Introduction
Think about that you’re about to supply a Python bundle that has the potential to fully rework the best way builders and knowledge analysts assess their fashions. The journey begins with an easy idea: a versatile RAG analysis device that may handle quite a lot of metrics and edge circumstances. You’ll go from initializing your bundle with poetry to making a stable evaluator class and testing your code as you dive into this put up. You’re going to get data on how you can create your bundle, calculate BLEU and ROUGE scores, and put up it on-line. By the tip, you’ll have gained extra perception into Python packaging and open-source contributions along with having a working device that’s prepared for utilization by most people.
Studying Outcomes
- Study to initialize and construction a Python bundle utilizing poetry.
- Develop and implement an evaluator class for a number of metrics.
- Calculate and consider metrics similar to BLEU and ROUGE scores.
- Write and execute checks to make sure code performance and robustness.
- Construct and publish a Python bundle to PyPI, together with dealing with distributions and licensing.
This text was revealed as part of the Information Science Blogathon.
Initializing Your Package deal with Poetry
Now that we have now the necessities we will begin by initializing a brand new python bundle utilizing poetry. The rationale for selecting poetry is:
- It removes the necessity for managing a number of digital environments.
- It helps all forms of python bundle codecs, each native and legacy packages.
- It ensures the suitable model even for the dependencies by means of the `poetry.lock` file.
- Pypi prepared with a single command.
Set up poetry utilizing the command for nearly all of the OS:
curl -sSL https://set up.python-poetry.org | python3 -Then we will create a brand new repository with the boilerplate utilizing the next command.
poetry new package_nameThere might be few generic questions for which you’ll be able to press the enter and depart it as default. Then you’ll land in a folder construction just like this.
poetry-demo
├── pyproject.toml
├── README.md
├── poetry_demo
│ └── __init__.py
└── checks
└── __init__.pyAlthough the construction is simply nice, we will use the `src` format in comparison with the `flat` format as mentioned within the official Python documentation. We will be following the `src` format in the remainder of the weblog.
Designing the Core Evaluator Class
The center of our bundle accommodates all of the supply code to energy the Python evaluator bundle. It accommodates the bottom class that’s going to be inherited by all of the metrics that we want to have. So this class must be essentially the most sturdy and utmost care have to be taken throughout building. This class may have the mandatory logic wanted for fundamental initialization, a way to get the outcome from the metric, and one other methodology(s) for dealing with person enter to be readily consumable.
All these strategies will need to have their very own scope and correct knowledge sorts outlined. The rationale to focus extra on the info sorts is as a result of Python is dynamically typed. Therefore, we should guarantee the right use of variables as these trigger errors solely at runtime. So there have to be check suites to catch these minute errors, quite than utilizing a devoted type-checking compiler. Effectively and good if we use correct typing in Python.
Defining Evaluator Class
Now that we noticed what all of the evaluator class should comprise and why it’s crucial we’re left with the implementation of the identical. For constructing this class we’re inheriting the ABC – Summary Base Class offered by python. The rationale for selecting this class is that it accommodates all of the concrete options upon which we will construct our evaluator base class. Now let’s outline the inputs and outputs of the evaluator class.
- Inputs: Candidates[list of string], References[list of string]
- Strategies: `padding` (to make sure the size of candidates and references are the identical), `get_score` (methodology to calculate the ultimate results of the analysis metrics)
# src/evaluator_blog/evaluator.py
import warnings
from typing import Union, Record
from abc import ABC, abstractmethod
class BaseEvaluator(ABC):
def __init__(self, candidates: Record, references: Record) -> None:
self.candidates = candidates
self.references = references
@staticmethod
def padding(
candidates: Record[str], references: Record[str]
) -> Union[List[str], Record[str]]:
"""_summary_
Args:
candidates (Record[str]): The response generated from the LLM
references (Record[str]): The response to be measured towards
Returns:
Union[List[str], Record[str]]: Ensures equal size of `candidates` and `references`
"""
_msg = str(
"""
The size of references and candidates (speculation) should not similar.
"""
)
warnings.warn(_msg)
max_length = max(len(candidates), len(references))
candidates.prolong([""] * (max_length - len(candidates)))
references.prolong([""] * (max_length - len(references)))
return candidates, references
@staticmethod
def list_to_string(l: Record) -> str:
assert (
len(l) >= 1
), "Make sure the size of the message is bigger than or equal to 1"
return str(l[0])
@abstractmethod
def get_score(self) -> float:
"""
Technique to calculate the ultimate results of the rating operate.
Returns:
Floating level worth of the chosen analysis metric.
"""Right here we will discover that the `__init()__` methodology accommodates the parameters required that’s the fundamental requirement for any evaluator metric i.e. candidates and references.
Then the padding required to make sure each the `candidates` and `references` comprise the identical size outlined because the static methodology as a result of we don’t must initialize this everytime we name. Subsequently, the staticmethod decorator accommodates the required logic.
Lastly, for the `get_score()` we use abstractmethod decorator which means all of the courses that inherit the bottom evaluator class should undoubtedly comprise this methodology.
Implementing Analysis Metrics
Now comes the center of the implementation of the library, the analysis of the metrics. At the moment for the calculation we make use of respective libraries that carry out the duty and show the metric rating. We primarily use `candidates` i.e. the LLM generated response and `references` i.e. the bottom fact and we calculate the worth respectively. For simplicity we calculate the BLEU and Rouge rating. This logic is extensible to all of the metrics obtainable available in the market.
Calculating BLEU Scores
Abbreviated as Bilingual Analysis Understudy is without doubt one of the widespread analysis metrics of machine translation(candidates) that’s fast, cheap, and language-independent. It has marginal errors compared to guide analysis. It compares the closeness of machine translation to the skilled human responses(references) and returns the analysis as a metric rating within the vary of 0-1, with something in the direction of 1 being termed as an in depth match. They think about n-gram(s) (chunks of n phrases) in a sentence from candidates. Eg. unigrams (1 gram) considers each phrase from candidates and references and return the normalized rating termed because the precision rating.
But it surely doesn’t all the time work nicely contemplating if the identical phrase seems a number of instances it accounts for the ultimate rating for every look which usually is inaccurate. Subsequently BLEU makes use of a modified precision rating the place it clips the variety of phrase matches and normalizes it with the variety of phrases within the candidate. One other catch right here is it doesn’t take the phrase ordering under consideration. Subsequently bleu rating considers a number of n-grams and shows the precision scores of 1-4 grams with different parameters.
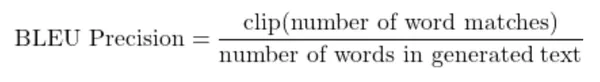

Benefits
- Sooner computation and easy calculations concerned.
- Extensively used and straightforward to benchmark outcomes.
Disadvantages
- Doesn’t think about the which means of translation.
- Doesn’t consider the sentence format.
- Although it’s bilingual, it struggles with non-english languages.
- Onerous to compute scores when human translations are already tokenized.
# src/evaluator_blog/metrics/bleu.py
from typing import Record, Callable, Elective
from src.evaluator_blog.evaluator import BaseEvaluator
from nltk.translate.bleu_score import corpus_bleu, SmoothingFunction
"""
BLEU implementation from NLTK
"""
class BLEUScore(BaseEvaluator):
def __init__(
self,
candidates: Record[str],
references: Record[str],
weights: Elective[List[float]] = None,
smoothing_function: Elective[Callable] = None,
auto_reweigh: Elective[bool] = False,
) -> None:
"""
Calculate BLEU rating (Bilingual Analysis Understudy) from
Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002.
"BLEU: a way for automated analysis of machine translation."
In Proceedings of ACL. https://aclanthology.org/P02-1040.pdf
Args:
weights (Elective[List[float]], elective): The weights that have to be utilized to every bleu_score. Defaults to None.
smoothing_function (Elective[Callable], elective): A callable operate to beat the issue of the sparsity of coaching knowledge by including or adjusting the chance mass distribution of phrases. Defaults to None.
auto_reweigh (Elective[bool], elective): Uniformly re-weighting primarily based on most speculation lengths if largest order of n-grams < 4 and weights is ready at default. Defaults to False.
"""
tremendous().__init__(candidates, references)
# Verify if `weights` is offered
if weights is None:
self.weights = [1, 0, 0, 0]
else:
self.weights = weights
# Verify if `smoothing_function` is offered
# If `None` defaulted to method0
if smoothing_function is None:
self.smoothing_function = SmoothingFunction().method0
else:
self.smoothing_function = smoothing_function
# If `auto_reweigh` allow it
self.auto_reweigh = auto_reweigh
def get_score(
self,
) -> float:
"""
Calculate the BLEU rating for the given candidates and references.
Args:
candidates (Record[str]): Record of candidate sentences
references (Record[str]): Record of reference sentences
weights (Elective[List[float]], elective): Weights for BLEU rating calculation. Defaults to (1.0, 0, 0, 0)
smoothing_function (Elective[function]): Smoothing method to for segment-level BLEU scores
Returns:
float: The calculated BLEU rating.
"""
# Verify if the size of candidates and references are equal
if len(self.candidates) != len(self.references):
self.candidates, self.references = self.padding(
self.candidates, self.references
)
# Calculate the BLEU rating
return corpus_bleu(
list_of_references=self.references,
hypotheses=self.candidates,
weights=self.weights,
smoothing_function=self.smoothing_function,
auto_reweigh=self.auto_reweigh,
)Measuring ROUGE Scores
Abbreviated as Recall Oriented Understudy for Gisting Analysis is without doubt one of the widespread analysis metrics for evaluating model-generated summaries with a number of human summaries. In a naive approach, it compares the n-grams of each the machine and human-generated abstract. That is referred to as the Rouge-n recall rating. To make sure extra relevancy in machine generated abstract to the human abstract we will calculate the precision rating. As we have now each precision and recall scores we will calculate the f1-score. It’s usually really helpful to think about a number of values of `n`. A small variant in rouge is the rouge-l rating which considers the sequence of phrases and computes the LCS (longest widespread subsequence). In the identical approach, we will get the precision and recall rating. A slight benefit right here is it considers the molecularity of the sentence and produces related outcomes.

Benefits
- Extremely efficient for evaluating the standard of automated textual content summarization by evaluating n-grams and longest widespread subsequences.
- ROUGE will be utilized to any language, making it versatile for multilingual textual content evaluation and analysis.
Disadvantages
- ROUGE focuses on surface-level textual content matching (n-grams), which could not seize deeper semantic which means and coherence.
- The accuracy of ROUGE closely depends upon the standard and representativeness of the reference summaries
# src/evaluator_blog/metrics/rouge.py
import warnings
from typing import Record, Union, Dict, Callable, Tuple, Elective
from ..evaluator import BaseEvaluator
from rouge_score import rouge_scorer
class RougeScore(BaseEvaluator):
def __init__(
self,
candidates: Record,
references: Record,
rouge_types: Elective[Union[str, Tuple[str]]] = [
"rouge1",
"rouge2",
"rougeL",
"rougeLsum",
],
use_stemmer: Elective[bool] = False,
split_summaries: Elective[bool] = False,
tokenizer: Elective[Callable] = None,
) -> None:
tremendous().__init__(candidates, references)
# Default `rouge_types` is all, else the person specified
if isinstance(rouge_types, str):
self.rouge_types = [rouge_types]
else:
self.rouge_types = rouge_types
# Allow `use_stemmer` to take away phrase suffixes to enhance matching functionality
self.use_stemmer = use_stemmer
# If enabled checks whether or not so as to add newlines between sentences for `rougeLsum`
self.split_summaries = split_summaries
# Allow `tokenizer` if person outlined or else use the `rouge_scorer` default
# https://github.com/google-research/google-research/blob/grasp/rouge/rouge_scorer.py#L83
if tokenizer:
self.tokenizer = tokenizer
else:
self.tokenizer = None
_msg = str(
"""
Using the default tokenizer
"""
)
warnings.warn(_msg)
def get_score(self) -> Dict:
"""
Returns:
Dict: JSON worth of the analysis for the corresponding metric
"""
scorer = rouge_scorer.RougeScorer(
rouge_types=self.rouge_types,
use_stemmer=self.use_stemmer,
tokenizer=self.tokenizer,
split_summaries=self.split_summaries,
)
return scorer.rating(self.list_to_string(self.candidates), self.list_to_string(self.references))
Testing Your Package deal
Now that we have now the supply file prepared earlier than the precise utilization we should confirm the working of the code. That’s the place the testing part comes into the image. In Python library format/conference/finest follow, we write all of the checks underneath the folder named `checks/`. This naming conference makes it straightforward for builders to grasp that this folder has its significance. Although we have now a number of improvement instruments we will prohibit the library utilizing sort checking, error dealing with, and way more. This caters to the primary spherical of checking and testing. However to make sure edge instances and exceptions, we will use unittest, and pytest because the go-to frameworks. With that being mentioned we simply go along with establishing the essential checks utilizing the `unittest` library.
Writing Efficient Unit Assessments
The important thing phrases to know with respect to `unittest` is the check case and check suite.
- Take a look at case: Smallest unit of testing the place we consider the inputs towards a set of outputs.
- Take a look at suite: A set of check instances, suites or each. Used to mixture checks to work collectively.
- Naming conference: This have to be prefixed with `tests_` to the file title in addition to the operate title. The reason being the parser will detect them and add them to the check suite.
Construct the wheel
Wheel is mainly a python bundle i.e. put in once we run the command `pip set up <package_name>`. The contents of the wheel are saved within the ‘.whl’ file. The wheel file is saved at `dist/`. There’s a constructed distribution `.whl` and the supply distribution `.gz`. Since we’re utilizing poetry we will construct the distribution utilizing the construct command:
poetry constructIt generates the wheel and zip file contained in the `dist/` folder within the root of the folder.
dist/
├── package_name-0.0.1-py3-none-any.whl
└── package_name-0.0.1.tar.gz
Aliter, The equal python command is putting in the `construct` bundle after which working the construct command from the foundation of the folder.
python3 -m pip set up --upgrade construct
python3 -m constructCreating Supply and Binary Distributions
Allow us to now look in to creating supply and binary distributions.
Supply Distribution (sdist)
`sdist` is the supply distribution of the bundle that accommodates supply code and metadata to construct from exterior instruments like pip or poetry. `sdist` is required to be constructed earlier than `bdist`. If `pip` doesn’t discover the construct distribution, the supply distribution acts as a fallback. Then it builds a wheel out of it after which installs the bundle necessities.
Binary Distribution (bdist)
`bdist` accommodates the mandatory recordsdata that must be moved to the proper location of the goal system. Among the finest-supported codecs is `.whl`. Level to be famous it doesn’t have compiled python recordsdata.
License
Whereas open-sourcing the bundle to the exterior world it’s all the time advisable to have a license that reveals the extent to which your code will be reused. Whereas making a repository in GitHub we have now the choice to pick the license there. It creates a `LICENSE` file with utilization choices. In case you are not sure which license to decide on then this exterior useful resource is an ideal one to the rescue.

Publish the Package deal
Now that we have now all the necessities we have to publish the bundle to the exterior world. So we’re utilizing the publish command which abstracts all of the steps with a single command.
check.pypi.org
In case you are not sure how the bundle would carry out or for testing functions it’s suggested to publish to a check.pypi.org quite than straight importing to the official repository. This provides us the flexibleness to check the bundle earlier than sharing it with everybody.
pypi.org
The official Python bundle accommodates all of the personal and public software program revealed by the Python neighborhood. It’s helpful for authors and organizations to share their packages by means of an official central repository. All that it takes to publish your bundle to the world is that this single command.
poetry publish --build --username $PYPI_USERNAME --password $PYPI_PASSWORDConclusion
By the tip of this text, you will have efficiently revealed a Python bundle that’s prepared for use by hundreds of thousands. We’ve initialized a brand new bundle utilizing poetry, labored on the use case, wrote the checks, constructed the bundle, and revealed them to the Pypi repository. This can add extra worth for your self and likewise allow you to to grasp the assorted open-source Python bundle repositories on how they’re structured. Final however not least, that is just the start and we will make it as extensible as potential. We will consult with the open-source Python packages and distributions, and get inspiration from the identical.
Key Takeaways
- Grasp Python bundle creation and administration with poetry.
- Implement and customise analysis metrics for various use instances.
- Construct and check sturdy Python packages with unit testing frameworks.
- Publish your bundle to PyPI and perceive distribution codecs.
- Achieve insights into open-source bundle improvement and licensing practices.
Regularly Requested Questions
A. The article helps you create and publish a Python bundle, specializing in a RAG evaluator device that can be utilized by the neighborhood for varied analysis metrics.
A. Poetry simplifies dependency administration and packaging by integrating model management, digital environments, and publishing duties right into a single device, making improvement and distribution simpler.
A. The article particulars how you can calculate BLEU and ROUGE scores, that are generally used metrics for assessing the standard of machine-generated textual content compared to reference texts.
A. You possibly can check your bundle utilizing frameworks like unittest or pytest to make sure the code works as anticipated and handles edge instances, offering confidence earlier than publishing.
A. Construct your bundle utilizing poetry or construct, check it on check.pypi.org, after which publish it to the official pypi.org repository utilizing the poetry publish command to make it obtainable to the general public.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Creator’s discretion.