Retrieval-Augmented Era is a way that enhances the capabilities of massive language fashions by integrating data retrieval processes into their operation. This strategy permits LLMs to tug in related knowledge from exterior data bases, making certain that the responses generated are extra correct, up-to-date, and contextually related. Corrective RAG (CRAG) is a sophisticated technique throughout the Retrieval-Augmented Era (RAG) framework that focuses on bettering the accuracy and relevance of generated responses by incorporating mechanisms for self-reflection and self-grading of retrieved paperwork.
Studying Goals
- Perceive the core mechanism of Corrective Retrieval-Augmented Era (CRAG) and its integration with net search.
- Learn the way CRAG evaluates and improves the relevance of retrieved paperwork utilizing binary scoring and query rewriting.
- Discover the important thing variations between Corrective RAG and conventional RAG frameworks.
- Acquire hands-on expertise in implementing CRAG utilizing Python, LangChain, and Tavily.
- Develop sensible expertise in organising evaluators, question rewriters, and net search instruments to boost retrieval and response accuracy.
This text was revealed as part of the Information Science Blogathon.
Mechanism Behind Corrective RAG (CRAG)
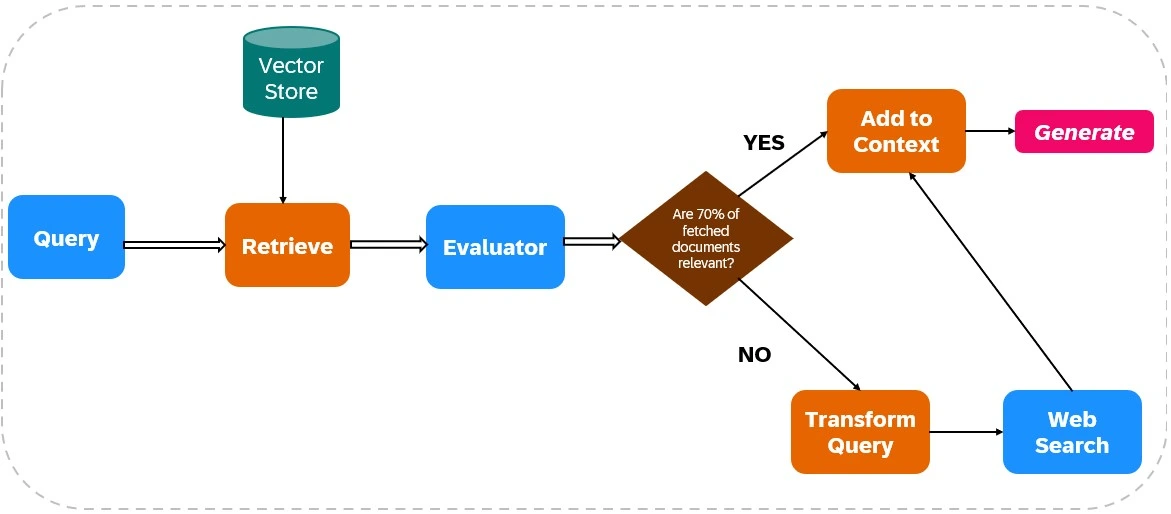
Corrective Retrieval Augmented Era (Corrective RAG or CRAG) is a sophisticated framework that enhances the reliability of language mannequin outputs by integrating net search capabilities into its retrieval and technology processes. Right here’s a breakdown of its mechanism, as illustrated in Determine 1.
Retrieval of Related Paperwork
- Information Ingestion: The method begins with loading related knowledge into an index, organising the mandatory instruments for net searches, equivalent to Tavily AI, to facilitate real-time data retrieval.
- Preliminary Retrieval: The system retrieves paperwork based mostly on the person’s question from a static data base.
Relevance Analysis
An evaluator assesses the relevance of the retrieved paperwork. This analysis is essential because it determines the subsequent steps based mostly on the standard of the retrieved data:
- If as an example,greater than 70% of the paperwork are deemed irrelevant , corrective actions are triggered. Else reponse technology takes place from the retrieved related paperwork.
Supplementing with Net Search
If the evaluator finds that the retrieved paperwork are inadequate (i.e., under the relevance threshold), CRAG employs net search to complement the preliminary retrieval. This step includes:
- Question Transformation: The unique question could also be remodeled to higher align with net search parameters, enhancing the probabilities of retrieving related data.
- Net Search Execution: Using net search instruments like Tavily AI, CRAG fetches further knowledge from broader sources, making certain entry to up-to-date and numerous data.
Response Era
After gathering related knowledge from each preliminary retrieval and net searches, CRAG synthesizes this data to generate a coherent and contextually correct response.
How is Corrective RAG completely different from Conventional RAG?
Corrective RAG incorporates lively error-checking and refinement processes. It evaluates the relevance and accuracy of retrieved paperwork earlier than they’re utilized in technology, decreasing the chance of producing incorrect or deceptive data. Conventional RAG depends on retrieved paperwork to help in textual content technology however doesn’t actively confirm or appropriate the knowledge.
Corrective RAG usually integrates real-time net search capabilities, permitting it to fetch probably the most present and related data dynamically throughout the retrieval part. Conventional RAG sometimes depends on a static data base which can lead to outdated data getting used for response technology.
Corrective RAG is due to this fact significantly helpful for purposes requiring excessive accuracy and real-time knowledge integration, equivalent to buyer help methods, authorized compliance, and monetary analytics.
Arms-on Implementation of Corrective RAG
Now we are going to dive into the sensible steps of implementing Corrective RAG, the place we leverage superior instruments and frameworks to boost the reliability and accuracy of AI-generated responses by real-time retrieval and self-correction mechanisms.
Step1: Putting in the Obligatory Libraries
Put together your workspace by putting in the mandatory instruments and libraries for environment friendly mannequin growth and execution.
!pip set up tiktoken langchain-openai langchainhub chromadb langchain langgraph tavily-python
!pip set up -qU pypdf langchain_communityStep2: Defining the API Keys
Generate and securely outline your API keys to allow seamless communication between your utility and exterior companies.
import os
os.environ["TAVILY_API_KEY"] = ""
os.environ["OPENAI_API_KEY"] = ""Step3: Importing the Obligatory Libraries
Import the required libraries to entry important features and modules wanted to your undertaking’s implementation.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Area
from typing import Record
from typing_extensions import TypedDict
from langchain.schema import Doc
from langgraph.graph import END, StateGraph, STARTStep4: Chunking the Doc and Creating the Retriever
Divide the doc into manageable chunks and arrange a retriever to effectively retrieve related data from the chunks.
Firstly load the PDF doc within the present working folder. We’re utilizing this doc right here.
file_path = "Brochure_Basic-Inventive-coffee-recipes.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(paperwork=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()- PDF Loading: The PyPDFLoader extracts textual content from the PDF file (Brochure_Basic-Inventive-coffee-recipes.pdf).
- Flattening Paperwork: The textual content from the PDF is loaded into a listing, and any nested lists are flattened.
- Textual content Splitting: The RecursiveCharacterTextSplitter splits the paperwork into smaller chunks, with or with out overlap.
- Vector Retailer Creation: OpenAI’s mannequin transforms the textual content chunks into vector embeddings and shops them in a vector database (Chroma).
- Retriever: We create a retriever that permits us to question the vector retailer for semantically comparable paperwork.
Step5: Setting Up the RAG Chain
Configure the RAG chain to hyperlink the doc retrieval course of with the generative mannequin for correct and contextually related responses.
# Immediate
rag_prompt = hub.pull("rlm/rag-prompt")
# LLM
rag_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# Chain
rag_chain = rag_prompt | rag_llm | StrOutputParser()
print(rag_prompt.messages[0].immediate.template)- rag_prompt: The system pulls a predefined immediate template associated to retrieval-augmented technology (RAG) from the hub. This immediate will instruct the language mannequin to guage retrieved paperwork and generate a response based mostly on the paperwork.
- rag_llm: An occasion of OpenAI’s GPT-4 mannequin is created with deterministic output (temperature=0).
- rag_chain: The chain connects the rag_prompt, the rag_llm, and the StrOutputParser. This chain will course of the enter (retrieved paperwork and person questions) and generate a formatted output.
The next is the output of the immediate template:
You might be an assistant for question-answering duties. Use the next items of
retrieved context to reply the query. If you do not know the reply, simply say
that you do not know. Use three sentences most and hold the reply concise.
Query: {query}
Context: {context}
Reply:
Step6: Setting Up an Evaluator
Combine an evaluator to evaluate the standard of generated responses, making certain they meet the specified requirements of accuracy and relevance.
### Retrieval Evaluator
class Evaluator(BaseModel):
"""Classify retrieved paperwork based mostly on its relevance to the query."""
binary_score: str = Area(
description="Paperwork are related to the query, 'sure' or 'no'"
)
# LLM with perform name
evaluator_llm = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0)
output_llm_evaluator = evaluator_llm.with_structured_output(Evaluator)
# Immediate
system = """You might be tasked with evaluating the relevance of a retrieved doc to a person's query. n If the doc incorporates key phrases or semantic content material associated to the query, mark it as related. n Output a binary rating: 'sure' if the doc is related, or 'no' if it isn't"""
retrieval_evaluator_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: nn {document} nn User question: {question}"),
]
)
retrieval_grader = retrieval_evaluator_prompt | output_llm_evaluator The category Evaluator defines a binary_score area (both ‘sure’ or ‘no’) to point whether or not a retrieved doc is related to a person’s query.
The system initializes a GPT mannequin (gpt-4o-mini) with zero temperature to make sure deterministic output.
The system configures the mannequin to return structured output that matches the Evaluator class.
A system immediate is created to information the mannequin. It asks the mannequin to guage a doc’s relevance based mostly on whether or not it incorporates key phrases or semantic content material associated to the person’s query, and to output a binary rating (‘sure’ or ‘no’). A human immediate supplies the context: a retrieved doc and a person query.
The system immediate combines with the evaluator mannequin to kind an entire course of (retrieval_grader) that evaluates the doc’s relevance.
Step7: Setting Up A Question Rewriter
Configure a question rewriter to optimize and refine person queries, enhancing the effectiveness of knowledge retrieval within the RAG system.
question_rewriter_llm = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0)
# Immediate
system = """You're a query rewriter who improves enter inquiries to make them more practical for net search. n Analyze the query and give attention to the underlying semantic intent to craft a greater model."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: nn {question} n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | question_rewriter_llm | StrOutputParser()A GPT mannequin (gpt-4o-mini) is initialized with a temperature of 0 for deterministic (non-random) output.
A system immediate is created to instruct the mannequin. It asks the mannequin to enhance an enter query by specializing in the underlying semantic intent to make it more practical for net search.
A human immediate supplies the precise query to be rewritten, asking the mannequin to formulate an improved model.
The system and human prompts rewrite the enter query by chaining with the GPT mannequin and the output parser (StrOutputParser) to kind an entire course of (question_rewriter).
Step8: Setting Up Net Search
Combine an online search functionality to broaden the data base, permitting the RAG system to fetch real-time, related data from the web.
from langchain_community.instruments.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(ok=3)The online search device is about up right here utilizing Tavily.
Step9: Setting Up the Graph State for LangGraph
Initialize and configure the graph state for LangGraph to handle advanced relationships and allow environment friendly retrieval and processing of information throughout the RAG system.
class GraphState(TypedDict):
query: str
technology: str
web_search: str
paperwork: Record[str]The system designs a GraphState to retailer knowledge because it transitions between nodes within the workflow. This state will comprise all related variables, together with the person’s query, retrieved paperwork, and generated solutions.
Step10: Setting Up the Operate Nodes
Outline and configure the person perform nodes, every representing a selected activity or operation within the RAG pipeline, making certain they align with the general workflow.
Operate for Retrieving Related Paperwork
def retrieve(state):
query = state["question"]
# Retrieval
paperwork = retriever.get_relevant_documents(query)
return {"paperwork": paperwork, "query": query}Producing Solutions From the Retrieved Paperwork
def generate(state):
query = state["question"]
paperwork = state["documents"]
# RAG technology
technology = rag_chain.invoke({"context": paperwork, "query": query})
return {"paperwork": paperwork, "query": query, "technology": technology}Operate for Evaluating the Retrieved Paperwork
def evaluate_documents(state):
query = state["question"]
documents_all = state["documents"]
# Rating every doc
docs_filtered = []
web_search = "No"
for d in paperwork:
rating = retrieval_grader.invoke(
{"query": query, "doc": d.page_content}
)
grade = rating.binary_score
if grade == "sure":
docs_filtered .append(d)
else:
proceed
if len(docs_filtered) / len(documents_all) <= 0.7:
web_search = "Sure"
return {"paperwork": docs_filtered, "query": query, "web_search": web_search}The perform takes in a state dictionary, which incorporates the person’s query and a listing of paperwork.
It loops by every doc and scores its relevance utilizing the retrieval_grader perform. We add a doc to the docs_filtered listing if we deem it related (with a “sure” rating).
If lower than or equal to 70% of the paperwork are related, the web_search flag is about to “Sure”.
The perform returns a dictionary containing the filtered paperwork, the unique query, and the web_search resolution (“Sure” or “No”).
Operate for Remodeling the Person Question For Higher Retrieval
def transform_query(state):
query = state["question"]
documents_all = state["documents"]
# Re-write query
transformed_question = question_rewriter.invoke({"query": query})
return {"paperwork": documents_all , "query": transformed_question }The transform_query perform rewrites the person’s query utilizing a query rewriter. It returns the unique paperwork together with the remodeled query
Operate for Net Looking out
def web_search(state):
query = state["question"]
documents_all = state["documents"]
# Net search
docs = web_search_tool.invoke({"question": query})
#Fetch outcomes from net
web_results = "n".be part of([d["content"] for d in docs])
web_results = Doc(page_content=web_results)
#Append the outcomes from the online to the paperwork
documents_all.append(web_results)
return {"paperwork": documents_all, "query": query}The web_search perform performs an online search based mostly on the person’s query and fetches the outcomes. It appends the online search outcomes to the unique paperwork and returns the up to date paperwork together with the query.
Operate for Deciding Subsequent Step
Whether or not to generate or remodeling the question for net search.
def decide_next_step(state):
web_search = state["web_search"]
if web_search == "Sure":
return "transform_query"
else:
return "generate"The decide_next_step perform checks if an online search is required. If the web_search variable is sure, it returns “transform_query”; in any other case, it returns “generate”.
Step11: Connecting all of the Operate Nodes & Including Edges
Set up connections between all perform nodes and add edges to create a cohesive movement of information and operations, making certain easy interplay throughout the RAG system.
workflow = StateGraph(GraphState)
# Outline the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", evaluate_documents) # consider paperwork
workflow.add_node("generate", generate) # generate
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search_node", web_search) # net search
# Including the Edges
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_next_step,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()A StateGraph object named workflow is created utilizing GraphState.
We add 5 nodes to the workflow, with every representing a selected perform.
- retrieve: Retrieves knowledge or paperwork.
- grade_documents: Evaluates the retrieved paperwork.
- generate: Generates output based mostly on earlier steps.
- transform_query: Transforms enter queries for additional processing.
- web_search_node: Conducts net searches.
Edge Creation
We add edges to outline the sequence and situations below which the nodes execute.
- The workflow begins from a predefined START node and strikes to the “retrieve” node.
- After retrieving, it proceeds to “grade_documents”.
- Conditional edges are established from “grade_documents” to both “transform_query” or “generate”, based mostly on the end result of the decide_next_step perform.
- The movement continues from “transform_query” to “web_search_node”, then to “generate”, and at last ends at an END node.
The workflow is compiled into an utility object named app.
Step12: Output utilizing Corrective RAG
from pprint import pprint
inputs = {"query": "What's the distinction between Flat white and cappuccino?"}
for output in app.stream(inputs):
for key, worth in output.objects():
# Node
pprint(f"Node '{key}':")
# Non-compulsory: print full state at every node
pprint(worth, indent=2, width=80, depth=None)
pprint("n---n")
# Remaining technology
pprint(worth["generation"])This code streams the outcomes of the workflow (app) processing the enter query. It shows the output at every node, remodeling the enter step-by-step, and at last presents the generated reply after processing all the workflow.
Remaining Output from Corrective RAG
The important thing variations between a flat white and a cappuccino lie of their milk '
'texture and proportions. A flat white options microfoam milk with a '
'stronger espresso taste and fewer foam, whereas a cappuccino has a thick layer '
'of froth, leading to a lighter, frothier drink. Moreover, the ratio of '
'espresso to take advantage of differs, with a cappuccino having a 1:1 ratio in comparison with '
'the 1:3 ratio in a flat white.
The output from Corrective RAG exhibits that the system fetched the precise reply from the online after the LLM evaluator decided all paperwork from the PDF to be irrelevant.
Allow us to now test what a standard RAG would have given as response to the identical query.
query = "How is Flat white completely different from cappuccino?"
technology = rag_chain.invoke({"context": docs, "query": query})
print("Remaining reply: %s" % technology)Remaining Output from Conventional RAG
Remaining reply: A flat white is ready by including espresso first, adopted by heat
milk, with the milk foam mendacity below the crema, which provides it a easy texture. In
distinction, a cappuccino is made by making ready the milk first, then including the espresso,
leading to a thick layer of milk foam on prime. This distinction in preparation
strategies impacts the feel and taste profile of every drink.
The standard RAG fetches the knowledge from the doc, but it surely doesn’t present the right response. In eventualities like these, Corrective RAG is immensely useful because it improves the accuracy of the responses.
Challenges of Corrective RAG
A key problem lies within the dependence on the effectiveness of the retrieval evaluator. This element performs a vital function in figuring out the relevance and accuracy of the paperwork retrieved. If the evaluator is weak or poorly designed, it might probably trigger substantial errors throughout the correction course of. For instance, a subpar evaluator may miss important contextual particulars or fail to notice vital discrepancies between the retrieved data and the person’s question. This may result in the propagation of errors, finally compromising the CRAG system’s reliability.
Moreover, counting on automated evaluators raises points associated to scalability and adaptableness. As language fashions evolve and new varieties of content material emerge, these evaluators want fixed updates and coaching to successfully handle numerous and altering knowledge sources.
One other limitation is CRAG’s reliance on net searches to switch or appropriate paperwork which might be inaccurate or ambiguous. Though this strategy can supply up-to-date and various data, it additionally carries the chance of introducing biased or unreliable content material. Given the vastness of the web, not all data is of equal high quality; some sources could unfold misinformation, whereas others may mirror specific ideological biases. Because of this, CRAG methods should implement superior filtering strategies to distinguish between credible and untrustworthy sources.
Conclusion
Corrective Retrieval Augmented Era (CRAG) represents a major development within the reliability and accuracy of language mannequin outputs by incorporating evaluators, dynamic net search capabilities alongside conventional doc retrieval. Its capability to guage the relevance of retrieved paperwork and complement them with real-time net knowledge makes it significantly helpful for purposes demanding excessive precision and present data.
Nonetheless, the system’s effectiveness hinges on the standard of its evaluators and the challenges related to filtering dependable knowledge from the huge expanse of the online. As language fashions evolve, continuous refinement of the CRAG framework can be important to beat these hurdles and guarantee its reliability.
Key Takeaways
- Corrective RAG (CRAG) enhances language mannequin outputs by incorporating net search capabilities to retrieve up-to-date, related data, bettering the accuracy of responses.
- The evaluator examines the standard of retrieved paperwork and triggers corrective actions if over 70% are irrelevant, making certain using high-quality data in response technology.
- To enhance retrieval accuracy, CRAG transforms person queries earlier than executing net searches, growing the probabilities of acquiring related outcomes.
- CRAG dynamically integrates real-time data from net searches, permitting it to entry broader and extra numerous knowledge sources in comparison with conventional RAG methods, which depend on static data bases.
- Not like conventional RAG, CRAG actively checks the relevance and accuracy of retrieved paperwork earlier than producing responses, decreasing the chance of producing deceptive or incorrect data.
- CRAG is especially helpful in domains requiring excessive accuracy and real-time knowledge, equivalent to buyer help, authorized compliance, and monetary analytics.
Ceaselessly Requested Questions
A. Corrective RAG is a sophisticated framework that enhances language mannequin outputs by integrating net search capabilities into its retrieval and technology processes to enhance the accuracy and reliability of generated responses.
A. Not like Conventional RAG, Corrective RAG actively checks and refines the retrieved paperwork for accuracy earlier than utilizing them for response technology, decreasing the chance of errors.
A. The relevance evaluator assesses retrieved paperwork to find out in the event that they require corrective actions or if the response technology can proceed as is.
A. If the preliminary retrieval lacks adequate paperwork, CRAG dietary supplements it by executing an online search to collect extra related knowledge.
A. CRAG should implement superior filtering strategies to determine credible sources and keep away from introducing biased or unreliable data, as net searches could present sources with misinformation or ideological biases.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.
Nibedita accomplished her grasp’s in Chemical Engineering from IIT Kharagpur in 2014 and is at present working as a Senior Information Scientist. In her present capability, she works on constructing clever ML-based options to enhance enterprise processes.