Generative AI functions have little, or typically destructive, worth with out accuracy — and accuracy is rooted in information.
To assist builders effectively fetch the most effective proprietary information to generate educated responses for his or her AI functions, NVIDIA as we speak introduced 4 new NVIDIA NeMo Retriever NIM inference microservices.
Mixed with NVIDIA NIM inference microservices for the Llama 3.1 mannequin assortment, additionally introduced as we speak, NeMo Retriever NIM microservices allow enterprises to scale to agentic AI workflows — the place AI functions function precisely with minimal intervention or supervision — whereas delivering the best accuracy retrieval-augmented era, or RAG.
NeMo Retriever permits organizations to seamlessly join customized fashions to numerous enterprise information and ship extremely correct responses for AI functions utilizing RAG. In essence, the production-ready microservices allow extremely correct info retrieval for constructing extremely correct AI functions.
For instance, NeMo Retriever can increase mannequin accuracy and throughput for builders creating AI brokers and customer support chatbots, analyzing safety vulnerabilities or extracting insights from complicated provide chain info.
NIM inference microservices allow high-performance, easy-to-use, enterprise-grade inferencing. And with NeMo Retriever NIM microservices, builders can profit from all of this — superpowered by their information.
These new NeMo Retriever embedding and reranking NIM microservices at the moment are typically accessible:
- NV-EmbedQA-E5-v5, a preferred neighborhood base embedding mannequin optimized for textual content question-answering retrieval
- NV-EmbedQA-Mistral7B-v2, a preferred multilingual neighborhood base mannequin fine-tuned for textual content embedding for high-accuracy query answering
- Snowflake-Arctic-Embed-L, an optimized neighborhood mannequin, and
- NV-RerankQA-Mistral4B-v3, a preferred neighborhood base mannequin fine-tuned for textual content reranking for high-accuracy query answering.
They be a part of the gathering of NIM microservices simply accessible by the NVIDIA API catalog.
Embedding and Reranking Fashions
NeMo Retriever NIM microservices comprise two mannequin varieties — embedding and reranking — with open and industrial choices that guarantee transparency and reliability.
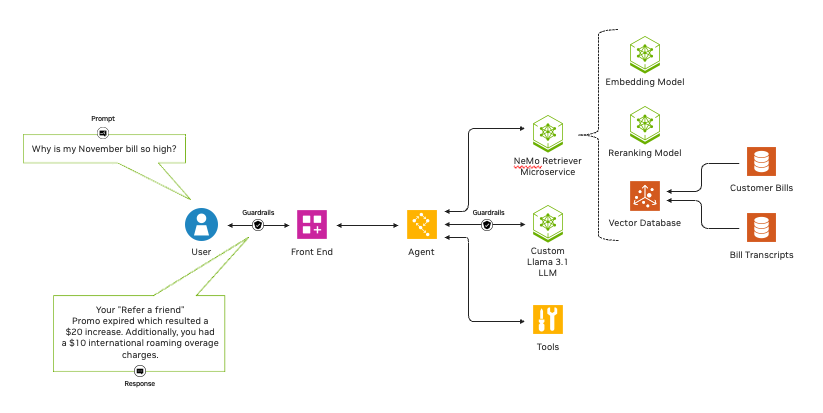
An embedding mannequin transforms numerous information — reminiscent of textual content, pictures, charts and video — into numerical vectors, saved in a vector database, whereas capturing their which means and nuance. Embedding fashions are quick and computationally cheaper than conventional massive language fashions, or LLMs.
A reranking mannequin ingests information and a question, then scores the information in response to its relevance to the question. Such fashions supply vital accuracy enhancements whereas being computationally complicated and slower than embedding fashions.
NeMo Retriever offers the most effective of each worlds. By casting a large internet of information to be retrieved with an embedding NIM, then utilizing a reranking NIM to trim the outcomes for relevancy, builders tapping NeMo Retriever can construct a pipeline that ensures probably the most useful, correct outcomes for his or her enterprise.
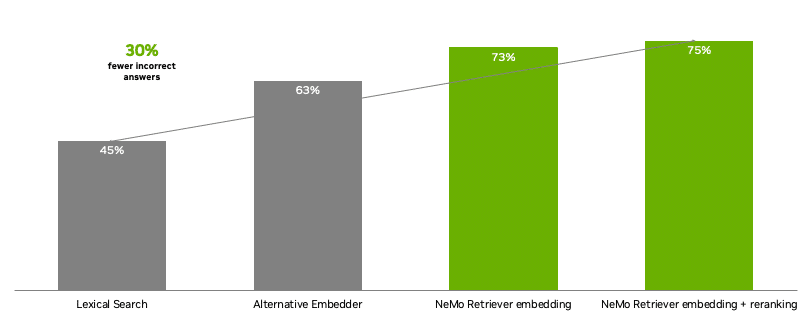
With NeMo Retriever, builders get entry to state-of-the-art open, industrial fashions for constructing textual content Q&A retrieval pipelines that present the best accuracy. In comparison with alternate fashions, NeMo Retriever NIM microservices offered 30% fewer inaccurate solutions for enterprise query answering.
Prime Use Instances
From RAG and AI agent options to data-driven analytics and extra, NeMo Retriever powers a variety of AI functions.
The microservices can be utilized to construct clever chatbots that present correct, context-aware responses. They will help analyze huge quantities of information to determine safety vulnerabilities. They’ll help in extracting insights from complicated provide chain info. They usually can increase AI-enabled retail purchasing advisors that supply pure, customized purchasing experiences, amongst different duties.
NVIDIA AI workflows for these use circumstances present a straightforward, supported place to begin for growing generative AI-powered applied sciences.
Dozens of NVIDIA information platform companions are working with NeMo Retriever NIM microservices to spice up their AI fashions’ accuracy and throughput.
DataStax has built-in NeMo Retriever embedding NIM microservices in its Astra DB and Hyper-Converged platforms, enabling the corporate to convey correct, generative AI-enhanced RAG capabilities to clients with sooner time to market.
Cohesity will combine NVIDIA NeMo Retriever microservices with its AI product, Cohesity Gaia, to assist clients put their information to work to energy insightful, transformative generative AI functions by RAG.
Kinetica will use NVIDIA NeMo Retriever to develop LLM brokers that may work together with complicated networks in pure language to reply extra rapidly to outages or breaches — turning insights into fast motion.
NetApp is collaborating with NVIDIA to attach NeMo Retriever microservices to exabytes of information on its clever information infrastructure. Each NetApp ONTAP buyer will be capable to seamlessly “speak to their information” to entry proprietary enterprise insights with out having to compromise the safety or privateness of their information.
NVIDIA world system integrator companions together with Accenture, Deloitte, Infosys, LTTS, Tata Consultancy Providers, Tech Mahindra and Wipro, in addition to service supply companions Knowledge Monsters, EXLService (Eire) Restricted, Latentview, Quantiphi, Slalom, SoftServe and Tredence, are growing companies to assist enterprises add NeMo Retriever NIM microservices into their AI pipelines.
Use With Different NIM Microservices
NeMo Retriever NIM microservices can be utilized with NVIDIA Riva NIM microservices, which supercharge speech AI functions throughout industries — enhancing customer support and enlivening digital people.
New fashions that may quickly be accessible as Riva NIM microservices embrace: FastPitch and HiFi-GAN for text-to-speech functions; Megatron for multilingual neural machine translation; and the record-breaking NVIDIA Parakeet household of fashions for computerized speech recognition.
NVIDIA NIM microservices can be utilized all collectively or individually, providing builders a modular method to constructing AI functions. As well as, the microservices could be built-in with neighborhood fashions, NVIDIA fashions or customers’ customized fashions — within the cloud, on premises or in hybrid environments — offering builders with additional flexibility.
NVIDIA NIM microservices can be found at ai.nvidia.com. Enterprises can deploy AI functions in manufacturing with NIM by the NVIDIA AI Enterprise software program platform.
NIM microservices can run on clients’ most popular accelerated infrastructure, together with cloud situations from Amazon Internet Providers, Google Cloud, Microsoft Azure and Oracle Cloud Infrastructure, in addition to NVIDIA-Licensed Programs from world server manufacturing companions together with Cisco, Dell Applied sciences, Hewlett Packard Enterprise, Lenovo and Supermicro.
NVIDIA Developer Program members will quickly be capable to entry NIM without spending a dime for analysis, improvement and testing on their most popular infrastructure.
Be taught extra in regards to the newest in generative AI and accelerated computing by becoming a member of NVIDIA at SIGGRAPH, the premier laptop graphics convention, working July 28-Aug. 1 in Denver.
See discover concerning software program product info.