DATA PREPROCESSING
6 enjoyable methods to categorize numbers into bins!

⛳️ Extra DATA PREPROCESSING, defined:
· Lacking Worth Imputation
· Categorical Encoding
· Information Scaling
▶ Discretization
· Over- & Underneath-sampling (quickly!)
Most machine studying mannequin requires the info to be numerical — all object or categorical information needs to be in numerical format first. However, truly, there are occasions when categorical information turns out to be useful (it’s extra helpful to us human than to the machines more often than not). Discretization (or binning) does precisely that — changing numerical information into categorical ones!
Relying in your aim, there are quite a few solution to categorize your information. Right here, we’ll use a easy dataset to point out via six completely different binning strategies. From equal-width to clustering-based approaches, we’ll sweep these numerical values into some categorical bins!

Discretization, often known as binning, is the method of remodeling steady numerical variables into discrete categorical options. It includes dividing the vary of a steady variable into intervals (bins) and assigning information factors to those bins based mostly on their values.
- Dealing with Outliers: Binning can cut back the influence of outliers with out eradicating information factors.
- Bettering Mannequin Efficiency: Some algorithms carry out higher with categorical inputs (equivalent to Bernoulli Naive Bayes).
- Simplifying Visualization: Binned information might be simpler to visualise and interpret.
- Lowering Overfitting: It might probably forestall fashions from becoming to noise in high-precision information.
Information That Typically Advantages from Binning:
- Steady variables with extensive ranges: Variables with a big unfold of values can typically profit from grouping.
- Skewed distributions: Binning may help normalize closely skewed information.
- Variables with outliers: Binning can deal with the impact of maximum values.
- Excessive-cardinality numerical information: Variables with many distinctive values might be simplified via binning.
Information That Often Doesn’t Want Binning:
- Already categorical information: Variables which can be already in discrete classes don’t want additional binning.
- Discrete numerical information with few distinctive values: If a variable solely has a small variety of potential values, binning may not present extra profit.
- Numeric IDs or codes: These are supposed to be distinctive identifiers, not for evaluation.
- Time sequence information: When you can bin time sequence information, it typically requires specialised strategies and cautious consideration, however much less widespread general.

To exhibit these binning strategies, we’ll be utilizing this synthetic dataset. Say, that is the climate situation in some golf course, collected on 15 completely different days.
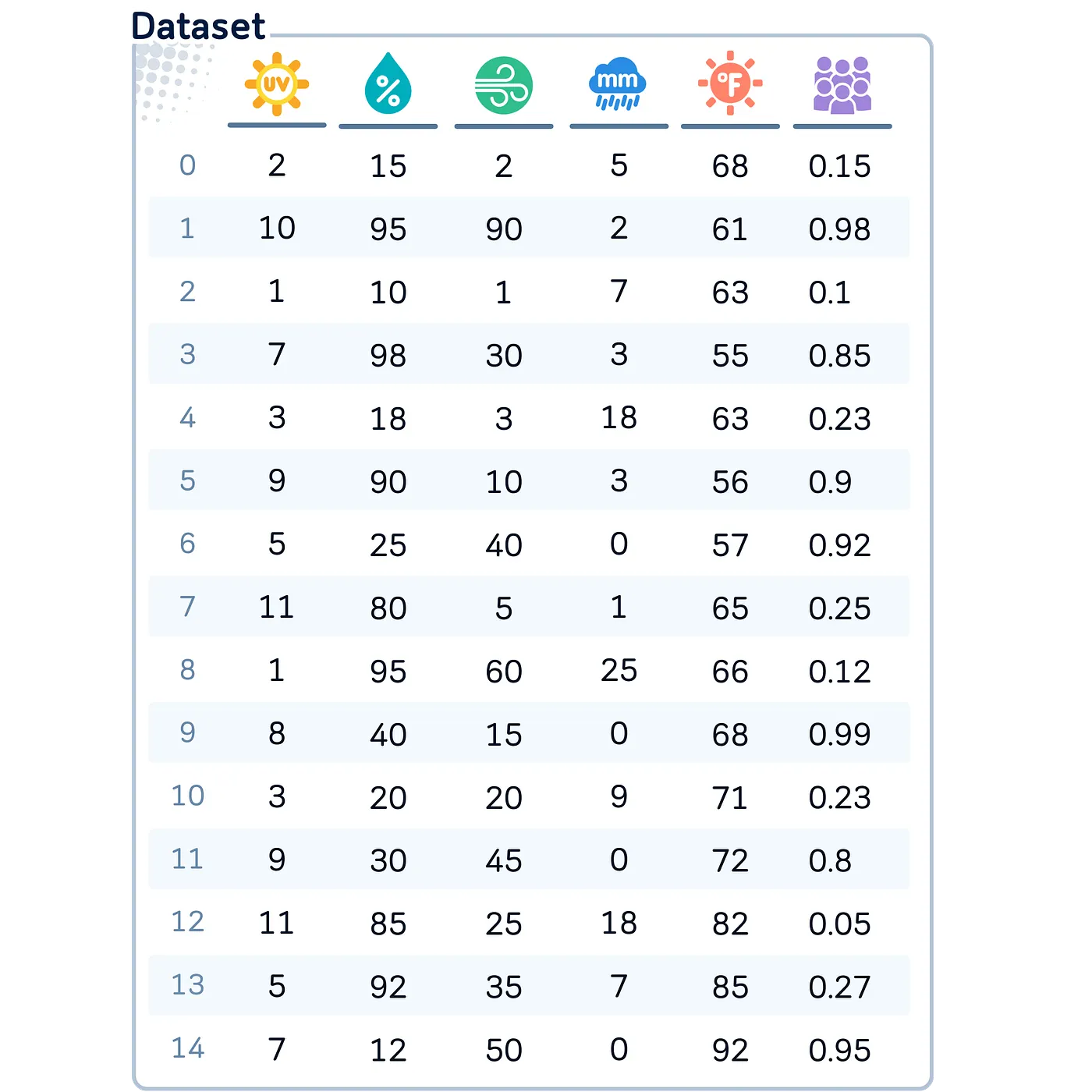
import pandas as pd
import numpy as np# Create the dataset as a dictionary
information = {
'UVIndex': [2, 10, 1, 7, 3, 9, 5, 11, 1, 8, 3, 9, 11, 5, 7],
'Humidity': [15, 95, 10, 98, 18, 90, 25, 80, 95, 40, 20, 30, 85, 92, 12],
'WindSpeed': [2, 90, 1, 30, 3, 10, 40, 5, 60, 15, 20, 45, 25, 35, 50],
'RainfallAmount': [5,2,7,3,18,3,0,1,25,0,9,0,18,7,0],
'Temperature': [68, 60, 63, 55, 50, 56, 57, 65, 66, 68, 71, 72, 79, 83, 81],
'Crowdedness': [0.15, 0.98, 0.1, 0.85, 0.2, 0.9, 0.92, 0.25, 0.12, 0.99, 0.2, 0.8, 0.05, 0.3, 0.95]
}
# Create a DataFrame from the dictionary
df = pd.DataFrame(information)
Utilizing this dataset, let’s see how varied binning strategies might be utilized to our columns!
Equal-width binning divides the vary of a variable right into a specified variety of intervals, all with the identical width.
Frequent Information Sort: This technique works nicely for information with a roughly uniform distribution and when the minimal and most values are significant.
In our Case: Let’s apply equal-width binning to our UV Index variable. We’ll create 4 bins: Low, Average, Excessive, and Very Excessive. We selected this technique for UV Index as a result of it provides us a transparent, intuitive division of the index vary, which may very well be helpful for understanding how completely different index ranges have an effect on {golfing} choices.
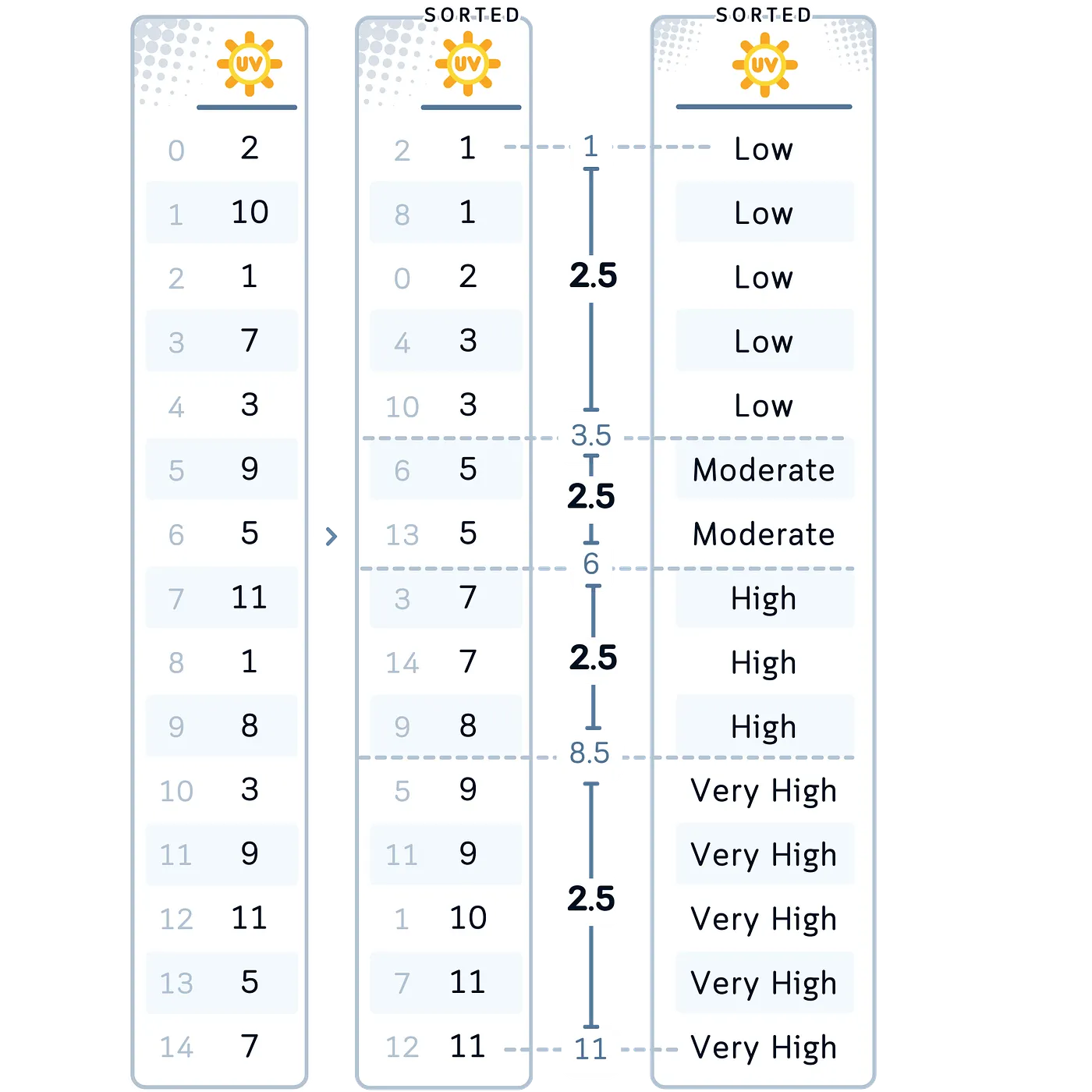
# 1. Equal-Width Binning for UVIndex
df['UVIndexBinned'] = pd.lower(df['UVIndex'], bins=4,
labels=['Low', 'Moderate', 'High', 'Very High'])
Equal-frequency binning creates bins that comprise roughly the identical variety of observations.
Frequent Information Sort: This technique is especially helpful for skewed information or once you wish to ensure a balanced illustration throughout classes.
In our Case: Let’s apply equal-frequency binning to our Humidity variable, creating three bins: Low, Medium, and Excessive. We selected this technique for Humidity as a result of it ensures we have now an equal variety of observations in every class, which might be useful if humidity values aren’t evenly distributed throughout their vary.
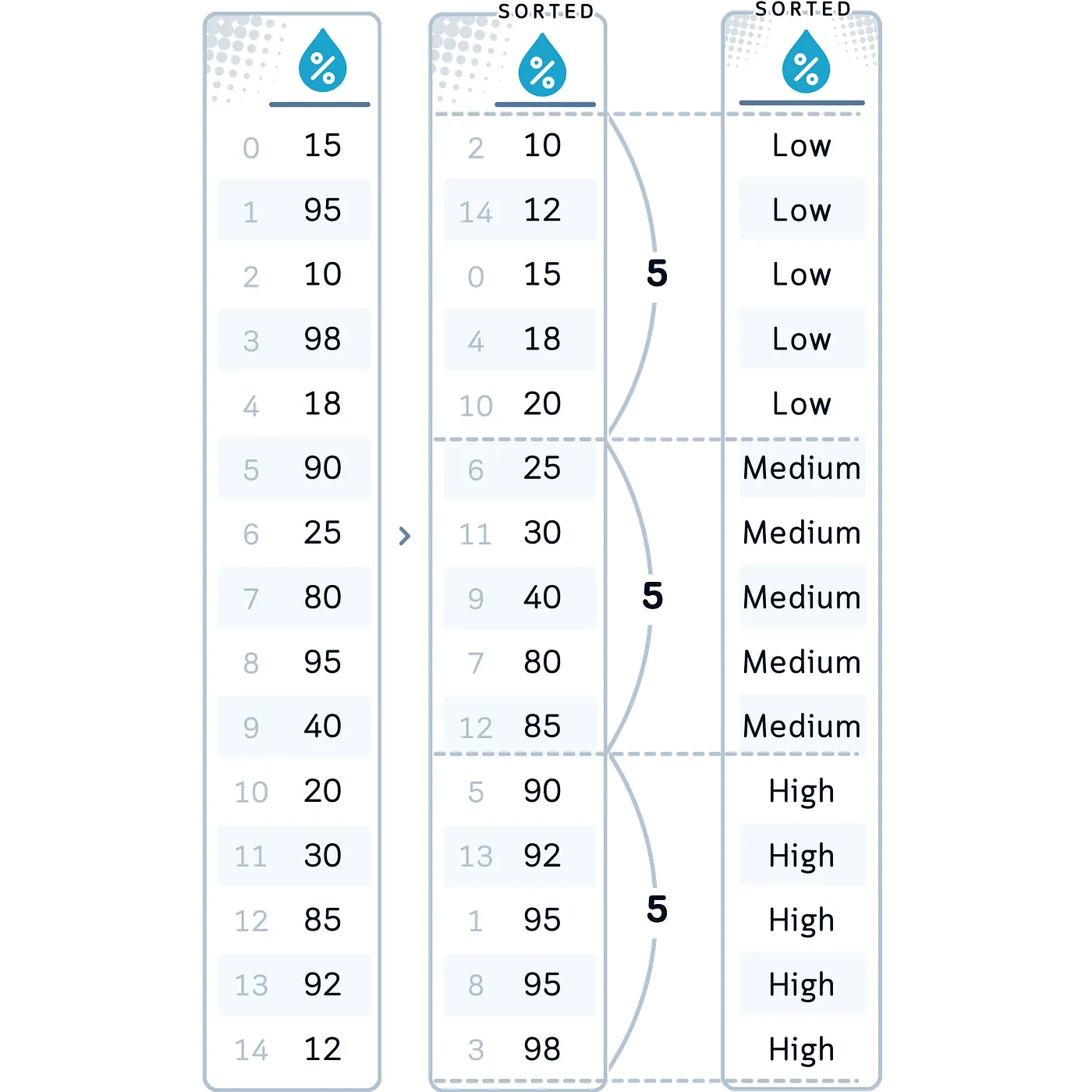
# 2. Equal-Frequency Binning for Humidity
df['HumidityBinned'] = pd.qcut(df['Humidity'], q=3,
labels=['Low', 'Medium', 'High'])
Customized binning lets you outline your personal bin edges based mostly on area data or particular necessities.
Frequent Information Sort: This technique is good when you’ve gotten particular thresholds which can be significant in your area or once you wish to deal with specific ranges of values.
In our Case: Let’s apply customized binning to our Rainfall Quantity. We selected this technique for this column as a result of there are standardized classes for rain (equivalent to described on this website) which can be extra significant than arbitrary divisions.
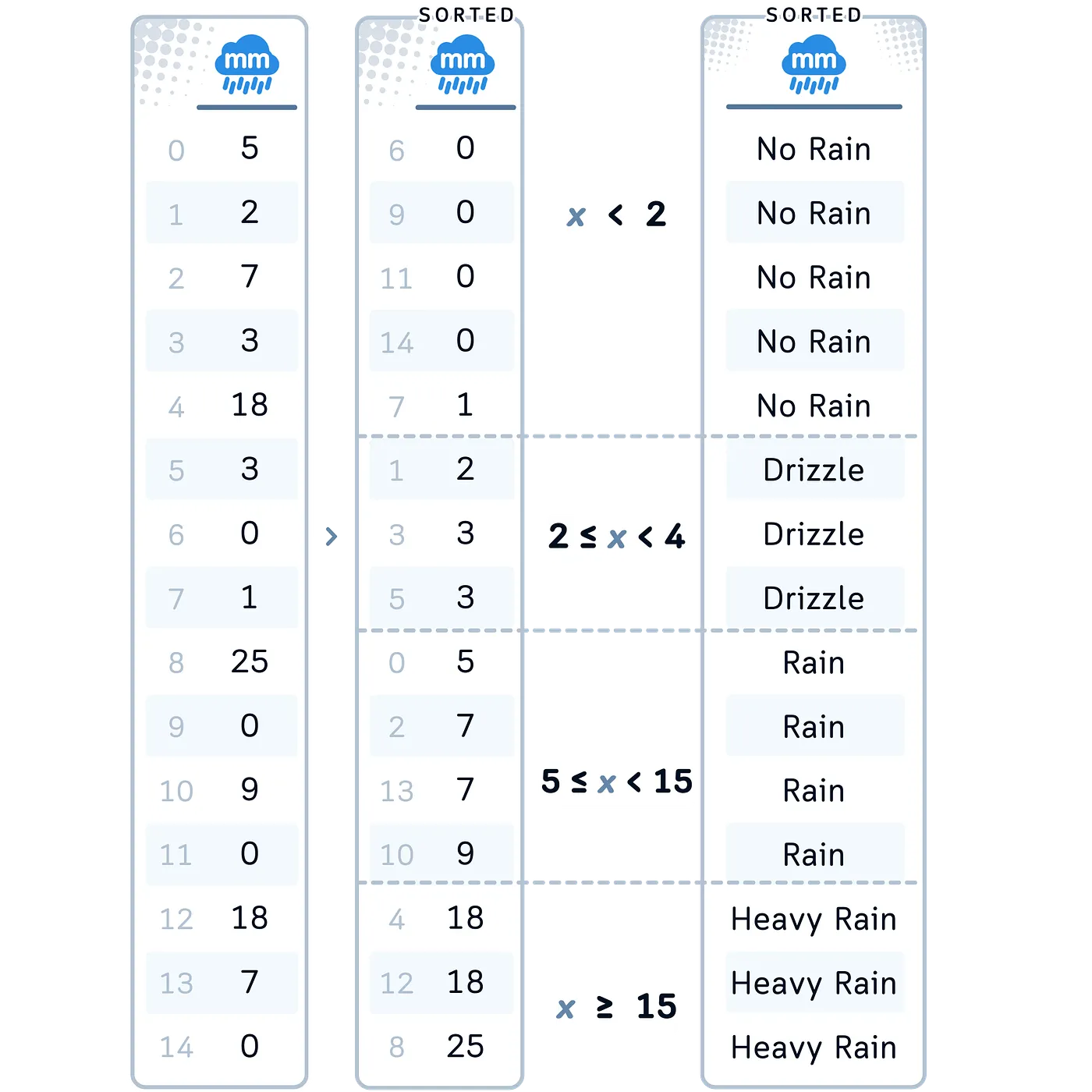
# 3. Customized Binning for RainfallAmount
df['RainfallAmountBinned'] = pd.lower(df['RainfallAmount'], bins=[-np.inf, 2, 4, 12, np.inf],
labels=['No Rain', 'Drizzle', 'Rain', 'Heavy Rain'])
Logarithmic binning creates bins that develop exponentially in dimension. The strategy mainly applies log transformation first then performs equal-width binning.
Frequent Information Sort: This technique is especially helpful for information that spans a number of orders of magnitude or follows an influence legislation distribution.
In our Case: Let’s apply logarithmic binning to our Wind Velocity variable. We selected this technique for Wind Velocity as a result of the impact of wind on a golf ball’s trajectory may not be linear. A change from 0 to five mph is likely to be extra important than a change from 20 to 25 mph.

# 4. Logarithmic Binning for WindSpeed
df['WindSpeedBinned'] = pd.lower(np.log1p(df['WindSpeed']), bins=3,
labels=['Light', 'Moderate', 'Strong'])
Commonplace Deviation based mostly binning creates bins based mostly on the variety of normal deviations away from the imply. This strategy is beneficial when working with usually distributed information or once you wish to bin information based mostly on how far values deviate from the central tendency.
Variations: The precise variety of normal deviations used for binning might be adjusted based mostly on the particular wants of the evaluation. The variety of bins is usually odd (to have a central bin). Some implementations may use unequal bin widths, with narrower bins close to the imply and wider bins within the tails.
Frequent Information Sort: This technique is well-suited for information that follows a standard distribution or once you wish to determine outliers and perceive the unfold of your information. Might not be appropriate for extremely skewed distributions.
In our Case: Let’s apply this binning technique scaling to our Temperature variable. We selected this technique for Temperature as a result of it permits us to categorize temperatures based mostly on how they deviate from the common, which might be notably helpful in understanding climate patterns or local weather tendencies.
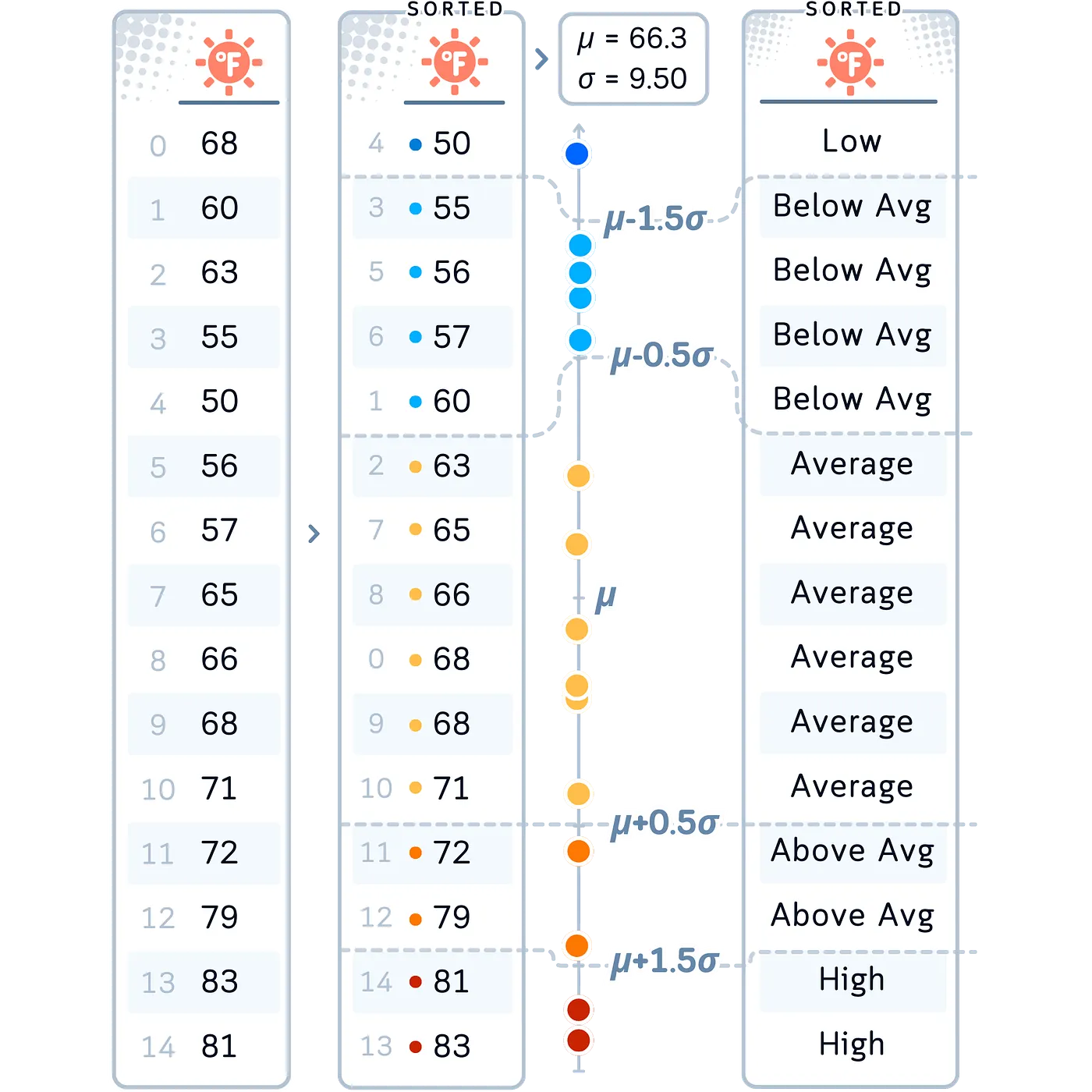
# 5. Commonplace Deviation-Primarily based Binning for Temperature
mean_temp, std_dev = df['Temperature'].imply(), df['Temperature'].std()
bin_edges = [
float('-inf'), # Ensure all values are captured
mean_temp - 2.5 * std_dev,
mean_temp - 1.5 * std_dev,
mean_temp - 0.5 * std_dev,
mean_temp + 0.5 * std_dev,
mean_temp + 1.5 * std_dev,
mean_temp + 2.5 * std_dev,
float('inf') # Ensure all values are captured
]
df['TemperatureBinned'] = pd.lower(df['Temperature'], bins=bin_edges,
labels=['Very Low', 'Low', 'Below Avg', 'Average','Above Avg', 'High', 'Very High'])
Okay-Means binning makes use of the Okay-Means clustering algorithm to create bins. It teams information factors into clusters based mostly on how comparable the info factors are to one another, with every cluster turning into a bin.
Frequent Information Sort: This technique is nice for locating teams in information which may not be apparent at first. It really works nicely with information that has one peak or a number of peaks, and it may well regulate to the way in which the info is organized.
In our Case: Let’s apply Okay-Means binning to our Crowdedness variable. We selected this technique for Crowdedness as a result of it’d reveal pure groupings in how busy the golf course will get, which may very well be influenced by varied elements not captured by easy threshold-based binning.
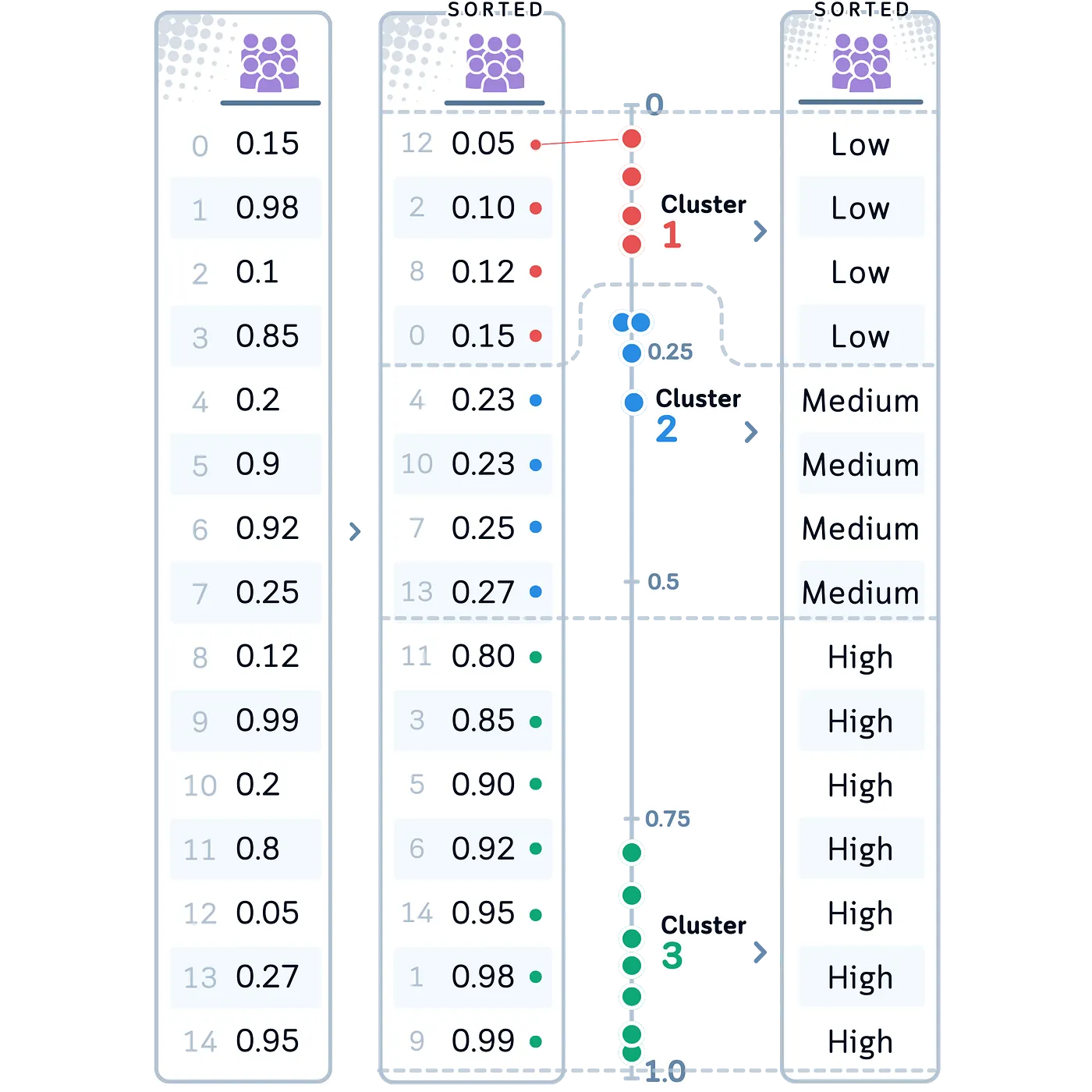
# 6. Okay-Means Binning for Crowdedness
kmeans = KMeans(n_clusters=3, random_state=42).match(df[['Crowdedness']])
df['CrowdednessBinned'] = pd.Categorical.from_codes(kmeans.labels_, classes=['Low', 'Medium', 'High'])
We tried six alternative ways to ‘discretize’ the numbers in our golf information. So, the ultimate dataset now seems to be like this:
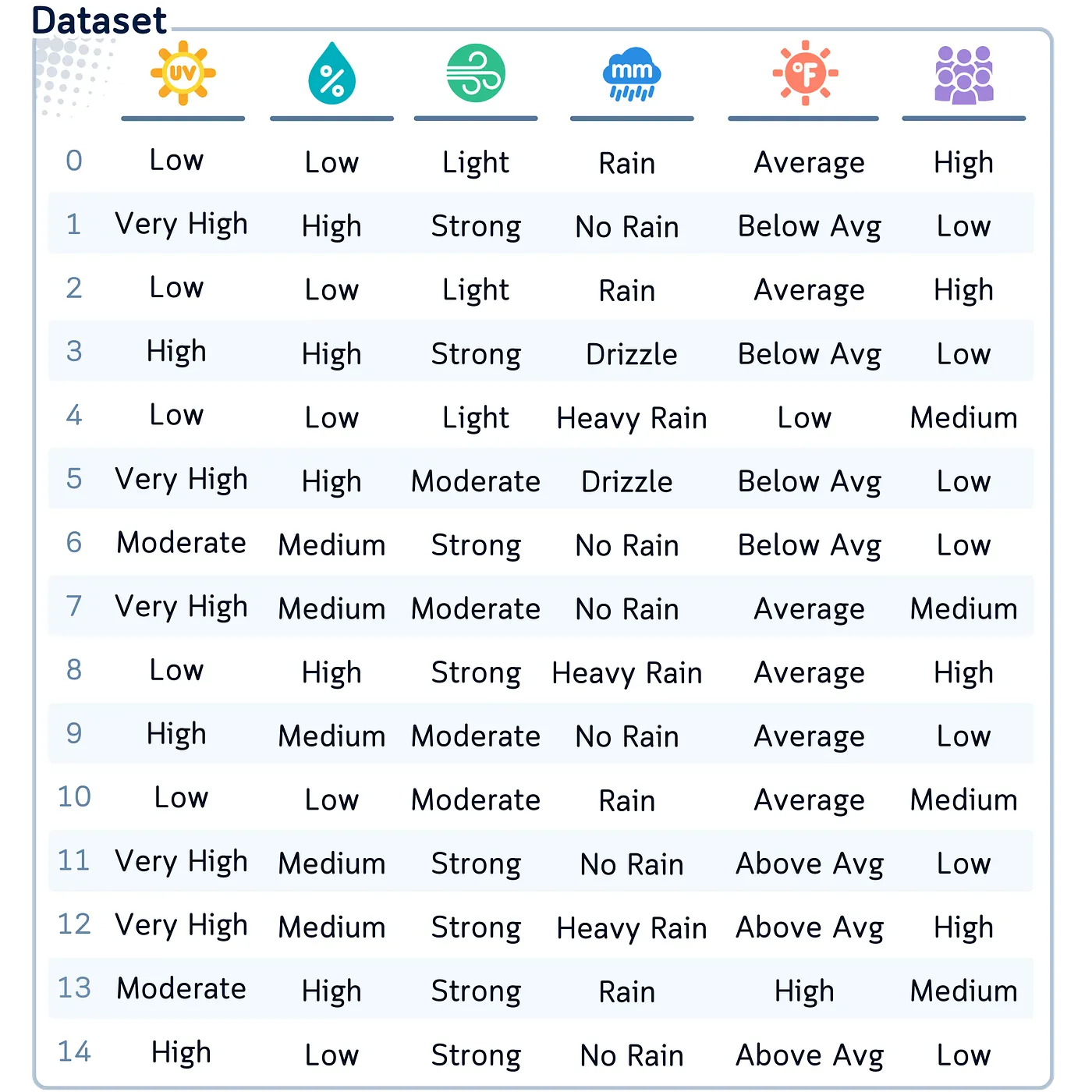
# Print solely the binned columns
binned_columns = [col for col in df.columns if col.endswith('Binned')]
print(df[binned_columns])
Let’s evaluate how every binning method reworked our climate information:
- Equal-Width Binning (UVIndex): Divided our UV Index scale into 4 equal ranges, categorizing publicity ranges from ‘Low’ to ‘Very Excessive’. This provides a simple interpretation of UV depth.
- Equal-Frequency Binning (Humidity): Sorted our Humidity readings into ‘Low’, ‘Medium’, and ‘Excessive’ classes, every containing an equal variety of information factors. This strategy makes positive a balanced illustration throughout humidity ranges.
- Logarithmic Binning (WindSpeed): Utilized to our Wind Velocity information, this technique accounts for the non-linear influence of wind on climate situations, categorizing speeds as ‘Mild’, ‘Average’, or ‘Sturdy’.
- Customized Binning (RainfallAmount): Used area data to categorise rainfall into significant classes from ‘No Rain’ to ‘Heavy Rain’. This technique immediately interprets measurements into sensible climate descriptions.
- Commonplace Deviation-Primarily based Binning (Temperature): Segmented our Temperature information based mostly on its distribution, starting from ‘Very Low’ to ‘Very Excessive’. This strategy highlights how temperatures deviate from the common.
- Okay-Means Binning (Crowdedness): Confirmed pure groupings in our Crowdedness information, doubtlessly exhibiting patterns.
It’s essential to keep away from making use of binning strategies with no thought. The character of every variable and your analytical targets are all the time diverse and it’s good to maintain that in thoughts when deciding on a binning technique. In lots of instances, making an attempt out a number of strategies and evaluating their outcomes can present essentially the most insights into your information!