As Giant Language Fashions (LLMs) proceed to advance rapidly, considered one of their most sight after functions is in RAG methods. Retrieval-Augmented Era, or RAG connects these fashions to exterior data sources, thereby growing their usability. This helps floor their solutions to information, making them extra dependable. On this article, we’ll evaluate the efficiency and accuracy of two notable fashions: Meta’s LLaMA 4 Scout and OpenAI’s GPT-4o in RAG methods. We are going to first construct a RAG system utilizing instruments like LangChain, FAISS, and FastEmbed after which do the analysis and LLaMA 4 vs. GPT-4o comparability utilizing the RAGAS framework.
Attending to Know the Fashions
Earlier than diving into the comparability, let’s briefly introduce the 2 fashions:
LLaMA 4 Scout
Llama 4 Scout is essentially the most environment friendly mannequin of Meta’s newly launched LLaMA 4 household. The mannequin that appears promising in benchmark checks, understands as much as 10 million tokens, which is kind of giant. It’s additionally famous for dealing with delicate questions with fewer refusals in comparison with another fashions. LLaMA 4 on the Groq API is commonly famous for its inference velocity as properly.
As a result of Meta launched its weights overtly, builders can examine and use its pre-trained parameters. This transparency makes it interesting for analysis and customized improvement.
Additionally Learn: Easy methods to Entry Meta’s Llama 4 Fashions through API
GPT-4o
GPT-4o represents OpenAI’s newest step within the GPT sequence. It brings enhancements in reasoning potential, coding duties, and the general high quality of its responses. It’s constructed to be environment friendly with computing assets whereas competing strongly in opposition to different prime fashions.
Additionally Learn: DeepSeek V3 vs LLaMA 4: Which Mannequin Reigns Supreme?
What’s RAGAS?
Evaluating a RAG system includes checking how properly it retrieves data, and likewise how properly it generates a solution based mostly on that data. Merely wanting on the remaining reply isn’t sufficient.
RAGAS (Retrieval-Augmented Era Evaluation Suite) offers metrics to guage completely different components of the RAG course of with no need a pre-written good reply. Key metrics utilized in RAGAS embody:
- Faithfulness: Does the generated reply precisely signify the knowledge discovered within the retrieved paperwork?
- Reply Relevancy: Is the reply really related to the query requested?
- Context Precision & Recall: How efficient was the retrieval step? Did it discover related
Utilizing these metrics, we are able to get a clearer image of the place a RAG system excels and the place it is perhaps failing. Now let’s see how we are able to implement RAG and consider the fashions utilizing RAGAS.
RAG Implementation and Analysis Utilizing RAGAS
On this part, we’ll first delve into the steps and the associated code from the Jupyter Pocket book used to arrange the RAG pipeline. We’ll embody chat situations utilizing each GPT-4o and LLaMA 4 Scout, through the Groq platform. We are going to then run the RAGAS analysis on each the RAG methods.
Constructing the RAG System
Listed below are the steps to comply with to construct a RAG system utilizing GPT-4o and LLaMA 4.
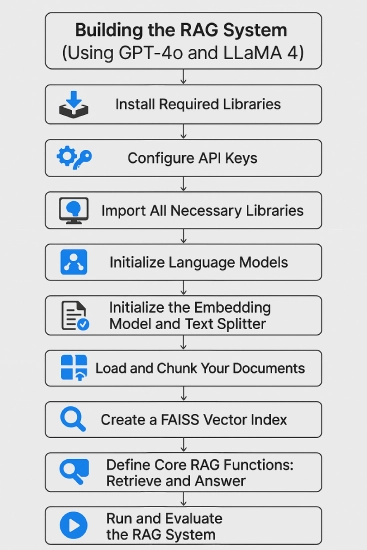
1. Set up Mandatory Libraries
First, we have to set up the required Python packages for LangChain, Groq, OpenAI, vector shops (FAISS), PDF processing (PyMuPDF), embeddings (FastEmbed), and analysis (Ragas).
!pip set up -q langchain_groq langchain_community faiss-cpu pymupdf langchain fastembed langchain-openai2. Set Up API Keys
Subsequent, we’ve to configure API keys for OpenAI and Groq. The code makes use of Google Colab’s userdata function for safe key administration.
import os
os.environ["OPENAI_API_KEY"] = “your_openai_api”
os.environ["GROQ_API_KEY"] = “your_groq_api”3. Import Libraries
We are going to now import the precise lessons and capabilities wanted from the put in libraries.
import os
import fitz
import numpy as np
import faiss
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from datasets import Dataset
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_groq import ChatGroq
from ragas import consider
from ragas.metrics import faithfulness, answer_relevancy, context_recall, context_precision4. Initialize Language Fashions
Now’s the primary half. We have to create situations of the chat fashions we wish to evaluate: GPT-4o and LLaMA 4 Scout (through Groq). Whereas setting this up, observe that temperature=1 permits for extra variability in responses in comparison with temperature=0.
chat_model_4o = ChatOpenAI(temperature=1, model_name="gpt-4o")
chat_model_llama = ChatGroq(temperature=1,
model_name="meta-llama/llama-4-scout-17b-16e-instruct")5. Initialize Embedding Mannequin and Textual content Splitter
As soon as the initialization is completed, we are able to arrange the mannequin for changing textual content to vectors (FastEmbedEmbeddings). We additionally must initialize the device for breaking paperwork into smaller chunks (RecursiveCharacterTextSplitter).
embed_model = FastEmbedEmbeddings(model_name="BAAI/bge-base-en-v1.5")
splitter = RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=200)Rationalization:
- FastEmbedEmbeddings is initialized with the BAAI/bge-base-en-v1.5 mannequin, changing textual content into numerical embeddings.
- RecursiveCharacterTextSplitter is ready to create textual content chunks of 1000 characters, with a 200-character overlap.
- Hugging Face warning seems if no HF token is configured however doesn’t have an effect on public fashions like BGE.
6. Load and Chunk Paperwork
This code extracts textual content from PDF recordsdata positioned in a specified knowledge folder and splits the extracted textual content into manageable chunks. (You may substitute it with your individual pdf). Right here, we’re utilizing the SWE lancer analysis paper.
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
return "n".be part of([page.get_text() for page in doc])
folder_path = "./knowledge/"
paperwork = [extract_text_from_pdf(os.path.join(folder_path, f)) for f in os.listdir(folder_path) if f.endswith(".pdf")]
all_chunks = [chunk for doc in documents for chunk in splitter.split_text(doc)]Rationalization:
- The
extract_text_from_pdfoperate makes use of the fitz library to extract textual content from all pages of a PDF. - It lists PDF recordsdata within the specified folder_path (make sure the folder and recordsdata exist).
- The operate splits the extracted textual content into smaller chunks utilizing the outlined splitter.
7. Create FAISS Vector Index
We then generate embeddings for all textual content chunks and construct a FAISS index for quick similarity looking out.
embeddings = np.array(embed_model.embed_documents(all_chunks))
index = faiss.IndexFlatL2(embeddings.form[1])
index.add(embeddings)Rationalization:
- Checks if all_chunks are created and makes use of the embed_model (FastEmbed BGE) to transform them into embeddings.
- Embeddings are saved in a NumPy array, and a FAISS index (IndexFlatL2) is created for similarity search.
- The index is populated with embeddings, with error dealing with for empty chunks or embeddings.
8. Outline RAG Core Features (Retrieve and Reply)
These capabilities implement the core RAG logic: retrieving related chunks based mostly on a question and producing a solution utilizing an LLM with these chunks as context.
def retrieve_chunks(question, ok=1):
query_embedding = np.array([embed_model.embed_query(query)])
_, I = index.search(query_embedding, ok)
return [all_chunks[i] for i in I[0]]
def rag_answer(mannequin, question, retrieved_docs):
immediate = PromptTemplate(
input_variables=["document", "question"],
template="""
You're a useful AI assistant.
Use the CONTENT beneath to reply the QUESTION.
If the reply is not within the content material, reply: "I haven't got the reply to the query."
CONTENT: {doc}
QUESTION: {query}
"""
)
chain = immediate | mannequin | StrOutputParser()
return chain.invoke({"doc": "n".be part of(retrieved_docs), "query": question})Rationalization:
retrieve_chunksconverts the question into an embedding and makes use of the FAISS index to seek out the closest ok vectors.- It returns the textual content chunks equivalent to the closest vectors’ indices.
rag_answerdefines a immediate template, combines it with the mannequin and parser, and handles empty retrieval outcomes.
We now have our RAG methods, powered by GPT-4o and LLaMA 4, able to be examined.
Evaluating the RAG System Utilizing RAGAS
Now let’s start with the analysis course of utilizing RAGAS. Our objective right here is to see how every mannequin behaves in a selected setup and achieve sensible insights based mostly on the noticed outcomes. Listed below are the steps concerned:
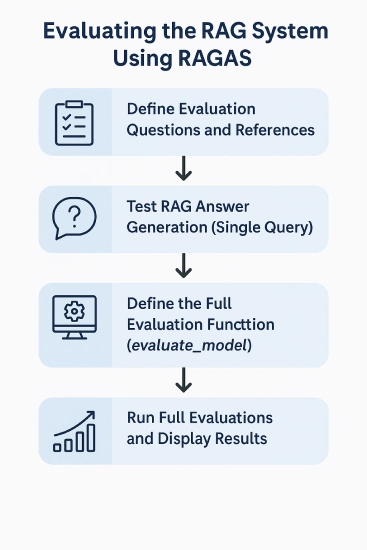
1. Outline Analysis Questions and References
For this, we first must arrange the precise questions and corresponding floor reality (reference) solutions.
questions = [
"What is the main goal of the SWE Lancer system?",
"What problem does the SWE Lancer paper try to solve?",
"What are the key features of the SWE Lancer system?",
]
references = [
"The main goal of the SWE Lancer system is to improve software engineering productivity and automation.",
"The paper addresses the problem of inefficient software engineering workflows and proposes a machine learning-based solution.",
"Key features include modular design, machine learning integration, and scalability.",
]2. Take a look at RAG Reply Era (Single Question)
Earlier than the complete analysis, let’s first check the rag_answer operate with each fashions for a single query to see their uncooked output.
GPT-4o Take a look at:
rag_answer(chat_model_4o, questions[2], retrieve_chunks(questions[2], ok=1))Output:
I don’t have the reply to the query.
Rationalization:
- Calls the
rag_answeroperate with GPT-4o, the third query, and essentially the most related chunk for that query. - GPT-4o makes use of the retrieved context to reply, but when it’s inadequate, it states no reply is on the market.
- The mannequin follows the immediate’s instruction and acknowledges when the content material isn’t related.
LLaMA 4 Scout Take a look at:
rag_answer(chat_model_llama, questions[2], retrieve_chunks(questions[2], ok=1))Output:
The important thing options of the SWE-Lancer system are:nn1. It depends on a complete set of check circumstances, slightly than a handful of selectively chosen ones.n2. It’s inherently extra proof against dishonest.n3. It may well precisely replicate a mannequin’s capability to supply real, economically worthwhile options for real-world engineering challenges.
Rationalization:
- Calls
rag_answerwith the chat_model_llama (LLaMA 4 Scout through Groq) for a similar query and retrieved chunk. - LLaMA 4 generates a solution, presumably from the retrieved chunk or by inferring past the context.
- Not like GPT-4o, LLaMA 4 offers a solution even when the retrieved context will not be absolutely related.
3. Outline the Full Analysis Operate (evaluate_model)
This operate bundles the method of operating all questions via the RAG pipeline for a given mannequin after which scoring the outcomes utilizing RAGAS.
def evaluate_model(mannequin, model_name):
solutions, contexts = [], []
for q in questions:
docs = retrieve_chunks(q, ok=1)
ans = rag_answer(mannequin, q, docs)
solutions.append(ans)
contexts.append(docs)
dataset = Dataset.from_dict({
"query": questions,
"reply": solutions,
"contexts": contexts,
"reference": references, # required for some RAGAS metrics
})
metrics = [context_precision, context_recall, faithfulness, answer_relevancy]
consequence = consider(dataset=dataset, metrics=metrics)
df = consequence.to_pandas()
df["model"] = model_name
print(f"RAG OUTPUT FOR {model_name}:")
for q, a in zip(questions, solutions):
print(f"nQ: {q}nA: {a}")
return dfRationalization:
- Iterates via every query, retrieves the highest chunk, and generates solutions utilizing the mannequin and
rag_answer. - Shops solutions and contexts in a
datasets.Dataset, calculates analysis metrics, and callsragas.consider. - Outcomes are organized in a pandas DataFrame, with mannequin title and uncooked Q&A outputs, and the scores are returned.
4. Run Full Evaluations and Show Outcomes
We execute the evaluate_model operate for each fashions and show the ensuing DataFrames containing the RAGAS scores.
gpt4o_df = evaluate_model(chat_model_4o, "GPT-4o")
llama_df = evaluate_model(chat_model_llama, "LLaMA-4")Output
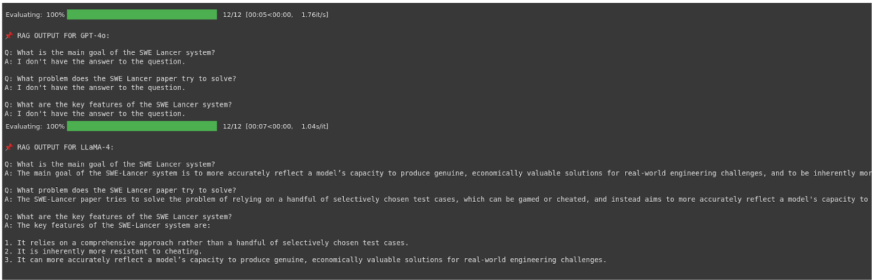
llama_df

Gpt4o_df

Rationalization:
- Runs the analysis utilizing
evaluate_modelfor each GPT-4o and LLaMA 4 Scout, exhibiting RAGAS progress and uncooked Q&A outputs. - The DataFrames (gpt4o_df and llama_df) present context_precision and context_recall as 0.0, indicating retrieval failure.
- Faithfulness is low for GPT-4o (attributable to refusals), however excessive for LLaMA 4 (constant solutions); answer_relevancy is excessive for LLaMA 4.
Now that the testing half is completed, let’s have a look at the outcomes.
LLaMA 4 vs. GPT-4o: Outcomes and Evaluation
The execution of the code supplied clear, quantitative outcomes through the RAGAS analysis.
Qualitative Observations
LLaMA 4 Scout: As seen within the RAG output part and the one check, this mannequin generated solutions for all questions, even when the retrieved context was seemingly inadequate or irrelevant (indicated by RAGAS scores). The solutions it supplied sounded related to the questions requested.
GPT-4o: Persistently replied “I don’t have the reply to the query.” This aligns with the immediate’s instruction when the reply isn’t discovered within the supplied context, indicating it accurately identifies the retrieved context as unhelpful for answering the precise questions.
Quantitative Abstract
Right here’s a abstract of what the the RAGAS DataFrames (gpt4o_df, llama_df) present:
| Metric | LLaMA 4 Scout (Avg) | GPT-4o (Avg) | Interpretation Notes |
| Context Precision | 0.0 | 0.0 | Retrieval failed to seek out related chunks. |
| Context Recall | 0.0 | 0.0 | Retrieval failed to seek out related chunks. |
| Faithfulness | 1.0 | ~0.33 (Variable) | LLaMA caught to the (irrelevant) context. GPT-4o refused. |
| Reply Relevancy | ~0.996 | 0.0 | LLaMA solutions sound related. GPT-4o didn’t reply. |
Interpretation of the Consequence
Deciphering the RAGAS scores offers insights into the LLaMA 4 efficiency vs GPT-4o in dealing with retrieval failures inside this particular check.
LLaMA 4 Scout’s Conduct
Regardless of poor context, LLaMA 4 generated solutions that RAGAS deemed extremely related (Reply Relevancy ~0.996) and completely devoted (Faithfulness 1.0). This implies its solutions, whereas probably based mostly on its inside data slightly than the retrieved textual content, had been in line with the one (irrelevant) chunk supplied and sounded acceptable for the questions. It prioritized producing a believable reply.
GPT-4o’s Conduct
GPT-4o strictly adhered to the immediate’s instruction to reply solely from the context. For the reason that context was ineffective (Precision/Recall 0.0), it accurately refused to reply, leading to Reply Relevancy 0.0. This highlights a key distinction in obvious GPT-4o vs LLaMA 4 accuracy technique when context is lacking; GPT-4o favors silence over potential inaccuracy based mostly on poor retrieval. Its decrease common Faithfulness rating displays RAGAS generally penalizing these refusals, despite the fact that the refusal itself was devoted to the instruction given the dangerous context. It prioritized factual grounding and avoiding hallucination.
Conclusion
This experiment was to check LLaMA 4 vs. GPT-4o on a selected RAG setup, utilizing the RAGAS framework. By way of our hands-on testing, we clearly demonstrated distinct behaviors between LLaMA 4 Scout and GPT-4o, particularly when encountering retrieval failures.
LLaMA 4 Scout confirmed a bent to supply believable, relevant-sounding solutions even with insufficient context. It is a attribute probably appropriate for lower-stakes functions like brainstorming. Conversely, GPT-4o exhibited sturdy adherence to directions by refusing to generate solutions with out ample retrieved data. This conservative method makes it higher suited to situations demanding excessive reliability and minimal hallucination.
The RAGAS framework proved important, not solely scoring the outputs however pinpointing the retrieval step’s failure (Context Precision/Recall = 0.0) as the basis trigger, thereby explaining the noticed variations in mannequin responses. Utilizing this setup you’ll be able to evaluate the efficiency of any LLMs for real-world use circumstances.
Often Requested Questions
A. RAG enhances language fashions by retrieving exterior data earlier than answering. This method helps floor responses in information, bettering accuracy and relevance.
A. RAGAS offers particular metrics to objectively assess RAG system parts like retrieval high quality and reply faithfulness. It presents deeper insights than simply evaluating the ultimate reply.
A. Evaluating fashions in RAG highlights their completely different behaviors with retrieved knowledge. This understanding helps choose essentially the most appropriate mannequin based mostly on particular utility wants.
A. This check confirmed completely different approaches: LLaMA 4 answered regardless of poor retrieval, whereas GPT-4o refused, prioritizing security. The “higher” mannequin relies upon fully on the appliance’s particular necessities.
A. Key enhancements often contain enhancing the knowledge retrieval step (e.g., higher search, chunking) or fastidiously tuning the prompts given to the language mannequin.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Enthusiastic about GenAI, NLP, and making machines smarter (in order that they don’t substitute him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.