Deepseek has just lately made fairly a buzz within the AI group, because of its spectacular efficiency at comparatively low prices. I feel this can be a excellent alternative to dive deeper into how Giant Language Fashions (LLMs) are skilled. On this article, we’ll give attention to the Reinforcement Studying (RL) aspect of issues: we’ll cowl TRPO, PPO, and, extra just lately, GRPO (don’t fear, I’ll clarify all these phrases quickly!)
I’ve aimed to maintain this text comparatively straightforward to learn and accessible, by minimizing the maths, so that you gained’t want a deep Reinforcement Studying background to comply with alongside. Nevertheless, I’ll assume that you’ve some familiarity with Machine Studying, Deep Studying, and a primary understanding of how LLMs work.
I hope you benefit from the article!
The three steps of LLM coaching
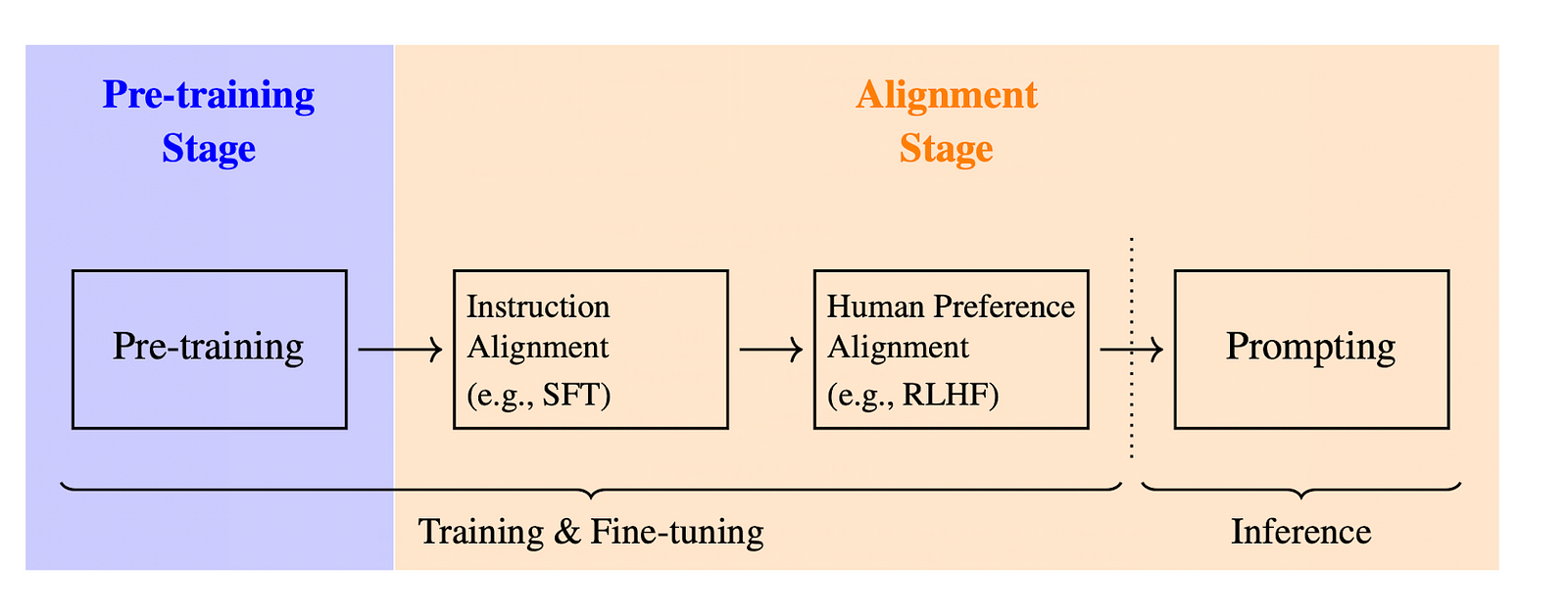
Earlier than diving into RL specifics, let’s briefly recap the three principal levels of coaching a Giant Language Mannequin:
- Pre-training: the mannequin is skilled on an enormous dataset to foretell the following token in a sequence based mostly on previous tokens.
- Supervised Positive-Tuning (SFT): the mannequin is then fine-tuned on extra focused information and aligned with particular directions.
- Reinforcement Studying (typically known as RLHF for Reinforcement Studying with Human Suggestions): that is the main focus of this text. The principle purpose is to additional refine responses’ alignments with human preferences, by permitting the mannequin to be taught immediately from suggestions.
Reinforcement Studying Fundamentals

Earlier than diving deeper, let’s briefly revisit the core concepts behind Reinforcement Studying.
RL is sort of easy to grasp at a excessive degree: an agent interacts with an surroundings. The agent resides in a particular state throughout the surroundings and may take actions to transition to different states. Every motion yields a reward from the surroundings: that is how the surroundings supplies suggestions that guides the agent’s future actions.
Take into account the next instance: a robotic (the agent) navigates (and tries to exit) a maze (the surroundings).
- The state is the present state of affairs of the surroundings (the robotic’s place within the maze).
- The robotic can take completely different actions: for instance, it may transfer ahead, flip left, or flip proper.
- Efficiently navigating in direction of the exit yields a optimistic reward, whereas hitting a wall or getting caught within the maze ends in destructive rewards.
Simple! Now, let’s now make an analogy to how RL is used within the context of LLMs.
RL within the context of LLMs
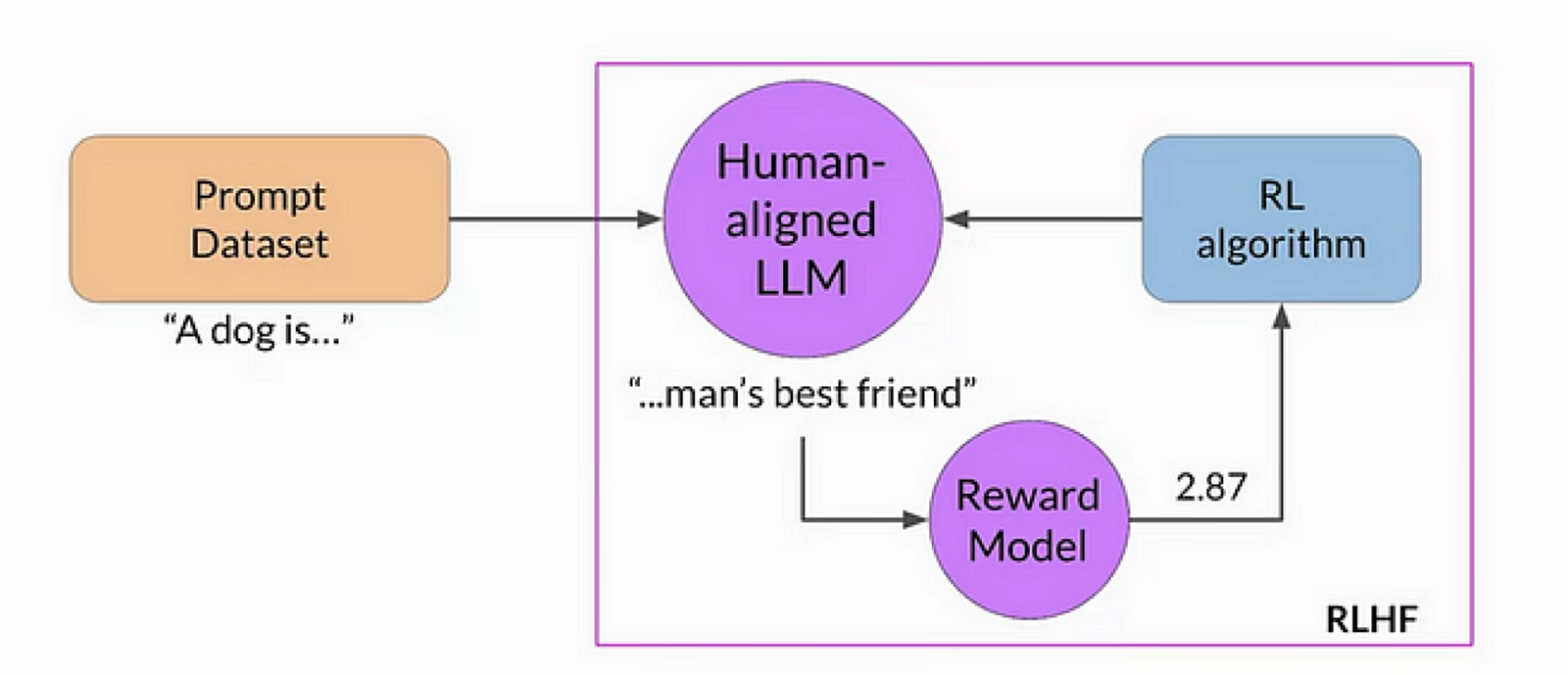
When used throughout LLM coaching, RL is outlined by the next elements:
- The LLM itself is the agent
- Setting: every thing exterior to the LLM, together with consumer prompts, suggestions programs, and different contextual info. That is mainly the framework the LLM is interacting with throughout coaching.
- Actions: these are responses to a question from the mannequin. Extra particularly: these are the tokens that the LLM decides to generate in response to a question.
- State: the present question being answered together with tokens the LLM has generated up to now (i.e., the partial responses).
- Rewards: this is a little more difficult right here: not like the maze instance above, there may be often no binary reward. Within the context of LLMs, rewards often come from a separate reward mannequin, which outputs a rating for every (question, response) pair. This mannequin is skilled from human-annotated information (therefore “RLHF”) the place annotators rank completely different responses. The purpose is for higher-quality responses to obtain greater rewards.
Observe: in some instances, rewards can really get easier. For instance, in DeepSeekMath, rule-based approaches can be utilized as a result of math responses are usually extra deterministic (appropriate or mistaken reply)
Coverage is the ultimate idea we want for now. In RL phrases, a coverage is solely the technique for deciding which motion to take. Within the case of an LLM, the coverage outputs a likelihood distribution over attainable tokens at every step: in brief, that is what the mannequin makes use of to pattern the following token to generate. Concretely, the coverage is decided by the mannequin’s parameters (weights). Throughout RL coaching, we modify these parameters so the LLM turns into extra prone to produce “higher” tokens— that’s, tokens that produce greater reward scores.
We regularly write the coverage as:
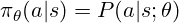
the place a is the motion (a token to generate), s the state (the question and tokens generated up to now), and θ (mannequin’s parameters).
This concept of discovering the most effective coverage is the entire level of RL! Since we don’t have labeled information (like we do in supervised studying) we use rewards to regulate our coverage to take higher actions. (In LLM phrases: we modify the parameters of our LLM to generate higher tokens.)
TRPO (Belief Area Coverage Optimization)
An analogy with supervised studying
Let’s take a fast step again to how supervised studying usually works. you have got labeled information and use a loss operate (like cross-entropy) to measure how shut your mannequin’s predictions are to the true labels.
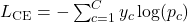
We are able to then use algorithms like backpropagation and gradient descent to attenuate our loss operate and replace the weights θ of our mannequin.
Recall that our coverage additionally outputs chances! In that sense, it’s analogous to the mannequin’s predictions in supervised studying… We’re tempted to write down one thing like:
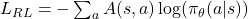
the place s is the present state and a is a attainable motion.
A(s, a) is known as the benefit operate and measures how good is the chosen motion within the present state, in comparison with a baseline. That is very very similar to the notion of labels in supervised studying however derived from rewards as an alternative of express labeling. To simplify, we will write the benefit as:
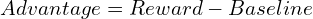
In observe, the baseline is calculated utilizing a worth operate. It is a widespread time period in RL that I’ll clarify later. What it’s essential to know for now could be that it measures the anticipated reward we might obtain if we proceed following the present coverage from the state s.
What’s TRPO?
TRPO (Belief Area Coverage Optimization) builds on this concept of utilizing the benefit operate however provides a important ingredient for stability: it constrains how far the brand new coverage can deviate from the outdated coverage at every replace step (just like what we do with batch gradient descent for instance).
- It introduces a KL divergence time period (see it as a measure of similarity) between the present and the outdated coverage:
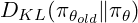
- It additionally divides the coverage by the outdated coverage. This ratio, multiplied by the benefit operate, offers us a way of how useful every replace is relative to the outdated coverage.
Placing all of it collectively, TRPO tries to maximize a surrogate goal (which includes the benefit and the coverage ratio) topic to a KL divergence constraint.
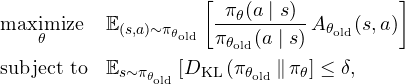
PPO (Proximal Coverage Optimization)
Whereas TRPO was a big development, it’s not used broadly in observe, particularly for coaching LLMs, on account of its computationally intensive gradient calculations.
As an alternative, PPO is now the popular method in most LLMs structure, together with ChatGPT, Gemini, and extra.
It’s really fairly just like TRPO, however as an alternative of implementing a tough constraint on the KL divergence, PPO introduces a “clipped surrogate goal” that implicitly restricts coverage updates, and tremendously simplifies the optimization course of.
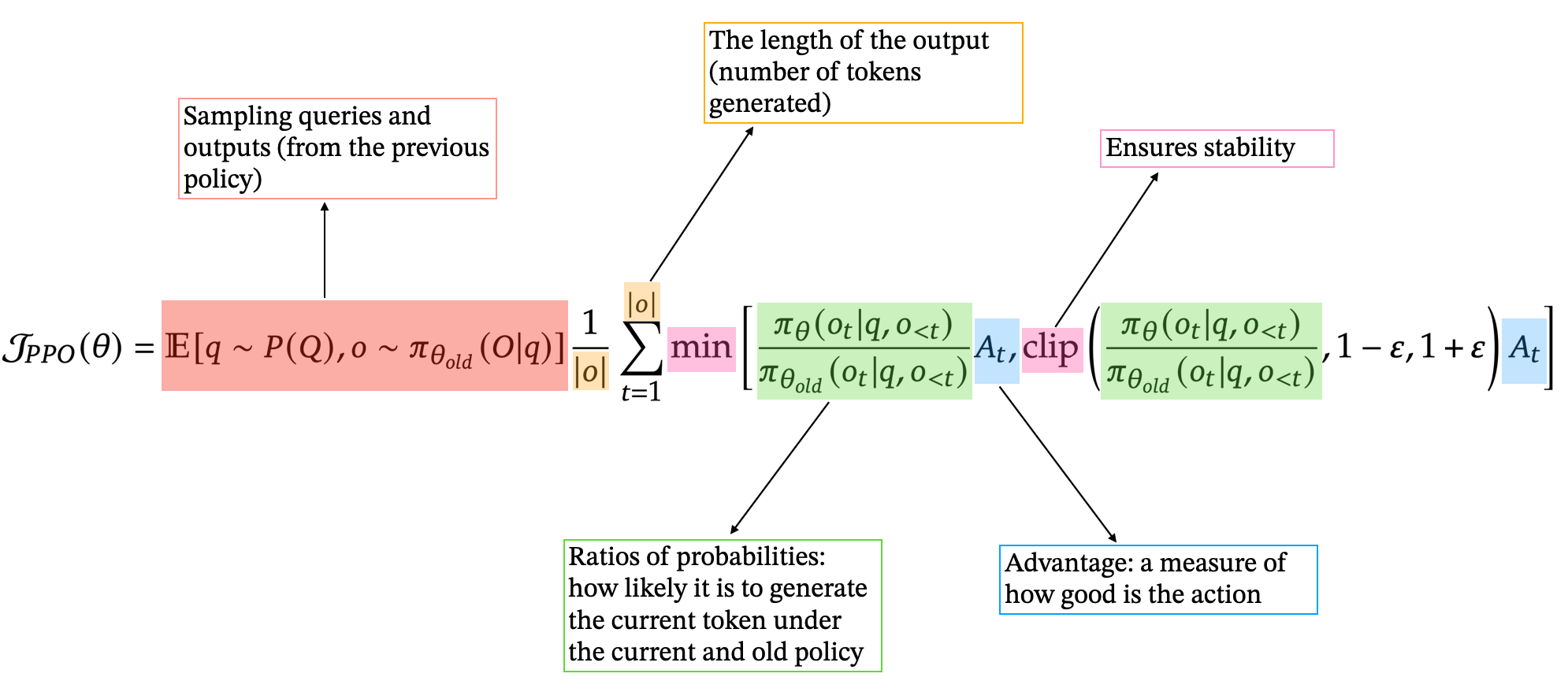
Here’s a breakdown of the PPO goal operate we maximize to tweak our mannequin’s parameters.
GRPO (Group Relative Coverage Optimization)
How is the worth operate often obtained?
Let’s first discuss extra in regards to the benefit and the worth capabilities I launched earlier.
In typical setups (like PPO), a worth mannequin is skilled alongside the coverage. Its purpose is to foretell the worth of every motion we take (every token generated by the mannequin), utilizing the rewards we get hold of (do not forget that the worth ought to symbolize the anticipated cumulative reward).
Right here is the way it works in observe. Take the question “What’s 2+2?” for example. Our mannequin outputs “2+2 is 4” and receives a reward of 0.8 for that response. We then go backward and attribute discounted rewards to every prefix:
- “2+2 is 4” will get a price of 0.8
- “2+2 is” (1 token backward) will get a price of 0.8γ
- “2+2” (2 tokens backward) will get a price of 0.8γ²
- and so on.
the place γ is the low cost issue (0.9 for instance). We then use these prefixes and related values to coach the worth mannequin.
Essential word: the worth mannequin and the reward mannequin are two various things. The reward mannequin is skilled earlier than the RL course of and makes use of pairs of (question, response) and human rating. The worth mannequin is skilled concurrently to the coverage, and goals at predicting the long run anticipated reward at every step of the era course of.
What’s new in GRPO
Even when in observe, the reward mannequin is usually derived from the coverage (coaching solely the “head”), we nonetheless find yourself sustaining many fashions and dealing with a number of coaching procedures (coverage, reward, worth mannequin). GRPO streamlines this by introducing a extra environment friendly methodology.
Bear in mind what I stated earlier?
In PPO, we determined to make use of our price operate because the baseline. GRPO chooses one thing else: Here’s what GRPO does: concretely, for every question, GRPO generates a gaggle of responses (group of dimension G) and makes use of their rewards to calculate every response’s benefit as a z-score:

the place rᵢ is the reward of the i-th response and μ and σ are the imply and commonplace deviation of rewards in that group.
This naturally eliminates the necessity for a separate worth mannequin. This concept makes lots of sense when you consider it! It aligns with the worth operate we launched earlier than and in addition measures, in a way, an “anticipated” reward we will get hold of. Additionally, this new methodology is nicely tailored to our drawback as a result of LLMs can simply generate a number of non-deterministic outputs through the use of a low temperature (controls the randomness of tokens era).
That is the principle concept behind GRPO: eliminating the worth mannequin.
Lastly, GRPO provides a KL divergence time period (to be precise, GRPO makes use of a easy approximation of the KL divergence to enhance the algorithm additional) immediately into its goal, evaluating the present coverage to a reference coverage (typically the post-SFT mannequin).
See the ultimate formulation under:

And… that’s largely it for GRPO! I hope this offers you a transparent overview of the method: it nonetheless depends on the identical foundational concepts as TRPO and PPO however introduces extra enhancements to make coaching extra environment friendly, sooner, and cheaper — key elements behind DeepSeek’s success.
Conclusion
Reinforcement Studying has turn out to be a cornerstone for coaching right now’s Giant Language Fashions, significantly via PPO, and extra just lately GRPO. Every methodology rests on the identical RL fundamentals — states, actions, rewards, and insurance policies — however provides its personal twist to steadiness stability, effectivity, and human alignment:
• TRPO launched strict coverage constraints through KL divergence
• PPO eased these constraints with a clipped goal
• GRPO took an additional step by eradicating the worth mannequin requirement and utilizing group-based reward normalization. In fact, DeepSeek additionally advantages from different improvements, like high-quality information and different coaching methods, however that’s for one more time!
I hope this text gave you a clearer image of how these strategies join and evolve. I consider that Reinforcement Studying will turn out to be the principle focus in coaching LLMs to enhance their efficiency, surpassing pre-training and SFT in driving future improvements.
For those who’re all in favour of diving deeper, be at liberty to take a look at the references under or discover my earlier posts.
Thanks for studying, and be at liberty to go away a clap and a remark!
Wish to be taught extra about Transformers or dive into the maths behind the Curse of Dimensionality? Try my earlier articles:
Transformers: How Do They Remodel Your Knowledge?
Diving into the Transformers structure and what makes them unbeatable at language dutiestowardsdatascience.com
The Math Behind “The Curse of Dimensionality”
Dive into the “Curse of Dimensionality” idea and perceive the maths behind all of the stunning phenomena that come up…towardsdatascience.com