing technical duties, realizing how you can tweak these parameters helps you get the very best output in your particular wants.
By adjusting LLM parameters like temperature, max_tokens, and top_p, you achieve management over the mannequin’s creativity, coherence, and size. Then again, penalties like frequency and presence be sure that outputs stay recent and keep away from repetitive patterns. Lastly, the cease sequence ensures clear and well-defined completions.
Experimenting with these settings is essential, because the optimum configuration relies on your software. Begin by tweaking one parameter at a time and observe how the outputs shift—this may assist you dial within the good setup in your use case!
Are you in search of a Generative AI course on-line? If sure, discover this: GenAI Pinnacle Program.
Often Requested Questions
Ans. LLM technology parameters management how AI fashions like GPT-4 generate textual content, affecting creativity, accuracy, and size.
Ans. The temperature controls how inventive or centered the mannequin’s output is. Decrease values make it extra exact, whereas larger values improve creativity.
Ans. Max_tokens limits the size of the generated response, with larger values producing longer and extra detailed outputs.
Ans. Prime-p (nucleus sampling) controls the range of responses by setting a threshold for the cumulative likelihood of token selections, balancing precision and creativity.
Ans. These penalties scale back repetition and encourage the mannequin to generate extra various content material, enhancing total output high quality.
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Enthusiastic about storytelling and crafting compelling narratives that rework concepts into impactful content material. I really like studying about expertise revolutionizing our way of life.