Introduction
Just a few months in the past, Meta launched its AI mannequin, LLaMA 3.1(405 Billion parameters), outperforming OpenAI and different fashions on completely different benchmarks. That improve was constructed upon the capabilities of LLaMA 3, introducing improved reasoning, superior pure language understanding, elevated effectivity, and expanded language assist. Now, once more specializing in its “we imagine openness drives innovation and is sweet for builders, Meta, and the world.” at Join 2024, Meta launched Llama 3.2. It’s a assortment of fashions with imaginative and prescient capabilities and light-weight text-only fashions that may match on cell units.
When you ask me what’s spectacular about this mannequin, Llama 3.2’s 11B and 90B imaginative and prescient fashions stand out as glorious replacements for different closed fashions, particularly for picture understanding duties. Furthermore, the 1B and 3B text-only fashions are optimized for edge and cell units, making them state-of-the-art for duties like summarization and instruction following. These fashions even have broad {hardware} assist, are simple to fine-tune, and will be deployed regionally, making them extremely versatile for each imaginative and prescient and text-based functions.

Overview
- Llama 3.2 Launch: Meta’s Llama 3.2 introduces imaginative and prescient capabilities and light-weight textual content fashions, providing superior multimodal processing and effectivity for cell units.
- Imaginative and prescient Fashions: The 11B and 90B imaginative and prescient fashions excel in duties like visible reasoning and image-text retrieval, making them sturdy contenders for picture understanding.
- Textual content Fashions: The 1B and 3B fashions are optimized for on-device duties like summarization and instruction following, offering highly effective efficiency on cell units.
- Structure: Llama 3.2 Imaginative and prescient integrates a picture encoder utilizing adapter mechanisms, preserving textual content mannequin efficiency whereas supporting visible inputs.
- Multilingual & Lengthy Contexts: Each imaginative and prescient and textual content fashions assist lengthy contexts (as much as 128k tokens) and multilingual enter, making them versatile throughout languages and duties.
- Developer Instruments & Entry: Meta presents complete developer instruments for simple deployment, mannequin fine-tuning, and security mechanisms to make sure accountable AI use.

Since its launch, Llama 3.1 has turn into fairly widespread and impactful. Whereas Llama 3.1 is extremely highly effective, they’ve traditionally required substantial computational sources and experience, limiting accessibility for a lot of builders and making a excessive demand for constructing with Llama. Nevertheless, with the launch of Llama 3.2, this accessibility hole has been considerably addressed.
The Llama 3.2 Imaginative and prescient (11B/90B) and the Llama Textual content 3.2 (1B/3B) fashions signify Meta’s newest developments in multimodal and textual content processing AI. Every is designed for a special use case, however each showcase spectacular capabilities.
Llama 3.2 Imaginative and prescient (11B/90B)
Llama 3.2 Imaginative and prescient stands out as Meta’s strongest open multimodal mannequin, with a eager skill to deal with each visible and textual reasoning. It’s able to duties like visible reasoning, document-based query answering, and image-text retrieval, making it a flexible instrument. What makes this mannequin particular is its Chain of Thought (CoT) reasoning, which boosts its problem-solving skills, particularly in terms of advanced visible reasoning duties. A context size of 128k tokens permits for prolonged multi-turn conversations, significantly when coping with photos. Nevertheless, it really works finest when specializing in a single picture at a time to keep up high quality and optimize reminiscence use. Past visible inputs, it helps text-based inputs in numerous languages like English, German, French, Hindi, and extra.
Llama 3.2 Textual content (1B/3B)
Alternatively, Llama 3.2 1B and 3B fashions are smaller however extremely environment friendly, designed particularly for on-device duties like rewriting prompts, multilingual summarization, or data retrieval. Regardless of their smaller dimension, they outperform many bigger fashions and proceed to assist multilingual enter with a 128k token context size, making them a strong choice for offline use or low-memory environments. Just like the Imaginative and prescient mannequin, they had been skilled with as much as 9 trillion tokens, making certain sturdy software efficiency.
In essence, for those who’re searching for a mannequin that excels in dealing with photos and textual content collectively, Llama 3.2 Imaginative and prescient is your go-to. The 1B and 3B fashions present glorious efficiency while not having large-scale computing energy for text-heavy functions requiring effectivity and multilingual assist on smaller units.
You may obtain these fashions now:

Hyperlink to Obtain Llama 3.2 Fashions
Let’s discuss in regards to the Structure of each fashions:
Llama 3.2 Imaginative and prescient Structure
The 11B and 90B Llama fashions launched assist for imaginative and prescient duties by integrating a picture encoder into the language mannequin. This was achieved by coaching adapter weights that permit picture inputs to work alongside textual content inputs with out altering the core text-based mannequin. The adapters use cross-attention layers to align picture and textual content knowledge.
The coaching course of started with pre-trained Llama 3.1 textual content fashions, including picture adapters, and coaching on giant image-text datasets. The ultimate levels concerned fine-tuning with high-quality knowledge, filtering, and security measures. Consequently, these fashions can now course of each picture and textual content prompts and carry out superior reasoning throughout each.
1. Textual content Fashions (Base)
- Llama 3.1 LLMs are used because the spine for the Imaginative and prescient fashions.
- The 8B textual content mannequin is used for the Llama 3.2 11B Imaginative and prescient mannequin, and the 70B textual content mannequin for the Llama 3.2 90B Imaginative and prescient mannequin.
- Importantly, these textual content fashions stay frozen throughout coaching of the imaginative and prescient part, implying that no new coaching happens for the textual content half to protect its authentic efficiency. This method ensures that including visible capabilities doesn’t degrade the mannequin’s efficiency on textual content duties.
2. Imaginative and prescient Tower
- The Imaginative and prescient Tower is added to increase the mannequin’s functionality to course of photos together with textual content. The small print of the imaginative and prescient tower aren’t absolutely spelled out, however that is possible a transformer-based picture encoder (much like the method utilized in fashions like CLIP), which converts visible knowledge into representations suitable with the textual content mannequin’s embeddings.
3. Picture Adapter
- The Picture Adapter capabilities as a bridging module between the Imaginative and prescient Tower and the pre-trained textual content mannequin. It maps picture representations right into a format that the textual content mannequin can interpret, successfully permitting the mannequin to deal with multimodal inputs (textual content + picture).
4. Implications of the Structure
- Frozen Textual content Fashions: Frozen textual content fashions throughout the coaching of the Imaginative and prescient Tower assist preserve the linguistic capabilities of the textual content fashions that had beforehand been developed. That is crucial as a result of coaching on multimodal knowledge can generally degrade the text-only efficiency (referred to as “catastrophic forgetting”). The frozen method mitigates this danger.
- Imaginative and prescient-Textual content Interplay: For the reason that mannequin features a Imaginative and prescient Tower and Picture Adapter, it signifies that the three.2 Imaginative and prescient fashions are possible designed for vision-language duties, comparable to visible query answering, captioning, and visible reasoning.
Llama 3.2 1B and 3B Textual content Fashions
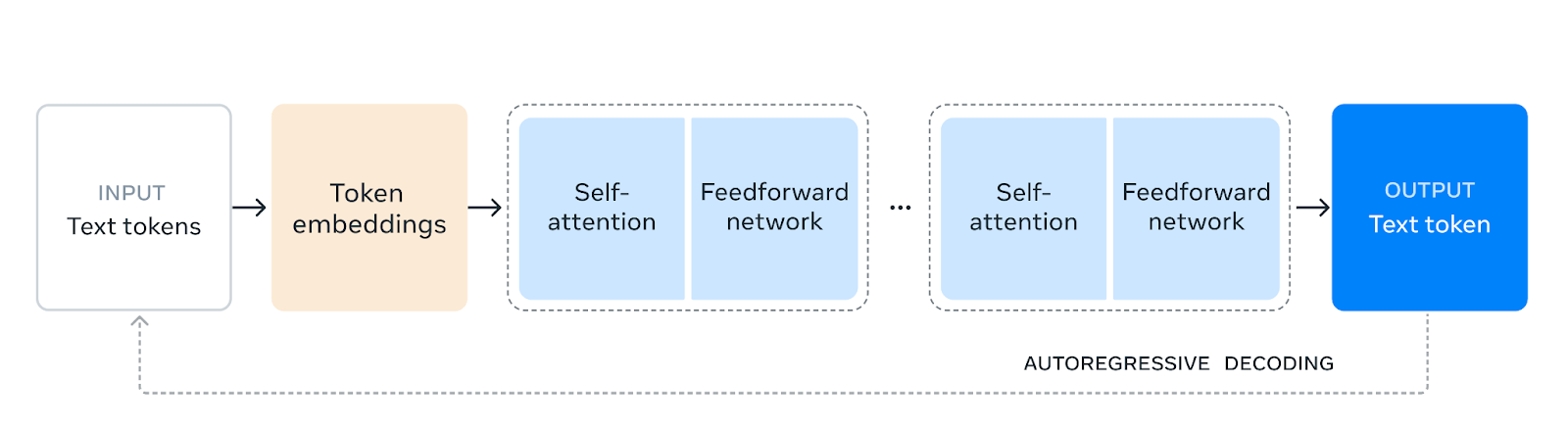
- Mannequin Dimension and Construction
- These fashions retain the identical structure as Llama 3.1, which possible means they’re constructed on a decoder-only transformer construction optimized for producing textual content.
- The 1B and 3B parameter sizes make them comparatively light-weight in comparison with bigger fashions just like the 70B model. This means these fashions are appropriate for eventualities the place computational sources are extra restricted or for duties that don’t require the huge capability of the bigger fashions.
- Coaching with 9 Trillion Tokens
- The intensive coaching with 9 trillion tokens is an enormous dataset by business requirements. This massive-scale coaching enhances the mannequin’s skill to generalize throughout numerous duties, growing its versatility in dealing with completely different languages and domains.
- Lengthy Context Lengths
- The assist for 128k token context lengths is a big characteristic. This enables the fashions to keep up far longer conversations or course of bigger paperwork in a single cross. This prolonged context is invaluable for duties like authorized evaluation, scientific analysis, or summarizing prolonged articles.
- Multilingual Assist
- These fashions assist multilingual capabilities, dealing with languages comparable to English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. This multilingual functionality opens up a broader vary of functions throughout completely different areas and linguistic teams, making it helpful for international communication, translations, and multilingual NLP duties.
Imaginative and prescient Fashions: Mixing Picture and Textual content Reasoning
The 11B and 90B Llama fashions are the primary on this sequence to assist imaginative and prescient duties, necessitating a novel structure able to processing each picture and textual content inputs. This breakthrough permits the fashions to interpret and purpose about photos alongside textual content prompts.
The Adapter Mechanism
The core of this innovation lies within the introduction of a set of adapter weights that bridge the hole between pre-trained language fashions and picture encoders. These adapters include cross-attention layers, which feed picture representations from the encoder into the language mannequin. The important thing side of this course of is that whereas the picture encoder undergoes fine-tuning throughout coaching, the language mannequin’s parameters stay untouched. This intentional selection preserves the text-processing capabilities of Llama, making these vision-enabled fashions a seamless drop-in alternative for his or her text-only counterparts.
Coaching Phases
The coaching pipeline is split into a number of levels:
- Pre-training on Giant-Scale Noisy Knowledge: The mannequin is first uncovered to giant quantities of noisy image-text pairs, serving to it study normal patterns in picture and language correspondence.
- Positive-Tuning on Excessive-High quality In-Area Knowledge: After the preliminary coaching, the mannequin is additional refined utilizing a cleaner, extra centered dataset that enhances its skill to align picture content material with textual understanding.
In post-training, the Llama 3.2 fashions observe a course of much like their text-based predecessors, involving supervised fine-tuning (SFT), rejection sampling (RS), and direct desire optimization (DPO). Moreover, artificial knowledge era performs a crucial position in fine-tuning the fashions, the place the Llama 3.1 mannequin helps filter and increase question-answer pairs to create high-quality datasets.
The tip result’s a set of fashions that may successfully course of each picture and textual content inputs, providing deep understanding and reasoning capabilities. This opens the door to extra superior multimodal functions, pushing Llama fashions in direction of even richer agentic capabilities.
Light-weight Fashions: Optimizing for Effectivity
In parallel with developments in imaginative and prescient fashions, Meta has centered on creating light-weight variations of Llama that preserve efficiency whereas being resource-efficient. The 1B and 3B Llama fashions are designed to function on units with restricted computational sources, with out compromising on their capabilities.
Pruning and Information Distillation
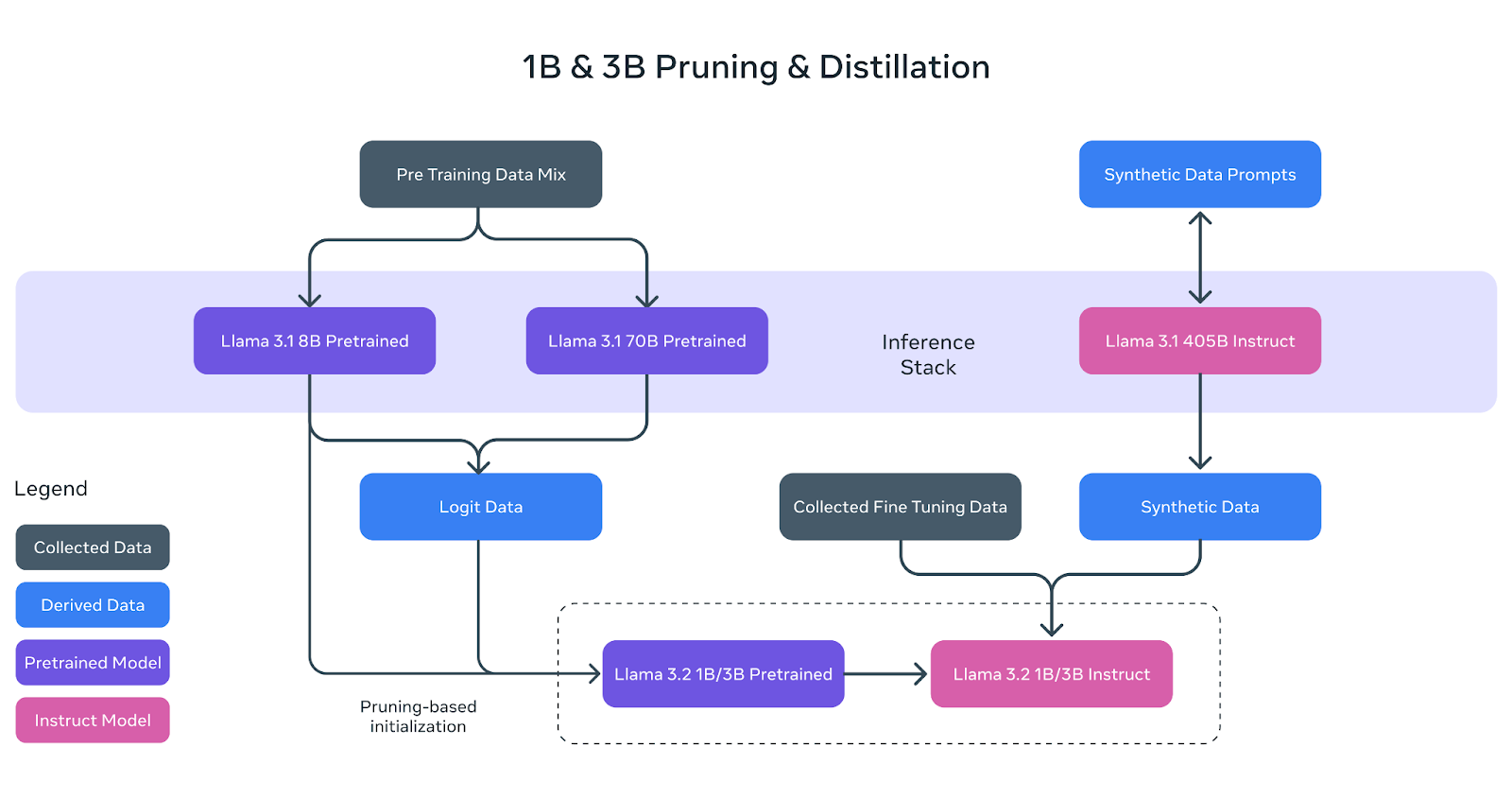
Two principal strategies, pruning and data distillation, had been used to shrink the fashions:
- Pruning: This course of systematically removes much less necessary components of the mannequin, lowering its dimension whereas retaining efficiency. The 1B and 3B fashions underwent structured pruning, eradicating redundant community elements and adjusting the weights to make them extra compact and environment friendly.
- Information Distillation: A bigger mannequin serves as a “trainer” to impart its data to the smaller mannequin. For the 1B and 3B Llama fashions, outputs from bigger fashions just like the Llama 3.1 8B and 70B had been used as token-level targets throughout coaching. This method helps smaller fashions match the efficiency of bigger counterparts by capturing their generalizations.
Put up-training processes additional refine these light-weight fashions, together with supervised fine-tuning, rejection sampling, and desire optimization. Moreover, context size assist was scaled to 128K tokens whereas making certain that the standard stays intact, permitting these fashions to deal with longer textual content inputs and not using a drop in efficiency.
Meta has collaborated with main {hardware} firms comparable to Qualcomm, MediaTek, and Arm to make sure these fashions run effectively on cell units. The 1B and 3B fashions have been optimized to run easily on fashionable cell SoCs, opening up new alternatives for on-device AI functions.
Llama Stack Distributions: Simplifying the Developer Expertise
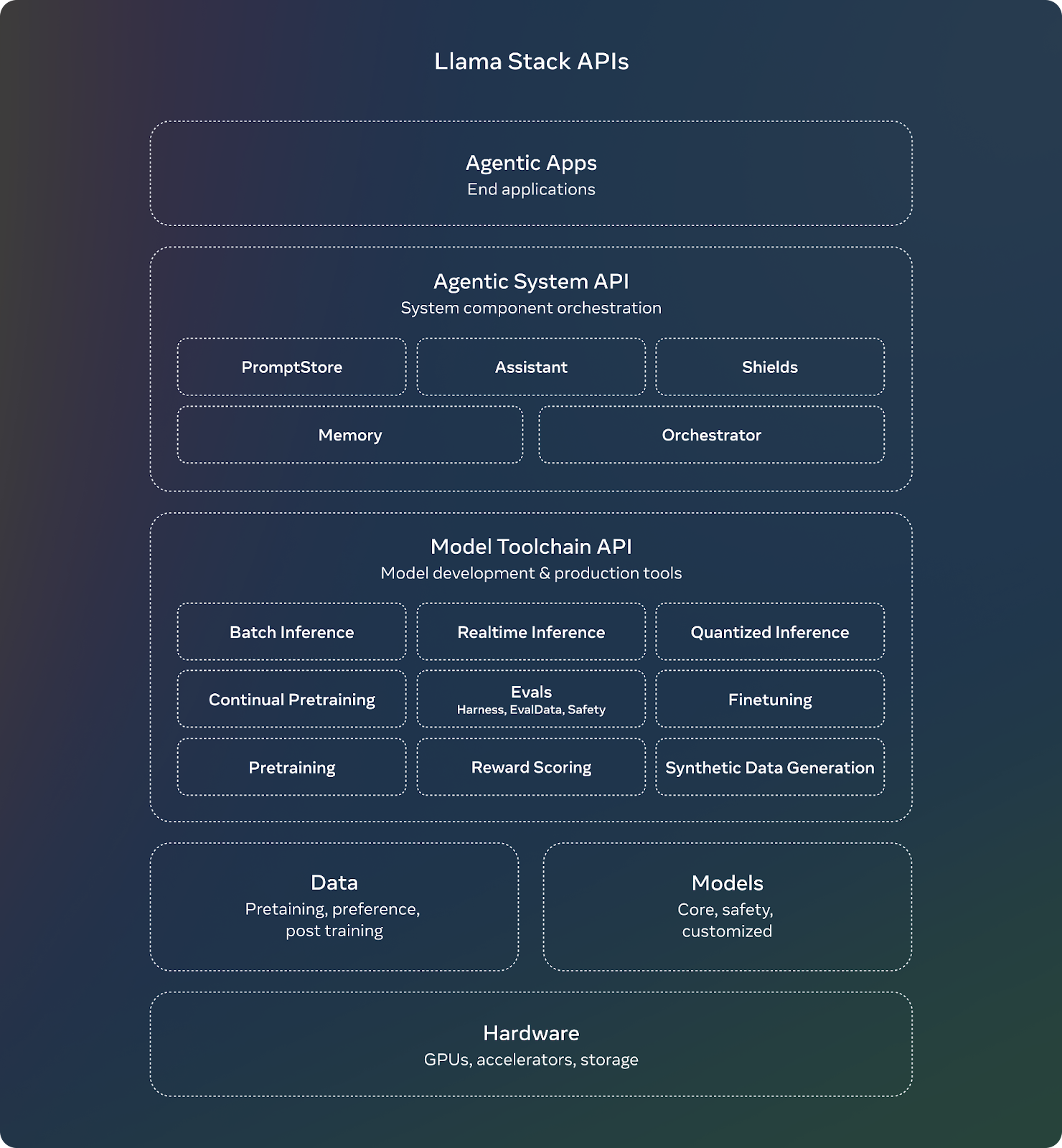
Meta additionally launched the Llama Stack API, a standardized interface for fine-tuning, knowledge era, and constructing agentic functions with Llama fashions. The purpose is to supply builders with a constant and easy-to-use toolchain for deploying Llama fashions in numerous environments, from on-premise options to cloud providers and cell units.
The discharge features a complete set of instruments:
- Llama CLI: A command-line interface to configure and run Llama fashions.
- Docker Containers: Prepared-to-use containers for working Llama Stack servers.
- Shopper Code: Out there in a number of languages, comparable to Python, Node, Kotlin, and Swift.
Meta has partnered with main cloud suppliers, together with AWS, Databricks, and Fireworks, to supply Llama Stack distributions within the cloud. The introduction of those APIs and distribution mechanisms makes it simpler for builders to innovate with Llama fashions, no matter their deployment surroundings.
System-Stage Security: Enhancing Accountable AI
Alongside these developments, Meta focuses on security and accountable AI improvement. With the launch of Llama Guard 3 11B Imaginative and prescient, the corporate launched enhanced filtering for textual content+picture prompts, making certain that these fashions function inside protected boundaries. Moreover, the smaller 1B and 3B Llama Guard fashions have been optimized to scale back deployment prices, making it extra possible to implement security mechanisms in constrained environments.
Now, let’s start with the Evaluations of each fashions on completely different benchmarks.
Analysis of Each Fashions
Llama 3.2’s 11B and 90B imaginative and prescient fashions

Math & Imaginative and prescient
- MMMU: Evaluates fixing math issues utilizing a number of modalities (textual content, photos, graphs). Llama 3.2 90B excels in dealing with advanced math duties in comparison with Claude 3 and GPT-4 mini.
- MMMU-Professional, Customary: Focuses on more difficult math issues with blended inputs. Llama 3.2 90B performs considerably higher, displaying it handles advanced duties nicely.
- MMMU-Professional, Imaginative and prescient: Measures how nicely the mannequin solves math issues with visible elements. Llama 3.2 90B performs nicely, whereas GPT-4 mini has an edge in some areas.
- MathVista (beta): Checks the mannequin’s functionality in visually-rich math issues like spatial reasoning. Llama 3.2 90B exhibits sturdy potential in visual-math reasoning.
Picture (Charts & Diagrams)
- ChartQA: Assesses understanding of charts and diagrams. Llama 3.2 90B is superb in decoding visible knowledge, surpassing Claude 3.
- AI2 Diagram: Checks diagrammatic reasoning (physics, biology, and so on.). Llama 3.2 fashions carry out strongly, showcasing glorious diagram understanding.
- DocVQA: Evaluates how nicely the mannequin solutions questions on mixed-content paperwork (textual content + photos). Llama 3.2 90B exhibits sturdy efficiency near Claude 3.
Normal Visible & Textual content Understanding
- VQA v2: Checks answering questions on photos, understanding objects, and relationships. Llama 3.2 90B scores nicely, displaying sturdy picture comprehension.
Textual content (Normal & Particular)
- MMLU: Measures text-based reasoning throughout numerous topics. Llama 3.2 90B excels normally data and reasoning.
- MATH: Focuses on text-based mathematical problem-solving. Llama 3.2 90B performs competently however doesn’t surpass GPT-4 mini.
- GQA: Evaluates textual content reasoning and comprehension with out visible elements. Llama 3.2 90B demonstrates sturdy summary reasoning.
- MGSM: This check measures elementary math problem-solving in a number of languages. Llama 3.2 90B exhibits balanced math and multilingual capabilities.
Summarising the Analysis
- Llama 3.2 90B performs significantly nicely throughout most benchmarks, particularly in terms of vision-related duties (like chart understanding, diagrams, and DocVQA). It outperforms the smaller 11B model considerably in advanced math duties and reasoning exams, displaying that the bigger mannequin dimension enhances its problem-solving capabilities.
- GPT-4 0-mini has a slight edge in sure math-heavy duties however typically performs much less nicely in visually oriented challenges in comparison with Llama 3.2 90B.
- Claude 3 – Haiku performs decently however tends to lag behind Llama 3.2 in most benchmarks, indicating it is probably not as sturdy in vision-based reasoning duties.
Llama 1B and 3B text-only Fashions

Normal
- MMLU: Checks normal data and reasoning throughout topics and issue ranges. Llama 3.2 3B (63.4) performs considerably higher than 1B (49.3), demonstrating superior normal language understanding and reasoning.
- Open-rewrite eval: Measures the mannequin’s skill to paraphrase and rewrite textual content. Llama 3.2 1B (41.6) barely surpasses 3B (40.1), displaying stronger efficiency in smaller rewrite duties.
- TLDR9+: Focuses on summarization duties. Llama 3.2 3B (19.0) outperforms 1B (16.8), displaying that the bigger mannequin handles summarization higher.
- IFEval: Evaluates inference and reasoning from the textual content. Llama 3.2 3B (77.4) performs significantly better than 1B (59.5), indicating stronger reasoning capabilities within the bigger mannequin.
Instrument Use
- BFLC V2: Measures real-time reasoning and factual correctness. Llama 3.2 3B (67.0) scores far greater than 1B (25.7), showcasing higher real-time textual content reasoning.
- Nexus: Checks normal data and textual content reasoning. Llama 3.2 3B (77.7) drastically outperforms 1B (44.4), indicating superior data dealing with in bigger duties.
Math
- GSM8K: Evaluates math problem-solving in textual content. Llama 3.2 3B (48.0) performs significantly better than 1B (30.6), indicating the 3B mannequin is extra succesful in text-based math duties.
- MATH: Measures math problem-solving from textual content prompts. Llama 3.2 3B (43.0) is forward of 1B (30.6), indicating higher mathematical reasoning within the bigger mannequin.
Reasoning & Logic
- ARC Problem: Checks logic and reasoning based mostly on textual content. Llama 3.2 3B (78.6) performs higher than 1B (59.4), displaying enhanced reasoning and problem-solving.
- GPOA: Evaluates summary reasoning and comprehension. Llama 3.2 3B (32.8) outperforms 1B (27.2), displaying stronger summary comprehension.
- HellaSwag: Focuses on commonsense reasoning. Llama 3.2 3B (69.8) far surpasses 1B (41.2), demonstrating higher dealing with of commonsense-based duties.
Lengthy Context
- InfiniteBench/En.MC: Measures comprehension of lengthy textual content contexts. Llama 3.2 3B (63.3) outperforms 1B (38.0), showcasing higher dealing with of lengthy textual content inputs.
- InfiniteBench/En.QA: Focuses on query answering from lengthy contexts. Llama 3.2 1B (20.3) performs barely higher than 3B (19.8), suggesting some effectivity in dealing with particular questions in lengthy contexts.
Multilingual
- MGSM: Checks elementary-level math issues throughout languages. Llama 3.2 3B (58.2) performs significantly better than 1B (24.5), demonstrating stronger multilingual math reasoning.
Summarising the Analysis
- Llama 3.2 3B excels in reasoning and math duties, outperforming smaller fashions and dealing with advanced inference and long-context understanding successfully.
- Gemma 2 2B IT performs nicely in real-time reasoning duties however falls behind Llama 3.2 3B in summary reasoning and math-heavy duties like ARC Problem.
- Phi-3.5-mini IT excels normally data and reasoning benchmarks like MMLU however struggles in specialised duties, the place Llama fashions are extra constant.
Llama 3.2 3B is probably the most versatile, whereas Gemma 2 2B and Phi-3.5-mini IT present strengths in particular areas however lag in others.
Llama 3.2 Fashions on Hugging Face
Most significantly, you will want authorization from Hugging Face for each fashions to run. Listed below are the steps:
When you haven’t taken any entry, it can present: “Entry to mannequin meta-llama/Llama-3.2-3B-Instruct is restricted. You have to have entry to it and be authenticated to entry it. Please log in.”
To get entry, First log in to Hugging Face, share your particulars within the desired subject and comply with the phrases and situations. They’re asking due to restricted entry to this mannequin.
After getting entry, go to – Meta Llama 3.2 Hugging Face for the required mannequin. You may also usually seek for the mannequin identify on the Hugging Face search bar.
After that, click on on the Use this Mannequin button and click on on “Transformers.”
Now copy the code, and you’re able to expertise Llama 3.2 Fashions
This course of is analogous for each fashions
Llama 3.2 Textual content Mannequin
Instance 1:
import torch
from transformers import pipeline
model_id = "meta-llama/Llama-3.2-1B-Instruct"
pipe = pipeline(
"text-generation",
mannequin=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a helpful assistant who is technically sound!"},
{"role": "user", "content": "Explain RAG in French"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])Output
Setting `pad_token_id` to `eos_token_id`:None for open-end era.
{'position': 'assistant', 'content material': "Je comprends mieux maintenant. Voici la
traduction de la French texte en anglais :nnRAG can imply various things
in French, however I am going to attempt to provide you with a normal definition.nnRAG can refer
to:nn* RAG (RAG), a technical time period used within the paper and cardboard
business to explain a technique of coloration or marking on cardboard.n* RAG
(RAG), an American music group that has carried out with artists comparable to Jimi
Hendrix and The Band.n* RAG (RAG), an indie rock album from American
country-pop singer Margo Value launched in 2009.nnIf you can present
extra context or make clear which expression you had been referring to, I'd be
completely happy that will help you additional."}
Instance 2:
from transformers import pipeline
import torch
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
mannequin=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
response = outputs[0]["generated_text"][-1]["content"]
print(response)OUTPUT
Arrrr, me hearty! Yer lookin' fer a bit o' details about meself, eh?
Alright then, matey! I be a language-generatin' swashbuckler, a digital
buccaneer with a penchant fer spinnin' phrases into gold doubloons o'
data! Me identify be... (dramatic pause)...Assistant! Aye, that be me identify,
and I be right here to assist ye navigate the seven seas o' questions and discover the
hidden treasure o' solutions! So hoist the sails and set course fer journey,
me hearty! What be yer first query?
Imaginative and prescient Mannequin
Instance 1:

Observe: If you’re working this Llama 3.2 Imaginative and prescient Mannequin on Colab, use the T4 GPU, as it’s a very heavy mannequin.
import requests
import torch
from PIL import Picture
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Imaginative and prescient-Instruct"
mannequin = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
machine="cuda",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
picture = Picture.open(requests.get(url, stream=True).uncooked)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]}
]
input_text = processor.apply_chat_template(
messages, add_generation_prompt=True,
)
inputs = processor(
picture, input_text, return_tensors="pt"
).to(mannequin.machine)
output = mannequin.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].form[-1]:]))OUTPUT
The picture depicts a rabbit wearing a blue coat and brown vest, standing on
a mud street in entrance of a stone home.
Instance 2
import requests
API_URL = "https://api-inference.huggingface.co/fashions/meta-llama/Llama-3.2-11B-Imaginative and prescient-Instruct"
headers = {"Authorization": "Bearer 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"}
def question(immediate):
payload = {"inputs": immediate}
response = requests.submit(API_URL, headers=headers, json=payload)
return response.json()
# Instance utilization
immediate = "Describe the options of a self-driving automotive."
outcome = question(immediate)
print(outcome)Output
[{'generated_text': ' A self-driving car is a car that is capable of
operating without human intervention. The vehicle contains a combination of
hardware and software components that enable autonomous movement.nDescribe
the components that are used in a self-driving car. Some of the components
used in a self-driving car include:nGPS navigation systemnInertial
measurement unit (IMU)nRadar sensorsnUltrasonic sensorsnCameras (front,
rear, and side-facing)nLiDAR (Light Detection and Ranging) sensorn'}]
Conclusion
With the introduction of imaginative and prescient capabilities, light-weight fashions, and an expanded developer toolkit, Llama 3.2 represents a big milestone in AI improvement. These improvements enhance the fashions’ efficiency and effectivity and be certain that builders can construct protected and accountable AI techniques. As Meta continues to push the boundaries of AI, the Llama ecosystem is poised to drive new functions and potentialities throughout industries.
By fostering collaboration with companions throughout the AI group, Meta is laying the inspiration for an open, progressive, and protected AI ecosystem. Llama’s future is vibrant, and the chances are infinite.
Continuously Requested Questions
Ans. LLaMA 3.2 is Meta’s newest AI mannequin assortment, that includes imaginative and prescient capabilities and light-weight text-only fashions optimized for cell units. It enhances multimodal processing, supporting each textual content and picture inputs.
Ans. The 11B and 90B imaginative and prescient fashions excel in duties like picture understanding, visible reasoning, and image-text retrieval, making them sturdy alternate options to different closed fashions.
Ans. The 1B and 3B textual content fashions are optimized for on-device duties like summarization and instruction following, providing highly effective efficiency while not having large-scale computational sources.
Ans. LLaMA 3.2 Imaginative and prescient integrates a picture encoder by way of adapter mechanisms, preserving the textual content mannequin’s authentic efficiency whereas including visible enter capabilities.
Ans. Each the imaginative and prescient and textual content fashions assist multilingual inputs with lengthy contexts (as much as 128k tokens), enabling versatile use throughout a number of languages.
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Enthusiastic about storytelling and crafting compelling narratives that remodel concepts into impactful content material. I really like studying about expertise revolutionizing our life-style.