Quicker, smarter, extra responsive AI purposes – that’s what your customers count on. However when massive language fashions (LLMs) are sluggish to reply, consumer expertise suffers. Each millisecond counts.
With Cerebras’ high-speed inference endpoints, you’ll be able to cut back latency, pace up mannequin responses, and preserve high quality at scale with fashions like Llama 3.1-70B. By following a number of easy steps, you’ll be capable to customise and deploy your personal LLMs, supplying you with the management to optimize for each pace and high quality.
On this weblog, we’ll stroll you thru you tips on how to:
- Arrange Llama 3.1-70B within the DataRobot LLM Playground.
- Generate and apply an API key to leverage Cerebras for inference.
- Customise and deploy smarter, quicker purposes.
By the top, you’ll be able to deploy LLMs that ship pace, precision, and real-time responsiveness.
Prototype, customise, and check LLMs in a single place
Prototyping and testing generative AI fashions typically require a patchwork of disconnected instruments. However with a unified, built-in setting for LLMs, retrieval strategies, and analysis metrics, you’ll be able to transfer from thought to working prototype quicker and with fewer roadblocks.
This streamlined course of means you’ll be able to give attention to constructing efficient, high-impact AI purposes with out the effort of piecing collectively instruments from completely different platforms.
Let’s stroll by way of a use case to see how one can leverage these capabilities to develop smarter, quicker AI purposes.
Use case: Rushing up LLM interference with out sacrificing high quality
Low latency is important for constructing quick, responsive AI purposes. However accelerated responses don’t have to return at the price of high quality.
The pace of Cerebras Inference outperforms different platforms, enabling builders to construct purposes that really feel easy, responsive, and clever.
When mixed with an intuitive growth expertise, you’ll be able to:
- Cut back LLM latency for quicker consumer interactions.
- Experiment extra effectively with new fashions and workflows.
- Deploy purposes that reply immediately to consumer actions.
The diagrams under present Cerebras’ efficiency on Llama 3.1-70B, illustrating quicker response occasions and decrease latency than different platforms. This permits fast iteration throughout growth and real-time efficiency in manufacturing.
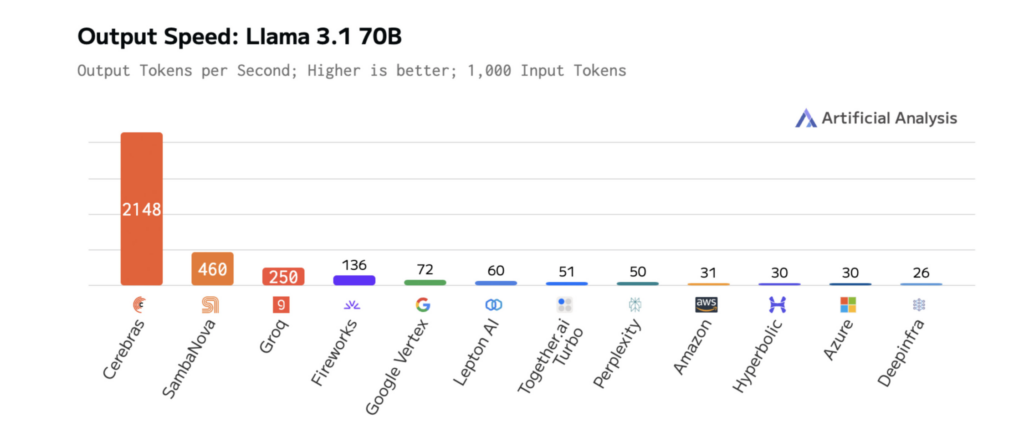
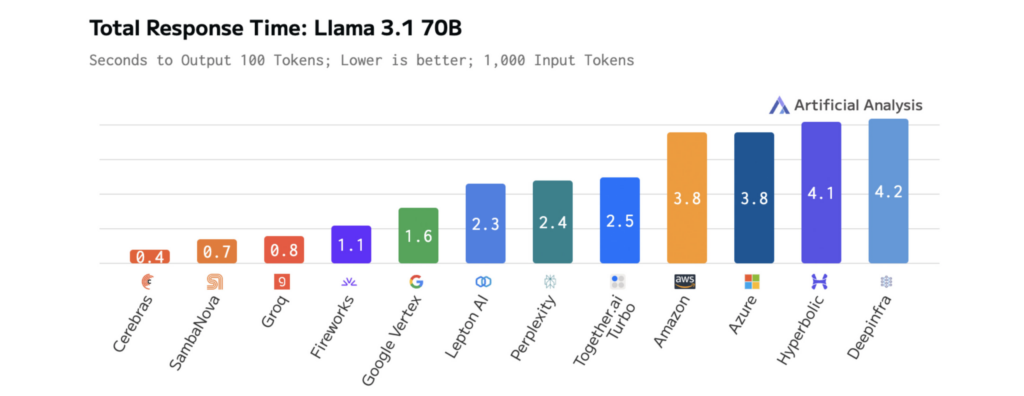
How mannequin dimension impacts LLM pace and efficiency
As LLMs develop bigger and extra complicated, their outputs develop into extra related and complete — however this comes at a value: elevated latency. Cerebras tackles this problem with optimized computations, streamlined information switch, and clever decoding designed for pace.
These pace enhancements are already reworking AI purposes in industries like prescribed drugs and voice AI. For instance:
- GlaxoSmithKline (GSK) makes use of Cerebras Inference to speed up drug discovery, driving increased productiveness.
- LiveKit has boosted the efficiency of ChatGPT’s voice mode pipeline, reaching quicker response occasions than conventional inference options.
The outcomes are measurable. On Llama 3.1-70B, Cerebras delivers 70x quicker inference than vanilla GPUs, enabling smoother, real-time interactions and quicker experimentation cycles.
This efficiency is powered by Cerebras’ third-generation Wafer-Scale Engine (WSE-3), a customized processor designed to optimize the tensor-based, sparse linear algebra operations that drive LLM inference.
By prioritizing efficiency, effectivity, and adaptability, the WSE-3 ensures quicker, extra constant outcomes throughout mannequin efficiency.
Cerebras Inference’s pace reduces the latency of AI purposes powered by their fashions, enabling deeper reasoning and extra responsive consumer experiences. Accessing these optimized fashions is easy — they’re hosted on Cerebras and accessible through a single endpoint, so you can begin leveraging them with minimal setup.

Step-by-step: The best way to customise and deploy Llama 3.1-70B for low-latency AI
Integrating LLMs like Llama 3.1-70B from Cerebras into DataRobot permits you to customise, check, and deploy AI fashions in only a few steps. This course of helps quicker growth, interactive testing, and higher management over LLM customization.
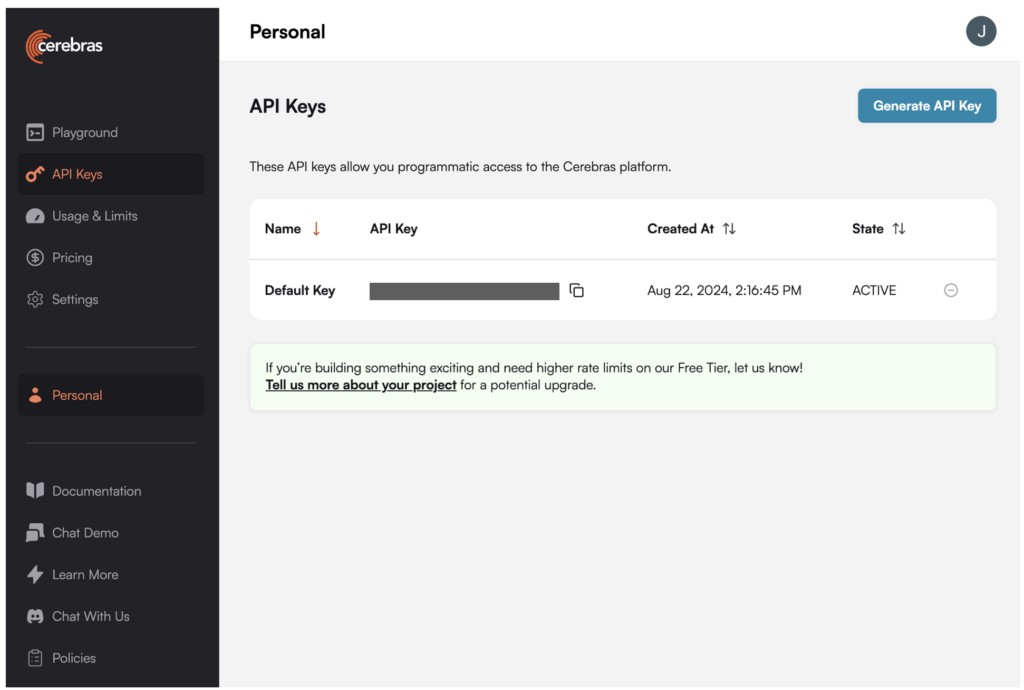
1. Generate an API key for Llama 3.1-70B within the Cerebras platform.
2. In DataRobot, create a customized mannequin within the Mannequin Workshop that calls out to the Cerebras endpoint the place Llama 3.1 70B is hosted.
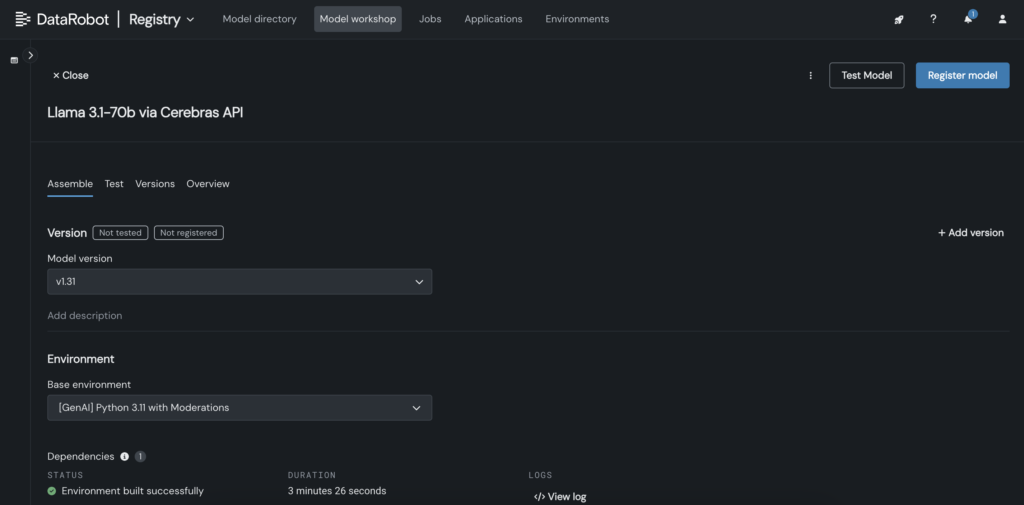
3. Throughout the customized mannequin, place the Cerebras API key throughout the customized.py file.
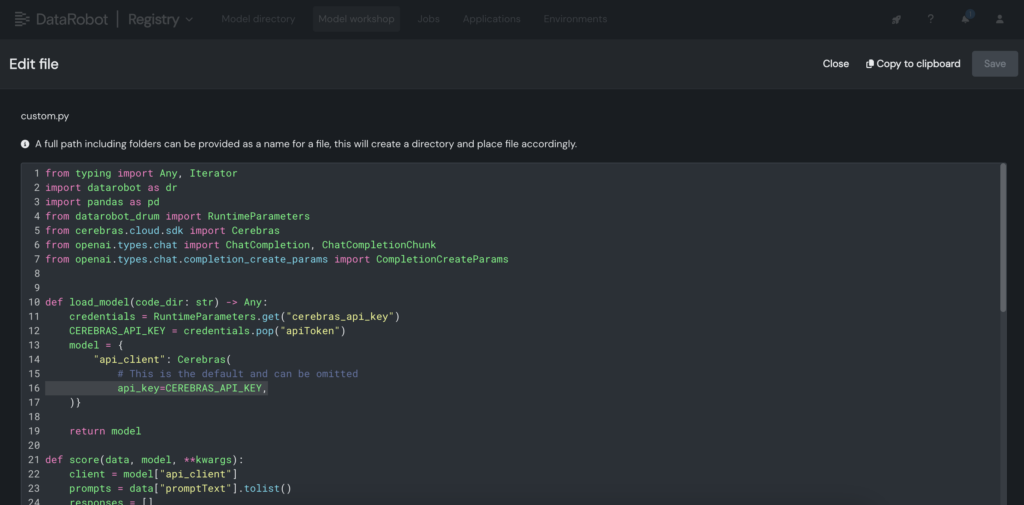
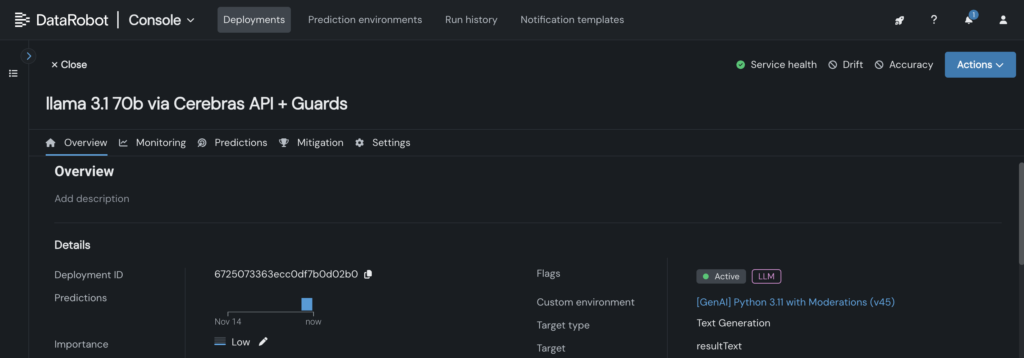
4. Deploy the customized mannequin to an endpoint within the DataRobot Console, enabling LLM blueprints to leverage it for inference.
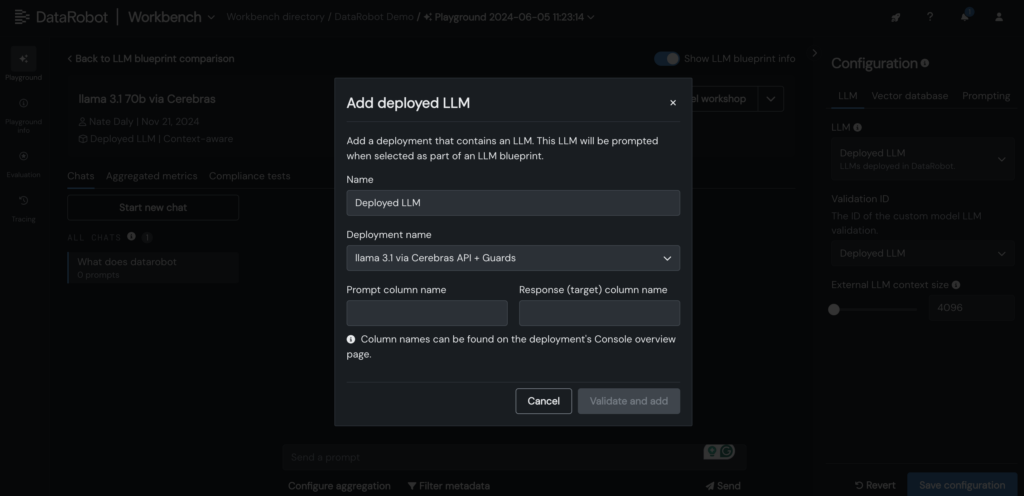
5. Add your deployed Cerebras LLM to the LLM blueprint within the DataRobot LLM Playground to start out chatting with Llama 3.1 -70B.
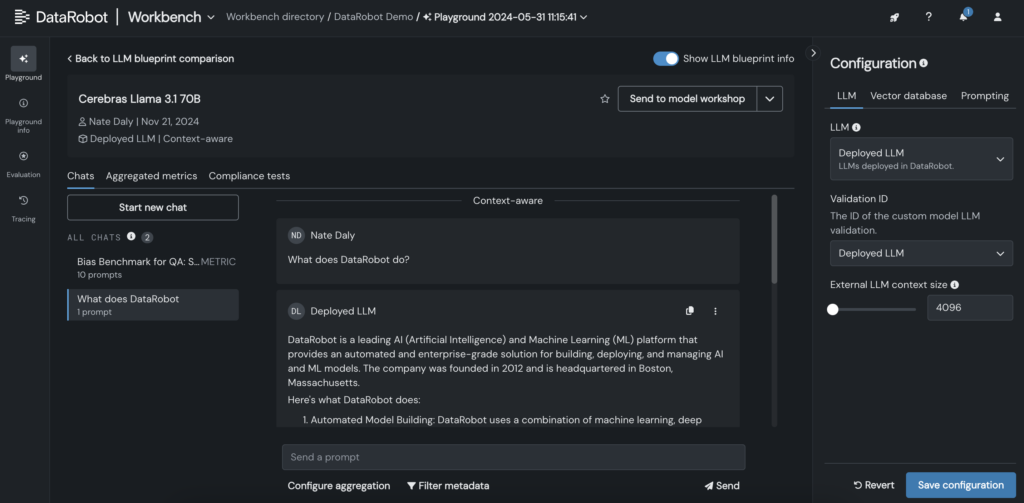
6. As soon as the LLM is added to the blueprint, check responses by adjusting prompting and retrieval parameters, and evaluate outputs with different LLMs immediately within the DataRobot GUI.
Increase the bounds of LLM inference on your AI purposes
Deploying LLMs like Llama 3.1-70B with low latency and real-time responsiveness isn’t any small job. However with the precise instruments and workflows, you’ll be able to obtain each.
By integrating LLMs into DataRobot’s LLM Playground and leveraging Cerebras’ optimized inference, you’ll be able to simplify customization, pace up testing, and cut back complexity – all whereas sustaining the efficiency your customers count on.
As LLMs develop bigger and extra highly effective, having a streamlined course of for testing, customization, and integration, will likely be important for groups trying to keep forward.
Discover it your self. Entry Cerebras Inference, generate your API key, and begin constructing AI purposes in DataRobot.
Concerning the creator

Kumar Venkateswar is VP of Product, Platform and Ecosystem at DataRobot. He leads product administration for DataRobot’s foundational companies and ecosystem partnerships, bridging the gaps between environment friendly infrastructure and integrations that maximize AI outcomes. Previous to DataRobot, Kumar labored at Amazon and Microsoft, together with main product administration groups for Amazon SageMaker and Amazon Q Enterprise.

Nathaniel Daly is a Senior Product Supervisor at DataRobot specializing in AutoML and time sequence merchandise. He’s targeted on bringing advances in information science to customers such that they will leverage this worth to unravel actual world enterprise issues. He holds a level in Arithmetic from College of California, Berkeley.