Retrieval-Augmented Technology (RAG) methods have revolutionized how we entry and make the most of huge quantities of knowledge, enabling AI to ship extra knowledgeable and context-aware responses. Nevertheless, their capabilities have largely been confined to digital textual content, overlooking worthwhile data in multimodal codecs like scanned paperwork, pictures, and handwritten notes. Mistral OCR breaks this limitation by seamlessly integrating advanced paperwork into clever retrieval methods, increasing the attain of usable information. This development enhances AI interactions, making data extra accessible, complete, and relevant throughout numerous real-world situations. On this article, we are going to discover the options and functions of Mistral OCR and perceive its impression on RAG methods.
Understanding RAG and Its Limitations
RAG fashions function by retrieving related paperwork and utilizing them to generate responses. Whereas they excel at dealing with massive textual content repositories, they battle with non-text knowledge. This is because of:
- Incapability to interpret pictures, equations, and tables: Many essential paperwork comprise structured knowledge within the type of tables and equations that conventional RAG fashions can not comprehend.
- Lack of context in OCR-extracted textual content: Even when textual content is extracted from scanned paperwork, its which means usually will get distorted if the construction and format are ignored.
- Challenges in processing multimodal content material: Combining visible and textual components in a significant means is past the capability of most standard RAG methods.
- Restricted applicability throughout industries: Sectors comparable to analysis, legislation, and finance depend on advanced paperwork that require extra than simply text-based understanding.
With out an efficient strategy to extract and construction data from numerous codecs, RAG stays incomplete. That’s the place Mistral OCR adjustments the sport.
What’s Mistral OCR and What Makes It Totally different?
Mistral OCR is a complicated Optical Character Recognition (OCR) API constructed to do extra than simply extract textual content. Not like conventional OCR instruments, it acknowledges the construction and context of a doc, making certain that the knowledge it retrieves is each correct and significant. Its mix of precision and efficiency makes it the right selection for dealing with massive volumes of paperwork with ease. Right here’s what makes it stand out:
- Deep Doc Understanding: It acknowledges and extracts not simply textual content but in addition tables, charts, equations, and interleaved pictures, sustaining doc integrity.
- Excessive-Pace Processing: With the potential to course of as much as 2000 pages per minute on a single node, Mistral OCR is constructed for high-throughput environments.
- Doc-as-Immediate Performance: This function permits customers to deal with whole paperwork as prompts, enabling exact and structured data extraction.
- Structured Output Codecs: The extracted content material may be formatted as JSON, making it simpler to combine into workflows and AI functions.
- Safe and Versatile Deployment: For organizations with strict privateness insurance policies, Mistral OCR gives self-hosting choices, making certain knowledge safety and compliance.
These capabilities make Mistral OCR a strong instrument for remodeling unstructured paperwork into AI-ready information sources.
How Mistral OCR Enhances RAG
Integrating Mistral OCR with RAG unlocks a brand new dimension of data retrieval. Right here’s the way it improves the system:
- Increasing RAG to Multimodal Information: By processing scanned paperwork, pictures, and PDFs, Mistral OCR permits RAG fashions to work past simply text-based data.
- Preserving Doc Construction for Higher Context: Mistral OCR maintains the relationships between textual content, pictures, and structured components, making certain the which means of the extracted textual content just isn’t misplaced.
- Accelerating Information Retrieval: The power to course of huge doc repositories at excessive speeds ensures that AI-driven search and evaluation stay environment friendly and updated.
- Empowering Industries with AI-Prepared Information: Whether or not it’s authorized filings, scientific analysis, or buyer help documentation, Mistral OCR helps make knowledge-rich paperwork extra accessible to AI methods.
- Enabling Seamless Integration with AI Pipelines: Structured outputs enable RAG methods to seamlessly combine extracted data into numerous AI functions.
Palms-on with Mistral OCR: A Step-by-Step Information
Mistral OCR is a strong instrument for extracting structured data from pictures and scanned paperwork. On this part, we are going to stroll by a Python script that leverages Mistral OCR to course of a picture and return structured knowledge.
Pre-requisite: Accessing the API
Earlier than we begin with the steps to check the mistral ocr, let’s first see how we are able to generate the required API keys.
1. Mistral API Key
To entry the Mistral API key, go to Mistral API and join a mistral account. If you have already got an account, merely log in.
After logging in, click on on “Create new key” to generate a brand new key.
2. OpenAI API Key
To entry the OpenAI API key, go to OpenAI and login to your account. Join one in the event you don’t have already got an OpenAI account.
After logging in, click on on “Create new secret key” to generate a brand new key.
3. Gemini API Key
To entry the Gemini API key, go to the Google AI Studio web site and log in to your Google account. Join in the event you don’t have already got an account.
After logging in, navigate to the API keys part and click on on “Create API Key” to create a brand new key.
Now that we’re all set, let’s start the implementation.
Step 1: Importing Dependencies
The script imports important libraries, together with:
- Enum and BaseModel from “pydantic”
- Path for dealing with file paths.
- base64 for encoding picture information.
- “pycountry” to map language codes to their full names.
- Mistral SDK to work together with the OCR API.
from enum import Enum
from pathlib import Path
from pydantic import BaseModel
import base64
import pycountry
from mistralai import MistralStep 2: Setting Up the Mistral OCR Shopper
The script initializes the Mistral OCR shopper with an API key:
api_key = "API_KEY"
shopper = Mistral(api_key=api_key)
languages = {lang.alpha_2: lang.title for lang in pycountry.languages if hasattr(lang, 'alpha_2')}Make sure you substitute “API_KEY” together with your precise API key.
Step 3: Defining Language Dealing with
To make sure the extracted textual content is tagged with correct language data, the script makes use of “pycountry” to create a dictionary mapping language codes (e.g., en for English) to full names.
languages = {lang.alpha_2: lang.title for lang in pycountry.languages if hasattr(lang, 'alpha_2')}
class LanguageMeta(Enum.__class__):
def __new__(metacls, cls, bases, classdict):
for code, title in languages.objects():
classdict[name.upper().replace(' ', '_')] = title
return tremendous().__new__(metacls, cls, bases, classdict)
class Language(Enum, metaclass=LanguageMeta):
crossAn Enum class (Language) dynamically generates language labels for structured output.
Step 4: Defining the Structured Output Mannequin
A StructuredOCR class is created utilizing “pydantic”. This defines how the extracted OCR knowledge will probably be formatted, together with:
- file_name: The processed picture filename.
- matters: Detected matters from the picture.
- languages: Recognized languages.
- ocr_contents: Extracted textual content in a structured format.
class StructuredOCR(BaseModel):
file_name: str
matters: listing[str]
languages: listing[Language]
ocr_contents: dict
print(StructuredOCR.schema_json())Step 5: Processing an Picture with OCR
The structured_ocr() operate handles the core OCR course of:
- Picture Encoding: The picture is learn and encoded as a base64 string to ship to the API.
- OCR Processing: The picture is handed to Mistral OCR, and the extracted textual content is retrieved in Markdown format.
- Structuring the OCR Output: A follow-up request converts the extracted textual content right into a structured JSON format.
def structured_ocr(image_path: str) -> StructuredOCR:
image_file = Path(image_path)
assert image_file.is_file(), "The offered picture path doesn't exist."
# Learn and encode the picture file
encoded_image = base64.b64encode(image_file.read_bytes()).decode()
base64_data_url = f"knowledge:picture/jpeg;base64,{encoded_image}"
# Course of the picture utilizing OCR
image_response = shopper.ocr.course of(doc=ImageURLChunk(image_url=base64_data_url), mannequin="mistral-ocr-latest")
image_ocr_markdown = image_response.pages[0].markdown
# Parse the OCR outcome right into a structured JSON response
chat_response = shopper.chat.parse(
mannequin="pixtral-12b-latest",
messages=[
{
"role": "user",
"content": [
ImageURLChunk(image_url=base64_data_url),
TextChunk(text=(
"This is the image's OCR in markdown:n"
f"<BEGIN_IMAGE_OCR>n{image_ocr_markdown}n<END_IMAGE_OCR>.n"
"Convert this into a structured JSON response with the OCR contents in a sensible dictionnary."
))
],
},
],
response_format=StructuredOCR,
temperature=0
)
return chat_response.decisions[0].message.parsed
image_path = "receipt.png"
structured_response = structured_ocr(image_path)
response_dict = json.masses(structured_response.json())
json_string = json.dumps(response_dict, indent=4)
print(json_string)Enter picture

Step 6: Working the OCR and Viewing Outcomes
The script calls the structured_ocr() operate with a picture (receipt.png), retrieves the structured OCR output, and codecs it as a JSON string.
image_path = "receipt.png"
structured_response = structured_ocr(image_path)
response_dict = json.masses(structured_response.json())
json_string = json.dumps(response_dict, indent=4)
print(json_string)This prints the extracted data in a readable format, making it simple to combine into functions.
Go to right here to view the whole model of the code.
Mistral Vs Gemini 2.0 Flash Vs GPT 4o
Now that we’ve seen how Mistral OCR works, let’s examine its efficiency to that of Gemini 2.0 Flash and GPT-4o. To make sure a constant and honest comparability, we’ll be utilizing the identical picture that was examined on Mistral OCR within the hands-on part. The aim is to guage how Mistral, Gemini 2.0, and GPT-4o performs on the very same enter. Under is the output generated by every mannequin.
Output utilizing mistral-ocr:
Right here’s the response we obtained in the course of the hands-on.

Output utilizing gemini-2.0-flash:
from google import genai
from PIL import Picture
# Initialize the GenAI shopper together with your API key
shopper = genai.Shopper(api_key="AIzaSyCxpgd6KbNOwqNhMmDxskSY3alcY2NUiM0")
# Open the picture file
image_path = "/content material/obtain.png"
picture = Picture.open(image_path)
# Outline the immediate for the mannequin
immediate = "Please extract and supply the textual content content material from the picture."
# Generate content material utilizing the Gemini mannequin
response = shopper.fashions.generate_content(
mannequin="gemini-2.0-flash",
contents=[image, prompt]
)
# Print the extracted textual content
print(response.textual content)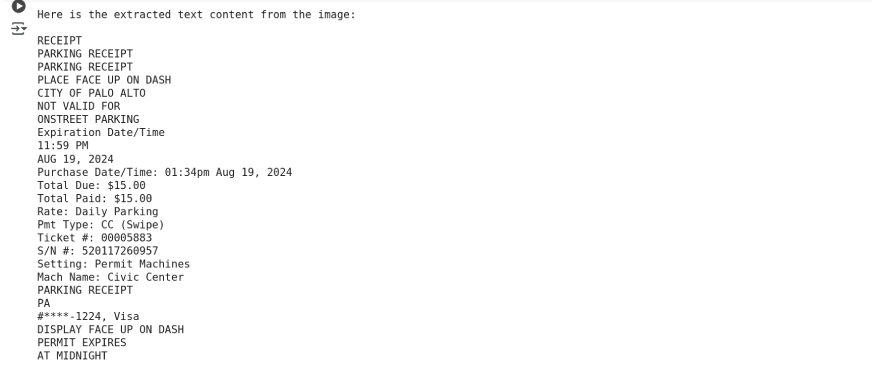
Output utilizing gpt-4o:
After I examined GPT-4o, it was unable to entry native information. Subsequently, I offered the URL of an identical picture for GPT to guage its textual content extraction capabilities.
from openai import OpenAI
shopper = OpenAI(api_key="api_key")
response = shopper.chat.completions.create(
mannequin="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://preview.redd.it/11gu042ydlub1.jpg?width=640&crop=smart&auto=webp&s=8cbb551c29e76ecc31210a79a0ef6c179b7609a3",
}
},
],
}
],
max_tokens=300,
)
print(response.decisions[0].message.content material)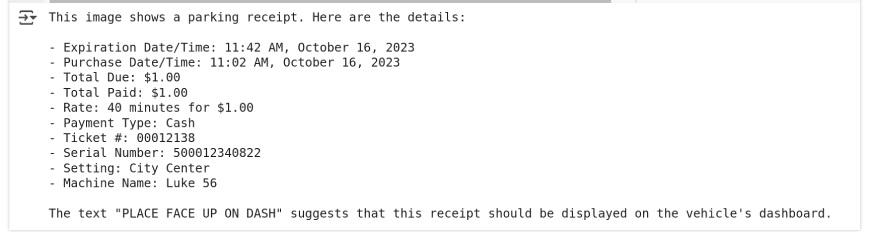
Comparative Evaluation
| Standards | Mistral OCR | GPT-4o | Gemini 2.0 Flash |
| API Worth | 1000 pages / $ (and roughly double the pages per greenback with batch inference). | $5.00 per 1 million enter tokens | $0.10 (textual content / picture / video) |
| Pace | Quick | Average to Excessive | Average |
| Weight | Light-weight | Heavy | Heavy |
Mistral OCR Efficiency Benchmarks
Now, let’s take a look at how Mistral OCR performs throughout numerous benchmarks.
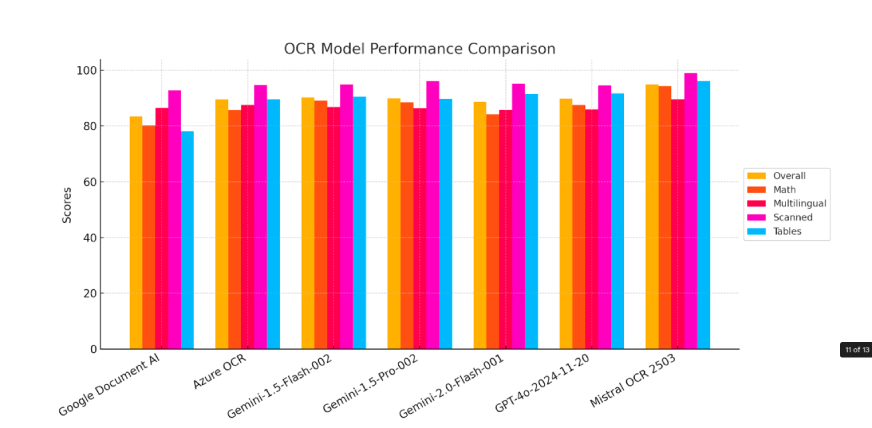
1. Normal Benchmarks
Mistral OCR has set a brand new customary in doc evaluation, persistently outperforming different main OCR fashions in rigorous benchmark evaluations. Its superior capabilities prolong past easy textual content extraction, precisely figuring out and retrieving embedded pictures alongside textual content material – one thing many competing fashions battle to realize.
2. Benchmark by Language
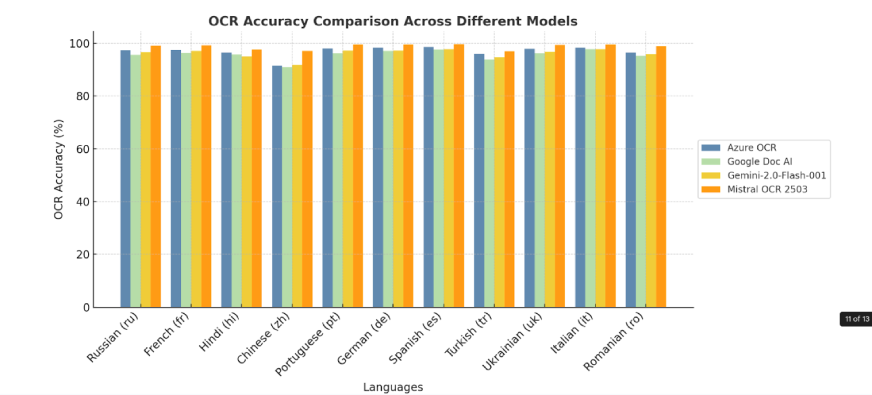
Mistral OCR units the bar excessive with its capability to determine, decipher, and translate hundreds of languages, scripts, and fonts from all around the globe. With Mistral OCR effortlessly processing assorted linguistic constructions, nothing is left behind in translation, and it turns into an extremely great tool for bridging language gaps.
Future Purposes of Mistral OCR
Mistral OCR has the potential to revolutionize numerous industries by making advanced paperwork extra accessible and actionable. Listed below are some key functions:
- Digitizing Scientific Analysis: Analysis organizations could make use of Mistral OCR to translate scientific articles, journals, and technical stories into AI-compatible types. This expedites the sharing of data, facilitates smoother collaboration, and improves AI-aided literature opinions.
- Preserving Historic and Cultural Heritage: Historic manuscripts, artworks, and cultural artifacts from museums, libraries, and archives may be made extra accessible to researchers and the general public whereas additionally being digitally preserved in the long run.
- Streamlining Buyer Service: Firms can convert consumer guides, product manuals, and FAQs into organized, searchable information bases, reducing response instances and enhancing buyer satisfaction.
- Making Literature Throughout Design, Schooling, and Authorized Sectors AI-ready: From engineering blueprints to authorized agreements and academic content material, Mistral OCR makes certain that key trade paperwork are listed and readily accessible for AI-driven insights and automation.
Conclusion
For too lengthy, worthwhile information hidden in advanced paperwork—whether or not scientific diagrams, handwritten manuscripts, or structured stories—has remained out of AI’s attain. Mistral OCR adjustments that, turning RAG methods from easy textual content retrievers into highly effective instruments that actually perceive and navigate data in all its types. This isn’t only a step ahead in expertise—it’s a breakthrough in how we entry and share information. By opening the door to paperwork that have been as soon as troublesome to course of, Mistral OCR helps AI bridge the hole between data and understanding, making information extra accessible than ever earlier than.
Ceaselessly Requested Questions
A. Mistral OCR can course of a variety of paperwork, together with PDFs, scanned pictures, handwritten notes, authorized contracts, analysis papers, and monetary stories. It precisely extracts and constructions textual content, tables, and embedded pictures.
A. Mistral OCR is designed for high-speed processing, able to dealing with as much as 2000 pages per minute on a single node, making it ideally suited for enterprises and analysis establishments coping with massive datasets.
A. “Doc-as-Immediate” permits customers to deal with whole paperwork as prompts, enabling exact data extraction and structured responses from the extracted content material. This function enhances AI-driven doc processing workflows.
A. Sure, Mistral OCR helps hundreds of languages, making it a wonderful instrument for multilingual doc processing. It additionally options fuzzy matching to acknowledge and proper minor errors in scanned textual content.
A. Mistral OCR gives structured outputs in JSON format, making it simple to combine into AI pipelines and enterprise functions.
A. Whereas Mistral OCR is very superior, its efficiency could range relying on the standard of scanned paperwork. Extraordinarily low-resolution pictures or distorted textual content could have an effect on accuracy.
A. Sure, Mistral OCR gives self-hosting choices for organizations with strict privateness necessities. It ensures knowledge safety and compliance with trade requirements.
Information Scientist | AWS Licensed Options Architect | AI & ML Innovator
As a Information Scientist at Analytics Vidhya, I concentrate on Machine Studying, Deep Studying, and AI-driven options, leveraging NLP, pc imaginative and prescient, and cloud applied sciences to construct scalable functions.
With a B.Tech in Laptop Science (Information Science) from VIT and certifications like AWS Licensed Options Architect and TensorFlow, my work spans Generative AI, Anomaly Detection, Faux Information Detection, and Emotion Recognition. Enthusiastic about innovation, I attempt to develop clever methods that form the way forward for AI.