Introduction
In our earlier article about LangChain Doc Loaders, we explored how LangChain’s doc loaders facilitate loading varied file sorts and knowledge sources into an LLM utility. Can we ship the info to the LLM now? Not so quick. LLMs have limits on context window measurement when it comes to token numbers, so any knowledge greater than that measurement will probably be reduce off, resulting in potential lack of data and fewer correct responses. Even when the context measurement is infinite, extra enter tokens will result in greater prices, and cash will not be infinite. So, relatively than sending all the info to the LLM, it’s higher to ship the info that’s related to our question in regards to the knowledge. To realize this, we have to cut up the info first, and for that, LangChain Textual content Splitters is required. Now, let’s study LangChain Textual content Splitters.

Overview
- Perceive the Significance of Textual content Splitters in LLM Functions: Study why textual content splitting is essential for optimizing giant language fashions (LLMs) and its influence on context window measurement and price effectivity.
- Study Completely different Strategies of Textual content Splitting: Discover varied text-splitting methods, together with character rely, token rely, recursive splitting, HTML construction, and code syntax.
- Implement Textual content Splitters Utilizing LangChain: Study to make use of LangChain’s textual content splitters, together with putting in them, writing code to separate textual content, and dealing with completely different knowledge codecs.
- Apply Semantic Splitting for Enhanced Relevance: Use sentence embeddings and cosine similarity to establish pure breakpoints, guaranteeing semantically related content material stays collectively.
What are Textual content Splitters?
Textual content splitters cut up giant volumes of textual content into smaller chunks in order that we will retrieve extra related content material for the given question. These splitters could be utilized on to uncooked textual content or to doc objects loaded utilizing LangChain’s doc loaders.
A number of strategies can be found for splitting knowledge, every tailor-made to several types of content material and use instances. Listed below are the assorted methods we will make use of textual content splitters to boost knowledge processing.
Additionally learn: A Complete Information to Utilizing Chains in Langchain
Strategies for Splitting Knowledge
LangChain Textual content Splitters are important for dealing with giant paperwork by breaking them into manageable chunks. This improves efficiency, enhances contextual understanding, permits parallel processing, and facilitates higher knowledge administration. Moreover, they allow custom-made processing and strong error dealing with, optimizing NLP duties and making them extra environment friendly and correct. Additional, we are going to focus on strategies to separate knowledge into manageable chunks.
Pre-requisites
First, set up the bundle utilizing 'pip set up langchain_text_splitters'
By Character Rely
The textual content is cut up based mostly on the variety of characters. We will specify the separator to make use of for splitting the textual content. Let’s perceive utilizing the code. You may obtain the doc used right here: Free Technique Formulation E-Guide.
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import CharacterTextSplitter
# load the info
loader = UnstructuredPDFLoader('how-to-formulate-successful-business-strategy.pdf', mode="single")
knowledge = loader.load()
text_splitter = CharacterTextSplitter(
separator="n",
chunk_size=500,
chunk_overlap=0,
is_separator_regex=False,
)This perform splits the textual content the place every chunk has a most of 500 characters. Textual content will probably be cut up solely at new traces since we’re utilizing the brand new line (“n”) because the separator. If any chunk has a measurement greater than 500 however no new traces in it, it is going to be returned as such.
texts = text_splitter.split_documents(knowledge)
# Created a bit of measurement 535, which is longer than the required 500
# Created a bit of measurement 688, which is longer than the required 500
len(texts)
>>> 73for i in texts[48:49]:
print(len(i.page_content))
print(i.page_content)Output
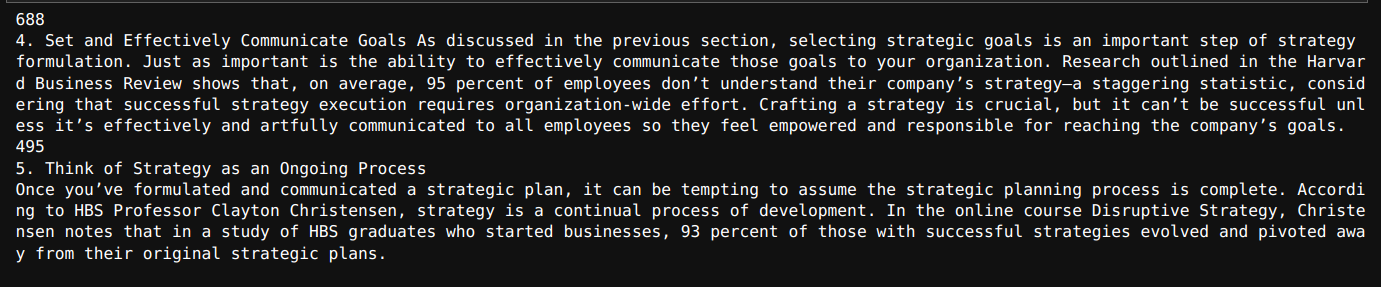
As we will see, the above-displayed chunk has 688 characters.
Recursive
Slightly than utilizing a single separator, we use a number of separators. This methodology will use every separator sequentially to separate the info till the chunk reaches lower than chunk_size. We will use this to separate the textual content by every sentence, as proven beneath.
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = UnstructuredPDFLoader('how-to-formulate-successful-business-strategy.pdf', mode="single")
knowledge = loader.load()
recursive_splitter = RecursiveCharacterTextSplitter(
separators=["nn", "n", r"(?<=[.?!])s+"],
keep_separator=False, is_separator_regex=True,
chunk_size=30, chunk_overlap=0)
texts = recursive_splitter.split_documents(knowledge)
len(texts)
>>> 293
# a number of pattern chunks
for textual content in texts[123:129]:
print(len(textual content.page_content))
print(textual content.page_content) Output
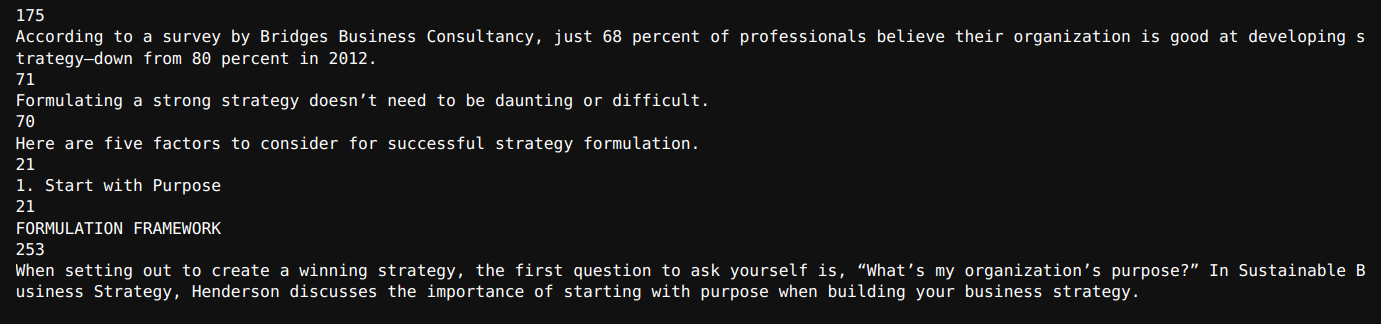
As we will see, we have now talked about three separators, with the third one for splitting by sentence utilizing regex.
By Token rely
Each of the above strategies use character counts. Since LLMs use tokens to rely, we will additionally cut up the info by token rely. Completely different LLMs use completely different token encodings. Allow us to use the encoding utilized in GPT-4o and GPT-4o-mini. You’ll find the mannequin and encoding mapping right here—GitHub hyperlink.
from langchain_text_splitters import TokenTextSplitter
text_splitter = TokenTextSplitter(encoding_name="o200k_base", chunk_size=50, chunk_overlap=0)
texts = text_splitter.split_documents(knowledge)
len(texts)
>>> 105We will additionally use character textual content splitter strategies together with token counting.
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="o200k_base",
separators=["nn", "n", r"(?<=[.?!])s+"],
keep_separator=False,
is_separator_regex=True,
chunk_size=10, # chunk_size is variety of tokens
chunk_overlap=0)
texts = text_splitter.split_documents(knowledge)
len(texts)
>>> 279
for i in texts[:4]:
print(len(i.page_content))
print(i.page_content)Output
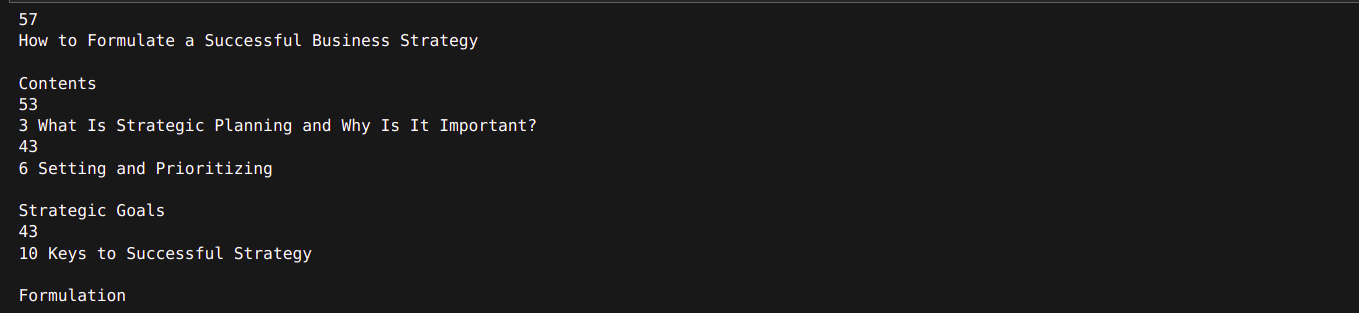
As proven, we will use token counting together with a recursive textual content splitter.
Among the many three strategies talked about above, a recursive splitter with both character or token counting is healthier for splitting plain textual content knowledge.
HTML
Whereas the above strategies are high-quality for plain textual content, If the info has some inherent construction like HTML or Markdown pages, it’s higher to separate by contemplating that construction.
We will cut up the HTML web page based mostly on the headers
from langchain_text_splitters import HTMLHeaderTextSplitter, HTMLSectionSplitter
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on, return_each_element=True)
html_header_splits = html_splitter.split_text_from_url('https://diataxis.fr/')
len(html_header_splits)
>>> 37Right here, we cut up the HTML web page from the URL by headers h1, h2, and h3. We will additionally use this class by specifying a file path or HTML string.
for header in html_header_splits[20:22]:
print(header.metadata)
>>> {'Header 1': 'Diátaxis¶'}
{'Header 1': 'Diátaxis¶', 'Header 2': 'Contents¶'} # there isn't a h3 on this web page.Equally, we will additionally cut up Markdown file textual content utilizing headers with MarkdownHeaderTextSplitter
We will additionally cut up based mostly on another sections of the HTML. For that, we’d like HTML as a textual content.
import requests
r = requests.get('https://diataxis.fr/')
sections_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("p", "section"),
]
html_splitter = HTMLSectionSplitter(sections_to_split_on)
html_section_splits = html_splitter.split_text(r.textual content)
len(html_section_splits)
>>> 18
for part in html_section_splits[1:6]:
print(len(part.page_content))
print(part)Output
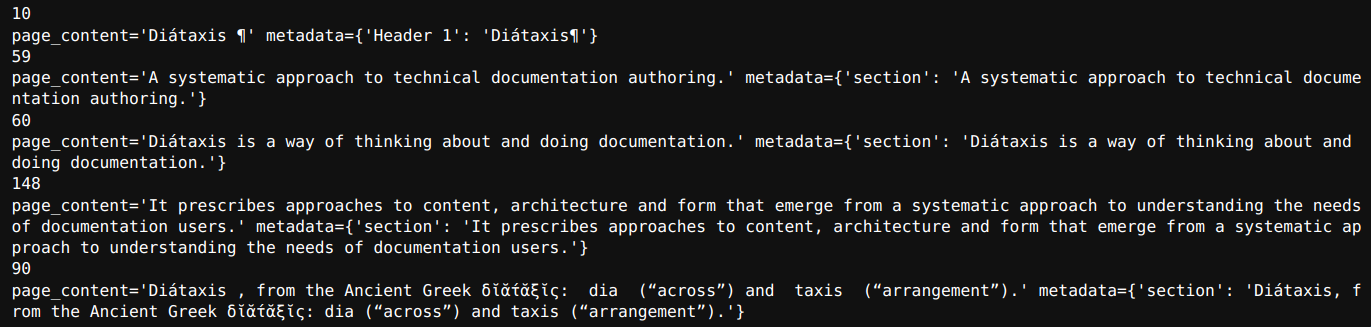
Right here, we use h1, h2, and p tags to separate the info within the HTML web page.
Code
Since Programming languages have completely different buildings than plain textual content, we will cut up the code based mostly on the syntax of the particular language.
from langchain_text_splitters import RecursiveCharacterTextSplitter, Language
PYTHON_CODE = """
def add(a, b):
return a + b
class Calculator:
def __init__(self):
self.consequence = 0
def add(self, worth):
self.consequence += worth
return self.consequence
def subtract(self, worth):
self.consequence -= worth
return self.consequence
# Name the perform
def principal():
calc = Calculator()
print(calc.add(5))
print(calc.subtract(2))
if __name__ == "__main__":
principal()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=100, chunk_overlap=0)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docsOutput

Right here, the Python code is cut up based mostly on the syntax phrases like class, def, and many others. We will discover separators for various languages right here – GitHub Hyperlink.
JSON
A nested json object could be cut up such that preliminary json keys are in all of the associated chunks of textual content. If there are any lengthy lists inside, we will convert them into dictionaries to separate. Let’s take a look at an instance.
from langchain_text_splitters import RecursiveJsonSplitter
# Instance JSON object
json_data = {
"firm": {
"title": "TechCorp",
"location": {
"metropolis": "Metropolis",
"state": "NY"
},
"departments": [
{
"name": "Research",
"employees": [
{"name": "Alice", "age": 30, "role": "Scientist"},
{"name": "Bob", "age": 25, "role": "Technician"}
]
},
{
"title": "Improvement",
"workers": [
{"name": "Charlie", "age": 35, "role": "Engineer"},
{"name": "David", "age": 28, "role": "Developer"}
]
}
]
},
"financials": {
"12 months": 2023,
"income": 1000000,
"bills": 750000
}
}
# Initialize the RecursiveJsonSplitter with a most chunk measurement
splitter = RecursiveJsonSplitter(max_chunk_size=200, min_chunk_size=20)
# Break up the JSON object
chunks = splitter.split_text(json_data, convert_lists=True)
# Course of the chunks as wanted
for chunk in chunks:
print(len(chunk))
print(chunk)Output

This splitter maintains preliminary keys comparable to firm and departments if the chunk accommodates knowledge similar to these keys.
Semantic Splitter
The above strategies work based mostly on the textual content’s construction. Nonetheless, splitting two sentences will not be useful if they’ve related meanings. We will make the most of sentence embeddings and cosine similarity to establish pure break factors the place the semantic content material of adjoining sentences diverges considerably.
Listed below are the Steps:
- Break up the enter textual content into particular person sentences.
- Mix Sentences Utilizing Buffer Dimension: Create mixed sentences for a given buffer measurement. For instance, if there are 10 sentences and the buffer measurement is 1, the mixed sentences could be:
- Sentences 1 and a pair of
- Sentences 1, 2, and three
- Sentences 2, 3, and 4
- Proceed this sample till the final mixture, which will probably be sentences 9 and 10
- Compute the embeddings for every mixed sentence utilizing an embedding mannequin.
- Decide sentence splits based mostly on distance:
- Calculate the cosine distance (1 – cosine similarity) between adjoining mixed sentences
- Establish indices the place the cosine distance is above an outlined threshold.
- Be a part of the sentences based mostly on these indices
from langchain_community.document_loaders import WikipediaLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# be sure so as to add OPENAI_API_KEY
loader = WikipediaLoader(question='Generative AI', load_max_docs=1, doc_content_chars_max=5000, load_all_available_meta=True)
knowledge = loader.load()
semantic_splitter = SemanticChunker(OpenAIEmbeddings(mannequin="text-embedding-3-small"), buffer_size=1,
breakpoint_threshold_type="percentile", breakpoint_threshold_amount=70)
texts = semantic_splitter.create_documents([data[0].page_content])
len(texts)
>>> 10
for textual content in texts[:2]:
print(len(textual content.page_content))
print(textual content.page_content)Output

The doc is cut up into 10 chunks, and there are 29 sentences in it. We’ve got these breakpoint threshold sorts obtainable together with default values:
“percentile”: 95,
“standard_deviation”: 3,
“interquartile”: 1.5,
“gradient”: 95
In case you’re fascinated with studying how embedding fashions compute embeddings for sentences, search for the subsequent article, the place we’ll focus on the main points.
Conclusion
This text explored varied text-splitting strategies utilizing LangChain, together with character rely, recursive splitting, token rely, HTML construction, code syntax, JSON objects, and semantic splitter. Every methodology presents distinctive benefits for processing completely different knowledge sorts, enhancing the effectivity and relevance of the content material despatched to LLMs. By understanding and implementing these methods, you’ll be able to optimize knowledge for higher accuracy and decrease prices in your LLM functions.
Often Requested Questions
Ans. Textual content splitters are instruments that divide giant volumes of textual content into smaller chunks, making it simpler to course of and retrieve related content material for queries in LLM functions.
Ans. Splitting textual content is essential as a result of LLMs have limits on context window measurement. Sending smaller, related chunks ensures no data is misplaced and lowers processing prices.
Ans. LangChain presents varied strategies comparable to splitting by character rely, token rely, recursive splitting, HTML construction, code syntax, JSON objects, and semantic splitting.
Ans. Implementing a textual content splitter includes putting in the LangChain bundle, writing code to specify splitting standards, and making use of the splitter to completely different knowledge codecs.
Ans. Semantic splitting makes use of sentence embeddings and cosine similarity to maintain semantically related content material collectively. It’s very best for sustaining the context and which means in textual content chunks.