
Diffusion fashions have lately emerged because the de facto customary for producing advanced, high-dimensional outputs. You could know them for his or her skill to provide gorgeous AI artwork and hyper-realistic artificial photographs, however they’ve additionally discovered success in different functions comparable to drug design and steady management. The important thing thought behind diffusion fashions is to iteratively rework random noise right into a pattern, comparable to a picture or protein construction. That is sometimes motivated as a most probability estimation drawback, the place the mannequin is educated to generate samples that match the coaching information as carefully as doable.
Nevertheless, most use circumstances of diffusion fashions usually are not straight involved with matching the coaching information, however as an alternative with a downstream goal. We don’t simply need a picture that appears like current photographs, however one which has a selected sort of look; we don’t simply desire a drug molecule that’s bodily believable, however one that’s as efficient as doable. On this submit, we present how diffusion fashions will be educated on these downstream targets straight utilizing reinforcement studying (RL). To do that, we finetune Steady Diffusion on a wide range of targets, together with picture compressibility, human-perceived aesthetic high quality, and prompt-image alignment. The final of those targets makes use of suggestions from a big vision-language mannequin to enhance the mannequin’s efficiency on uncommon prompts, demonstrating how highly effective AI fashions can be utilized to enhance one another with none people within the loop.
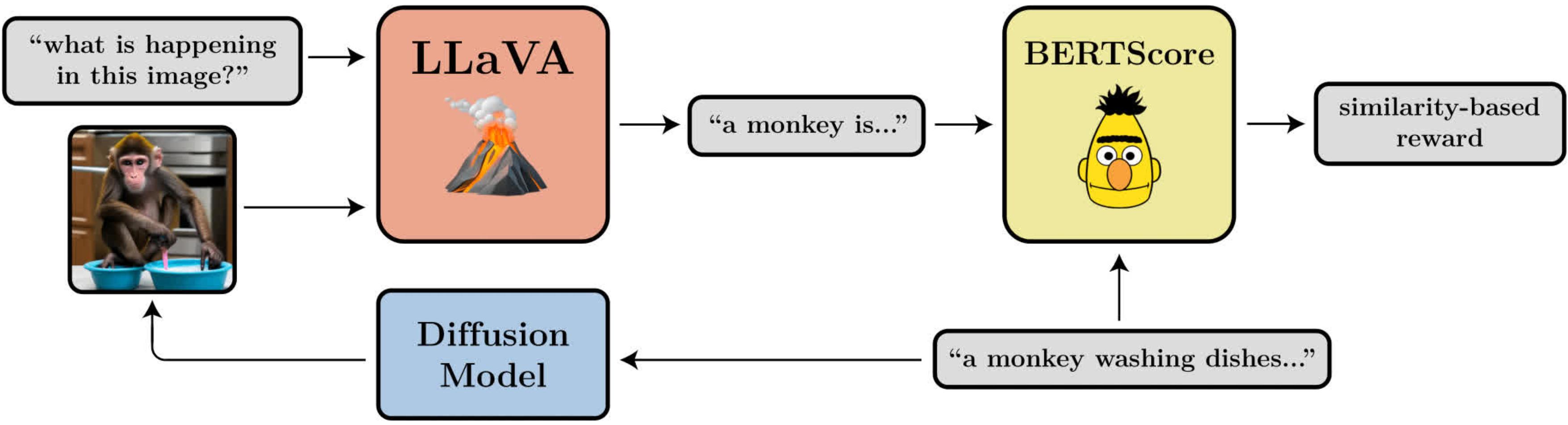
A diagram illustrating the prompt-image alignment goal. It makes use of LLaVA, a big vision-language mannequin, to guage generated photographs.
Denoising Diffusion Coverage Optimization
When turning diffusion into an RL drawback, we make solely probably the most fundamental assumption: given a pattern (e.g. a picture), we’ve entry to a reward perform that we are able to consider to inform us how “good” that pattern is. Our aim is for the diffusion mannequin to generate samples that maximize this reward perform.
Diffusion fashions are sometimes educated utilizing a loss perform derived from most probability estimation (MLE), which means they’re inspired to generate samples that make the coaching information look extra probably. Within the RL setting, we now not have coaching information, solely samples from the diffusion mannequin and their related rewards. A method we are able to nonetheless use the identical MLE-motivated loss perform is by treating the samples as coaching information and incorporating the rewards by weighting the loss for every pattern by its reward. This offers us an algorithm that we name reward-weighted regression (RWR), after current algorithms from RL literature.
Nevertheless, there are a couple of issues with this method. One is that RWR shouldn’t be a very actual algorithm — it maximizes the reward solely roughly (see Nair et. al., Appendix A). The MLE-inspired loss for diffusion can also be not actual and is as an alternative derived utilizing a variational certain on the true probability of every pattern. Because of this RWR maximizes the reward by way of two ranges of approximation, which we discover considerably hurts its efficiency.
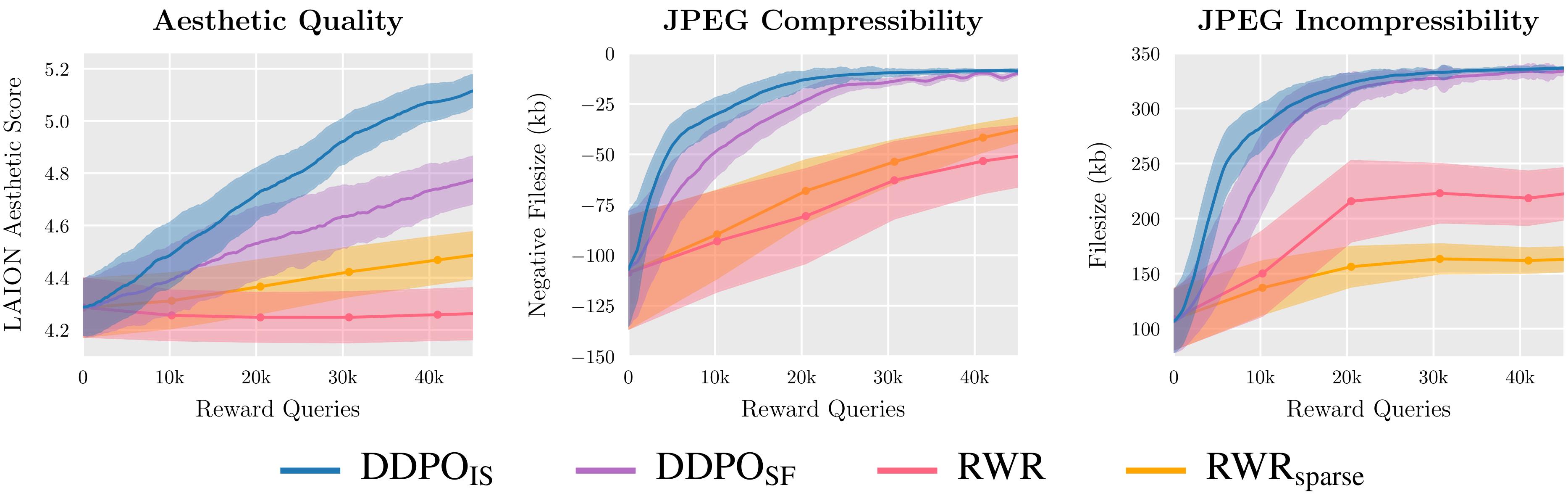
We consider two variants of DDPO and two variants of RWR on three reward capabilities and discover that DDPO constantly achieves the perfect efficiency.
The important thing perception of our algorithm, which we name denoising diffusion coverage optimization (DDPO), is that we are able to higher maximize the reward of the ultimate pattern if we take note of your entire sequence of denoising steps that obtained us there. To do that, we reframe the diffusion course of as a multi-step Markov resolution course of (MDP). In MDP terminology: every denoising step is an motion, and the agent solely will get a reward on the ultimate step of every denoising trajectory when the ultimate pattern is produced. This framework permits us to use many highly effective algorithms from RL literature which might be designed particularly for multi-step MDPs. As an alternative of utilizing the approximate probability of the ultimate pattern, these algorithms use the precise probability of every denoising step, which is extraordinarily simple to compute.
We selected to use coverage gradient algorithms because of their ease of implementation and previous success in language mannequin finetuning. This led to 2 variants of DDPO: DDPOSF, which makes use of the easy rating perform estimator of the coverage gradient also referred to as REINFORCE; and DDPOIS, which makes use of a extra highly effective significance sampled estimator. DDPOIS is our best-performing algorithm and its implementation carefully follows that of proximal coverage optimization (PPO).
Finetuning Steady Diffusion Utilizing DDPO
For our important outcomes, we finetune Steady Diffusion v1-4 utilizing DDPOIS. Now we have 4 duties, every outlined by a special reward perform:
- Compressibility: How simple is the picture to compress utilizing the JPEG algorithm? The reward is the destructive file measurement of the picture (in kB) when saved as a JPEG.
- Incompressibility: How arduous is the picture to compress utilizing the JPEG algorithm? The reward is the constructive file measurement of the picture (in kB) when saved as a JPEG.
- Aesthetic High quality: How aesthetically interesting is the picture to the human eye? The reward is the output of the LAION aesthetic predictor, which is a neural community educated on human preferences.
- Immediate-Picture Alignment: How properly does the picture characterize what was requested for within the immediate? This one is a little more difficult: we feed the picture into LLaVA, ask it to explain the picture, after which compute the similarity between that description and the unique immediate utilizing BERTScore.
Since Steady Diffusion is a text-to-image mannequin, we additionally want to select a set of prompts to offer it throughout finetuning. For the primary three duties, we use easy prompts of the shape “a(n) [animal]”. For prompt-image alignment, we use prompts of the shape “a(n) [animal] [activity]”, the place the actions are “washing dishes”, “taking part in chess”, and “driving a motorbike”. We discovered that Steady Diffusion usually struggled to provide photographs that matched the immediate for these uncommon eventualities, leaving loads of room for enchancment with RL finetuning.
First, we illustrate the efficiency of DDPO on the easy rewards (compressibility, incompressibility, and aesthetic high quality). The entire photographs are generated with the identical random seed. Within the prime left quadrant, we illustrate what “vanilla” Steady Diffusion generates for 9 completely different animals; all the RL-finetuned fashions present a transparent qualitative distinction. Apparently, the aesthetic high quality mannequin (prime proper) tends in direction of minimalist black-and-white line drawings, revealing the sorts of photographs that the LAION aesthetic predictor considers “extra aesthetic”.

Subsequent, we reveal DDPO on the extra advanced prompt-image alignment activity. Right here, we present a number of snapshots from the coaching course of: every sequence of three photographs reveals samples for a similar immediate and random seed over time, with the primary pattern coming from vanilla Steady Diffusion. Apparently, the mannequin shifts in direction of a extra cartoon-like type, which was not intentional. We hypothesize that it is because animals doing human-like actions usually tend to seem in a cartoon-like type within the pretraining information, so the mannequin shifts in direction of this type to extra simply align with the immediate by leveraging what it already is aware of.

Surprising Generalization
Stunning generalization has been discovered to come up when finetuning massive language fashions with RL: for instance, fashions finetuned on instruction-following solely in English usually enhance in different languages. We discover that the identical phenomenon happens with text-to-image diffusion fashions. For instance, our aesthetic high quality mannequin was finetuned utilizing prompts that had been chosen from a listing of 45 widespread animals. We discover that it generalizes not solely to unseen animals but additionally to on a regular basis objects.

Our prompt-image alignment mannequin used the identical record of 45 widespread animals throughout coaching, and solely three actions. We discover that it generalizes not solely to unseen animals but additionally to unseen actions, and even novel mixtures of the 2.

Overoptimization
It’s well-known that finetuning on a reward perform, particularly a discovered one, can result in reward overoptimization the place the mannequin exploits the reward perform to realize a excessive reward in a non-useful method. Our setting isn’t any exception: in all of the duties, the mannequin ultimately destroys any significant picture content material to maximise reward.

We additionally found that LLaVA is inclined to typographic assaults: when optimizing for alignment with respect to prompts of the shape “[n] animals”, DDPO was in a position to efficiently idiot LLaVA by as an alternative producing textual content loosely resembling the right quantity.

There’s at present no general-purpose technique for stopping overoptimization, and we spotlight this drawback as an vital space for future work.
Conclusion
Diffusion fashions are arduous to beat in terms of producing advanced, high-dimensional outputs. Nevertheless, thus far they’ve principally been profitable in functions the place the aim is to be taught patterns from heaps and many information (for instance, image-caption pairs). What we’ve discovered is a option to successfully prepare diffusion fashions in a method that goes past pattern-matching — and with out essentially requiring any coaching information. The chances are restricted solely by the standard and creativity of your reward perform.
The way in which we used DDPO on this work is impressed by the latest successes of language mannequin finetuning. OpenAI’s GPT fashions, like Steady Diffusion, are first educated on large quantities of Web information; they’re then finetuned with RL to provide helpful instruments like ChatGPT. Sometimes, their reward perform is discovered from human preferences, however others have extra lately discovered produce highly effective chatbots utilizing reward capabilities based mostly on AI suggestions as an alternative. In comparison with the chatbot regime, our experiments are small-scale and restricted in scope. However contemplating the large success of this “pretrain + finetune” paradigm in language modeling, it definitely looks like it’s value pursuing additional on this planet of diffusion fashions. We hope that others can construct on our work to enhance massive diffusion fashions, not only for text-to-image era, however for a lot of thrilling functions comparable to video era, music era, picture modifying, protein synthesis, robotics, and extra.
Moreover, the “pretrain + finetune” paradigm shouldn’t be the one method to make use of DDPO. So long as you could have a very good reward perform, there’s nothing stopping you from coaching with RL from the beginning. Whereas this setting is as-yet unexplored, it is a place the place the strengths of DDPO might actually shine. Pure RL has lengthy been utilized to all kinds of domains starting from taking part in video games to robotic manipulation to nuclear fusion to chip design. Including the highly effective expressivity of diffusion fashions to the combo has the potential to take current functions of RL to the following stage — and even to find new ones.
This submit relies on the next paper:
If you wish to be taught extra about DDPO, you possibly can take a look at the paper, web site, unique code, or get the mannequin weights on Hugging Face. If you wish to use DDPO in your individual undertaking, take a look at my PyTorch + LoRA implementation the place you possibly can finetune Steady Diffusion with lower than 10GB of GPU reminiscence!
If DDPO evokes your work, please cite it with:
@misc{black2023ddpo,
title={Coaching Diffusion Fashions with Reinforcement Studying},
creator={Kevin Black and Michael Janner and Yilun Du and Ilya Kostrikov and Sergey Levine},
yr={2023},
eprint={2305.13301},
archivePrefix={arXiv},
primaryClass={cs.LG}
}