Federated Studying, first launched by Google in 2016, is a distributed machine studying paradigm that permits Deep Studying fashions to be educated in a decentralized atmosphere on delicate information whereas sustaining privateness.
Deep Studying fashions are data-hungry, which suggests the extra information, the higher the mannequin’s efficiency. Edge units comparable to cell phones, IoT sensors, and cameras maintain enormous quantities of knowledge. This information could be beneficial for coaching Deep Studying (DL) fashions. Utilizing personal information to coach a mannequin can result in privateness breaches. Cell phones retailer delicate info comparable to pictures, and sensors detect and maintain beneficial info concerning the settings during which individuals place them.
About us: viso.ai offers Viso Suite, the world’s solely end-to-end Pc Imaginative and prescient Platform. The know-how permits international organizations to develop, deploy, and scale all laptop imaginative and prescient functions in a single place. Get a demo.
Introduction to Federated Studying
In Pc Imaginative and prescient functions, privateness is extraordinarily essential. For instance, footage taken on cell phones comprise the faces of individuals. If the incorrect individuals get entry to this information, they may compromise the consumer’s id.
One other instance is the information from surveillance functions which can be put in to cater to site visitors violations or detect if somebody isn’t carrying a masks. This will get much more delicate inside the well being division. The X-ray scans and different diagnoses comprise affected person diagnoses and an information breach would violate affected person confidentiality. This can be a risk to the safety and privateness of residents, sufferers, and staff.
That is the place Federated Studying is available in; it permits DL fashions (particularly for Pc Imaginative and prescient) to be educated on the information saved in edge units with out compromising privateness.

The thought behind Federated Studying (FL) is to ship native fashions to consumer’s units, after which practice the native mannequin on the delicate information. As soon as the coaching is completed, it shares the native mannequin’s discovered parameters (comparable to weights, and gradients) with the server in an encrypted atmosphere, and eventually, the worldwide mannequin within the server merges the weights obtained from consumer units into the worldwide mannequin.
On this weblog, we are going to dive deep into Federated Studying, the completely different methods used, and eventually have a look at the challenges that have to be solved.
What’s Federated Studying?
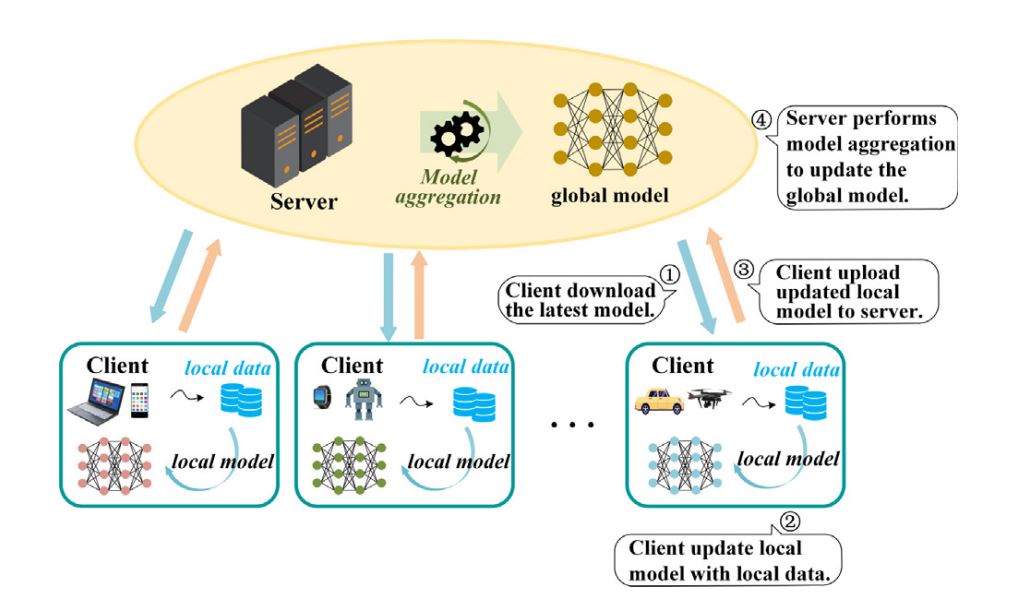
Federated Studying permits a number of decentralized units or servers to collaboratively study a shared mannequin whereas holding the consumer’s information domestically saved on every gadget. As an alternative of sending the consumer’s personal information to a central server for coaching, every gadget trains the mannequin domestically utilizing its dataset after which sends the mannequin updates (gradients, weights, and so on.) to a central server. Lastly, these updates (gradients and weights) are aggregated to a world mannequin. This method is completely different from normal DL coaching.
That is utterly completely different in comparison with an ordinary DL workflow. In normal DL approaches, we ship the information itself to central servers, and the mannequin will get educated on the information. Nonetheless, this method has a number of limitations comparable to communication overhead, and privateness dangers.
Furthermore, information privateness legal guidelines and regulatory our bodies comparable to GDPR (The Normal Information Safety Regulation) of the EU area and HIPPA (Well being Insurance coverage and Portability and Accountability Act) within the US limit centralized storage of delicate information, as there are very excessive possibilities of information theft.
Alternatively, in Federated Studying, particular person units practice the fashions, so the information by no means leaves the consumer’s gadget. Throughout the sharing course of, the system encrypts gradients and weights earlier than transferring them to the worldwide mannequin. Consequently, FL complies with varied regulatory our bodies.
Furthermore, FL has the potential to revolutionize industries comparable to Healthcare and Finance, the place the information may be very delicate and normal DL processes can’t be utilized. Consequently, these industries are lagging within the adoption of DL, as they will’t share the personal info of customers. FL permits these industries to make the most of developments made in AI applied sciences.
Evolution of Federated Studying
The time period “Federated Studying” was first launched by Google of their printed analysis paper in 2016, during which they tried to deal with the restrictions of the usual method of coaching DL fashions. On this paper, they mentioned the heavy utilization of consumer’s community bandwidth and privateness dangers. They launched the concept of sending native ML fashions to the consumer’s units and solely sending the parameters discovered to the servers.
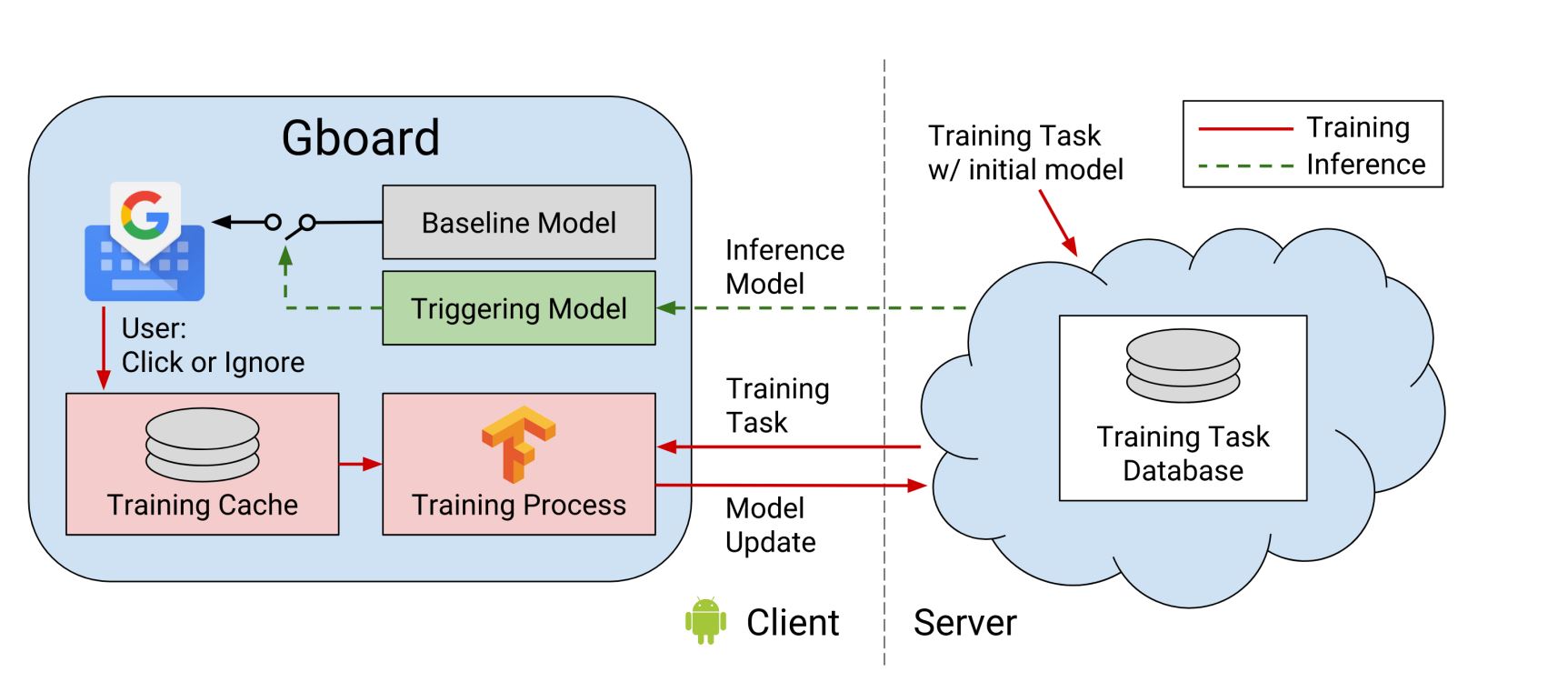
In a while, they carried out FL of their Gboard (Google’s keyboard). Right here they’d solely ship the parameters discovered when the cellphone was linked to Wi-Fi and was charging.
Quick ahead to as we speak, we see varied firms, organizations, and researchers displaying elevated curiosity in FL. They’ve developed a number of Federated Studying frameworks to make integrating and utilizing FL simpler.
How does Federated Studying work?
As we mentioned above, FL’s core precept is that the information by no means leaves the consumer’s gadget, and the system solely sends parameters comparable to gradients and weights.
Here’s what the workflow seems like in FL.
Federated Studying Workflow
- Information Gathering and Preprocessing
- Native information: Edge units retailer personal information that’s specific to their atmosphere.
- Information normalization and augmentation: The native Machine Studying mannequin in edge units normalizes and performs varied information augmentation.
- Mannequin Coaching and Updates
- Native mannequin coaching: Every gadget trains its native mannequin utilizing its information.
- Communication and synchronization: After units full the coaching for desired epochs, they share the mannequin parameters with a central server for aggregation. Researchers use a number of methods, comparable to encryption and different safety measures, to make sure protected sharing, which we are going to focus on shortly.
- Aggregation: Aggregating is among the most vital steps in FL. To merge the weights acquired from particular person units into the worldwide mannequin, researchers use completely different algorithms, FedAvg (weighted averaging based mostly on the dimensions and high quality of the native datasets) being the preferred algorithm.
- Distributing the International Mannequin: After updating and testing the worldwide mannequin for accuracy, researchers ship it again to all contributors for the subsequent spherical of native coaching.
- Mannequin Analysis and Deployment
- International mannequin validation: Earlier than finalizing the worldwide mannequin with the brand new weights, researchers take a number of precautions, because the weights acquired from units can alter the mannequin’s efficiency, presumably making it unusable. To handle this, they carry out validation assessments and cross-validation assessments to make sure the mannequin’s accuracy stays intact.
Federated Studying Averaging Algorithms
FedAvg
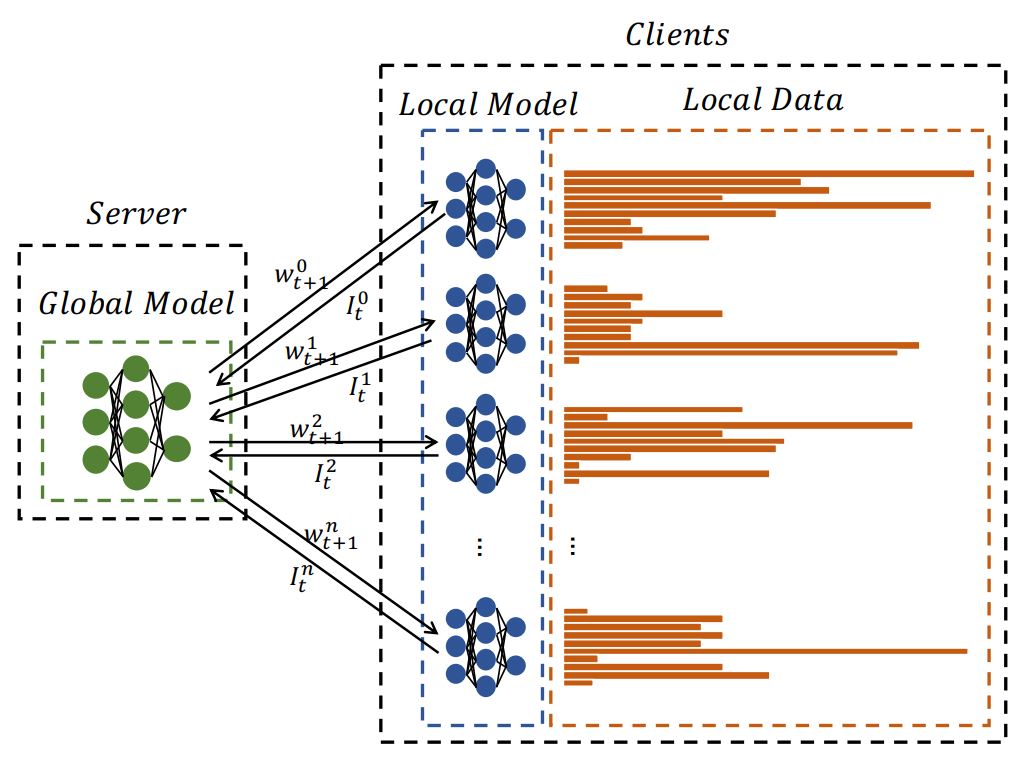
This is among the earliest and mostly used strategies in FL for mannequin aggregation.
On this methodology, the system randomly chooses a bunch of purchasers at every spherical of coaching. Throughout the aggregation course of, it weighs the purchasers’ parameters based mostly on the proportion of every consumer’s information dimension and averages them to supply a world mannequin.

One essential factor to notice right here is that not all purchasers are chosen, they’re randomly chosen. This helps with community overhead and consumer heterogeneity (as some purchasers could have bad-quality datasets or information from very particular environments).
FedProx
Researchers have launched a number of variations of FedAvg, and FedProx is considered one of them. They launched FedProx to deal with the issue of consumer heterogeneity and information distribution when coping with non-IID (non-Identically Independently Distributed information).
FedProx modifies the unique FedAvg by introducing a proximal time period into the consumer’s native mannequin. This time period makes positive that the native mannequin doesn’t drastically deviate from the worldwide mannequin by penalizing the mannequin if it diverges. The equation is as follows:
Lprox(θ)=Lnative(θ)+μ/2∥θ−θt∥2
Right here,
- Lnative(θ) is the native loss operate on the consumer’s information.
- θ is the native mannequin parameter.
- θt is the worldwide mannequin parameters on the present iteration.
- μ is a hyperparameter controlling the power of the proximal time period.
- ∥θ−θt∥2 makes positive that the mannequin doesn’t deviate. If the mannequin does, the time period will increase quadratically, and in consequence, the loss will increase considerably.
Community Constructions in Federated Studying
Main community constructions comparable to centralized and decentralized constructions are utilized in Federated Studying. In a centralized FL system, a server is positioned on the heart, forming a star community construction. A number of purchasers connect with this central server for mannequin aggregation and synchronization.
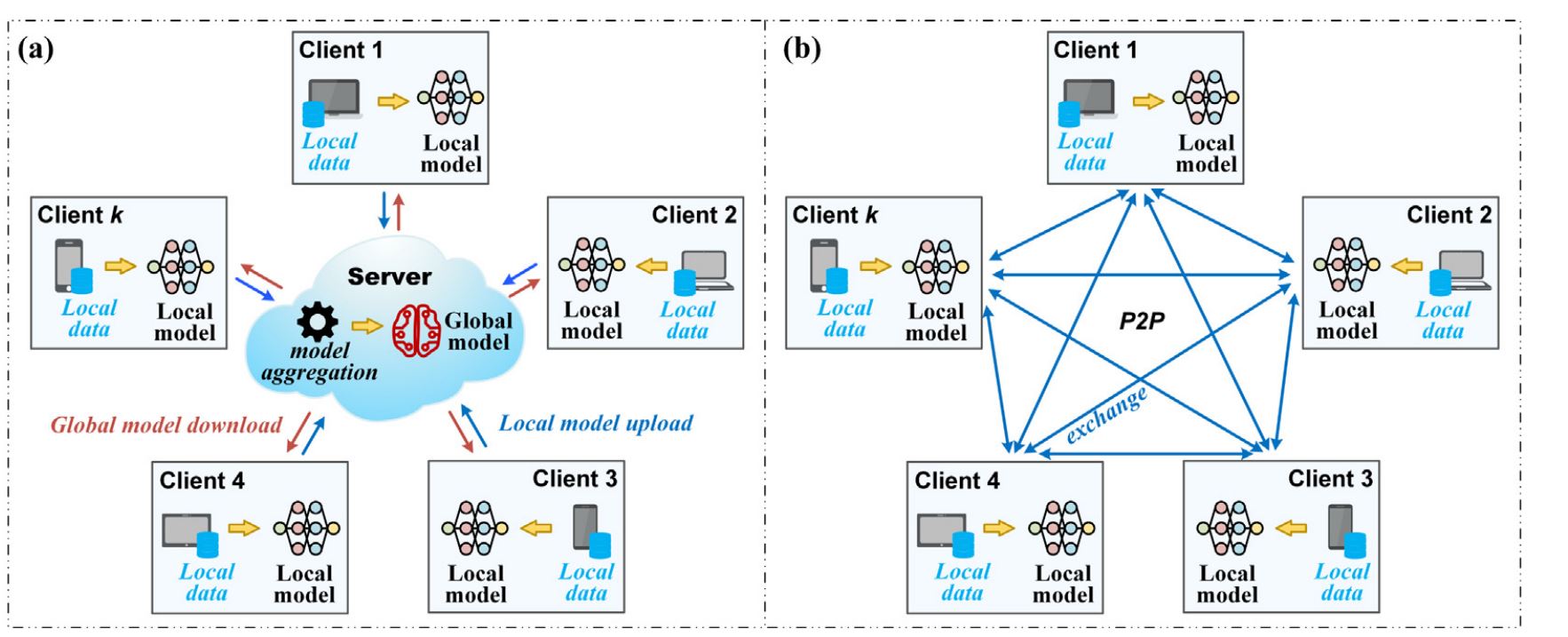
In a decentralized FL system, there is no such thing as a central server. As an alternative, purchasers immediately talk with one another in a peer-to-peer (P2P) community, making a mesh construction. This design helps overcome the presence of untrusted servers and affords benefits comparable to elevated resilience to community failures and communication delays.
Information-based Federated Studying
Federated Studying could be divided into three classes based mostly on characteristic and pattern house distribution.
Function house right here means the attributes or traits (options) which can be used to explain information situations. For instance, every consumer in FL is perhaps utilizing information options like age, revenue, and site. Regardless of variations in particular situations (consumer information), the characteristic house stays constant throughout purchasers.
Whereas, pattern house means, a set of potential information samples. For instance, a consumer has consumer information for customers inside a selected metropolis, whereas one other consumer has consumer information for customers in one other metropolis. Every set of consumer information represents a special pattern house, though the characteristic house (like age, revenue, and site) is identical.
Classes of Federated Studying
Now we have three classes in FL: horizontal FL, vertical FL, and federated switch studying.
- Horizontal Federated Studying: In Horizontal FL, purchasers share the identical characteristic house however have completely different pattern areas. Because of this completely different purchasers pattern information from completely different objects, comparable to A, B, C, and so on., however all the information share the identical traits, comparable to age and revenue. For instance, researchers who performed a examine to detect COVID-19 an infection used chest CT pictures as coaching information for every consumer. They sampled these pictures from individuals of various ages and genders, making certain that each one the information had the identical characteristic house.
- Vertical Federated Studying: In Vertical FL, purchasers pattern information from the identical object (object A) however distribute completely different options (completely different age demographics) amongst themselves. Firms or organizations that don’t compete, comparable to e-commerce platforms and promoting firms with completely different information traits, generally use this method to collaborate and practice a shared studying mannequin.
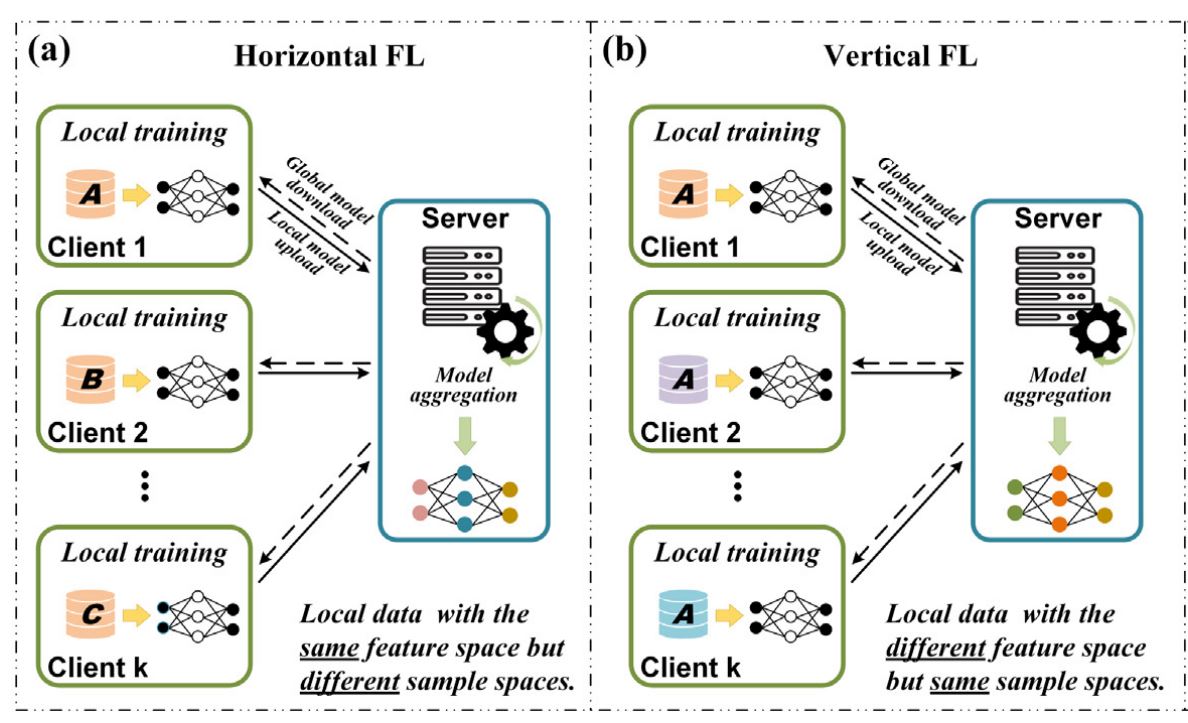
Horizontal and Vertical FL –supply - Federated switch studying: Federated switch studying offers with information that’s from completely different contributors not solely in samples but in addition in characteristic areas. For instance, native information could come from completely different objects (objects A, B, C…) with completely different options (for instance completely different colours). These discovered representations are then utilized to the pattern prediction job with solely one-sided options.
One frequent use case is in FedHealth, a framework for researching wearable healthcare utilizing federated switch studying. The method begins with a cloud server that develops a cloud mannequin utilizing a primary dataset. As soon as the server learns the essential dataset, it makes use of switch studying to coach the mannequin on the native consumer’s dataset.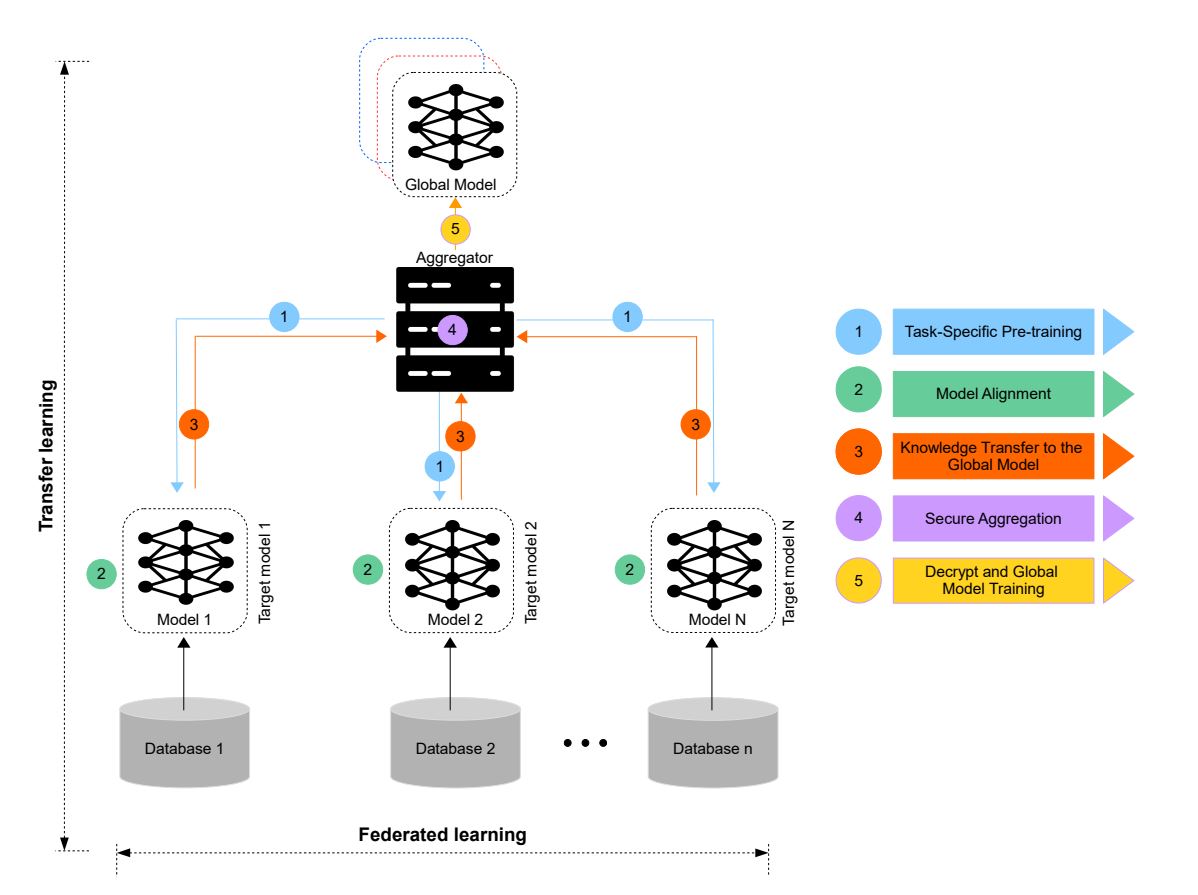
Federated Switch Studying –supply
Challenges of Federated Studying
Compared to normal DL coaching, FL comes up with a set of latest challenges. The purchasers often have completely different {hardware} capabilities, comparable to computation energy, community connectivity, and sensors utilized.
Furthermore, challenges additionally come up in information used, as some purchasers have extra information than others, higher high quality information, or might need skewed datasets. These challenges may even break a mannequin, as an alternative of enhancing it.
Communication Overhead
Communication overhead is a vital side of FL environments, because it entails sharing mannequin parameters from a number of purchasers with servers for a number of rounds.
Though FL is healthier than sending datasets utilized in normal DL, community bandwidth and computation energy could be limiting. Some IoT units could also be positioned in distant areas with restricted web connectivity. Moreover, the elevated participation of consumer units additional introduces delays when synchronizing.
Researchers have proposed varied methods to beat communication overhead. One method compresses the information being transferred. One other technique is figuring out and excluding irrelevant fashions from aggregation, as this could decrease communication prices.
Heterogeneity of consumer information
This is among the main challenges FL faces, as it will possibly hinder convergence charges. To beat this situation, researchers make the most of a number of methods. For instance, they will use FedCor, an FL framework that employs a correlation-based consumer choice technique to enhance the convergence charge of FL.
This framework works by correlating loss and completely different purchasers utilizing a Gaussian course of (GP). This course of is used to pick out purchasers in a means that considerably reduces the anticipated international loss in every spherical. The experiments performed on this technique confirmed that FedCor can enhance convergence charges by 34% to 99% on FMNIST and 26% to 51% on CIFAR-10.
One other technique to beat the difficulty of gradual nodes and irregular community connectivity is to make use of a reinforcement learning-based central server, which steadily weights the purchasers based mostly on the standard of their fashions and their responses. That is then used to group purchasers that obtain optimum efficiency.
Privateness and assaults
Though FL is designed to maintain information privateness in thoughts, there are nonetheless situations the place an FL system may end up in privateness breaches. Malicious actors can reverse-engineer the gradients and weights shared with the server to entry actual personal info. Furthermore, the FL system can be susceptible to adversary assaults, the place a malicious consumer might have an effect on the worldwide mannequin by sending poisoned native information that might cease the mannequin from converging and making it unusable.
Researchers can defend in opposition to poisoning assaults by detecting malicious customers by means of anomaly detection of their native fashions. They analyze whether or not the characteristic distribution of malicious customers differs from the remainder of the customers within the community.
To handle the privateness dangers, researchers have proposed a blockchain-based FL system, formally often known as FLchain.
- FLchain: On this, the cellular units ship their mannequin parameters to servers as transactions, and the server shops the native mannequin parameters on the blockchain, after validating them with different nodes. Lastly, the aggregation node verifies the domestically saved mannequin from the blockchain and aggregates them.
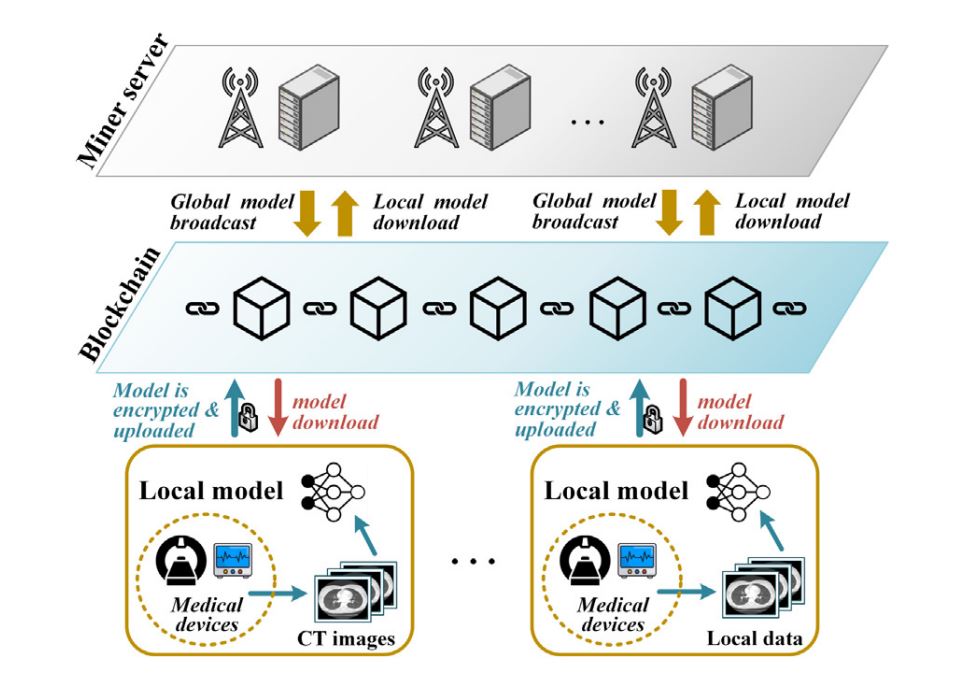
Blockchain-based Federated Studying – supply
One other methodology to cut back the chance of privateness is differential privateness. On this, every consumer provides noise to its domestically educated parameters earlier than importing it to the server. The noise added doesn’t alter the efficiency of the mannequin considerably, and on the similar time makes it troublesome to research the distinction between educated parameters.
Researchers and builders extensively use cryptographic methods comparable to homomorphic encryption and secret sharing to protect privateness. For instance, they encrypt mannequin updates earlier than sharing them with the server for aggregation utilizing a public key that solely the nodes or a number of members of the community can entry. Devoted members should collaborate to decrypt the data.
Implementing Federated Studying
On this part, we are going to undergo the code for implementing FL in TensorFlow. To get began, you want first to get the TensorFlow library for Federated Studying.
pip set up tensorflow-federated
After getting gotten the dependencies, we have to initialize the mode. The next code will create a sequential mannequin with a dense neural community.
import tensorflow as tf
def create_keras_model():
mannequin = tf.keras.fashions.Sequential([
tf.keras.layers.Input(shape=(784,)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
return mannequin
Now, we have to present information for the mannequin. For this tutorial, we are going to use synthetically created information, however you’ll be able to strive along with your dataset, or import the MINST handwriting dataset from TensorFlow.
import numpy as np
def create_federated_data(num_clients=10, num_samples=100):
federated_data = []
for _ in vary(num_clients):
x = np.random.rand(num_samples, 784).astype(np.float32)
y = np.random.randint(0, 10, dimension=(num_samples,)).astype(np.int32)
dataset = tf.information.Dataset.from_tensor_slices((x, y))
dataset = dataset.batch(10)
federated_data.append(dataset)
return federated_data
The next line of code will convert the Keras mannequin you created earlier to a TensorFlow Federated mannequin.
import tensorflow_federated as tff
def create_tff_model():
def model_fn():
keras_model = create_keras_model() #initialize keras mannequin first
return tff.studying.fashions.from_keras_model(
keras_model,
input_spec=(
tf.TensorSpec(form=[None, 784], dtype=tf.float32), # The enter options are anticipated to be tensors
tf.TensorSpec(form=[None], dtype=tf.int32)
),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
return model_fn
The next code creates the Fedavg operate that we mentioned above within the weblog. Server and consumer studying charges are additionally outlined right here.
def federated_averaging_process():
return tff.studying.algorithms.build_weighted_fed_avg(
model_fn=create_tff_model(),
client_optimizer_fn=lambda: tf.keras.optimizers.Adam(learning_rate=0.01),
server_optimizer_fn=lambda: tf.keras.optimizers.Adam(learning_rate=1.0)
)
Right here, we outline the primary operate that runs the mannequin, by creating and invoking the features we outlined above. Furthermore, as you’ll be able to see we’ve got initialized a loop, that runs the FL course of 10 instances.
def foremost():
federated_data = create_federated_data()
federated_averaging = federated_averaging_process()
state = federated_averaging.initialize()
for round_num in vary(1, 11): # Variety of rounds
state, metrics = federated_averaging.subsequent(state, federated_data)
print(f'Spherical {round_num}, Metrics: {metrics}')
if __name__ == '__main__':
foremost()
What’s subsequent for Federated Studying?
On this weblog, we seemed in-depth at coaching machine studying fashions utilizing Federated Studying (FL). We understood that the FL coaching course of works by sending mannequin parameters (mannequin weight and gradient) obtained by coaching the native mannequin on the consumer’s uncooked information after which sending these parameters to the central mannequin saved within the server. We then checked out how FL makes mannequin coaching safe and makes privateness a precedence. And the several types of FL techniques that exist. We additionally checked out completely different aggregating algorithms which can be utilized in FL.
Lastly, we checked out a few of the limitations that exist inside the Federated Studying mannequin, and the way these could be solved. After which went by means of a code implementation on the MINST handwriting dataset.
In conclusion, FL offers a chance for varied fields which have been skeptical about adopting DL as a result of nature of their information, and considerations concerning privateness of the information. FL is an ongoing course of and several other ongoing analysis is going down to make the system higher. Nonetheless, we are able to see that FL holds a vibrant future up forward at making the lives of individuals higher with Synthetic Intelligence.
Ceaselessly Requested Questions (FAQS)
Q1. How safe is federated studying in opposition to cyber assaults?
A. The target of Federated Studying is to make sure the privateness and safety of customers’ information, nonetheless, it isn’t completely proof against cyber assaults. A number of analysis papers have been printed, discussing the opportunity of cyber-attacks on FL. A few of these assaults embrace:
- Adversary Assault: That is the place the malicious individual tries to deduce the consumer’s info from the gradient or mannequin weight replace.
- Mannequin Poisoning: The attacker can ship corrupt mannequin weight to the worldwide mannequin, this may significantly lower the worldwide mannequin’s efficiency.
FL comes with varied precautionary steps to keep away from these assaults. Strategies comparable to safe multi-party-computation, holomorphic encryption, differential privateness, and strong weight aggregation strategies are used.
Q2. How does federated studying differ from conventional machine studying?
A. Federated studying differs from normal ML based mostly on:
Information Distribution: ML makes use of a central database that shops the information, and the information is fed to ML for coaching. In distinction, FL makes use of distributed coaching, the place the information is saved in a number of units, the place a neighborhood ML calculates mannequin parameters and sends them to a world mannequin for aggregation.
Q3. Can federated studying be used with real-time information?
A. Sure, FL can be utilized with real-time information. Furthermore, FL is continuously utilized in situations the place real-time information switch is required. Gadgets comparable to sensors, cameras, and IoT integrated with FL can compute gradients and loss periodically on the newly generated information and ship updates to the worldwide mannequin.
This fall. What are some well-liked frameworks and instruments for federated studying?
A. There exist a number of frameworks that make it simple to arrange and run FL.
- TensorFlow Federated (TFF): An open-source framework by Google designed for machine studying and different computations on decentralized information.
- PySyft: This can be a Python library for safe and personal machine studying. It options FL, Differential Privateness, and Encrypted computations.
- Federated AI Know-how Enabler (FATE): That is an Industrial Grade Federated Studying Framework, constructed by Webank. It helps federated studying architectures and safe computation for any machine studying algorithm.
The submit Federated Studying: Balancing Information Privateness & AI Efficiency appeared first on viso.ai.