Though the deepfaking of personal people has grow to be a rising public concern and is more and more being outlawed in numerous areas, really proving {that a} user-created mannequin – reminiscent of one enabling revenge porn – was particularly educated on a specific individual’s photos stays extraordinarily difficult.
To place the issue in context: a key component of a deepfake assault is falsely claiming that a picture or video depicts a selected individual. Merely stating that somebody in a video is id #A, fairly than only a lookalike, is sufficient to create hurt, and no AI is important on this situation.
Nevertheless, if an attacker generates AI photos or movies utilizing fashions educated on actual individual’s knowledge, social media and search engine face recognition programs will routinely hyperlink the faked content material to the sufferer –with out requiring names in posts or metadata. The AI-generated visuals alone make sure the affiliation.
The extra distinct the individual’s look, the extra inevitable this turns into, till the fabricated content material seems in picture searches and finally reaches the sufferer.
Face to Face
The commonest technique of disseminating identity-focused fashions is at present via Low-Rank Adaptation (LoRA), whereby the person trains a small variety of photos for a couple of hours in opposition to the weights of a far bigger basis mannequin reminiscent of Secure Diffusion (for static photos, principally) or Hunyuan Video, for video deepfakes.
The commonest targets of LoRAs, together with the new breed of video-based LoRAs, are feminine celebrities, whose fame exposes them to this type of therapy with much less public criticism than within the case of ‘unknown’ victims, as a result of assumption that such spinoff works are lined beneath ‘honest use’ (not less than within the USA and Europe).
Feminine celebrities dominate the LoRA and Dreambooth listings on the civit.ai portal. The preferred such LoRA at present has greater than 66,000 downloads, which is appreciable, provided that this use of AI stays seen as a ‘fringe’ exercise.
There isn’t a such public discussion board for the non-celebrity victims of deepfaking, who solely floor within the media when prosecution circumstances come up, or the victims converse out in standard retailers.
Nevertheless, in each eventualities, the fashions used to pretend the goal identities have ‘distilled’ their coaching knowledge so fully into the latent area of the mannequin that it’s tough to determine the supply photos that had been used.
If it had been doable to take action inside an appropriate margin of error, this is able to allow the prosecution of those that share LoRAs, because it not solely proves the intent to deepfake a specific id (i.e., that of a specfic ‘unknown’ individual, even when the malefactor by no means names them through the defamation course of), but additionally exposes the uploader to copyright infringement expenses, the place relevant.
The latter can be helpful in jurisdictions the place authorized regulation of deepfaking applied sciences is missing or lagging behind.
Over-Uncovered
The target of coaching a basis mannequin, such because the multi-gigabyte base mannequin {that a} person may obtain from Hugging Face, is that the mannequin ought to grow to be well-generalized, and ductile. This entails coaching on an satisfactory variety of various photos, and with acceptable settings, and ending coaching earlier than the mannequin ‘overfits’ to the info.
An overfitted mannequin has seen the info so many (extreme) instances through the coaching course of that it’s going to have a tendency to breed photos which might be very comparable, thereby exposing the supply of coaching knowledge.

The id ‘Ann Graham Lotz’ may be nearly completely reproduced within the Secure Diffusion V1.5 mannequin. The reconstruction is sort of similar to the coaching knowledge (on the left within the picture above). Supply: https://arxiv.org/pdf/2301.13188
Nevertheless, overfitted fashions are typically discarded by their creators fairly than distributed, since they’re in any case unfit for goal. Subsequently that is an unlikely forensic ‘windfall’. In any case, the precept applies extra to the costly and high-volume coaching of basis fashions, the place a number of variations of the identical picture which have crept into an enormous supply dataset could make sure coaching photos straightforward to invoke (see picture and instance above).
Issues are just a little completely different within the case of LoRA and Dreambooth fashions (although Dreambooth has fallen out of vogue on account of its massive file sizes). Right here, the person selects a really restricted variety of various photos of a topic, and makes use of these to coach a LoRA.

On the left, output from a Hunyuan Video LoRA. On the fitting, the info that made the resemblance doable (photos used with permission of the individual depicted).
Often the LoRA may have a trained-in trigger-word, reminiscent of [nameofcelebrity]. Nevertheless, fairly often the specifically-trained topic will seem in generated output even with out such prompts, as a result of even a well-balanced (i.e., not overfitted) LoRA is considerably ‘fixated’ on the fabric it was educated on, and can have a tendency to incorporate it in any output.
This predisposition, mixed with the restricted picture numbers which might be optimum for a LoRA dataset, expose the mannequin to forensic evaluation, as we will see.
Unmasking the Information
These issues are addressed in a brand new paper from Denmark, which provides a technique to determine supply photos (or teams of supply photos) in a black-box Membership Inference Assault (MIA). The method not less than partly entails the usage of custom-trained fashions which might be designed to assist expose supply knowledge by producing their very own ‘deepfakes’:

Examples of ‘pretend’ photos generated by the brand new strategy, at ever-increasing ranges of Classifier-Free Steerage (CFG), as much as the purpose of destruction. Supply: https://arxiv.org/pdf/2502.11619
Although the work, titled Membership Inference Assaults for Face Photos Towards Fantastic-Tuned Latent Diffusion Fashions, is a most fascinating contribution to the literature round this specific matter, it is usually an inaccessible and tersely-written paper that wants appreciable decoding. Subsequently we’ll cowl not less than the essential ideas behind the venture right here, and a choice of the outcomes obtained.
In impact, if somebody fine-tunes an AI mannequin in your face, the authors’ technique will help show it by on the lookout for telltale indicators of memorization within the mannequin’s generated photos.
Within the first occasion, a goal AI mannequin is fine-tuned on a dataset of face photos, making it extra more likely to reproduce particulars from these photos in its outputs. Subsequently, a classifier assault mode is educated utilizing AI-generated photos from the goal mannequin as ‘positives’ (suspected members of the coaching set) and different photos from a special dataset as ‘negatives’ (non-members).
By studying the delicate variations between these teams, the assault mannequin can predict whether or not a given picture was a part of the unique fine-tuning dataset.
The assault is best in circumstances the place the AI mannequin has been fine-tuned extensively, which means that the extra a mannequin is specialised, the better it’s to detect if sure photos had been used. This typically applies to LoRAs designed to recreate celebrities or personal people.
The authors additionally discovered that including seen watermarks to coaching photos makes detection simpler nonetheless – although hidden watermarks don’t assist as a lot.
Impressively, the strategy is examined in a black-box setting, which means it really works with out entry to the mannequin’s inside particulars, solely its outputs.
The tactic arrived at is computationally intense, because the authors concede; nevertheless, the worth of this work is in indicating the route for extra analysis, and to show that knowledge may be realistically extracted to an appropriate tolerance; subsequently, given its seminal nature, it needn’t run on a smartphone at this stage.
Methodology/Information
A number of datasets from the Technical College of Denmark (DTU, the host establishment for the paper’s three researchers) had been used within the examine, for fine-tuning the goal mannequin and for coaching and testing the assault mode.
Datasets used had been derived from DTU Orbit:
DseenDTU The bottom picture set.
DDTU Photos scraped from DTU Orbit.
DseenDTU A partition of DDTU used to fine-tune the goal mannequin.
DunseenDTU A partition of DDTU that was not used to fine-tune any picture era mannequin and was as a substitute used to check or prepare the assault mannequin.
wmDseenDTU A partition of DDTU with seen watermarks used to fine-tune the goal mannequin.
hwmDseenDTU A partition of DDTU with hidden watermarks used to fine-tune the goal mannequin.
DgenDTU Photos generated by a Latent Diffusion Mannequin (LDM) which has been fine-tuned on the DseenDTU picture set.
The datasets used to fine-tune the goal mannequin include image-text pairs captioned by the BLIP captioning mannequin (maybe not by coincidence probably the most standard uncensored fashions within the informal AI group).
BLIP was set to prepend the phrase ‘a dtu headshot of a’ to every description.
Moreover, a number of datasets from Aalborg College (AAU) had been employed within the checks, all derived from the AU VBN corpus:
DAAU Photos scraped from AAU vbn.
DseenAAU A partition of DAAU used to fine-tune the goal mannequin.
DunseenAAU A partition of DAAU that isn’t used to fine-tune any picture era mannequin, however fairly is used to check or prepare the assault mannequin.
DgenAAU Photos generated by an LDM fine-tuned on the DseenAAU picture set.
Equal to the sooner units, the phrase ‘a aau headshot of a’ was used. This ensured that each one labels within the DTU dataset adopted the format ‘a dtu headshot of a (…)’, reinforcing the dataset’s core traits throughout fine-tuning.
Checks
A number of experiments had been carried out to guage how effectively the membership inference assaults carried out in opposition to the goal mannequin. Every check aimed to find out whether or not it was doable to hold out a profitable assault inside the schema proven under, the place the goal mannequin is fine-tuned on a picture dataset that was obtained with out authorization.

Schema for the strategy.
With the fine-tuned mannequin queried to generate output photos, these photos are then used as constructive examples for coaching the assault mannequin, whereas further unrelated photos are included as unfavorable examples.
The assault mannequin is educated utilizing supervised studying and is then examined on new photos to find out whether or not they had been initially a part of the dataset used to fine-tune the goal mannequin. To guage the accuracy of the assault, 15% of the check knowledge is put aside for validation.
As a result of the goal mannequin is fine-tuned on a recognized dataset, the precise membership standing of every picture is already established when creating the coaching knowledge for the assault mannequin. This managed setup permits for a transparent evaluation of how successfully the assault mannequin can distinguish between photos that had been a part of the fine-tuning dataset and those who weren’t.
For these checks, Secure Diffusion V1.5 was used. Although this fairly previous mannequin crops up quite a bit in analysis as a result of want for constant testing, and the in depth corpus of prior work that makes use of it, that is an acceptable use case; V1.5 remained standard for LoRA creation within the Secure Diffusion hobbyist group for a very long time, regardless of a number of subsequent model releases, and even despite the arrival of Flux – as a result of the mannequin is totally uncensored.
The researchers’ assault mannequin was based mostly on Resnet-18, with the mannequin’s pretrained weights retained. ResNet-18’s 1000-neuron final layer was substituted with a fully-connected layer with two neurons. Coaching loss was categorical cross-entropy, and the Adam optimizer was used.
For every check, the assault mannequin was educated 5 instances utilizing completely different random seeds to compute 95% confidence intervals for the important thing metrics. Zero-shot classification with the CLIP mannequin was used because the baseline.
(Please notice that the unique main outcomes desk within the paper is terse and unusually obscure. Subsequently I’ve reformulated it under in a extra user-friendly vogue. Please click on on the picture to see it in higher decision)
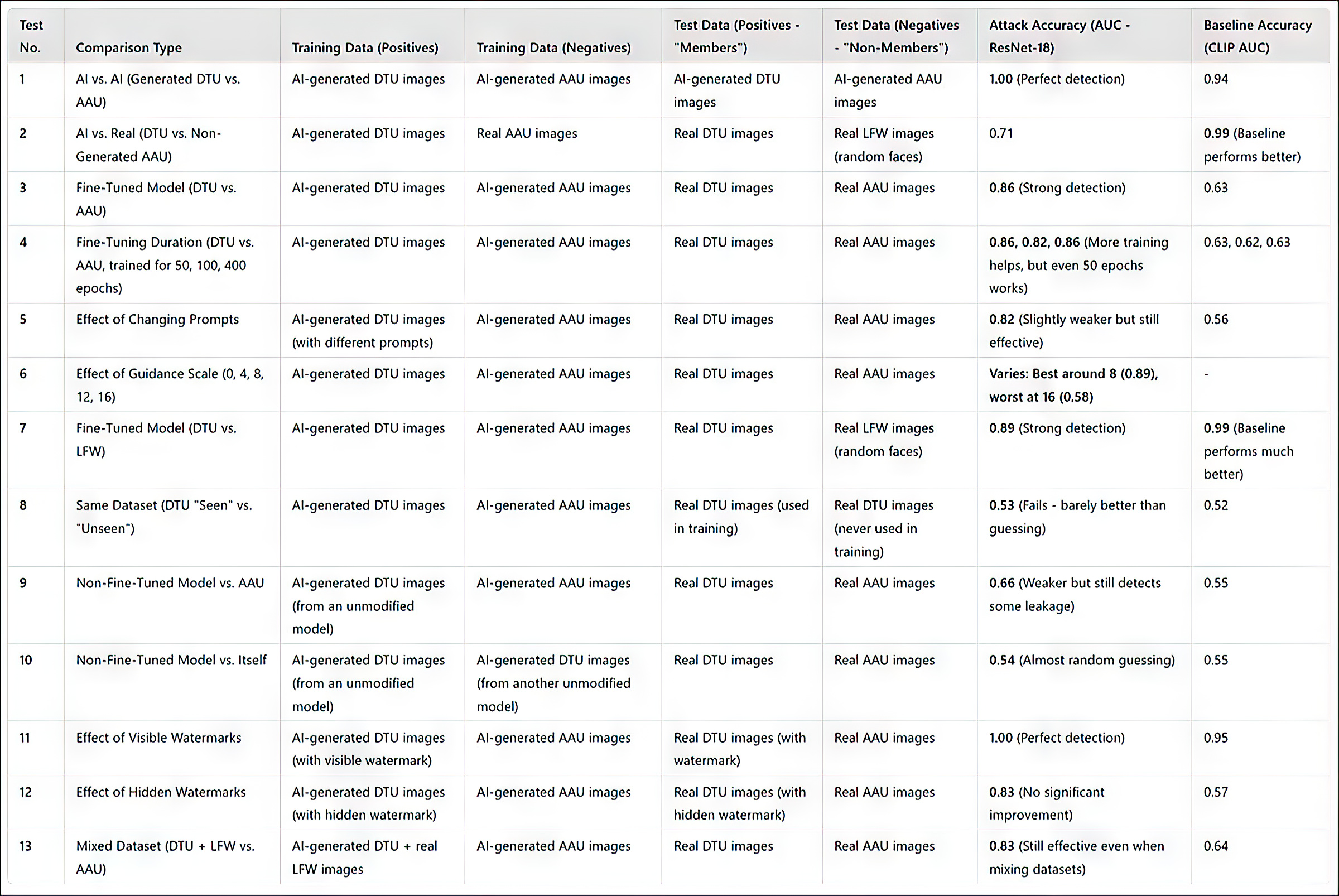
Abstract of outcomes from all checks. Click on on the picture to see increased decision
The researchers’ assault technique proved best when focusing on fine-tuned fashions, notably these educated on a selected set of photos, reminiscent of a person’s face. Nevertheless, whereas the assault can decide whether or not a dataset was used, it struggles to determine particular person photos inside that dataset.
In sensible phrases, the latter will not be essentially a hindrance to utilizing an strategy reminiscent of this forensically; whereas there’s comparatively little worth in establishing {that a} well-known dataset reminiscent of ImageNet was utilized in a mannequin, an attacker on a non-public particular person (not a star) will are likely to have far much less alternative of supply knowledge, and want to completely exploit out there knowledge teams reminiscent of social media albums and different on-line collections. These successfully create a ‘hash’ which may be uncovered by the strategies outlined.
The paper notes that one other means to enhance accuracy is to make use of AI-generated photos as ‘non-members’, fairly than relying solely on actual photos. This prevents artificially excessive success charges that might in any other case mislead the outcomes.
A further issue that considerably influences detection, the authors notice, is watermarking. When coaching photos include seen watermarks, the assault turns into extremely efficient, whereas hidden watermarks provide little to no benefit.

The appropriate-most determine exhibits the precise ‘hidden’ watermark used within the checks.
Lastly, the extent of steerage in text-to-image era additionally performs a task, with the best stability discovered at a steerage scale of round 8. Even when no direct immediate is used, a fine-tuned mannequin nonetheless tends to supply outputs that resemble its coaching knowledge, reinforcing the effectiveness of the assault.
Conclusion
It’s a disgrace that this fascinating paper has been written in such an inaccessible method, appropriately of some curiosity to privateness advocates and informal AI researchers alike.
Although membership inference assaults could change into an fascinating and fruitful forensic software, it’s extra vital, maybe, for this analysis strand to develop relevant broad ideas, to forestall it ending up in the identical sport of whack-a-mole that has occurred for deepfake detection basically, when the discharge of a more moderen mannequin adversely impacts detection and comparable forensic programs.
Since there’s some proof of a higher-level guideline cleaned on this new analysis, we will hope to see extra work on this route.
First revealed Friday, February 21, 2025