DataFrames are one of the crucial common knowledge buildings for dealing with and analyzing tabular knowledge in knowledge science and analytics. Python libraries like pandas present sturdy instruments for working with DataFrames, permitting knowledge manipulation, transformation, and visualization. As soon as the evaluation is full, it’s typically essential to export DataFrames to a CSV (Comma-Separated Values) file for sharing, additional evaluation, or archiving.
The CSV format is extensively used due to its simplicity and compatibility with varied instruments, together with Excel, databases, and different programming environments. In Jupyter Pocket book, the method of exporting DataFrames to CSV is seamless and extremely customizable. The DataFrame.to_csv() technique in Pandas permits customers to export knowledge with choices to incorporate/exclude headers, customise delimiters, deal with lacking values, and extra.

Desk of contents
- Find out how to Save DataFrame to CSV?
- Parameters of to_csv() Perform
- sep (str, default ‘,’)
- na_rep (str, default ”)
- columns (record of str, elective)
- header (bool or record of str, default True)
- index (bool, default True)
- index_label (str or sequence, elective)
- mode (str, default ‘w’)
- encoding (str, elective)
- date_format (str, elective)
- compression (str or dict, elective)
- chunksize (int, elective)
- Conclusion
- Steadily Requested Questions
Find out how to Save DataFrame to CSV?
Step 1: Import pandas and Create a Dataframe
You’ll be able to both create a dataframe manually, import it from an exterior supply (e.g., a CSV or Excel file) or use an inbuilt dataset from sklearn library. Right here’s an instance of making one manually:
1st Methodology: Create a DataFrame Manually
import pandas as pd
# Making a dataframe manually
knowledge = {
"Identify": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"Metropolis": ["New York", "Los Angeles", "Chicago"]
}
df_manual = pd.DataFrame(knowledge)
print(df_manual)2nd Methodology: Import DataFrame from an Exterior Supply
# Importing a CSV file
df_csv = pd.read_csv("pattern.csv")
print("nDataFrame imported from CSV:")
print(df_csv)third Methodology: Use an Inbuilt Dataset from sklearn
from sklearn.datasets import load_iris
import pandas as pd
# Load the Iris dataset
iris = load_iris()
# Create a dataframe from the dataset
df_sklearn = pd.DataFrame(knowledge=iris.knowledge, columns=iris.feature_names)
# Add the goal column
df_sklearn['target'] = iris.goal
print("nDataFrame created from sklearn's Iris dataset:")
print(df_sklearn.head())Step 2: Export the dataframe to a CSV file
When exporting a DataFrame to a CSV file in Pandas, you may specify the file path within the to_csv() technique. This path determines the listing the place the file will probably be saved. Under are a number of situations explaining methods to save the file in numerous directories:
1. Save within the Present Working Listing
To verify the present working listing, use:
import os
print(os.getcwd()) # Prints the present working listing
Output:

By default, if you happen to present simply the file identify (e.g., output.csv), the file will probably be saved within the present working listing the place you might be utilizing your jupyter pocket book or python file to export the dataframe
import pandas as pd
# Create a pattern DataFrame
knowledge = {"Identify": ["Alice", "Bob"], "Age": [25, 30]}
df = pd.DataFrame(knowledge)
# Save within the present working listing
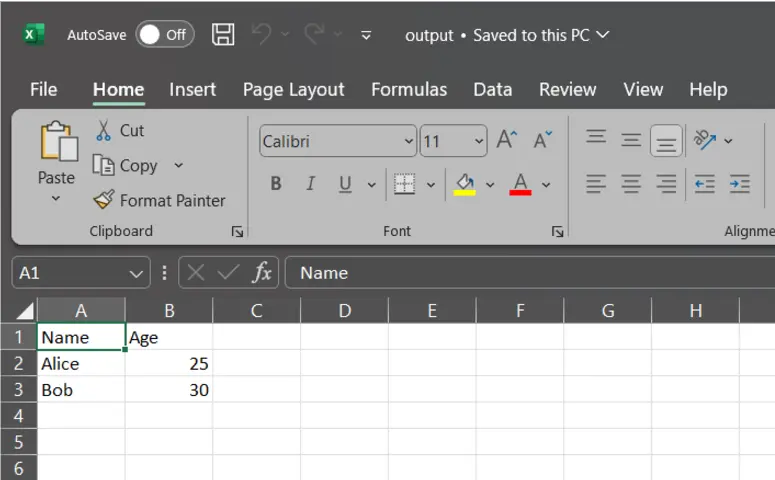
df.to_csv("output.csv", index=False)
As you may see the output.csv is exported in the identical listing the place our jupyter pocket book is saved
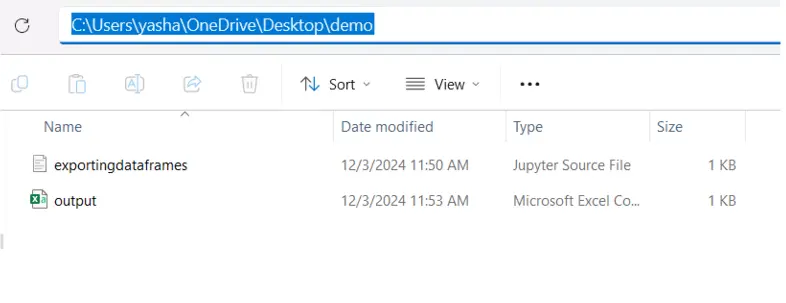
2. Save in a Subdirectory
If you wish to save the file in a subdirectory of the present listing, embrace the subdirectory within the file path. Make sure the subdirectory exists, or you’re going to get a FileNotFoundError.
If the listing doesn’t exist, create it:
import os
if not os.path.exists("knowledge"):
os.makedirs("knowledge")
df.to_csv("knowledge/output.csv", index=False)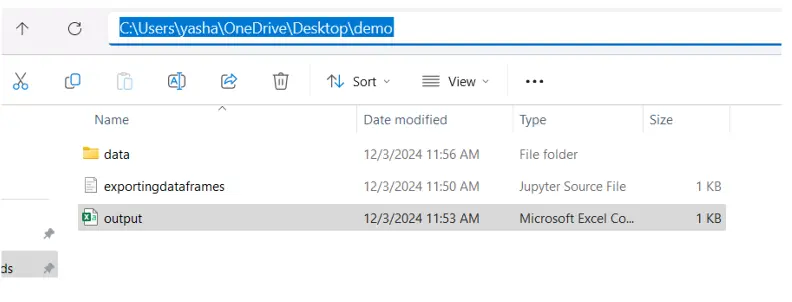
# Save to a subdirectory (e.g., "knowledge" folder)
df.to_csv("knowledge/output.csv", index=False)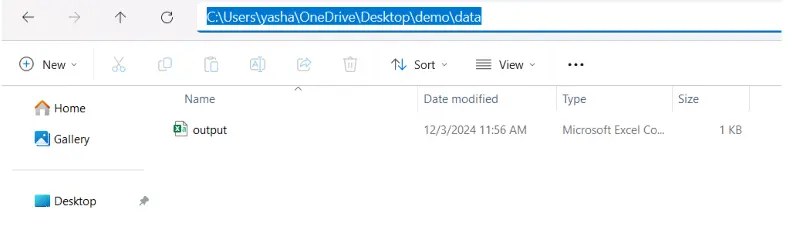
3. Save in an Absolute Path
To save lots of the file in an absolute listing (e.g., C:UsersYourNameDocuments or /residence/consumer/paperwork), present the total path.
# Save to an absolute path on Home windows
df.to_csv(r"C:UsersyashaVideosdemo2output.csv", index=False) # Use uncooked string (r"") to keep away from escaping backslashes
Parameters of to_csv() Perform
Listed below are the parameters of to_csv() operate:
1. sep (str, default ‘,’)
Specifies the delimiter to make use of within the CSV file.
df.to_csv("output.csv", sep=";") # Use semicolon as a delimiter
2. na_rep (str, default ”)
Specifies how lacking values (NaN) are represented within the output.
import pandas as pd
# Create a pattern DataFrame
knowledge = {"Identify": ["Alice", "Bob",None], "Age": [25, 30,None]}
df = pd.DataFrame(knowledge)
df.to_csv("output.csv", na_rep="N/A") # Change NaN with "N/A"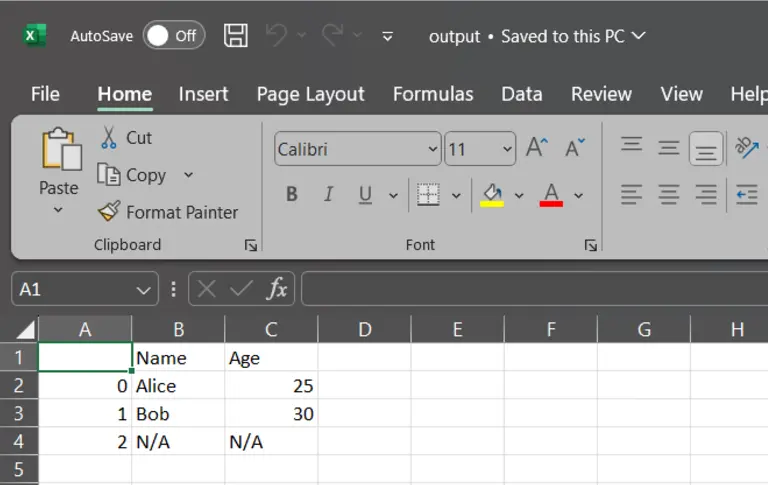
3. columns (record of str, elective)
Selects particular columns to jot down to the CSV.
import pandas as pd
# Create a pattern DataFrame
knowledge = {"Identify": ["Alice", "Bob",None], "Age": [25, 30,None]}
df = pd.DataFrame(knowledge)
df.to_csv("output.csv", columns=["Name"]) # Export solely "Identify" column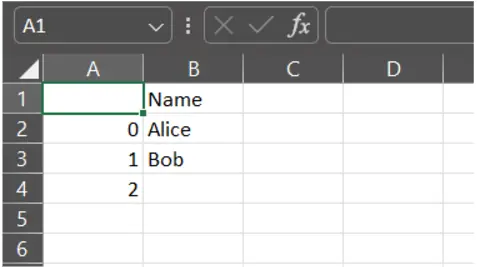
Controls whether or not to jot down column names within the CSV. You can even move a customized record of header names.
import pandas as pd
# Create a pattern DataFrame
knowledge = {"Identify": ["Alice", "Bob",None], "Age": [25, 30,None]}
df = pd.DataFrame(knowledge)
df.to_csv("output.csv", header=False) # Don't write column names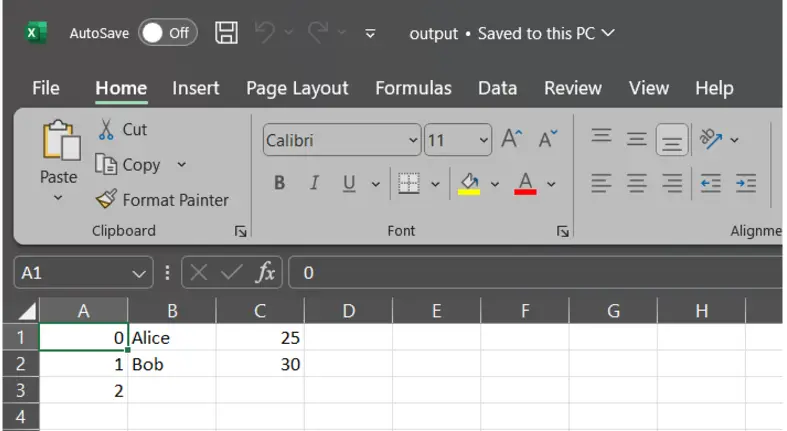
Right here, the column names “Identify” and “Age” should not seen within the sheet
import pandas as pd
# Create a pattern DataFrame
knowledge = {"Identify": ["Alice", "Bob",None], "Age": [25, 30,None]}
df = pd.DataFrame(knowledge)
df.to_csv("output.csv", header=["Col1", "Col2"]) # Use customized column names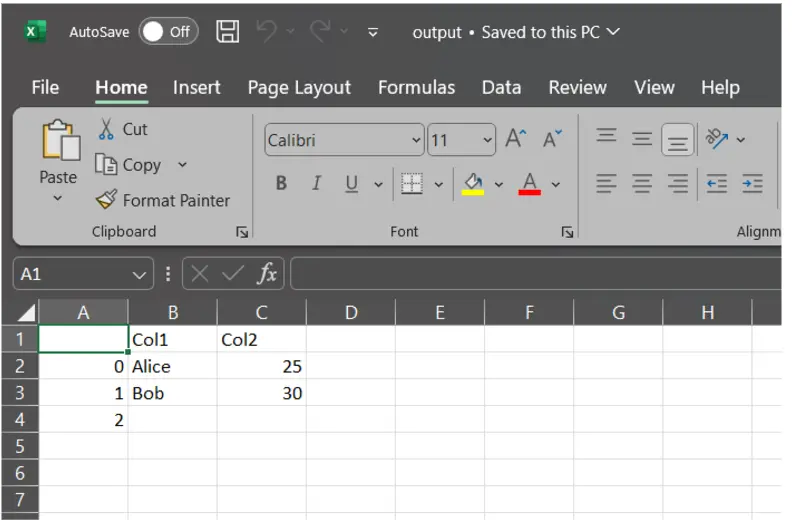
As you may see the identify of the columns have now been modified, as a substitute of “Identify” and “Age” its “Col1” and “Col2” now
5. index (bool, default True)
Controls whether or not to jot down the row index to the CSV.
import pandas as pd
# Create a pattern DataFrame
knowledge = {"Identify": ["Alice", "Bob",None], "Age": [25, 30,None]}
df = pd.DataFrame(knowledge)
df.to_csv("output.csv", index=False) # Don't embrace row indices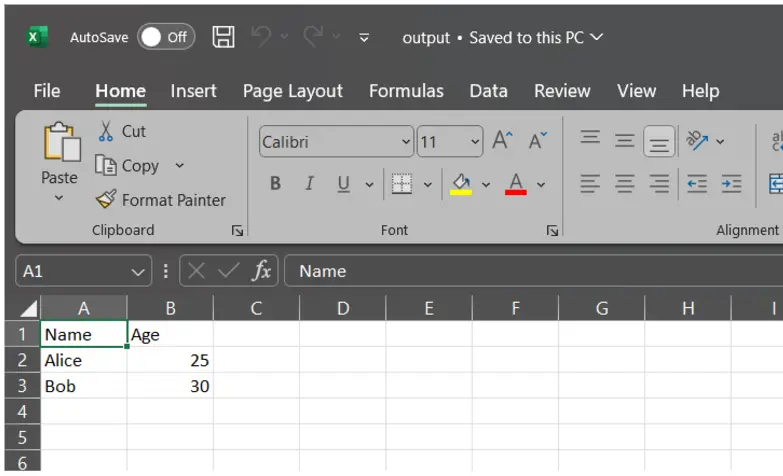
import pandas as pd
# Create a pattern DataFrame
knowledge = {"Identify": ["Alice", "Bob",None], "Age": [25, 30,None]}
df = pd.DataFrame(knowledge)
df.to_csv("output.csv", index=True) # Don't embrace row indices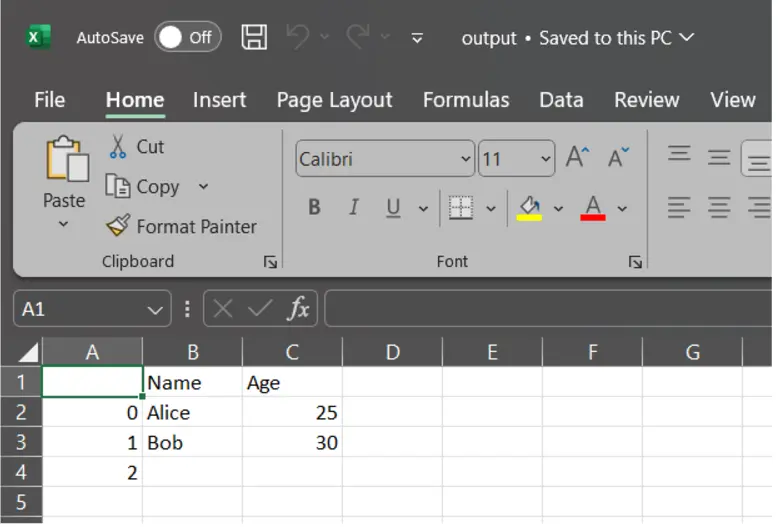
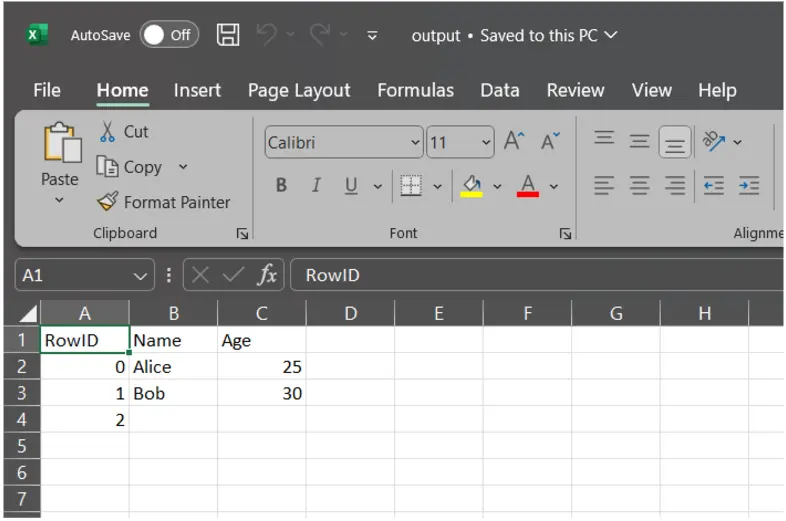
6. index_label (str or sequence, elective)
Specifies a customized label for the index column(s) if index=True.
import pandas as pd
# Create a pattern DataFrame
knowledge = {"Identify": ["Alice", "Bob",None], "Age": [25, 30,None]}
df = pd.DataFrame(knowledge)
df.to_csv("output.csv", index=True, index_label="RowID") # Label index column as "RowID"
7. mode (str, default ‘w’)
File mode to open the file. ‘w’ for write (overwrite), ‘a’ for append.
Unique Knowledge in output.csv
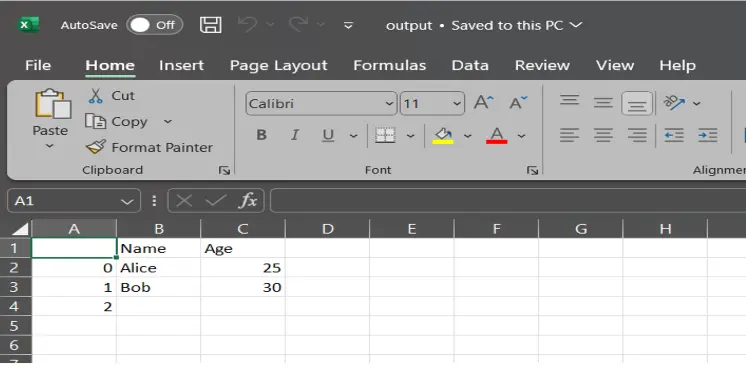
data1 = {"Identify": ["Aaron", "Bella"], "Age": [30, 35]}
df1= pd.DataFrame(data1)
df.to_csv("output.csv",mode="a") # Append to the file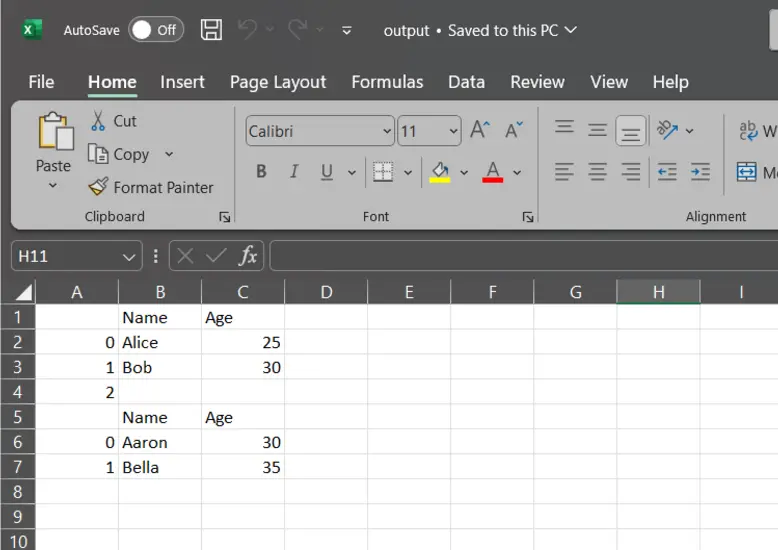
8. encoding (str, elective)
Specifies the encoding for the CSV file (e.g., utf-8, latin1).
df.to_csv("output.csv", encoding="utf-8") # Save with UTF-8 encoding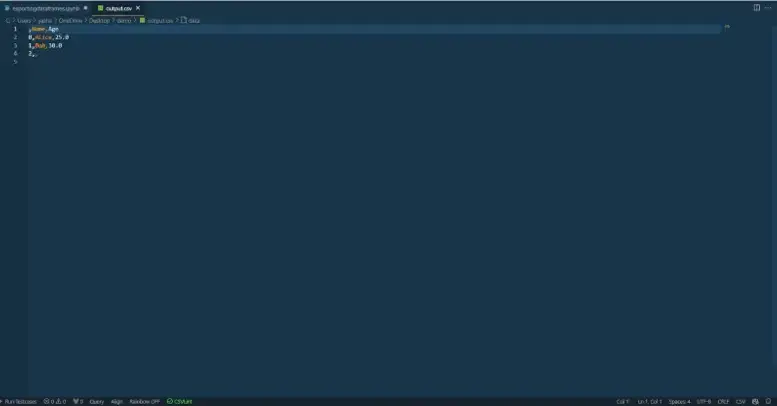
After opening the output.csv file in vs code on proper backside facet there’s a standing bar the place you may see that the encoding is utf-8

9. date_format (str, elective)
Specifies a customized date format for datetime objects.
import pandas as pd
# Pattern knowledge with date columns
knowledge = {
"Identify": ["Alice", "Bob", "Charlie"],
"Becoming a member of Date": ["2024-12-01", "2023-11-25", "2022-10-15"],
"Final Login": ["2024-12-03 14:23:00", "2023-11-30 09:15:00", "2022-10-20 18:45:00"],
}
# Create a DataFrame
df = pd.DataFrame(knowledge)
# Convert columns to datetime
df["Joining Date"] = pd.to_datetime(df["Joining Date"])
df["Last Login"] = pd.to_datetime(df["Last Login"])
# Save DataFrame to CSV with date formatting for date columns
df.to_csv("output.csv", date_format="%Y-%m-%d", index=False)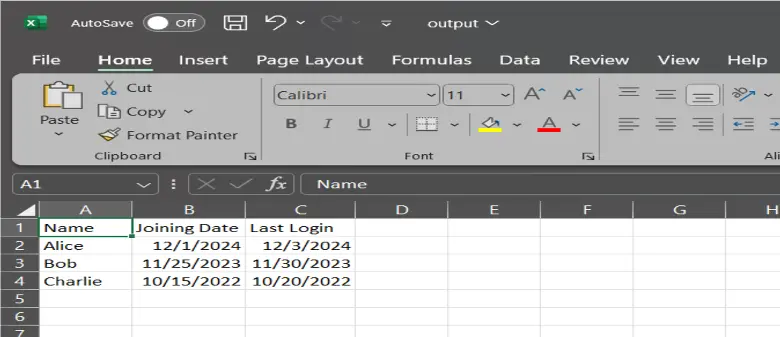
df.to_csv("output.csv", date_format="%m-%Y-%d", index=False)
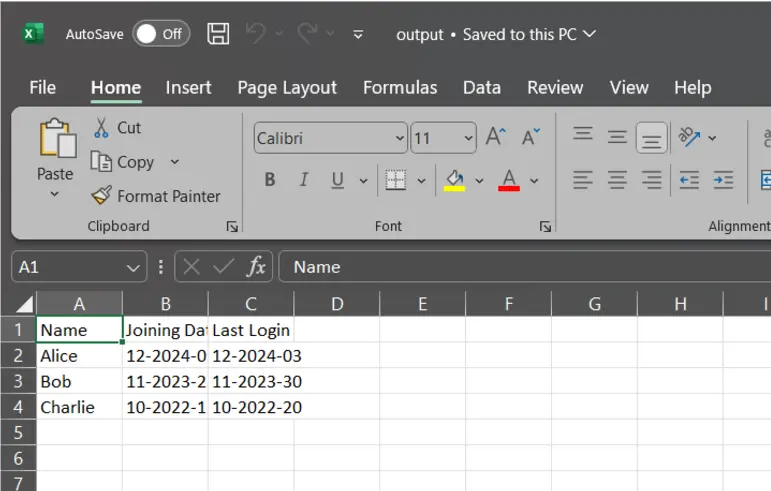
10. compression (str or dict, elective)
Specifies the compression mode for the output file (e.g., ‘gzip’, ‘bz2’, ‘zip’, ‘xz’).
df.to_csv("output.csv.gz", compression="gzip") # Save as a gzip-compressed file
11. chunksize (int, elective)
Writes the file in chunks of specified dimension, helpful for giant datasets.
df=pd.read_csv("knowledge.csv")
print(df.form)
df.to_csv("output.csv", chunksize=1000) # Write 1000 rows at a time
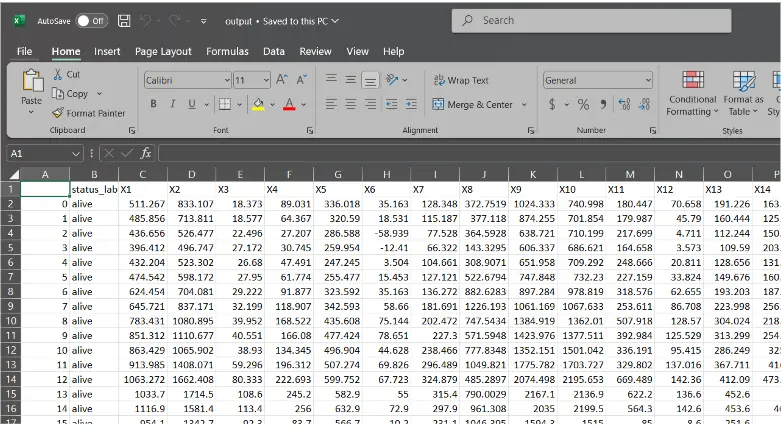
Conclusion
Exporting DataFrames to CSV information in Jupyter Pocket book is an easy but highly effective technique to save your processed knowledge for additional use, additionally, by leveraging the pandas.DataFrame.to_csv() technique, customers can seamlessly export their knowledge with a excessive diploma of customization. This technique means that you can save DataFrames in varied directories, whether or not it’s the present working listing, subdirectories, and even absolute paths. This flexibility ensures that your knowledge may be organized and saved precisely the place it’s wanted.
The to_csv() operate supplies in depth choices to tailor the CSV output to particular necessities. For instance, you may customise the file’s delimiter, deal with lacking values, embrace or exclude headers, specify index behaviour, and management encoding codecs. These options will let you create CSV information which might be optimized for compatibility with completely different software program, instruments, and workflows.
Moreover, the operate helps superior use circumstances, comparable to compressing information for environment friendly storage or exporting massive datasets in manageable chunks utilizing the chunksize parameter. These capabilities make it simpler to work with massive or complicated knowledge buildings whereas sustaining efficiency and reliability.
Lastly, the CSV format is a universally accepted commonplace for knowledge change, making certain interoperability with instruments like Excel, databases, and different programming environments. By mastering the to_csv() operate, you may successfully save, share, and archive your knowledge, streamlining your workflow and enabling higher collaboration in data-driven tasks.
Steadily Requested Questions
Ans. CSV (Comma-Separated Values) information are easy, universally appropriate, and simple to handle. They’re plain textual content information the place data are separated by commas, making them human-readable and editable with primary instruments like textual content editors or spreadsheets. CSV information are extensively supported throughout methods, programming languages, and knowledge instruments, making them splendid for knowledge change. They’re compact, with out additional metadata, which helps hold file sizes small, particularly for giant datasets. Moreover, most programming languages supply built-in help for studying and writing CSV information, making them versatile for varied knowledge processing duties.
Ans. The to_csv technique in Python, used with pandas DataFrames, permits straightforward export of tabular knowledge to CSV format, making certain cross-language and system compatibility. It presents flexibility, letting customers customise delimiters, embrace headers or indices, specify encodings, and append knowledge. Its effectivity with massive datasets makes it splendid for each easy and sophisticated knowledge storage wants.
Ans. You’ll be able to export pandas DataFrames to CSV utilizing strategies past to_csv. For numerical knowledge, use NumPy’s savetxt, the place you may manually format the information and add headers. Alternatively, the built-in csv module helps you to write DataFrame rows to a file with a csv.author. You can even use open() and handbook file I/O for full management over formatting. These choices supply flexibility when to_csv doesn’t meet your wants.
Hi there, my identify is Yashashwy Alok, and I’m enthusiastic about knowledge science and analytics. I thrive on fixing complicated issues, uncovering significant insights from knowledge, and leveraging expertise to make knowledgeable selections. Through the years, I’ve developed experience in programming, statistical evaluation, and machine studying, with hands-on expertise in instruments and methods that assist translate knowledge into actionable outcomes.
I’m pushed by a curiosity to discover revolutionary approaches and constantly improve my ability set to remain forward within the ever-evolving area of information science. Whether or not it’s crafting environment friendly knowledge pipelines, creating insightful visualizations, or making use of superior algorithms, I’m dedicated to delivering impactful options that drive success.
In my skilled journey, I’ve had the chance to realize sensible publicity by way of internships and collaborations, which have formed my skill to sort out real-world challenges. I’m additionally an enthusiastic learner, all the time searching for to increase my information by way of certifications, analysis, and hands-on experimentation.
Past my technical pursuits, I take pleasure in connecting with like-minded people, exchanging concepts, and contributing to tasks that create significant change. I sit up for additional honing my abilities, taking over difficult alternatives, and making a distinction on the planet of information science.