DensePose is a Deep Studying mannequin for dense human pose estimation which was launched by researchers at Fb in 2010. It performs pose estimation with out requiring devoted sensors. It maps commonplace RGB photos to a 3D floor illustration of the human physique, making a dense correspondence between 2D photos and 3D human fashions.
Consequently, the dense pose created by this mannequin is a lot richer and detailed in comparison with commonplace pose estimation.
After we have a look at its potential purposes, it’s infinite. DensePose can be utilized within the area of AR/VR, however other than that, it opens numerous inventive purposes, for instance, you’ll be able to check out garments and see how they might look in your physique earlier than shopping for them or use this Deep Studying mannequin for efficiency evaluation in sports activities to trace participant actions and biomechanics.

On this weblog, we are going to look into the workings of DensePose and the way it converts a easy image into dense human poses of the human physique, with out the necessity for devoted sensors.
About us: Viso Suite is the premier pc imaginative and prescient infrastructure for enterprises. With your entire ML pipeline beneath one roof, Viso Suite eliminates the necessity for level options. To be taught extra about how Viso Suite will help automate your corporation wants, ebook a demo with our group.
Excessive-Degree Overview of DensePose
As we mentioned above, DensePose maps every pixel in a picture to a UV-created 3D mannequin. To carry out this, DensePose goes by the next intermediatory steps:
- Enter Picture
- Function Extraction with CNN
- Area Proposal Community (RPN)
- RoI Align
- Segmentation Department for physique components segmentation
- UV Mapping utilizing the UV Mapping Head
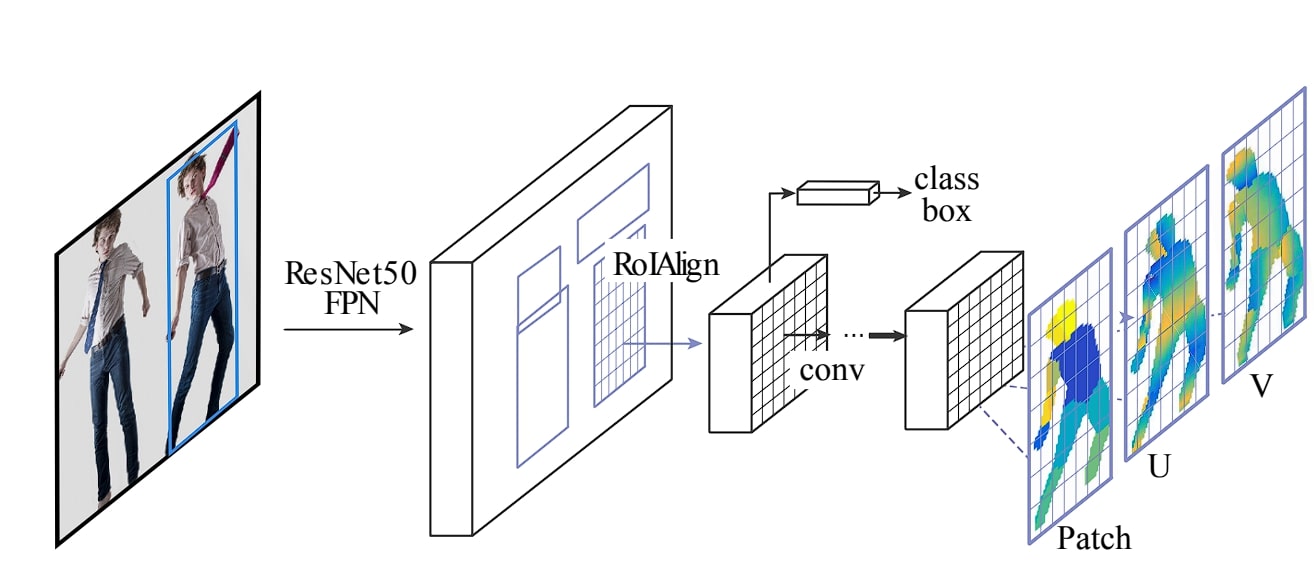
Allow us to focus on the working of the DensePose mannequin.
Function Extraction
Enter Picture:
- We offer the enter picture to the mannequin.
Function Extraction with a Convolutional Neural Community (CNN):
- On this first step of the method, DensePose passes the given picture right into a pre-trained Convolutional Neural Community (CNN), equivalent to ResNet. ResNet extracts options from the enter picture.
Area Proposal Community (RPN):
- DensePose makes use of a Area Proposal Community (RPN) to generate proposals for areas (bounding containers round human physique components). This step is vital because it helps to slim down the areas the mannequin must give attention to.
RoI Align and Area of Curiosity-Primarily based Options:
- The proposals generated by the RPN community are additional refined utilizing Area of Curiosity (RoI) Align. This method additional improves the situation of proposed areas.
Pose Estimation:
- As soon as the areas are proposed, the mannequin performs occasion segmentation to distinguish between a number of human physique components that may be current within the picture. From this segmentation, it creates a human pose.
UV Mapping
For every detected human pose, the DensePose mannequin predicts UV coordinates for every pixel throughout the area of curiosity. UV mapping is a course of utilized in pc graphics to map a 2D picture onto a 3D mannequin. “u” and “v” right here means the coordinates in a 2D mannequin.
DensePose makes use of a standardized 3D mannequin of the human physique, often known as the canonical physique mannequin. This mannequin has its floor parameterized with UV coordinates. To do that, a devoted UV mapping head is used.

UV Mapping Head:
- That is the a part of the DensePose community that focuses on taking the RoI Aligned options to foretell the UV coordinates. This head consists of a number of convolutional layers adopted by absolutely linked layers to refine the prediction.
- The output from this head is a dense correspondence map the place each pixel throughout the area of curiosity is assigned a UV coordinate, which maps it to the 3D physique mannequin.
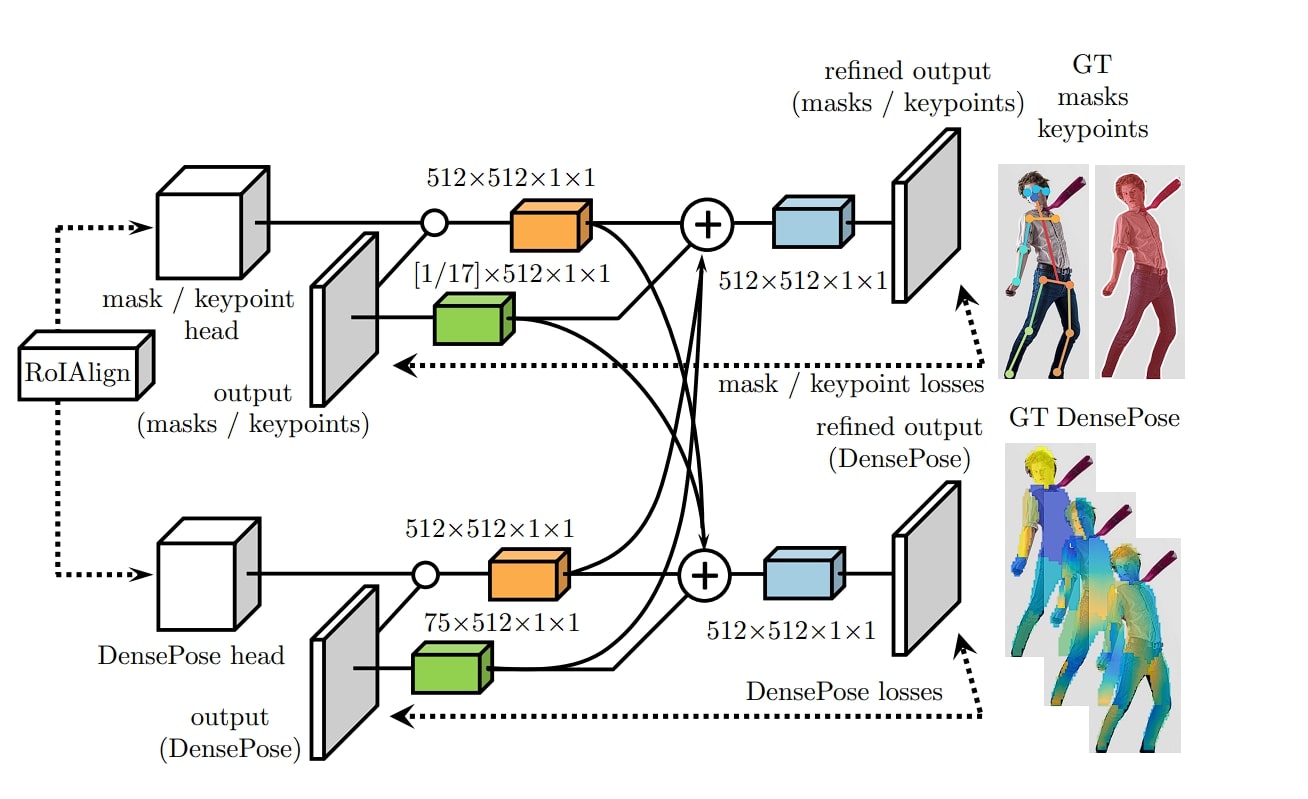
Structure of DensePose mannequin
Within the above part, we checked out an summary of the steps the picture goes by within the DensePose community. Right here is the detailed structure:
- Spine Community: Makes use of ResNet for characteristic extraction
- Area Proposal Community (RPN): Proposes Area of curiosity utilizing Masks-RCNN
- RoIAlign Layer: As a substitute of utilizing Area of Curiosity (RoI), DensePose makes use of a RoI Align layer.
- Segmentation Masks Prediction: A separate department contained in the RPN community to phase totally different human physique components.
- DensePose Head: Maps physique components to UV coordinates
- Keypoint Head: Used for pose estimation
Spine Community
As we mentioned above, DensePose makes use of ResNet as its spine, which is used to extract options from the given picture to facilitate the method of mapping UV coordinates.
ResNet is a deep studying mannequin made up of convolution layers. What differentiates ResNet from a normal convolution community is that it makes use of residual blocks, on this, the enter from one layer is added straight to a different layer later within the community, which helps with combating the vanishing gradient downside present in deep Neural Networks.
Area Proposal Community (RPN)
In DensePose, the authors used Masks-RCNN to detect potential areas of curiosity within the human physique. It really works by taking enter from options extracted by the spine community. Then it conducts a number of steps to generate bounding field proposals utilizing anchor containers. Listed below are the steps concerned:
- Anchor Packing containers: Anchor containers are reference containers which are predefined with numerous scales and side ratios. The mannequin locations these containers and predicts whether or not a selected human physique is current contained in the field or not. You may be questioning why use these.
The reply is that with out this the mannequin may have an infinite variety of potential locations to look into; by utilizing anchor containers, the mannequin is restricted to sure prospects solely. Anchor containers give a place to begin to the mannequin. - Objectness Scores: The RPN predicts objectness scores for every anchor field to calculate the chance of containing an object (on this case, human physique components in DensePose).
- Bounding Field Regression: As soon as the mannequin selects the anchor containers, bounding field regression offsets assist to regulate the anchor containers to suit the area of curiosity by shifting them across the physique half.
Keypoint Head
The Keypoint head in DensePose helps with localizing keypoints within the human physique (equivalent to joints), these are then used to estimate the pose of the individual. It really works by producing a heatmap for numerous physique components (every physique half has its heatmap channel), the place every key level is represented with the best worth.
Furthermore, the important thing level head is beneficial for numerous oblique features equivalent to bettering DensePose estimation by serving as an auxiliary supervisor, as the important thing factors function coaching indicators.
RoI Align
The RoI Align layer in DensePose ensures that the options extracted from every area of curiosity (human physique areas) are precisely aligned and represented. The RoI Align layer differs from commonplace RoI pooling. The issue with the RoI pooling layer is that it extracts fixed-size characteristic maps from the area of curiosity proposed.
Furthermore, it additionally quantifies the coordinates of the area to discrete values (it’s a course of the place the continual coordinates of the extracted areas of curiosity are rounded to the closest integer grid factors). It is a downside, particularly in duties that require excessive precision, equivalent to DensePose estimation.
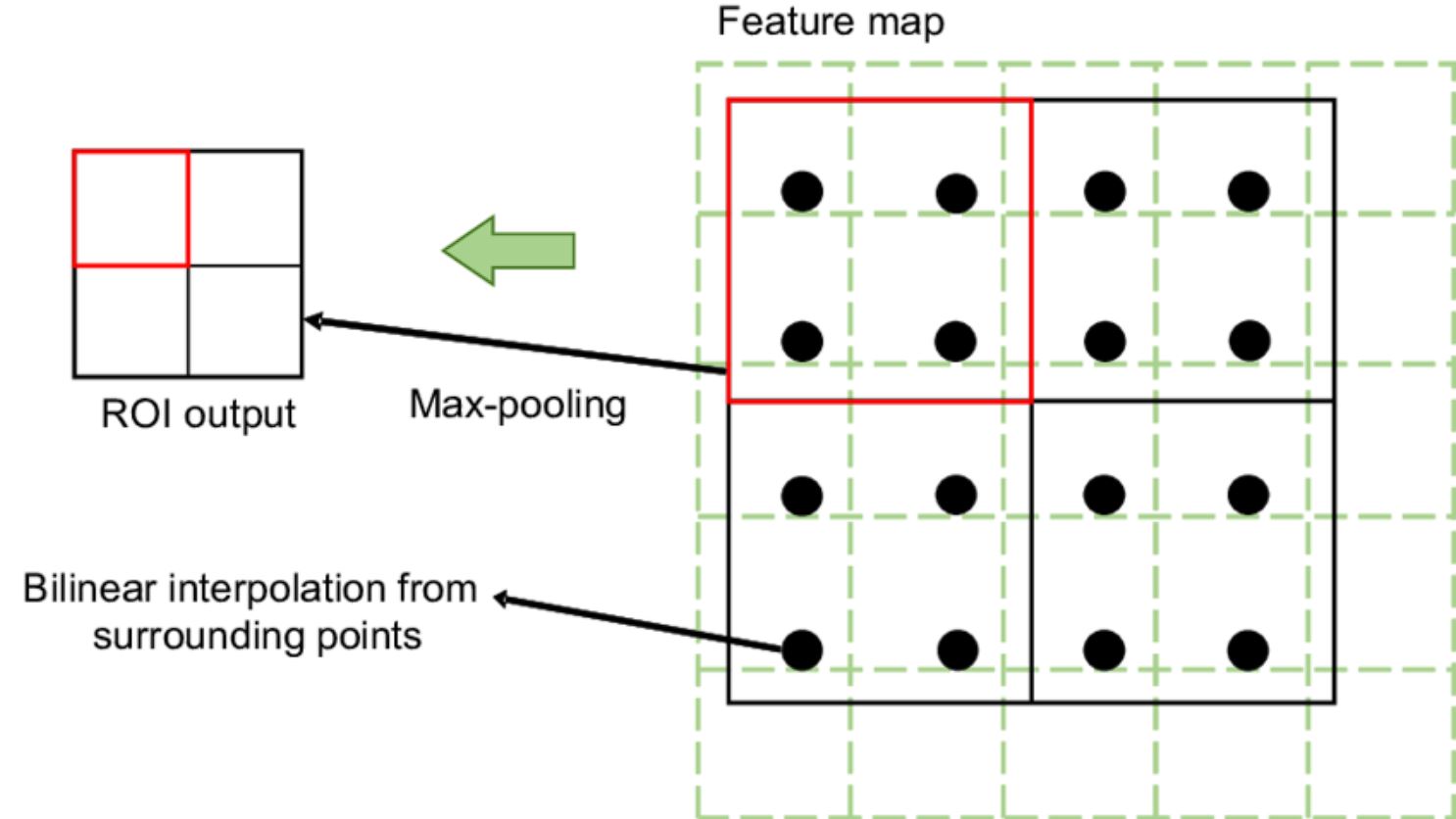
The RoI align layer overcomes the restrictions by eliminating the quantization of RoI boundaries by utilizing bilinear interpolation (interpolation is a mathematical method that estimates unknown values that fall between recognized values in a sequence). Bilinear interpolation extends linear interpolation to 2 dimensions.
DensePose-RCNN
A area proposal community attracts bounding containers round components of a picture the place human physique components are more likely to be discovered. The output from RPN is a set of area proposals.
Moreover, DensePose makes use of a Masks-RCNN (an extension of Sooner-RCNN). The distinction between Sooner-RCNN and Masks-RCNN is using separate heads as an example segmentation masks prediction, which is a department that predicts binary masks (utilizing bilinear interpolation).
Subsequently, DensePose-RCNN is shaped by combining the segmentation masks with dense pose estimation.
Segmentation Masks Prediction
It is a separate department contained in the RPN community for the segmentation of various physique components within the human physique.
Nonetheless, to carry out segmentation prediction, the next steps happen:
- The Area Proposal Community generates bounding containers across the candidate areas which are more likely to include objects (on this case, people).
- RoI Align is utilized to those proposals for exact alignment of the proposed areas.
- Lastly, the segmentation process is carried out. A devoted department within the community processes the aligned options to foretell binary masks for every proposed area. This department consists of a number of convolutional layers that output a masks for every area of curiosity, that signifies the presence of physique components.
Lastly, the DensePose head takes totally different segmented physique components and maps them to a steady floor that outputs the UV coordinates.
Coaching the DensePose Mannequin
The DensePose mannequin is educated on the COCO-DensePose, an extension of the unique COCO dataset. The extra photos include the human physique annotated with labels that map picture pixels to the 3D floor of the human mannequin.
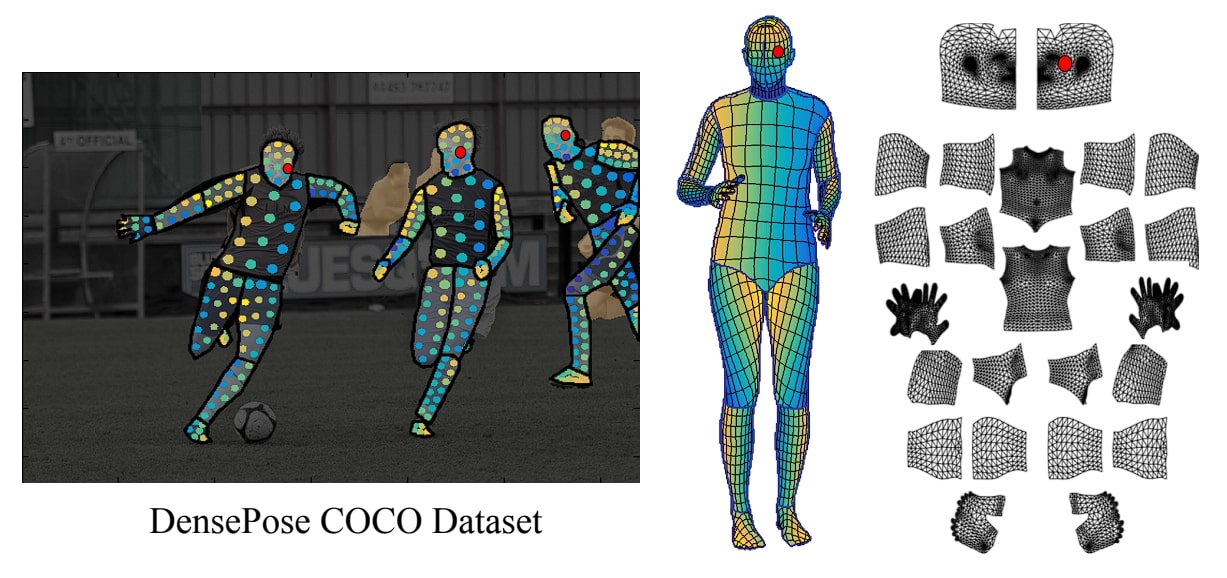
The annotators first phase the physique into totally different components equivalent to the pinnacle, torso, and legs. Then every 2D picture is mapped to a 3D human mannequin by creating dense correspondence mapping pixels from 2D photos to UV coordinates on the 3D mannequin.
Functions of DensePose
The DensePose mannequin with its dense pose estimation affords integration into various fields. We are going to have a look at potential situations the place the mannequin may be applied on this part.
Augmented Actuality (AR):
The sphere of AR will get a lift as a result of DensePose. As AR relies upon upon cameras and sensors, DensePose supplies a possibility to beat the {hardware} stipulations. This permits for a greater and extra seamless expertise for the customers. Furthermore, utilizing DensePose we will create digital avatars of the customers, and permit them to attempt on totally different outfits and attire within the simulation.

Animation and VFX
The mannequin can be utilized to generate and simplify the method of character animations, the place the human movement is captured after which transferred to digital characters. This can be utilized in films, video games, and simulation functions.
Sports activities Evaluation
DensePose mannequin can be utilized in sports activities to research athlete efficiency. This may be executed by monitoring physique actions and postures throughout coaching and competitions. The info generated can then be used to know motion and biomechanics for teaching and analytic functions.

Medical Area
The medical area and particularly chiropractors can use DensePose to research physique posture and actions. This may equip the docs higher for treating sufferers.
E-Commerce
DensePose can be utilized by clients to nearly attempt on garments and equipment, and visualize how they might look in them earlier than they commit to purchasing selections. This may enhance buyer satisfaction and supply a novel promoting level for the companies.
Furthermore, they’ll additionally provide customized vogue suggestions, by utilizing the DensePose mannequin to first seize the consumer’s physique after which create avatars that resemble them.
Limitations of DensePose
Within the earlier part, we focus on the potential makes use of of the mannequin. Nonetheless, there are limitations that DensePose faces, and subsequently it requires additional analysis and enchancment in these key areas.
Lack of 3D Mesh
Though DensePose supplies 3D mesh coordinates, it doesn’t yield 3D illustration. There’s nonetheless a developmental hole between changing an RGB picture to a 3D mannequin straight.
Lack of Cell Integration
One other key limitation of the DensePose mannequin is its dependency on computational sources. This makes it tough to combine DensePose into cellular and dealt with devices. Nonetheless, utilizing cloud architectures to do the computation can repair this downside.
However, this creates a excessive dependence on the provision of high-speed web connection. A majority of individuals lack high-speed connections at house.
Dataset
The important thing motive that DensePose can carry out dense pose estimation is because of the dataset used. Creating the DensePose-COCO dataset required in depth human annotation and time sources, and given these, there are solely 50k photos with UV coordinates for twenty-four physique components with a decision of 256 x 256. It is a limiting issue by way of coaching and accuracy of the mannequin. A denser UV correspondence factors may make the mannequin carry out higher.
Conclusion
On this weblog, we appeared on the structure of DensePose, a dense pose estimation mannequin developed by researchers at Fb. It extends the usual Masks-RCNN framework by including a UV mapping head. The mannequin takes in an image and makes use of a spine community to extract options of the picture, then the Area Proposal Community generates potential candidates within the picture that doubtless include people.
The RoI Align layer additional improves the areas detected, after which that is handed to the segmentation department which detects totally different human physique components. For pose estimation, a keypoint head is used to detect joints and key factors within the human physique. Lastly, the DensePose head maps the physique components to UV coordinates for correct dense pose estimation.
One of many key components that make the DensePose mannequin spectacular is the creation of a devoted dataset for its coaching, the place the human annotators map components of the human physique to a 3D mannequin.
Examine different Deep Studying fashions in our fascinating blogs beneath:
Viso Suite Infrastructure
Viso Suite supplies absolutely personalized, end-to-end options with edge computing capabilities. With cameras, sensors, and different {hardware} linked to Viso Suite pc imaginative and prescient infrastructure, enterprises can simply handle your entire utility pipeline. Be taught extra about Viso Suite by reserving a demo with our group.