Thus far, varied fashions have served distinct functions in synthetic intelligence. These fashions have considerably impacted human life, from understanding and producing textual content primarily based on enter to considerably striding in pure language processing. Nonetheless, whereas these fashions set benchmarks for linguistic duties, they fall quick in relation to including real-world motion and interactions. This undermines the need of an autonomous system that takes motion primarily based on the data it processes. That is the place AI brokers come into the image. Brokers are programs that may motive and act dynamically, permitting them to work with out human intervention.
When paired with highly effective language fashions, AI brokers can unlock a brand new frontier of clever decision-making and action-taking. Historically, fashions like Lengthy Context LLMs and Retrieval-Augmented Technology (RAG) have sought to beat reminiscence and context limitations by extending the enter size or combining exterior information retrieval with technology. Whereas these approaches improve the mannequin’s capacity to course of giant datasets or complicated directions, they nonetheless rely closely on static environments. RAG excels at augmenting the mannequin’s understanding with exterior databases, and Lengthy Context LLMs deal with in depth conversations or paperwork by sustaining related context. Nonetheless, each lack the capability for autonomous, goal-driven behaviour. That is the place Agentic RAG involves the rescue. Additional on this article, we are going to speak in regards to the evolution of Agentic RAG.

Overview
- AI Mannequin Evolution: Progressed from conventional LLMs to RAG and Agentic RAG, enhancing capabilities.
- LLM Limitations: Conventional LLMs deal with textual content effectively however can’t carry out autonomous actions.
- RAG Enhancement: RAG boosts LLMs by integrating exterior information for extra correct responses.
- Agentic RAG Development: Provides autonomous decision-making, enabling dynamic process execution.
- Self-Route Hybrid: Combines RAG and Lengthy Context LLMs for balanced price and efficiency.
- Optimum Utilization: Choice is dependent upon wants like cost-efficiency, context dealing with, and question complexity.
Evolution of Agentic RAG, So Far
When giant language fashions (LLMs) emerged, they revolutionized how folks engaged with data. Nonetheless, it was famous that counting on them to unravel complicated issues generally led to factual inaccuracies, as they rely solely on their inner information base. This led to the rise of the Retrieval-Augmented Technology (RAG).
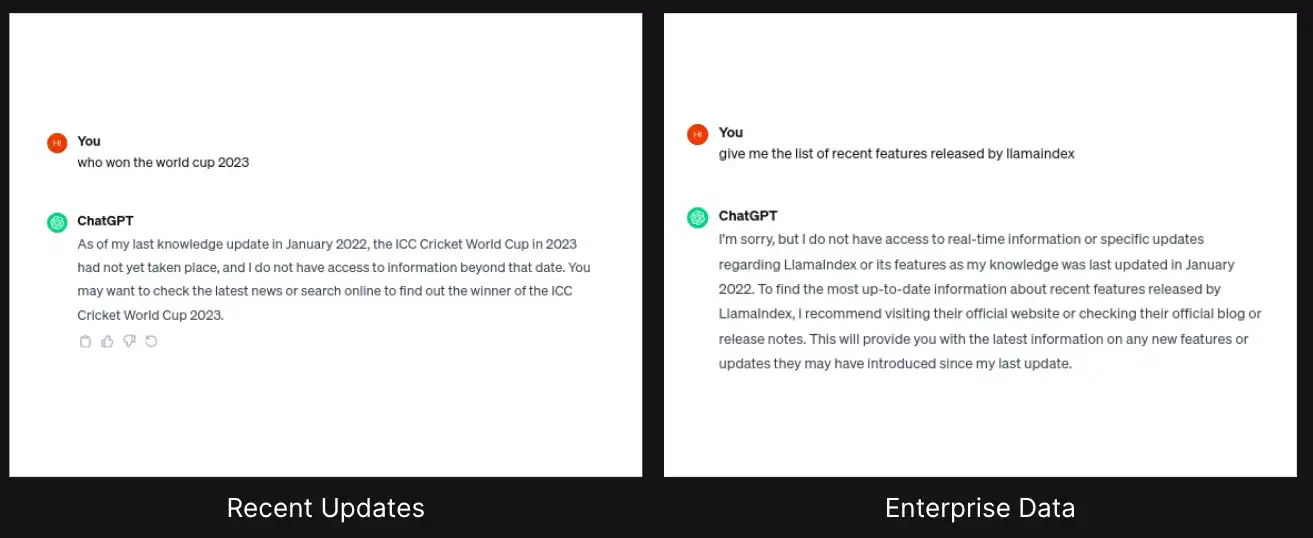
RAG is a way or a strategy to reinforce the exterior information into the LLMs.
We are able to straight join the exterior information base to LLMs, like chat GPT, and immediate the LLMs to fetch solutions in regards to the exterior information base.
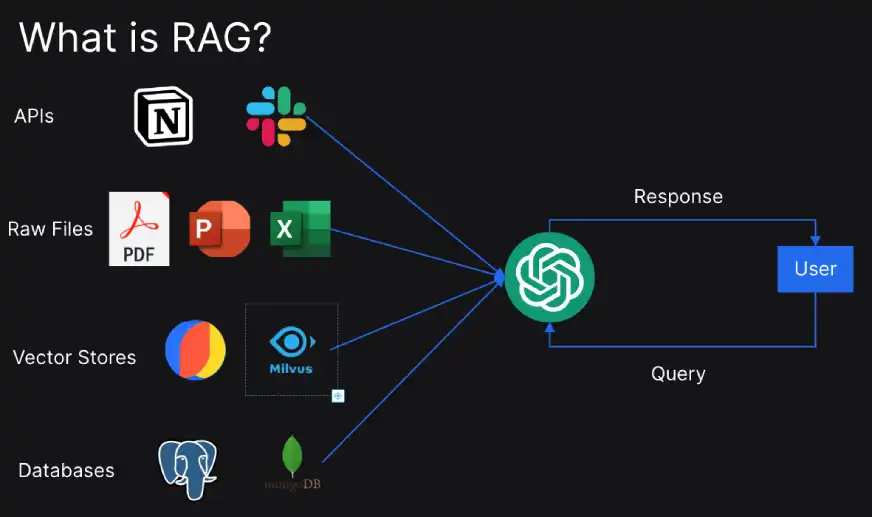
Let’s rapidly perceive how RAG works:
- Question Administration: Within the preliminary step, a question is processed to enhance the search efficiency.
- Data Retrieval: Then comes the step the place algorithms search the exterior information sources for related paperwork.
- Response Technology: Within the closing step, the front-end LLM makes use of data retrieved from the exterior database to craft correct responses.
RAG excels at easy queries throughout just a few paperwork, nevertheless it nonetheless lacks a layer of intelligence. The invention of agentic RAG led to the event of a system that may act as an autonomous decision-maker, analyzing the preliminary retrieved data and strategically choosing the best instruments for additional response optimization.
Agentic RAG and Agentic AI are carefully associated phrases that fall below the broader umbrella of Agentic Methods. Earlier than we examine Agentic RAG intimately, let’s have a look at the current discoveries within the fields of LLM and RAG.
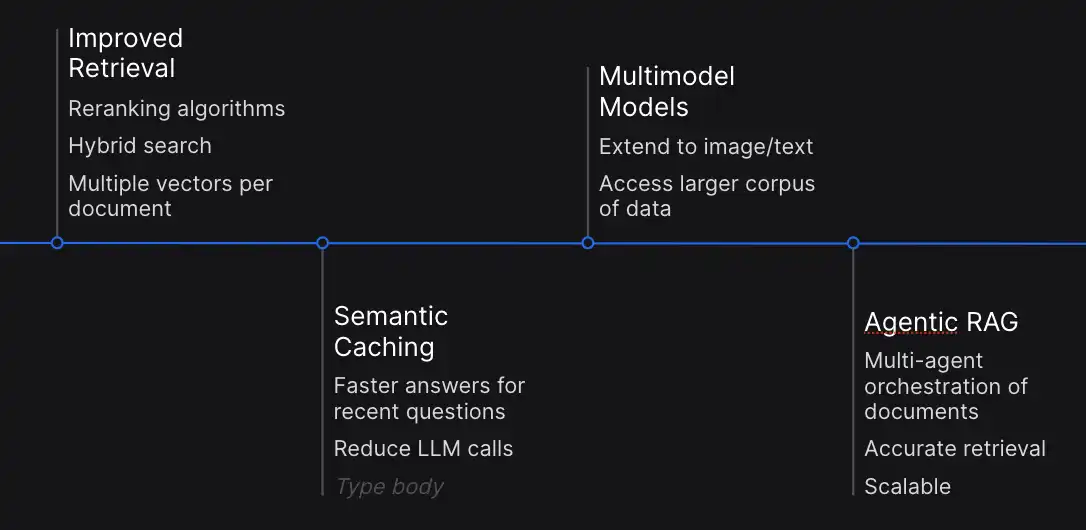
- Improved Retrieval: It is very important optimize retrieval for steady efficiency. Latest developments concentrate on reranking algorithms and hybrid search methodologies, additionally using a number of vectors per doc to boost relevance identification.
- Semantic Caching: Semantic caching has emerged as a key technique to mitigate computational complexity. It permits storing solutions to the current queries which can be utilized to reply the same requests with out repeating.
- Multimodal Integration: This expands the capabilities of LLMs and RAG past textual content, integrating pictures and different modalities. This integration facilitates seamless integration between textual and visible information.
Key Variations and Concerns between RAG and AI Brokers
Thus far, we now have understood the fundamental variations between RAG and AI brokers, however to know it intricately, let’s take a better have a look at among the defining parameters.
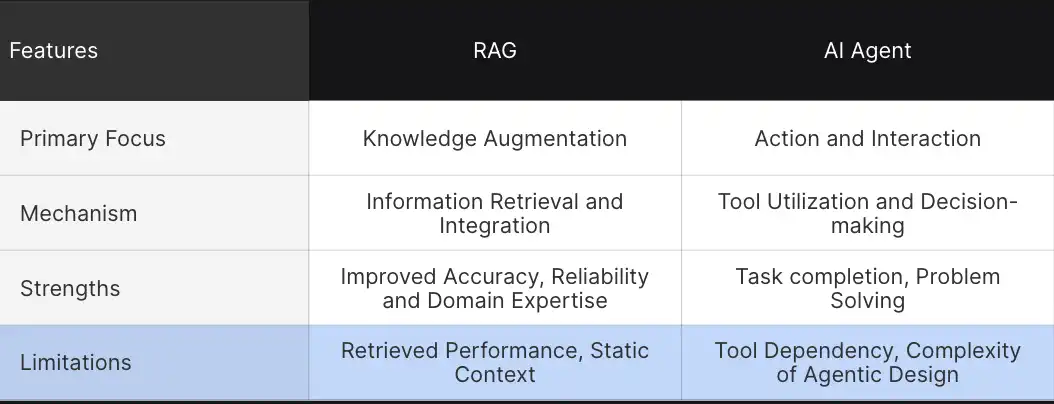
These comparisons assist us perceive how these superior applied sciences differ of their strategy to augmenting and performing duties.
- Main Focus: The first objective of RAG programs is to reinforce information, which consists of a mannequin’s understanding by retrieving related data. This enables for extra decision-making and improved contextual understanding. In distinction, AI brokers are designed for actions and environmental interactions. Right here, brokers go a step forward and work together with the instruments and full complicated duties.
- Mechanisms: RAG is dependent upon data extraction and integration. It pulls information from exterior sources and integrates it into the responses, whereas AI brokers perform by device utilization and autonomous decision-making.
- Energy: RAG’s power lies in its capacity to offer improved responses. By connecting LLM with exterior information, RAG prompts to offer extra correct and contextual data. Brokers, alternatively, are masters at process execution autonomously by interacting with the atmosphere.
- Limitations: RAG programs face challenges like retrieval issues, static context, and an absence of autonomous intervention whereas producing responses. Regardless of numerous strengths, brokers’ main limitations embody solely relying on instruments and the complexity of agentic design patterns.
Architectural Distinction Between Lengthy Context LLMs, RAGs and Agentic RAG
Thus far, you’ve got noticed how integrating LLMs with the retrieval mechanisms has led to extra superior AI functions and the way Agentic RAG (ARAG) is optimizing the interplay between the retrieval system and the technology mannequin.
Now, backed by these learnings, let’s discover the architectural variations to know how these applied sciences construct upon one another.
| Characteristic | Lengthy Context LLMs | RAG ( Retrieval Augmented Technology) | Agentic RAG |
| Core Parts | Static information base | LLM+ Exterior information supply | LLM+ Retrieval module + Autonomous Agent |
| Data Retrieval | No exterior retrieval | Queries exterior information sources throughout responses | Queries exterior databases and choose applicable device |
| Interplay Functionality | Restricted to textual content technology | Retrieves and integrates context | Autonomous choices to take actions |
| Use Instances | Textual content summarization, understanding | Augmented responses and contextual technology | Multi-tasking, end-to-end process technology |
Architectural Variations
- Lengthy Context LLMs: Transformer-based fashions corresponding to GPT -3 are normally skilled on a considerable amount of information and depend on a static information base. Their structure is appropriate for textual content technology and summarization, the place they don’t require exterior data to generate responses. Nonetheless, they lack the susceptibility to offer up to date or specialised information. Our space of focus is the Lengthy Context LLM fashions. These fashions are designed to deal with and course of for much longer enter tokens in comparison with conventional LLMs.
Fashions corresponding to GPT-3 or earlier fashions are sometimes restricted to the variety of enter tokens. Lengthy context fashions tackle such limitations by extending the context window measurement, making them higher at:- Summarizing bigger paperwork
- Sustaining coherence over lengthy dialogues
- Processing paperwork with in depth context
- RAG (Retrieval Augmented Technology): RAG has emerged as an answer to beat LLMs’ limitations. The retrieval part permits LLMs to be linked to exterior information sources, and the augmentation part permits RAG to offer extra contextual data than a regular LLM. Nonetheless, RAG nonetheless lacks autonomous decision-making capabilities.
- Agentic RAG: Subsequent is Agentic RAG, which contains a further intelligence layer. It could possibly retrieve exterior data and contains an autonomous reasoning module that analyzes the retrieved data and implements strategic choices.
These architectural distinctions assist clarify how every system permits information, augmentation, and decision-making in another way. Now comes the purpose the place we have to decide essentially the most appropriate—LLMs, RAG, and Agentic RAG. To choose one, you must think about particular necessities corresponding to Value, Efficiency, and Performance. Let’s examine them in higher element beneath.
A Comparative Evaluation of Lengthy Context LLMs, RAG and Agentic RAG
- Lengthy-context LLMs: There have all the time been efforts to allow LLMs to deal with lengthy contexts. Whereas current LLMs like Gemini 1.5, GPT 4, and Claude 3 obtain considerably bigger context sizes, there is no such thing as a or little change in price associated to long-context prompting.
- Retrieval-Augmented Technology: Augmenting LLMs with RAG achieved suboptimal efficiency in comparison with LC. Nonetheless, its considerably decrease computational price makes it a viable resolution. The graph reveals that the price distinction between LLMs and RAG for the reference fashions is round 83%. Thus, RAGs can’t be made out of date. So, there’s a want for a way that makes use of the fusion of those two to make the mannequin quick and cost-effective concurrently.
However, earlier than we transfer onto understanding the brand new fusion approach, let’s first have a look at the consequence it has produced.
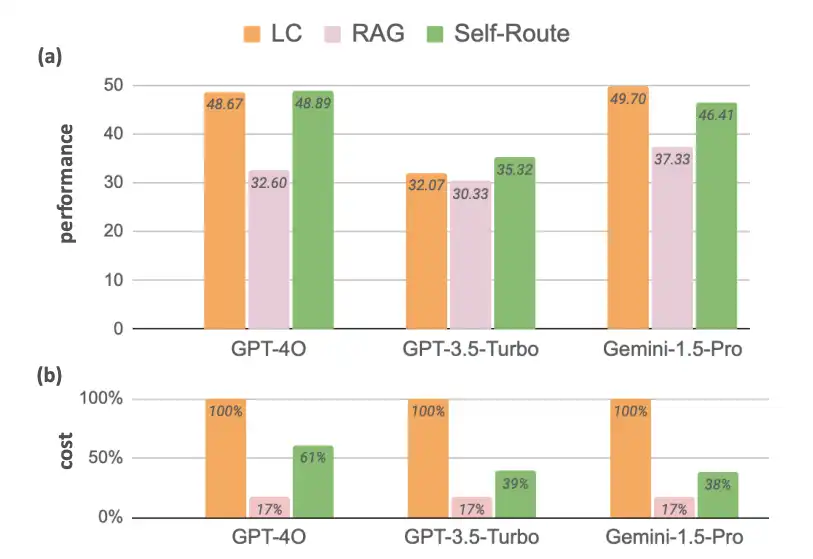
Self-Route: Self-Route is an Agentic Retrieval-Augmented Technology (RAG), designed to realize a balanced trade-off between price and efficiency. For queries that may be answered with out routing, it makes use of fewer tokens, and solely resorting to LC for extra complicated queries.
Now full of this understanding, let’s transfer on to know Self-Route.
Self-Route: Fusion of RAG and Agentic RAG
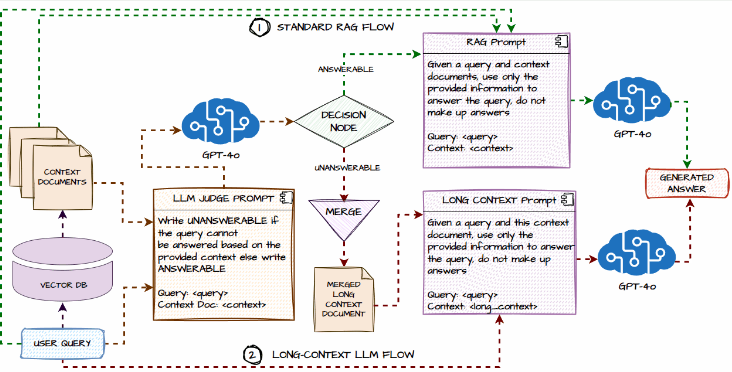
Self-Route is an Agentic AI design sample that makes use of LLMs itself to route queries primarily based on self-reflection, below the idea that LLMs are well-calibrated in predicting whether or not a question is answerable given offered context.
- RAG-and-Route-Step: In step one, customers present a question and the retrieved chunks to the LLM and ask it to foretell whether or not the question is answerable and, if that’s the case, generate the reply. This is similar as Commonplace RAG, besides that the LLM is given the choice to say no answering the immediate.
- Lengthy Context Prediction Step: For the queries which can be deemed unanswerable, the second step is to offer the complete context to the lengthy context LLMs to acquire the ultimate prediction.
Self-Route proves to be an efficient technique when efficiency and value have to be balanced. This makes it a perfect system for functions that require coping with a various set of queries.
Key Takeaways
- When to Use RAG ( Retrieval Augmented Technology)?
- There’s a want for decrease computational prices.
- Question exceeds the mannequin’s context window measurement, making RAG most effectively.
- When to make use of Lengthy Context LLMs (LC)?
- Dealing with lengthy context is required.
- Enough sources can be found to assist greater computational price.
- When to make use of Self-route?
- A balanced resolution is required – some queries might be answered utilizing RAG, and LC handles extra complicated one.
Conclusion
We now have mentioned the evolution of Agentic RAG, particularly evaluating Lengthy Context LLMs, Retrieval-Augmented Technology (RAG), and the extra superior Agentic RAG. Whereas Lengthy Context LLMs excel at sustaining context over prolonged dialogues or giant paperwork, RAG improves upon this by integrating exterior information retrieval to boost contextual accuracy. Nonetheless, each fall quick when it comes to autonomous action-taking.
With the evolution of agentic RAG, we now have launched a brand new intelligence layer by enabling decision-making and autonomous actions, bridging the hole between static data processing and dynamic process execution. The article additionally presents a hybrid strategy known as “Self-Route,” which mixes the strengths of RAG and Lengthy Context LLMs, balancing efficiency and value by routing queries primarily based on complexity.
In the end, the selection between these programs is dependent upon particular wants, corresponding to cost-efficiency, context measurement, and the complexity of queries, with Self-Route rising as a balanced resolution for various functions.
Additionally, to know the Agent AI higher, discover: The Agentic AI Pioneer Program
Steadily Requested Questions
Ans. RAG is a strategy that connects a big language mannequin (LLM) with an exterior information base. It enhances the LLM’s capacity to offer correct responses by retrieving and integrating related exterior data into its solutions.
Ans. Lengthy Context LLMs are designed to deal with for much longer enter tokens in comparison with conventional LLMs, permitting them to take care of coherence over prolonged textual content and summarize bigger paperwork successfully.
Ans. AI Brokers are autonomous programs that may make choices and take actions primarily based on processed data. In contrast to RAG, which augments information retrieval, AI Brokers work together with their atmosphere to finish duties independently.
Ans. Lengthy Context LLMs are greatest used when you must deal with in depth content material, corresponding to summarizing giant paperwork or sustaining coherence over lengthy conversations, and have ample sources for greater computational prices.
Ans. RAG is extra cost-efficient in comparison with Lengthy Context LLMs, making it appropriate for situations the place computational price is a priority and the place further contextual data is required to reply queries.