Introduction
Retrieval Augmented Technology techniques, higher generally known as RAG techniques, have turn out to be the de-facto customary for constructing clever AI assistants answering questions on customized enterprise information with out the hassles of high-priced fine-tuning of huge language fashions (LLMs). One of many key benefits of RAG techniques is you may simply combine your personal information and increase your LLM’s intelligence, and provides extra contextual solutions to your questions. Nevertheless, the important thing limitation of most RAG techniques is that it really works properly solely on textual content information. Nevertheless, lots of real-world information is multimodal in nature, which implies a mix of textual content, photographs, tables, and extra. On this complete hands-on information, we’ll take a look at constructing a Multimodal RAG System that may deal with combined information codecs utilizing clever information transformations and multimodal LLMs.

Overview
- Retrieval Augmented Technology (RAG) techniques allow clever AI assistants to reply questions on customized enterprise information with no need costly LLM fine-tuning.
- Conventional RAG techniques are constrained to textual content information, making them ineffective for multimodal information, which incorporates textual content, photographs, tables, and extra.
- These techniques combine multimodal information processing (textual content, photographs, tables) and make the most of multimodal LLMs, like GPT-4o, to offer extra contextual and correct solutions.
- Multimodal Massive Language Fashions (LLMs) like GPT-4o, Gemini, and LLaVA-NeXT can course of and generate responses from a number of information codecs, dealing with combined inputs like textual content and pictures.
- The information gives an in depth information on constructing a Multimodal RAG system with LangChain, integrating clever doc loaders, vector databases, and multi-vector retrievers.
- The information reveals how you can course of advanced multimodal queries by using multimodal LLMs and clever retrieval techniques, creating superior AI techniques able to answering various data-driven questions.
Conventional RAG System Structure
A retrieval augmented era (RAG) system structure sometimes consists of two main steps:
- Knowledge Processing and Indexing
- Retrieval and Response Technology
In Step 1, Knowledge Processing and Indexing, we deal with getting our customized enterprise information right into a extra consumable format by loading sometimes the textual content content material from these paperwork, splitting giant textual content parts into smaller chunks, changing them into embeddings utilizing an embedder mannequin after which storing these chunks and embeddings right into a vector database as depicted within the following determine.
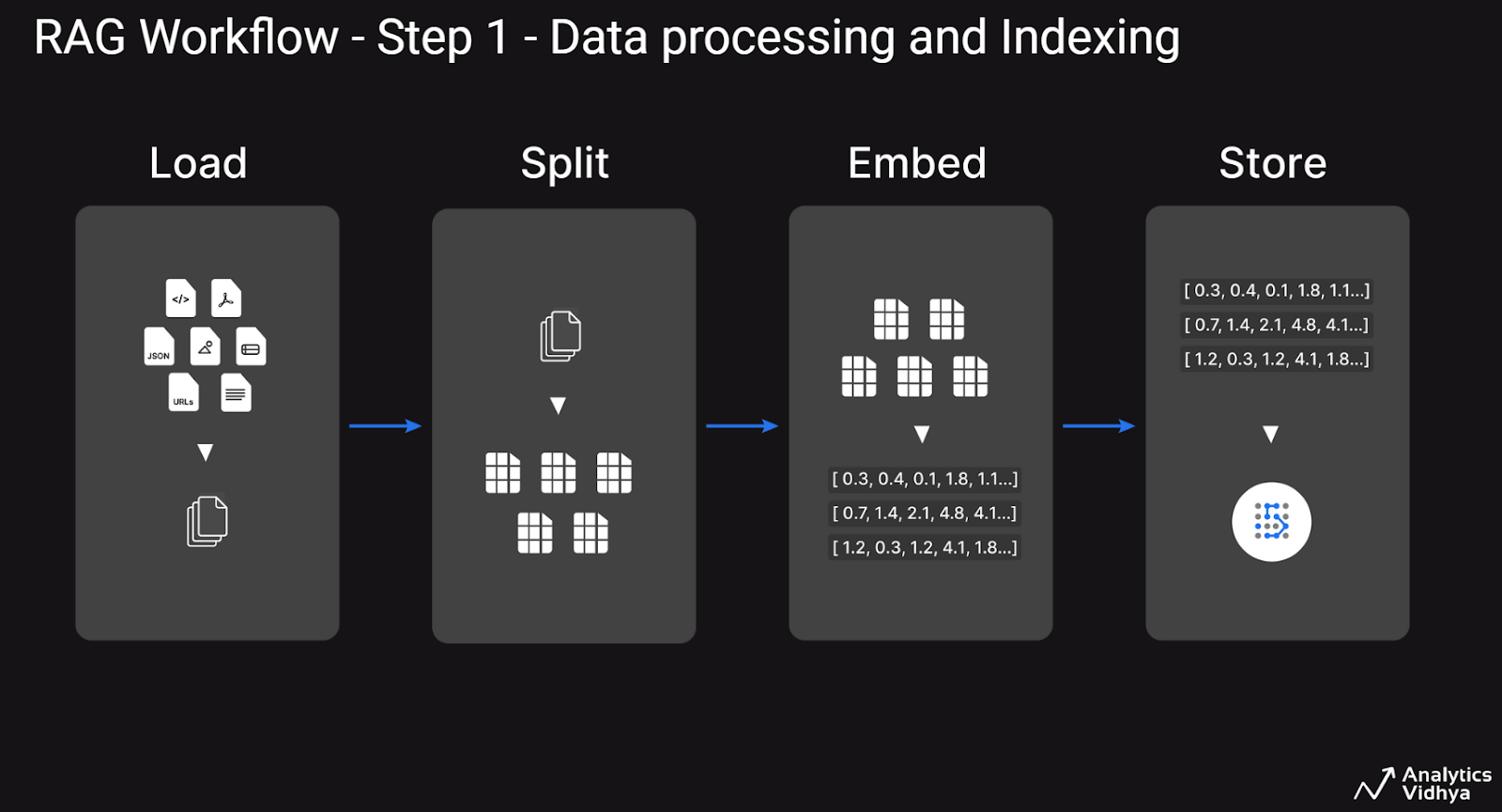
In Step 2, the workflow begins with the consumer asking a query, related textual content doc chunks that are much like the enter query are retrieved from the vector database after which the query and the context doc chunks are despatched to an LLM to generate a human-like response as depicted within the following determine.
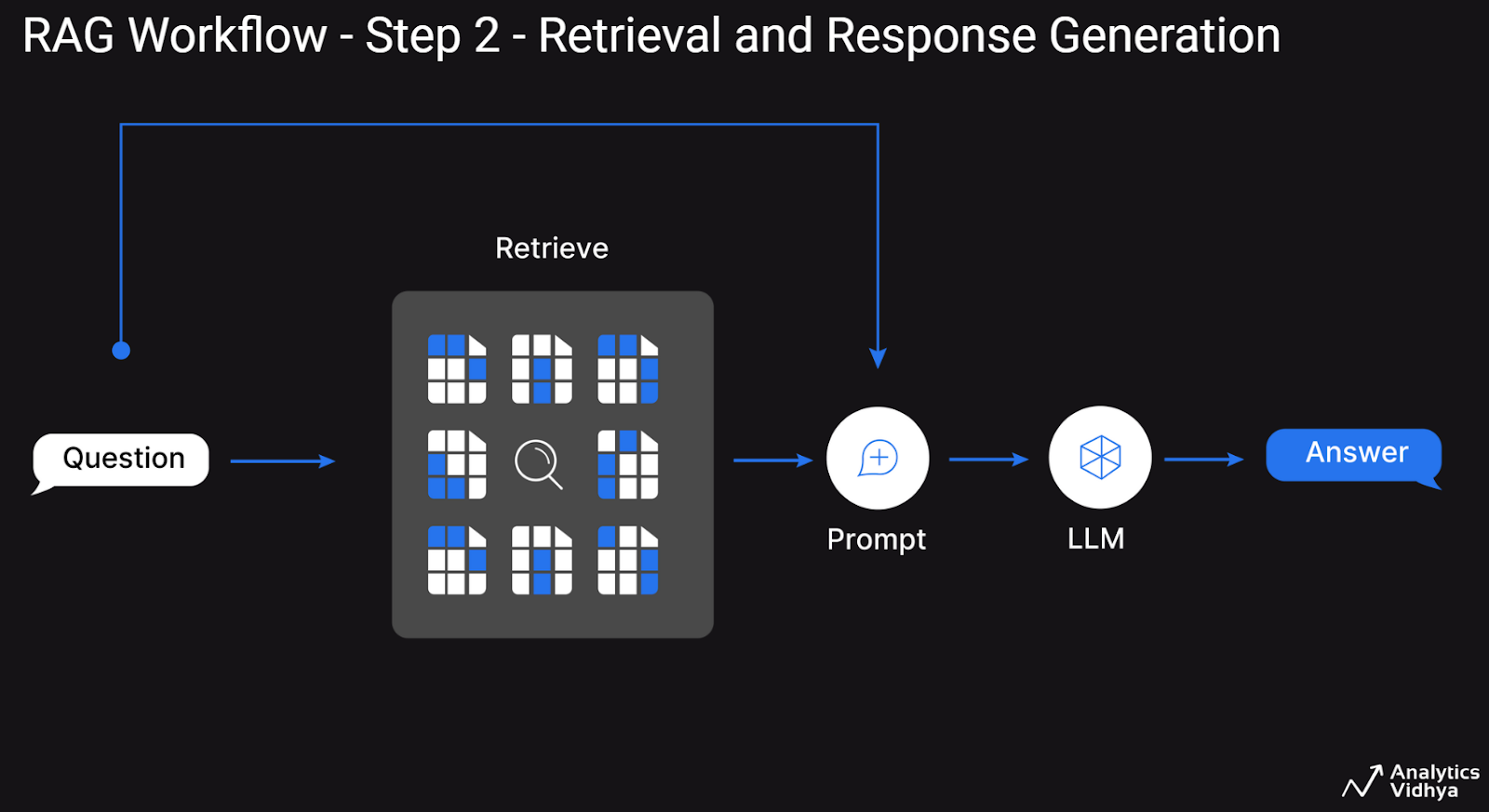
This two-step workflow is often used within the trade to construct a conventional RAG system; nevertheless, it does have its personal set of limitations, a few of which we talk about under intimately.
Conventional RAG System limitations
Conventional RAG techniques have a number of limitations, a few of that are talked about as follows:
- They don’t seem to be aware of real-time information
- The system is nearly as good as the info you’ve in your vector database
- Most RAG techniques solely work on textual content information for each retrieval and era
- Conventional LLMs can solely course of textual content content material to generate solutions
- Unable to work with multimodal information
On this article, we’ll focus notably on fixing the restrictions of conventional RAG techniques when it comes to their incapacity to work with multimodal content material, in addition to conventional LLMs, which may solely cause and analyze textual content information to generate responses. Earlier than diving into multimodal RAG techniques, let’s first perceive what Multimodal information is.
What’s Multimodal Knowledge?
Multimodal information is actually information belonging to a number of modalities. The formal definition of modality comes from the context of Human-Laptop Interplay (HCI) techniques, the place a modality is termed because the classification of a single impartial channel of enter and output between a pc and human (extra particulars on Wikipedia). Frequent Laptop-Human modalities embody the next:
- Textual content: Enter and output via written language (e.g., chat interfaces).
- Speech: Voice-based interplay (e.g., voice assistants).
- Imaginative and prescient: Picture and video processing for visible recognition (e.g., face detection).
- Gestures: Hand and physique motion monitoring (e.g., gesture controls).
- Contact: Haptic suggestions and touchscreens.
- Audio: Sound-based indicators (e.g., music recognition, alerts).
- Biometrics: Interplay via physiological information (e.g., eye-tracking, fingerprints).
In brief, multimodal information is actually information that has a mix of modalities or codecs, as seen within the pattern doc under, with a number of the distinct codecs highlighted in varied colours.
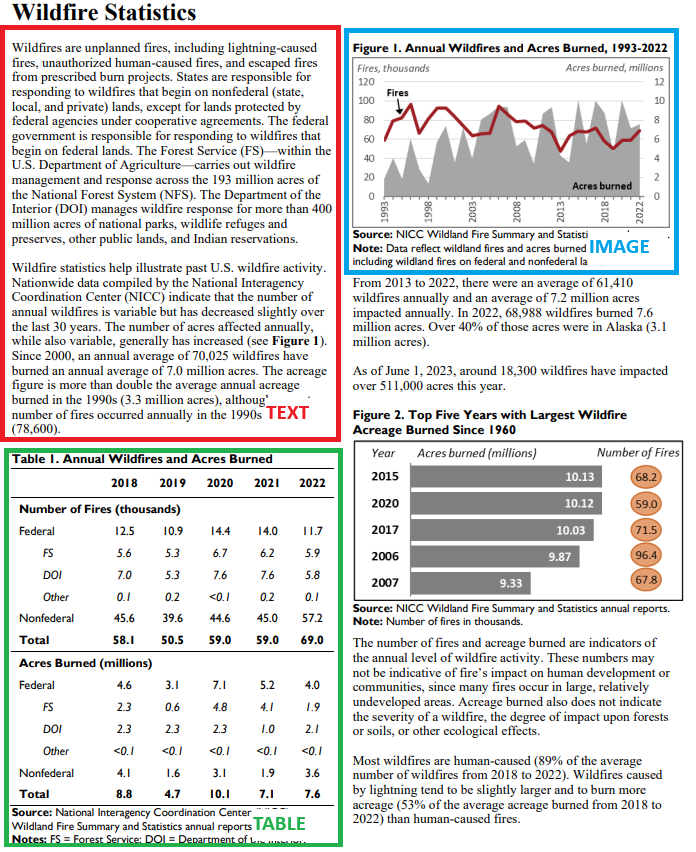
The important thing focus right here is to construct a RAG system that may deal with paperwork with a mix of information modalities, corresponding to textual content, photographs, tables, and perhaps even audio and video, relying in your information sources. This information will deal with dealing with textual content, photographs, and tables. One of many key parts wanted to know such information is multimodal giant language fashions (LLMs).
What’s a Multimodal Massive Language Mannequin?
Multimodal Massive Language Fashions (LLMs) are basically transformer-based LLMs which have been pre-trained and fine-tuned on multimodal information to investigate and perceive varied information codecs, together with textual content, photographs, tables, audio, and video. A real multimodal mannequin ideally ought to have the opportunity not simply to know combined information codecs but in addition generate the identical as proven within the following workflow illustration of NExT-GPT, printed as a paper, NExT-GPT: Any-to-Any Multimodal Massive Language Mannequin
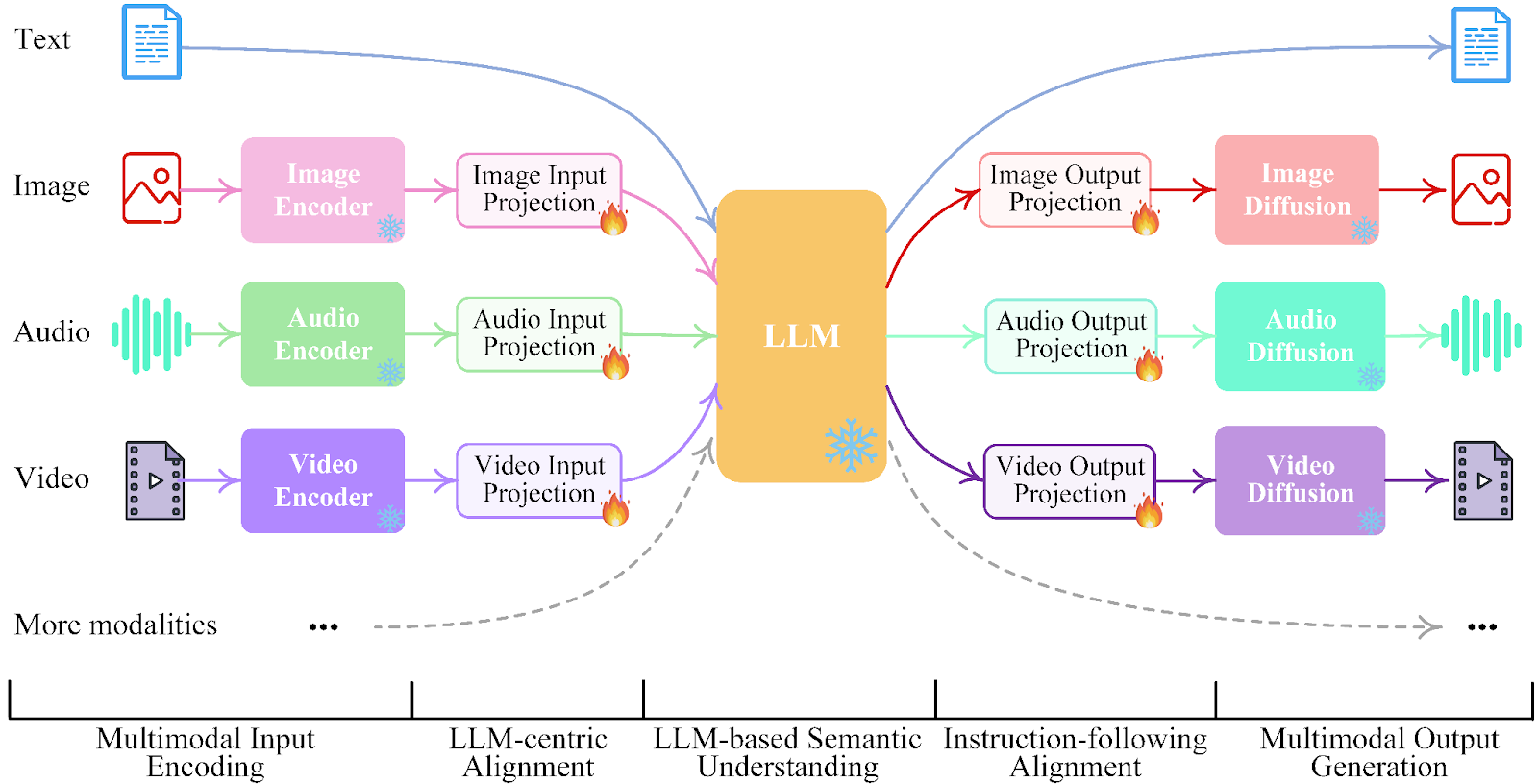
From the paper on NExT-GPT, any true multimodal mannequin would sometimes have the next levels:
- Multimodal Encoding Stage. Leveraging current well-established fashions to encode inputs of varied modalities.
- LLM Understanding and Reasoning Stage. An LLM is used because the core agent of NExT-GPT. Technically, they make use of the Vicuna LLM which takes as enter the representations from totally different modalities and carries out semantic understanding and reasoning over the inputs. It outputs 1) the textual responses straight and a pair of) sign tokens of every modality that function directions to dictate the decoding layers whether or not to generate multimodal content material and what content material to provide if sure.
- Multimodal Technology Stage. Receiving the multimodal indicators with particular directions from LLM (if any), the Transformer-based output projection layers map the sign token representations into those which might be comprehensible to following multimodal decoders. Technically, they make use of the present off-the-shelf latent conditioned diffusion fashions of various modal generations, i.e., Secure Diffusion (SD) for picture synthesis, Zeroscope for video synthesis, and AudioLDM for audio synthesis.
Nevertheless, most present Multimodal LLMs accessible for sensible use are one-sided, which implies they’ll perceive combined information codecs however solely generate textual content responses. The most well-liked business multimodal fashions are as follows:
- GPT-4V & GPT-4o (OpenAI): GPT-4o can perceive textual content, photographs, audio, and video, though audio and video evaluation are nonetheless not open to the general public.
- Gemini (Google): A multimodal LLM from Google with true multimodal capabilities the place it could possibly perceive textual content, audio, video, and pictures.
- Claude (Anthropic): A extremely succesful business LLM that features multimodal capabilities in its newest variations, corresponding to dealing with textual content and picture inputs.
You may also contemplate open or open-source multimodal LLMs in case you need to construct a very open-source resolution or have considerations on information privateness or latency and like to host the whole lot regionally in-house. The most well-liked open and open-source multimodal fashions are as follows:
- LLaVA-NeXT: An open-source multimodal mannequin with capabilities to work with textual content, photographs and likewise video, which an enchancment on high of the favored LLaVa mannequin
- PaliGemma: A vision-language mannequin from Google that integrates each picture and textual content processing, designed for duties like optical character recognition (OCR), object detection, and visible query answering (VQA).
- Pixtral 12B: A sophisticated multimodal mannequin from Mistral AI with 12 billion parameters that may course of each photographs and textual content. Constructed on Mistral’s Nemo structure, Pixtral 12B excels in duties like picture captioning and object recognition.
For our Multimodal RAG System, we’ll leverage GPT-4o, some of the highly effective multimodal fashions presently accessible.
Multimodal RAG System Workflow
On this part, we’ll discover potential methods to construct the structure and workflow of a multimodal RAG system. The next determine illustrates potential approaches intimately and highlights the one we’ll use on this information.
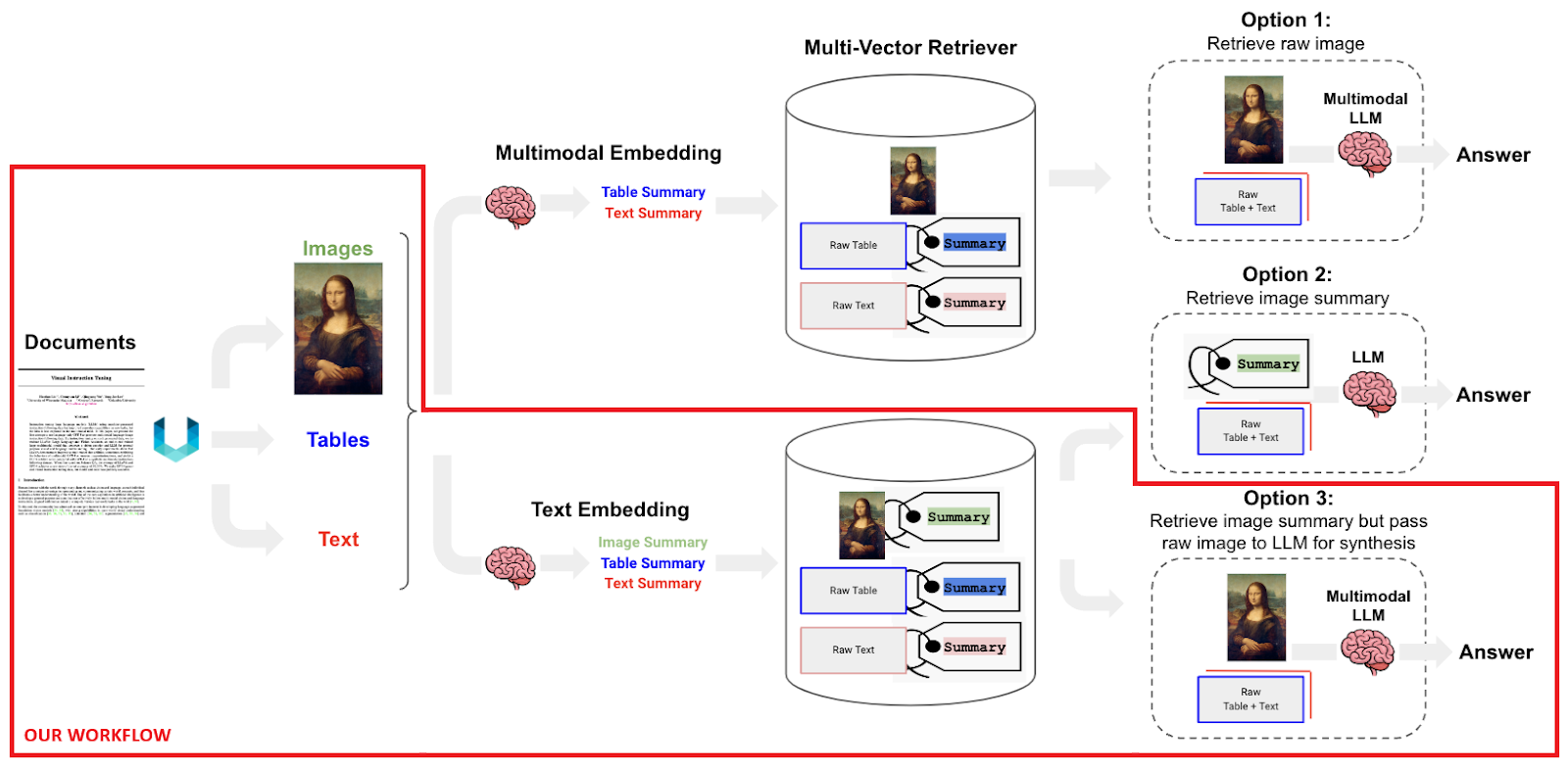
Finish-to-Finish Workflow
Multimodal RAG Techniques might be applied in varied methods, the above determine illustrates three attainable workflows as beneficial within the LangChain weblog, this embody:
- Choice 1: Use multimodal embeddings (corresponding to CLIP) to embed photographs and textual content collectively. Retrieve both utilizing similarity search, however merely hyperlink to pictures in a docstore. Cross uncooked photographs and textual content chunks to a multimodal LLM for synthesis.
- Choice 2: Use a multimodal LLM (corresponding to GPT-4o, GPT4-V, LLaVA) to provide textual content summaries from photographs. Embed and retrieve textual content summaries utilizing a textual content embedding mannequin. Once more, reference uncooked textual content chunks or tables from a docstore for reply synthesis by a daily LLM; on this case, we exclude photographs from the docstore.
- Choice 3: Use a multimodal LLM (corresponding to GPT-4o, GPT4-V, LLaVA) to provide textual content, desk and picture summaries (textual content chunk summaries are optionally available). Embed and retrieved textual content, desk, and picture summaries just about the uncooked parts, as we did above in possibility 1. Once more, uncooked photographs, tables, and textual content chunks shall be handed to a multimodal LLM for reply synthesis. This feature is smart if we don’t need to use multimodal embeddings, which don’t work properly when working with photographs which might be extra charts and visuals. Nevertheless, we will additionally use multimodal embedding fashions right here to embed photographs and abstract descriptions collectively if obligatory.
There are limitations in Choice 1 as we can’t use photographs, that are charts and visuals, which is commonly the case with lots of paperwork. The reason being that multimodal embedding fashions can’t usually encode granular info like numbers in these visible photographs and compress them into significant embedding. Choice 2 is severely restricted as a result of we don’t find yourself utilizing photographs in any respect on this system even when it would comprise helpful info and it isn’t actually a multimodal RAG system.
Therefore, we’ll proceed with Choice 3 as our Multimodal RAG System workflow. On this workflow, we’ll create summaries out of our photographs, tables, and, optionally, our textual content chunks and use a multi-vector retriever, which might help in mapping and retrieving the unique picture, desk, and textual content parts primarily based on their corresponding summaries.
Multi-Vector Retrieval Workflow
Contemplating the workflow we’ll implement as mentioned within the earlier part, for our retrieval workflow, we shall be utilizing a multi-vector retriever as depicted within the following illustration, as beneficial and talked about within the LangChain weblog. The important thing objective of the multi-vector retriever is to behave as a wrapper and assist in mapping each textual content chunk, desk, and picture abstract to the precise textual content chunk, desk, and picture aspect, which may then be obtained throughout retrieval.
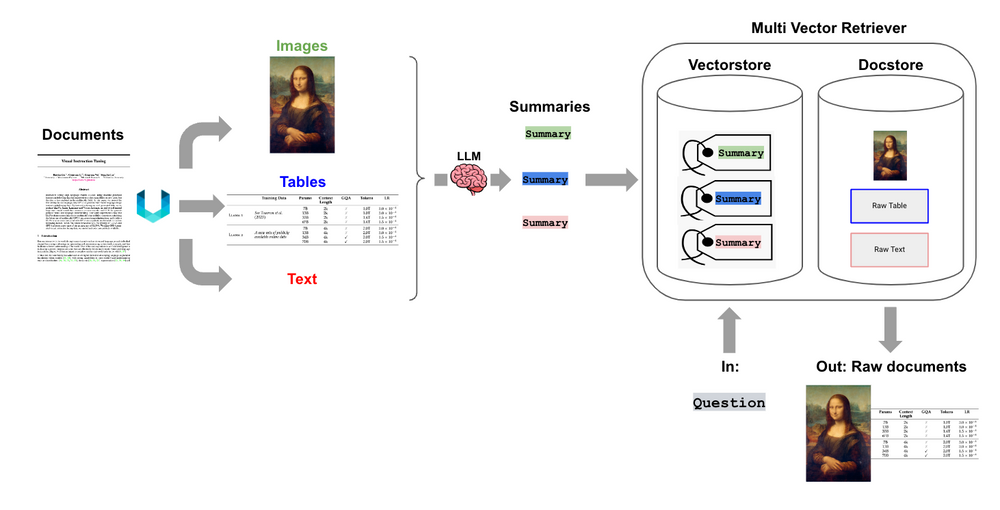
The workflow illustrated above will first use a doc parsing software like Unstructured to extract the textual content, desk and picture parts individually. Then we’ll go every extracted aspect into an LLM and generate an in depth textual content abstract as depicted above. Subsequent we’ll retailer the summaries and their embeddings right into a vector database by utilizing any in style embedder mannequin like OpenAI Embedders. We will even retailer the corresponding uncooked doc aspect (textual content, desk, picture) for every abstract in a doc retailer, which might be any database platform like Redis.
The multi-vector retriever hyperlinks every abstract and its embedding to the unique doc’s uncooked aspect (textual content, desk, picture) utilizing a typical doc identifier (doc_id). Now, when a consumer query is available in, first, the multi-vector retriever retrieves the related summaries, that are much like the query when it comes to semantic (embedding) similarity, after which utilizing the frequent doc_ids, the unique textual content, desk and picture parts are returned again that are additional handed on to the RAG system’s LLM because the context to reply the consumer query.
Detailed Multimodal RAG System Structure
Now, let’s dive deep into the detailed system structure of our multimodal RAG system. We are going to perceive every element on this workflow and what occurs step-by-step. The next illustration depicts this structure intimately.
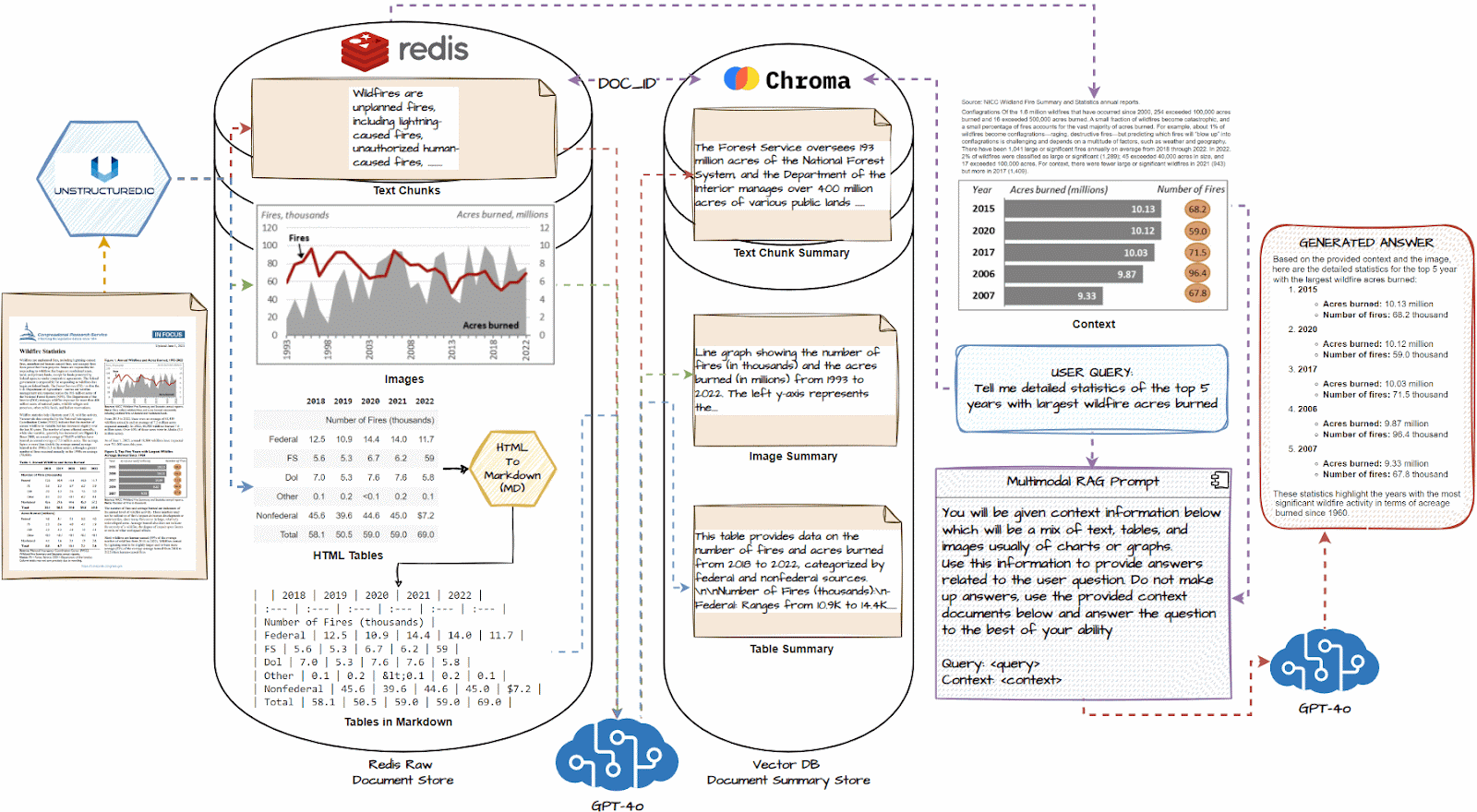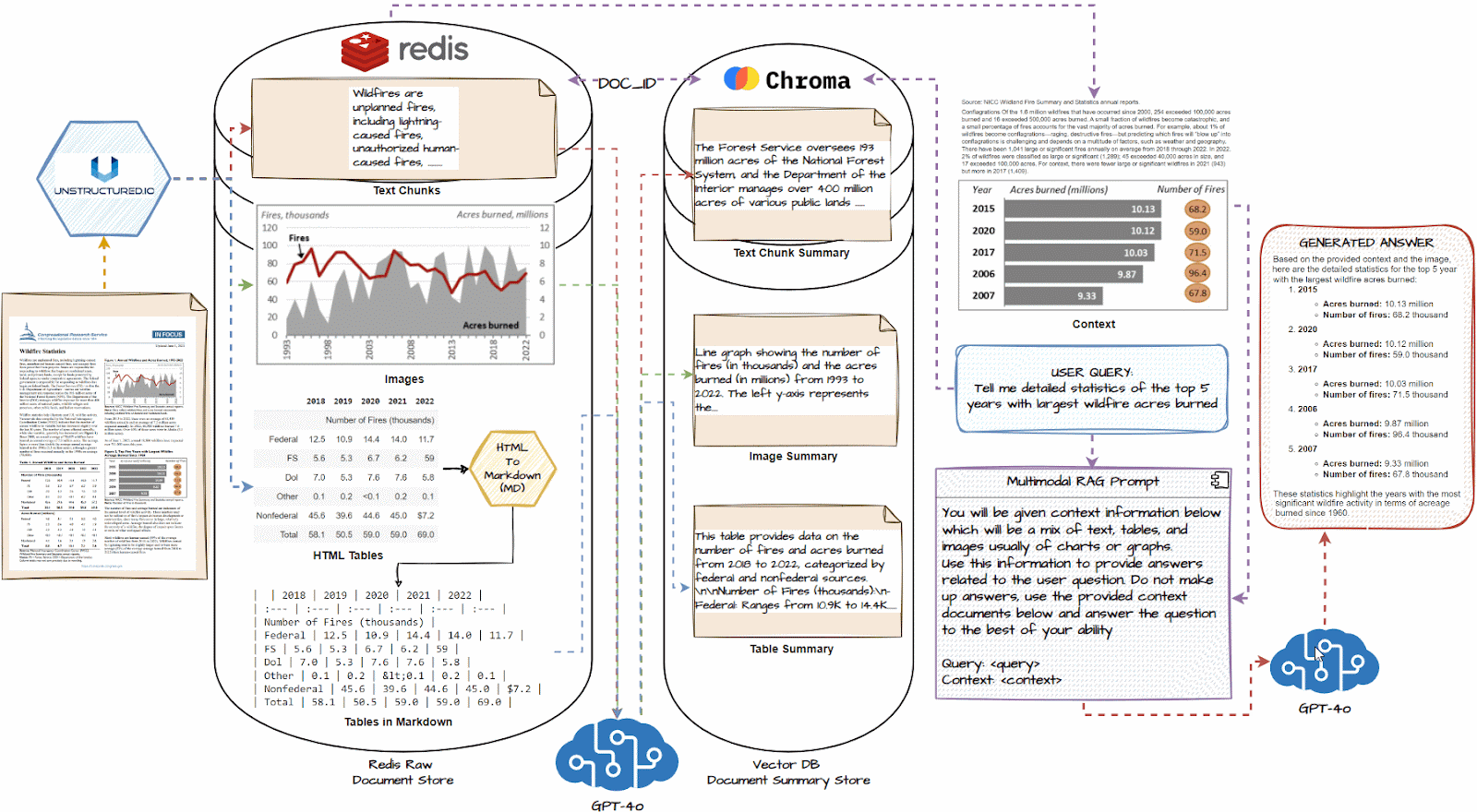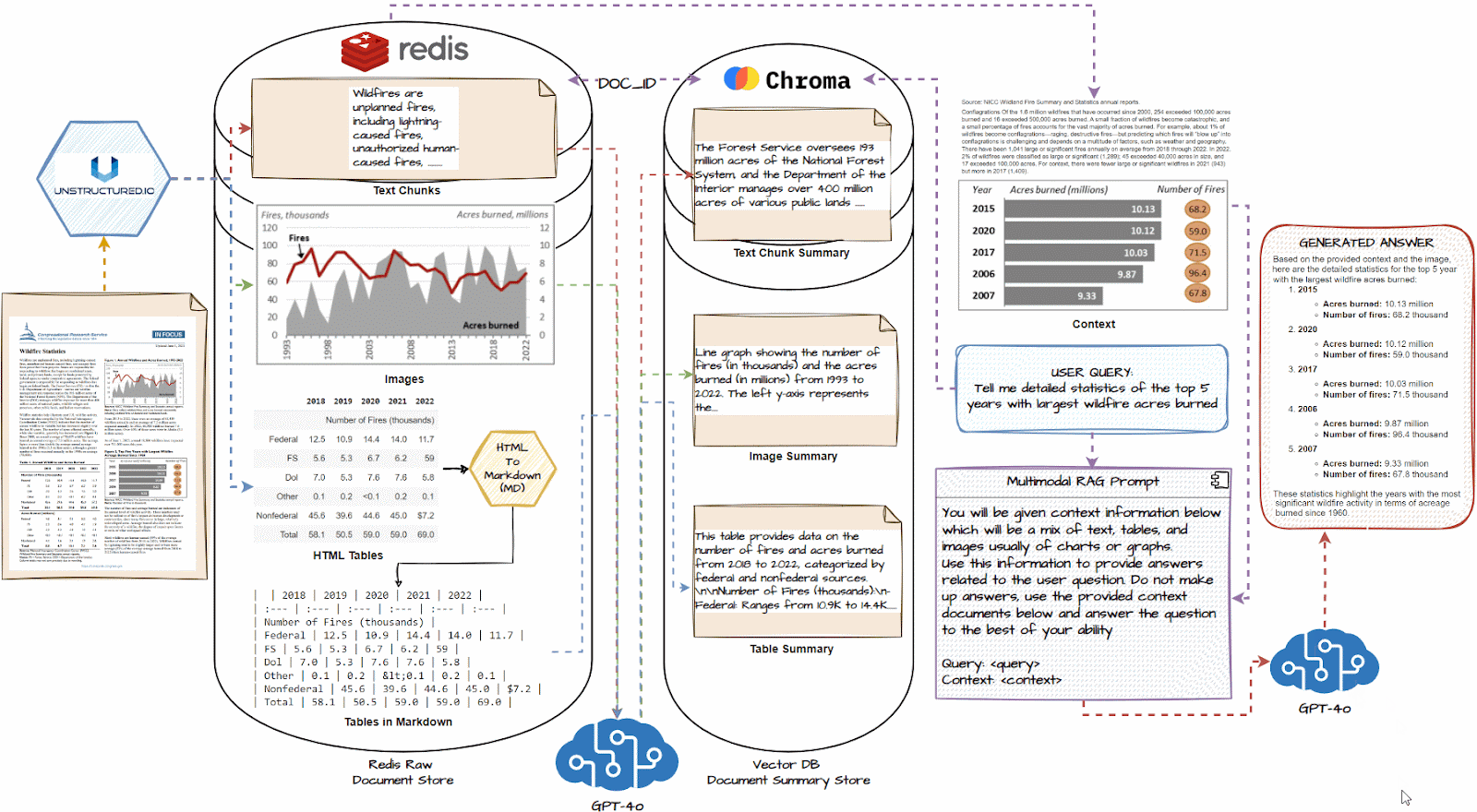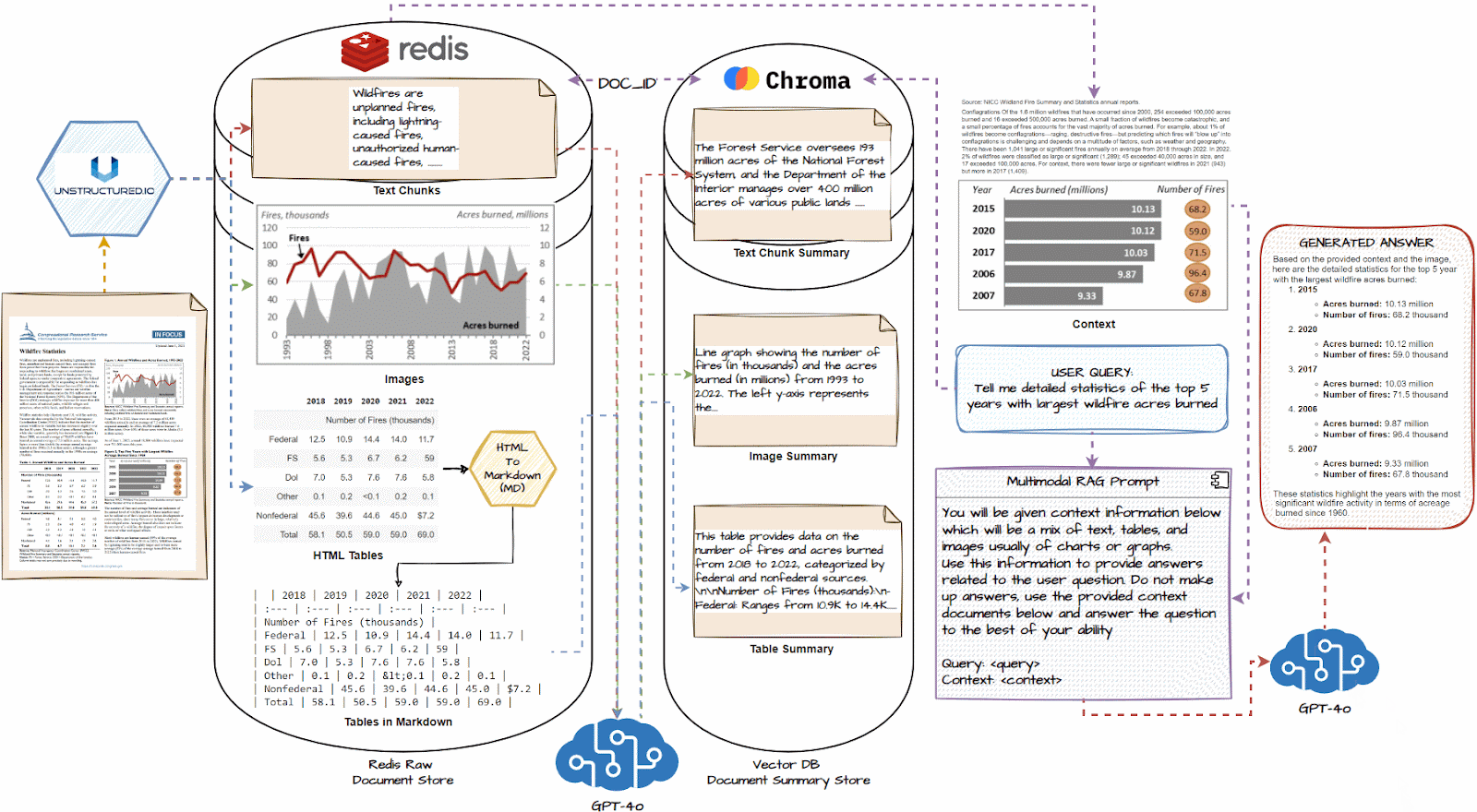
We are going to now talk about the important thing steps of the above-illustrated multimodal RAG System and the way it will work. The workflow is as follows:
- Load all paperwork and use a doc loader like unstructured.io to extract textual content chunks, picture, and tables.
- If obligatory, convert HTML tables to markdown; they’re usually very efficient with LLMs
- Cross every textual content chunk, picture, and desk right into a multimodal LLM like GPT-4o and get an in depth abstract.
- Retailer summaries in a vector DB and the uncooked doc items in a doc DB like Redis
- Join the 2 databases with a typical document_id utilizing a multi-vector retriever to establish which abstract maps to which uncooked doc piece.
- Join this multi-vector retrieval system with a multimodal LLM like GPT-4o.
- Question the system, and primarily based on comparable summaries to the question, get the uncooked doc items, together with tables and pictures, because the context.
- Utilizing the above context, generate a response utilizing the multimodal LLM for the query.
It’s not too difficult when you see all of the parts in place and construction the circulate utilizing the above steps! Let’s implement this method now within the subsequent part.
Palms-on Implementation of our Multimodal RAG System
We are going to now implement the Multimodal RAG System we have now mentioned thus far utilizing LangChain. We shall be loading the uncooked textual content, desk and picture parts from our paperwork into Redis and the aspect summaries and their embeddings in our vector database which would be the Chroma database and join them collectively utilizing a multi-vector retriever. Connections to LLMs and prompting shall be finished with LangChain. For our multimodal LLM, we shall be utilizing ChatGPT GPT-4o which is a strong multimodal LLM. Nevertheless you’re free to make use of another multimodal LLM additionally together with open-source choices which we talked about earlier, however it’s endorsed to make use of a strong multimodal LLM, which may perceive photographs, desk and textual content properly to generate good summaries and likewise responses.
Set up Dependencies
We begin by putting in the mandatory dependencies, that are going to be the libraries we shall be utilizing to construct our system. This consists of langchain, unstructured in addition to obligatory dependencies like openai, chroma and utilities for information processing and extraction of tables and pictures.
!pip set up langchain
!pip set up langchain-openai
!pip set up langchain-chroma
!pip set up langchain-community
!pip set up langchain-experimental
!pip set up "unstructured[all-docs]"
!pip set up htmltabletomd
# set up OCR dependencies for unstructured
!sudo apt-get set up tesseract-ocr
!sudo apt-get set up poppler-utilsDownloading Knowledge
We downloaded a report on wildfire statistics within the US from the Congressional Analysis Service Reviews Web page which gives open entry to detailed stories. This doc has a mix of textual content, tables and pictures as proven within the Multimodal Knowledge part above. We are going to construct a easy Chat to my PDF software right here utilizing our multimodal RAG System however you may simply prolong this to a number of paperwork additionally.
!wget https://sgp.fas.org/crs/misc/IF10244.pdfOUTPUT
--2024-08-18 10:08:54-- https://sgp.fas.org/crs/misc/IF10244.pdf
Connecting to sgp.fas.org (sgp.fas.org)|18.172.170.73|:443... linked.
HTTP request despatched, awaiting response... 200 OK
Size: 435826 (426K) [application/pdf]
Saving to: ‘IF10244.pdf’
IF10244.pdf 100%[===================>] 425.61K 732KB/s in 0.6s
2024-08-18 10:08:55 (732 KB/s) - ‘IF10244.pdf’ saved [435826/435826]
Extracting Doc Components with Unstructured
We are going to now use the unstructured library, which gives open-source parts for ingesting and pre-processing photographs and textual content paperwork, corresponding to PDFs, HTML, Phrase docs, and extra. We are going to use it to extract and chunk textual content parts and extract tables and pictures individually utilizing the next code snippet.
from langchain_community.document_loaders import UnstructuredPDFLoader
doc="./IF10244.pdf"
# takes 1 min on Colab
loader = UnstructuredPDFLoader(file_path=doc,
technique='hi_res',
extract_images_in_pdf=True,
infer_table_structure=True,
# section-based chunking
chunking_strategy="by_title",
max_characters=4000, # max dimension of chunks
new_after_n_chars=4000, # most well-liked dimension of chunks
# smaller chunks < 2000 chars shall be mixed into a bigger chunk
combine_text_under_n_chars=2000,
mode="parts",
image_output_dir_path="./figures")
information = loader.load()
len(information)OUTPUT
7
This tells us that unstructured has efficiently extracted seven parts from the doc and likewise downloaded the photographs individually within the `figures` listing. It has used section-based chunking to chunk textual content parts primarily based on part headings within the paperwork and a bit dimension of roughly 4000 characters. Additionally doc intelligence deep studying fashions have been used to detect and extract tables and pictures individually. We will take a look at the kind of parts extracted utilizing the next code.
[doc.metadata['category'] for doc in information]OUTPUT
['CompositeElement',
'CompositeElement',
'Table',
'CompositeElement',
'CompositeElement',
'Table',
'CompositeElement']
This tells us we have now some textual content chunks and tables in our extracted content material. We will now discover and take a look at the contents of a few of these parts.
# This can be a textual content chunk aspect
information[0]OUTPUT
Doc(metadata={'supply': './IF10244.pdf', 'filetype': 'software/pdf',
'languages': ['eng'], 'last_modified': '2024-04-10T01:27:48', 'page_number':
1, 'orig_elements': 'eJzF...eUyOAw==', 'file_directory': '.', 'filename':
'IF10244.pdf', 'class': 'CompositeElement', 'element_id':
'569945de4df264cac7ff7f2a5dbdc8ed'}, page_content="a. aa = Informing the
legislative debate since 1914 Congressional Analysis ServicennUpdated June
1, 2023nnWildfire StatisticsnnWildfires are unplanned fires, together with
lightning-caused fires, unauthorized human-caused fires, and escaped fires
from prescribed burn tasks. States are liable for responding to
wildfires that start on nonfederal (state, native, and personal) lands, besides
for lands protected by federal companies beneath cooperative agreements. The
federal authorities is liable for responding to wildfires that start on
federal lands. The Forest Service (FS)—inside the U.S. Division of
Agriculture—carries out wildfire administration ...... Over 40% of these acres
have been in Alaska (3.1 million acres).nnAs of June 1, 2023, round 18,300
wildfires have impacted over 511,000 acres this 12 months.")
The next snippet depicts one of many desk parts extracted.
# This can be a desk aspect
information[2]OUTPUT
Doc(metadata={'supply': './IF10244.pdf', 'last_modified': '2024-04-
10T01:27:48', 'text_as_html': '<desk><thead><tr><th></th><th>2018</th>
<th>2019</th><th>2020</th><th>2021</th><th>2022</th></tr></thead><tbody><tr>
<td colspan="6">Variety of Fires (hundreds)</td></tr><tr><td>Federal</td>
<td>12.5</td><td>10.9</td><td>14.4</td><td>14.0</td><td>11.7</td></tr><tr>
<td>FS</td>......<td>50.5</td><td>59.0</td><td>59.0</td><td>69.0</td></tr>
<tr><td colspan="6">Acres Burned (thousands and thousands)</td></tr><tr><td>Federal</td>
<td>4.6</td><td>3.1</td><td>7.1</td><td>5.2</td><td>40</td></tr><tr>
<td>FS</td>......<td>1.6</td><td>3.1</td><td>Lg</td><td>3.6</td></tr><tr>
<td>Complete</td><td>8.8</td><td>4.7</td><td>10.1</td><td>7.1</td><td>7.6</td>
</tr></tbody></desk>', 'filetype': 'software/pdf', 'languages': ['eng'],
'page_number': 1, 'orig_elements': 'eJylVW1.....AOBFljW', 'file_directory':
'.', 'filename': 'IF10244.pdf', 'class': 'Desk', 'element_id':
'40059c193324ddf314ed76ac3fe2c52c'}, page_content="2018 2019 2020 Variety of
Fires (hundreds) Federal 12.5 10......Nonfederal 4.1 1.6 3.1 1.9 Complete 8.8
4.7 10.1 7.1 <0.1 3.6 7.6")
We will see the textual content content material extracted from the desk utilizing the next code snippet.
print(information[2].page_content)OUTPUT
2018 2019 2020 Variety of Fires (hundreds) Federal 12.5 10.9 14.4 FS 5.6 5.3
6.7 DOI 7.0 5.3 7.6 2021 14.0 6.2 7.6 11.7 5.9 5.8 Different 0.1 0.2 <0.1 0.2
0.1 Nonfederal 45.6 39.6 44.6 45.0 57.2 Complete 58.1 Acres Burned (thousands and thousands)
Federal 4.6 FS 2.3 DOI 2.3 50.5 3.1 0.6 2.3 59.0 7.1 4.8 2.3 59.0 5.2 4.1
1.0 69.0 4.0 1.9 2.1 Different <0.1 <0.1 <0.1 <0.1 Nonfederal 4.1 1.6 3.1 1.9
Complete 8.8 4.7 10.1 7.1 <0.1 3.6 7.6
Whereas this may be fed into an LLM, the construction of the desk is misplaced right here so we will reasonably deal with the HTML desk content material itself and do some transformations later.
information[2].metadata['text_as_html']OUTPUT
<desk><thead><tr><th></th><th>2018</th><th>2019</th><th>2020</th>
<th>2021</th><th>2022</th></tr></thead><tbody><tr><td colspan="6">Variety of
Fires (hundreds)</td></tr><tr><td>Federal</td><td>12.5</td><td>10.9</td>
<td>14.4</td><td>14.0</td><td>11.7</td>......<td>45.6</td><td>39.6</td>
<td>44.6</td><td>45.0</td><td>$7.2</td></tr><tr><td>Complete</td><td>58.1</td>
<td>50.5</td><td>59.0</td><td>59.0</td><td>69.0</td></tr><tr><td
colspan="6">Acres Burned (thousands and thousands)</td></tr><tr><td>Federal</td>
<td>4.6</td><td>3.1</td><td>7.1</td><td>5.2</td><td>40</td></tr><tr>
<td>FS</td><td>2.3</td>......<td>1.0</td><td>2.1</td></tr><tr><td>Different</td>
We will view this as HTML as follows to see what it appears like.
show(Markdown(information[2].metadata['text_as_html']))OUTPUT
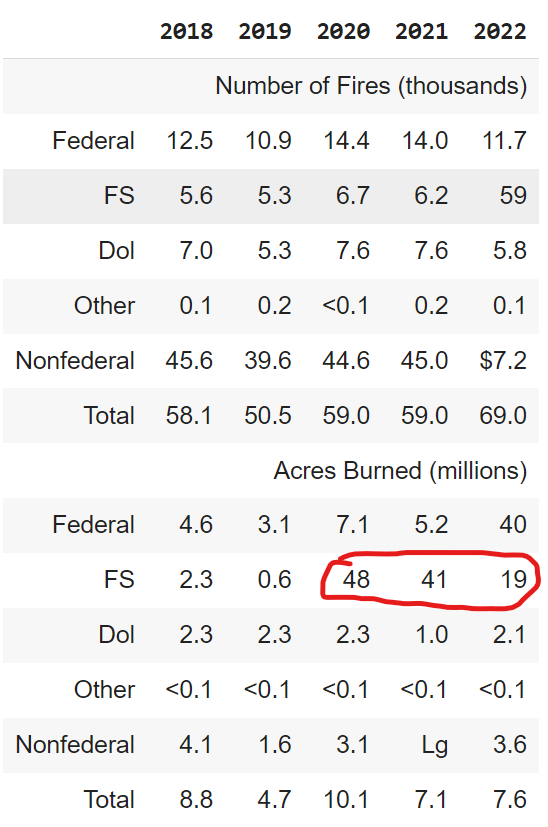
It does a reasonably good job right here in preserving the construction nevertheless a number of the extractions will not be appropriate however you may nonetheless get away with it when utilizing a strong LLM like GPT-4o which we’ll see later. One possibility right here is to make use of a extra highly effective desk extraction mannequin. Let’s now take a look at how you can convert this HTML desk into Markdown. Whereas we will use the HTML textual content and put it straight in prompts (LLMs perceive HTML tables properly) and even higher convert HTML tables to Markdown tables as depicted under.
import htmltabletomd
md_table = htmltabletomd.convert_table(information[2].metadata['text_as_html'])
print(md_table)OUTPUT
| | 2018 | 2019 | 2020 | 2021 | 2022 |
| :--- | :--- | :--- | :--- | :--- | :--- |
| Variety of Fires (hundreds) |
| Federal | 12.5 | 10.9 | 14.4 | 14.0 | 11.7 |
| FS | 5.6 | 5.3 | 6.7 | 6.2 | 59 |
| Dol | 7.0 | 5.3 | 7.6 | 7.6 | 5.8 |
| Different | 0.1 | 0.2 | <0.1 | 0.2 | 0.1 |
| Nonfederal | 45.6 | 39.6 | 44.6 | 45.0 | $7.2 |
| Complete | 58.1 | 50.5 | 59.0 | 59.0 | 69.0 |
| Acres Burned (thousands and thousands) |
| Federal | 4.6 | 3.1 | 7.1 | 5.2 | 40 |
| FS | 2.3 | 0.6 | 48 | 41 | 19 |
| Dol | 2.3 | 2.3 | 2.3 | 1.0 | 2.1 |
| Different | <0.1 | <0.1 | <0.1 | <0.1 | <0.1 |
| Nonfederal | 4.1 | 1.6 | 3.1 | Lg | 3.6 |
| Complete | 8.8 | 4.7 | 10.1 | 7.1 | 7.6 |
This appears nice! Let’s now separate the textual content and desk parts and convert all desk parts from HTML to Markdown.
docs = []
tables = []
for doc in information:
if doc.metadata['category'] == 'Desk':
tables.append(doc)
elif doc.metadata['category'] == 'CompositeElement':
docs.append(doc)
for desk in tables:
desk.page_content = htmltabletomd.convert_table(desk.metadata['text_as_html'])
len(docs), len(tables)OUTPUT
(5, 2)
We will additionally validate the tables extracted and transformed into Markdown.
for desk in tables:
print(desk.page_content)
print()OUTPUT

We will now view a number of the extracted photographs from the doc as proven under.
! ls -l ./figuresOUTPUT
whole 144
-rw-r--r-- 1 root root 27929 Aug 18 10:10 figure-1-1.jpg
-rw-r--r-- 1 root root 27182 Aug 18 10:10 figure-1-2.jpg
-rw-r--r-- 1 root root 26589 Aug 18 10:10 figure-1-3.jpg
-rw-r--r-- 1 root root 26448 Aug 18 10:10 figure-2-4.jpg
-rw-r--r-- 1 root root 29260 Aug 18 10:10 figure-2-5.jpg
from IPython.show import Picture
Picture('./figures/figure-1-2.jpg')OUTPUT
Picture('./figures/figure-1-3.jpg')OUTPUT
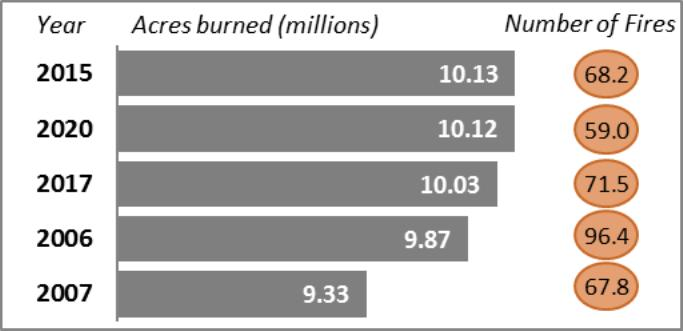
The whole lot appears to be so as, we will see that the photographs from the doc that are largely charts and graphs have been accurately extracted.
Enter Open AI API Key
We enter our Open AI key utilizing the getpass() perform so we don’t by chance expose our key within the code.
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')Setup Surroundings Variables
Subsequent, we setup some system surroundings variables which shall be used later when authenticating our LLM.
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEYLoad Connection to Multimodal LLM
Subsequent, we create a connection to GPT-4o, the multimodal LLM we’ll use in our system.
from langchain_openai import ChatOpenAI
chatgpt = ChatOpenAI(model_name="gpt-4o", temperature=0)Setup the Multi-vector Retriever
We are going to now construct our multi-vector-retriever to index picture, textual content chunk and desk aspect summaries, create their embeddings and retailer within the vector database and the uncooked parts in a doc retailer and join them in order that we will then retrieve the uncooked picture, textual content and desk parts for consumer queries.
Create Textual content and Desk Summaries
We are going to use GPT-4o to provide desk and textual content summaries. Textual content summaries are suggested if utilizing giant chunk sizes (e.g., as set above, we use 4k token chunks). Summaries are used to retrieve uncooked tables and / or uncooked chunks of textual content in a while utilizing the multi-vector retriever. Creating summaries of textual content parts is optionally available.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
# Immediate
prompt_text = """
You're an assistant tasked with summarizing tables and textual content notably for semantic retrieval.
These summaries shall be embedded and used to retrieve the uncooked textual content or desk parts
Give an in depth abstract of the desk or textual content under that's properly optimized for retrieval.
For any tables additionally add in a one line description of what the desk is about apart from the abstract.
Don't add extra phrases like Abstract: and so on.
Desk or textual content chunk:
{aspect}
"""
immediate = ChatPromptTemplate.from_template(prompt_text)
# Abstract chain
summarize_chain = (
{"aspect": RunnablePassthrough()}
|
immediate
|
chatgpt
|
StrOutputParser() # extracts response as textual content
)
# Initialize empty summaries
text_summaries = []
table_summaries = []
text_docs = [doc.page_content for doc in docs]
table_docs = [table.page_content for table in tables]
text_summaries = summarize_chain.batch(text_docs, {"max_concurrency": 5})
table_summaries = summarize_chain.batch(table_docs, {"max_concurrency": 5})The above snippet makes use of a LangChain chain to create an in depth abstract of every textual content chunk and desk and we will see the output for a few of them under.
# Abstract of a textual content chunk aspect
text_summaries[0]OUTPUT
Wildfires embody lightning-caused, unauthorized human-caused, and escaped
prescribed burns. States deal with wildfires on nonfederal lands, whereas federal
companies handle these on federal lands. The Forest Service oversees 193
million acres of the Nationwide Forest System, ...... In 2022, 68,988
wildfires burned 7.6 million acres, with over 40% of the acreage in Alaska.
As of June 1, 2023, 18,300 wildfires have burned over 511,000 acres.
#Abstract of a desk aspect
table_summaries[0]OUTPUT
This desk gives information on the variety of fires and acres burned from 2018 to
2022, categorized by federal and nonfederal sources. nnNumber of Fires
(hundreds):n- Federal: Ranges from 10.9K to 14.4K, peaking in 2020.n- FS
(Forest Service): Ranges from 5.3K to six.7K, with an anomaly of 59K in
2022.n- Dol (Division of the Inside): Ranges from 5.3K to 7.6K.n-
Different: Persistently low, largely round 0.1K.n- ....... Different: Persistently
lower than 0.1M.n- Nonfederal: Ranges from 1.6M to 4.1M, with an anomaly of
"Lg" in 2021.n- Complete: Ranges from 4.7M to 10.1M.
This appears fairly good and the summaries are fairly informative and may generate good embeddings for retrieval in a while.
Create Picture Summaries
We are going to use GPT-4o to provide the picture summaries. Nevertheless since photographs can’t be handed straight, we’ll base64 encode the photographs as strings after which go it to them. We begin by creating just a few utility capabilities to encode photographs and generate a abstract for any enter picture by passing it to GPT-4o.
import base64
import os
from langchain_core.messages import HumanMessage
# create a perform to encode photographs
def encode_image(image_path):
"""Getting the base64 string"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.learn()).decode("utf-8")
# create a perform to summarize the picture by passing a immediate to GPT-4o
def image_summarize(img_base64, immediate):
"""Make picture abstract"""
chat = ChatOpenAI(mannequin="gpt-4o", temperature=0)
msg = chat.invoke(
[
HumanMessage(
content=[
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url":
f"data:image/jpeg;base64,{img_base64}"},
},
]
)
]
)
return msg.content materialThe above capabilities serve the next objective:
- encode_image(image_path): Reads a picture file from the offered path, converts it to a binary stream, after which encodes it to a base64 string. This string can be utilized to ship the picture over to GPT-4o.
- image_summarize(img_base64, immediate): Sends a base64-encoded picture together with a textual content immediate to the GPT-4o mannequin. It returns a abstract of the picture primarily based on the given immediate by invoking a immediate the place each textual content and picture inputs are processed.
We now use the above utilities to summarize every of our photographs utilizing the next perform.
def generate_img_summaries(path):
"""
Generate summaries and base64 encoded strings for photographs
path: Path to checklist of .jpg recordsdata extracted by Unstructured
"""
# Retailer base64 encoded photographs
img_base64_list = []
# Retailer picture summaries
image_summaries = []
# Immediate
immediate = """You're an assistant tasked with summarizing photographs for retrieval.
Bear in mind these photographs might probably comprise graphs, charts or
tables additionally.
These summaries shall be embedded and used to retrieve the uncooked picture
for query answering.
Give an in depth abstract of the picture that's properly optimized for
retrieval.
Don't add extra phrases like Abstract: and so on.
"""
# Apply to pictures
for img_file in sorted(os.listdir(path)):
if img_file.endswith(".jpg"):
img_path = os.path.be part of(path, img_file)
base64_image = encode_image(img_path)
img_base64_list.append(base64_image)
image_summaries.append(image_summarize(base64_image, immediate))
return img_base64_list, image_summaries
# Picture summaries
IMG_PATH = './figures'
imgs_base64, image_summaries = generate_img_summaries(IMG_PATH) We will now take a look at one of many photographs and its abstract simply to get an concept of how GPT-4o has generated the picture summaries.
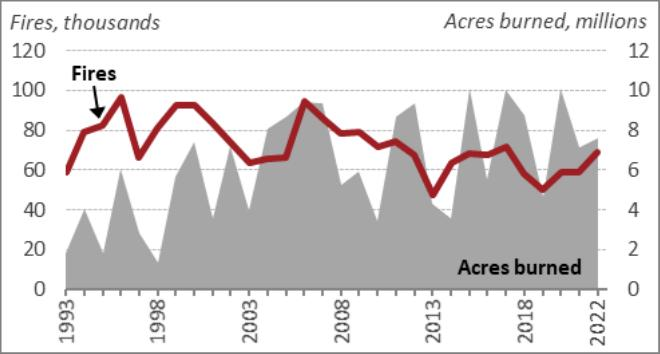
# View one of many photographs
show(Picture('./figures/figure-1-2.jpg'))OUTPUT
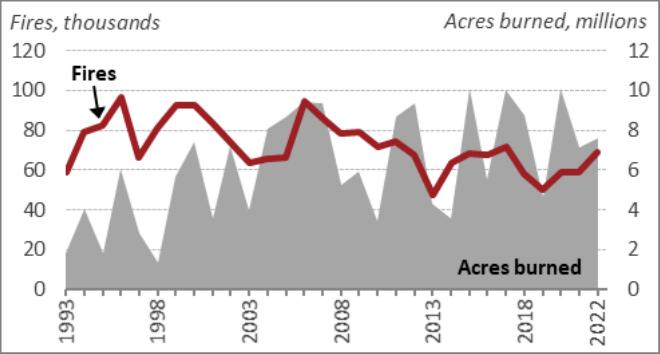
# View the picture abstract generated by GPT-4o
image_summaries[1]OUTPUT
Line graph exhibiting the variety of fires (in hundreds) and the acres burned
(in thousands and thousands) from 1993 to 2022. The left y-axis represents the variety of
fires, peaking round 100,000 within the mid-Nineteen Nineties and fluctuating between
50,000 and 100,000 thereafter. The precise y-axis represents acres burned,
with peaks reaching as much as 10 million acres. The x-axis reveals the years from
1993 to 2022. The graph makes use of a purple line to depict the variety of fires and a
gray shaded space to characterize the acres burned.
General appears to be fairly descriptive and we will use these summaries and embed them right into a vector database quickly.
Index Paperwork and Summaries within the Multi-Vector Retriever
We at the moment are going so as to add the uncooked textual content, desk and picture parts and their summaries to a Multi Vector Retriever utilizing the next technique:
- Retailer the uncooked texts, tables, and pictures within the docstore (right here we’re utilizing Redis).
- Embed the textual content summaries (or textual content parts straight), desk summaries, and picture summaries utilizing an embedder mannequin and retailer the summaries and embeddings within the vectorstore (right here we’re utilizing Chroma) for environment friendly semantic retrieval.
- Join the 2 utilizing a typical doc_id identifier within the multi-vector retriever
Begin Redis Server for Docstore
Step one is to get the docstore prepared, for this we use the next code to obtain the open-source model of Redis and begin a Redis server regionally as a background course of.
%%sh
curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) fundamental" | sudo tee /and so on/apt/sources.checklist.d/redis.checklist
sudo apt-get replace > /dev/null 2>&1
sudo apt-get set up redis-stack-server > /dev/null 2>&1
redis-stack-server --daemonize sureOUTPUT
deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg]
https://packages.redis.io/deb jammy fundamental
Beginning redis-stack-server, database path /var/lib/redis-stack
Open AI Embedding Fashions
LangChain permits us to entry Open AI embedding fashions which embody the latest fashions: a smaller and extremely environment friendly text-embedding-3-small mannequin, and a bigger and extra highly effective text-embedding-3-large mannequin. We want an embedding mannequin to transform our doc chunks into embeddings earlier than storing in our vector database.
from langchain_openai import OpenAIEmbeddings
# particulars right here: https://openai.com/weblog/new-embedding-models-and-api-updates
openai_embed_model = OpenAIEmbeddings(mannequin="text-embedding-3-small")Implement the Multi-Vector Retriever Operate
We now create a perform that can assist us join our vector retailer and docs and index the paperwork, summaries, and embeddings utilizing the next perform.
import uuid
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain_community.storage import RedisStore
from langchain_community.utilities.redis import get_client
from langchain_chroma import Chroma
from langchain_core.paperwork import Doc
from langchain_openai import OpenAIEmbeddings
def create_multi_vector_retriever(
docstore, vectorstore, text_summaries, texts, table_summaries, tables,
image_summaries, photographs
):
"""
Create retriever that indexes summaries, however returns uncooked photographs or texts
"""
id_key = "doc_id"
# Create the multi-vector retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=docstore,
id_key=id_key,
)
# Helper perform so as to add paperwork to the vectorstore and docstore
def add_documents(retriever, doc_summaries, doc_contents):
doc_ids = [str(uuid.uuid4()) for _ in doc_contents]
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(doc_summaries)
]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(checklist(zip(doc_ids, doc_contents)))
# Add texts, tables, and pictures
# Test that text_summaries isn't empty earlier than including
if text_summaries:
add_documents(retriever, text_summaries, texts)
# Test that table_summaries isn't empty earlier than including
if table_summaries:
add_documents(retriever, table_summaries, tables)
# Test that image_summaries isn't empty earlier than including
if image_summaries:
add_documents(retriever, image_summaries, photographs)
return retrieverFollowing are the important thing parts within the above perform and their position:
- create_multi_vector_retriever(…): This perform units up a retriever that indexes textual content, desk, and picture summaries however retrieves uncooked information (texts, tables, or photographs) primarily based on the listed summaries.
- add_documents(retriever, doc_summaries, doc_contents): A helper perform that generates distinctive IDs for the paperwork, provides the summarized paperwork to the vectorstore, and shops the total content material (uncooked textual content, tables, or photographs) within the docstore.
- retriever.vectorstore.add_documents(…): Provides the summaries and embeddings to the vectorstore, the place the retrieval shall be carried out primarily based on the abstract embeddings.
- retriever.docstore.mset(…): Shops the precise uncooked doc content material (texts, tables, or photographs) within the docstore, which shall be returned when an identical abstract is retrieved.
Create the vector database
We are going to now create our vectorstore utilizing Chroma because the vector database so we will index summaries and their embeddings shortly.
# The vectorstore to make use of to index the summaries and their embeddings
chroma_db = Chroma(
collection_name="mm_rag",
embedding_function=openai_embed_model,
collection_metadata={"hnsw:house": "cosine"},
)Create the doc database
We are going to now create our docstore utilizing Redis because the database platform so we will index the precise doc parts that are the uncooked textual content chunks, tables and pictures shortly. Right here we simply connect with the Redis server we began earlier.
# Initialize the storage layer - to retailer uncooked photographs, textual content and tables
shopper = get_client('redis://localhost:6379')
redis_store = RedisStore(shopper=shopper) # you should utilize filestore, memorystore, another DB retailer additionallyCreate the multi-vector retriever
We are going to now index our doc uncooked parts, their summaries and embeddings within the doc and vectorstore and construct the multi-vector retriever.
# Create retriever
retriever_multi_vector = create_multi_vector_retriever(
redis_store, chroma_db,
text_summaries, text_docs,
table_summaries, table_docs,
image_summaries, imgs_base64,
)Take a look at the Multi-vector Retriever
We are going to now take a look at the retrieval side in our RAG pipeline to see if our multi-vector retriever is ready to return the proper textual content, desk and picture parts primarily based on consumer queries. Earlier than we test it out, let’s create a utility to have the ability to visualize any photographs retrieved as we have to convert them again from their encoded base64 format into the uncooked picture aspect to have the ability to view it.
from IPython.show import HTML, show, Picture
from PIL import Picture
import base64
from io import BytesIO
def plt_img_base64(img_base64):
"""Disply base64 encoded string as picture"""
# Decode the base64 string
img_data = base64.b64decode(img_base64)
# Create a BytesIO object
img_buffer = BytesIO(img_data)
# Open the picture utilizing PIL
img = Picture.open(img_buffer)
show(img)This perform will assist in taking in any base64 encoded string illustration of a picture, convert it again into a picture and show it. Now let’s take a look at our retriever.
# Test retrieval
question = "Inform me in regards to the annual wildfires development with acres burned"
docs = retriever_multi_vector.invoke(question, restrict=5)
# We get 3 related docs
len(docs)OUTPUT
3
We will take a look at the paperwork retrieved as follows:
docs[b'a. aa = Informing the legislative debate since 1914 Congressional Research
ServicennUpdated June 1, 2023nnWildfire StatisticsnnWildfires are
unplanned fires, including lightning-caused fires, unauthorized human-caused
fires, and escaped fires from prescribed burn projects ...... and an average
of 7.2 million acres impacted annually. In 2022, 68,988 wildfires burned 7.6
million acres. Over 40% of those acres were in Alaska (3.1 million
acres).nnAs of June 1, 2023, around 18,300 wildfires have impacted over
511,000 acres this year.',b'| | 2018 | 2019 | 2020 | 2021 | 2022 |n| :--- | :--- | :--- | :--- | :--
- | :--- |n| Number of Fires (thousands) |n| Federal | 12.5 | 10.9 | 14.4 |
14.0 | 11.7 |n| FS | 5.6 | 5.3 | 6.7 | 6.2 | 59 |n| Dol | 7.0 | 5.3 | 7.6
| 7.6 | 5.8 |n| Other | 0.1 | 0.2 | <0.1 | 0.2 | 0.1 |n| Nonfederal |
45.6 | 39.6 | 44.6 | 45.0 | $7.2 |n| Total | 58.1 | 50.5 | 59.0 | 59.0 |
69.0 |n| Acres Burned (millions) |n| Federal | 4.6 | 3.1 | 7.1 | 5.2 | 40
|n| FS | 2.3 | 0.6 | 48 | 41 | 19 |n| Dol | 2.3 | 2.3 | 2.3 | 1.0 | 2.1
|n| Other | <0.1 | <0.1 | <0.1 | <0.1 | <0.1 |n| Nonfederal
| 4.1 | 1.6 | 3.1 | Lg | 3.6 |n| Total | 8.8 | 4.7 | 10.1 | 7.1 | 7.6 |n',
b'/9j/4AAQSkZJRgABAQAAAQABAAD/......RXQv+gZB+RrYooAx/']
It’s clear that the primary retrieved aspect is a textual content chunk, the second retrieved aspect is a desk and the final retrieved aspect is a picture for our given question. We will additionally use the utility perform from above to view the retrieved picture.
# view retrieved picture
plt_img_base64(docs[2])OUTPUT
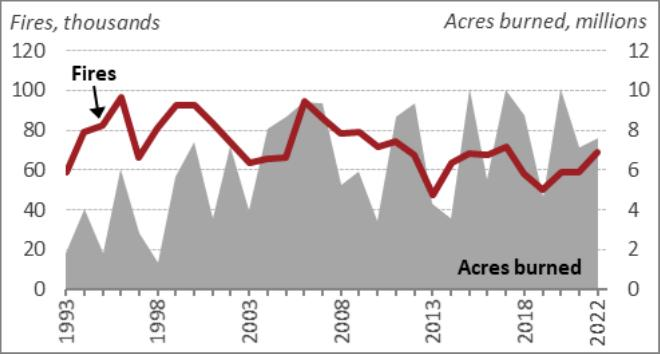
We will undoubtedly see the proper context being retrieved primarily based on the consumer query. Let’s strive another and validate this once more.
# Test retrieval
question = "Inform me in regards to the share of residences burned by wildfires in 2022"
docs = retriever_multi_vector.invoke(question, restrict=5)
# We get 2 docs
docsOUTPUT
[b'Source: National Interagency Coordination Center (NICC) Wildland Fire
Summary and Statistics annual reports. Notes: FS = Forest Service; DOI =
Department of the Interior. Column totals may not sum precisely due to
rounding.nn2022nnYear Acres burned (millions) Number of Fires 2015 2020
2017 2006 2007nnSource: NICC Wildland Fire Summary and Statistics annual
reports. ...... and structures (residential, commercial, and other)
destroyed. For example, in 2022, over 2,700 structures were burned in
wildfires; the majority of the damage occurred in California (see Table 2).',b'| | 2019 | 2020 | 2021 | 2022 |n| :--- | :--- | :--- | :--- | :--- |n|
Structures Burned | 963 | 17,904 | 5,972 | 2,717 |n| % Residences | 46% |
54% | 60% | 46% |n']
This undoubtedly reveals that our multi-vector retriever is working fairly properly and is ready to retrieve multimodal contextual information primarily based on consumer queries!
import re
import base64
# helps in detecting base64 encoded strings
def looks_like_base64(sb):
"""Test if the string appears like base64"""
return re.match("^[A-Za-z0-9+/]+[=]{0,2}$", sb) isn't None
# helps in checking if the base64 encoded picture is definitely a picture
def is_image_data(b64data):
"""
Test if the base64 information is a picture by trying at first of the info
"""
image_signatures = {
b"xffxd8xff": "jpg",
b"x89x50x4ex47x0dx0ax1ax0a": "png",
b"x47x49x46x38": "gif",
b"x52x49x46x46": "webp",
}
strive:
header = base64.b64decode(b64data)[:8] # Decode and get the primary 8 bytes
for sig, format in image_signatures.objects():
if header.startswith(sig):
return True
return False
besides Exception:
return False
# returns a dictionary separating photographs and textual content (with desk) parts
def split_image_text_types(docs):
"""
Cut up base64-encoded photographs and texts (with tables)
"""
b64_images = []
texts = []
for doc in docs:
# Test if the doc is of kind Doc and extract page_content if that's the case
if isinstance(doc, Doc):
doc = doc.page_content.decode('utf-8')
else:
doc = doc.decode('utf-8')
if looks_like_base64(doc) and is_image_data(doc):
b64_images.append(doc)
else:
texts.append(doc)
return {"photographs": b64_images, "texts": texts}These utility capabilities talked about above assist us in separating the textual content (with desk) parts and picture parts individually from the retrieved context paperwork. Their performance is defined in a bit extra element as follows:
- looks_like_base64(sb): Makes use of a daily expression to verify if the enter string follows the everyday sample of base64 encoding. This helps establish whether or not a given string could be base64-encoded.
- is_image_data(b64data): Decodes the base64 string and checks the primary few bytes of the info towards identified picture file signatures (JPEG, PNG, GIF, WebP). It returns True if the base64 string represents a picture, serving to confirm the kind of base64-encoded information.
- split_image_text_types(docs): Processes an inventory of paperwork, differentiating between base64-encoded photographs and common textual content (which might embody tables). It checks every doc utilizing the looks_like_base64 and is_image_data capabilities after which splits the paperwork into two classes: photographs (base64-encoded photographs) and texts (non-image paperwork). The result’s returned as a dictionary with two lists.
We will shortly take a look at this perform on any retrieval output from our multi-vector retriever as proven under with an instance.
# Test retrieval
question = "Inform me detailed statistics of the highest 5 years with largest wildfire
acres burned"
docs = retriever_multi_vector.invoke(question, restrict=5)
r = split_image_text_types(docs)
r OUTPUT
{'photographs': ['/9j/4AAQSkZJRgABAQAh......30aAPda8Kn/wCPiT/eP86PPl/56v8A99GpURSgJGTQB//Z'],'texts': ['Figure 2. Top Five Years with Largest Wildfire Acreage Burned
Since 1960nnTable 1. Annual Wildfires and Acres Burned',
'Source: NICC Wildland Fire Summary and Statistics annual reports.nnConflagrations Of the 1.6 million wildfires that have occurred
since 2000, 254 exceeded 100,000 acres burned and 16 exceeded 500,000 acres
burned. A small fraction of wildfires become .......']}
Appears like our perform is working completely and separating out the retrieved context parts as desired.
Construct Finish-to-Finish Multimodal RAG Pipeline
Now let’s join our multi-vector retriever, immediate directions and construct a multimodal RAG chain. To begin with, we create a multimodal immediate perform which can take the context textual content, tables and pictures and construction a correct immediate in the proper format which may then be handed into GPT-4o.
from operator import itemgetter
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_core.messages import HumanMessage
def multimodal_prompt_function(data_dict):
"""
Create a multimodal immediate with each textual content and picture context.
This perform codecs the offered context from `data_dict`, which comprises
textual content, tables, and base64-encoded photographs. It joins the textual content (with desk) parts
and prepares the picture(s) in a base64-encoded format to be included in a
message.
The formatted textual content and pictures (context) together with the consumer query are used to
assemble a immediate for GPT-4o
"""
formatted_texts = "n".be part of(data_dict["context"]["texts"])
messages = []
# Including picture(s) to the messages if current
if data_dict["context"]["images"]:
for picture in data_dict["context"]["images"]:
image_message = {
"kind": "image_url",
"image_url": {"url": f"information:picture/jpeg;base64,{picture}"},
}
messages.append(image_message)
# Including the textual content for evaluation
text_message = {
"kind": "textual content",
"textual content": (
f"""You're an analyst tasked with understanding detailed info
and tendencies from textual content paperwork,
information tables, and charts and graphs in photographs.
You can be given context info under which shall be a mixture of
textual content, tables, and pictures normally of charts or graphs.
Use this info to offer solutions associated to the consumer
query.
Don't make up solutions, use the offered context paperwork under and
reply the query to the very best of your means.
Consumer query:
{data_dict['question']}
Context paperwork:
{formatted_texts}
Reply:
"""
),
}
messages.append(text_message)
return [HumanMessage(content=messages)]This perform helps in structuring the immediate to be despatched to GPT-4o as defined right here:
- multimodal_prompt_function(data_dict): creates a multimodal immediate by combining textual content and picture information from a dictionary. The perform codecs textual content context (with tables), appends base64-encoded photographs (if accessible), and constructs a HumanMessage to ship to GPT-4o for evaluation together with the consumer query.
We now assemble our multimodal RAG chain utilizing the next code snippet.
# Create RAG chain
multimodal_rag = (
{
"context": itemgetter('context'),
"query": itemgetter('enter'),
}
|
RunnableLambda(multimodal_prompt_function)
|
chatgpt
|
StrOutputParser()
)
# Cross enter question to retriever and get context doc parts
retrieve_docs = (itemgetter('enter')
|
retriever_multi_vector
|
RunnableLambda(split_image_text_types))
# Under, we chain `.assign` calls. This takes a dict and successively
# provides keys-- "context" and "reply"-- the place the worth for every key
# is set by a Runnable (perform or chain executing at runtime).
# This helps in having the retrieved context together with the reply generated by GPT-4o
multimodal_rag_w_sources = (RunnablePassthrough.assign(context=retrieve_docs)
.assign(reply=multimodal_rag)
)The chains create above work as follows:
- multimodal_rag_w_sources: This chain, chains the assignments of context and reply. It assigns the context from the paperwork retrieved utilizing retrieve_docs and assigns the reply generated by the multimodal RAG chain utilizing multimodal_rag. This setup ensures that each the retrieved context and the ultimate reply can be found and structured collectively as a part of the output.
- retrieve_docs: This chain retrieves the context paperwork associated to the enter question. It begins by extracting the consumer’s enter , passes the question via our multi-vector retriever to fetch related paperwork, after which calls the split_image_text_types perform we outlined earlier through RunnableLambda to separate base64-encoded photographs and textual content (with desk) parts.
- multimodal_rag: This chain is the ultimate step which creates a RAG (Retrieval-Augmented Technology) chain, the place it makes use of the consumer enter and retrieved context obtained from the earlier two chains, processes them utilizing the multimodal_prompt_function we outlined earlier, via a RunnableLambda, and passes the immediate to GPT-4o to generate the ultimate response. The pipeline ensures multimodal inputs (textual content, tables and pictures) are processed by GPT-4o to present us the response.
Take a look at the Multimodal RAG Pipeline
The whole lot is about up and able to go; let’s take a look at out our multimodal RAG pipeline!
# Run multimodal RAG chain
question = "Inform me detailed statistics of the highest 5 years with largest wildfire acres
burned"
response = multimodal_rag_w_sources.invoke({'enter': question})
responseOUTPUT
{'enter': 'Inform me detailed statistics of the highest 5 years with largest
wildfire acres burned',
'context': {'photographs': ['/9j/4AAQSkZJRgABAa.......30aAPda8Kn/wCPiT/eP86PPl/56v8A99GpURSgJGTQB//Z'],
'texts': ['Figure 2. Top Five Years with Largest Wildfire Acreage Burned
Since 1960nnTable 1. Annual Wildfires and Acres Burned',
'Source: NICC Wildland Fire Summary and Statistics annual
reports.nnConflagrations Of the 1.6 million wildfires that have occurred
since 2000, 254 exceeded 100,000 acres burned and 16 exceeded 500,000 acres
burned. A small fraction of wildfires become catastrophic, and a small
percentage of fires accounts for the vast majority of acres burned. For
example, about 1% of wildfires become conflagrations—raging, destructive
fires—but predicting which fires will “blow up” into conflagrations is
challenging and depends on a multitude of factors, such as weather and
geography. There have been 1,041 large or significant fires annually on
average from 2018 through 2022. In 2022, 2% of wildfires were classified as
large or significant (1,289); 45 exceeded 40,000 acres in size, and 17
exceeded 100,000 acres. For context, there were fewer large or significant
wildfires in 2021 (943)......']},
'reply': 'Primarily based on the offered context and the picture, listed here are the
detailed statistics for the highest 5 years with the most important wildfire acres
burned:nn1. **2015**n - **Acres burned:** 10.13 millionn - **Quantity
of fires:** 68.2 thousandnn2. **2020**n - **Acres burned:** 10.12
millionn - **Variety of fires:** 59.0 thousandnn3. **2017**n -
**Acres burned:** 10.03 millionn - **Variety of fires:** 71.5
thousandnn4. **2006**n - **Acres burned:** 9.87 millionn - **Quantity
of fires:** 96.4 thousandnn5. **2007**n - **Acres burned:** 9.33
millionn - **Variety of fires:** 67.8 thousandnnThese statistics
spotlight the years with probably the most important wildfire exercise when it comes to
acreage burned, exhibiting a development of large-scale wildfires over the previous few
a long time.'}
Appears like we’re above to get the reply in addition to the supply context paperwork used to reply the query! Let’s create a perform now to format these outcomes and show them in a greater means!
def multimodal_rag_qa(question):
response = multimodal_rag_w_sources.invoke({'enter': question})
print('=='*50)
print('Reply:')
show(Markdown(response['answer']))
print('--'*50)
print('Sources:')
text_sources = response['context']['texts']
img_sources = response['context']['images']
for textual content in text_sources:
show(Markdown(textual content))
print()
for img in img_sources:
plt_img_base64(img)
print()
print('=='*50)This can be a easy perform which simply takes the dictionary output from our multimodal RAG pipeline and shows the ends in a pleasant format. Time to place this to the take a look at!
question = "Inform me detailed statistics of the highest 5 years with largest wildfire acres
burned"
multimodal_rag_qa(question)OUTPUT
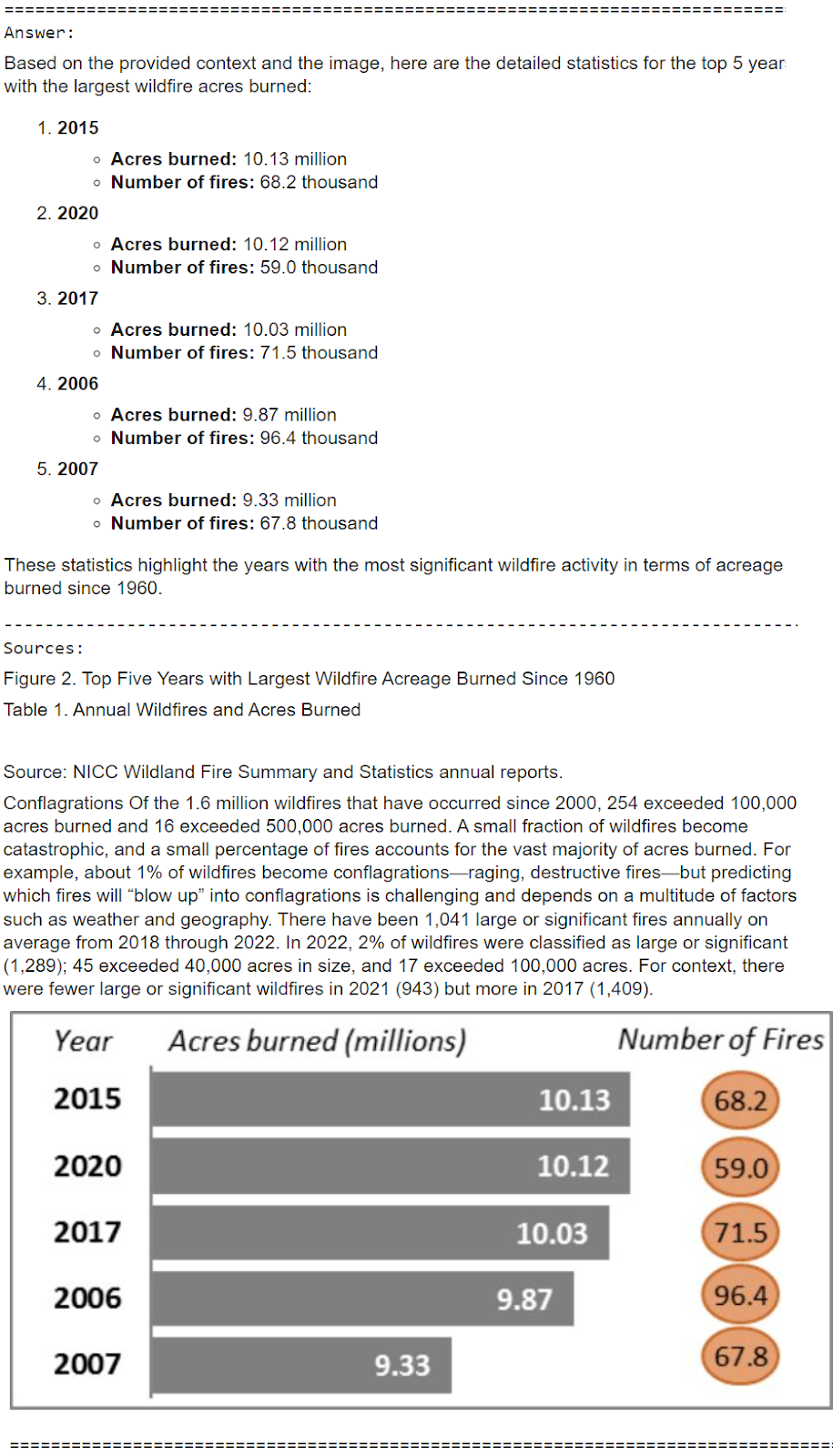
It does a reasonably good job, leveraging textual content and picture context paperwork right here to reply the query appropriate;y! Let’s strive one other one.
# Run RAG chain
question = "Inform me in regards to the annual wildfires development with acres burned"
multimodal_rag_qa(question)OUTPUT
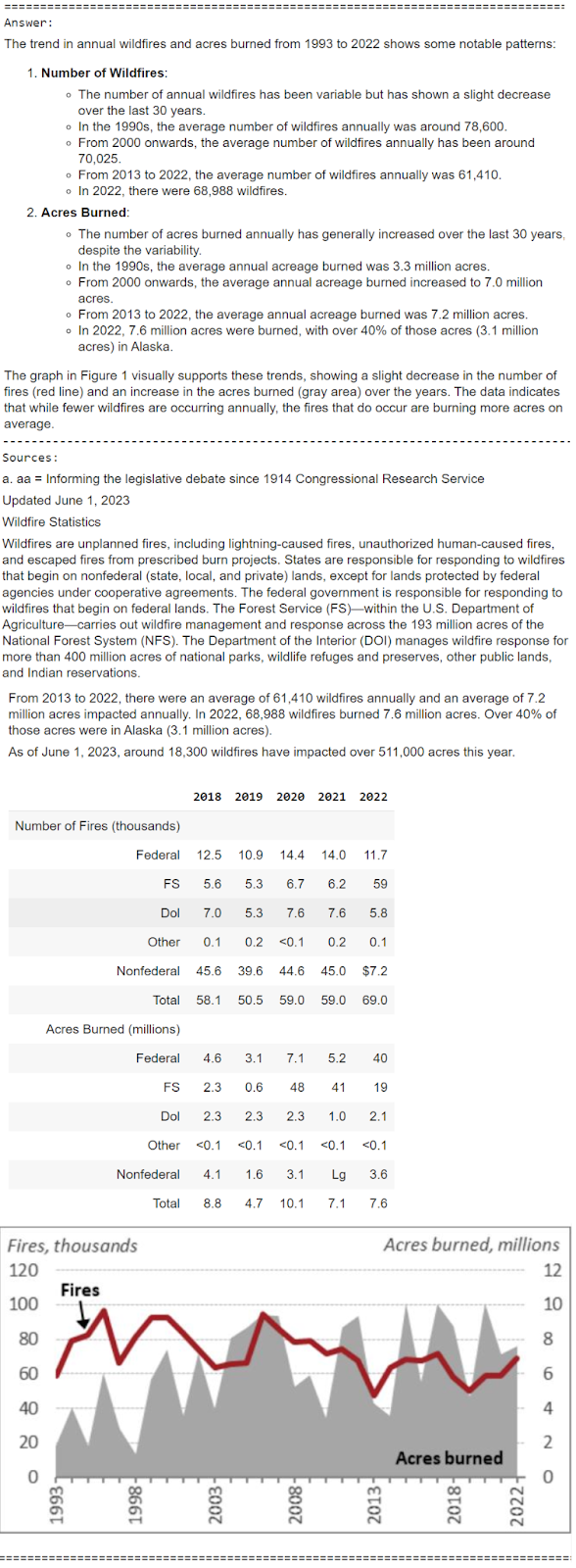
It does a reasonably good job right here analyzing tables, photographs and textual content context paperwork to reply the consumer query with an in depth report. Let’s take a look at another instance of a really particular question.
# Run RAG chain
question = "Inform me in regards to the variety of acres burned by wildfires for the forest service in 2021"
multimodal_rag_qa(question)OUTPUT
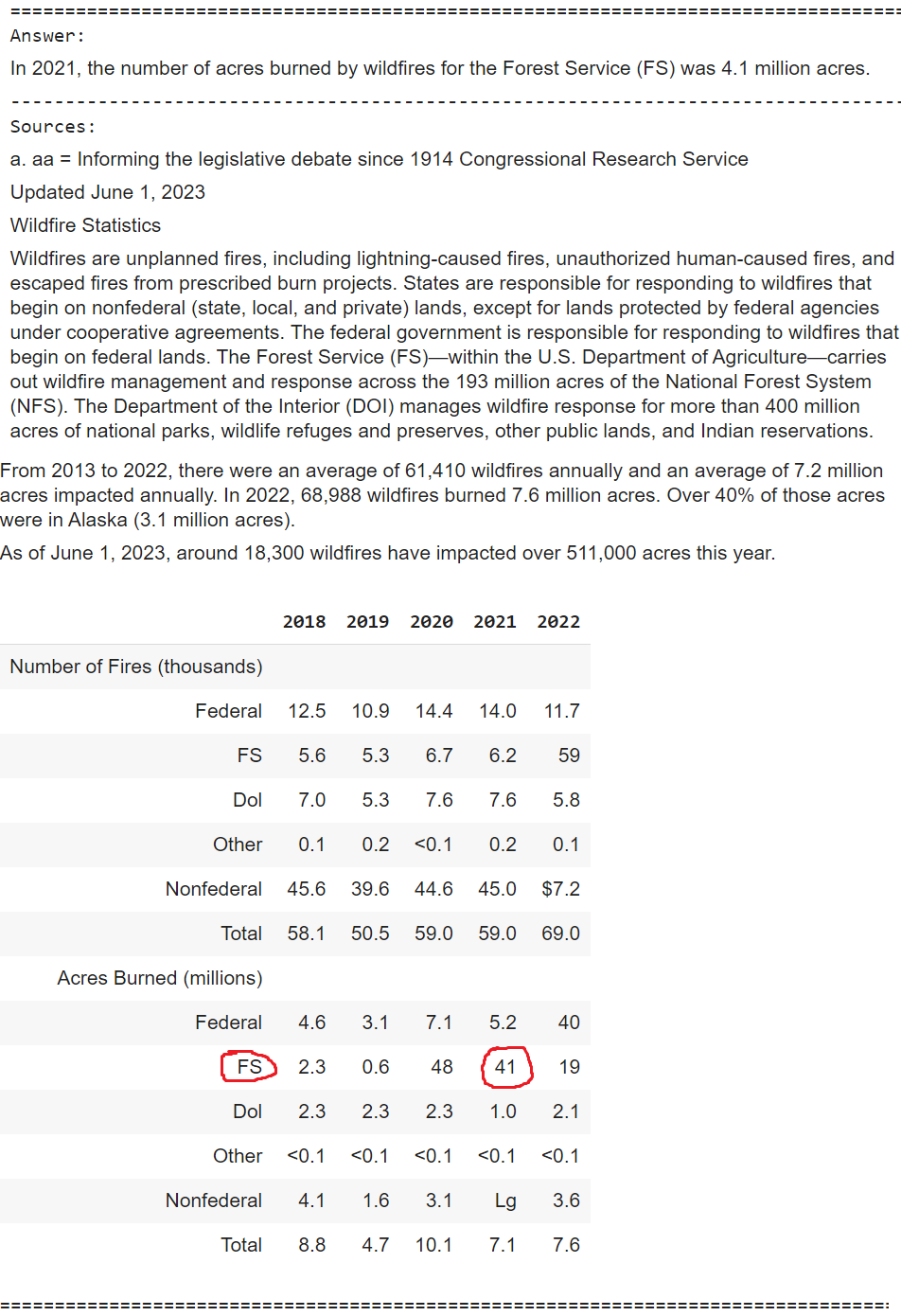
Right here you may clearly see that despite the fact that the desk parts have been wrongly extracted for a number of the rows, particularly the one getting used to reply the query, GPT-4o is clever sufficient to have a look at the encircling desk parts and the textual content chunks retrieved to present the proper reply of 4.1 million as a substitute of 41 million. In fact this may occasionally not all the time work and that’s the place you may must deal with enhancing your extraction pipelines.
Conclusion
In case you are studying this, I commend your efforts in staying proper until the top on this large information! Right here, we went via an in-depth understanding of the present challenges in conventional RAG techniques particularly in dealing with multimodal information. We then talked about what’s multimodal information in addition to multimodal giant language fashions (LLMs). We mentioned at size an in depth system structure and workflow for a Multimodal RAG system with GPT-4o. Final however not the least, we applied this Multimodal RAG system with LangChain and examined it on varied situations. Do take a look at this Colab pocket book for straightforward entry to the code and check out enhancing this method by including extra capabilities like assist for audio, video and extra!
Incessantly Requested Questions
Ans. A Retrieval Augmented Technology (RAG) system is an AI framework that mixes information retrieval with language era, enabling extra contextual and correct responses with out the necessity for fine-tuning giant language fashions (LLMs).
Ans. Conventional RAG techniques primarily deal with textual content information, can’t course of multimodal information (like photographs or tables), and are restricted by the standard of the saved information within the vector database.
Ans. Multimodal information consists of a number of kinds of information codecs corresponding to textual content, photographs, tables, audio, video, and extra, permitting AI techniques to course of a mixture of those modalities.
Ans. A multimodal Massive Language Mannequin (LLM) is an AI mannequin able to processing and understanding varied information varieties (textual content, photographs, tables) to generate related responses or summaries.
Ans. Some in style multimodal LLMs embody GPT-4o (OpenAI), Gemini (Google), Claude (Anthropic), and open-source fashions like LLaVA-NeXT and Pixtral 12B.