Introduction
We have already mentioned that Python is essentially the most highly effective programming language, especially in knowledge science and Gen-AI. When working with voluminous knowledge, it’s actually essential to grasp methods to manipulate (retailer, handle, and entry) it effectively.
We’ve additionally explored numbers and strings and the way they’re saved in reminiscence earlier than, which yow will discover right here. On this half, we’ll dive deep into the flexibility of Python’s Constructed-in Information Buildings and perceive the distinction between Mutable and Immutable Objects.

Overview
- Python’s Energy: Python is a flexible programming language, particularly for knowledge science and Gen-AI.
- Information Buildings Overview: This part discusses built-in knowledge buildings, equivalent to lists, arrays, tuples, dictionaries, units, and frozen units.
- Lists: Mutable, dynamic arrays; heterogeneous gadgets; varied manipulation strategies.
- Arrays vs. Lists: Arrays are homogeneous and memory-efficient; lists are versatile and help varied knowledge varieties.
- Tuples: Immutable collections; sooner and consumes much less reminiscence than lists; appropriate for mounted collections.
- Dictionaries: Key-value pairs; mutable and versatile; used for counting, reversing, memoization, and sorting advanced knowledge.
What are the Python Constructed-in Information Buildings?
An information construction is a container that shops knowledge in an organized manner that may be accessed and manipulated each time crucial. This text will talk about the Python built-in Information Buildings: lists, Arrays, Tuples, Dictionaries, Units, and Frozen Units.
Moreover, right here’s the Python pocket book, which you need to use as a fast syntax reference.
Additionally learn: A Full Python Tutorial to Be taught Information Science from Scratch
A. Working with Lists
Record literal
The record is a Python built-in datatype used to retailer gadgets of various datatypes in a single variable.
Technically, python lists are like dynamic arrays, which means they’re mutable as they’re extra versatile to modifications.
Notice: The values held by the record are separated by commas (,) and enclosed inside sq. brackets([]).
Creating Lists
# 1D Record -- Homogeneous Record
numbers = [1,7,8,9]
print(numbers)
# Heterogenous Record
list1 = record(1, True, 20.24, 5+8j, "Python")
print("Heterogenous record: ", list1)Output
[1, 7, 8, 9][1, True, 20.24, 5+8j, "Python"]
Array in Python
In Python, an array is an information construction that shops a number of values of the identical knowledge sort.
Notice: Python arrays should not a built-in knowledge sort like lists supplied by Java or CPP, although they supply an `array` module for environment friendly storage of homogeneous knowledge, equivalent to integers or floats.
from array import array
arr = array('i', [1, 2, 3])
print(arr)Output
array('i', [1, 2, 3])
Array VS Lists (Dynamic Array)
| Function | Array (Utilizing array module) | Record (Dynamic Array in Python) |
|---|---|---|
| Information Sort | Homogeneous (similar knowledge sort) | Heterogeneous (completely different knowledge varieties) |
| Syntax | array(‘i’, [1, 2, 3]) | [1, 2, 3] |
| Reminiscence Effectivity | Extra reminiscence environment friendly | Much less reminiscence environment friendly |
| Velocity | Sooner for numerical operations | Slower for numerical operations |
| Flexibility | Much less versatile (restricted to particular knowledge varieties) | Extra versatile (can retailer any knowledge sort) |
| Strategies | Restricted built-in strategies | Wealthy set of built-in strategies |
| Module Required | Sure, from array import array | No module required |
| Mutable | Sure | Sure |
| Indexing and Slicing | Helps indexing and slicing | Helps indexing and slicing |
| Use Case | Most well-liked for giant arrays of numbers | Common-purpose storage of components |
Reverse a Record with Slicing
knowledge = [1, 2, 3, 4, 5]
print("Reversed of the string : ", knowledge[::-1])Output
Reversed of the string : [5, 4, 3, 2, 1]
Strategies to Traverse a Record
- item-wise loop: We will iterate item-wise over a loop utilizing the vary(len()) perform.
# item-wise
l1 = ["a", "b", "c"]
for i in vary(len(l1)):
print(l1[i])Output
ab
c
- index-wise loop: Utilizing vary(0, len()) perform we are able to iterate index-wise over a loop.
# index-wise
l1 = ["a", "b", "c"]
for i in vary(0, len(l1)):
print(l1[i])Output
01
2
The record can comprise/retailer any objects in Python
l = [1, 3.5, "hi", [1, 2, 3], sort, print, enter]
print(l)Output
[1, 3.5, 'hi', [1, 2, 3], <class 'sort'>, <built-in perform print>, <sure
methodology Kernel.raw_input of <google.colab._kernel.Kernel object at
0x7bfd7eef5db0>>]
keyboard_arrow_down
Reverse a Record utilizing the reverse() methodology
reverse(): Completely reverses the weather of the record in place.
knowledge = [1, 2, 3, 4, 5]
knowledge.reverse()
print("Reversed of the string : ", knowledge)Output
Reversed of the string : [5, 4, 3, 2, 1]
Record “reversed” perform
reversed(sequence): Returns the reversed iterator object of a given sequence. Notice that this isn’t a everlasting change to an inventory.
fruits = ['apple', 'banana', 'orange', 'grape', 'kiwi', 'apple']
for fruit in reversed(fruits):
print(fruit, finish=" ")Output
apple kiwi grape orange banana apple
in-place strategies
Python operates “IN PLACE”, like [].type and [].reverse. The algorithm doesn’t use additional house to control the enter however might require a small, non-constant additional house for its operation.
sort_data = [3, 2, 1]
print("Deal with of authentic record is: ", id(sort_data))
sort_data.type()
print("Sorted record is: ", sort_data)
print("Deal with of Sorted record is: ", id(sort_data))
sort_data.reverse()
print("Reversed record is: ", sort_data)
print("Deal with of Reversed record is: ", id(sort_data))Output
Deal with of authentic record is: 2615849898048Sorted record is: [1, 2, 3]
Deal with of Sorted record is: 2615849898048
Reversed record is: [3, 2, 1]
Deal with of Reversed record is: 2615849898048
Therefore, all three addresses are the identical.
Changing “record” vs. Changing record’s “content material”
# Modifies argument go in (Substitute the record with new record)
def replace_list(knowledge):
"""
The perform `replace_list(knowledge)` is creating a brand new native variable `knowledge` and assigning it the worth `['Programming Languages']`.
This doesn't modify the unique record `programming_languages` that was handed as an argument.
"""
knowledge = ['Programming Languages']
# Does not Modifies argument go in (Change the info of the record)
def replace_list_content(knowledge):
"""
The perform `replace_list_content` is modifying the content material of the record handed as an argument.
It makes use of the slice project `knowledge[:]` to switch all the weather within the record with the brand new record `['Programming Languages']`.
Which means that the unique record `programming_languages` will likely be modified and can now comprise solely the ingredient `'Programming Languages'`.
"""
knowledge[:] = ['Programming Languages']
# If you want to maintain similar id simply use slicing
programming_languages = ['C', 'C++', 'JavaScript', 'Python']
print("Authentic record of languages is:", programming_languages)
# When perform modifies the passed-in argument:
replace_list(programming_languages)
print("Modified record of languages is:", programming_languages)
# When perform modifies the content material of the passed-in argument:
replace_list_content(programming_languages)
print("Unmodified record of languages is:", programming_languages) Output
Authentic record of languages is: ['C', 'C++', 'JavaScript', 'Python']Modified record of languages is: ['C', 'C++', 'JavaScript', 'Python']
Unmodified record of languages is: ['Programming Languages']
Copying a Record utilizing “Slicing”
# Don't level to similar actual record deal with within the reminiscence even whether it is copied
programming_languages = ['C', 'C++', 'JavaScript', 'Python']
learning_programming_lamnguages = programming_languages[:]
print("Id of 'programming_languages' is :", id(programming_languages), "n" "Id of 'learning_programming_languages' is :", id(learning_programming_lamnguages))Output
Id of 'programming_languages' is : 1899836578560Id of 'learning_programming_languages' is : 1899836579328
Copying a Record utilizing “copy()” methodology
copy(): Return a shallow copy of ‘programming_language.’ If there are any Nested objects, simply the reference to these objects is what’s copied (deal with), and the info object itself is just not copied.
programming_languages = ['C', 'C++', 'JavaScript', 'Python']
learning_programming_languages = programming_languages.copy()
print("Id of 'programming_languages' is :", id(programming_languages), "n" "Id of 'learning_programming_languages' is :", id(learning_programming_languages))Output
Id of 'programming_languages' is : 1899836614272Id of 'learning_programming_languages' is : 1899836577536
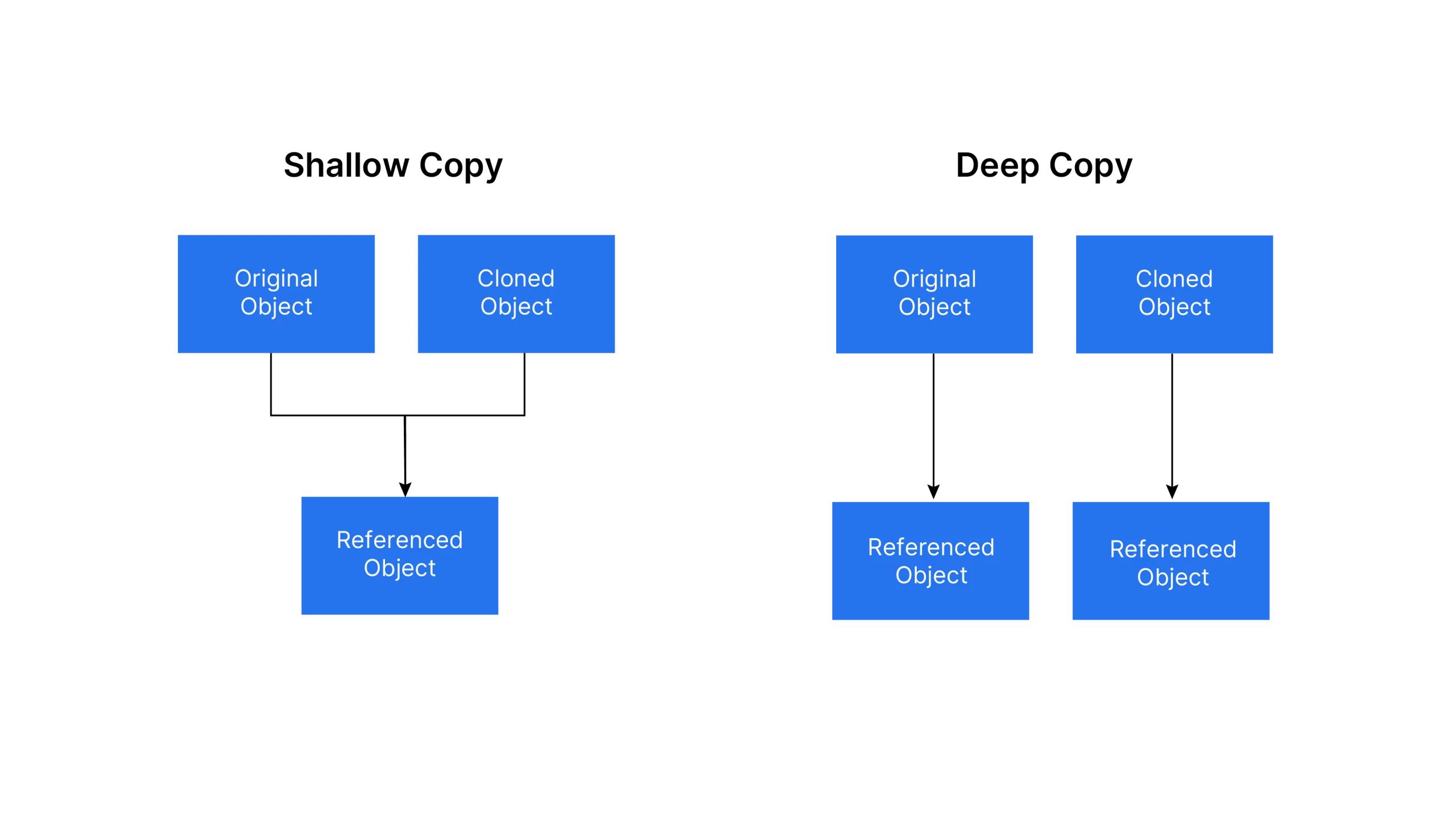
Copying a Record utilizing “deepcopy()”
Deepcopy(): Creates a brand new compound object after which recursively inserts copies of the objects discovered within the authentic into it.
import copy
original_list = [1, [2, 3], [4, 5]]
shallow_copied_list = copy.copy(original_list)
deep_copied_list = copy.deepcopy(original_list) # To make use of 'deepcopy' : from copy import deepcopy
# Modify the unique record
original_list[1][0] = 'X'
print("Authentic Record:", original_list)
print("Shallow Copied Record:", shallow_copied_list)
print("Deep Copied Record:", deep_copied_list)Output
Authentic Record: [1, ['X', 3], [4, 5]]Shallow Copied Record: [1, ['X', 3], [4, 5]]
Deep Copied Record: [1, [2, 3], [4, 5]]
Concatenating lists utilizing “+” Operator
x = [1, 2, 3]
y = [4, 5, 6]
z = [7, 8, 9]
print("The concatenated record is:", x + y + z)Output
The concatenated record is: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Use vary to generate lists
print(record(vary(0, 10, 3)))
print(sort(vary(0, 10, 3))) # python 3Output
[0, 3, 6, 9]<class 'vary'>
Create a Record utilizing Comprehension
Right here, on this instance, we are able to take away sure components from an inventory as a substitute of utilizing “for row” loops.
fruits = ['apple', 'banana', 'orange', 'grape', 'kiwi', 'apple']
removing_fruits = [fruit for fruit in fruits if fruit not in ["kiwi", "apple"]]
print("Fruits are: ", removing_fruits)Output
Fruits are: ['banana', 'orange', 'grape']
Nested-if with Record Comprehension
startswith(): Checks if the string begins with the required prefix.
fruits = ["apple", "orange", "avacado", "kiwi", "banana"]
basket = ["apple", "avacado", "apricot", "kiwi"]
[i for i in fruits if i in basket if i.startswith("a")]Output
['apple', 'avacado']
“flatten” an inventory of nested lists
nested_list = [[1, 2, 3], [4, 5], [6, 7, 8]]
# Methodology 1: Utilizing Nested Loop:
flattened_list = []
for sublist in nested_list:
for merchandise in sublist:
flattened_list.append(merchandise)
print("Flattened Record (utilizing nested loop):", flattened_list)
# Methodology 2: Utilizing Record Comprehension:
flattened_list = [item for sublist in nested_list for item in sublist]
print("Flattened Record (utilizing record comprehension):", flattened_list)
# Methodology 3 : Utilizing Recursive Perform:
def flatten_list(nested_list):
flattened_list = []
for merchandise in nested_list:
if isinstance(merchandise, record):
flattened_list.prolong(flatten_list(merchandise))
else:
flattened_list.append(merchandise)
return flattened_list
nested_list = [[1, 2, 3], [4, 5], [6, 7, [8, 9]]]
flattened_list_recursive = flatten_list(nested_list)
print("Flattened Record (utilizing recursive perform):", flattened_list_recursive)Output
Flattened Record (utilizing nested loop): [1, 2, 3, 4, 5, 6, 7, 8]Flattened Record (utilizing record comprehension): [1, 2, 3, 4, 5, 6, 7, 8]
Flattened Record (utilizing recursive perform): [1, 2, 3, 4, 5, 6, 7, 8, 9]
Area-separated numbers to integer record
map(): Runs the particular perform for each ingredient within the iterable.
user_input = "1 2 3 4 5"
new_list = record(map(int, user_input.break up()))
print("The record: ", new_list)Output
The record: [1, 2, 3, 4, 5]
Mix two lists as an inventory of lists
zip(): Returns an aggregated tuple iterable of a number of iterables.
# Totally different set of names and factors
names = ['Alice', 'Bob', 'Eva', 'David']
factors = [80, 300, 50, 450]
zipped = record(zip(names, factors))
print(zipped)Output
[('Alice', 80), ('Bob', 300), ('Eva', 50), ('David', 450)]
Convert an inventory of tuples to record of lists
# Totally different set of names and factors
names = ['Alice', 'Bob', 'Eva', 'David']
factors = [80, 300, 50, 450]
zipped = record(zip(names, factors))
knowledge = [list(item) for item in zipped]
print(knowledge)Output
[['Alice', 80], ['Bob', 300], ['Eva', 50], ['David', 450]]
B. Working with Tuple/s
Tuple literal
A Python tuple is an immutable assortment of various knowledge varieties. The values are enclosed with comma-separated (,) contained in the parentheses or small brackets ‘()‘.
even_number = (2, 4, 6, 8)
print(even_number)
odd_number = (1, 3, 5, 7)
print(odd_number)Output
(2, 4, 6, 8)(1, 3, 5, 7)
Distinction between Lists and Tuples
They’re each completely different based mostly on beneath the next:
| Function | Lists | Tuples |
|---|---|---|
| Syntax | list_variable = [1, 2, 3] | tuple_variable = (1, 2, 3) |
| Mutability | Mutable (could be modified) | Immutable (can’t be modified) |
| Velocity | Slower attributable to dynamic nature | Sooner attributable to immutability |
| Reminiscence | Consumes extra reminiscence | Consumes much less reminiscence |
| Constructed-in Performance | Intensive built-in features and strategies (e.g., append, prolong, take away) | Restricted built-in features (e.g., depend, index) |
| Error Inclined | Extra error-prone attributable to mutability | Much less error-prone attributable to immutability |
| Usability | Appropriate for collections of things that will change over time | Appropriate for collections of things which might be mounted and shouldn’t change |
Velocity
- Lists: The Python record is slower attributable to its dynamic nature due to mutability.
- Tuples: Python tuples are sooner due to their immutable nature.
import time
# Create a big record and tuple
sample_list = record(vary(100000))
sample_tuple = tuple(vary(100000))
begin = time.time()
# Outline a perform to iterate over an inventory
for ingredient in sample_list:
ingredient * 100
print(f"Record iteration time: {time.time()-start} seconds")
begin = time.time()
# Outline a perform to iterate over a tuple
for ingredient in sample_tuple:
ingredient * 100
print(f"Tuple iteration time: {time.time()-start} seconds")
Output
Record iteration time: 0.009648799896240234 secondsTuple iteration time: 0.008893728256225586 seconds
Reminiscence
- Lists: As a consequence of their mutability and dynamic nature, lists require extra reminiscence to carry up to date components.
- Tuples: Tuples are immutable; therefore, they’ve a hard and fast measurement within the reminiscence.
import sys
list_ = record(vary(1000))
tuple_ = tuple(vary(1000))
print('Record measurement',sys.getsizeof(list_))
print('Tuple measurement',sys.getsizeof(tuple_))Output
Record measurement 8056Tuple measurement 8040
Error Inclined
- Lists: Mark this! Python lists are vulnerable to errors attributable to their mutable nature, which might happen attributable to unintended modifications.
a = [1, 3, 4]
b = a
print(a)
print(b)
print(id(a))
print(id(b))
a.append(2)
print(a)
print(b)
print(id(a))
print(id(b))
Output
[1, 3, 4][1, 3, 4]
134330236712192
134330236712192
[1, 3, 4, 2]
[1, 3, 4, 2]
134330236712192
134330236712192
- Tuples: Python tuples are much less vulnerable to errors than lists as a result of they don’t permit modifications and supply a hard and fast construction.
a = (1,2,3)
b = a
print(a)
print(b)
print(id(a))
print(id(b))
a = a + (4,)
print(a)
print(b)
print(id(a))
print(id(b))Output
(1, 2, 3)(1, 2, 3)
134330252598848
134330252598848
(1, 2, 3, 4)
(1, 2, 3)
134330236763520
134330252598848
Returning a number of values and Assigning to a number of variables
def returning_position():
#get from consumer or one thing
return 5, 10, 15, 20
print("A tuple", returning_position())
x, y, z, a = returning_position()
print("Assigning to a number of variables: ", "x is", x, "y is", y,"z is", z,"a is", a)Output
A tuple (5, 10, 15, 20)Assigning to a number of variables: x is 5 y is 10 z is 15 a is 20
Create a Tuple Utilizing Mills
There isn’t a such factor as Tuple Comprehension. However you need to use Generator Expressions, which is a memory-efficient different.
# Generator expression transformed to a tuple
tuple(i**2 for i in vary(10))Output
(0, 1, 4, 9, 16, 25, 36, 49, 64, 81)
Tuple zip() perform
t1 = ["a", "b", "c"]
t2 = [1, 2, 3]
tuple(zip(t1, t2))Output
(('a', 1), ('b', 2), ('c', 3))
Additionally learn: Every part You Ought to Know About Information Buildings in Python
C. Working with Dictionary/s
Dictionary Literal
The dictionary is the mutable datatype that shops the info within the key-value pair, enclosed by curly braces ‘{}‘.
alphabets = {'a': 'apple', 'b': 'ball', 'c': 'cat'}
print(alphabets)
info = {'id': 20, 'identify': 'amit', 'wage': 20000.00, }
print(info)Output
{'a': 'apple', 'b': 'ball', 'c': 'cat'}{'id': 20, 'identify': 'amit', 'wage': 20000.00,}
2D Dictionary is JSON
The 2D Dictionary or the nested dictionary is often known as a JSON File. If you wish to depend what number of instances every letter seems in a given string, you need to use a dictionary for this.
j = {
'identify':'Nikita',
'faculty':'NSIT',
'sem': 8,
'topics':{
'dsa':80,
'maths':97,
'english':94
}
}
print("JSON format: ", j)Output
JSON format: {'identify': 'Nikita', 'faculty': 'NSIT', 'sem': 8, 'topics':
{'dsa': 80, 'maths': 97, 'english': 94}}
Including a brand new key-value pair to the nested dictionary
j['subjects']['python'] = 90
print("Up to date JSON format: ", j)Up to date JSON format: {‘identify’: ‘Nikita’, ‘faculty’: ‘NSIT’, ‘sem’: 8, ‘topics’: {‘dsa’: 80, ‘maths’: 97, ‘english’: 94, ‘python’: 90}}
Eradicating key-value pair from nested dictionary
del j['subjects']['maths']
print("Up to date JSON format: ", j)Up to date JSON format: {‘identify’: ‘Nikita’, ‘faculty’: ‘NSIT’, ‘sem’: 8, ‘topics’: {‘dsa’: 80, ‘english’: 94, ‘python’: 90}}
Dictionary as Assortment of Counters
We will additionally use a dictionary as a group of counters. For instance:
def value_counts(string):
counter = {}
for letter in string:
if letter not in counter:
counter[letter] = 1
else:
counter[letter] += 1
return counter
counter = value_counts('AnalyticalNikita')
counterOutput
{'A' : 1, 'n' : 1, 'a' : 3, 'l' : 2, 'y' : 1, 't' : 2, 'c' : 1, 'N': 1, 'i' : 2, 'ok' :1}
That is high quality, however what if we need to reverse the dictionary, i.e., key to values and values to key? Let’s do it,
Inverting the Dictionary
The next perform takes a dictionary and returns its inverse as a brand new dictionary:
def invert_dict(d):
new = {}
for key, worth in d.gadgets():
if worth not in new:
new[value] = [key]
else:
new[value].append(key)
return new
invert_dict({'A' : 1, 'n' : 1, 'a' : 3, 'l' : 2, 'y' : 1, 't' : 2,
'c' : 1, 'N': 1, 'i' : 2, 'ok' :1} )Output
{1: ['A', 'n', 'y', 'c', 'N', 'k'], 2: ['l', 't', 'i'], 3: ['l'] }
This dictionary maps integers to the phrases that seem that variety of instances as “key” to symbolize knowledge higher.
Memoized Fibonacci
When you’ve got ever run a Fibonacci perform, you will have observed that the larger the argument you present, the longer it takes to run.
One answer is to make use of dynamic programming to maintain observe of already computed values by storing them in a dictionary. The method of storing beforehand computed values for later use is known as memoization.
Here’s a “memoized” model of, The Rabbit Downside-Fibonacci Collection:
def memo_fibonacci(month, dictionary):
if month in dictionary:
return dictionary[month]
else:
dictionary[month] = memo_fibonacci(month-1, dictionary) + memo_fibonacci(month-2, dictionary)
return dictionary[month]
dictionary = {0:1, 1:1}
memo_fibonacci(48,dictionary)Output
7778742049
Kind advanced iterables with sorted()
sorted(): Returns a particular iterable’s sorted record (by default in ascending order).
dictionary_data = [{"name": "Max", "age": 6},
{"name": "Max", "age": 61},
{"name": "Max", "age": 36},
]
sorted_data = sorted(dictionary_data, key=lambda x : x["age"])
print("Sorted knowledge: ", sorted_data)Output
Sorted knowledge: [{'name': 'Max', 'age': 6}, {'name': 'Max', 'age': 36}, {'name': 'Max', 'age': 61}]
Outline default values in Dictionaries with .get() and .setdefault()
get(): Returns the worth of the dictionary for a specified key. Returns None if the worth is just not current.
setdefault(): Returns the worth of the dictionary for a specified key that isn’t current within the iterable with some default worth.
my_dict = {"identify": "Max", "age": 6}
depend = my_dict.get("depend")
print("Rely is there or not:", depend)
# Setting default worth if depend is none
depend = my_dict.setdefault("depend", 9)
print("Rely is there or not:", depend)
print("Up to date my_dict:", my_dict)Output
Rely is there or not: NoneRely is there or not: 9
Up to date my_dict: {'identify': 'Max', 'age': 6, 'depend': 9}
Merging two dictionaries utilizing **
d1 = {"identify": "Max", "age": 6}
d2 = {"identify": "Max", "metropolis": "NY"}
merged_dict = {**d1, **d2}
print("Right here is merged dictionary: ", merged_dict)Output
Right here is merged dictionary: {'identify': 'Max', 'age': 6, 'metropolis': 'NY'}
Utilizing the zip() perform to create a dictionary
days = ["Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"]
temp_C = [30.5, 32.6, 31.8, 33.4, 29.8, 30.2, 29.9]
print({i: j for (i, j) in zip(days, temp_C)})Output
{'Sunday': 30.5, 'Monday': 32.6, 'Tuesday': 31.8, 'Wednesday': 33.4, 'Thursday': 29.8, 'Friday': 30.2, 'Saturday': 29.9}
Create a Dictionary utilizing Comprehension
# Creating dictionary with squares of first 10 numbers
print({i: i**2 for i in vary(1, 11)})Output
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100}
Creating new dic utilizing current dict
# Changing forex from USD to INR
prices_usd = {'apple': 1.2, 'banana': 0.5, 'cherry': 2.5}
# New Dictionary: Convert Costs to INR
conversion_rate = 85
prices_inr = {merchandise: value * conversion_rate for merchandise, value in prices_usd.gadgets()}
print(prices_inr)Output
{'apple': 102.0, 'banana': 42.5, 'cherry': 212.5}
D. Working with Set/s
Set Literal
Python Set is the gathering of unordered knowledge. It’s enclosed by the `{}` with comma (,) separated components.
vowels = {'a', 'e', 'i', 'o', 'u'}
numbers = {1,2,2,2,2,2,29,29,11}
print(vowels)
print(numbers)Output
{'i', 'u', 'o', 'a', 'e'}
{1, 2, 11, 29}
Take away record duplicates utilizing “set”
fruits = ['apple', 'banana', 'banana', 'banana', 'kiwi', 'apple']
unique_fruits = record(set(fruits))
print("Distinctive fruits are: ", unique_fruits)Output
Distinctive fruits are: ['apple', 'kiwi', 'banana']Set Operations
Python gives the junior faculty set operations equivalent to:
- Union utilizing `|`
- Intersection utilizing `&`
- Minus/Distinction utilizing `–`
- Symmetric Distinction utilizing `^`
# Two instance units
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
# Union: Combines all distinctive components from each units.
print("Union: ", s1 | s2)
# Intersection: Finds widespread components in each units.
print("Intersection: ", s1 & s2)
# Minus/Distinction: Components in s1 however not in s2, and vice versa.
print("S1 gadgets that aren't current in S2 - Distinction: ", s1 - s2)
print("S2 gadgets that aren't current in S1 - Distinction: ", s2 - s1)
# Symmetric Distinction (^): Components in both set, however not in each.
print("Symmetric Distinction: ", s1 ^ s2)Output
Union: {1, 2, 3, 4, 5, 6, 7, 8}Intersection: {4, 5}
S1 gadgets that aren't current in S2 - Distinction: {1, 2, 3}
S2 gadgets that aren't current in S1 - Distinction: {8, 6, 7}
Symmetric Distinction: {1, 2, 3, 6, 7, 8}
In addition to these, Python gives further set performance, together with disjoint, subset, and superset.
isdisjoint()/issubset()/issuperset()
# Two instance units
s1 = {1, 2, 3, 4}
s2 = {7, 8, 5, 6}
# isdisjoint(): Checks if two units have a null intersection. (Mathematically: No widespread gadgets)
print(s1.isdisjoint(s2))
# issubset(): Checks if all components of 1 set are current in one other set.
print(s1.issubset(s2))
# issuperset(): Checks if all components of 1 set are current in one other set.
print(s1.issuperset(s2))Output
TrueFalse
False
Create a Set utilizing Comprehension.
# Making a set utilizing set comprehension with conditional
print({i**2 for i in vary(1, 11) if i > 5})Output
{64, 36, 100, 49, 81}
Units Operations on FrozenSets
Much like Units, FrozenSets even have the identical operational performance, equivalent to:
- Union
- Intersection
- Minus/Distinction
- Symmetric Distinction
# Two instance frozensets
fs1 = frozenset([1, 2, 3])
fs2 = frozenset([3, 4, 5])
print("Union: ", fs1 | fs2)
print("Intersection: ", fs1 & fs2)
print("Differencing: ", fs1 - fs2)
print("Symmetric Differencing: ", fs1 ^ fs2)Output
Union: frozenset({1, 2, 3, 4, 5})Intersection: frozenset({3})
Differencing: frozenset({1, 2})
Symmetric Differencing: frozenset({1, 2, 4, 5})
Conclusion
So, if in case you have made it this far, congratulations; you now know the way highly effective Python Information buildings are!
We’ve seen many examples of writing good production-level codes and exploring lists, units, tuples, and dictionaries to one of the best of our means. Nonetheless, this is step one, and we’ve got way more to cowl. Keep tuned for the subsequent article!!
Regularly Requested Questions
Ans. The comprehensions are an optimized and concise manner of writing a loop. They’re additionally sooner than conventional loops. Nonetheless, it isn’t really useful for too advanced logic or when readability is compromised. In such instances, conventional loops may be an acceptable different.
Ans. Immutable objects have a fixed-size knowledge construction upon its creation. This makes them extra memory-efficient than mutable objects as a result of there’s no overhead for resizing reminiscence to accommodate modifications in these objects.
Ans. A Frozen Set is used when working with an immutable set, equivalent to a set used as a key in a dictionary. This helps retain the effectivity of set operations whereas making certain the set’s contents can’t be altered, sustaining knowledge integrity.
Ans. For mutable objects, copy() often known as shallow copy creates a brand new object with the identical reference as the unique object, whereas deepcopy() not solely duplicates the unique object to a brand new object but additionally clones its reference as a brand new cloned reference object within the reminiscence.