The sort of content material that customers may need to create utilizing a generative mannequin corresponding to Flux or Hunyuan Video might not be all the time be simply out there, even when the content material request is pretty generic, and one may guess that the generator might deal with it.
One instance, illustrated in a brand new paper that we’ll check out on this article, notes that the increasingly-eclipsed OpenAI Sora mannequin has some issue rendering an anatomically appropriate firefly, utilizing the immediate ‘A firefly is glowing on a grass’s leaf on a serene summer time night time’:

OpenAI’s Sora has a barely wonky understanding of firefly anatomy. Supply: https://arxiv.org/pdf/2503.01739
Since I not often take analysis claims at face worth, I examined the identical immediate on Sora at present and acquired a barely higher end result. Nevertheless, Sora nonetheless didn’t render the glow appropriately – somewhat than illuminating the tip of the firefly’s tail, the place bioluminescence happens, it misplaced the glow close to the insect’s toes:

My very own check of the researchers’ immediate in Sora produces a end result that reveals Sora doesn’t perceive the place a Firefly’s mild truly comes from.
Sarcastically, the Adobe Firefly generative diffusion engine, educated on the corporate’s copyright-secured inventory images and movies, solely managed a 1-in-3 success charge on this regard, after I tried the identical immediate in Photoshop’s generative AI function:

Solely the ultimate of three proposed generations of the researchers’ immediate produces a glow in any respect in Adobe Firefly (March 2025), although at the very least the glow is located within the appropriate a part of the insect’s anatomy.
This instance was highlighted by the researchers of the brand new paper for instance that the distribution, emphasis and protection in coaching units used to tell standard basis fashions might not align with the consumer’s wants, even when the consumer will not be asking for something significantly difficult – a subject that brings up the challenges concerned in adapting hyperscale coaching datasets to their most effective and performative outcomes as generative fashions.
The authors state:
‘[Sora] fails to seize the idea of a glowing firefly whereas efficiently producing grass and a summer time [night]. From the information perspective, we infer that is primarily as a result of [Sora] has not been educated on firefly-related matters, whereas it has been educated on grass and night time. Moreover, if [Sora had] seen the video proven in [above image], it’s going to perceive what a glowing firefly ought to seem like.’
They introduce a newly curated dataset and counsel that their methodology could possibly be refined in future work to create information collections that higher align with consumer expectations than many current fashions.
Knowledge for the Individuals
Basically their proposal posits a knowledge curation strategy that falls someplace between the customized information for a model-type corresponding to a LoRA (and this strategy is much too particular for common use); and the broad and comparatively indiscriminate high-volume collections (such because the LAION dataset powering Secure Diffusion) which aren’t particularly aligned with any end-use state of affairs.
The brand new strategy, each as methodology and a novel dataset, is (somewhat tortuously) named Customers’ FOcus in text-to-video, or VideoUFO. The VideoUFO dataset includes 1.9 million video clips spanning 1291 user-focused matters. The matters themselves had been elaborately developed from an current video dataset, and parsed via various language fashions and Pure Language Processing (NLP) methods:
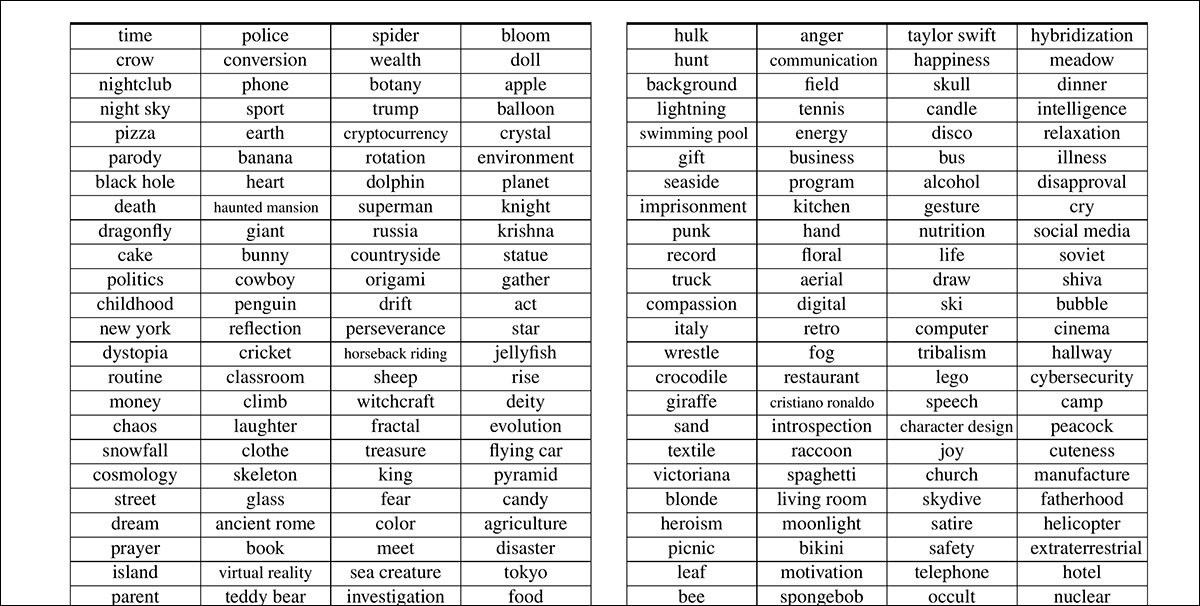
Samples of the distilled matters offered within the new paper.
The VideoUFO dataset includes a excessive quantity of novel movies trawled from YouTube – ‘novel’ within the sense that the movies in query don’t function in video datasets which are at present standard within the literature, and subsequently within the many subsets which have been curated from them (and most of the movies had been in truth uploaded subsequent to the creation of the older datasets thar the paper mentions).
Actually, the authors declare that there’s solely 0.29% overlap with current video datasets – a powerful demonstration of novelty.
One cause for this is likely to be that the authors would solely settle for YouTube movies with a Inventive Commons license that will be much less prone to hamstring customers additional down the road: it is potential that this class of movies has been much less prioritized in prior sweeps of YouTube and different high-volume platforms.
Secondly, the movies had been requested on the premise of pre-estimated user-need (see picture above), and never indiscriminately trawled. These two components together might result in such a novel assortment. Moreover, the researchers checked the YouTube IDs of any contributing movies (i.e., movies that will later have been cut up up and re-imagined for the VideoUFO assortment) in opposition to these featured in current collections, lending credence to the declare.
Although not every little thing within the new paper is kind of as convincing, it is an attention-grabbing learn that emphasizes the extent to which we’re nonetheless somewhat on the mercy of uneven distributions in datasets, by way of the obstacles the analysis scene is commonly confronted with in dataset curation.
The new work is titled VideoUFO: A Million-Scale Person-Centered Dataset for Textual content-to-Video Technology, and comes from two researchers, respectively from the College of Expertise Sydney in Australia, and Zhejiang College in China.

Choose examples from the ultimate obtained dataset.
A ‘Private Shopper’ for AI Knowledge
The subject material and ideas featured within the whole sum of web photographs and movies don’t essentially mirror what the common finish consumer might find yourself asking for from a generative system; even the place content material and demand do are inclined to collide (as with porn, which is plentifully out there on the web and of nice curiosity to many gen AI customers), this may increasingly not align with the builders’ intent and requirements for a brand new generative system.
In addition to the excessive quantity of NSFW materials uploaded every day, a disproportionate quantity of net-available materials is prone to be from advertisers and people making an attempt to control search engine optimization. Business self-interest of this sort makes the distribution of material removed from neutral; worse, it’s tough to develop AI-based filtering programs that may deal with the issue, since algorithms and fashions developed from significant hyperscale information might in themselves mirror the supply information’s tendencies and priorities.
Due to this fact the authors of the brand new work have approached the issue by reversing the proposition, via figuring out what customers are prone to need, and acquiring movies that align with these wants.
On the floor, this strategy appears simply as prone to set off a semantic race to the underside as to attain a balanced, Wikipedia-style neutrality. Calibrating information curation round consumer demand dangers amplifying the preferences of the lowest-common-denominator whereas marginalizing area of interest customers, since majority pursuits will inevitably carry larger weight.
Nonetheless, let’s check out how the paper tackles the problem.
Distilling Ideas with Discretion
The researchers used the 2024 VidProM dataset because the supply for matter evaluation that will later inform the venture’s web-scraping.
This dataset was chosen, the authors state, as a result of it’s the solely publicly-available 1m+ dataset ‘written by actual customers’ – and it needs to be acknowledged that this dataset was itself curated by the 2 authors of the brand new paper.
The paper explains*:
‘First, we embed all 1.67 million prompts from VidProM into 384-dimensional vectors utilizing SentenceTransformers Subsequent, we cluster these vectors with Ok-means. Observe that right here we preset the variety of clusters to a comparatively massive worth, i.e., 2, 000, and merge comparable clusters within the subsequent step.
‘Lastly, for every cluster, we ask GPT-4o to conclude a subject [one or two words].’
The authors level out that sure ideas are distinct however notably adjoining, corresponding to church and cathedral. Too granular a standards for circumstances of this sort would result in idea embeddings (for example) for every kind of canine breed, as an alternative of the time period canine; whereas too broad a standards might corral an extreme variety of sub-concepts right into a single over-crowded idea; subsequently the paper notes the balancing act crucial to judge such circumstances.
Singular and plural kinds had been merged, and verbs restored to their base (infinitive) kinds. Excessively broad phrases – corresponding to animation, scene, movie and motion – had been eliminated.
Thus 1,291 matters had been obtained (with the total record out there within the supply paper’s supplementary part).
Choose Internet-Scraping
Subsequent, the researchers used the official YouTube API to hunt movies based mostly on the standards distilled from the 2024 dataset, in search of to acquire 500 movies for every matter. In addition to the requisite inventive commons license, every video needed to have a decision of 720p or increased, and needed to be shorter than 4 minutes.
On this approach 586,490 movies had been scraped from YouTube.
The authors in contrast the YouTube ID of the downloaded movies to a lot of standard datasets: OpenVid-1M; HD-VILA-100M; Intern-Vid; Koala-36M; LVD-2M; MiraData; Panda-70M; VidGen-1M; and WebVid-10M.
They discovered that only one,675 IDs (the aforementioned 0.29%) of the VideoUFO clips featured in these older collections, and it needs to be conceded that whereas the dataset comparability record will not be exhaustive, it does embody all the most important and most influential gamers within the generative video scene.
Splits and Evaluation
The obtained movies had been subsequently segmented into a number of clips, in line with the methodology outlined within the Panda-70M paper cited above. Shot boundaries had been estimated, assemblies stitched, and the concatenated movies divided into single clips, with transient and detailed captions supplied.

Every information entry within the VideoUFO dataset includes a clip, an ID, begin and finish occasions, and a short and an in depth caption.
The transient captions had been dealt with by the Panda-70M methodology, and the detailed video captions by Qwen2-VL-7B, alongside the rules established by Open-Sora-Plan. In circumstances the place clips didn’t efficiently embody the supposed goal idea, the detailed captions for every such clip had been fed into GPT-4o mini, with a view to verify whether or not it was really a match for the subject. Although the authors would have most popular analysis by way of GPT-4o, this might have been too costly for thousands and thousands of video clips.
Video high quality evaluation was dealt with with six strategies from the VBench venture .
Comparisons
The authors repeated the subject extraction course of on the aforementioned prior datasets. For this, it was essential to semantically-match the derived classes of VideoUFO to the inevitably completely different classes within the different collections; it needs to be conceded that such processes provide solely approximated equal classes, and subsequently this can be too subjective a course of to vouchsafe empirical comparisons.
Nonetheless, within the picture beneath we see the outcomes the researchers obtained by this methodology:
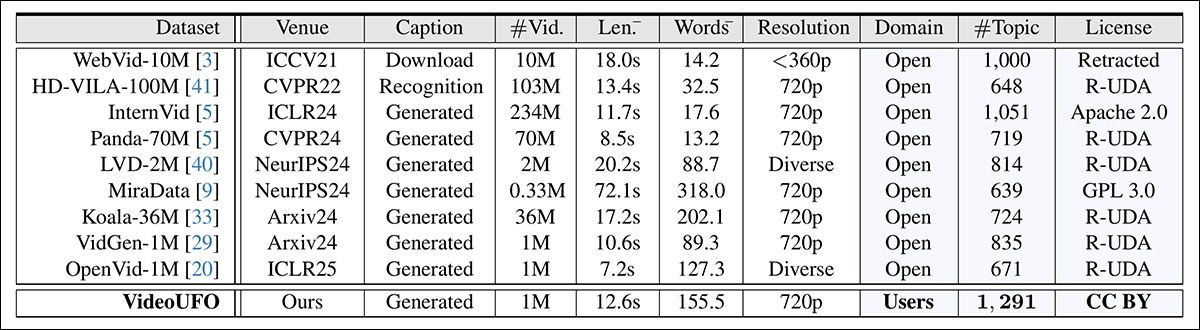
Comparability of the elemental attributes derived throughout VideoUFO and the prior datasets.
The researchers acknowledge that their evaluation relied on the present captions and descriptions supplied in every dataset. They admit that re-captioning older datasets utilizing the identical methodology as VideoUFO might have supplied a extra direct comparability. Nevertheless, given the sheer quantity of knowledge factors, their conclusion that this strategy could be prohibitively costly appears justified.
Technology
The authors developed a benchmark to judge text-to-video fashions’ efficiency on user-focused ideas, titled BenchUFO. This entailed choosing 791 nouns from the 1,291 distilled consumer matters in VideoUFO. For every chosen matter, ten textual content prompts from VidProM had been then randomly chosen.
Every immediate was handed via to a text-to-video mannequin, with the aforementioned Qwen2-VL-7B captioner used to judge the generated outcomes. With all generated movies thus captioned, SentenceTransformers was used to calculate cosine similarity for each the enter immediate and output (inferred) description in every case.
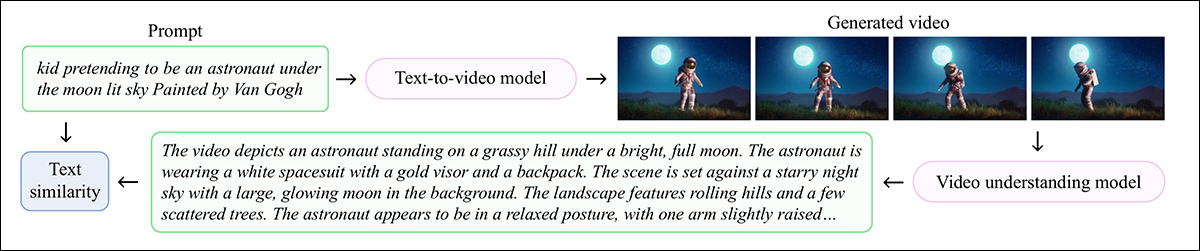
Schema for the BenchUFO course of.
The evaluated generative fashions had been: Mira; Present-1; LTX-Video; Open-Sora-Plan; Open Sora; TF-T2V; Mochi-1; HiGen; Pika; RepVideo; T2V-Zero; CogVideoX; Latte-1; Hunyuan Video; LaVie; and Pyramidal.
In addition to VideoUFO, MVDiT-VidGen and MVDit-OpenVid had been the choice coaching datasets.
The outcomes take into account the Tenth-Fiftieth worst-performing and best-performing matters throughout the architectures and datasets.
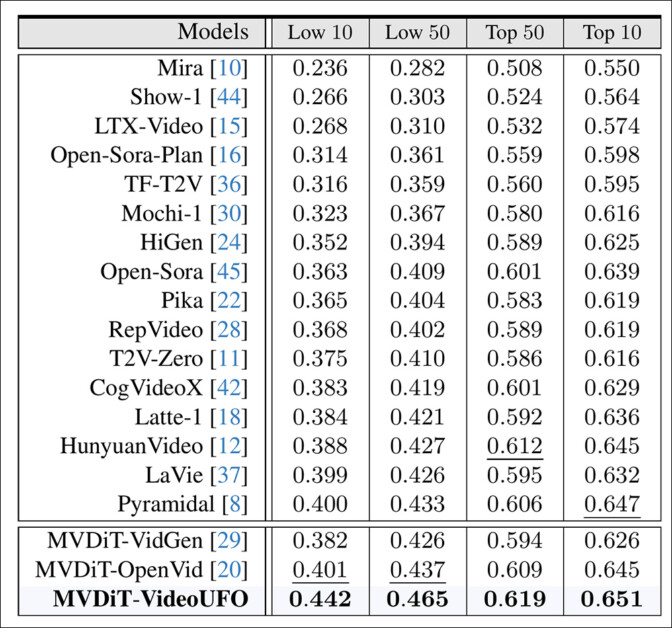
Outcomes for the efficiency of public T2V fashions vs. the authors’ educated fashions, on BenchUFO.
Right here the authors remark:
‘Present text-to-video fashions don’t constantly carry out nicely throughout all user-focused matters. Particularly, there’s a rating distinction starting from 0.233 to 0.314 between the top-10 and low-10 matters. These fashions might not successfully perceive matters corresponding to “large squid”, “animal cell”, “Van Gogh”, and “historic Egyptian” as a result of inadequate coaching on such movies.
‘Present text-to-video fashions present a sure diploma of consistency of their best-performing matters. We uncover that the majority text-to-video fashions excel at producing movies on animal-related matters, corresponding to ‘seagull’, ‘panda’, ‘dolphin’, ‘camel’, and ‘owl’. We infer that that is partly as a result of a bias in the direction of animals in present video datasets.’
Conclusion
VideoUFO is an excellent providing if solely from the standpoint of recent information. If there was no error in evaluating and eliminating YouTube IDs, and if the dataset incorporates a lot materials that’s new to the analysis scene, it’s a uncommon and doubtlessly precious proposition.
The draw back is that one wants to provide credence to the core methodology; in case you do not consider that consumer demand ought to inform web-scraping formulation, you would be shopping for right into a dataset that comes with its personal units of troubling biases.
Additional, the utility of the distilled matters will depend on each the reliability of the distilling methodology used (which is usually hampered by price range constraints), and likewise the formulation strategies for the 2024 dataset that gives the supply materials.
That stated, VideoUFO actually deserves additional investigation – and it’s out there at Hugging Face.
* My substitution of the authors’ citations for hyperlinks.
First printed Wednesday, March 5, 2025