Monetary experiences are vital for assessing an organization’s well being. They span a whole bunch of pages, making it tough to extract particular insights effectively. Analysts and traders spend hours sifting by way of stability sheets, revenue statements and footnotes simply to reply easy questions comparable to – What was the corporate’s income in 2024? With current developments in LLM fashions and vector search applied sciences, we are able to automate monetary report evaluation utilizing LlamaIndex and associated frameworks. This weblog publish explores how we are able to use LlamaIndex, ChromaDB, Gemini2.0, and Ollama to construct a sturdy monetary RAG system that solutions queries from prolonged experiences with precision.
Studying Aims
- Perceive the necessity for monetary report retrieval methods for environment friendly evaluation.
- Learn to preprocess and vectorize monetary experiences utilizing LlamaIndex.
- Discover ChromaDB for constructing a sturdy vector database for doc retrieval.
- Implement question engines utilizing Gemini 2.0 and Llama 3.2 for monetary knowledge evaluation.
- Uncover superior question routing strategies utilizing LlamaIndex for enhanced insights.
This text was revealed as part of the Information Science Blogathon.
Why do we want a Monetary Report Retrieval System?
Monetary experiences comprise vital insights about an organization’s efficiency, together with income, bills, liabilities, and profitability. Nonetheless, these experiences are large, prolonged, and stuffed with technical jargon, making it extraordinarily time consuming for analysts, traders, and executives to extract related info manually.
A monetary Report Retrieval System can automate this course of by enabling pure language queries. As a substitute of looking out by way of PDFs, customers can merely ask questions like, “What was the income in 2023?” or “Summarize the liquidity considerations for 2023.” The system rapidly retrieves and summarizes related sections, saving hours of handbook effort.
Challenge Implementation
For mission implementation we have to first arrange the setting and set up the required libraries:
Step 1: Setting Up the Atmosphere
We are going to begin by creating and conda env for our growth work.
$conda create --name finrag python=3.12
$conda activate finragStep 2: Set up important Python libraries
Putting in libraires is the essential step for any mission implementation:
$pip set up llama-index llama-index-vector-stores-chroma chromadb
$pip set up llama-index-llms-gemini llama-index-llms-ollama
$pip set up llama-index-embeddings-gemini llama-index-embeddings-ollama
$pip set up python-dotenv nest-asyncio pypdfStep 3: Creating Challenge Listing
Now create a mission listing and create a file named .env and on that file put all of your API keys for safe API key administration.
# on .env file
GOOGLE_API_KEY="<your-api-key>"We load the setting variable from that .env file to retailer the delicate API key securely. This ensures that our Gemini API or Google API stays protected.
We are going to do our mission utilizing Jupyter Pocket book.
Create a Jupyter Pocket book file and begin implementing step-by-step.
Step 4: Loading API key
Now we’ll load the API key under:
import os
from dotenv import load_dotenv
load_dotenv()
GEMINI_API_KEY = os.getenv("GOOGLE_API_KEY")
# Solely to test .env is accessing correctly or not.
# print(f"GEMINI_API_KEY: {GEMINI_API_KEY}")Now, our enviroment prepared so we are able to go to the subsequent most essential section.
Paperwork Processing with Llamaindex
Accumulating Motorsport Video games Inc. monetary report from AnnualReports web site.
Obtain Hyperlink right here.
First web page appears like:
This experiences have a complete of 123 pages, however I simply take the monetary statements of the experiences and create a brand new PDF for our mission.
How I do it? It is extremely straightforward with PyPDF libraries.
from pypdf import PdfReader
from pypdf import PdfWriter
reader = PdfReader("NASDAQ_MSGM_2023.pdf")
author = PdfWriter()
# web page 66 to 104 have monetary statements.
page_to_extract = vary(66, 104)
for page_num in page_to_extract:
author.add_page(reader.pages[page_num])
output_pdf = "Motorsport_Games_Financial_report.pdf"
with open(output_pdf, "wb") as outfile:
author.write(output_pdf)
print(f"New PDF created: {output_pdf}")The brand new report file has solely 38 pages, which can assist us to embed the doc rapidly.
Loading and Splitting Monetary Studies
In your mission knowledge listing, put your newly created Motorsport_Games_Financial_report.pdf file, which shall be listed for the mission.
Monetary experiences are usually in PDF format, containing in depth tabular knowledge, footnotes, and authorized statements. We use LlamaIndex’s SimpleDirectoryReader to load these paperwork and convert them to paperwork.
from llama_index.core import SimpleDirectoryReader
paperwork = SimpleDirectoryReader("./knowledge").load_data()Since experiences are very giant to course of as a single paperwork, we slit them into smaller chunk or nodes. Every chunk corresponds to a web page or part, it helps retrieval extra effectively.
from copy import deepcopy
from llama_index.core.schema import TextNode
def get_page_nodes(docs, separator="n---n"):
"""Cut up every doc into web page node, by separator."""
nodes = []
for doc in docs:
doc_chunks = doc.textual content.break up(separator)
for doc_chunk in doc_chunks:
node = TextNode(
textual content=doc_chunk,
metadata=deepcopy(doc.metadata),
)
nodes.append(node)
return nodesTo know the method of the doc ingestion see under diagram.
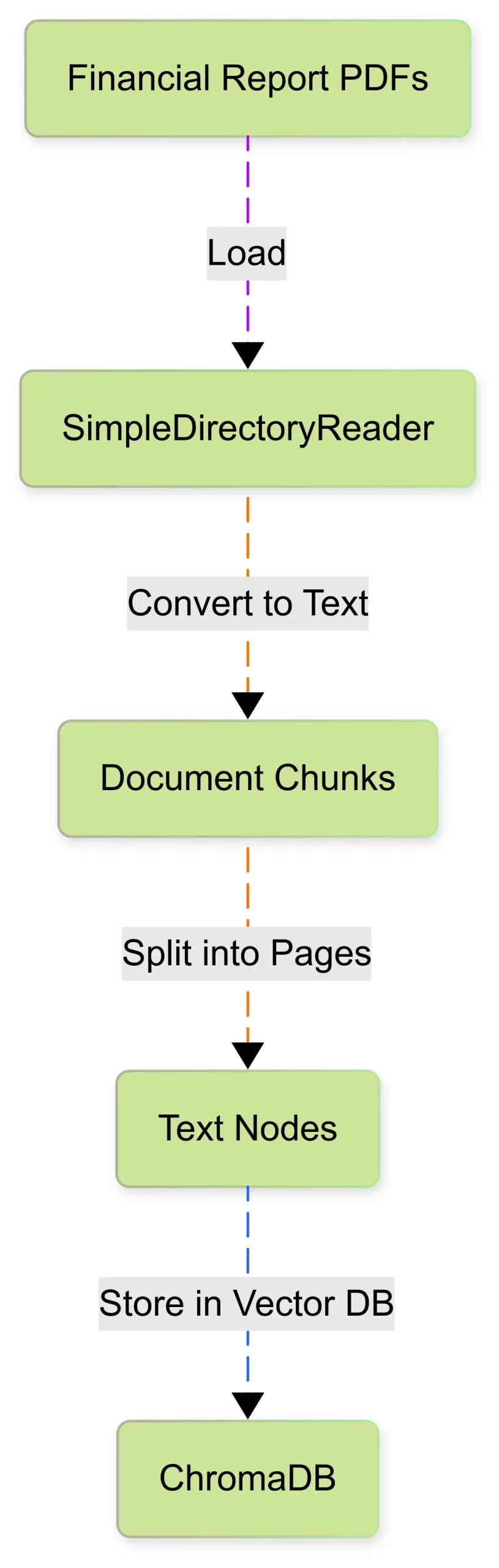
Now our monetary knowledge is prepared for vectorizing and storing for retrieval.
Constructing the Vector Database with ChromaDB
We are going to use ChromaDB for quick, correct, and native vector database. Our embedded illustration of economic textual content shall be saved into ChromaDB.
We initialize the vector database and configure Nomic-embed-text mannequin utilizing Ollama for native embedding era.
import chromadb
from llama_index.llms.gemini import Gemini
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import Settings
embed_model = OllamaEmbedding(model_name="nomic-embed-text")
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = chroma_client.get_or_create_collection("financial_collection")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)Lastly, we create a Vector Index utilizing LLamaIndex’s VectorStoreIndex. This index hyperlinks our vector database to LlamaIndex’s question engine.
from llama_index.core import VectorStoreIndex, StorageContext
storage_context = StorageContext.from_defaults(vector_store=vector_store)
vector_index = VectorStoreIndex.from_documents(paperwork=paperwork, storage_context=storage_context, embed_model=embed_model)The above code will create the Vector Index utilizing nomic-embed-text from monetary textual content paperwork. It’ll take time, relying in your native system specification.
When your indexing is finished, then you need to use the code for reuse that’s embedded when obligatory with out re-indexing once more.
vector_index = VectorStoreIndex.from_vector_store(
vector_store=vector_store, embed_model=embed_model
)It will permit you employ chromadb embedding file from the storage.
Now our heavy loading was accomplished, time for question the report and chill out.
Question Monetary Information with Gemini 2.0
As soon as our monetary knowledge is listed, we are able to ask pure language questions and obtain correct solutions. For querying we’ll use Gemini-2.0 Flash mannequin which interacts with our vector database to fetch related sections and generate insights responses.
Setting-up Gemini-2.0
from llama_index.llms.gemini import Gemini
llm = Gemini(api_key=GEMINI_API_KEY, model_name="fashions/gemini-2.0-flash")
Provoke question engine utilizing Gemini 2.0 with vector index
query_engine = vector_index.as_query_engine(llm=llm, similarity_top_k=5)Example Queries and Response
Beneath we now have a number of queries with totally different responses:
Question-1
response = query_engine.question("what's the income of on 2022 12 months Ended December 31?")
print(str(response))Response

Corresponding picture from Report:

Question-2
response = query_engine.question(
"what's the Web Loss Attributable to Motossport Video games Inc. on 2022 12 months Ended December 31?"
)
print(str(response))Response

Corresponding picture from Report:
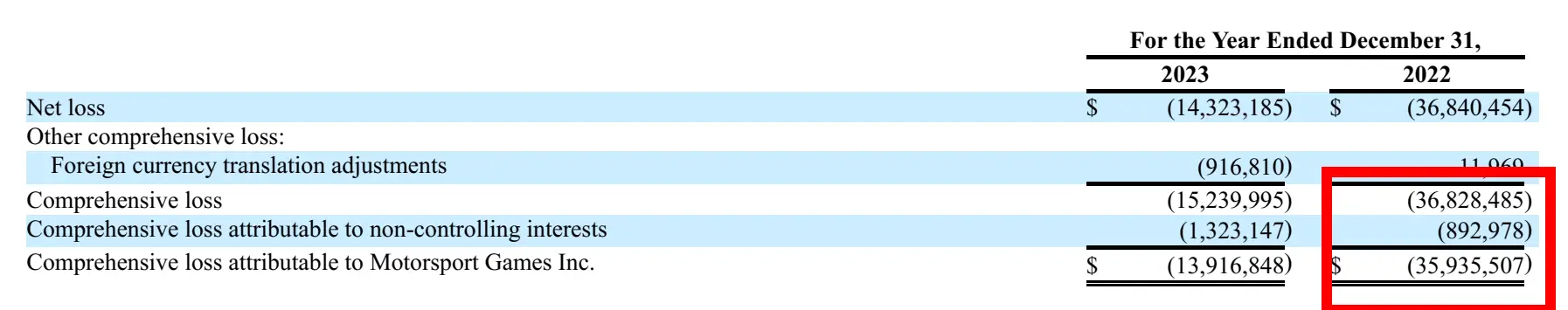
Question-3
response = query_engine.question(
"What are the Liquidity and Going concern for the Firm on December 31, 2023"
)
print(str(response))Response

Question-4
response = query_engine.question(
"Summarise the Principal versus agent issues of the corporate?"
)
print(str(response))Response

Corresonding picture from Report:

Question-5
response = query_engine.question(
"Summarise the Web Loss Per Frequent Share of the corporate with monetary knowledge?"
)
print(str(response))Response

Corresonding picture from Report:
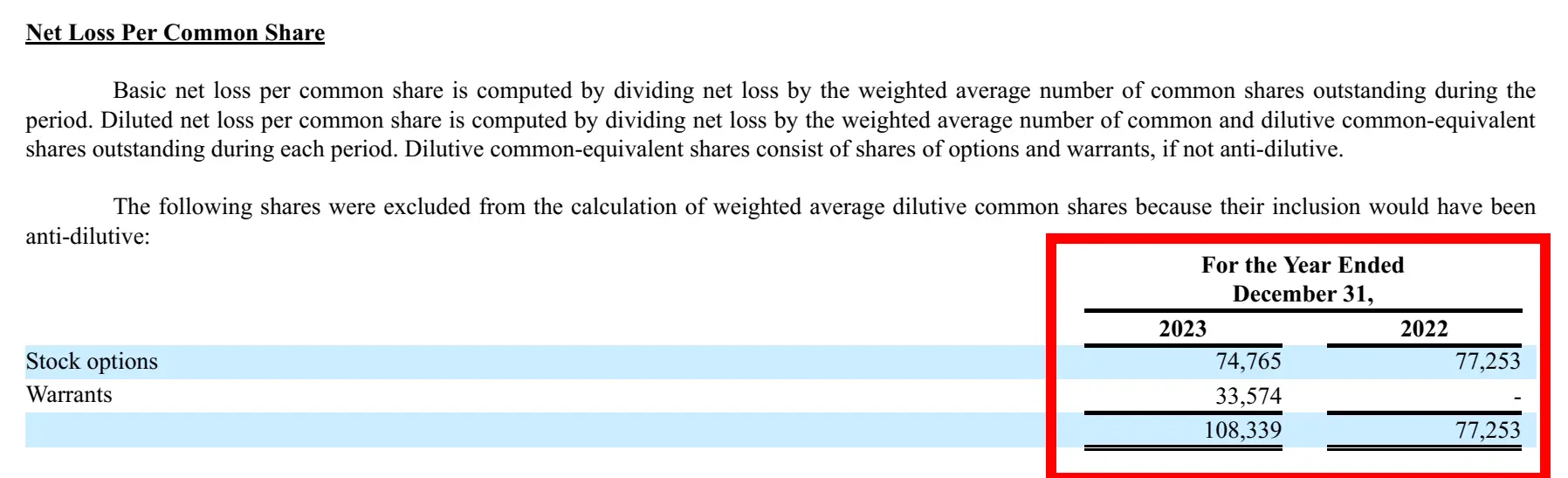
Question-6
response = query_engine.question(
"Summarise Property and gear encompass the next balances as of December 31, 2023 and 2022 of the corporate with monetary knowledge?"
)
print(str(response))Response

Corresponding picture from Report:

Question-7
response = query_engine.question(
"Summarise The Intangible Belongings on December 21, 2023 of the corporate with monetary knowledge?"
)
print(str(response))Response

Question-8
response = query_engine.question(
"What are leases of the corporate with yearwise monetary knowledge?"
)
print(str(response))Response
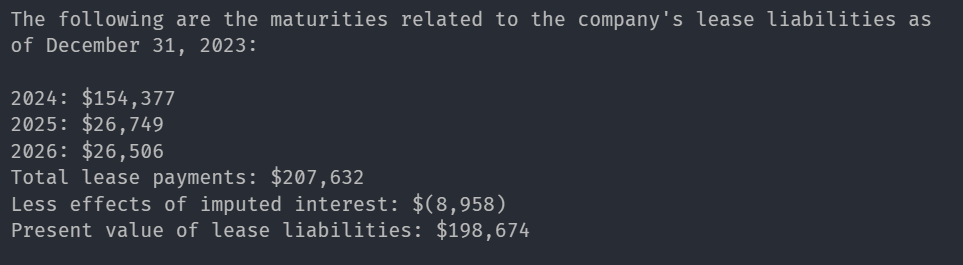
Corresponding picture from Report:

Native Question Utilizing Llama 3.2
Leverage Llama 3.2 regionally to question monetary experiences with out counting on cloud-based fashions.
Seting Up Llama 3.2:1b
local_llm = Ollama(mannequin="llama3.2:1b", request_timeout=1000.0)
local_query_engine = vector_index.as_query_engine(llm=local_llm, similarity_top_k=3)Question-9
response = local_query_engine.question(
"Abstract of chart of Accrued bills and different liabilities utilizing the monetary knowledge of the corporate"
)
print(str(response))Response
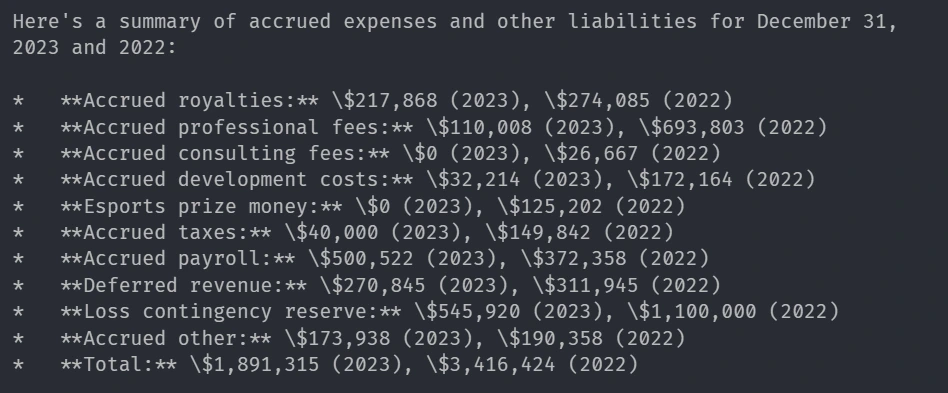
Corresonding picture from Report:
Superior Question Routing with LlamaIndex
Generally, we want each detailed retrieval and summarized insights. We will do that by combining each vector index and abstract index.
- Vector Index for exact doc retrieval
- Abstract Index for concise monetary summaries
Now we have already constructed the Vector Index, now we’ll create a abstract Index that makes use of a hierarchical strategy to summarizing monetary statements.
from llama_index.core import SummaryIndex
summary_index = SummaryIndex(nodes=page_nodes)Then combine RouterQueryEngine, which conditionally decides whether or not to retrieve knowledge from the abstract index or the vector index primarily based on the question kind.
from llama_index.core.instruments import QueryEngineTool
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelectorNow creating abstract question engine
summary_query_engine = summary_index.as_query_engine(
llm=llm, response_mode="tree_summarize", use_async=True
)This abstract question engine goes into the abstract software. and the vector question engine into the vector software.
# Creating abstract software
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Helpful for summarization questions associated to Motorsport Video games Firm."
),
)
# Creating vector software
vector_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
description=(
"Helpful for retriving particular context from the Motorsport Video games Firm."
),
)Each of the instruments is finished now we join these instruments by way of Router in order that when question ass by way of the router it’s going to resolve which software to make use of by analyzing person question.
# Router Question Engine
adv_query_engine = RouterQueryEngine(
llm=llm,
selector=LLMSingleSelector.from_defaults(llm=llm),
query_engine_tools=[summary_tool, vector_tool],
verbose=True,
)Our superior question system is absolutely arrange, now question our newly favored superior question engine.
Question-10
response = adv_query_engine.question(
"Summarize the charts describing the revenure of the corporate."
)
print(str(response))Response

You may see that our clever router will resolve to make use of the abstract software as a result of within the question person asks for abstract.
Question-11
response = adv_query_engine.question("What's the Complete Belongings of the corporate Yearwise?")
print(str(response))Response
And right here the Router selects Vector software as a result of the person asks for particular info, not abstract.
All of the code used on this article is right here
Conclusion
We will effectively analyze the monetary experiences with LlamaIndex, ChromaDB and Superior LLMs. This method allows automated monetary insights, real-time querying, and highly effective summarization. This kind of system makes monetary evaluation extra accessible and environment friendly to take higher selections throughout investing, buying and selling, and doing enterprise.
Key Takeaways
- LLM powered doc retrieval system can drastically scale back the time spent on analyzing complicated monetary experiences.
- A hybrid strategy utilizing cloud and native LLMs ensures an economical, privateness, and versatile option to design a system.
- LlamaIndex’s modular framework permits for a simple option to automate the monetary report rag workflows
- This kind of system may be tailored for various domains comparable to authorized paperwork, medical experiences and regulatory submitting, which makes it a flexible RAG resolution.
Ceaselessly Requested Questions
A. The system is designed to course of any structured monetary paperwork by breaking them into textual content chunks, embedding them and storing them in ChromaDB. New experiences may be added dynamically with out requiring a whole re-indexing.
A. Sure, by integrating Matplotlib, Pandas and Streamlit, you may visualize traits comparable to income development, internet loss evaluation, or asset distribution.
A. The RouterQueryEngine routinely detects whether or not a question requires a summarized response or particular monetary knowledge retrieval. This reduces irrelevant outputs and ensures precision in responses.
A. It may well, however it is determined by how ceaselessly the vector retailer is up to date. You need to use OpenAI embedding API for steady ingestion pipeline for real-time monetary report question dynamically.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Creator’s discretion.
A self-taught, project-driven learner, like to work on complicated tasks on deep studying, Pc imaginative and prescient, and NLP. I all the time attempt to get a deep understanding of the subject which can be in any subject comparable to Deep studying, Machine studying, or Physics. Like to create content material on my studying. Attempt to share my understanding with the worlds.
Login to proceed studying and luxuriate in expert-curated content material.