Output parsers are important for changing uncooked, unstructured textual content from language fashions (LLMs) into structured codecs, similar to JSON or Pydantic fashions, making it simpler for downstream duties. Whereas operate or instrument calling can automate this transformation in lots of LLMs, output parsers are nonetheless helpful for producing structured knowledge or normalizing mannequin outputs.

Output Parsers for Structured Knowledge
LLMs usually produce unstructured textual content, however output parsers can remodel this into structured knowledge. Some fashions natively assist structured output, however after they don’t, parsers step in. Output parsers implement two key strategies:
- get_format_instructions: Specifies the required format for the mannequin’s response.
- parse: Converts the mannequin’s output into the specified structured format.
Some parsers additionally embody an elective technique:
- parse_with_prompt: Makes use of each the response and immediate to enhance parsing, which is useful for retries or corrections.
Instance: PydanticOutputParser
The PydanticOutputParser is beneficial for outlining and validating structured outputs. Beneath is a step-by-step instance of learn how to use it.
Workflow Instance:
import os
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI # Use ChatOpenAI for GPT-4
from pydantic import BaseModel, Area, model_validator
# Guarantee OpenAI API secret's set appropriately
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY') # Set key from userdata
openai_key = os.getenv('OPENAI_API_KEY')
# Outline the mannequin utilizing ChatOpenAI
mannequin = ChatOpenAI(api_key=openai_key, model_name="gpt-4o", temperature=0.0)
# Outline a Pydantic mannequin for the output
class Joke(BaseModel):
setup: str = Area(description="The query within the joke")
punchline: str = Area(description="The reply within the joke")
@model_validator(mode="earlier than")
@classmethod
def validate_setup(cls, values: dict) -> dict:
setup = values.get("setup")
if setup and setup[-1] != "?":
increase ValueError("Setup should finish with a query mark!"
return values
# Create the parser
parser = PydanticOutputParser(pydantic_object=Joke)
# Outline the immediate template
immediate = PromptTemplate(
template="Reply the person question.n{format_instructions}n{question}n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Mix the mannequin and parser
prompt_and_model = immediate | mannequin
# Generate output
output = prompt_and_model.invoke({"question": "Inform me a joke."})
# Parse the output
parsed_output = parser.invoke(output)
# Print the parsed output
print(parsed_output)Output:

LCEL Integration
Output parsers combine easily with LangChain Expression Language (LCEL), enabling complicated chaining and streaming of information. For instance:
chain = immediate | mannequin | parser
parsed_response = chain.invoke({"question": "Inform me a joke."})
print(parsed_response)
Output:

Streaming Structured Outputs
LangChain’s output parsers additionally assist streaming, permitting partial outputs to be generated dynamically.
Instance with SimpleJsonOutputParser:
from langchain.output_parsers.json import SimpleJsonOutputParser
json_prompt = PromptTemplate.from_template(
"Return a JSON object with an `reply` key that solutions the next query: {query}"
)
json_parser = SimpleJsonOutputParser()
json_chain = json_prompt | mannequin | json_parser
for chunk in json_chain.stream({"query": "Who invented the bulb?"}):
print(chunk)Output:
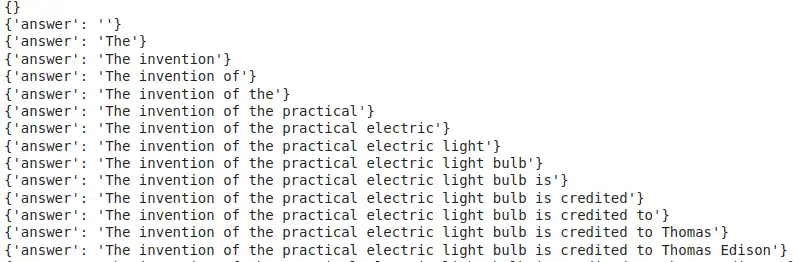
Instance with PydanticOutputParser:
for chunk in chain.stream({"question": "Inform me a joke."}):
print(chunk)Output:

- Unified Parsing: Output parsers convert uncooked textual content into significant, structured codecs.
- Validation: Parsers can validate knowledge earlier than parsing it.
- Streaming Compatibility: Streaming permits partial outputs for real-time interactions.
Output parsers like PydanticOutputParser allow the environment friendly extraction, validation, and streaming of structured responses from LLMs, bettering flexibility in dealing with mannequin outputs.
How one can Parse JSON Output?
Whereas some language fashions natively assist structured outputs, others depend on output parsers for outlining and processing structured knowledge. The JsonOutputParser is a robust instrument for parsing JSON schemas, enabling structured info extraction from mannequin responses.
Key Options of JsonOutputParser
- Schema Definition: Permits arbitrary JSON schemas to be specified immediately within the immediate.
- Streaming Assist: Streams partial JSON objects as they’re generated.
- Pydantic Integration (Elective): Can combine with Pydantic fashions for strict schema validation.
Instance: Utilizing JsonOutputParser with Pydantic
Right here’s an instance of learn how to mix JsonOutputParser with Pydantic to parse a language mannequin’s output right into a structured format.
Workflow Instance:
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Area
# Initialize the mannequin
mannequin = ChatOpenAI(temperature=0)
# Outline the specified knowledge construction
class MovieQuote(BaseModel):
character: str = Area(description="The character who mentioned the quote")
quote: str = Area(description="The quote itself")
# Create the parser with the schema
parser = JsonOutputParser(pydantic_object=MovieQuote)
# Outline a question
quote_query = "Give me a well-known film quote with the character title."
# Arrange the immediate with formatting directions
immediate = PromptTemplate(
template="Reply the person question.n{format_instructions}n{question}n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Mix the immediate, mannequin, and parser
chain = immediate | mannequin | parser
# Invoke the chai
response = chain.invoke({"question": quote_query})
print(response)Output:
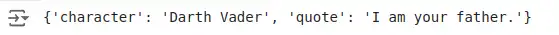
Streaming JSON Outputs
A serious benefit of the JsonOutputParser is its potential to stream partial JSON objects, which is beneficial for real-time purposes.
Instance: Streaming Film Quotes
for chunk in chain.stream({"question": quote_query}):
print(chunk)
Output:

Utilizing JsonOutputParser With out Pydantic
For situations the place strict schema validation shouldn’t be mandatory, you need to use JsonOutputParser with out defining a Pydantic schema. This method is easier however presents much less management over the output construction.
Instance:
# Outline a easy question
quote_query = "Inform me a enjoyable truth about motion pictures."
# Initialize the parser with no Pydantic object
parser = JsonOutputParser()
immediate = PromptTemplate(
template="Reply the person question.n{format_instructions}n{question}n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = immediate | mannequin | parser
response = chain.invoke({"question": quote_query})
print(response)Output:
{'response': "Positive! Here's a enjoyable truth about motion pictures: The primary film
ever made is taken into account to be 'Roundhay Backyard Scene,' which was filmed
in 1888 and is simply 2.11 seconds lengthy.", 'fun_fact': "The primary film ever
made is taken into account to be 'Roundhay Backyard Scene,' which was filmed in
1888 and is simply 2.11 seconds lengthy."}
- Versatility: Use JsonOutputParser with or with out Pydantic for versatile schema enforcement.
- Streaming Assist: Stream partial JSON objects for real-time purposes
By integrating JsonOutputParser into your workflow, you may effectively handle structured knowledge outputs from language fashions, making certain readability and consistency in responses.
Parsing XML Output with XMLOutputParser
LLMs fluctuate of their potential to provide structured knowledge, and XML is a generally used format for organizing hierarchical knowledge. The XMLOutputParser is a robust instrument for requesting, structuring, and parsing XML outputs from fashions right into a usable format.
When to Use XMLOutputParser?
- Structured Knowledge Necessities: If you want hierarchical or nested knowledge.
- Flexibility in Tags: When the XML schema must be dynamic or custom-made.
- Streaming Wants: Helps incremental outputs for real-time use instances.
Primary Instance: Producing and Parsing XML Output
Right here’s learn how to immediate a mannequin to generate XML content material and parse it right into a structured format.
1. Mannequin Generates XML Output
from langchain_core.output_parsers import XMLOutputParser
from langchain_core.prompts import PromptTemplate
# Initialize the mannequin
mannequin = ChatOpenAI(api_key=openai_key, model_name="gpt-4o", temperature=0.0)
# Outline a easy question
question = "Listing well-liked books written by J.Okay. Rowling, enclosed in <ebook></ebook> tags."
# Mannequin generates XML output
response = mannequin.invoke(question)
print(response.content material)Output:

2. Parsing XML Output
To transform the generated XML right into a structured format like a dictionary, use the XMLOutputParser:
parser = XMLOutputParser()
# Add formatting directions to the immediate
immediate = PromptTemplate(
template="{question}n{format_instructions}",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Create a sequence of immediate, mannequin, and parser
chain = immediate | mannequin | parser
# Execute the question
parsed_output = chain.invoke({"question": question})
print(parsed_output)Parsed Output:
{'books': [{'book': [{'title': "Harry Potter and the
Philosopher's Stone"}]}, {'ebook': [{'title': 'Harry
Potter and the Chamber of Secrets'}]}, {'ebook':
[{'title': 'Harry Potter and the Prisoner of Azkaban'}
]}, {'ebook': [{'title': 'Harry Potter and the Goblet
of Fire'}]}, {'ebook': [{'title': 'Harry Potter and
the Order of the Phoenix'}]}, {'ebook': [{'title':
'Harry Potter and the Half-Blood Prince'}]},
{'ebook': [{'title': 'Harry Potter and the Deathly
Hallows'}]}, {'ebook': [{'title': 'The Casual Vacancy'}]},
{'ebook': [{'title': "The Cuckoo's Calling"}]},
{'ebook': [{'title': 'The Silkworm'}]},
{'ebook': [{'title': 'Career of Evil'}]},
{'ebook': [{'title': 'Lethal White'}]},
{'ebook': [{'title': 'Troubled Blood'}]}]}
Customizing XML Tags
You’ll be able to specify customized tags for the output, permitting larger management over the construction of the information.
parser = XMLOutputParser(tags=["author", "book", "genre", "year"])
immediate = PromptTemplate(
template="{question}n{format_instructions}",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = immediate | mannequin | parser
question = "Present an in depth checklist of books by J.Okay. Rowling, together with style and publication 12 months."
custom_output = chain.invoke({"question": question})
print(custom_output)Personalized Output:
{'creator': [{'name': 'J.K. Rowling'},
{'books': [{'book': [{'title': "Harry Potter and the Philosopher's Stone"},
{'genre': 'Fantasy'}, {'year': '1997'}]},
{'ebook': [{'title': 'Harry Potter and the Chamber of Secrets'},
{'genre': 'Fantasy'}, {'year': '1998'}]},
{'ebook': [{'title': 'Harry Potter and the Prisoner of Azkaban'},
{'genre': 'Fantasy'}, {'year': '1999'}]},
{'ebook': [{'title': 'Harry Potter and the Goblet of Fire'},
{'genre': 'Fantasy'}, {'year': '2000'}]},
{'ebook': [{'title': 'Harry Potter and the Order of the Phoenix'},
{'genre': 'Fantasy'}, {'year': '2003'}]},
{'ebook': [{'title': 'Harry Potter and the Half-Blood Prince'},
{'genre': 'Fantasy'}, {'year': '2005'}]},
{'ebook': [{'title': 'Harry Potter and the Deathly Hallows'},
{'genre': 'Fantasy'}, {'year': '2007'}]},
{'ebook': [{'title': 'The Casual Vacancy'},
{'genre': 'Fiction'}, {'year': '2012'}]},
{'ebook': [{'title': "The Cuckoo's Calling"},
{'genre': 'Crime Fiction'}, {'year': '2013'}]},
{'ebook': [{'title': 'The Silkworm'},
{'genre': 'Crime Fiction'}, {'year': '2014'}]},
{'ebook': [{'title': 'Career of Evil'},
{'genre': 'Crime Fiction'}, {'year': '2015'}]},
{'ebook': [{'title': 'Lethal White'},
{'genre': 'Crime Fiction'}, {'year': '2018'}]},
{'ebook': [{'title': 'Troubled Blood'},
{'genre': 'Crime Fiction'}, {'year': '2020'}]},
{'ebook': [{'title': 'The Ink Black Heart'},
{'genre': 'Crime Fiction'}, {'year': '2022'}]}]}]}
Streaming XML Outputs
The XMLOutputParser additionally helps streaming partial outcomes for real-time processing, making it best for situations the place knowledge have to be processed as it’s generated.
Instance:
for chunk in chain.stream({"question": question}):
print(chunk)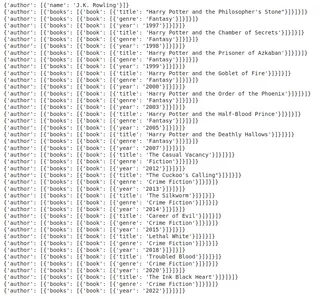
Key Suggestions
- Formatting Directions: Use parser.get_format_instructions() to include clear pointers for the mannequin.
- Experiment with Tags: Outline particular tags to tailor the construction to your wants.
- Mannequin Choice: Select fashions with sturdy XML era capabilities, like Anthropic’s Claude-2.
By leveraging XMLOutputParser, you may effectively request, validate, and remodel XML-based outputs into structured knowledge codecs, permitting you to work with complicated hierarchical info successfully.
Parsing YAML Output with YamlOutputParser
YAML is a widely-used format for representing structured knowledge clear and human-readable. The YamlOutputParser presents a simple technique to request and parse YAML-formatted outputs from language fashions, simplifying structured knowledge extraction whereas adhering to an outlined schema.
When to Use YamlOutputParser
- Readable Outputs: YAML is good when human readability is prioritized over uncooked knowledge codecs like JSON or XML.
- Customized Knowledge Fashions: If the information wants to evolve to a selected schema for additional processing.
- Integration with Pydantic: That is used to validate and map parsed YAML to Python knowledge fashions.
Primary Instance: Producing YAML Output
To get began, outline an information construction and use the YamlOutputParser to information the mannequin’s output.
1. Mannequin Generates YAML Output
from langchain.output_parsers import YamlOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Area
# Outline the specified construction
class Recipe(BaseModel):
title: str = Area(description="The title of the dish")
substances: checklist[str] = Area(description="Listing of substances for the recipe")
steps: checklist[str] = Area(description="Steps to organize the recipe")
# Initialize the mannequin
mannequin = ChatOpenAI(temperature=0)
# Outline a question to generate structured YAML output
question = "Present a easy recipe for pancakes."
# Arrange the parser
parser = YamlOutputParser(pydantic_object=Recipe)
# Inject parser directions into the immediate
immediate = PromptTemplate(
template="Reply the person question.n{format_instructions}n{question}n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Chain the parts collectively
chain = immediate | mannequin | parser
# Execute the question
output = chain.invoke({"question": question})
print(output)Instance Output:
title="Pancakes" substances=['1 cup all-purpose flour',
'2 tablespoons sugar', '1 tablespoon baking powder',
'1/2 teaspoon salt', '1 cup milk',
'2 tablespoons unsalted butter, melted', '1 large egg']
steps=['In a mixing bowl, whisk together flour, sugar,
baking powder, and salt.', 'In a separate bowl,
mix milk, melted butter, and egg.',
'Combine wet and dry ingredients,
stirring until just combined (batter may be lumpy).',
'Heat a non-stick pan over medium heat and pour
1/4 cup of batter for each pancake.',
'Cook until bubbles form on the surface,
then flip and cook until golden brown.',
'Serve hot with your favorite toppings.']

Parsing and Validating YAML
As soon as the YAML output is generated, the YamlOutputParser converts the YAML right into a Pydantic object, making the information programmatically accessible.
Parsed Output:
print(output.title)
print(output.substances)
print(output.steps[0])
Customizing YAML Schema
You’ll be able to customise the schema to satisfy particular wants by defining further fields or constraints.
from langchain.output_parsers import YamlOutputParser
from pydantic import BaseModel, Area
# Outline a customized schema for HabitChange
class HabitChange(BaseModel):
behavior: str = Area(description="A day by day behavior")
sustainable_alternative: str = Area(description="An environmentally pleasant various")
# Create the parser utilizing the customized schema
parser = YamlOutputParser(pydantic_object=HabitChange)
# Pattern output out of your chain
output = """
behavior: Utilizing plastic baggage for grocery buying.
sustainable_alternative: Convey reusable baggage to the shop to cut back plastic waste and shield the atmosphere.
"""
# Parse the output
parsed_output = parser.parse(output)
# Print the parsed output
print(parsed_output)
Customized Output:
behavior="Utilizing plastic baggage for grocery buying."
sustainable_alternative="Convey reusable baggage to the shop
to cut back plastic waste and shield the atmosphere."
Including Your Personal Formatting Directions
You’ll be able to increase the mannequin’s default YAML directions with your personal to additional management the format of the output.
Instance of Generated Directions:
The output ought to be formatted as a YAML occasion that conforms to the next JSON schema:
- At all times use 2-space indentation and enclose YAML output in triple backticks.
You’ll be able to edit the immediate to offer further context or implement stricter formatting necessities.
Why YAML?
- Readable Hierarchical Knowledge: Splendid for nested buildings.
- Schema Validation: Seamlessly integrates with instruments like Pydantic to make sure legitimate outputs.
- Flexibility in Output Construction: Tags and formatting could be simply tailor-made to particular purposes.
The YamlOutputParser is a robust instrument for leveraging YAML for structured outputs from language fashions. By combining it with instruments like Pydantic, you may make sure that the generated knowledge is each legitimate and usable, streamlining workflows that depend on structured responses.
Dealing with Parsing Errors with RetryOutputParser
Parsing errors can happen when a mannequin’s output doesn’t adhere to the anticipated construction or when the response is incomplete. In such instances, the RetryOutputParser presents a mechanism to retry parsing by using the unique immediate alongside the invalid output. This method helps enhance the ultimate consequence by asking the mannequin to refine its response.
When to Retry Parsing
- Partially Full Output: The response is structurally invalid however accommodates recoverable info.
- Context-Particular Lacking Knowledge: The parser can’t infer lacking fields, even with a fixing method.
Instance: Retrying on Parsing Errors
Contemplate a situation the place you’re prompting the mannequin to offer structured motion info, however the response is incomplete.
from langchain.output_parsers import RetryOutputParser, PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
from pydantic import BaseModel, Area
# Outline the anticipated construction
class Motion(BaseModel):
motion: str = Area(description="The motion to be carried out")
action_input: str = Area(description="The enter required for the motion")
# Initialize the parser
parser = PydanticOutputParser(pydantic_object=Motion)
# Outline a immediate template
template = """Based mostly on the person's query, present an Motion and its corresponding Motion Enter.
{format_instructions}
Query: {question}
Response:"""
immediate = PromptTemplate(
template=template,
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Put together the question and unhealthy response
question = "Who's Leo DiCaprio's girlfriend?"
prompt_value = immediate.format_prompt(question=question)
bad_response="{"motion": "search"}"
# Try parsing the unfinished response
attempt:
parser.parse(bad_response)
besides Exception as e:
print(f"Parsing failed: {e}")Output:

Retrying Parsing with RetryOutputParser
The RetryOutputParser retries parsing by passing the unique immediate and incomplete output again to the mannequin, prompting it to offer a extra full reply.
# Initialize a RetryOutputParser
retry_parser = RetryOutputParser.from_llm(parser=parser, llm=OpenAI(temperature=0))
# Retry parsing
retried_output = retry_parser.parse_with_prompt(bad_response, prompt_value)
print(retried_output)Output:
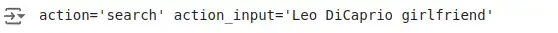
Customized Chains for Retrying Parsing
You’ll be able to combine the RetryOutputParser into a sequence to streamline the dealing with of parsing errors and automate reprocessing.
from langchain_core.runnables import RunnableLambda, RunnableParallel
# Outline a sequence for producing and retrying responses
completion_chain = immediate | OpenAI(temperature=0)
main_chain = RunnableParallel(
completion=completion_chain,
prompt_value=immediate
) | RunnableLambda(lambda x: retry_parser.parse_with_prompt(**x))
# Invoke the chain
output = main_chain.invoke({"question": question})
print(output)
Output:
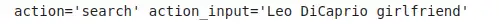
Key Advantages of RetryOutputParser
- Immediate Utilization: Combines the unique immediate and incomplete output for extra correct retries.
- Higher than Fixing Parsers: When context is critical to deduce lacking fields, retries enhance outcomes.
- Seamless Integration: Might be embedded in chains for automated error dealing with and reprocessing.
The RetryOutputParser gives a sturdy approach to deal with parsing errors by leveraging the mannequin’s potential to regenerate outputs in gentle of prior errors. This ensures extra constant, full, and contextually acceptable responses for structured knowledge workflows.
How one can Use the Output-Fixing Parser?
The OutputFixingParser is designed to assist when one other output parser fails on account of formatting errors. As an alternative of merely elevating an error, it might try and right the misformatted output by passing it again to a language mannequin for reprocessing. This helps “repair” points similar to incorrect JSON formatting or lacking required fields.
When to Use the Output-Fixing Parser
- Preliminary Output Does Not Adhere to Anticipated Schema: When the response doesn’t match the anticipated format or construction.
- Incomplete or Malformed Knowledge: When there’s a necessity to repair minor errors within the response with out failing your entire course of.
Instance: Parsing and Fixing Output
Suppose you’re parsing an actor’s filmography, however the knowledge you obtain is misformatted and doesn’t adjust to the anticipated schema.
from typing import Listing
from langchain_core.exceptions import OutputParserException
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Area
# Outline the anticipated construction
class Actor(BaseModel):
title: str = Area(description="title of the actor")
film_names: Listing[str] = Area(description="checklist of names of movies they starred in")
# Outline the question
actor_query = "Generate the filmography for a random actor."
# Initialize the parser
parser = PydanticOutputParser(pydantic_object=Actor)
# Misformatted response
misformatted = "{'title': 'Tom Hanks', 'film_names': ['Forrest Gump']}"
# Attempt to parse the misformatted output
attempt:
parser.parse(misformatted)
besides OutputParserException as e:
print(f"Parsing failed: {e}")Output:

Fixing the Output with OutputFixingParser
To repair the error, we go the problematic output to the OutputFixingParser, which makes use of the mannequin to right it:
from langchain.output_parsers import OutputFixingParser
# Initialize the OutputFixingParser
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
# Use the OutputFixingParser to try fixing the response
fixed_output = new_parser.parse(misformatted)
print(fixed_output)
Output:

Key Options of OutputFixingParser
- Error Dealing with and Fixing: If the preliminary parser fails, the OutputFixingParser makes an attempt to repair the output utilizing the language mannequin.
- Versatile: Works with any current output parser and language mannequin to deal with varied parsing errors.
- Improved Parsing: Permits the system to get better from minor errors, making it extra resilient to inconsistencies in mannequin outputs.
This method is especially helpful in data-driven duties the place the mannequin’s output might typically be incomplete or poorly formatted however nonetheless accommodates helpful info that may be salvaged with some corrections.
Conclusion
The output parsers—YamlOutputParser, RetryOutputParser, and OutputFixingParser—play essential roles in dealing with structured knowledge and addressing parsing errors in language mannequin outputs. The YamlOutputParser is especially helpful for producing and parsing structured YAML outputs, making knowledge human-readable and simply mapped to Python fashions by way of Pydantic. It’s best when knowledge must be readable, validated, and customised.
However, the RetryOutputParser helps get better from incomplete or invalid responses by using the unique immediate and output, permitting the mannequin to refine its response. This ensures extra correct, contextually acceptable outputs when sure fields are lacking or the information is incomplete.
Lastly, the OutputFixingParser tackles misformatted outputs, similar to incorrect JSON or lacking fields, by reprocessing the invalid knowledge. This parser enhances resilience by correcting minor errors with out halting the method, making certain that the system can get better from inconsistencies. Collectively, these instruments allow constant, structured, and error-free outputs, even when confronted with incomplete or misformatted knowledge.
Additionally, in case you are in search of Generative AI course on-line, then discover: GenAI Pinnacle Program
Steadily Requested Questions
Ans. The YamlOutputParser is used to parse and generate YAML-formatted outputs from language fashions. It helps in structuring knowledge in a human-readable method and maps it to Python fashions utilizing instruments like Pydantic. This parser is good for duties the place structured and readable outputs are wanted.
Ans. The RetryOutputParser is used when a parsing error happens, similar to incomplete or invalid responses. It retries the parsing course of through the use of the unique immediate and the preliminary invalid output, asking the mannequin to refine and proper its response. This helps to generate extra correct, full outputs, particularly when fields are lacking or partially accomplished.
Ans. The OutputFixingParser is beneficial when the output is misformatted or doesn’t adhere to the anticipated schema, similar to when JSON formatting points come up or required fields are lacking. It helps in fixing these errors by passing the misformatted output again to the mannequin for correction, making certain the information could be parsed appropriately.
Ans. Sure, the YamlOutputParser could be custom-made to suit particular wants. You’ll be able to outline customized schemas utilizing Pydantic fashions and specify further fields, constraints, or codecs to make sure the parsed knowledge matches your necessities.
Ans. If parsing fails after retrying with the RetryOutputParser, the system may have additional handbook intervention. Nevertheless, this parser considerably reduces the probability of failures by leveraging the unique immediate and output to refine the response.
Hello, I’m Janvi, a passionate knowledge science fanatic at the moment working at Analytics Vidhya. My journey into the world of information started with a deep curiosity about how we are able to extract significant insights from complicated datasets.