Think about an AI that may write poetry, draft authorized paperwork, or summarize advanced analysis papers—however how can we really measure its effectiveness? As Massive Language Fashions (LLMs) blur the strains between human and machine-generated content material, the search for dependable analysis metrics has turn out to be extra essential than ever.
Enter ROUGE (Recall-Oriented Understudy for Gisting Analysis), a strong toolkit that serves as a linguistic microscope for machine-generated textual content. Born within the realm of textual content summarization, ROUGE has developed right into a cornerstone metric for assessing the efficiency of Massive Language Fashions throughout pure language processing (NLP) duties. It’s not only a measurement software—it’s a bridge between the uncooked output of AI methods and the nuanced expectations of human communication.
Metric Description in LLM Context
Within the realm of Massive Language Fashions, ROUGE serves as a precision-focused analysis metric that compares generated mannequin outputs towards reference texts or anticipated responses. In distinction to standard accuracy metrics, ROUGE provides a extra refined analysis of how successfully an LLM retains the structural integrity, semantic that means, and very important substance of supposed outputs.
Utilizing skip-grams, n-grams, and the longest frequent subsequence, ROUGE assesses the diploma of overlap between the generated textual content (speculation) and the reference textual content (floor fact). In jobs like summarization, the place recollection is extra essential than accuracy, ROUGE may be very useful. ROUGE provides precedence on capturing the entire pertinent data from the reference textual content, in distinction to BLEU, which is precision-focused. ROUGE doesn’t absolutely seize semantic that means, although, therefore complementary measures like BERTScore and METEOR are required even when it provides precious insights.
Why ROUGE Issues for LLM Analysis?
For LLMs, ROUGE helps decide how effectively a generated response aligns with anticipated human-written textual content. It’s significantly helpful in:
- Textual content summarization: Checking how effectively the abstract preserves key particulars from the unique textual content.
- Textual content era duties: Evaluating chatbot or AI assistant responses with reference solutions.
- Machine translation analysis: Measuring how carefully a translation matches a reference translation.
- Query-answering methods: Assessing if generated solutions comprise related data.
Kinds of ROUGE for LLM Analysis
ROUGE supplies a number of variants tailor-made to completely different facets of textual content similarity analysis. Every sort is beneficial in assessing completely different language mannequin outputs, equivalent to summaries, responses, or translations. Beneath are the important thing ROUGE variants generally utilized in LLM analysis:
Supply: Rouge Varieties
ROUGE-N (N-gram Overlap)
ROUGE-N measures the overlap of n-grams (steady sequences of phrases) between the generated textual content and reference textual content. It’s extensively utilized in summarization and translation analysis.
System:
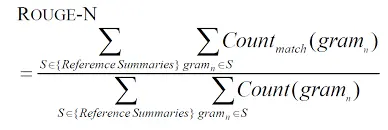
Code Instance:
from rouge import Rouge
generated_text = "The cat is sitting on the mat."
reference_text = "A cat sat on the mat."
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_text)
print(scores[0]['rouge-1']) # ROUGE-1 rating (unigram overlap)
print(scores[0]['rouge-2']) # ROUGE-2 rating (bigram overlap)Output:
{
"rouge-1": {"r": 0.75, "p": 0.6, "f": 0.66},
"rouge-2": {"r": 0.33, "p": 0.25, "f": 0.28}
}ROUGE-S (Skip-Bigram Overlap)
ROUGE-S (Skip-Bigram) measures the overlap of phrase pairs that seem in the identical order however not essentially adjoining. It captures semantic similarity higher than strict n-gram matching.
System:

Code Instance:
print(scores[0]['rouge-s'])Output:
{
"rouge-s": {"r": 0.55, "p": 0.4, "f": 0.46}
}ROUGE-W (Weighted LCS)
ROUGE-W is a weighted model of ROUGE-L that offers greater weight to longer contiguous matching sequences. It’s helpful for assessing fluency and coherence in LLM-generated textual content.
System:

Code Instance:
print(scores[0]['rouge-w'])Output:
{
"rouge-w": {"r": 0.72, "p": 0.58, "f": 0.64}
}ROUGE-L (Longest Widespread Subsequence – LCS)
ROUGE-L measures the longest frequent subsequence (LCS) between the reference and generated texts. It’s helpful for measuring sentence fluency and syntactic correctness.
System:

Code Instance:
print(scores[0]['rouge-l'])Output:
{
"rouge-l": {"r": 0.75, "p": 0.6, "f": 0.66}
}ROUGE-SU (Skip-Bigram with Unigrams)
ROUGE-SU is an extension of ROUGE-S that additionally considers unigrams, making it extra versatile for evaluating LLM-generated responses the place particular person phrase matches matter.
System:

Code Instance:
print(scores[0]['rouge-su'])Output:
{
"rouge-su": {"r": 0.68, "p": 0.52, "f": 0.59}
}ROUGE-Lsum (LCS for Summarization)
ROUGE-Lsum is a variant of ROUGE-L particularly designed for evaluating summarization fashions. It computes LCS over your entire document-summary pair, as a substitute of sentence-by-sentence comparability.
System:

Code Instance:
print(scores[0]['rouge-lsum'])Output:
{
"rouge-lsum": {"r": 0.72, "p": 0.59, "f": 0.65}
}| ROUGE TYPE | MEASURES | BEST FOR |
| ROUGE-N | N-gram overlap (Unigrams, Bigrams, and many others.) | Fundamental textual content similarity |
| ROUGE-S | Skip-Bigram overlap | Capturing versatile phrasing |
| ROUGE-W | Weighted LCS | Evaluating fluency and coherence |
| ROUGE-L | Longest Widespread Subsequence | Measuring sentence construction |
| ROUGE-SU | Skip-bigrams + Unigrams | Dealing with diverse textual content buildings |
| ROUGE-Lsum | LCS for summaries | Summarization duties |
The best way to Use ROUGE for LLM Analysis?
Enter: ROUGE requires three foremost inputs.
Generated Textual content (Speculation)
That is the textual content output produced by a mannequin, equivalent to an LLM-generated abstract or response. The generated textual content is evaluated towards a reference textual content to find out how effectively it captures key data. The standard of the speculation immediately impacts the ROUGE rating, as longer, extra detailed responses might obtain greater recall however decrease precision.
Reference Textual content (Floor Fact)
The reference textual content serves as the perfect or right response, usually written by people. It acts as a benchmark for evaluating the generated textual content’s accuracy. In lots of instances, a number of reference texts are used to account for variations in wording and phrasing. Utilizing a number of references can present a extra balanced evaluation, as completely different human-written texts would possibly convey the identical that means in numerous methods.
Analysis Parameters
ROUGE permits customers to specify completely different analysis settings primarily based on their wants. The important thing parameters embody:
- N-gram measurement: Defines the variety of phrases in a sequence used for overlap comparability (e.g., ROUGE-1 for unigrams, ROUGE-2 for bigrams).
- LCS (Longest Widespread Subsequence) weight: Adjusts the affect of longer shared phrase sequences in ROUGE-L calculations.
- Aggregation methodology: Determines how scores are averaged when a number of reference texts can be found. Widespread approaches embody macro-averaging (averaging throughout all references) and micro-averaging (contemplating occurrences proportionally throughout all situations).
Output
ROUGE supplies numerical scores that point out the similarity between the generated and reference texts. These scores are calculated for various ROUGE variants and embody three foremost elements:
- Recall (r) – Measures how a lot of the reference textual content seems within the generated textual content.
- Precision (p) – Measures how a lot of the generated textual content matches the reference textual content.
- F1-score (f) – The harmonic imply of recall and precision, balancing each metrics.
A typical output from ROUGE (in Python) seems to be like this:
{
"rouge-1": {"r": 0.75, "p": 0.6, "f": 0.66},
"rouge-2": {"r": 0.2, "p": 0.16, "f": 0.18},
"rouge-l": {"r": 0.75, "p": 0.6, "f": 0.66},
"rouge-s": {"r": 0.55, "p": 0.4, "f": 0.46}
}Amongst these, ROUGE-L and ROUGE-S present extra insights into textual content similarity. ROUGE-L focuses on the longest frequent subsequence (LCS), making it helpful for evaluating fluency and sentence construction. Alternatively, ROUGE-S (Skip-Bigram) measures phrase pair overlaps even when they aren’t adjoining, capturing extra versatile phrasing.
The computed scores can range when a number of reference texts can be found. In such instances, ROUGE permits aggregation throughout a number of references utilizing two strategies:
- Macro-averaging: Computes ROUGE scores for every reference individually after which averages them.
- Micro-averaging: Combines all reference texts and evaluates them collectively, giving extra weight to longer references.
As an example, when aggregating ROUGE scores throughout a number of reference texts, we receive:
Macro-Averaged Scores:
ROUGE-1 F1-score: 0.71
ROUGE-2 F1-score: 0.21
ROUGE-L F1-score: 0.67
ROUGE-S F1-score: 0.51
Micro-Averaged Scores:
ROUGE-1 F1-score: 0.72
ROUGE-2 F1-score: 0.24
ROUGE-L F1-score: 0.69
ROUGE-S F1-score: 0.53These aggregated scores present a extra dependable analysis of mannequin efficiency when a number of references exist. By contemplating macro-averaging, which treats every reference equally, and micro-averaging, which accounts for variations in reference size, ROUGE ensures a extra balanced evaluation of textual content era high quality.
ROUGE Implementation in Python
We’ll now implement ROUGE in Python.
Step1: Importing libraries
from rouge import RougeStep2: Instance Implementation
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
class LLMEvaluator:
def __init__(self, model_name):
self.rouge = Rouge()
self.mannequin = AutoModelForCausalLM.from_pretrained(model_name)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
def evaluate_model_response(self, immediate, reference_response):
# Generate mannequin response
inputs = self.tokenizer(immediate, return_tensors="pt")
output = self.mannequin.generate(**inputs, max_length=100)
generated_response = self.tokenizer.decode(output[0])
# Compute ROUGE scores
rouge_scores = self.rouge.get_scores(generated_response, reference_response)[0]
return {
'generated_response': generated_response,
'rouge_scores': rouge_scores
}
ROUGE Implementation with and with out Aggregation
Step 1: Importing libraries
We first import the Rouge class from the rouge bundle to compute similarity scores between generated and reference textual content.
from rouge import RougeStep 2: Instance Implementation
We outline a LLMEvaluator class that hundreds a pre-trained causal language mannequin and tokenizer. The category generates responses for a given immediate and computes ROUGE scores by evaluating them with a reference response.
# Instance: Single reference textual content vs. generated textual content
generated_text = "A cat was sitting on a mat."
reference_text = "The cat sat on the mat."
rouge = Rouge()
# Compute ROUGE scores with out aggregation (single reference)
scores = rouge.get_scores(generated_text, reference_text)
print("ROUGE Scores (With out Aggregation):")
print(scores)
# Instance with a number of references
reference_texts = [
"The cat sat on the mat.",
"A small cat rested on the mat.",
"A feline was sitting quietly on a rug."
]
# Compute ROUGE scores with aggregation
aggregated_scores = rouge.get_scores(generated_text, reference_texts, avg=True)
print("nROUGE Scores (With Aggregation throughout A number of References):")
print(aggregated_scores)Step 3: Output
With out aggregation (Single Reference)
[
{
"rouge-1": {"r": 0.75, "p": 0.6, "f": 0.66},
"rouge-2": {"r": 0.2, "p": 0.16, "f": 0.18},
"rouge-l": {"r": 0.75, "p": 0.6, "f": 0.66}
}
]
With aggregation (A number of References)
{
"rouge-1": {"r": 0.78, "p": 0.65, "f": 0.71},
"rouge-2": {"r": 0.25, "p": 0.20, "f": 0.22},
"rouge-l": {"r": 0.80, "p": 0.67, "f": 0.73}
}High 3 Translation Jokes ROUGE Would Respect:
- Why did the translator go to remedy? Too many unresolved references!
- What’s a language mannequin’s favourite dance? The N-gram Shuffle!
- How does ROUGE inform a joke? With good recall and precision!
Past the humor, ROUGE represents a essential breakthrough in understanding how machines comprehend language. It’s not nearly counting phrases – it’s about capturing the soul of communication.
Use Circumstances of ROUGE
- Evaluating Summarization Fashions: ROUGE is the usual metric for summarization duties.
- Assessing LLM Efficiency: Used to check LLM-generated content material with human-written references.
- Machine Translation Analysis: Helps in measuring similarity with reference translations.
- Dialogue Era: Evaluates chatbot and conversational AI responses.
- Automated Content material Scoring: Utilized in instructional platforms to evaluate student-generated solutions.
- Textual content-Based mostly Query Answering: Helps measure how precisely AI-generated solutions align with anticipated responses.
The Translation Roulette Problem
def translation_detective_game():
translations = [
"The cat sat on the mat.",
"A feline occupied a floor covering.",
"Whiskers found horizontal support on the textile surface."
]
print("🕵️ ROUGE DETECTIVE CHALLENGE 🕵️")
print("Guess which translation is closest to the unique!")
# Simulated ROUGE scoring (with a twist of humor)
def rouge_score(textual content):
# Completely scientific detective methodology
return random.uniform(0.5, 0.9)
for translation in translations:
rating = rouge_score(translation)
print(f"Translation: '{translation}'")
print(f"Thriller Rating: {rating:.2f} 🕵️♀️")
print("nCan you crack the ROUGE code?")
translation_detective_game()
Limitations and Bias in ROUGE
We’ll now look into the restrictions and bias in ROUGE.
- Floor-Stage Comparability: ROUGE focuses on n-gram overlap, ignoring that means and context.
- Synonym and Paraphrasing Points: It penalizes variations even when they protect that means.
- Bias Towards Longer Texts: Increased recall can inflate scores with out really enhancing high quality.
- Does Not Measure Fluency or Grammar: It doesn’t seize sentence coherence and readability.
- Incapability to Deal with Factual Correctness: ROUGE doesn’t confirm whether or not generated content material is factually correct.
Conclusion
ROUGE is sort of a GPS for language fashions—helpful for navigation, however unable to really perceive the journey. As AI continues to push boundaries, our analysis metrics should evolve from mere number-crunching to real comprehension. The way forward for LLM evaluation isn’t about counting phrase matches, however about capturing the essence of human communication—nuance, creativity, and that means.
Whereas ROUGE supplies an important first step in quantifying textual content similarity, it stays simply that—a primary step. The true problem is in creating evaluation measures that may differentiate between a technically sound response and one that’s genuinely clever. As language fashions advance, our analysis methods should additionally advance, evolving from easy measurement devices to advanced interpreters of textual content produced by machines.
Key Takeaways
- ROUGE is a essential metric for evaluating Massive Language Mannequin (LLM) outputs in summarization, translation, and textual content era duties.
- Completely different ROUGE variants (ROUGE-N, ROUGE-L, ROUGE-S) measure textual content similarity utilizing n-grams, longest frequent subsequence, and skip-bigrams.
- ROUGE prioritizes recall over precision, making it significantly helpful for evaluating how a lot key data is retained.
- It has limitations, because it doesn’t absolutely seize semantic that means, requiring complementary metrics like BERTScore and METEOR.
- Python implementation of ROUGE permits builders to evaluate model-generated textual content towards human-written references successfully.
Regularly Requested Questions
A. ROUGE is an analysis metric used to evaluate textual content similarity in NLP duties like summarization and machine translation.
A. ROUGE focuses on recall (capturing key data), whereas BLEU emphasizes precision (matching precise phrases and phrases).
A. The primary sorts are ROUGE-N (n-gram overlap), ROUGE-L (longest frequent subsequence), and ROUGE-S (skip-bigram overlap).
A. No, ROUGE measures lexical overlap however doesn’t absolutely seize that means; BERTScore and METEOR are higher for semantics.
A. The rouge library in Python permits customers to compute ROUGE scores by evaluating generated textual content with reference textual content.
Gen AI Intern at Analytics Vidhya
Division of Pc Science, Vellore Institute of Know-how, Vellore, India
I’m presently working as a Gen AI Intern at Analytics Vidhya, the place I contribute to modern AI-driven options that empower companies to leverage knowledge successfully. As a final-year Pc Science scholar at Vellore Institute of Know-how, I carry a strong basis in software program growth, knowledge analytics, and machine studying to my position.
Be happy to attach with me at [email protected]
Login to proceed studying and luxuriate in expert-curated content material.