Information abstract: New libraries in accelerated computing ship order-of-magnitude speedups and scale back vitality consumption and prices in information processing, generative AI, recommender methods, AI information curation, information processing, 6G analysis, AI-physics and extra. They embrace:
- LLM functions: NeMo Curator, to create customized datasets, provides picture curation and Nemotron-4 340B for high-quality artificial information era
- Information processing: cuVS for vector search to construct indexes in minutes as an alternative of days and a brand new Polars GPU Engine in open beta
- Bodily AI: For physics simulation, Warp accelerates computations with a brand new TIle API. For wi-fi community simulation, Aerial provides extra map codecs for ray tracing and simulation. And for link-level wi-fi simulation, Sionna provides a brand new toolchain for real-time inference
Firms around the globe are more and more turning to NVIDIA accelerated computing to hurry up functions they first ran on CPUs solely. This has enabled them to realize excessive speedups and profit from unbelievable vitality financial savings.
In Houston, CPFD makes computational fluid dynamics simulation software program for industrial functions, like its Barracuda Digital Reactor software program that helps design next-generation recycling services. Plastic recycling services run CPFD software program in cloud situations powered by NVIDIA accelerated computing. With a CUDA GPU-accelerated digital machine, they’ll effectively scale and run simulations 400x quicker and 140x extra vitality effectively than utilizing a CPU-based workstation.

A well-liked video conferencing software captions a number of hundred thousand digital conferences an hour. When utilizing CPUs to create reside captions, the app may question a transformer-powered speech recognition AI mannequin thrice a second. After migrating to GPUs within the cloud, the appliance’s throughput elevated to 200 queries per second — a 66x speedup and 25x energy-efficiency enchancment.
In houses throughout the globe, an e-commerce web site connects lots of of hundreds of thousands of consumers a day to the merchandise they want utilizing a sophisticated suggestion system powered by a deep studying mannequin, working on its NVIDIA accelerated cloud computing system. After switching from CPUs to GPUs within the cloud, it achieved considerably decrease latency with a 33x speedup and almost 12x energy-efficiency enchancment.
With the exponential progress of information, accelerated computing within the cloud is about to allow much more revolutionary use instances.
NVIDIA Accelerated Computing on CUDA GPUs Is Sustainable Computing
NVIDIA estimates that if all AI, HPC and information analytics workloads which are nonetheless working on CPU servers have been CUDA GPU-accelerated, information facilities would save 40 terawatt-hours of vitality yearly. That’s the equal vitality consumption of 5 million U.S. houses per 12 months.
Accelerated computing makes use of the parallel processing capabilities of CUDA GPUs to finish jobs orders of magnitude quicker than CPUs, enhancing productiveness whereas dramatically lowering value and vitality consumption.
Though including GPUs to a CPU-only server will increase peak energy, GPU acceleration finishes duties rapidly after which enters a low-power state. The whole vitality consumed with GPU-accelerated computing is considerably decrease than with general-purpose CPUs, whereas yielding superior efficiency.
Prior to now decade, NVIDIA AI computing has achieved roughly 100,000x extra vitality effectivity when processing massive language fashions. To place that into perspective, if the effectivity of automobiles improved as a lot as NVIDIA has superior the effectivity of AI on its accelerated computing platform, they’d get 500,000 miles per gallon. That’s sufficient to drive to the moon, and again, on lower than a gallon of gasoline.
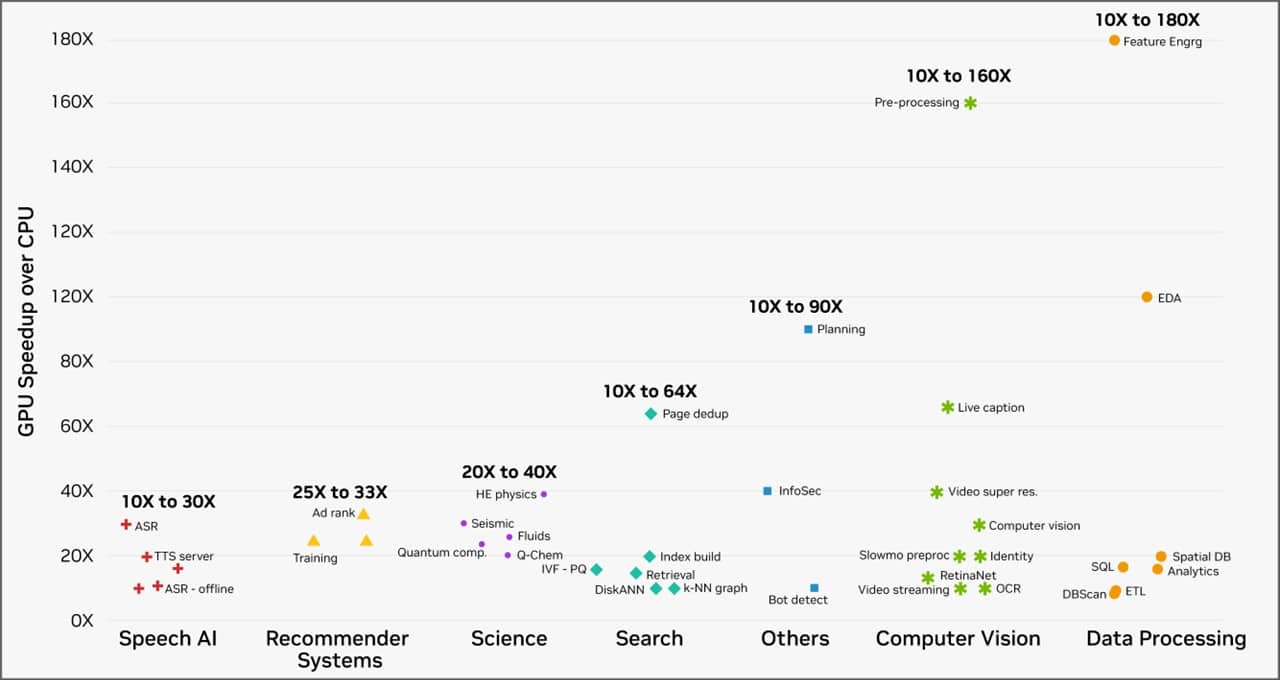
Along with these dramatic boosts in effectivity on AI workloads, GPU computing can obtain unbelievable speedups over CPUs. Prospects of the NVIDIA accelerated computing platform working workloads on cloud service suppliers noticed speedups of 10-180x throughout a gamut of real-world duties, from information processing to laptop imaginative and prescient, because the chart under reveals.
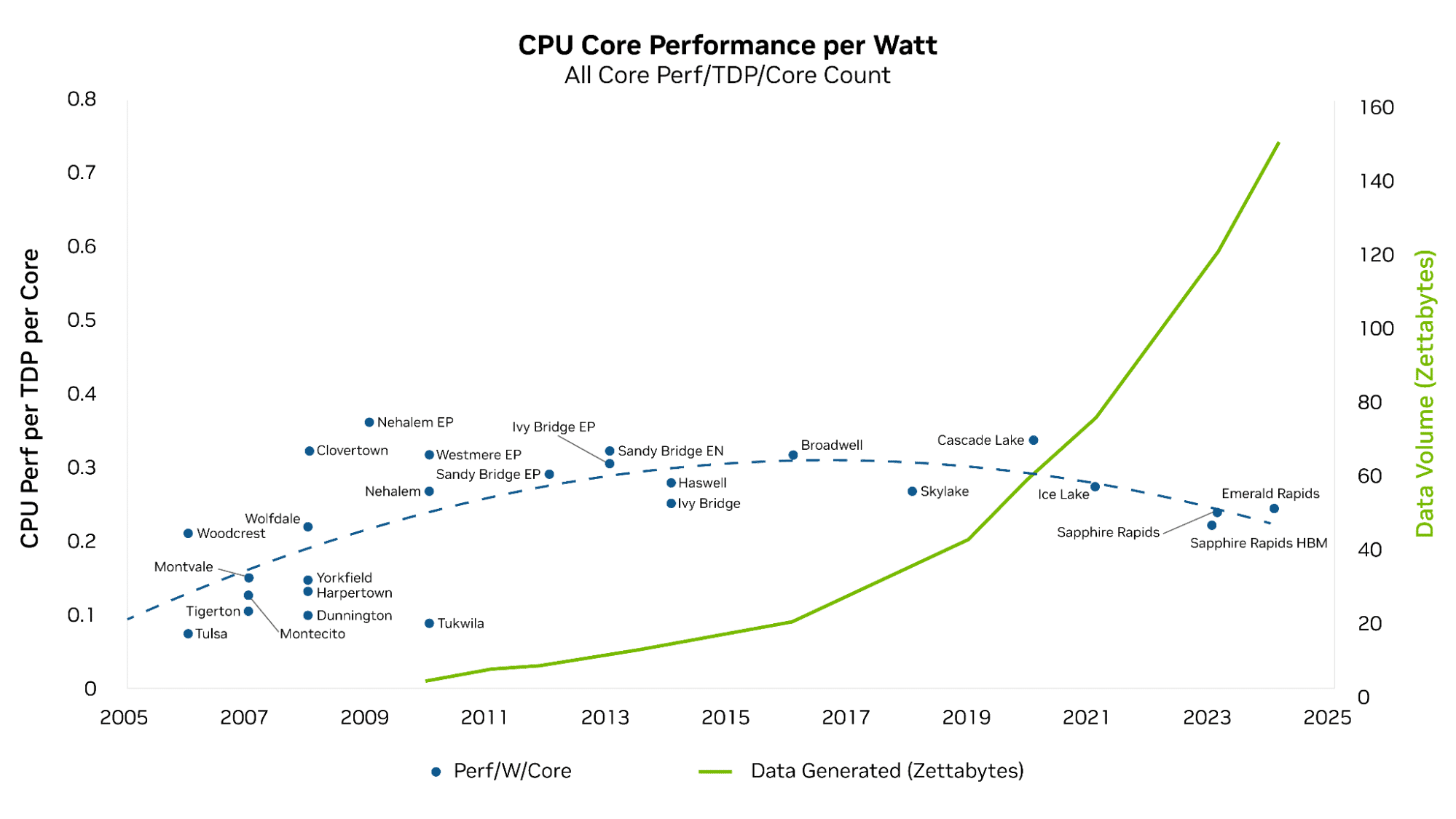
As workloads proceed to demand exponentially extra computing energy, CPUs have struggled to offer the mandatory efficiency, making a rising efficiency hole and driving “compute inflation.” The chart under illustrates a multiyear development of how information progress has far outpaced the expansion in compute efficiency per watt of CPUs.
The vitality financial savings of GPU acceleration frees up what would in any other case have been wasted value and vitality.
With its huge energy-efficiency financial savings, accelerated computing is sustainable computing.
The Proper Instruments for Each Job
GPUs can’t speed up software program written for general-purpose CPUs. Specialised algorithm software program libraries are wanted to speed up particular workloads. Identical to a mechanic would have a whole toolbox from a screwdriver to a wrench for various duties, NVIDIA gives a various set of libraries to carry out low-level capabilities like parsing and executing calculations on information.
Every NVIDIA CUDA library is optimized to harness {hardware} options particular to NVIDIA GPUs. Mixed, they embody the ability of the NVIDIA platform.
New updates proceed to be added on the CUDA platform roadmap, increasing throughout numerous use instances:
LLM Purposes
NeMo Curator provides builders the flexibleness to rapidly create customized datasets in massive language mannequin (LLM) use instances. Lately, we introduced capabilities past textual content to develop to multimodal assist, together with picture curation.
SDG (artificial information era) augments present datasets with high-quality, synthetically generated information to customise and fine-tune fashions and LLM functions. We introduced Nemotron-4 340B, a brand new suite of fashions particularly constructed for SDG that permits companies and builders to make use of mannequin outputs and construct customized fashions.
Information Processing Purposes
cuVS is an open-source library for GPU-accelerated vector search and clustering that delivers unbelievable velocity and effectivity throughout LLMs and semantic search. The newest cuVS permits massive indexes to be inbuilt minutes as an alternative of hours and even days, and searches them at scale.
Polars is an open-source library that makes use of question optimizations and different methods to course of lots of of hundreds of thousands of rows of information effectively on a single machine. A brand new Polars GPU engine powered by NVIDIA’s cuDF library might be obtainable in open beta. It delivers as much as a 10x efficiency increase in comparison with CPU, bringing the vitality financial savings of accelerated computing to information practitioners and their functions.
Bodily AI
Warp, for high-performance GPU simulation and graphics, helps speed up spatial computing by making it simpler to put in writing differentiable packages for physics simulation, notion, robotics and geometry processing. The subsequent launch can have assist for a brand new Tile API that enables builders to make use of Tensor Cores inside GPUs for matrix and Fourier computations.
Aerial is a collection of accelerated computing platforms that features Aerial CUDA-Accelerated RAN and Aerial Omniverse Digital Twin for designing, simulating and working wi-fi networks for industrial functions and trade analysis. The subsequent launch will embrace a brand new growth of Aerial with extra map codecs for ray tracing and simulations with larger accuracy.
Sionna is a GPU-accelerated open-source library for link-level simulations of wi-fi and optical communication methods. With GPUs, Sionna achieves orders-of-magnitude quicker simulation, enabling interactive exploration of those methods and paving the best way for next-generation bodily layer analysis. The subsequent launch will embrace your complete toolchain required to design, practice and consider neural network-based receivers, together with assist for real-time inference of such neural receivers utilizing NVIDIA TensorRT.
NVIDIA gives over 400 libraries. Some, like CV-CUDA, excel at pre- and post-processing of laptop imaginative and prescient duties frequent in user-generated video, recommender methods, mapping and video conferencing. Others, like cuDF, speed up information frames and tables central to SQL databases and pandas in information science.
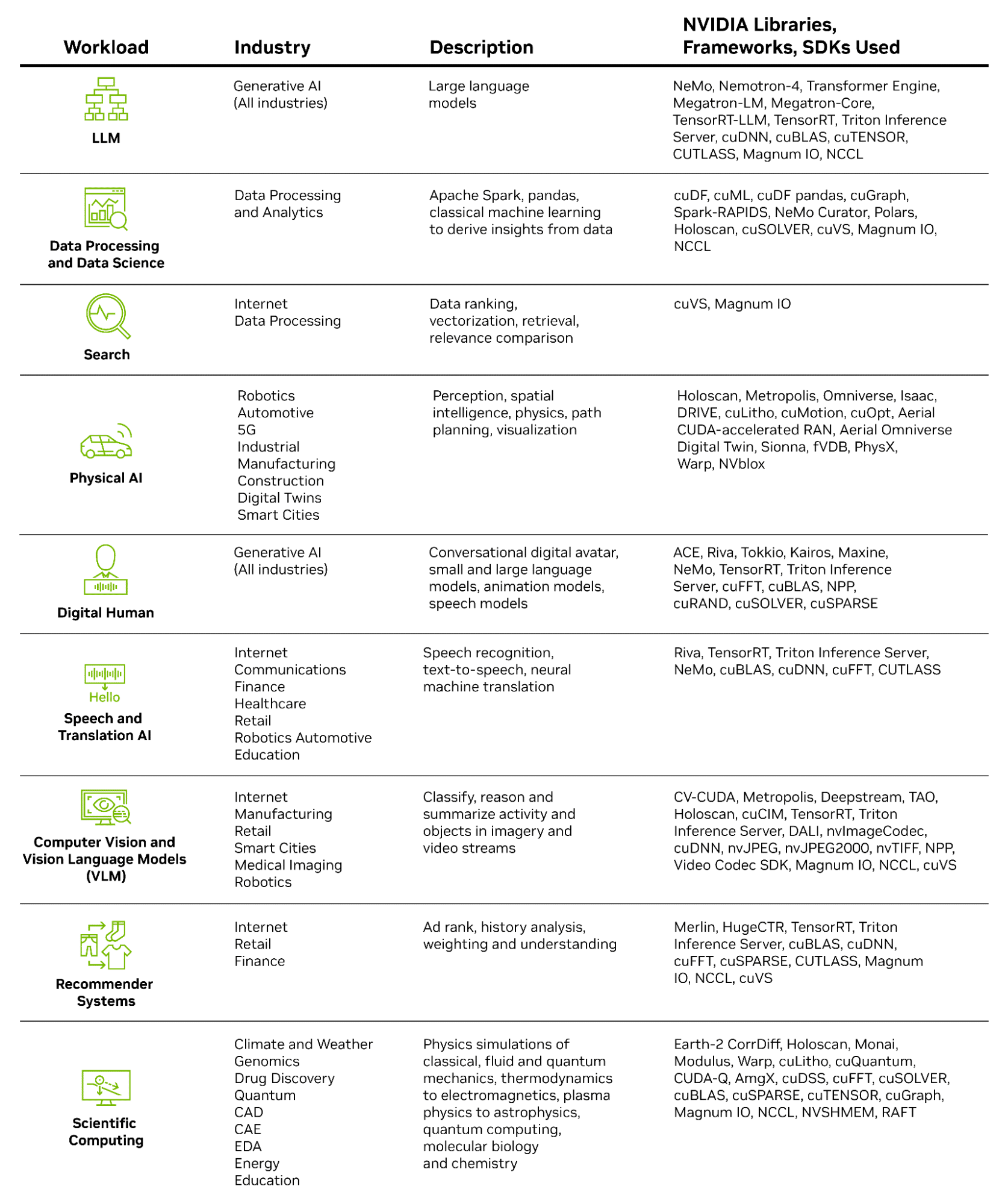
Many of those libraries are versatile — for instance, cuBLAS for linear algebra acceleration — and can be utilized throughout a number of workloads, whereas others are extremely specialised to deal with a selected use case, like cuLitho for silicon computational lithography.
For researchers who don’t wish to construct their very own pipelines with NVIDIA CUDA-X libraries, NVIDIA NIM gives a streamlined path to manufacturing deployment by packaging a number of libraries and AI fashions into optimized containers. The containerized microservices ship improved throughput out of the field.
Augmenting these libraries’ efficiency are an increasing variety of hardware-based acceleration options that ship speedups with the very best vitality efficiencies. The NVIDIA Blackwell platform, for instance, features a decompression engine that unpacks compressed information information inline as much as 18x quicker than CPUs. This dramatically accelerates information processing functions that have to ceaselessly entry compressed information in storage like SQL, Apache Spark and pandas, and decompress them for runtime computation.
The combination of NVIDIA’s specialised CUDA GPU-accelerated libraries into cloud computing platforms delivers outstanding velocity and vitality effectivity throughout a variety of workloads. This mix drives important value financial savings for companies and performs an important position in advancing sustainable computing, serving to billions of customers counting on cloud-based workloads to learn from a extra sustainable and cost-effective digital ecosystem.
Study extra about NVIDIA’s sustainable computing efforts and take a look at the Power Effectivity Calculator to find potential vitality and emissions financial savings.
See discover relating to software program product info.