For the reason that rise of AI chatbots, Google’s Gemini has emerged as some of the highly effective gamers driving the evolution of clever methods. Past its conversational energy, Gemini additionally unlocks sensible prospects in laptop imaginative and prescient, enabling machines to see, interpret, and describe the world round them.
This information walks you thru the steps to leverage Google Gemini for laptop imaginative and prescient, together with the way to arrange your surroundings, ship photos with directions, and interpret the mannequin’s outputs for object detection, caption technology, and OCR. We’ll additionally contact on information annotation instruments (like these used with YOLO) to provide context for customized coaching eventualities.
What’s Google Gemini?
Google Gemini is a household of AI fashions constructed to deal with a number of information varieties, reminiscent of textual content, photos, audio, and code collectively. This implies they will course of duties that contain understanding each photos and phrases.
Gemini 2.5 Professional Options
- Multimodal Enter: It accepts mixtures of textual content and pictures in a single request.
- Reasoning: The mannequin can analyze info from the inputs to carry out duties like figuring out objects or describing scenes.
- Instruction Following: It responds to textual content directions (prompts) that information its evaluation of the picture.
These options permit builders to make use of Gemini for vision-related duties via an API with out coaching a separate mannequin for every job.
The Position of Information Annotation: The YOLO Annotator
Whereas Gemini fashions present highly effective zero-shot or few-shot capabilities for these laptop imaginative and prescient duties, constructing extremely specialised laptop imaginative and prescient fashions requires coaching on a dataset tailor-made to the particular drawback. That is the place information annotation turns into important, notably for supervised studying duties like coaching a customized object detector.
The YOLO Annotator (usually referring to instruments appropriate with the YOLO format, like Labeling, CVAT, or Roboflow) is designed to create labeled datasets.
What’s Information Annotation?
For object detection, annotation includes drawing bounding bins round every object of curiosity in a picture and assigning a category label (e.g., ‘automotive’, ‘particular person’, ‘canine’). This annotated information tells the mannequin what to search for and the place throughout coaching.
Key Options of Annotation Instruments (like YOLO Annotator)
- Person Interface: They supply graphical interfaces permitting customers to load photos, draw bins (or polygons, keypoints, and so forth.), and assign labels effectively.
- Format Compatibility: Instruments designed for YOLO fashions save annotations in a particular textual content file format that YOLO coaching scripts count on (usually one .txt file per picture, containing class index and normalized bounding field coordinates).
- Effectivity Options: Many instruments embrace options like hotkeys, computerized saving, and typically model-assisted labeling to hurry up the customarily time-consuming annotation course of. Batch processing permits for more practical dealing with of huge picture units.
- Integration: Utilizing commonplace codecs like YOLO ensures that the annotated information will be simply used with well-liked coaching frameworks, together with Ultralytics YOLO.
Whereas Google Gemini for Laptop Imaginative and prescient, can detect normal objects with out prior annotation, for those who wanted a mannequin to detect very particular, customized objects (e.g., distinctive kinds of industrial tools, particular product defects), you’ll seemingly want to gather photos and annotate them utilizing a software like a YOLO annotator to coach a devoted YOLO mannequin.
Code Implementation – Google Gemini for Laptop Imaginative and prescient
First, you might want to set up the mandatory software program libraries.
Step 1: Set up the Stipulations
1. Set up Libraries
Run this command in your terminal:
!uv pip set up -U -q google-genai ultralyticsThis command installs the google-genai library to speak with the Gemini API and the ultralytics library, which comprises useful capabilities for dealing with photos and drawing on them.
2. Import Modules
Add these traces to your Python Pocket book:
import json
import cv2
import ultralytics
from google import genai
from google.genai import varieties
from PIL import Picture
from ultralytics.utils.downloads import safe_download
from ultralytics.utils.plotting import Annotator, colours
ultralytics.checks()This code imports libraries for duties like studying photos (cv2, PIL), dealing with JSON information (json), interacting with the API (google.generativeai), and utility capabilities (ultralytics).
3. Configure API Key
Initialize the consumer utilizing your Google AI API key.
# Change "your_api_key" together with your precise key
# Use GenerativeModel for newer variations of the library
# Initialize the Gemini consumer together with your API key
consumer = genai.Shopper(api_key=”your_api_key”)This step prepares your script to ship authenticated requests.
Step 2: Operate to Work together with Gemini
Create a operate to ship requests to the mannequin. This operate takes a picture and a textual content immediate and returns the mannequin’s textual content output.
def inference(picture, immediate, temp=0.5):
"""
Performs inference utilizing Google Gemini 2.5 Professional Experimental mannequin.
Args:
picture (str or genai.varieties.Blob): The picture enter, both as a base64-encoded string or Blob object.
immediate (str): A textual content immediate to information the mannequin's response.
temp (float, non-compulsory): Sampling temperature for response randomness. Default is 0.5.
Returns:
str: The textual content response generated by the Gemini mannequin primarily based on the immediate and picture.
"""
response = consumer.fashions.generate_content(
mannequin="gemini-2.5-pro-exp-03-25",
contents=[prompt, image], # Present each the textual content immediate and picture as enter
config=varieties.GenerateContentConfig(
temperature=temp, # Controls creativity vs. determinism in output
),
)
return response.textual content # Return the generated textual responseClarification
- This operate sends the picture and your textual content instruction (immediate) to the Gemini mannequin specified within the model_client.
- The temperature setting (temp) influences output randomness; decrease values give extra predictable outcomes.
Step 3: Getting ready Picture Information
It’s essential to load photos appropriately earlier than sending them to the mannequin. This operate downloads a picture if wanted, reads it, converts the colour format, and returns a PIL Picture object and its dimensions.
def read_image(filename):
image_name = safe_download(filename)
# Learn picture with opencv
picture = cv2.cvtColor(cv2.imread(f"/content material/{image_name}"), cv2.COLOR_BGR2RGB)
# Extract width and peak
h, w = picture.form[:2]
# # Learn the picture utilizing OpenCV and convert it into the PIL format
return Picture.fromarray(picture), w, hClarification
- This operate makes use of OpenCV (cv2) to learn the picture file.
- It converts the picture shade order to RGB, which is commonplace.
- It returns the picture as a PIL object, appropriate for the inference operate, and its width and peak.
Step 4: End result formatting
def clean_results(outcomes):
"""Clear the outcomes for visualization."""
return outcomes.strip().removeprefix("```json").removesuffix("```").strip()This operate codecs the consequence into JSON format.
Activity 1: Object Detection
Gemini can discover objects in a picture and report their places (bounding bins) primarily based in your textual content directions.
# Outline the textual content immediate
immediate = """
Detect the 2nd bounding bins of objects in picture.
"""
# Mounted, plotting operate is dependent upon this.
output_prompt = "Return simply box_2d and labels, no extra textual content."
picture, w, h = read_image("https://media-cldnry.s-nbcnews.com/picture/add/t_fit-1000w,f_auto,q_auto:greatest/newscms/2019_02/2706861/190107-messy-desk-stock-cs-910a.jpg") # Learn img, extract width, peak
outcomes = inference(picture, immediate + output_prompt) # Carry out inference
cln_results = json.hundreds(clean_results(outcomes)) # Clear outcomes, listing convert
annotator = Annotator(picture) # initialize Ultralytics annotator
for idx, merchandise in enumerate(cln_results):
# By default, gemini mannequin return output with y coordinates first.
# Scale normalized field coordinates (0–1000) to picture dimensions
y1, x1, y2, x2 = merchandise["box_2d"] # bbox submit processing,
y1 = y1 / 1000 * h
x1 = x1 / 1000 * w
y2 = y2 / 1000 * h
x2 = x2 / 1000 * w
if x1 > x2:
x1, x2 = x2, x1 # Swap x-coordinates if wanted
if y1 > y2:
y1, y2 = y2, y1 # Swap y-coordinates if wanted
annotator.box_label([x1, y1, x2, y2], label=merchandise["label"], shade=colours(idx, True))
Picture.fromarray(annotator.consequence()) # show the outputSupply Picture: Hyperlink
Output
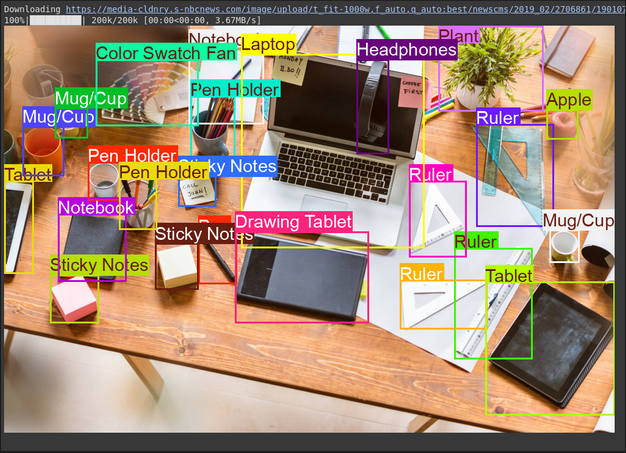
Clarification
- The immediate tells the mannequin what to search out and the way to format the output (JSON)
- It converts the normalized field coordinates (0-1000) to pixel coordinates utilizing the picture width (w) and peak (h).
- The Annotator software attracts the bins and labels on a duplicate of the picture
Activity 2: Testing Reasoning Capabilities
With Gemini fashions, you may sort out advanced duties utilizing superior reasoning that understands context and delivers extra exact outcomes.
# Outline the textual content immediate
immediate = """
Detect the 2nd bounding field round:
spotlight the realm of morning gentle +
PC on desk
potted plant
espresso cup on desk
"""
# Mounted, plotting operate is dependent upon this.
output_prompt = "Return simply box_2d and labels, no extra textual content."
picture, w, h = read_image("https://thumbs.dreamstime.com/b/modern-office-workspace-laptop-coffee-cup-cityscape-sunrise-sleek-desk-featuring-stationery-organized-neatly-city-345762953.jpg") # Learn picture and extract width, peak
outcomes = inference(picture, immediate + output_prompt)
# Clear the outcomes and cargo ends in listing format
cln_results = json.hundreds(clean_results(outcomes))
annotator = Annotator(picture) # initialize Ultralytics annotator
for idx, merchandise in enumerate(cln_results):
# By default, gemini mannequin return output with y coordinates first.
# Scale normalized field coordinates (0–1000) to picture dimensions
y1, x1, y2, x2 = merchandise["box_2d"] # bbox submit processing,
y1 = y1 / 1000 * h
x1 = x1 / 1000 * w
y2 = y2 / 1000 * h
x2 = x2 / 1000 * w
if x1 > x2:
x1, x2 = x2, x1 # Swap x-coordinates if wanted
if y1 > y2:
y1, y2 = y2, y1 # Swap y-coordinates if wanted
annotator.box_label([x1, y1, x2, y2], label=merchandise["label"], shade=colours(idx, True))
Picture.fromarray(annotator.consequence()) # show the outputSupply Picture: Hyperlink
Output

Clarification
- This code block comprises a fancy immediate to check the mannequin’s reasoning capabilities.
- It converts the normalized field coordinates (0-1000) to pixel coordinates utilizing the picture width (w) and peak (h).
- The Annotator software attracts the bins and labels on a duplicate of the picture.
Activity 3: Picture Captioning
Gemini can create textual content descriptions for a picture.
# Outline the textual content immediate
immediate = """
What's contained in the picture, generate an in depth captioning within the type of brief
story, Make 4-5 traces and begin every sentence on a brand new line.
"""
picture, _, _ = read_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg") # Learn picture and extract width, peak
plt.imshow(picture)
plt.axis('off') # Cover axes
plt.present()
print(inference(picture, immediate)) # Show the outcomesSupply Picture: Hyperlink
Output

Clarification
- This immediate asks for a particular model of description (narrative, 4 traces, new traces).
- The supplied picture is proven within the output.
- The operate returns the generated textual content. That is helpful for creating alt textual content or summaries.
Activity 4: Optical Character Recognition (OCR)
Gemini can learn textual content inside a picture and let you know the place it discovered the textual content.
# Outline the textual content immediate
immediate = """
Extract the textual content from the picture
"""
# Mounted, plotting operate is dependent upon this.
output_prompt = """
Return simply box_2d which might be location of detected textual content areas + label"""
picture, w, h = read_image("https://cdn.mos.cms.futurecdn.internet/4sUeciYBZHaLoMa5KiYw7h-1200-80.jpg") # Learn picture and extract width, peak
outcomes = inference(picture, immediate + output_prompt)
# Clear the outcomes and cargo ends in listing format
cln_results = json.hundreds(clean_results(outcomes))
print()
annotator = Annotator(picture) # initialize Ultralytics annotator
for idx, merchandise in enumerate(cln_results):
# By default, gemini mannequin return output with y coordinates first.
# Scale normalized field coordinates (0–1000) to picture dimensions
y1, x1, y2, x2 = merchandise["box_2d"] # bbox submit processing,
y1 = y1 / 1000 * h
x1 = x1 / 1000 * w
y2 = y2 / 1000 * h
x2 = x2 / 1000 * w
if x1 > x2:
x1, x2 = x2, x1 # Swap x-coordinates if wanted
if y1 > y2:
y1, y2 = y2, y1 # Swap y-coordinates if wanted
annotator.box_label([x1, y1, x2, y2], label=merchandise["label"], shade=colours(idx, True))
Picture.fromarray(annotator.consequence()) # show the outputSupply Picture: Hyperlink
Output
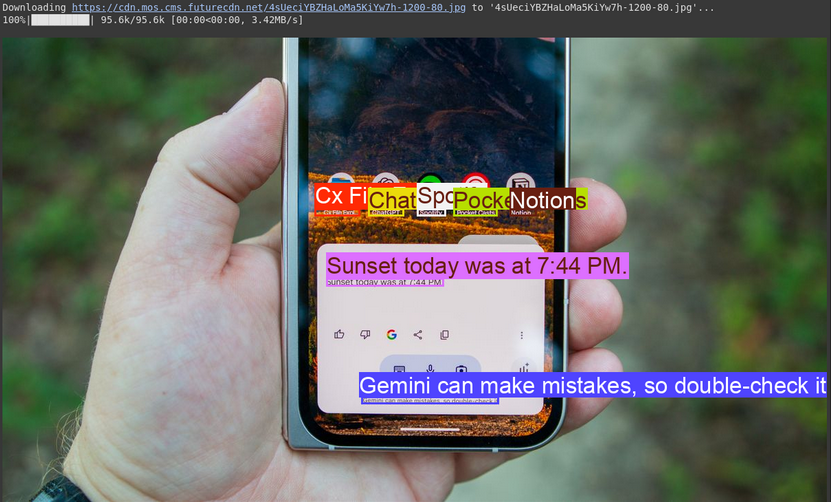
Clarification
- This makes use of a immediate much like object detection however asks for textual content (label) as a substitute of object names.
- The code extracts the textual content and its location, printing the textual content and drawing bins on the picture.
- That is helpful for digitizing paperwork or studying textual content from indicators or labels in photographs.
Conclusion
Google Gemini for Laptop Imaginative and prescient makes it straightforward to sort out duties like object detection, picture captioning, and OCR via easy API calls. By sending photos together with clear textual content directions, you may information the mannequin’s understanding and get usable, real-time outcomes.
That mentioned, whereas Gemini is nice for general-purpose duties or fast experiments, it’s not all the time the most effective match for extremely specialised use instances. Suppose you’re working with area of interest objects or want tighter management over accuracy. In that case, the standard route nonetheless holds robust: gather your dataset, annotate it with instruments like YOLO labelers, and prepare a customized mannequin tuned on your wants.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Enthusiastic about GenAI, NLP, and making machines smarter (so that they don’t change him simply but). When not optimizing fashions, he’s in all probability optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.