Because the introduction of GANs (Generative Adversarial Networks) by Goodfellow and his colleagues in 2014, they’ve revolutionized generative fashions and have been helpful in numerous fields for picture era, creating artificial faces and information.
Furthermore, past picture era, GANs have been used extensively in quite a lot of duties resembling image-to-image translation (utilizing CycleGAN), super-resolution, text-to-image synthesis, drug discovery, and protein folding.
Picture-to-image translation is an space of pc imaginative and prescient that offers with remodeling one picture to a different type whereas sustaining sure semantic particulars (e.g. translating the picture of a horse right into a zebra). CycleGAN is particularly designed to deal with this process, the place it could possibly carry out type switch, picture colorization, changing portray to actual picture and actual picture again to portray.
On this weblog put up, we’ll look into CycleGAN and the way it performs picture to picture, the way it remodeled this space of analysis, and what makes it higher than earlier fashions.

About us: Viso Suite is a versatile and scalable infrastructure developed for enterprises to combine pc imaginative and prescient into their tech ecosystems seamlessly. Viso Suite permits enterprise ML groups to coach, deploy, handle, and safe pc imaginative and prescient functions in a single interface. To be taught extra, e-book a demo with our staff.
What’s a GAN?
GAN is a deep studying structure consisting of two neural networks, a generator and a discriminator, which can be educated concurrently by means of adversarial studying, which is sort of a recreation, the place the generator and discriminator attempt to beat one another.
The aim of the generator is to provide real looking pictures from random noise which can be indistinguishable from actual pictures, whereas the discriminator makes an attempt to tell apart whether or not the photographs are actual or synthetically generated. This recreation continues till the generator learns to generate pictures that idiot the discriminator.
Picture-to-Picture Translation Duties
This process entails changing a picture from one area to a different. For instance, should you educated an ML mannequin on a portray from Picasso, it could possibly convert a traditional portray into one thing that Pablo Picasso wish to paint. Whenever you prepare a mannequin like CycleGAN, it learns the important thing options and stylistic parts of the portray after which might be replicated in a traditional portray.
Picture to Picture translation fashions might be divided into two, based mostly on the coaching information they use:
- Paired dataset
- Unpaired dataset
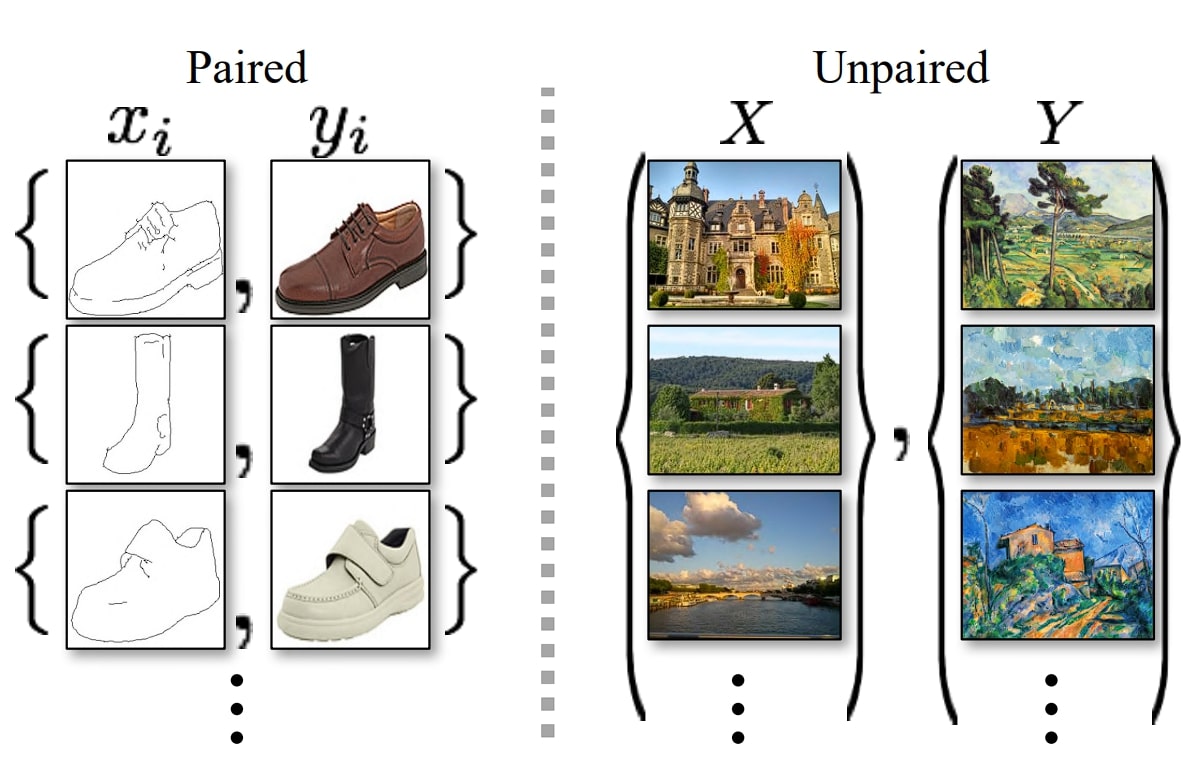
Paired Picture Datasets
In paired picture datasets, every picture in a single area has a corresponding picture within the different area. For instance, in case you are to transform a picture from summer time to winter, then these have to be offered in paired type (the earlier than and after pictures).
It is a process of supervised studying the place the mannequin learns a direct mapping from the enter picture to the output picture.
Pix2Pix is one such mannequin that makes use of paired datasets and might convert sketches into images, daytime to night-time images, and maps to satellite tv for pc pictures.
Nevertheless, such fashions have a giant disadvantage. Creating paired datasets is tough, costly, and typically not possible. However such fashions even have its benefits:
- Direct Supervision: Paired datasets present direct steering on the way it translate pictures.
- Increased High quality Outputs: In consequence, it generates greater picture high quality and higher outcomes.
Unpaired Picture Datasets
In unpaired picture datasets, there isn’t any pairing required between pictures from totally different domains, and consequently, it’s a type of unsupervised studying. Such fashions are simpler to coach as unpaired datasets are simpler to gather and supply extra flexibility since in the actual world it isn’t all the time potential to get paired pictures.
CycleGAN is one such mannequin that excels at this process. It could actually do the whole lot a paired dataset mannequin can do resembling changing paintings, creating Google Maps pictures from satellite tv for pc pictures, and so on. One main drawback of such fashions is that they’re advanced.
What’s CycleGAN? (CycleGAN Defined)
CycleGAN, quick for Cycle-Constant Generative Adversarial Community, is a kind of Generative Adversarial Community (GAN) for unpaired image-to-image translation.
As we mentioned above, paired dataset fashions have a significant disadvantage that you have to have earlier than and after pictures in pairs, which isn’t very straightforward to do. For instance, if you wish to convert summer time images into winter images, you have to have them sorted out in pairs
Nevertheless, CycleGAN overcomes this limitation and offers image-to-image translation with out the necessity for a paired dataset.
The important thing innovation of CycleGAN compared to customary GAN fashions like Pix2Pix lies in its cycle-consistency loss. Normal GANs be taught a direct mapping between the enter and output domains. This works effectively for duties with clear and constant correspondences however battle with duties the place such correspondences are ambiguous or nonexistent.
The important thing thought in CycleGAN and cycle consistency loss features is to transform a picture from area A to area B, after which again from area B to area A. The reversed picture ought to resemble the unique picture. This cycle-consistency mechanism permits the mannequin to be taught significant mappings and semantic particulars between domains with out the necessity for direct pairings.

Here’s what you are able to do with CycleGAN:
- Creative Fashion Switch: Mechanically convert images into inventive kinds, resembling turning {a photograph} right into a portray or vice versa.
- Area Adaptation: Translate pictures from one area to a different, for example, changing day-time images to night-time images or winter images to summer time images.
- Medical Imaging: Translate pictures from totally different medical imaging, resembling changing MRI scans to CT scans.
- Information Augmentation: Generate new coaching samples by translating pictures from one area to a different.

CycleGAN Structure
CycleGAN consists of 4 most important elements: two mills and two discriminators. These elements work along with adversarial loss and cycle consistency loss to carry out picture translation utilizing unpaired picture datasets.
Whereas there are a number of architectures current, the Generator and Discriminator might be comprised of numerous strategies such because the Consideration mechanism, and U-Internet. Nevertheless, the core idea of CycleGANs stays the identical. Subsequently, it’s secure to say that CycleGAN is a manner of performing picture translations quite than a definite structure mannequin.
Furthermore, within the authentic printed paper in 2017, the community incorporates convolution layers with a number of residual blocks, impressed by the paper printed by Justin Johnson and Co. on Perceptual Losses for Actual-Time Fashion Switch and Tremendous-Decision. Learn right here for extra.
Allow us to take a look at the core workings of CycleGAN.
Mills
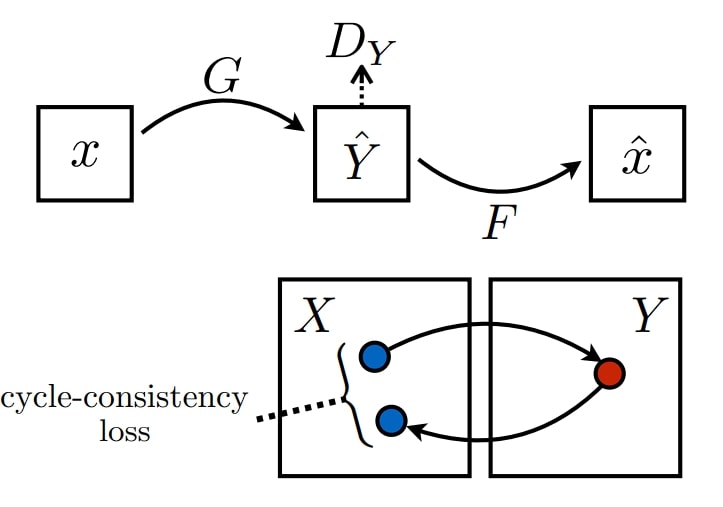
The CycleGAN fashions use two mills, G and F. G interprets pictures from area X to area Y (e.g., horse to zebra), and F interprets the photographs again from area Y to area X (e.g., zebra to horse). That is what varieties a cycle.
- Area- X (horse) -> Generator-G -> Area-Y (zebra)
- Area-Y (zebra)-> Generator-F -> Area-X (horse)
Discriminators
There are two discriminators, DX and DY, one for every generator. DX differentiates between actual pictures from area X and faux pictures generated by F. DY differentiates between actual pictures from area Y and faux pictures generated by G.
Area-X (horse) -> Generator-G (zebra) -> Discriminator- DX -> [Real/Fake]
Area-Y (zebra) -> Generator-F (horse) -> Discriminator- DY -> [Real/Fake]
The discriminator and generator fashions are educated in a typical adversarial zero-sum course of, identical to regular GAN fashions. The mills be taught to idiot the discriminators higher and the discriminator learns to higher detect faux pictures.
Adversarial Loss
The adversarial loss is an important element of CycleGAN and some other GAN mannequin, driving the mills and discriminators to enhance by means of competitors.
- Generator Loss: The generator goals to idiot the discriminator by producing real looking pictures. The generator’s loss measures the success of fooling the discriminator.
- Discriminator Loss: The discriminator goals to categorise actual pictures and generate pictures accurately. The discriminator’s loss measures its potential to tell apart between the 2.
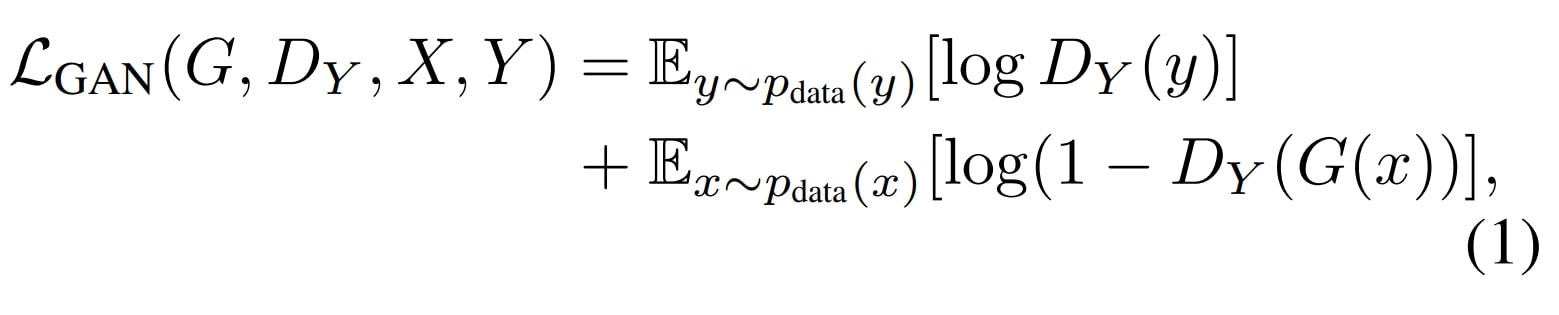
Cycle Consistency Loss
The cycle consistency loss is crucial a part of CycleGAN, because it ensures that a picture from one area when translated to the opposite area and again, ought to appear like the unique picture.
This loss is essential for sustaining the integrity of the photographs and enabling the unpaired image-to-image translation utilizing cycle-consistent adversarial networks.
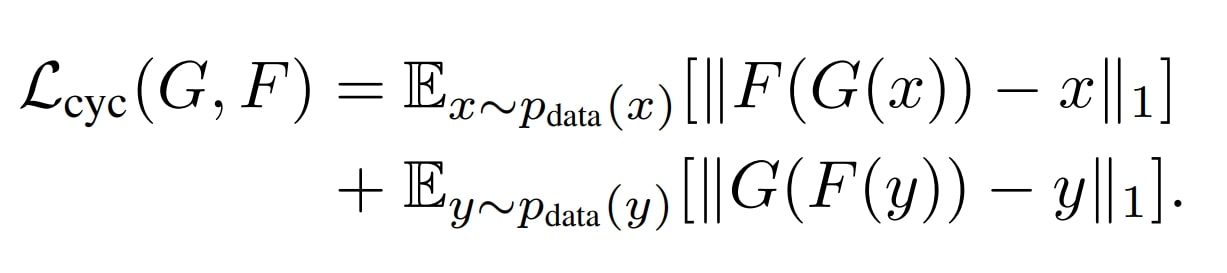
Significance of Cycle Consistency Loss in CycleGAN
Cycle Consistency Loss is what makes CycleGAN particular. By simply utilizing adversarial loss alone, the GAN can generate an infinite variety of eventualities the place the discriminator might be fooled.
However once we use Cycle loss, the mannequin will get a way of course, because the infinite prospects (ineffective) beforehand are was a selected set of prospects (helpful).
- The cycle consistency loss ensures that a picture from one area, when translated to the opposite area after which again, is just like the unique picture. Utilizing this loss makes the mannequin protect the underlying construction and content material of the picture and be taught helpful semantic illustration and never output random pictures.
- With out this loss, the mills will produce arbitrary transformations (that idiot the discriminator) and don’t include any helpful options realized, resulting in unrealistic or meaningless outcomes.
- Mode collapse is one other drawback that the GAN mannequin will face (a typical drawback in GANs the place the generator produces a restricted number of output) with out the cycle loss.
Furthermore, the cycle consistency loss is what offers CycleGAN with a self-supervised sign, guiding the coaching course of even within the absence of paired information.
For instance, with out cycle consistency loss, the interpretation from horse to zebra would possibly produce a picture that appears like a zebra however has misplaced the particular options of the horse (e.g., pose, background). The reverse translation from zebra to horse will then produce a horse picture that appears very totally different from the unique horse, with a unique pose or background.
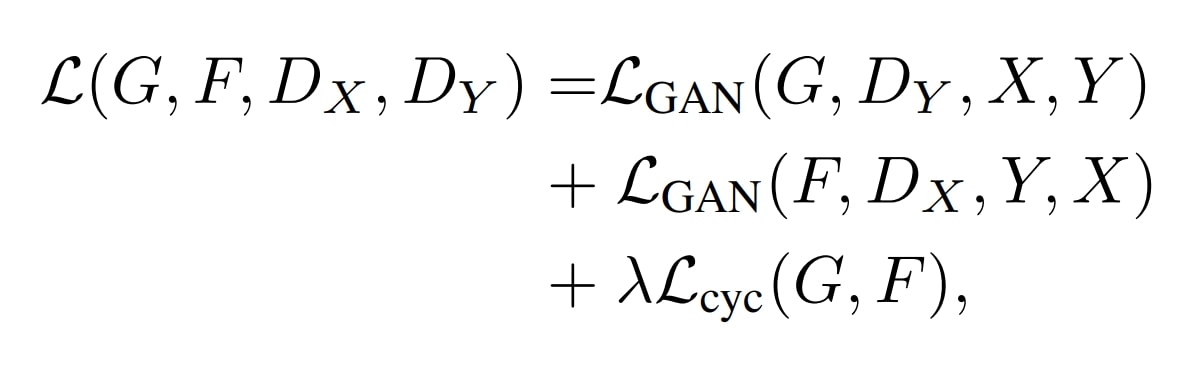
Variants and Enhancements
Because the introduction of CycleGAN, a number of architectures have been launched that use quite a lot of methods to enhance the efficiency of the mannequin. Furthermore, as stated above cycleGAN is a technique and never a discrete structure, subsequently it offers nice flexibility.
Listed below are some variations of CycleGAN.
Masks CycleGAN
The generator in Masks CycleGAN added a masking community compared to customary CycleGAN.
This community generates masks that determine areas of the picture that have to be altered or remodeled. The masks assist in focusing the generative course of on particular areas, resulting in extra exact and real looking transformations.
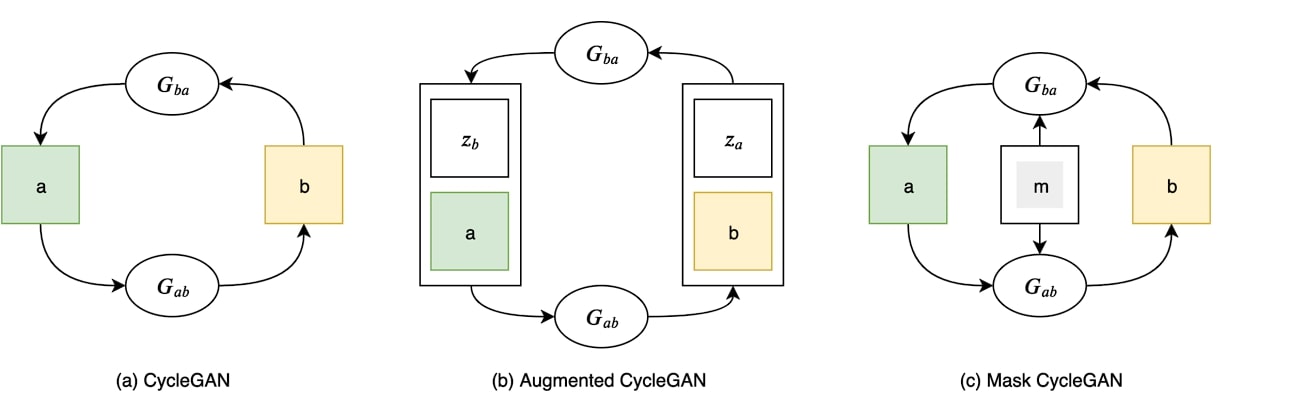
Furthermore, masks CycleGAN combines conventional CycleGAN loss with an extra masks loss and identification loss. This ensures the generated masks give attention to related areas.
This community has a number of makes use of, because the masks permit the community to carry out transformations on particular areas. This results in extra managed and correct outcomes. It may be used for:
- Remodeling objects inside pictures whereas conserving the background unchanged, resembling altering the colour of a automobile with out affecting the environment.
- Picture Inpainting: For instance, filling in lacking elements of a picture or eradicating undesirable objects.
- Altering facial attributes like age, expression, or coiffure.
- Enhancing or remodeling particular areas in medical pictures, resembling highlighting tumors or lesions in MRI scans.
Transformer-based CycleGAN
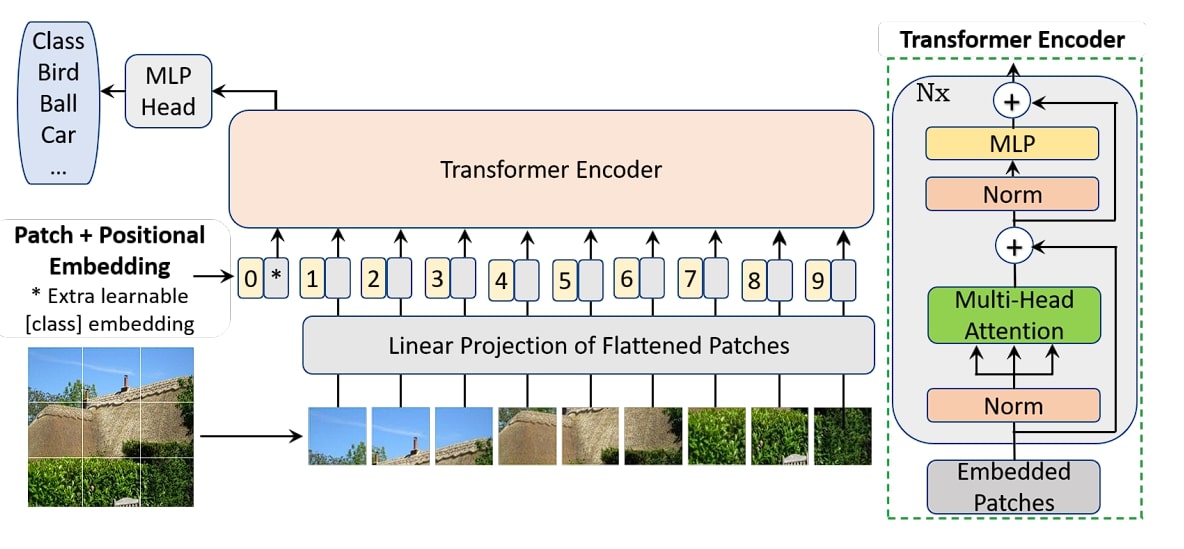
This model of CycleGAN makes use of transformer networks as a substitute of Convolutional Neural Networks (CNNs) within the generator. The generator community of CycleGAN is changed by a Imaginative and prescient Transformer. This distinction on this mannequin provides the power to deal with picture context and long-range dependencies.
Inspecting CycleGAN and Generative AI Additional
On this weblog, we checked out CycleGAN, a GAN-based mannequin, that permits image-to-image translation with out paired coaching information. The structure consists of two mills and two discriminators which can be guided by adversarial and cycle loss.
We then regarded on the core working of CycleGAN, that’s it generates a picture for goal area B from area A, then tries to deliver the unique picture as precisely as potential. This course of permits CycleGAN to be taught the important thing options of the generated picture. Furthermore, we additionally checked out what we might do with the mannequin, resembling changing Google Maps pictures to satellite tv for pc pictures and vice versa or making a portray from the unique picture.
Lastly, we regarded on the variants of CycleGAN, masks cycle GAN, and transformer-based CycleGAN, and the way they differ from the unique proposed mannequin.