Evaluating language fashions has at all times been a difficult activity. How can we measure if a mannequin really understands language, generates coherent textual content, or produces correct responses? Among the many numerous metrics developed for this objective, the Perplexity Metric stands out as probably the most elementary and broadly used analysis metrics within the discipline of Pure Language Processing (NLP) and Language Mannequin (LM) evaluation.
Perplexity has been used for the reason that early days of statistical language modeling and continues to be related even within the period of enormous language fashions (LLMs). On this article, we’ll dive deep into perplexity—what it’s, the way it works, its mathematical foundations, implementation particulars, benefits, limitations, and the way it compares to different analysis metrics.
By the top of this text, you’ll have an intensive understanding of perplexity and have the ability to implement it your self to guage language fashions.
What’s Perplexity Metric?
Perplexity Metric is a measurement of how nicely a likelihood mannequin predicts a pattern. Within the context of language fashions, perplexity quantifies how “stunned” or “confused” a mannequin is when encountering a textual content sequence. The decrease the perplexity, the higher the mannequin is at predicting the pattern textual content.

To place it extra intuitively:
- Low perplexity: The mannequin is assured and correct in its predictions about what phrases come subsequent in a sequence.
- Excessive perplexity: The mannequin is unsure and struggles to foretell the following phrases in a sequence.
Consider perplexity as answering the query: “On common, what number of totally different phrases might plausibly observe every phrase on this textual content, in response to the mannequin?” An ideal mannequin would assign a likelihood of 1 to every appropriate phrase, leading to a perplexity of 1 (the minimal potential worth). Actual fashions, nonetheless, distribute likelihood throughout a number of potential phrases, leading to larger perplexity.
Fast Test: If a language mannequin assigns equal likelihood to 10 potential subsequent phrases at every step, what would its perplexity be? (Reply: Precisely 10)
How Does Perplexity Work?
Perplexity works by measuring how nicely a language mannequin predicts a take a look at set. The method includes:
- Coaching a language mannequin on a corpus of textual content
- Evaluating the mannequin on unseen knowledge (the take a look at set)
- Calculating how seemingly the mannequin thinks the take a look at knowledge is
The basic thought is to make use of the mannequin to assign a likelihood to every phrase within the take a look at sequence, given the previous phrases. These possibilities are then mixed to provide a single perplexity rating.
For instance, take into account the sentence “The cat sat on the mat”:
- The mannequin calculates P(“cat” | “The”)
- Then P(“sat” | “The cat”)
- Then P(“on” | “The cat sat”)
- And so forth…
These possibilities are mixed to get the general chance of the sentence, which is then transformed to perplexity.
How is Perplexity Calculated?
Let’s dive into the arithmetic behind perplexity. For a language mannequin, perplexity is outlined because the exponential of the typical unfavourable log-likelihood:
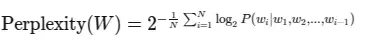
The place:
- $W$ is the take a look at sequence $(w_1, w_2, …, w_N)$
- $N$ is the variety of phrases within the sequence
- $P(w_i|w_1, w_2, …, w_{i-1})$ is the conditional likelihood of the phrase $w_i$ given all earlier phrases
Alternatively, if we use the chain rule of likelihood to precise the joint likelihood of the sequence, we get:
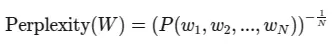
The place $P(w_1, w_2, …, w_N)$ is the joint likelihood of the complete sequence.
Let’s break down these formulation step-by-step:
- We calculate the likelihood of every phrase given its context (earlier phrases)
- We take the logarithm (usually base 2) of every likelihood
- We common these log possibilities throughout the complete sequence
- We take the unfavourable of this common (since log possibilities are unfavourable)
- Lastly, we compute 2 raised to this energy
The ensuing worth is the perplexity rating.
Attempt It: Think about a easy mannequin that assigns P(“the”)=0.2, P(“cat”)=0.1, P(“sat”)=0.05 for “The cat sat”. Calculate the perplexity of this sequence. (We’ll present the answer within the implementation part)
Alternate Representations of Perplexity Metric
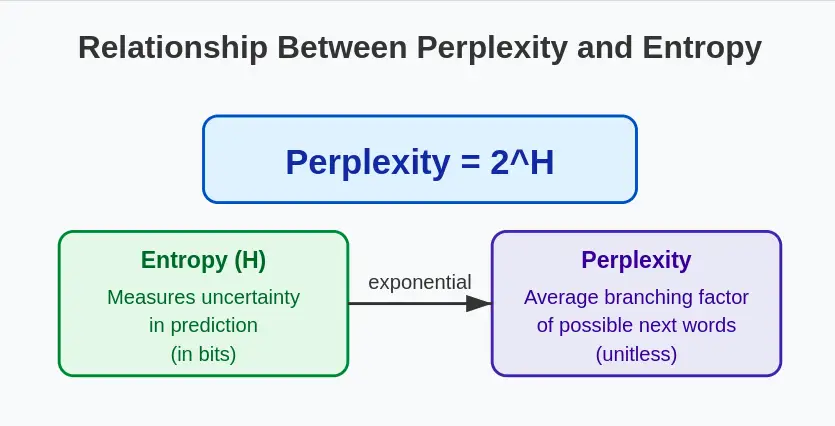
1. Perplexity in Phrases of Entropy
Perplexity is instantly associated to the information-theoretic idea of entropy. If we denote the entropy of the likelihood distribution as $H$, then:

This relationship highlights that perplexity is basically measuring the typical uncertainty in predicting the following phrase in a sequence. The upper the entropy (uncertainty), the upper the perplexity.
2. Perplexity as a Multiplicative Inverse
One other approach to perceive the Perplexity Metric is because the inverse of the geometric imply of the phrase possibilities:
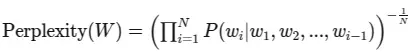
This formulation emphasizes that perplexity is inversely associated to the mannequin’s confidence in its predictions. Because the mannequin turns into extra assured (larger possibilities), the perplexity decreases.
Implementation of Perplexity Metric from Scratch in Python
Let’s implement perplexity calculation in Python to solidify our understanding:
import numpy as np
from collections import Counter, defaultdict
class NgramLanguageModel:
def __init__(self, n=2):
self.n = n
self.context_counts = defaultdict(Counter)
self.context_totals = defaultdict(int)
def practice(self, corpus):
"""Prepare the language mannequin on a corpus"""
# Add begin and finish tokens
tokens = ['<s>'] * (self.n - 1) + corpus + ['</s>']
# Depend n-grams
for i in vary(len(tokens) - self.n + 1):
context = tuple(tokens[i:i+self.n-1])
phrase = tokens[i+self.n-1]
self.context_counts[context][word] += 1
self.context_totals[context] += 1
def likelihood(self, phrase, context):
"""Calculate likelihood of phrase given context"""
if self.context_totals[context] == 0:
return 1e-10 # Smoothing for unseen contexts
return (self.context_counts[context][word] + 1) / (self.context_totals[context] + len(self.context_counts))
def sequence_probability(self, sequence):
"""Calculate likelihood of whole sequence"""
tokens = ['<s>'] * (self.n - 1) + sequence + ['</s>']
prob = 1.0
for i in vary(len(tokens) - self.n + 1):
context = tuple(tokens[i:i+self.n-1])
phrase = tokens[i+self.n-1]
prob *= self.likelihood(phrase, context)
return prob
def perplexity(self, test_sequence):
"""Calculate perplexity of a take a look at sequence"""
N = len(test_sequence) + 1 # +1 for the top token
log_prob = 0.0
tokens = ['<s>'] * (self.n - 1) + test_sequence + ['</s>']
for i in vary(len(tokens) - self.n + 1):
context = tuple(tokens[i:i+self.n-1])
phrase = tokens[i+self.n-1]
prob = self.likelihood(phrase, context)
log_prob += np.log2(prob)
return 2 ** (-log_prob / N)
# Let's take a look at our implementation
def tokenize(textual content):
"""Easy tokenization by splitting on areas"""
return textual content.decrease().cut up()
# Instance utilization
corpus = tokenize("the cat sat on the mat the canine chased the cat the cat ran away")
take a look at = tokenize("the cat sat on the ground")
mannequin = NgramLanguageModel(n=2)
mannequin.practice(corpus)
print(f"Perplexity of take a look at sequence: {mannequin.perplexity(take a look at):.2f}")This implementation creates a primary n-gram language mannequin with add-one smoothing for dealing with unseen phrases or contexts. Let’s analyze what’s occurring within the code:
- We outline an NgramLanguageModel class that shops counts of contexts and phrases.
- The practice technique processes a corpus and builds the n-gram statistics.
- The likelihood technique calculates P(phrase|context) with primary smoothing.
- The sequence_probability technique computes the joint likelihood of a sequence.
- Lastly, the perplexity technique calculates the perplexity as outlined by our formulation.
Output
Perplexity of take a look at sequence: 129.42
Instance and Output
Let’s run by means of an entire instance with our implementation:
# Coaching corpus
train_corpus = tokenize("the cat sat on the mat the canine chased the cat the cat ran away")
# Check sequences
test_sequences = [
tokenize("the cat sat on the mat"),
tokenize("the dog sat on the floor"),
tokenize("a bird flew through the window")
]
# Prepare a bigram mannequin
mannequin = NgramLanguageModel(n=2)
mannequin.practice(train_corpus)
# Calculate perplexity for every take a look at sequence
for i, take a look at in enumerate(test_sequences):
ppl = mannequin.perplexity(take a look at)
print(f"Check sequence {i+1}: '{' '.be part of(take a look at)}'")
print(f"Perplexity: {ppl:.2f}")
print()Output
Check sequence 1: 'the cat sat on the mat'Perplexity: 6.15
Check sequence 2: 'the canine sat on the ground'
Perplexity: 154.05
Check sequence 3: 'a hen flew by means of the window'
Perplexity: 28816455.70
Observe how the perplexity will increase as we transfer from take a look at sequence 1 (which seems verbatim within the coaching knowledge) to sequence 3 (which incorporates many phrases not seen in coaching). This demonstrates how perplexity displays mannequin uncertainty.
Implementing Perplexity Metric in NLTK
For sensible purposes, you may need to use established libraries like NLTK, which offer extra subtle implementations of language fashions and perplexity calculations:
import nltk
from nltk.lm import Laplace
from nltk.lm.preprocessing import padded_everygram_pipeline
from nltk.tokenize import word_tokenize
import math
# Obtain required assets
nltk.obtain('punkt')
# Put together the coaching knowledge
train_text = "The cat sat on the mat. The canine chased the cat. The cat ran away."
train_tokens = [word_tokenize(train_text.lower())]
# Create n-grams and vocabulary
n = 2 # Bigram mannequin
train_data, padded_vocab = padded_everygram_pipeline(n, train_tokens)
# Prepare the mannequin utilizing Laplace smoothing
mannequin = Laplace(n) # Laplace (add-1) smoothing to deal with unseen phrases
mannequin.match(train_data, padded_vocab)
# Check sentence
test_text = "The cat sat on the ground."
test_tokens = word_tokenize(test_text.decrease())
# Put together take a look at knowledge with padding
test_data = record(nltk.ngrams(test_tokens, n, pad_left=True, pad_right=True,
left_pad_symbol="<s>", right_pad_symbol="</s>"))
# Compute perplexity manually
log_prob_sum = 0
N = len(test_data)
for ngram in test_data:
prob = mannequin.rating(ngram[-1], ngram[:-1]) # P(w_i | w_{i-1})
log_prob_sum += math.log2(prob) # Keep away from log(0) on account of smoothing
# Compute ultimate perplexity
perplexity = 2 ** (-log_prob_sum / N)
print(f"Perplexity (Laplace smoothing): {perplexity:.2f}")Output: Perplexity (Laplace smoothing): 8.33
In pure language processing (NLP), perplexity measures how nicely a language mannequin predicts a sequence of phrases. A decrease perplexity rating signifies a greater mannequin. Nonetheless, Most Chance Estimation (MLE) fashions endure from the out-of-vocabulary (OOV) downside, assigning zero likelihood to unseen phrases, resulting in infinite perplexity.
To unravel this, we use Laplace smoothing (Add-1 smoothing), which assigns small possibilities to unseen phrases, stopping zero possibilities. The corrected code implements a bigram language mannequin utilizing NLTK’s Laplace class as a substitute of MLE. This ensures a finite perplexity rating, even when the take a look at sentence incorporates phrases not current in coaching.
This method is essential in constructing sturdy n-gram fashions for textual content prediction and speech recognition.
Benefits of Perplexity
Perplexity affords a number of benefits as an analysis metric for language fashions:
- Interpretability: Perplexity has a transparent interpretation as the typical branching issue of the prediction activity.
- Mannequin-Agnostic: It may be utilized to any probabilistic language mannequin that assigns possibilities to sequences.
- No Human Annotations Required: In contrast to many different analysis metrics, perplexity doesn’t require human-annotated reference texts.
- Effectivity: It’s computationally environment friendly to calculate, particularly in comparison with metrics that require technology or sampling.
- Historic Precedent: As one of many oldest metrics in language modeling, perplexity has established benchmarks and a wealthy analysis historical past.
- Allows Direct Comparability: Fashions with the identical vocabulary may be instantly in contrast based mostly on their perplexity scores.
Limitations of Perplexity
Regardless of its widespread use, perplexity has a number of essential limitations:
- Vocabulary Dependency: Perplexity scores are solely comparable between fashions that use the identical vocabulary.
- Not Aligned with Human Judgment: Decrease perplexity doesn’t at all times translate to higher high quality in human evaluations.
- Restricted for Open-ended Technology: Perplexity evaluates how nicely a mannequin predicts particular textual content, not how coherent, numerous, or attention-grabbing its generations are.
- No Semantic Understanding: A mannequin might obtain low perplexity by memorizing n-grams with out true understanding.
- Activity-Agnostic: Perplexity doesn’t measure task-specific efficiency (e.g., query answering, summarization).
- Points with Lengthy-Vary Dependencies: Conventional implementations of perplexity wrestle with evaluating long-range dependencies in textual content.
Overcoming Limitations Utilizing LLM-as-a-Choose
To handle the restrictions of perplexity, researchers have developed various analysis approaches, together with utilizing giant language fashions as judges (LLM-as-a-Choose):
- Precept: Use a extra highly effective LLM to guage the outputs of one other language mannequin.
- Implementation:
- Generate textual content utilizing the mannequin being evaluated
- Present this textual content to a “choose” LLM together with analysis standards
- Have the choose LLM rating or rank the generated textual content
- Benefits:
- Can consider facets like coherence, factuality, and relevance
- Extra aligned with human judgments
- Could be custom-made for particular analysis standards
- Instance Implementation:
def llm_as_judge(generated_text, reference_text=None, standards="coherence and fluency"):
"""Use a big language mannequin to evaluate generated textual content"""
# It is a simplified instance - in apply, you'd name an precise LLM API
if reference_text:
immediate = f"""
Please consider the next generated textual content based mostly on {standards}.
Reference textual content: {reference_text}
Generated textual content: {generated_text}
Rating from 1-10 and supply reasoning.
"""
else:
immediate = f"""
Please consider the next generated textual content based mostly on {standards}.
Generated textual content: {generated_text}
Rating from 1-10 and supply reasoning.
"""
# In an actual implementation, you'd name your LLM API right here
# response = llm_api.generate(immediate)
# return parse_score(response)
# For demonstration functions solely:
import random
rating = random.uniform(1, 10)
return ratingThis method enhances perplexity by offering human-like judgments of textual content high quality throughout a number of dimensions.
Sensible Purposes
Perplexity finds purposes in numerous NLP duties:
- Language Mannequin Analysis: Evaluating totally different LM architectures or hyperparameter settings.
- Area Adaptation: Measuring how nicely a mannequin adapts to a selected area.
- Out-of-Distribution Detection: Figuring out textual content that doesn’t match the coaching distribution.
- Information High quality Evaluation: Evaluating the standard of coaching or take a look at knowledge.
- Textual content Technology Filtering: Utilizing perplexity to filter out low-quality generated textual content.
- Anomaly Detection: Figuring out uncommon or anomalous textual content patterns.
Comparability with Different LLM Analysis Metrics
Let’s examine perplexity with different common analysis metrics for language fashions:
| Metric | What It Measures | Benefits | Limitations |
| Perplexity | Prediction accuracy | No reference wanted, environment friendly | Vocabulary dependent, not aligned with human judgment |
| BLEU | N-gram overlap with reference | Good for translation, summarization | Requires reference, poor for creativity |
| ROUGE | Recall of n-grams from reference | Good for summarization | Requires reference, focuses on overlap |
| BERTScore | Semantic similarity utilizing contextual embeddings | Higher semantic understanding | Computationally intensive |
| Human Analysis | Varied facets as judged by people | Most dependable for high quality | Costly, time-consuming, subjective |
| LLM-as-Choose | Varied facets as judged by an LLM | Versatile, scalable | Is dependent upon choose mannequin high quality |
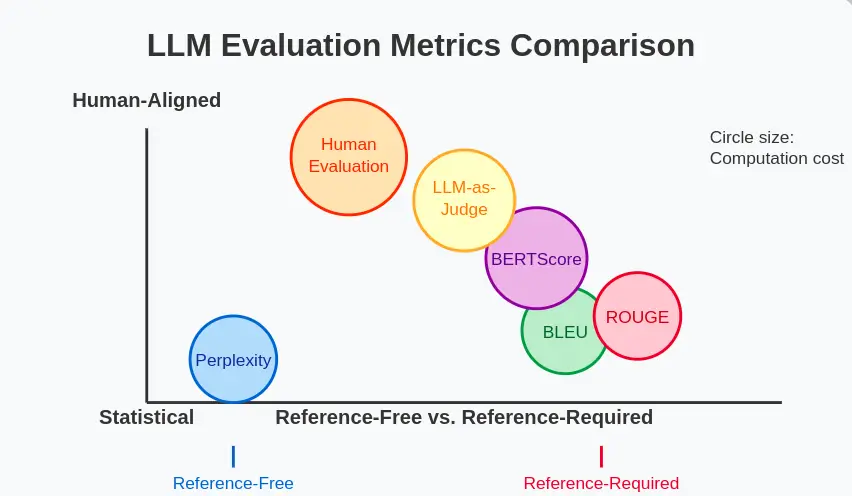
To decide on the fitting metric, take into account:
- Activity: What facet of language technology are you evaluating?
- Availability of References: Do you’ve gotten reference texts?
- Computational Assets: How environment friendly does the analysis must be?
- Interpretability: How essential is it to grasp the metric?
A hybrid method usually works finest—combining perplexity for effectivity with different metrics for complete analysis.
Conclusion
Perplexity Metric has lengthy served as a key metric for evaluating language fashions, providing a transparent, information-theoretic measure of how nicely a mannequin predicts textual content. Regardless of its limits—like poor alignment with human judgment—it stays helpful when mixed with newer strategies, reminiscent of reference-based scores, embedding similarities, and LLM-based evaluations.
As fashions develop extra superior, analysis will seemingly shift towards hybrid approaches that mix perplexity’s effectivity with extra human-aligned metrics.
The underside line: deal with perplexity as one sign amongst many, figuring out each its strengths and its blind spots.
Problem for You: Attempt implementing perplexity calculation on your personal textual content corpus! Use the code offered on this article as a place to begin, and experiment with totally different n-gram sizes, smoothing methods, and take a look at units. How does altering these parameters have an effect on the perplexity scores?
Gen AI Intern at Analytics Vidhya
Division of Pc Science, Vellore Institute of Know-how, Vellore, India
I’m at the moment working as a Gen AI Intern at Analytics Vidhya, the place I contribute to progressive AI-driven options that empower companies to leverage knowledge successfully. As a final-year Pc Science scholar at Vellore Institute of Know-how, I convey a strong basis in software program growth, knowledge analytics, and machine studying to my position.
Be at liberty to attach with me at [email protected]
Login to proceed studying and revel in expert-curated content material.