Have you ever ever discovered it obscure a big, messy codebase? Or puzzled how instruments that analyze and discover code really work? On this article, we’ll remedy these issues by constructing a strong codebase exploration software from scratch. Utilizing static code evaluation and the Gemini mannequin, we’ll create an easy-to-use system that helps builders question, perceive, and acquire helpful insights from their code. Prepared to alter the way in which you navigate code? Let’s start!
Studying Goals
- Advanced software program growth utilizing Object Oriented Programming.
- The best way to parse and analyze the Python Codebase utilizing AST or Summary Syntax Tree.
- Understanding the right way to combine Google’s Gemini LLM API with the Python utility of code evaluation.
- Typer Command line-based question system for codebase exploration.
This text was revealed as part of the Information Science Blogathon.
The Want for Smarter Code Exploration
Initially, constructing such an utility provides you a studying enhance in software program growth, it should enable you to learn to implement advanced software program utilizing Object Oriented Programming paradigm and likewise enable you to to grasp the artwork of dealing with massive initiatives (though it’s not that enormous)
Second, immediately’s software program initiatives encompass hundreds of strains of code written throughout many recordsdata and folders. Conventional approaches to code exploration, resembling Grep or IDE search operate. This sort of system will fall brief when builders want to know the higher-level ideas or relationships inside the codebase. Our AI-powered instruments could make a major stride on this realm. Our utility permits builders to ask questions on their codebase in plain English and obtain detailed, contextual responses.
Structure Overview
The software consists of 4 essential parts
- Code Parser: It’s the basis of our system, which is answerable for analyzing Python recordsdata and extracting their construction utilizing Python’s Summary Syntax Tree (AST) module. It identifies lessons, strategies, capabilities, and imports. It would create a complete map of the codebase.
- Gemini Consumer: A wrapper round Google’s Gemini API that handles communication with the LLM mannequin. These parts handle API authentication and supply a clear interface for sending queries and receiving responses.
- Question Processor: It’s the essential engine of the software which is answerable for formatting the codebase context and queries in a manner that Gemini can perceive and course of successfully. It maintains a persistent index of the codebase construction and manages the interplay between the parser and the LLM.
- CLI interface: A user-friendly command-line interface constructed with Typer, offering instructions for indexing codebase, querying code construction, and analyzing stack traces.
Beginning Fingers-on Undertaking
This part will information you thru the preliminary steps to construct and implement your venture, making certain a clean begin and efficient studying expertise.
Undertaking Folder Construction
The venture folder construction can be just like these
|--codebase_explorer/
|src/
├──| __init__.py
├──| indexer/
│ ├── __init__.py
│ └── code_parser.py
├──| query_engine/
│ ├── __init__.py
│ ├── query_processor.py
│ └── gemini_client.py
|
├── essential.py
└── .env
Setup Undertaking Setting
Setup venture atmosphere within the following step:
#create a brand new conda env
conda create -n cb_explorer python=3.11
conda activate cb_explorerSet up all the required libraries:
pip set up google-generativeai google-ai-generativelanguage
pip set up python-dotenv typer llama-indexImplementing the Code
We’ll begin with understanding and implementing the codebase parsing system. It has two essential capabilities
- parse_codebase()
- extract_definitions()
Extracting definitions from the Summary Syntax Tree:
import ast
import os
from typing import Dict, Any
def extract_definitions(tree: ast.AST) -> Dict[str, list]:
"""Extract class and performance definitions from AST."""
definitions = {
"lessons": [],
"capabilities": [],
"imports": []
}
for node in ast.stroll(tree):
if isinstance(node, ast.ClassDef):
definitions["classes"].append({
"identify": node.identify,
"lineno": node.lineno
})
elif isinstance(node, ast.FunctionDef):
definitions["functions"].append({
"identify": node.identify,
"lineno": node.lineno
})
elif isinstance(node, ast.Import):
for identify in node.names:
definitions["imports"].append(identify.identify)
return definitionsIt is a helper operate for parse_codebase(). It would take an summary syntax tree(AST) of a Python file. The operate initiates a dictionary with empty lists for lessons, capabilities, and imports. Now, ast.stroll() iterates via all nodes within the AST tree. The AST module will determine all of the Courses, Features, Imports, and line numbers. Then append all of the definitions to the definitions dictionary.
Parsing CodeBase
This operate scans a listing for Python recordsdata, reads their content material, and extracts their construction.
import ast
import os
from typing import Dict, Any
def parse_codebase(listing: str) -> Dict[str, Any]:
"""Parse Python recordsdata within the listing and extract code construction."""
code_structure = {}
for root, _, recordsdata in os.stroll(listing):
for file in recordsdata:
if file.endswith(".py"):
file_path = os.path.be part of(root, file)
with open(file_path, "r", encoding="utf-8") as f:
attempt:
content material = f.learn()
tree = ast.parse(content material)
code_structure[file_path] = {
"definitions": extract_definitions(tree),
"content material": content material
}
besides Exception as e:
print(f"Error parsing {file_path}: {e}")
return code_structureThe capabilities provoke with the listing path as a string. It outputs a dictionary of code’s buildings. The dictionary shops the extracted knowledge for every Python file.
It loops via all subdirectories and the recordsdata within the given listing. os.stroll() offered a recursive technique to discover your entire listing tree. It would course of recordsdata ending the .py extensions.
Utilizing the Python ast module to parse the file’s content material into an summary syntax tree (AST), which represents the file’s construction. The extracted tree is then handed to the extract_definitions(tree). If parsing fails, it prints an error message however continues processing different recordsdata.
Question Processing Engine
Within the question engine listing create two recordsdata named gemini_client.py and query_processor.py
Gemini Consumer
This file will use <GOOGLE_API_KEY> to authenticate the Gemini mannequin API from Google. Within the root of the venture, create a .env file and put your GEMINI API KEY in it. Get your API_KEY right here.
import os
from typing import Non-compulsory
from google import generativeai as genai
from dotenv import load_dotenv
load_dotenv()
class GeminiClient:
def __init__(self):
self.api_key = os.getenv("GOOGLE_API_KEY")
if not self.api_key:
elevate ValueError("GOOGLE_API_KEY atmosphere variable just isn't set")
genai.configure(api_key=self.api_key)
self.mannequin = genai.GenerativeModel("gemini-1.5-flash")
def question(self, immediate: str) -> Non-compulsory[str]:
"""Question Gemini with the given immediate."""
attempt:
response = self.mannequin.generate_content(immediate)
return response.textual content
besides Exception as e:
print(f"Error querying Gemini: {e}")
return NoneRight here, we outline a GeminiClient class to work together with Google’s Gemini AI mannequin. It would authenticate the mannequin utilizing GOOGLE_API_KEY out of your .env file. After configuring the mannequin API, it supplies a question technique to generate a response on a given immediate.
Question Dealing with System
On this part, we are going to implement the QueryProcessor class to handle the codebase context and allow querying with Gemini.
import os
import json
from llama_index.embeddings.gemini import GeminiEmbedding
from dotenv import load_dotenv
from typing import Dict, Any, Non-compulsory
from .gemini_client import GeminiClient
load_dotenv()
gemini_api_key = os.getenv("GOOGLE_API_KEY")
model_name = "fashions/embeddings-001"
embed_model = GeminiEmbedding(model_name=model_name, api_key=gemini_api_key)
class QueryProcessor:
def __init__(self):
self.gemini_client = GeminiClient()
self.codebase_context: Non-compulsory[Dict[str, Any]] = None
self.index_file = "./indexes/codebase_index.json"
def load_context(self):
"""Load the codebase context from disk if it exists."""
if os.path.exists(self.index_file):
attempt:
with open(self.index_file, "r", encoding="utf-8") as f:
self.codebase_context = json.load(f)
besides Exception as e:
print(f"Error loading index: {e}")
self.codebase_context = None
def save_context(self):
"""Save the codebase context to disk."""
if self.codebase_context:
attempt:
with open(self.index_file, "w", encoding="utf-8") as f:
json.dump(self.codebase_context, f, indent=2)
besides Exception as e:
print(f"Error saving index: {e}")
def set_context(self, context: Dict[str, Any]):
"""Set the codebase context for queries."""
self.codebase_context = context
self.save_context()
def format_context(self) -> str:
"""Format the codebase context for Gemini."""
if not self.codebase_context:
return ""
context_parts = []
for file_path, particulars in self.codebase_context.gadgets():
defs = particulars["definitions"]
context_parts.append(
f"File: {file_path}n"
f"Courses: {[c['name'] for c in defs['classes']]}n"
f"Features: {[f['name'] for f in defs['functions']]}n"
f"Imports: {defs['imports']}n"
)
return "nn".be part of(context_parts)
def question(self, question: str) -> Non-compulsory[str]:
"""Course of a question concerning the codebase."""
if not self.codebase_context:
return (
"Error: No codebase context out there. Please index the codebase first."
)
immediate = f"""
Given the next codebase construction:
{self.format_context()}
Question: {question}
Please present an in depth and correct reply based mostly on the codebase construction above.
"""
return self.gemini_client.question(immediate)After loading the required libraries, load_dotenv() masses atmosphere variables from the .env file which incorporates our GOOGLE_API_KEY for the Gemini API key.
- GeminiEmbedding class initializes the embedding-001 fashions from the Google server.
- QueryProcessor class is designed to deal with the codebase context and work together with the GeminiClient. Loading_context technique masses codebase info from a JSON file it exists.
- The saving_context technique saves the present codebase context into the JSON file for persistence. save_context technique updates the codebase context and instantly saves it utilizing save_context and the format_context technique converts the codebase knowledge right into a human-readable string format, summarizing file paths, lessons, capabilities, and imports for queries.
- Querying Gemini is an important technique which is able to assemble a immediate utilizing the codebase context and the person’s question. It sends this immediate to the Gemini mannequin via GeminiClient and will get again the response.
Command Line App Implementation(CLI)
Create a essential.py file within the src folder of the venture and comply with the steps
Step 1: Import Libraries
import os
import json
import typer
from pathlib import Path
from typing import Non-compulsory
from indexer.code_parser import parse_codebase
from query_engine.query_processor import QueryProcessorStep 2: Initialize typer and question processor
Let’s create a typer and question processor object from the lessons.
app = typer.Typer()
query_processor = QueryProcessor()Step 3: Indexing the Python Undertaking Listing
Right here, the index technique can be used as a command within the terminal, and the operate will index the Python codebase within the specified listing for future querying and evaluation.
@app.command()
def index(listing: str):
"""Index a Python codebase for querying and evaluation."""
dir_path = Path(listing)
if not dir_path.exists():
typer.echo(f"Error: Listing '{listing}' doesn't exist")
elevate typer.Exit(1)
typer.echo("Indexing codebase...")
attempt:
code_structure = parse_codebase(listing)
query_processor.set_context(code_structure)
typer.echo(f"Efficiently listed {len(code_structure)} Python recordsdata")
besides Exception as e:
typer.echo(f"Error indexing codebase: {e}")
elevate typer.Exit(1)It would first verify if the listing exists after which use the parse_codebase operate to extract the construction of Python recordsdata within the listing.
After parsing it should save the parsed codebase construction in query_processor. All of the processes are within the attempt to besides block in order that exceptions will be dealt with with care throughout parsing. It would put together the codebase for environment friendly querying utilizing the Gemini mannequin.
Step 4: Querying the codebase
After indexing we are able to question the codebase for understanding or getting details about any capabilities within the codebase.
@app.command()
def question(query_text: str):
"""Question the listed codebase utilizing pure language."""
if not query_processor.codebase_context:
query_processor.load_context()
response = query_processor.question(query_text)
if response:
typer.echo(response)
else:
typer.echo("Error: Didn't course of question")
elevate typer.Exit(1)First, verify whether or not the query_processor has loaded a codebase context or not and attempt to load the context from the pc’s laborious disk. after which makes use of the query_processor’s question technique to course of the question.
And the final, it should print the response from the LLM to the terminal utilizing typer.echo() technique.
Step 5: Run the Utility
if __name__ == "__main__":
app()Take a look at the Utility
To check your laborious work comply with the under steps:
- Create a folder identify indexes in your venture root the place we are going to put all our index recordsdata.
- Create a codebase_index.json and put it within the beforehand (indexes) created folder.
- Then create a project_test folder within the root the place we are going to retailer our Python recordsdata for testing
- Create a find_palidrome.py file within the project_test folder and put the under code within the file.
Code Implementation
def find_palindromes(s: str) -> listing:
"""
Discover all distinct palindromic substrings within the given string.
Args:
s (str): Enter string to seek for palindromes.
Returns:
listing: An inventory of all distinct palindromic substrings.
"""
def is_palindrome(substring: str) -> bool:
return substring == substring[::-1]
n = len(s)
palindromes = set()
for i in vary(n):
# Odd-length palindromes (centered at i)
l, r = i, i
whereas l >= 0 and r < n and s[l] == s[r]:
palindromes.add(s[l : r + 1])
l -= 1
r += 1
# Even-length palindromes (centered between i and that i+1)
l, r = i, i + 1
whereas l >= 0 and r < n and s[l] == s[r]:
palindromes.add(s[l : r + 1])
l -= 1
r += 1
return sorted(palindromes)
# Instance utilization:
input_string = "ababa"
print(find_palindromes(input_string))This file will discover the palindrome from a given string. we are going to index this file question from terminal utilizing the CLI utility.
Now, open your terminal, paste the code and see the magic.
Indexing the venture
$ python .srcmain.py index .project_testOutput:

You might present Efficiently listed 1 Python file. and the JSON knowledge appears like
{
".project_testfind_palindrome.py": {
"definitions": {
"lessons": [],
"capabilities": [
{
"name": "find_palindromes",
"lineno": 1
},
{
"name": "is_palindrome",
"lineno": 12
}
],
"imports": []
},
"content material": "def find_palindromes(s: str) -> listing:n """n Discover all distinct palindromic substrings within the given string.nn Args:n s (str): Enter string to seek for palindromes.nn Returns:n
listing: An inventory of all distinct palindromic substrings.n """nn def is_palindrome(substring: str) -> bool:n return substring == substring[::-1]nn n = len(s)n palindromes = set()nn for i in vary(n):n
# Odd-length palindromes (centered at i)n l, r = i, in whereas l >= 0 and r < n and s[l] == s[r]:n palindromes.add(s[l : r + 1])n l -= 1n r += 1nn
# Even-length palindromes (centered between i and that i+1)n
l, r = i, i + 1n whereas l >= 0 and r < n and s[l] == s[r]:n palindromes.add(s[l : r + 1])n l -= 1n r += 1nn return sorted(palindromes)nnn#
Instance utilization:ninput_string = "ababa"nprint(find_palindromes(input_string))n"
},
}Querying the venture
$ python ./src/essential.py question "Clarify is_palindrome operate in 30 phrases?"Output:
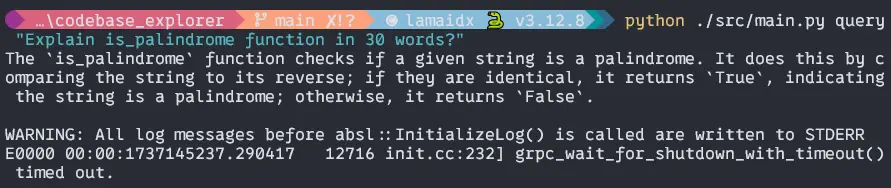
$ python ./src/essential.py question "Clarify find_palindrome operate in 30 phrases?Output:
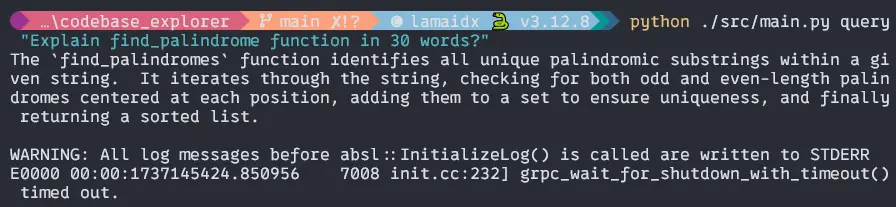
If every thing is completed correctly you’ll get these outputs in your terminal. You possibly can attempt it together with your Python code recordsdata and inform me within the remark part what’s your output. THANK YOU for staying with me.
Future Improvement
It is a prototype of the inspiration system that may be prolonged with many attention-grabbing options, resembling
- You possibly can combine with IDE plugins for seamless code exploration.
- AI-driven automated debugging system (I’m engaged on that).
- Including help for a lot of common languages resembling Javascript, Java, Typescripts, Rust.
- Actual-time code evaluation and LLM powered ideas for enhancements.
- Automated documentation utilizing Gemini or LLama3.
- Native LLM integration for on-device code exploration , options addition.
Conclusion
The Codebase Explorer helps you perceive the sensible utility of AI in software program growth instruments. By combining conventional static evaluation with trendy AI capabilities, we have now created a software that makes codebase exploration extra intuitive and environment friendly. This method reveals how AI can increase developer workflows with out changing current instruments, offering a brand new layer of understanding and accessibility to advanced codebases.
All of the code used on this article is right here.
Key Takeaways
- Construction code parsing is probably the most imortant approach for the code evaluation.
- CodeBase Explorer simplifies code navigation, permitting builders to shortly perceive and handle advanced code buildings.
- CodeBase Explorer enhances debugging effectivity, providing instruments to investigate dependencies and determine points quicker.
- Gemini can considerably improve code understanding when mixed with conventional static evaluation.
- CLI instruments can present a strong interface for LLM assisted code exploration.
Regularly Requested Questions
A. The software makes use of a persistent indexing system that parses and shops the codebase construction, permitting for environment friendly queries with out nedding to reanalyze the code every time. The index is up to date solely when the codebase modifications.
A. The code parsing and index administration can work offline, however the querying the codebase utilizing Gemini API want web connection to speak with the exterior servers. We are able to built-in Ollama with the instruments which is able to attainable to make use of on-device LLM or SLM mannequin resembling LLama3 or Phi-3 for querying the codebase.
A. The accuracy depends upon each the standard of the parsed code context and the capabilities of the Gemini mannequin. The instruments supplies structured code info to the AI mannequin, with helps enhance response accuracy, however customers ought to nonetheless confirm vital info via conventional means.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.
A self-taught, project-driven learner, like to work on advanced initiatives on deep studying, Pc imaginative and prescient, and NLP. I at all times attempt to get a deep understanding of the subject which can be in any discipline resembling Deep studying, Machine studying, or Physics. Like to create content material on my studying. Attempt to share my understanding with the worlds.