Have you ever ever thought of find out how to consider AI textual content analysis successfully? Whether or not it’s textual content summarization, chatbot responses, or machine translation, we want a method to check AI outcomes to human expectations. That is the place METEOR is available in helpful!
METEOR (Metric for Analysis of Translation with Specific Ordering) is a strong analysis metric designed to evaluate the accuracy and fluency of machine-generated textual content. It takes phrase order, stemming, and synonyms under consideration, in contrast to extra conventional approaches like BLEU. Intrigued? Let’s dive in!
Studying Targets
- Perceive how AI textual content analysis works and the way METEOR improves accuracy by contemplating phrase order, stemming, and synonyms.
- Study the benefits of METEOR over conventional metrics in AI textual content analysis, together with its means to align higher with human judgment.
- Discover the method and key parts of METEOR, together with precision, recall, and penalty.
- Acquire hands-on expertise implementing METEOR in Python utilizing the NLTK library.
- Examine METEOR with different analysis metrics to find out its strengths and limitations in NLP duties.
What’s a METEOR Rating?
METEOR (Metric for Analysis of Translation with Specific Ordering) is an NLP analysis metric initially designed for machine translation however now extensively used for evaluating numerous pure language technology duties, together with these carried out by Massive Language Fashions (LLMs).
In contrast to less complicated metrics that focus solely on actual phrase matches, METEOR was developed to deal with the restrictions of different metrics by incorporating semantic similarities and alignment between a machine-generated textual content and its reference textual content(s).
Fast Examine: Consider METEOR as a classy decide that doesn’t simply depend matching phrases however understands when totally different phrases imply related issues!
How Does METEOR Work?
METEOR evaluates textual content high quality via a step-by-step course of:

- Alignment: First, METEOR creates an alignment between the phrases within the generated textual content and reference textual content(s).
- Matching: It identifies matches primarily based on:
- Actual matches (an identical phrases)
- Stem matches (phrases with the identical root)
- Synonym matches (phrases with related meanings)
- Paraphrase matches (phrases with related meanings)
- Scoring: METEOR calculates precision, recall, and a weighted F-score.
- Penalty: It applies a fragmentation penalty to account for phrase order and fluency.
- Remaining Rating: The ultimate METEOR rating combines the F-score and penalty.

It improves upon older strategies by incorporating:
- Precision & Recall: Ensures a steadiness between correctness and protection.
- Synonyms Matching: Identifies phrases with related meanings.
- Stemming: Acknowledges phrases in several kinds (e.g., “run” vs. “working”).
- Phrase Order Penalty: Penalizes incorrect phrase sequence whereas permitting slight flexibility.
Strive It Your self: Contemplate these two translations of a French sentence:
- Reference: “The cat is sitting on the mat.”
- Translation A: “The feline is sitting on the mat.”
- Translation B: “Mat the one sitting is cat the.”
Which do you assume would get a better METEOR rating? (Translation A would rating greater as a result of whereas it makes use of a synonym, the order is preserved. Translation B has all the correct phrases however in a totally jumbled order, triggering a excessive fragmentation penalty.)
Key Options of METEOR
METEOR stands out from different analysis metrics with these distinctive traits:
- Semantic Matching: Goes past actual matches to acknowledge synonyms and paraphrases
- Phrase Order Consideration: Penalizes incorrect phrase ordering
- Weighted Harmonic Imply: Balances precision and recall with adjustable weights
- Language Adaptability: Might be configured for various languages
- A number of References: Can consider towards a number of reference texts

Why It Issues: These options make METEOR notably invaluable for evaluating artistic textual content technology duties the place there are a lot of legitimate methods to precise the identical thought.
Components of METEOR Rating and Rationalization
The METEOR rating is calculated utilizing the next method:
METEOR = (1 – Penalty) × F_mean
The place:
F_mean is the weighted harmonic imply of precision and recall:

- P (Precision) = Variety of matched phrases within the candidate / Whole phrases in candidate
- R (Recall) = Variety of matched phrases within the candidate / Whole phrases in reference
Penalty accounts for fragmentation:
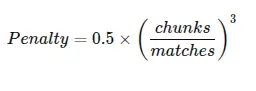
- chunks is the entire variety of chunks
- matched_chunks is the entire variety of matched phrases
Analysis of METEOR Metric
METEOR has been extensively evaluated towards human judgments:

- Correlation with Human Judgment: Research present METEOR correlates higher with human evaluations in comparison with metrics like BLEU, notably for evaluating fluency and adequacy.
- Efficiency Throughout Languages: METEOR performs constantly throughout totally different languages, particularly when language-specific assets (like WordNet for English) can be found.
- Robustness: METEOR exhibits higher stability when evaluating shorter texts in comparison with n-gram primarily based metrics.
Analysis Discovering: In research evaluating numerous metrics, METEOR usually achieves correlation coefficients with human judgments within the vary of 0.60-0.75, outperforming BLEU which normally scores within the 0.45-0.60 vary.
Methods to Implement METEOR in Python?
Implementing METEOR is easy utilizing the NLTK library in Python:
Step1: Set up Required Libraries
Under we are going to first set up all required libraries.
pip set up nltkStep2: Obtain Required NLTK Sources
Subsequent we are going to obtain required NLTK assets.
import nltk
nltk.obtain('wordnet')
nltk.obtain('omw-1.4')Instance Code
Right here’s a complete instance displaying find out how to calculate METEOR scores in Python:
import nltk
from nltk.translate.meteor_score import meteor_score
# Guarantee required assets are downloaded
nltk.obtain('wordnet', quiet=True)
nltk.obtain('omw-1.4', quiet=True)
# Outline reference and speculation texts
reference = "The short brown fox jumps over the lazy canine."
hypothesis_1 = "The quick brown fox jumps over the lazy canine."
hypothesis_2 = "Brown fast the fox jumps over the canine lazy."
# Calculate METEOR scores
score_1 = meteor_score([reference.split()], hypothesis_1.break up())
score_2 = meteor_score([reference.split()], hypothesis_2.break up())
print(f"Reference: {reference}")
print(f"Speculation 1: {hypothesis_1}")
print(f"METEOR Rating 1: {score_1:.4f}")
print(f"Speculation 2: {hypothesis_2}")
print(f"METEOR Rating 2: {score_2:.4f}")
# Instance with a number of references
references = [
"The quick brown fox jumps over the lazy dog.",
"A swift brown fox leaps above the sleepy hound."
]
speculation = "The quick brown fox jumps over the sleepy canine."
# Convert strings to lists of tokens
references_tokenized = [ref.split() for ref in references]
hypothesis_tokenized = speculation.break up()
# Calculate METEOR rating with a number of references
multi_ref_score = meteor_score(references_tokenized, hypothesis_tokenized)
print("nMultiple References Instance:")
print(f"References: {references}")
print(f"Speculation: {speculation}")
print(f"METEOR Rating: {multi_ref_score:.4f}")Instance Output:
Reference: The short brown fox jumps over the lazy canine.
Speculation 1: The quick brown fox jumps over the lazy canine.
METEOR Rating 1: 0.9993
Speculation 2: Brown fast the fox jumps over the canine lazy.
METEOR Rating 2: 0.7052A number of References Instance:
References: ['The quick brown fox jumps over the lazy dog.', 'A swift brown fox leaps above the sleepy hound.']
Speculation: The quick brown fox jumps over the sleepy canine.
METEOR Rating: 0.8819
Problem for you: Strive modifying the hypotheses in numerous methods to see how the METEOR rating modifications. What occurs in case you exchange phrases with synonyms? What in case you fully rearrange the phrase order?
Benefits of the METEOR Rating
METEOR gives a number of benefits over different metrics:
- Semantic Understanding: Acknowledges synonyms and paraphrases, not simply actual matches
- Phrase Order Sensitivity: Considers fluency via its fragmentation penalty
- Balanced Analysis: Combines precision and recall in a weighted method
- Linguistic Sources: Leverages language assets like WordNet
- A number of References: Can consider towards a number of reference translations
- Language Flexibility: Adaptable to totally different languages with applicable assets
- Interpretability: Parts (precision, recall, penalty) could be analyzed individually
Finest For: Advanced analysis eventualities the place semantic equivalence issues greater than actual wording.
Limitations of the METEOR Rating
Regardless of its strengths, METEOR has some limitations:
- Useful resource Dependency: Requires linguistic assets (like WordNet) which will not be equally obtainable for all languages
- Computational Overhead: Extra computationally intensive than less complicated metrics like BLEU
- Parameter Tuning: Optimum parameter settings could differ throughout languages and duties
- Restricted Context Understanding: Nonetheless doesn’t totally seize contextual which means past phrase stage
- Area Sensitivity: Efficiency could differ throughout totally different textual content domains
- Size Bias: Could favor sure textual content lengths in some implementations
Contemplate This: When evaluating specialised technical content material, METEOR may not acknowledge domain-specific equivalences except supplemented with specialised dictionaries.
Sensible Purposes of METEOR Rating
METEOR finds utility in numerous pure language processing duties:
- Machine Translation Analysis: Its unique function, evaluating translations throughout languages
- Summarization Evaluation: Evaluating the standard of automated textual content summaries
- LLM Output Analysis: Measuring the standard of textual content generated by language fashions
- Paraphrasing Programs: Evaluating automated paraphrasing instruments
- Picture Captioning: Assessing the standard of robotically generated picture descriptions
- Dialogue Programs: Evaluating responses in conversational AI
Actual-World Instance: The WMT (Workshop on Machine Translation) competitions have used METEOR as one in every of their official analysis metrics, influencing the event of economic translation programs.
How Does METEOR Examine to Different Metrics?
Let’s evaluate METEOR with different in style analysis metrics:
| Metric | Strengths | Weaknesses | Finest For |
| METEOR | Semantic matching, phrase order sensitivity | Useful resource dependency, computational value | Duties the place which means preservation is important |
| BLEU | Simplicity, language-independence | Ignores synonyms, poor for single sentences | Excessive-level system comparisons |
| ROUGE | Good for summarization, easy to implement | Focuses on recall, restricted semantic understanding | Summarization duties |
| BERTScore | Contextual embeddings, robust correlation with people | Computationally costly, advanced | Nuanced semantic analysis |
| ChrF | Character-level matching, good for morphologically wealthy languages | Restricted semantic understanding | Languages with advanced phrase kinds |
Select METEOR when evaluating artistic textual content the place there are a number of legitimate methods to precise the identical which means, and when reference texts can be found.
Conclusion
METEOR represents a big development in pure language technology analysis by addressing many limitations of less complicated metrics. Its means to acknowledge semantic similarities, account for phrase order, and steadiness precision and recall makes it notably invaluable for evaluating LLM outputs the place actual phrase matches are much less essential than preserving which means.
As language fashions proceed to evolve, analysis metrics like METEOR will play a vital function in guiding their growth and assessing their efficiency. Whereas not excellent, METEOR’s method to analysis aligns properly with how people decide textual content high quality, making it a invaluable instrument within the NLP practitioner’s toolkit.
For duties the place semantic equivalence issues greater than actual wording, METEOR supplies a extra nuanced analysis than less complicated n-gram primarily based metrics, serving to researchers and builders create extra pure and efficient language technology programs.
Key Takeaways
- METEOR enhances AI textual content analysis by contemplating phrase order, stemming, and synonyms, providing a extra human-aligned evaluation.
- In contrast to conventional metrics, AI textual content analysis with METEOR supplies higher accuracy by incorporating semantic matching and versatile scoring.
- METEOR performs properly throughout languages and a number of NLP duties, together with machine translation, summarization, and chatbot analysis.
- Implementing METEOR in Python is easy utilizing the NLTK library, permitting builders to evaluate textual content high quality successfully.
- In comparison with BLEU and ROUGE, METEOR gives higher semantic understanding however requires linguistic assets like WordNet.
Ceaselessly Requested Questions
A. METEOR (Metric for Analysis of Translation with Specific ORdering) is an analysis metric designed to evaluate the standard of machine-generated textual content by contemplating phrase order, stemming, synonyms, and paraphrases.
A. In contrast to BLEU, which depends on actual phrase matches and n-grams, METEOR incorporates semantic understanding by recognizing synonyms, stemming, and paraphrasing, making it extra aligned with human evaluations.
A. METEOR accounts for fluency, coherence, and which means preservation by penalizing incorrect phrase ordering and rewarding semantic similarity, making it a extra human-like analysis methodology than less complicated metrics.
A. Sure, METEOR is extensively used for evaluating summarization, chatbot responses, paraphrasing, picture captioning, and different pure language technology duties.
A. Sure, METEOR can consider a candidate textual content towards a number of references, bettering the accuracy of its evaluation by contemplating totally different legitimate expressions of the identical thought.
Gen AI Intern at Analytics Vidhya
Division of Laptop Science, Vellore Institute of Expertise, Vellore, India
I’m at present working as a Gen AI Intern at Analytics Vidhya, the place I contribute to revolutionary AI-driven options that empower companies to leverage knowledge successfully. As a final-year Laptop Science pupil at Vellore Institute of Expertise, I deliver a stable basis in software program growth, knowledge analytics, and machine studying to my function.
Be happy to attach with me at [email protected]
Login to proceed studying and revel in expert-curated content material.