In our fast-paced digital age, accessing essentially the most present info rapidly is extra vital than ever. Conventional sources usually fall brief, both as a result of they’re outdated or just unavailable after we want them essentially the most. That is the place the idea of a real-time, web-enhanced Agentic RAG utility steps in, providing a groundbreaking answer. By harnessing the capabilities of LangChain and LLMs for language understanding and Tavily for real-time net information integration, builders can create purposes that transcend the restrictions of static databases.
This progressive strategy allows the appliance to scour the net for the newest info, making certain that customers obtain essentially the most related and present solutions to their queries. It’s an clever assistant that doesn’t simply reply with pre-loaded info however actively seeks out and incorporates new information in actual time. This text goals to information you thru the event of such an utility, addressing potential challenges like sustaining accuracy and making certain speedy responses. The aim is to democratize entry to info, making it as up-to-date and accessible as attainable, thereby eradicating the boundaries to the wealth of data accessible on the web. Be part of us in exploring easy methods to construct an AI-powered, web-enhanced Agentic RAG Utility that places the world’s info at your fingertips.

Studying Goals
- Achieve a complete understanding of constructing a state-of-the-art, real-time Agentic Retrieval-Augmented Technology (RAG) utility.
- Study to combine superior applied sciences seamlessly into your utility.
This text was printed as part of the Knowledge Science Blogathon.
What’s Agentic RAG and How Does it Work?
Agentic Retrieval-Augmented Technology (RAG) is a sophisticated framework that coordinates a number of instruments to deal with complicated duties by integrating info retrieval with language era. This technique enhances conventional RAG by using specialised instruments, every centered on distinct subtasks, to provide extra correct and contextually related outputs. The method begins by decomposing a posh drawback into smaller, manageable subtasks, with every device dealing with a particular side of the duty. These instruments work together via a shared reminiscence or message-passing mechanism, permitting them to construct upon one another’s outputs and refine the general response.
Sure instruments are outfitted with retrieval capabilities, enabling entry to exterior information sources equivalent to databases or the Web. This ensures that the generated content material is grounded in correct and up-to-date info. After processing their respective duties, the instruments mix their findings to generate a coherent and complete closing output that addresses the unique question or activity.
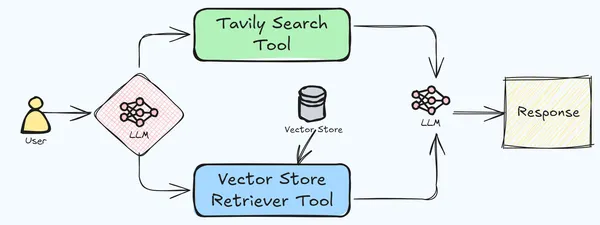
This strategy gives a number of advantages, together with specialization, the place every device excels in a selected space, resulting in extra exact dealing with of complicated duties; scalability, because of the modular nature of the system, permitting for simple adaptation to varied purposes and domains; and decreased hallucination, as incorporating a number of instruments with retrieval capabilities allows cross-verification of knowledge, minimizing the chance of producing incorrect or fabricated content material. In our present utility, we’ll use the Tavily net search and vector retailer retrieval instruments to create a sophisticated RAG pipeline.
Expertise Essential to Implement
The data and expertise essential to implement this answer successfully.
- Tavily Search API: From their docs, Tavily Search API is a search engine optimized for LLMs, aimed toward environment friendly, fast and chronic search outcomes.’ Utilizing the Tavily API, we will simply combine real-time net search into LLM-based purposes. LangChain has integration of Tavily API for real-time net search, which searches for related info from the net based mostly on the consumer’s question. Tavily API has the potential to fetch related info from a number of sources, which incorporates the URL, related pictures and the content material, all in a structured JSON format. This fetched info is then used as a context for LLM to reply the consumer’s question. We will likely be constructing an agent using the Tavily integration of LangChain that will likely be utilized by the pipeline to reply queries when the LLM will not be in a position to reply from the supplied doc.
- OpenAI GPT-4 Turbo: We will likely be utilizing OpenAI’s GPT 4 Turbo mannequin for this experiment, however you should utilize any mannequin for this pipeline, together with native fashions. Please don’t use OpenAI’s GPT 4o mannequin, as it’s seen to not carry out effectively on agentic purposes.
- Apple’s 2023 10-Ok Doc: We will likely be utilizing the 10K Annual studies doc for this experiment, however you should utilize any doc of alternative.
- Deeplake Vector Retailer: For this utility, we will likely be utilizing the Deeplake vector retailer. It’s quick and light-weight, which helps keep the latency of the appliance.
- Easy SQL Chat Reminiscence (optionally available): Moreover, we’ll implement a primary SQL-based chat reminiscence system for sustaining context and continuity throughout interactive chat classes. That is optionally available however protecting it within the utility enhances consumer expertise.
Implementation of Agentic RAG Utility
Now we’ll stroll via the creation of this easy, but highly effective Retrieval-Augmented Technology (RAG) system designed to reply consumer queries with excessive accuracy and relevance. The code outlined under demonstrates easy methods to combine these parts right into a cohesive utility able to retrieving info each from a particular doc and the huge assets of the net. Let’s dive into the specifics of the implementation, analyzing how every a part of the code contributes to the general performance of the system.
Creating Setting
First, create an atmosphere utilizing the below-mentioned packages-
#set up dependencies
deeplake==3.9.27
ipykernel==6.29.5
ipython==8.29.0
jupyter_client==8.6.3
jupyter_core==5.7.2
langchain==0.3.7
langchain-community==0.3.5
langchain-core==0.3.15
langchain-experimental==0.3.3
langchain-openai
langchain-text-splitters==0.3.2
numpy==1.26.4
openai==1.54.4
pandas==2.2.3
pillow==10.4.0
PyMuPDF==1.24.13
tavily-python==0.5.0
tiktoken==0.8.0Setting Setup and Preliminary Configurations: First, the required libraries are imported. This units up the inspiration for the appliance to work together with varied companies and functionalities.
Preliminary Configurations
import os
from langchain_core.prompts import (
ChatPromptTemplate,
)
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.brokers import AgentExecutor, create_openai_tools_agent
from langchain.instruments.retriever import create_retriever_tool
from langchain.instruments.tavily_search import TavilySearchResults
from langchain.vectorstores.deeplake import DeepLake
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.reminiscence import ConversationBufferWindowMemory, SQLChatMessageHistoryTavily Search Software Configuration
Tavily Search Software Configuration: Subsequent, the TavilySearchResults device is configured for net searches, setting parameters like max_results and search_depth. First, we export the Tavily API key as os atmosphere. You may get your personal Tavily API key from right here, by producing a brand new one.
os.environ["TAVILY_API_KEY"] = "tavily_api_key"
search_tool = TavilySearchResults(
identify="tavily_search_engine",
description="A search engine optimized for retrieving info from net based mostly on consumer question.",
max_results=5,
search_depth="superior",
include_answer=True,
include_raw_content=True,
include_images=True,
verbose=False,
)Chat OpenAI Configuration
Chat OpenAI Configuration: The Chat OpenAI mannequin is configured with the GPT-4 mannequin particulars and API keys. Notice that any Chat mannequin can be utilized for this use-case. Test the LangChain documentation for the mannequin you want to use and modify the code accordingly.
llm = ChatOpenAI(
mannequin="gpt-4",
temperature=0.3,
api_key="openai_api_key",
)Defining the Immediate Template
Defining the Immediate Template: A ChatPromptTemplate is outlined to information the chatbot’s interplay with customers, emphasizing the usage of doc context and net search.
immediate = ChatPromptTemplate([
("system",
f"""You are a helpful chatbot. You need to answer the user's queries in
detail from the document context. You have access to two tools:
deeplake_vectorstore_retriever and tavily_search_engine.
Always use the deeplake_vectorstore_retriever tool first to retrieve
the context and answer the question. If the context does not contain relevant
answer for the user's query, use the tavily_search_engine to fetch web search
results to answer them. NEVER give an incomplete answer. Always try your best
to find answer through web search if answer is not found from context."""),
("human", "{user_input}"),
("placeholder", "{messages}"),
("placeholder", "{agent_scratchpad}"),
])Doc Pre-processing and Ingestion
Doc Pre-processing and Ingestion: The doc is loaded, cut up into chunks, and these chunks are processed to create embeddings, that are then saved in a DeepLake vector retailer.
information = "Apple 10k 2023.pdf"
loader = PyMuPDFLoader(file_path=information)
text_splitter = CharacterTextSplitter(separator="n", chunk_size=1000, chunk_overlap=200)
docs = loader.load_and_split(text_splitter=text_splitter)
embeddings = OpenAIEmbeddings(api_key="openai_api_key",)
vectorstore = DeepLake(dataset_path="dataset", embedding=embeddings,)
_ = vectorstore.add_documents(paperwork=docs)Creating the Retrieval device
Creating the Retrieval device: A retrieval device is created from the vector retailer to facilitate doc search.
retriever_tool = create_retriever_tool(
retriever=vectorstore.as_retriever(
search_type="similarity",
search_kwargs={
"ok": 6,
"fetch_k": 12,
},
),
identify="deeplake_vectorstore_retriever",
description="Searches and returns contents from uploaded Apple SEC doc based mostly on consumer question.",
)
instruments = [
retriever_tool,
search_tool,
]Implementing a easy chat historical past/reminiscence (Non-compulsory): An SQL-based chat reminiscence is configured for sustaining the context. A SQLite database will likely be created and the chat conversations will likely be saved in that.
historical past = SQLChatMessageHistory(
session_id="ghdcfhdxgfx",
connection_string="sqlite:///chat_history.db",
table_name="message_store",
session_id_field_name="session_id",
)
reminiscence = ConversationBufferWindowMemory(chat_memory=historical past)Initializing the Agent and Agent Executor
Initializing the Agent and Agent Executor: An agent is created and executed to course of consumer queries and generate responses based mostly on the configured instruments and reminiscence.
agent = create_openai_tools_agent(llm, instruments, immediate)
agent_executor = AgentExecutor(
instruments=instruments,
agent=agent,
verbose=False,
max_iterations=8,
early_stopping_method="power",
reminiscence=reminiscence,
)Testing the pipeline on a couple of samples: With this, we now have our RAG with Actual-time search pipeline is prepared. Let’s take a look at the appliance with some queries.
consequence = agent_executor.invoke({
"user_input": "What's the fiscal 12 months highlights of Apple inc. for 2nd quarter of 2024?",
},)
print(consequence["output"])Output
The doc doesn't comprise particular details about the fiscal 12 months
highlights of Apple Inc. for the 2nd quarter of 2024. The newest info
contains:Whole Web Gross sales and Web Revenue: Apple's whole internet gross sales have been $383.3 billion,
and internet revenue was $97.6 billion throughout 2023.Gross sales Efficiency: There was a 3% lower in whole internet gross sales in comparison with
2022, amounting to an $11.0 billion discount. This lower was attributed
to forex trade headwinds and weaker shopper demand.Product Bulletins: Vital product bulletins throughout fiscal 12 months
2023 included:First Quarter: iPad and iPad Professional, Subsequent-generation Apple TV 4K, and MLS Season
Go (a Main League Soccer subscription streaming service).
Second Quarter: MacBook Professional 14", MacBook Professional 16", and Mac mini; Second-
era HomePod.
Third Quarter: MacBook Air 15", Mac Studio and Mac Professional; Apple Imaginative and prescient Professional™
(the corporate's first spatial laptop that includes its new visionOS).
Fourth Quarter: iPhone 15 collection (iPhone 15, iPhone 15 Plus, iPhone 15 Professional,
and iPhone 15 Professional Max); Apple Watch Collection 9 and Apple Watch Extremely 2.
Share Repurchase Program: In Might 2024, Apple introduced a brand new share repurchase
program of as much as $90 billion and raised its quarterly dividend.For the particular particulars relating to the 2nd quarter of 2024, it will be
essential to seek the advice of Apple's official publications or monetary studies.
The question that we requested was associated to 2024, for which the mannequin replied that the context has no info for 2024 highlights and offers the small print for 2023, which it will get from the vector retailer. Subsequent, let’s strive asking the identical query however for Nvidia.
consequence = agent_executor.invoke({
"user_input": "What's the fiscal 12 months highlights of Nvidia inc. for 2nd quarter of 2024?",
},)
print(consequence["output"])Output
The textual content from the picture is:For the 2nd quarter of the fiscal 12 months 2024, Nvidia Inc. reported distinctive
development, notably pushed by its Knowledge Heart phase. Listed below are the
highlights:Whole Revenues: Nvidia's whole income noticed a major improve, up 101%
year-over-year (YOY) to $13.51 billion, which was above the outlook.Knowledge Heart Income: The Knowledge Heart phase skilled a exceptional development
of 171% YOY, reaching $10.32 billion. This development underscores the robust
demand for AI-related computing options.Gaming Income: The Gaming phase additionally noticed development, up 22% YOY to $2.49
billion.Report Knowledge Heart Income: Nvidia achieved a document in Knowledge Heart income,
highlighting the robust demand for its services.These outcomes mirror Nvidia's robust place out there, notably in
areas associated to accelerated computing and AI platforms. The corporate
continues to profit from developments in synthetic intelligence and machine
studying.For extra detailed info, you'll be able to discuss with Nvidia's official press
launch relating to their monetary outcomes for the second quarter of fiscal
12 months 2024.
Additionally learn: RAG vs Agentic RAG: A Complete Information
Key Takeaways
- Integration of Superior Applied sciences: Combines instruments like LangChain, Azure OpenAI, Tavily Search API, and DeepLake vector shops to create a sturdy system for info retrieval and NLP.
- Retrieval-Augmented Technology (RAG): Blends real-time net search, doc retrieval, and conversational AI to ship correct and context-aware responses.
- Environment friendly Doc Administration: Makes use of DeepLake vector shops for fast retrieval of related doc sections, optimizing giant doc dealing with.
- Azure OpenAI Language Modeling: Leverages GPT-4 for coherent, human-like, and contextually applicable responses.
- Dynamic Internet Search: Tavily Search API enriches responses with real-time net info for complete solutions.
- Context and Reminiscence Administration: SQL-based chat reminiscence ensures coherent, context-aware interactions throughout classes.
- Versatile, Scalable Structure: Modular and configurable design helps simple growth with further fashions, info sources, or options.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.
Conclusion
On this article, we explored the creation of a real-time, Agentic RAG Utility utilizing LangChain, Tavily, and OpenAI GPT-4. This highly effective integration of applied sciences allows the appliance to offer correct, contextually related solutions by combining doc retrieval, real-time net search, and conversational reminiscence. Our information presents a versatile and scalable strategy, adaptable to varied fashions, information sources, and functionalities. By following these steps, builders can construct superior AI-powered options that meet right this moment’s demand for up-to-date and complete info accessibility.
In case you are on the lookout for an RAG course on-line then discover: RAG Systemt Necessities.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.
Continuously Requested Questions
Ans. The first objective of Agentic RAG utility is to offer correct, real-time solutions by combining doc retrieval, real-time net search, and language era. It leverages specialised instruments for subtasks, making certain exact and contextually related responses.
Ans. The Tavily Search API integrates real-time net search into the system, fetching up-to-date, related info in a structured JSON format. It gives further context to queries that can not be answered by pre-loaded doc information alone.
Ans. DeepLake serves because the vector retailer for storing doc embeddings. It permits for environment friendly retrieval of related doc chunks based mostly on similarity search, making certain the appliance can rapidly entry and use the required info.
An ace multi-skilled programmer whose main space of labor and curiosity lies in Software program Improvement, Knowledge Science, and Machine Studying. A proactive and detail-oriented particular person who loves information storytelling, and is curious and passionate to unravel complicated value-oriented enterprise issues with Knowledge Science and Machine Studying to ship strong machine studying pipelines that guarantee most affect.
In my free time, I give attention to creating Knowledge Science and AI/ML content material, offering 1:1 mentorships, profession steerage and interview preparation suggestions, with a sole give attention to instructing complicated matters the better manner, to assist folks make a profitable profession transition to Knowledge Science with the correct skillset!