Introduction
Giant Language Fashions (LLMs) have demonstrated unparalleled capabilities in pure language processing, but their substantial measurement and computational necessities hinder their deployment. Quantization, a way to scale back mannequin measurement and computational price, has emerged as a essential resolution. This paper gives a complete overview of LLM quantization, delving into numerous quantization strategies, their impression on mannequin efficiency, and their sensible functions throughout various domains. We additional discover the challenges and alternatives in LLM quantization, providing insights into future analysis instructions.

Overview
- A complete examination of how quantization can cut back the computational calls for of Giant Language Fashions (LLMs) with out considerably compromising their efficiency.
- Tracing the speedy developments in LLMs and the ensuing challenges posed by their substantial measurement and useful resource necessities.
- An exploration of quantization as a way to discretize steady values, specializing in its software in lowering LLM complexity.
- An in depth take a look at totally different quantization strategies, together with post-training quantization and quantization-aware coaching, and their impression on mannequin efficiency.
- Highlighting the potential of quantized LLMs in numerous domains like edge computing, cell functions, and autonomous methods.
- Discussing the trade-offs, {hardware} concerns, and the necessity for continued analysis to reinforce the effectivity and applicability of LLM quantization.
Introduction of Giant Language Mannequin
The appearance of LLMs has marked a big leap in pure language processing, enabling groundbreaking functions in numerous fields. Nevertheless, resulting from their immense measurement and computational depth, deploying these fashions on resource-constrained gadgets stays a formidable problem. Quantization, a way to scale back mannequin complexity whereas preserving efficiency, presents a promising avenue to deal with this limitation.
This paper comprehensively explores LLM quantization, encompassing its theoretical underpinnings, sensible implementation, and real-world functions. By delving into the nuances of various quantization strategies, their impression on mannequin efficiency, and the challenges related to their deployment, we intention to supply a holistic understanding of this essential method.
LLM Quantization: A Deep Dive
Understanding Quantization
Quantization is a means of mapping steady values to discrete representations, usually with a decrease bit-width. Within the context of LLMs, it entails lowering the precision of weights and activations from floating-point to lower-bit integer or fixed-point codecs. This discount results in smaller mannequin sizes, sooner inference speeds, and decreased reminiscence footprint.
Quantization Methods
- Publish-training Quantization:
- Uniform quantization: Maps floating-point values to a hard and fast variety of quantization ranges.
- Idea: Maps a steady vary of floating-point values to a hard and fast set of discrete quantization ranges.
Visible Illustration
Clarification: Divide the floating-point values into equal-sized bins and map every worth to the midpoint of its corresponding bin. The variety of bins determines the quantization degree (e.g., 8-bit quantization has 256 ranges). This technique is straightforward however can result in quantization errors, particularly for distributions with lengthy tails.

steady quantity line (floatingpoint values) with evenly spaced quantization ranges beneath it. Arrows point out the mapping of floatingpoint values to their nearest quantization degree.
Clarification:
- The continual vary of floating-point values is split into equal intervals.
- A single quantization degree represents every interval.
- Values inside an interval are rounded to the closest quantization degree.
- Dynamic quantization: Adapts quantization parameters throughout inference based mostly on enter statistics.
- Idea: Adapt quantization parameters based mostly on enter statistics throughout inference.

Clarification: Not like uniform quantization, dynamic quantization adjusts the quantization vary based mostly on the precise values encountered throughout inference. This will enhance accuracy however requires extra computational overhead.
- Weight clustering: Teams weights into clusters and represents every cluster with a central worth.
- Idea: Teams are weighted into clusters and signify every cluster with a central worth.

Clarification: Weights are clustered based mostly on their values. A central worth represents every cluster, and the unique weights are changed with their corresponding cluster facilities. This reduces the variety of distinctive weights within the mannequin, resulting in reminiscence financial savings and potential computational effectivity positive aspects.
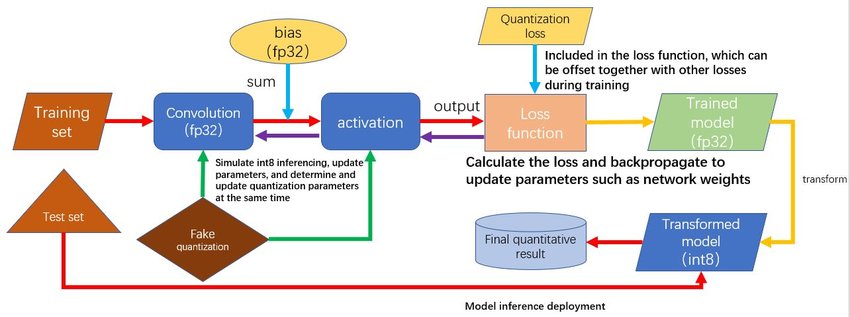
- Quantization-Conscious Coaching (QAT):
- Integrates quantization into the coaching course of, resulting in improved efficiency.
- Methods embrace simulated quantization, straight-through estimator (STE), and differentiable quantization.
Additionally learn: What are Giant Language Fashions(LLMs)?
Affect of Quantization on Mannequin Efficiency
Quantization inevitably introduces some efficiency degradation. Nevertheless, the extent of this degradation relies on a number of elements:
- Mannequin Structure: Deeper and wider fashions are typically extra resilient to quantization.
- Dataset Dimension and Complexity: Bigger and extra complicated datasets can mitigate efficiency loss.
- Quantization Bitwidth: Decrease bitwidths lead to bigger efficiency drops.
- Quantization Technique: The selection of quantization technique considerably impacts efficiency.
Analysis Metrics
To evaluate the impression of quantization, numerous metrics are employed:
- Accuracy: Measures the mannequin’s efficiency on a given activity (e.g., classification accuracy, BLEU rating).
- Mannequin Dimension: Quantifies the discount in mannequin measurement.
- Inference Pace: Evaluates the speedup achieved by quantization.
- Vitality Consumption: Measures the ability effectivity of the quantized mannequin.
Additionally learn: Newbie’s Information to Construct Giant Language Fashions from Scratch
Use Circumstances of Quantized LLMs
Quantized LLMs have the potential to revolutionize quite a few functions:
- Edge Computing: Deploying LLMs on resource-constrained gadgets for real-time functions.
- Cellular Functions: Enhancing the efficiency and effectivity of cell apps.
- Web of Issues (IoT): Enabling clever capabilities on IoT gadgets.
- Autonomous Methods: Decreasing computational prices for real-time decision-making.
- Pure Language Understanding (NLU): Accelerating NLU duties in numerous domains
Python Code Snippet that leverages PyTorch for lowering computational prices in real-time decision-making for autonomous methods use case:
# PyTorch Mannequin
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import fashions, transforms
from torch.utils.information import DataLoader
# Step 1: Outline the Mannequin
class AutonomousModel(nn.Module):
def __init__(self, num_classes=10):
tremendous(AutonomousModel, self).__init__()
# Utilizing a pre-trained MobileNetV2 mannequin for effectivity
self.mannequin = fashions.mobilenet_v2(pretrained=True)
# Exchange the final layer with a layer matching the variety of courses
self.mannequin.classifier[1] = nn.Linear(self.mannequin.last_channel, num_classes)
def ahead(self, x):
return self.mannequin(x)
# Step 2: Outline Information Transformation and DataLoader
# Use a easy transformation with normalization and resizing
rework = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# Assuming you may have a dataset for autonomous system enter (e.g., photos from sensors)
# dataset = YourDataset(rework=rework)
# dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# Step 3: Initialize Mannequin, Loss Perform, and Optimizer
mannequin = AutonomousModel(num_classes=10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(mannequin.parameters(), lr=0.001)
# Step 4: Quantization Preparation
# This step is essential for lowering computational prices
mannequin.fuse_model() # Fuse Conv2d + BatchNorm2d + ReLU layers
mannequin.qconfig = torch.quantization.get_default_qconfig('fbgemm') # Choose quantization configuration
torch.quantization.put together(mannequin, inplace=True)
# Step 5: Prepare or Nice-tune the Mannequin
# Be aware: For the sake of simplicity, we skip the coaching loop and assume the mannequin is already educated
# Step 6: Convert the Mannequin to a Quantized Model
torch.quantization.convert(mannequin, inplace=True)
# Step 7: Inference with Quantized Mannequin
# The quantized mannequin is now a lot sooner and lighter for real-time decision-making
mannequin.eval()
with torch.no_grad():
# Instance enter tensor representing sensor information
example_input = torch.randn(1, 3, 224, 224) # Batch measurement of 1, 3 channels, 224x224 picture
output = mannequin(example_input)
# Make choice based mostly on the output
choice = torch.argmax(output, dim=1)
print(f"Resolution: {choice.merchandise()}")
# Save the quantized mannequin for deployment
torch.save(mannequin.state_dict(), 'quantized_autonomous_model.pth')Clarification:
- Mannequin Definition:
- We use a pre-trained MobileNetV2, which is environment friendly for embedded methods and real-time functions.
- The final layer is changed to match the variety of courses for the precise activity.
- Information Transformation:
- Remodel the enter information right into a format appropriate for the mannequin, together with resizing and normalization.
- Quantization Preparation:
- Mannequin Fusion: Layers like Conv2d, BatchNorm2d, and ReLU are fused to scale back computation.
- Quantization Configuration: We choose a quantization configuration (fbgemm) optimized for x86 CPUs.
- Mannequin Conversion:
- After getting ready the mannequin, we convert it to its quantized model, considerably lowering its measurement and enhancing inference velocity.
- Inference:
- The quantized mannequin is used to make real-time choices. Inference is carried out on a pattern enter, and the output is used for decision-making.
- Saving the Mannequin:
- The quantized mannequin is saved for deployment, guaranteeing the system can function effectively in actual time.
Additionally learn: A Survey of Giant Language Fashions (LLMs)
Challenges of LLM Quantization
Regardless of its potential, LLM quantization faces a number of challenges:
- Efficiency-Accuracy Commerce-off: Balancing mannequin measurement discount with efficiency degradation.
- {Hardware} Acceleration: Creating specialised {hardware} for environment friendly quantization operations.
- Quantization for Particular Duties: Tailoring quantization methods for various duties and domains.
Future analysis ought to concentrate on:
- Creating novel quantization methods with minimal efficiency loss.
- Exploring hardware-software co-design for optimized quantization.
- Investigating the impression of quantization on totally different LLM architectures.
- Quantifying the environmental advantages of LLM quantization.
Conclusion
LLM quantization is essential for deploying large-scale language fashions on resource-constrained platforms. By rigorously contemplating quantization strategies, analysis metrics, and software necessities, practitioners can successfully leverage this method to realize optimum efficiency and effectivity. As analysis on this space progresses, we will anticipate even higher developments in LLM quantization, unlocking new potentialities for AI functions throughout numerous domains.
Incessantly Requested Questions
Ans. LLM Quantization reduces the precision of mannequin weights and activations to lower-bit codecs, making fashions smaller, sooner, and extra memory-efficient.
Ans. The first strategies are Publish-Coaching Quantization (uniform and dynamic) and Quantization-Conscious Coaching (QAT).
Ans. Challenges embrace balancing efficiency and accuracy, the necessity for specialised {hardware}, and task-specific quantization methods.
Ans. Quantization can degrade efficiency, however the impression varies with mannequin structure, dataset complexity, and the bitwidth used.