In immediately’s fast-paced enterprise surroundings, organizations are inundated with knowledge that drives choices, optimizes operations, and maintains competitiveness. Nonetheless, extracting actionable insights from this knowledge stays a major hurdle. A Retrieval-Augmented Technology (RAG) system, when built-in with Agentic AI, tackles this problem by not solely retrieving related data but in addition processing and delivering context-aware insights in real-time. This mixture permits companies to create clever brokers that autonomously question datasets, adapt, and extract insights on product options, integrations, and operations.
By merging RAG with Agentic AI, companies can improve decision-making and convert scattered knowledge into worthwhile intelligence. This weblog explores the method of constructing a RAG pipeline with Agentic AI, providing technical insights and code examples to empower sensible decision-making in organizations.
Studying Goals
- Discover ways to routinely extract and scrape related knowledge from a number of internet sources utilizing Python and scraping instruments, forming the inspiration for any firm intelligence platform.
- Discover ways to construction and course of scraped knowledge into worthwhile, actionable insights by extracting key factors equivalent to product functionalities, integrations, and troubleshooting steps utilizing AI-driven strategies.
- Discover ways to combine RAG with doc retrieval and pure language era to construct an clever querying system able to delivering context-aware solutions from huge datasets.
- Perceive construct an agentic AI system that mixes knowledge scraping, data extraction, and real-time question processing, enabling companies to extract actionable insights autonomously.
- Achieve an understanding of scale and deploy such a system utilizing cloud platforms and distributed architectures, making certain it will probably deal with massive datasets and excessive question hundreds successfully.
This text was printed as part of the Information Science Blogathon.
Information Extraction Utilizing BFS and Scraping the Information
Step one in constructing a strong RAG system for firm intelligence is accumulating the required knowledge. Since knowledge can come from numerous internet sources, scraping and organizing it effectively is essential. One efficient method for locating and accumulating the related pages is Breadth-First Search (BFS). BFS helps us recursively uncover hyperlinks ranging from a predominant web page, progressively increasing the search to deeper ranges. This ensures that we collect all related pages with out overwhelming the system with pointless knowledge.
On this part, we’ll take a look at extract hyperlinks from an internet site utilizing BFS, adopted by scraping the content material from these pages. Utilizing BFS, we systematically traverse web sites, gather knowledge, and create a significant dataset for processing in a RAG pipeline.
To start, we have to gather all of the related hyperlinks from a given web site. Utilizing BFS, we are able to discover the hyperlinks on the homepage, and from there, observe hyperlinks on different pages recursively as much as a specified depth. This technique ensures that we seize all the required pages that may include the related firm knowledge, equivalent to product options, integrations, or different key particulars.
The code under performs hyperlink extraction from a beginning URL utilizing BFS. It begins by fetching the primary web page, extracts all hyperlinks (<a> tags with href attributes), after which follows these hyperlinks to subsequent pages, recursively increasing the search based mostly on a given depth restrict.
Right here is the code to carry out hyperlink extraction:
import requests
from bs4 import BeautifulSoup
from collections import deque
# Perform to extract hyperlinks utilizing BFS
def bfs_link_extraction(start_url, max_depth=3):
visited = set() # To trace visited hyperlinks
queue = deque([(start_url, 0)]) # Queue to retailer URLs and present depth
all_links = []
whereas queue:
url, depth = queue.popleft()
if depth > max_depth:
proceed
# Fetch the content material of the URL
strive:
response = requests.get(url)
soup = BeautifulSoup(response.content material, 'html.parser')
# Extract all hyperlinks within the web page
hyperlinks = soup.find_all('a', href=True)
for hyperlink in hyperlinks:
full_url = hyperlink['href']
if full_url.startswith('http') and full_url not in visited:
visited.add(full_url)
queue.append((full_url, depth + 1))
all_links.append(full_url)
besides requests.exceptions.RequestException as e:
print(f"Error fetching {url}: {e}")
return all_links
# Begin the BFS from the homepage
start_url="https://www.instance.com" # Substitute with the precise homepage URL
all_extracted_links = bfs_link_extraction(start_url)
print(f"Extracted {len(all_extracted_links)} hyperlinks.")We keep a queue to trace the URLs to go to together with their corresponding depths, making certain environment friendly traversal. A visited set is used to stop revisiting the identical URL a number of instances. For every URL, we use BeautifulSoup to parse the HTML and extract all hyperlinks (tags with href attributes). The method makes use of BFS traversal, recursively fetching every URL’s content material, extracting hyperlinks, and exploring additional till reaching the depth restrict. This strategy ensures we effectively discover the online with out redundancy.
Output
This code outputs a listing of hyperlinks extracted from the web site, as much as the desired depth.
Extracted 1500 hyperlinks.The output exhibits that the system discovered and picked up 1500 hyperlinks from the beginning web site and its linked pages as much as a depth of three. You’ll change https://www.instance.com together with your precise goal URL. Beneath is the output screenshot of the unique code. Delicate data has been masked to take care of integrity.
As soon as we’ve extracted the related hyperlinks utilizing BFS, the following step is to scrape the content material from these pages. We’ll search for key data equivalent to product options, integrations, and some other related knowledge that may assist us construct a structured dataset for the RAG system.
On this step, we loop by the listing of extracted hyperlinks and scrape key content material, such because the title of the web page and its predominant content material. You may modify this code to scrape extra knowledge factors as wanted (e.g., product options, pricing, or FAQ data).
import json
# Perform to scrape and extract knowledge from the URLs
def scrape_data_from_links(hyperlinks):
scraped_data = []
for hyperlink in hyperlinks:
strive:
response = requests.get(hyperlink)
soup = BeautifulSoup(response.content material, 'html.parser')
# Instance: Extract 'title' and 'content material' (modify in line with your wants)
title = soup.discover('title').get_text()
content material = soup.discover('div', class_='content material').get_text() # Regulate selector
# Retailer the extracted knowledge
scraped_data.append({
'url': hyperlink,
'title': title,
'content material': content material
})
besides requests.exceptions.RequestException as e:
print(f"Error scraping {hyperlink}: {e}")
return scraped_data
# Scrape knowledge from the extracted hyperlinks
scraped_contents = scrape_data_from_links(all_extracted_links)
# Save scraped knowledge to a JSON file
with open('/content material/scraped_data.json', 'w') as outfile:
json.dump(scraped_contents, outfile, indent=4)
print("Information scraping full.")For every URL within the listing, we ship an HTTP request to fetch the web page’s content material and parse it utilizing BeautifulSoup to extract the title and predominant content material. We retailer the extracted knowledge in a listing of dictionaries, every containing the URL, title, and content material. Lastly, we save the scraped knowledge right into a JSON file, making certain it’s out there for later processing within the RAG pipeline. This course of ensures environment friendly assortment and storage of related knowledge for additional use.
Output
The output of this code can be a saved JSON file (scraped_data.json) containing the scraped knowledge from the hyperlinks. An instance of the info construction may appear like this:
[
{
"url": "https://www.example.com/page1",
"title": "Page 1 Title",
"content": "This is the content of the first page. It contains
information about integrations and features."
},
{
"url": "https://www.example.com/page2",
"title": "Page 2 Title",
"content": "Here we describe the functionalities of the product.
It includes various use cases and capabilities."
}
]This JSON file accommodates the URLs, titles, and content material for every of the pages we scraped. This structured knowledge can now be used for additional processing, equivalent to embedding era and question-answering within the RAG system. Beneath is the output screenshot of the unique code. Delicate data has been masked to take care of integrity.
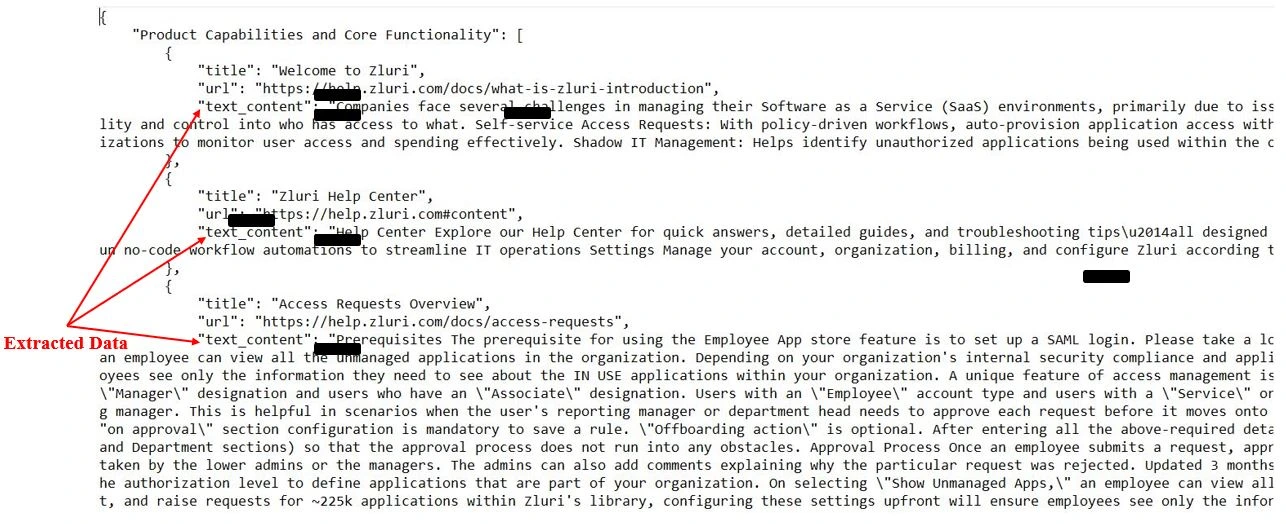
Within the earlier part, we coated the method of scraping hyperlinks and accumulating uncooked internet content material utilizing a breadth-first search (BFS) technique. As soon as the required knowledge is scraped, we want a strong system for organizing and extracting actionable insights from this uncooked content material. That is the place Agentic AI steps in: by processing the scraped knowledge, it routinely constructions the knowledge into significant sections.
On this part, we give attention to how Agentic AI extracts related product data from the scraped knowledge, making certain it’s prepared for stakeholder consumption. We’ll break down the important thing steps concerned, from loading the info to processing it and eventually saving the ends in a structured format.
Step 1: Loading Scraped Information
Step one on this course of is to load the uncooked scraped content material into our system. As we noticed earlier, the scraped knowledge is saved in JSON format, and every entry features a URL and related content material. We have to be certain that this knowledge is in an acceptable format for the AI to course of.
Code Snippet:
import json
# Load the scraped JSON file containing the online knowledge
with open('/content material/scraped_contents_zluri_all_links.json', 'r') as file:
knowledge = json.load(file)Right here, we load your entire dataset into reminiscence utilizing Python’s built-in json library. Every entry within the dataset accommodates the URL of the supply and a text_content subject, which holds the uncooked scraped textual content. This content material is what we are going to course of within the subsequent steps.
Subsequent, we iterate by the dataset to extract the related text_content for every entry. This ensures that we solely work with legitimate entries that include the required content material. Invalid or incomplete entries are skipped to take care of the integrity of the method.
Code Snippet:
# Loop by every entry and extract the content material
for entry in knowledge:
if 'consequence' in entry and 'text_content' in entry['result']:
input_text = entry['result']['text_content']At this level, the input_text variable accommodates the uncooked textual content content material that we are going to ship to the AI mannequin for additional processing. It’s essential that we make sure the presence of the required keys earlier than processing every entry.
Step 3: Sending Information to AI Agent for Processing
After extracting the uncooked content material, we ship it to the Agentic AI mannequin for structured extraction. We work together with the Groq API to request structured insights based mostly on predefined prompts. The AI mannequin processes the content material and returns organized data that covers key points like product capabilities, integrations, and troubleshooting steps.
Code Snippet:
response = shopper.chat.completions.create(
messages=[
{"role": "system", "content": """
You are tasked with acting as a product manager.
Extract structured information based on the following sections:
- Product Capabilities
- Integrations and Compatibility
- Modules and Sub-modules
- Recent Releases
- Troubleshooting Steps
"""},
{"role": "user", "content": input_text},
],
mannequin="llama-3.2-3b-preview",
temperature=1,
max_tokens=1024,
top_p=1,
)Right here, the code initiates an API name to Groq, sending the input_text and directions as a part of the messages payload. The system message instructs the AI mannequin on the precise job to carry out, whereas the person message supplies the content material to be processed. We use the temperature, max_tokens, and top_p parameters to manage the randomness and size of the generated output.
API Name Configuration:
- mannequin: Specifies the mannequin for use. On this case, a language mannequin is chosen to make sure it will probably deal with textual knowledge and generate responses.
- temperature: Controls the creativity of the responses. A better worth results in extra inventive responses, whereas decrease values make them extra deterministic.
- max_tokens: Units the utmost size of the generated response.
- top_p: Determines the cumulative likelihood distribution for token choice, controlling range within the response.
Step 4: Processing and Gathering Outcomes
As soon as the AI mannequin processes the content material, it returns chunks of structured data. We gather and concatenate these chunks to create a full set of outcomes, making certain no knowledge is misplaced and the ultimate output is full.
Code Snippet:
# Initialize a variable to gather the AI output
pm_points = ""
# Course of and gather all chunks from the API response
for chunk in response:
pm_points += chunk.decisions[0].delta.content material or ""
This code snippet concatenates the content material from every chunk to the pm_points variable, leading to a full, structured set of insights. It extracts these insights in a format that stakeholders can simply devour or use for additional evaluation. Beneath is the output screenshot of the unique code, with delicate data masked to take care of integrity.
Step 5: Error Dealing with and Sustaining Information Integrity
Whereas processing, there’s at all times the potential of encountering errors, equivalent to incomplete content material or community points. By utilizing error dealing with mechanisms, we be certain that the method continues easily for all legitimate entries.
Code Snippet:
besides Exception as e:
print(f"Error processing entry {entry.get('url', 'Unknown URL')}: {e}")
entry['pm_points'] = "Error processing content material.This try-except block catches and logs any errors, making certain the system continues processing different entries. If a selected entry causes a problem, the system marks it for assessment with out halting the general course of.
Step 6: Saving the Processed Information
After the AI processes the content material and returns structured insights, the ultimate step is saving this knowledge for later use. We write the structured outcomes again to a JSON file, making certain that each entry has its personal processed data saved for additional evaluation.
Code Snippet:
# Save the ultimate JSON file after processing all entries
with open('/content material/processed_data_with_pm_points.json', 'w') as outfile:
json.dump(knowledge, outfile, indent=4)This code shops the processed knowledge effectively and permits easy accessibility later. It saves every entry with its respective structured factors, making retrieval and evaluation of the extracted data easy.
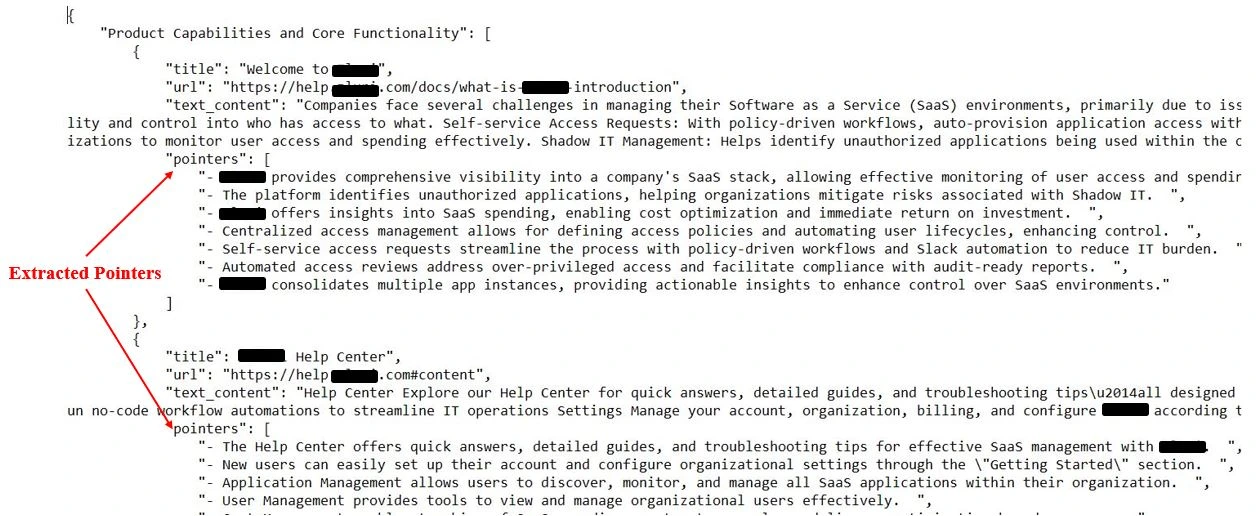
Output
After working the above code, the processed JSON file will include the extracted factors for every entry. The fields pm_points will maintain the structured data associated to product capabilities, integrations, troubleshooting steps, and extra, prepared for additional evaluation or integration into your workflows.
[
{
"url": "https://example.com/product1",
"result": {
"text_content": "This is the product description for Product 1.
It provides a variety of features including integration with tools
like Google Analytics and Salesforce."
},
"pm_points": {
"Product Capabilities and Core Functionality": [
"Provides analytics tools for product tracking.",
"Integrates with popular CRMs like Salesforce.",
"Supports real-time data processing."
],
"Integrations and Compatibility": [
"Compatible with Google Analytics.",
"Supports Salesforce integration for CRM management."
],
"Modules and Sub-modules": [
"Module 1: Data Analytics - Provides tools for real-time tracking.",
"Module 2: CRM Integration - Seamlessly integrates with CRM platforms."
],
"Current Releases": [
"Version 2.1 released with enhanced reporting features.",
"New integration with Slack for notifications."
],
"Fundamental Troubleshooting": [
"Check the API connection if data is not syncing.",
"Clear cache and try restarting the system if features are not loading."
]
}
},
{
"url": "https://instance.com/product2",
"consequence": {
"text_content": "Product 2 is a software program instrument designed for managing
group tasks and monitoring workflows. It gives strong job administration
options."
},
"pm_points": {
"Product Capabilities and Core Performance": [
"Enables efficient task and project management.",
"Features include automated reporting and team collaboration tools."
],
"Integrations and Compatibility": [
"Integrates with Asana for task tracking.",
"Supports Slack integration for team communication."
],
"Modules and Sub-modules": [
"Module 1: Task Management - Allows users to create, assign, and track
tasks.",
"Module 2: Reporting - Automatically generates project status reports."
],
"Current Releases": [
"Version 1.3 added Gantt chart views for better project visualization."
],
"Fundamental Troubleshooting": [
"If tasks are not updating, check your internet connection.",
"Ensure that your Slack token is valid for integrations."
]
}
}
]
Beneath is the output screenshot of the unique code. Delicate data has been masked to take care of integrity.
Retrieval-Augmented Technology Pipeline Implementation
Within the earlier part, we targeted on knowledge extraction from internet pages and changing them into structured codecs like JSON. We additionally applied strategies to extract and clear related knowledge, permitting us to generate a dataset that’s prepared for deeper evaluation.
Constructing on that, on this part, we are going to implement a Retrieval-Augmented Technology (RAG) pipeline, which mixes doc retrieval and language mannequin era to reply questions based mostly on the extracted data.
By integrating the structured knowledge we beforehand scraped and processed, this RAG pipeline won’t solely retrieve essentially the most related doc chunks but in addition generate correct, insightful responses based mostly on that context.
Step 1: Organising the Atmosphere
To start with, let’s set up all the required dependencies for the RAG pipeline:
!pip set up jq
!pip set up langchain
!pip set up langchain-openai
!pip set up langchain-chroma
!pip set up langchain-community
!pip set up langchain-experimental
!pip set up sentence-transformersThese packages are essential for integrating doc processing, vectorization, and OpenAI fashions inside LangChain. jq is a light-weight JSON processor, whereas langchain serves because the core framework for constructing language mannequin pipelines. langchain-openai facilitates the mixing of OpenAI fashions like GPT, and langchain-chroma gives Chroma-based vector shops for managing doc embeddings.
Moreover, we use sentence-transformers to generate textual content embeddings with pre-trained transformer fashions, enabling environment friendly doc dealing with and retrieval.
Now, we’ll load the structured knowledge that was extracted and processed within the earlier part utilizing JSONLoader. This knowledge, for example, may have been scraped from internet pages as a structured JSON, with key-value pairs related to particular matters or questions.
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path=r"/content material/company_data.json", # Up to date the file title to a extra generic time period
jq_schema=".[].product_points", # Adjusted schema title to be generic
text_content=False
)
knowledge = loader.load()On this step, the info that was beforehand extracted (maybe containing product capabilities, integrations, and options) is loaded for additional processing.
Step 3: Splitting the Paperwork into Smaller Chunks
Now that we now have the uncooked knowledge, we use the RecursiveCharacterTextSplitter to interrupt the doc into smaller chunks. This ensures that no single chunk exceeds the token restrict of the language mannequin.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=700, # Dimension of every chunk (in characters)
chunk_overlap=200, # Variety of overlapping characters between chunks
add_start_index=True # Embody an index to trace authentic doc order
)
all_splits = text_splitter.split_documents(knowledge)
print(f"Break up doc into {len(all_splits)} sub-documents.")The RecursiveCharacterTextSplitter divides a doc into smaller segments, making certain that chunk overlaps are preserved for higher contextual understanding. The chunk_size parameter determines the dimensions of every chunk, whereas chunk_overlap ensures vital data is retained throughout adjoining chunks. Moreover, add_start_index helps keep the doc’s order by together with an index, permitting for simple monitoring of the place every chunk originated within the authentic doc.
Step 4: Producing Embeddings for Doc Chunks
Now, we convert every chunk of textual content into embeddings utilizing the SentenceTransformer. These embeddings signify the which means of the textual content in a high-dimensional vector area, which is helpful for looking out and retrieving related paperwork later.
from sentence_transformers import SentenceTransformer
sentence_transformer_model = SentenceTransformer('all-MiniLM-L6-v2')
class SentenceTransformerEmbeddings:
def embed_documents(self, texts):
return sentence_transformer_model.encode(texts, convert_to_tensor=True).tolist()
def embed_query(self, textual content):
return sentence_transformer_model.encode(textual content, convert_to_tensor=True).tolist()
vectorstore = Chroma.from_documents(paperwork=all_splits,
embedding=SentenceTransformerEmbeddings())SentenceTransformer is used to generate embeddings for textual content chunks, creating dense vector representations that seize semantic data. The perform embed_documents processes a number of paperwork and returns their embeddings, whereas embed_query generates embeddings for person queries. Chroma, a vector retailer, manages these embeddings and permits environment friendly retrieval based mostly on similarity, permitting for quick and correct doc or question matching.
Step 5: Organising the Retriever
Now we configure the retriever. This part searches for essentially the most related chunks of textual content based mostly on a person’s question. It retrieves the top-k most related doc chunks to the question.
retriever = vectorstore.as_retriever(search_type="similarity",
search_kwargs={"okay": 6})- The retriever makes use of similarity search to search out essentially the most related chunks from the vector retailer.
- The parameter okay=6 means it’ll return the highest 6 chunks which might be most related to the question.
Step 6: Creating the Immediate Template
Subsequent, we create a immediate template that may format the enter for the language mannequin. This template consists of each the context (retrieved chunks) and the person’s question, guiding the mannequin to generate a solution based mostly solely on the offered context.
from langchain.prompts import ChatPromptTemplate
template = """Reply the query based mostly solely on the next context:
{context}
Query: {query}
"""
immediate = ChatPromptTemplate.from_template(template)- The ChatPromptTemplate codecs the enter for the mannequin in a manner that emphasizes the necessity for the reply to be based mostly solely on the given context.
- {context} might be changed with the related textual content chunks, and {query} might be changed with the person’s question.
Step 7: Organising the Language Mannequin
On this step, we initialize the OpenAI GPT mannequin. This mannequin will generate solutions based mostly on the structured context offered by the retriever.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(mannequin="gpt-4o-mini")- We initialize the ChatOpenAI mannequin, which is able to course of the immediate and generate a solution.
- We use a smaller mannequin, “gpt-4o-mini”, for environment friendly processing, although bigger fashions may very well be used for extra advanced duties.
Step 8: Establishing the RAG Pipeline
Right here, we combine all parts (retriever, immediate, LLM) right into a cohesive RAG pipeline. This pipeline will take the question, retrieve the related context, move it by the mannequin, and generate a response.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
chain = (
{"context": retriever, "query": RunnablePassthrough()}
| immediate
| llm
| StrOutputParser()
)- RunnablePassthrough ensures that the question is handed on to the immediate.
- StrOutputParser is used to scrub and format the output from the mannequin right into a string format.
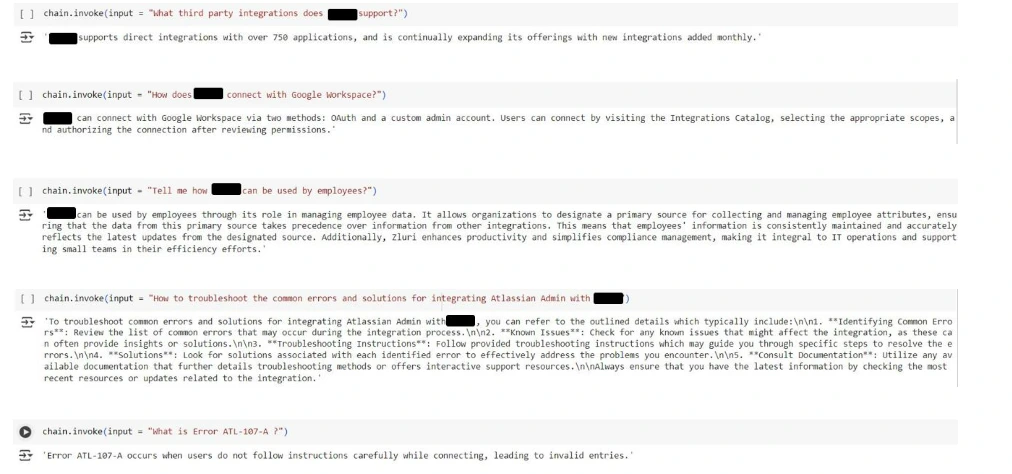
Step 9: Testing the RAG Pipeline
Lastly, we check the pipeline with numerous person queries. For every question, the system retrieves related doc chunks, passes them by the language mannequin, and generates a response.
queries = [
"What integrations are available with this platform?",
"What are the product capabilities and core functionalities offered
by this platform?",
"Does this platform support Salesforce integration?"
]
for question in queries:
consequence = chain.invoke(enter=question)
print(f"Question: {question}nAnswer: {consequence}n")
- The system iterates by every question, invoking the pipeline and printing the generated reply.
- For every question, the mannequin processes the retrieved context and supplies a solution grounded within the context.
Beneath are screenshots of the RAG output from the unique code. Delicate data has been masked to take care of integrity.
By combining internet scraping, knowledge extraction, and superior retrieval-augmented era (RAG) strategies, we’ve created a robust and scalable framework for firm intelligence. Step one of extracting hyperlinks and scraping knowledge ensures that we collect related and up-to-date data from the online. The second part focuses on pinpointing particular product-related particulars, making it simpler to categorize and course of knowledge effectively.
Lastly, leveraging RAG permits us to dynamically reply to advanced queries by retrieving and synthesizing contextual data from huge datasets. Collectively, these parts kind a complete setup that can be utilized to construct an agentic platform able to gathering, processing, and delivering actionable insights on corporations. This framework may function the inspiration for creating superior intelligence methods, enabling organizations to automate aggressive evaluation, monitor market tendencies, and keep knowledgeable about their trade.
Deployment and Scaling
As soon as the corporate intelligence system is constructed, the following step is to deploy and scale it for manufacturing use. You may deploy the system on cloud platforms like AWS or GCP for flexibility and scalability, or go for an on-premise answer if knowledge privateness is a precedence. To make the system extra user-friendly, contemplate constructing a easy API or UI that enables customers to work together with the platform and retrieve insights effortlessly. Because the system begins dealing with bigger datasets and better question hundreds, it’s important to scale effectively.
This may be achieved by leveraging distributed vector shops and optimizing the retrieval course of, making certain that the pipeline stays responsive and quick even beneath heavy utilization. With the precise infrastructure and optimization strategies in place, the agentic platform can develop to assist large-scale operations, enabling real-time insights and sustaining a aggressive edge in firm intelligence.
Conclusion
In immediately’s data-driven world, extracting actionable insights from unstructured firm knowledge is essential. A Retrieval-Augmented Technology (RAG) system combines knowledge scraping, pointer extraction, and clever querying to create a robust platform for firm intelligence. By organizing key data and enabling real-time, context-specific responses, RAG methods empower sensible decision-making in organizations, serving to companies make data-backed, adaptable choices.
This scalable answer grows together with your wants, dealing with advanced queries and bigger datasets whereas sustaining accuracy. With the precise infrastructure, this AI-driven platform turns into a cornerstone for smarter operations, enabling organizations to harness their knowledge, keep aggressive, and drive innovation by sensible decision-making in organizations.
Key Takeaways
- Hyperlink extraction and internet scraping improve firm intelligence by enabling automated, environment friendly knowledge assortment from a number of sources with minimal effort.
- Extracting key knowledge factors transforms unstructured content material into organized, actionable data, strengthening firm intelligence for AI-driven insights.
- Combining RAG with a customized vector retailer and optimized retriever permits clever, context-aware responses for higher decision-making.
- Cloud-based options and distributed vector shops guarantee environment friendly scaling, dealing with bigger datasets and question hundreds with out efficiency loss.
- The RAG pipeline processes real-time queries, delivering correct, on-demand insights immediately from the data base.
Bonus: All of the codes mentioned listed below are made out there within the following hyperlink. A complete of 4 notebooks can be found, with self-explanatory names for every pocket book. Be at liberty to discover, develop and revolutionize enterprise!
Often Requested Questions
A. RAG enhances the flexibility of AI fashions to offer context-aware responses by combining data retrieval with generative AI. It permits smarter querying of enormous datasets, making it simpler to retrieve exact, related solutions relatively than simply performing a primary key phrase search.
A. The first instruments and libraries used embrace Python, BeautifulSoup for internet scraping, Langchain for managing doc retrieval, OpenAI fashions for pure language processing, and Chroma for storing vectorized paperwork. These parts work collectively to create a complete firm intelligence platform.
A. Pointer extraction entails figuring out particular data from the scraped content material, equivalent to product options, integrations, and troubleshooting suggestions. The information is processed utilizing a prompt-driven system, which organizes the knowledge into structured, actionable insights. That is achieved utilizing a mix of AI fashions and customized prompts.
A. RAG and AI brokers improve firm intelligence by automating knowledge retrieval, processing, and evaluation, enabling companies to extract real-time, actionable insights.
A. Information scraping helps construct a powerful firm intelligence system by accumulating and structuring worthwhile data from a number of sources for knowledgeable decision-making.
The media proven on this article isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.
Neil is a analysis skilled presently engaged on the event of AI brokers. He has efficiently contributed to numerous AI tasks throughout totally different domains, together with his works printed in a number of high-impact, peer-reviewed journals. His analysis focuses on advancing the boundaries of synthetic intelligence, and he’s deeply dedicated to sharing data by writing. Via his blogs, Neil strives to make advanced AI ideas extra accessible to professionals and fans alike.