Discovering buyer segments for optimum retargetting utilizing LLM embeddings and ML mannequin
Introduction
On this article, we’re speaking a few methodology of discovering the client segments inside a binary classification dataset which have the utmost potential to tip over into the needed class. This methodology will be employed for various use-cases resembling selective targetting of consumers within the second spherical of a promotional marketing campaign, or discovering nodes in a community, that are offering less-than-desirable expertise, with the best potential to maneuver over into the fascinating class.
Basically, the strategy offers a approach to prioritise a phase of the dataset which might present the utmost bang for the buck.
The context
On this case, we’re taking a look at a financial institution dataset. The financial institution is actively making an attempt to promote mortgage merchandise to the potential prospects by runnign a marketing campaign. This dataset is in public area offered at Kaggle:
The outline of the issue given above is as follows:
“Nearly all of Thera-Financial institution’s prospects are depositors. The variety of prospects who’re additionally debtors (asset prospects) is kind of small, and the financial institution is fascinated by rapidly increasing this base to do extra mortgage enterprise whereas incomes extra by mortgage curiosity. Particularly, administration desires to search for methods to transform its legal responsibility prospects into retail mortgage prospects whereas maintaining them as depositors. A marketing campaign the financial institution ran final yr for deposit prospects confirmed a conversion fee of over 9.6% success. This has prompted the retail advertising division to develop campaigns with higher goal advertising to extend the success fee with a minimal finances.”
The above downside offers with classifying the shoppers and serving to to prioritise new prospects. However what if we are able to use the information collected within the first spherical to focus on prospects who didn’t buy the mortgage within the first spherical however are most certainly to buy within the second spherical, provided that no less than one attribute or function about them adjustments. Ideally, this might be the function which is best to vary by guide interventions or which might change by itself over time (for instance, earnings typically tends to extend over time or household dimension or schooling degree attained).
The Resolution
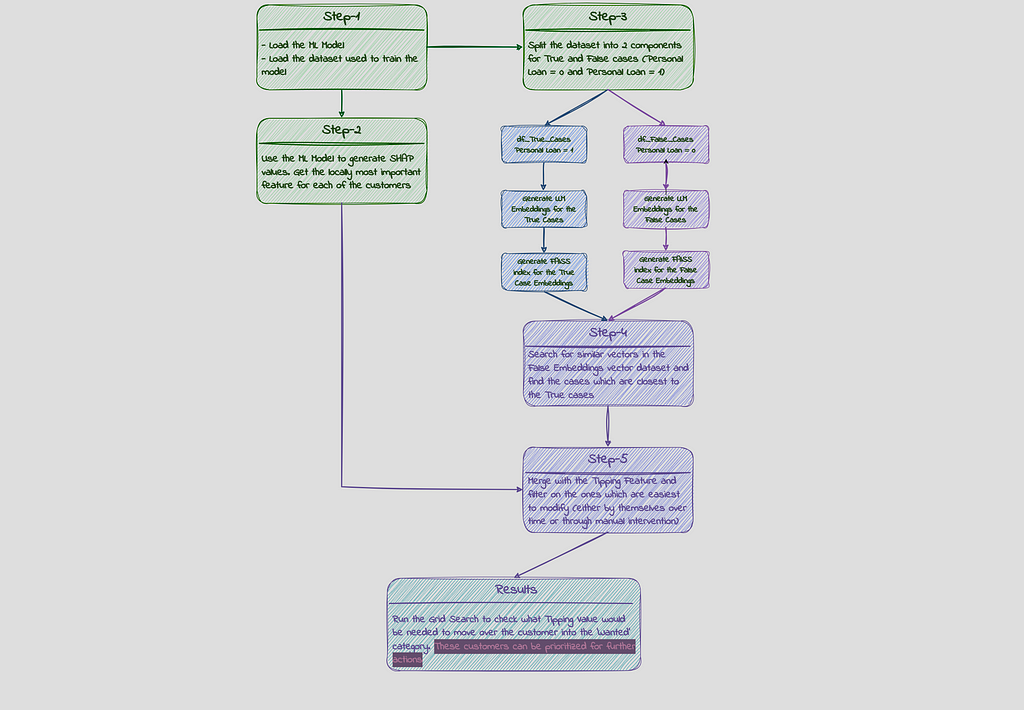
Right here is an outline of how this downside is approached on this instance:
Step -1a : Loading the ML Mannequin
There are quite a few notebooks on Kaggle/Github which offer options to do mannequin tuning utilizing the above dataset. We’ll begin our dialogue with the idea that the mannequin is already tuned and can load it up from our MLFlow repository. This can be a XGBoost mannequin with F1 Rating of 0.99 and AUC of 0.99. The dependent variable (y_label) on this case is ‘Private Mortgage’ column.
mlflow server --host 127.0.0.1 --port 8080
import mlflow
mlflow.set_tracking_uri(uri="http://127.0.0.1:8080")
def get_best_model(experiment_name, scoring_metric):
"""
Retrieves the mannequin from MLflow logged fashions in a given experiment
with one of the best scoring metric.
Args:
experiment_name (str): Title of the experiment to look.
scoring_metric (str): f1_score is used on this instance
Returns:
model_uri: The mannequin path with one of the best F1 rating,
or None if no mannequin or F1 rating is discovered.
artifcat_uri: The trail for the artifacts for one of the best mannequin
"""
experiment = mlflow.get_experiment_by_name(experiment_name)
# Extract the experiment ID
if experiment:
experiment_id = experiment.experiment_id
print(f"Experiment ID for '{experiment_name}': {experiment_id}")
else:
print(f"Experiment '{experiment_name}' not discovered.")
consumer = mlflow.monitoring.MlflowClient()
# Discover runs within the specified experiment
runs = consumer.search_runs(experiment_ids=experiment_id)
# Initialize variables for monitoring
best_run = None
best_score = -float("inf") # Destructive infinity for preliminary comparability
for run in runs:
strive:
run_score = float(run.information.metrics.get(scoring_metric, 0)) # Get F1 rating from params
if run_score > best_score:
best_run = run
best_score = run_score
Model_Path = best_run.information.tags.get("Model_Type")
besides (KeyError): # Skip if rating not discovered or error happens
move
# Return the mannequin model from the run with one of the best F1 rating (if discovered)
if best_run:
model_uri = f"runs:/{best_run.data.run_id}/{Model_Path}"
artifact_uri = f"mlflow-artifacts:/{experiment_id}/{best_run.data.run_id}/artifacts"
print(f"Greatest Rating discovered for {scoring_metric} for experiment: {experiment_name} is {best_score}")
print(f"Greatest Mannequin discovered for {scoring_metric} for experiment: {experiment_name} is {Model_Path}")
return model_uri, artifact_uri
else:
print(f"No mannequin discovered with logged {scoring_metric} for experiment: {experiment_name}")
return None
Experiment_Name = 'Imbalanced_Bank_Dataset'
best_model_uri, best_artifact_uri = get_best_model(Experiment_Name, "f1_score")
if best_model_uri:
loaded_model = mlflow.sklearn.load_model(best_model_uri)
Step-1b: Loading the information
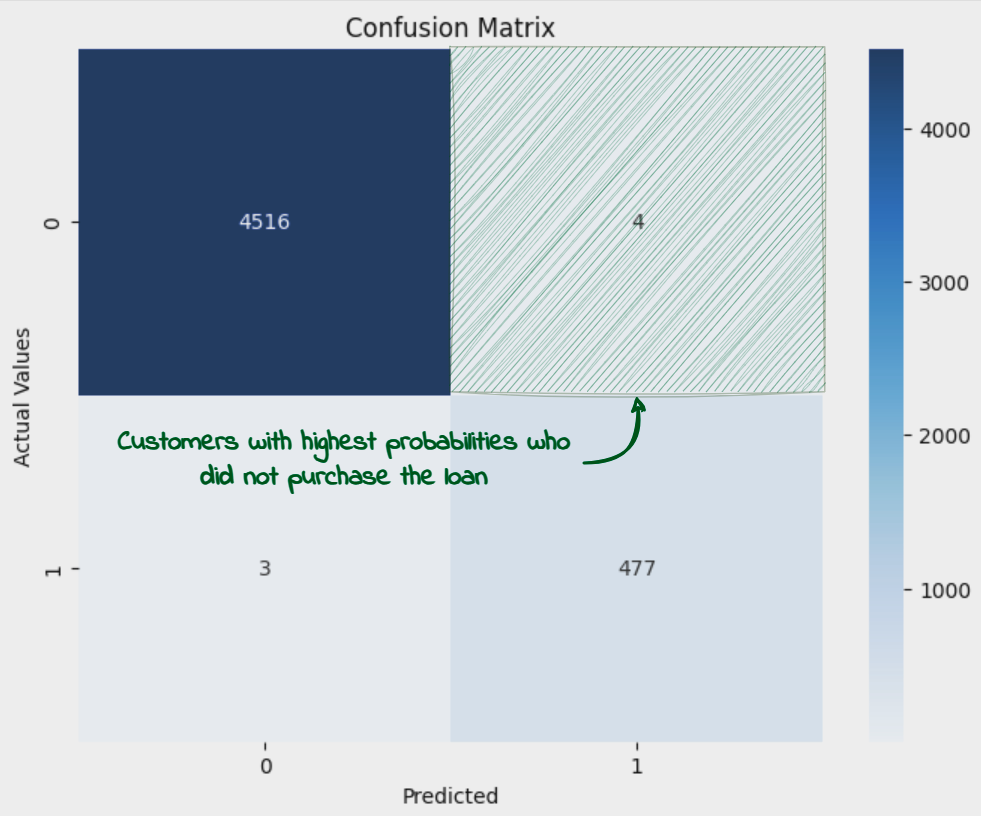
Subsequent, we’d load up the dataset. That is the dataset which has been used for coaching the mannequin, which suggests all of the rows with lacking information or those that are thought of outliers are already faraway from the dataset. We’d additionally calculate the possibilities for every of the shoppers within the dataset to buy the mortgage (given by the column ‘Private Mortgage). We’ll then filter out the shoppers with chances better than 0.5 however which didn’t buy the mortgage (‘Private Mortgage’ = 0). These are the shoppers which ought to have bought the Mortgage as per the prediction mannequin however they didn’t within the first spherical, on account of elements not captured by the options within the dataset. These are additionally the circumstances wrongly predicted by the mannequin and which have contributed to a decrease than 1 Accuracy and F1 figures.
As we set out for spherical 2 marketing campaign, these prospects would function the premise for the targetted advertising strategy.
import numpy as np
import pandas as pd
import os
y_label_column = "Private Mortgage"
def y_label_encoding (label):
strive:
if label == 1:
return 1
elif label == 0:
return 0
elif label == 'Sure':
return 1
elif label == 'No':
return 0
else:
print(f"Invalid label: {label}. Solely 'Sure/1' or 'No/0' are allowed.")
besides:
print('Exception Raised')
def df_splitting(df):
prediction_columns = ['Age', 'Experience', 'Income', 'ZIP Code', 'Family', 'CCAvg',
'Education', 'Mortgage', 'Personal Loan', 'Securities Account',
'CD Account', 'Online', 'CreditCard']
y_test = df[y_label_column].apply(y_label_encoding)
X_test = df[prediction_columns].drop(columns=y_label_column)
return X_test, y_test
"""
load_prediction_data operate ought to confer with the ultimate dataset used for coaching. The operate just isn't offered right here
"""
df_pred = load_prediction_data (best_artifact_uri) ##hundreds dataset right into a dataframe
df_pred['Probability'] = [x[1] for x in loaded_model.predict_proba(df_splitting(df_pred)[0])]
df_pred = df_pred.sort_values(by='Likelihood', ascending=False)
df_potential_cust = df_pred[(df_pred[y_label_column]==0) & (df_pred['Probability']> 0.5)]
print(f'Complete prospects: {df_pred.form[0]}')
df_pred = df_pred[~((df_pred[y_label_column]==0) & (df_pred['Probability']> 0.5))]
print(f'Remaining prospects: {df_pred.form[0]}')
df_potential_cust
We see that there are solely 4 such circumstances which get added to potential prospects desk and are faraway from the principle dataset.

Step-2: Producing SHAP values
We are actually going to generate the Shapely values to find out the native significance of the options and extract the Tipping function ie. the function whose variation can transfer over the client from undesirable class (‘Private Mortgage’ = 0) to the needed class (‘Private Mortgage’ = 1). Particulars about Shapely values will be discovered right here:
An introduction to explainable AI with Shapley values – SHAP newest documentation
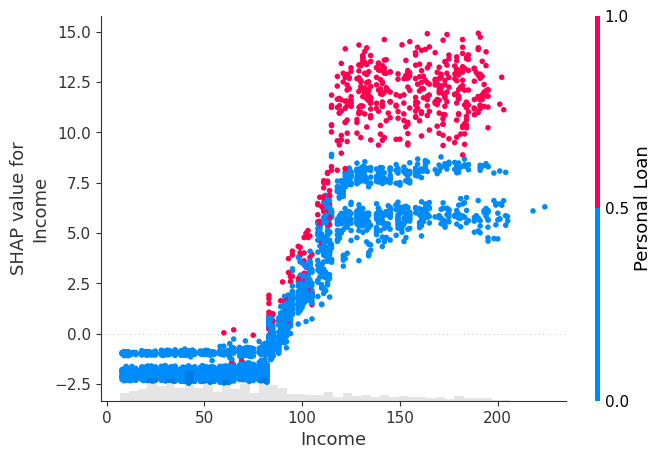
We’ll take a look at a number of the necessary options as nicely to have an concept in regards to the correlation with the dependent variable (‘Private Mortgage’). The three options we’ve shortlisted for this objective are ‘Revenue’, ‘Household’ (Household Dimension) and ‘Schooling’. As we are going to see in a while, these are the options which we’d wish to hold our concentrate on to get the likelihood modified.
import shap
explainer = shap.Explainer(loaded_model, df_pred)
Shap_explainer = explainer(df_pred)
shap.plots.scatter(Shap_explainer[:, "Income"], colour=Shap_explainer[:, "Personal Loan"])
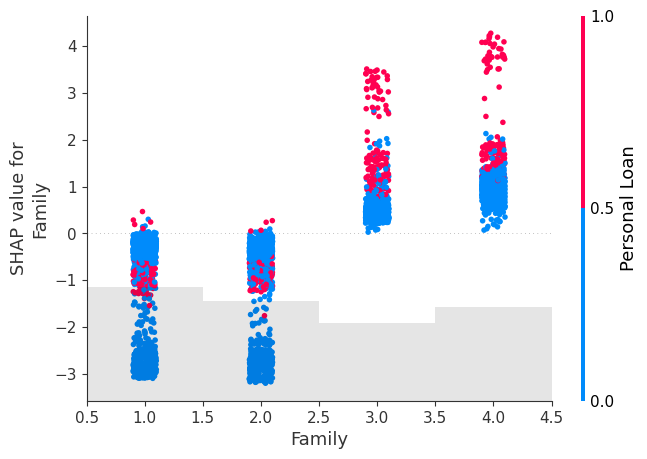
shap.plots.scatter(Shap_explainer[:, "Family"], colour=Shap_explainer[:,'Personal Loan'])
shap.plots.scatter(Shap_explainer[:, "Education"], colour=Shap_explainer[:,'Personal Loan'])
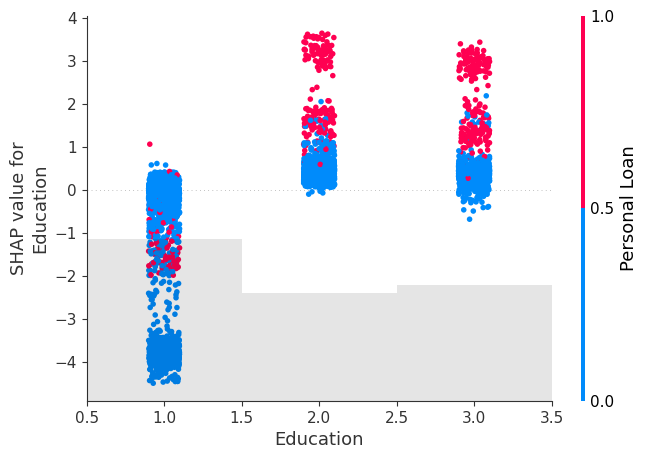
We see that for all 3 options, the acquisition of Private Mortgage enhance because the function worth tends to extend, with Shap values of better than 0 because the function worth will increase indicating a optimistic affect of those options on the tendency to buy.
We’ll now retailer the shap values for every of the shoppers in a dataframe so we are able to entry the domestically most necessary function for later processing.
X_test = df_splitting(df_pred)[0] ## Protecting solely the columns used for prediction
explainer = shap.Explainer(loaded_model.predict, X_test)
Shap_explainer = explainer(X_test)
df_Shap_values = pd.DataFrame(Shap_explainer.values, columns=X_test.columns)
df_Shap_values.to_csv('Credit_Card_Fraud_Shap_Values.csv', index=False)
Step-3 : Creating Vector Embeddings:
As the following step, we transfer on to create the vector embeddings for our dataset utilizing LLM mannequin. The principle objective for that is to have the ability to do vector similarity search. We intend to search out the shoppers within the dataset, who didn’t buy the mortgage, who’re closest to the shoppers within the dataset, who did buy the mortgage. We’d then choose the highest closest prospects and see how the likelihood adjustments for these as soon as we modify the values for crucial function for these prospects.
There are a selection of steps concerned in creating the vector embeddings utilizing LLM and they aren’t described intimately right here. For understanding of those processes, I’d counsel to undergo the under submit by Damian Gill:
Mastering Buyer Segmentation with LLM
In our case, we’re utilizing the sentence transformer SBERT mannequin obtainable at Hugging Face. Listed below are the small print of the mannequin:
sentence-transformers (Sentence Transformers)
For us to get higher vector embeddings, we’d wish to present as a lot particulars in regards to the information in phrases as potential. For the financial institution dataset, the small print of every of the columns are offered in ‘Description’ sheet of the Excel file ‘Bank_Personal_Loan_Modelling.xlsx’. We use this description for the column names. Moreover, we convert the values with just a little extra description than simply having numbers in there. For instance, we exchange column identify ‘Household’ with ‘Household dimension of the client’ and the values on this column from integers resembling 2 to string resembling ‘2 individuals’. Here’s a pattern of the dataset after making these conversions:
def Get_Highest_SHAP_Values (row, no_of_values = 1):
if row.sum() < 0:
top_values = row.nsmallest(no_of_values)
else:
top_values = row.nlargest(no_of_values)
return [f"{col}: {val}" for col, val in zip(top_values.index, top_values)]
def read_orig_data_categorized(categorized_filename, shap_filename = ''):
df = pd.read_csv(categorized_filename)
if shap_filename!= '':
df_shap = pd.read_csv(shap_filename)
df['Most Important Features'] = df_shap.apply(lambda row: Get_Highest_SHAP_Values(row, no_of_values = 1), axis=1)
return df
def Column_name_changes (column_description, df):
df_description = pd.read_excel(column_description, sheet_name='Description',skiprows=6, usecols=[1,2])
df_description.exchange('#','No of ', inplace=True, regex=True)
df_description.exchange('($000)','', inplace=True, regex=True)
df_description.loc[df_description['Unnamed: 1']=='Schooling','Unnamed: 2'] = 'Schooling Stage'
mapping_dict = dict(zip(df_description['Unnamed: 1'], df_description['Unnamed: 2']))
df = df.rename(columns=mapping_dict)
return df
Original_Categorized_Dataset = r'Bank_Personal_Loan_Modelling_Semantic.csv' ## Dataset with extra description of the values sorted in the identical means as df_pred and df_Shap_values
Shap_values_Dataset = r'Credit_Card_Fraud_Shap_Values.csv' ## Shap values dataset
column_description = r'Bank_Personal_Loan_Modelling.xlsx' ## Unique Financial institution Mortgage dataset with the Description Sheet
df_main = read_orig_data_categorized(Original_Categorized_Dataset, Shap_values_Dataset)
df_main = df_main.drop(columns=['ID','ZIP Code'])
df_main = Column_name_changes(column_description, df_main)
df_main.pattern(5)
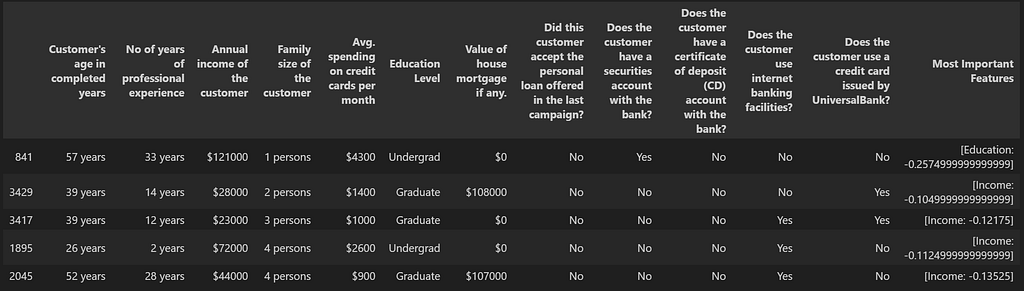
We’ll create two separate datasets — one for purchasers who bought the loans and one for many who didn’t.
y_label_column = 'Did this buyer settle for the private mortgage provided within the final marketing campaign?'
df_main_true_cases = df_main[df_main[y_label_column]=="Sure"].reset_index(drop=True)
df_main_false_cases = df_main[df_main[y_label_column]=="No"].reset_index(drop=True)
We’ll create vector embeddings for each of those circumstances. Earlier than we move on the dataset to condemn transformer, here’s what every row of the financial institution buyer dataset would look like:

from sentence_transformers import SentenceTransformer
def df_to_text(row):
textual content = ''
for col in row.index:
textual content += f"""{col}: {row[col]},"""
return textual content
def generating_embeddings(df):
sentences = df.apply(lambda row: df_to_text(row), axis=1).tolist()
mannequin = SentenceTransformer(r"sentence-transformers/paraphrase-MiniLM-L6-v2")
output = mannequin.encode(sentences=sentences,
show_progress_bar=True,
normalize_embeddings=True)
df_embeddings = pd.DataFrame(output)
return df_embeddings
df_embedding_all = generating_embeddings(df_main)
df_embedding_false_cases = generating_embeddings(df_main_false_cases)
df_embedding_true_cases = generating_embeddings(df_main_true_cases)
Step-4+5: Doing the Vector Search
Subsequent, we might be doing the Approximate Nearest Neighbor similarity search utilizing Euclidean Distance L2 with Fb AI Similarity Search (FAISS) and can create FAISS indexes for these vector datasets. The thought is to seek for prospects within the ‘Private Mortgage = 0’ dataset that are most just like those within the ‘Private Mortgage = 1’ dataset. Mainly we’re searching for prospects who didn’t buy the mortgage however are most related in nature to those who bought the mortgage. On this case, we’re doing the seek for one ‘false’ buyer for every ‘true’ buyer by setting ok=1 (one approximate nearest neighbor) after which sorting the outcomes based mostly on their distances.
Particulars about FAISS similarity search will be discovered right here:
Right here is one other article which explains the usage of L2 with FAISS:
The right way to Use FAISS to Construct Your First Similarity Search
import faiss
def generating_index(df_embeddings):
vector_dimension = df_embeddings.form[1]
index = faiss.IndexFlatL2(vector_dimension)
faiss.normalize_L2(df_embeddings.values)
index.add(df_embeddings.values)
return index
def vector_search(index, df_search, df_original, ok=1):
sentences = df_search.apply(lambda row: df_to_text(row), axis=1).tolist()
mannequin = SentenceTransformer(r"sentence-transformers/paraphrase-MiniLM-L6-v2")
output = mannequin.encode(sentences=sentences,
show_progress_bar=False,
normalize_embeddings=True)
search_vector = output
faiss.normalize_L2(search_vector)
distances, ann = index.search(search_vector, ok=ok)
outcomes = pd.DataFrame({'distances': distances[0], 'ann': ann[0]})
df_results = pd.merge(outcomes, df_original, left_on='ann', right_index= True)
return df_results
def cluster_search(index, df_search, df_original, ok=1):
df_temp = pd.DataFrame()
for i in vary(0,len(df_search)):
df_row_search = df_search.iloc[i:i+1].values
df_temp = pd.concat([df_temp,vector_search_with_embeddings(df_row_search, df_original, index, k=k)])
df_temp = df_temp.sort_values(by='distances')
return df_temp
def vector_search_with_embeddings(search_vector, df_original, index, ok=1):
faiss.normalize_L2(search_vector)
distances, ann = index.search(search_vector, ok=ok)
outcomes = pd.DataFrame({'distances': distances[0], 'ann': ann[0]})
df_results = pd.merge(outcomes, df_original, left_on='ann', right_index= True)
return df_results
index_all = generating_index(df_embedding_all)
index_false_cases = generating_index(df_embedding_false_cases)
index_true_cases = generating_index(df_embedding_true_cases)
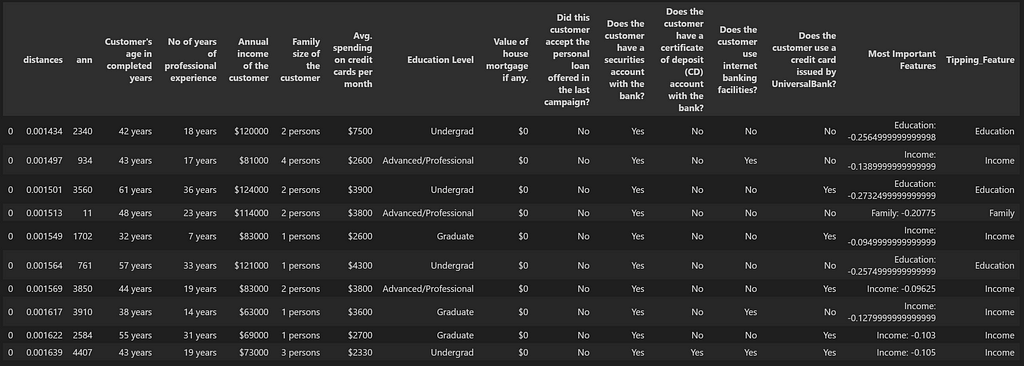
df_results = cluster_search(index_false_cases, df_embedding_true_cases, df_main_false_cases, ok=1)
df_results['Most Important Features'] = [x[0] for x in df_results['Most Important Features'].values]
df_results ['Tipping_Feature'] = [x[0] for x in df_results['Most Important Features'].str.cut up(':')]
df_results = df_results.drop_duplicates(subset=['ann'])
df_results.head(10)
This offers us the checklist of consumers most just like those who bought the mortgage and most certainly to buy within the second spherical, given crucial function which was holding them again within the first spherical, will get barely modified. This buyer checklist can now be prioritized.
Step-6: A comparability with different methodology
At this level, we wish to assess if the above methodology is well worth the time and if there will be one other environment friendly means of extracting the identical data? For instance, we are able to consider getting the ‘False’ prospects with the best chances as those which have the best potential for second spherical purchases. A comparability of such a listing with the above checklist will be useful to see if that may be a quicker means of deriving conclusions.
For this, we merely load up our dataset with the possibilities that we created earlier and choose the highest 10 ‘False’ prospects with the best chances.
df_trial_customers = df_pred[df_pred['Personal Loan']==0].iloc[0:10]
df_trial_customers
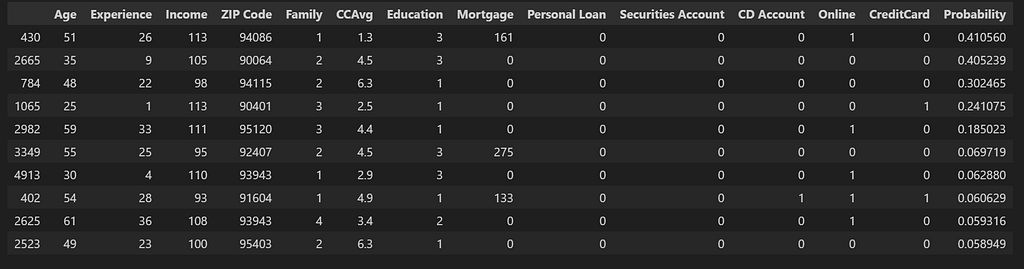
How efficient this checklist is as in comparison with our first checklist and methods to measure that? For this, we wish to consider the effectiveness of the checklist as the share of consumers which we’re in a position to tip over into the needed class with minimal change in crucial function by calculating new likelihood values after making slight change in crucial function. For our evaluation, we are going to solely concentrate on the options Schooling and Household — the options that are more likely to change over time. Although Revenue can be included on this class, for simplification functions, we is not going to think about it for now. We’ll shortlist the highest 10 candidates from each lists which have these because the Tipping_Feature.
It will give us the under 2 lists:
- List_A: That is the checklist we get utilizing the similarity search methodology
- List_B: That is the checklist we get by sorting the False circumstances utilizing their chances
features_list = ['Education', 'Family']
features_list = ('|').be part of(features_list)
df_list_A_Sim_Search = df_results[df_results['Tipping_Feature'].str.accommodates(features_list, case=False)].head(10)
df_list_A_Sim_Search
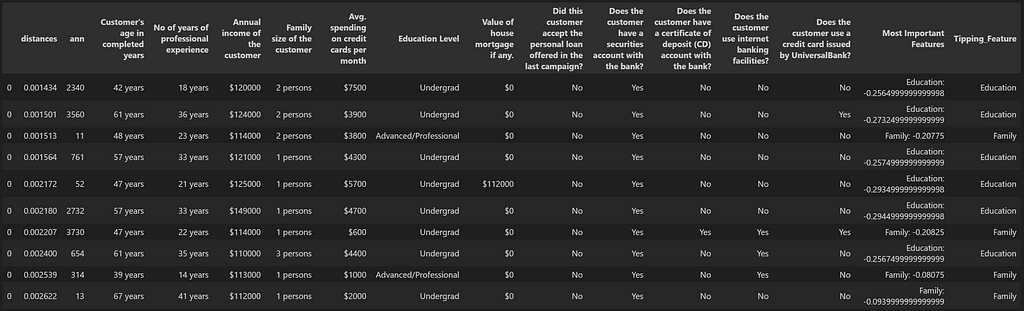
We’ll convert List_A into the unique format which will be then utilized by the ML Mannequin to calculate the possibilities. This is able to require a reference again to the unique df_pred dataset and here’s a operate which can be utilized for that objective.
def main_index_search(results_df, df_given_embeddings, df_original, search_index):
df_temp = pd.DataFrame()
for i in vary(0,len(results_df)):
index_number = results_df['ann'].iloc[i]
df_row_search = df_given_embeddings.iloc[index_number:index_number+1].values
df_temp = pd.concat([df_temp,vector_search_with_embeddings(df_row_search, df_original, search_index, k=1)])
return df_temp
df_list_A_Sim_Search_pred = pd.concat([(main_index_search(df_list_A_Sim_Search, df_embedding_false_cases, df_pred, index_all).drop(columns=['distances','ann'])),
df_list_A_Sim_Search ['Tipping_Feature']], axis=1).reset_index(drop=True)
df_list_A_Sim_Search_pred
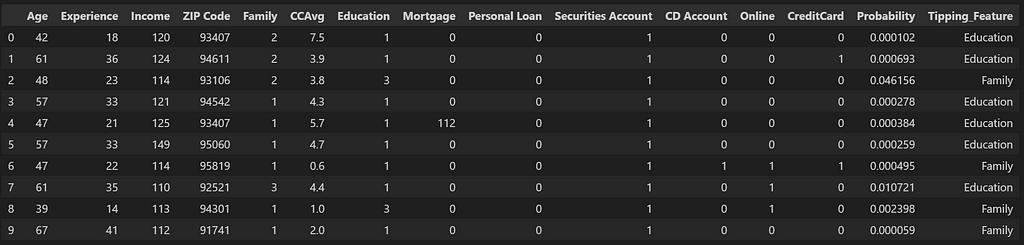
Under is how we are going to get List_B by placing within the required filters on the unique df_pred dataframe.
df_list_B_Probabilities = df_pred.copy().reset_index(drop=True)
df_list_B_Probabilities['Tipping_Feature'] = df_Shap_values.apply(lambda row: Get_Highest_SHAP_Values(row, no_of_values = 1), axis=1)
df_list_B_Probabilities['Tipping_Feature'] = [x[0] for x in df_list_B_Probabilities['Tipping_Feature'].values]
df_list_B_Probabilities ['Tipping_Feature'] = [x[0] for x in df_list_B_Probabilities['Tipping_Feature'].str.cut up(':')]
df_list_B_Probabilities = df_list_B_Probabilities[(df_list_B_Probabilities['Personal Loan']==0) &
(df_list_B_Probabilities['Tipping_Feature'].str.accommodates(features_list, case=False))].head(10)
df_list_B_Probabilities
For analysis, I’ve created a operate which does a grid search on the values of Household or Schooling relying upon the Tipping_Feature for that buyer from minimal worth (which might be the present worth) to the utmost worth (which is the utmost worth seen in the whole dataset for that function) until the likelihood will increase past 0.5.
def finding_max(df):
all_max_values = pd.DataFrame(df.max()).T
return all_max_values
def finding_min(df):
all_min_values = pd.DataFrame(df.min()).T
return all_min_values
def grid_search(row, min_value, max_value, increment, tipping_feature):
row[tipping_feature] = min_value
row['New_Probability'] = [x[1] for x in loaded_model.predict_proba(row_splitting(row).convert_dtypes())][0]
whereas (row['New_Probability']) < 0.5:
if row[tipping_feature] == max_value:
row['Tipping_Value'] = 'Max Worth Reached'
break
else:
row[tipping_feature] = row[tipping_feature] + increment
row['Tipping_Value'] = row[tipping_feature]
row['New_Probability'] = [x[1] for x in loaded_model.predict_proba(row_splitting(row).convert_dtypes())][0]
return row
def row_splitting(row):
prediction_columns = ['Age', 'Experience', 'Income', 'ZIP Code', 'Family', 'CCAvg',
'Education', 'Mortgage', 'Personal Loan', 'Securities Account',
'CD Account', 'Online', 'CreditCard']
X_test = row.to_frame().transpose()
X_test = X_test[prediction_columns].reset_index(drop=True)
X_test = X_test.drop(columns=y_label_column)
return X_test
def tipping_value(row, all_max_values, all_min_values):
tipping_feature = row['Tipping_Feature']
min_value = row[tipping_feature]
max_value = all_max_values[tipping_feature].values[0]
if tipping_feature == 'CCAvg':
increment = 0.2
else:
increment = 1
row = grid_search(row, min_value, max_value, increment, tipping_feature)
row ['Value_Difference'] = row[tipping_feature] - min_value
row ['Original_Value'] = min_value
return row
min_values = finding_min(df_pred)
max_values = finding_max(df_pred)
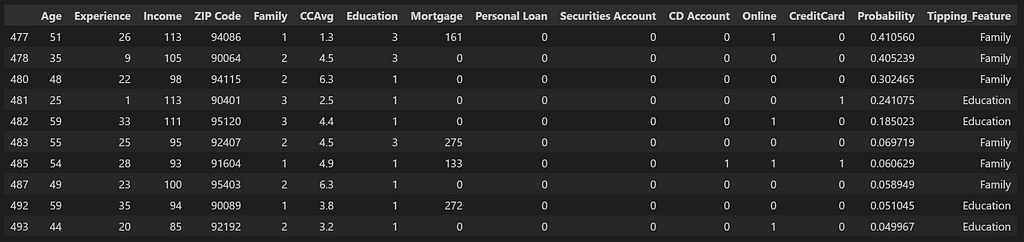
df_new_prob = df_list_B_Probabilities.apply(lambda row: tipping_value(row, max_values, min_values), axis=1)
df_new_prob

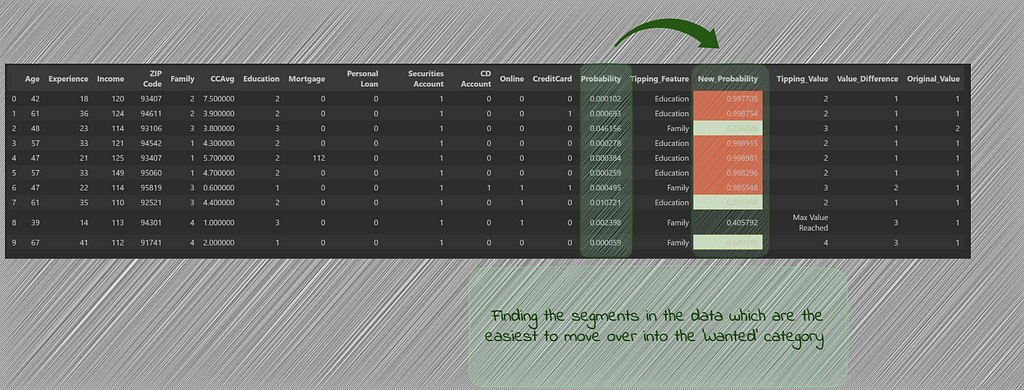
We see that with Checklist B, the candidates which we obtained by the usage of chances, there was one candidate which couldn’t transfer into the needed class after altering the tipping_values. On the similar time, there have been 4 candidates (highlighted in crimson) which present very excessive likelihood of buying the mortgage after the tipping function adjustments.
We run this once more for the candidates in Checklist A.
df_new_prob = df_list_A_Sim_Search_pred.apply(lambda row: tipping_value(row, max_values, min_values), axis=1)
df_new_prob
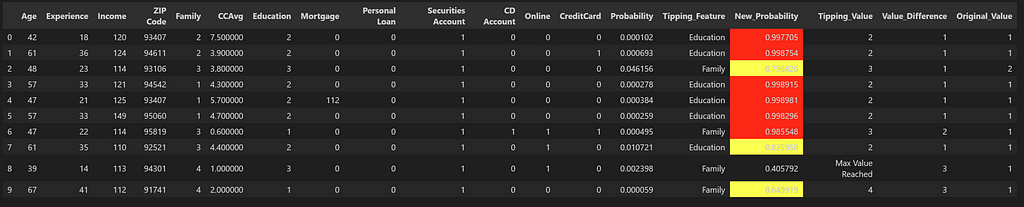
For Checklist A, we see that whereas there’s one candidate which couldn’t tip over into the needed class, there are 6 candidates (highlighted in crimson) which present very excessive likelihood as soon as the tipping function worth is modified. We are able to additionally see that these candidates initially had very low chances of buying the mortgage and with out the usage of similarity search, these potential candidates would have been missed out.
Conclusion
Whereas there will be different strategies to seek for potential candidates, similarity search utilizing LLM vector embeddings can spotlight candidates which might most certainly not get prioritized in any other case. The tactic can have varied utilization and on this case was mixed with the possibilities calculated with the assistance of XGBoost mannequin.
Except said in any other case, all photos are by the creator.
Unlocking Hidden Potential: Exploring Second-Spherical Purchasers was initially printed in In direction of Information Science on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.