
Superb Generative AI vs. Actuality
Foundational LLMs have learn each byte of textual content they might discover and their chatbot counterparts could be prompted to have clever conversations and be requested to carry out particular duties. Entry to complete data is democratized; No extra determining the fitting key phrases to look or choosing websites to learn from. Nonetheless, LLMs are liable to rambling and usually reply with the statistically most possible response you’d wish to hear (sycophancy) an inherent results of the transformer mannequin. Extracting 100% correct data out of an LLM’s data base doesn’t at all times yield reliable outcomes.
Chat LLMs are notorious for making up citations to scientific papers or courtroom instances that don’t exist. Legal professionals submitting a go well with towards an airline included citations to courtroom instances that by no means truly occurred. A 2023 research reported, that when ChatGPT is prompted to incorporate citations, it had solely supplied references that exist solely 14% of the time. Falsifying sources, rambling, and delivering inaccuracies to appease the immediate are dubbed hallucination, an enormous impediment to beat earlier than AI is totally adopted and trusted by the plenty.
One counter to LLMs making up bogus sources or arising with inaccuracies is retrieval-augmented era or RAG. Not solely can RAG lower the tendency of LLMs to hallucinate however a number of different benefits as nicely.
These benefits embody entry to an up to date data base, specialization (e.g. by offering personal knowledge sources), empowering fashions with data past what’s saved within the parametric reminiscence (permitting for smaller fashions), and the potential to comply with up with extra knowledge from professional references.
What’s RAG (Retrieval Augmented Era)?
Retrieval-Augmented Era (RAG) is a deep studying structure carried out in LLMs and transformer networks that retrieves related paperwork or different snippets and provides them to the context window to supply extra data, aiding an LLM to generate helpful responses. A typical RAG system would have two essential modules: retrieval and era.
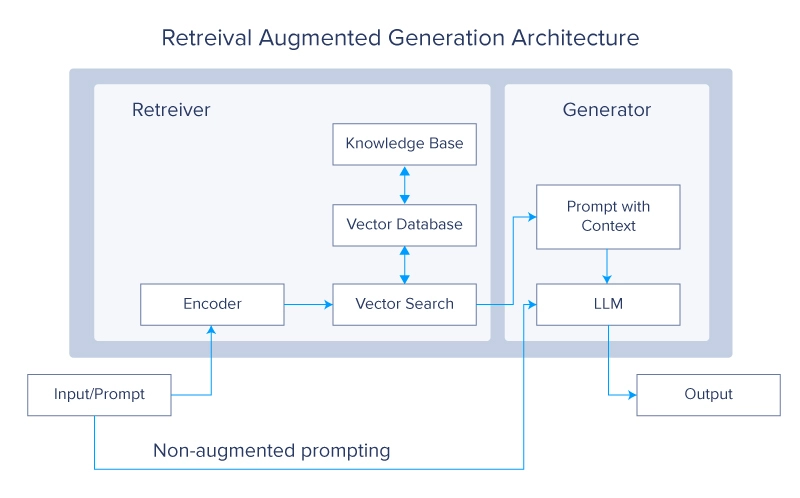
The principle reference for RAG is a paper by Lewis et al. from Fb. Within the paper, the authors use a pair of BERT-based doc encoders to rework queries and paperwork by embedding the textual content in a vector format. These embeddings are then used to determine the top-ok (sometimes 5 or 10) paperwork by way of a most inside product search (MIPS). Because the identify suggests, MIPS is predicated on the inside (or dot) product of the encoded vector representations of the question and people in a vector database pre-computed for the paperwork used as exterior, non-parametric reminiscence.
As described within the piece by Lewis et al., RAG was designed to make LLMs higher at knowledge-intensive duties which “people couldn’t moderately be anticipated to carry out with out entry to an exterior data supply”. Contemplate taking an open ebook and non-open ebook examination and also you’ll have a superb indication of how RAG may complement LLM-based programs.
RAG with the Hugging Face 🤗 Library
Lewis et al. open-sourced their RAG fashions on the Hugging Face Hub, thus we will experiment with the identical fashions used within the paper. A brand new Python 3.8 digital atmosphere with virtualenv is advisable.
virtualenv my_env --python=python3.8
supply my_env/bin/activate
After activating the atmosphere, we will set up dependencies utilizing pip: transformers and datasets from Hugging Face, the FAISS library from Fb that RAG makes use of for vector search, and PyTorch to be used as a backend.
pip set up transformers
pip set up datasets
pip set up faiss-cpu==1.8.0
#https://pytorch.org/get-started/domestically/ to
#match the pytorch model to your system
pip set up torch
Lewis et al. carried out two totally different variations of RAG: rag-sequence and rag-token. Rag-sequence makes use of the identical retrieved doc to reinforce the era of a complete sequence whereas rag-token can use totally different snippets for every token. Each variations use the identical Hugging Face courses for tokenization and retrieval, and the API is way the identical, however every model has a singular class for era. These courses are imported from the transformers library.
from transformers import RagTokenizer, RagRetriever
from transformers import RagTokenForGeneration
from transformers import RagSequenceForGeneration
The primary time the RagRetriever mannequin with the default “wiki_dpr” dataset is instantiated it’s going to provoke a considerable obtain (about 300 GB). When you’ve got a big knowledge drive and wish Hugging Face to make use of it (as a substitute of the default cache folder in your house drive), you’ll be able to set a shell variable, HF_DATASETS_CACHE.
# within the shell:
export HF_DATASETS_CACHE="/path/to/knowledge/drive"
# ^^ add to your ~/.bashrc file if you wish to set the variable
Make sure the code is working earlier than downloading the total wiki_dpr dataset. To keep away from the massive obtain till you’re prepared, you’ll be able to go use_dummy_dataset=True when instantiating the retriever. You’ll additionally instantiate a tokenizer to transform strings to integer indices (similar to tokens in a vocabulary) and vice-versa. Sequence and token variations of RAG use the identical tokenizer. RAG sequence (rag-sequence) and RAG token (rag-token) every have fine-tuned (e.g. rag-token-nq) and base variations (e.g. rag-token-base).
tokenizer = RagTokenizer.from_pretrained(
"fb/rag-token-nq")
token_retriever = RagRetriever.from_pretrained(
"fb/rag-token-nq",
index_name="compressed",
use_dummy_dataset=False)
sequence_retriever = RagRetriever.from_pretrained(
"fb/rag-sequence-nq",
index_name="compressed",
use_dummy_dataset=False)
dummy_retriever = RagRetriever.from_pretrained(
"fb/rag-sequence-nq",
index_name="actual",
use_dummy_dataset=True)
token_model = RagTokenForGeneration.from_pretrained(
"fb/rag-token-nq",
retriever=token_retriever)
seq_model = RagTokenForGeneration.from_pretrained(
"fb/rag-sequence-nq",
retriever=seq_retriever)
dummy_model = RagTokenForGeneration.from_pretrained(
"fb/rag-sequence-nq",
retriever=dummy_retriever)
As soon as your fashions are instantiated, you’ll be able to present a question, tokenize it, and go it to the “generate” perform of the mannequin. We’ll evaluate outcomes from rag-sequence, rag-token, and RAG utilizing a retriever with the dummy model of the wiki_dpr dataset. Notice that these rag-models are case-insensitive
question = "what's the identify of the oldest tree on Earth?"
input_dict = tokenizer.prepare_seq2seq_batch(
question, return_tensors="pt")
token_generated = token_model.generate(**input_dict) token_decoded = token_tokenizer.batch_decode(
token_generated, skip_special_tokens=True)
seq_generated = seq_model.generate(**input_dict)
seq_decoded = seq_tokenizer.batch_decode(
seq_generated, skip_special_tokens=True)
dummy_generated = dummy_model.generate(**input_dict)
dummy_decoded = seq_tokenizer.batch_decode(
dummy_generated, skip_special_tokens=True)
print(f"solutions to question '{question}': ")
print(f"t rag-sequence-nq: {seq_decoded[0]},"
f" rag-token-nq: {token_decoded[0]},"
f" rag (dummy): {dummy_decoded[0]}")
>> solutions to question 'What's the identify of the oldest tree on Earth?': Prometheus was the oldest tree found till 2012, with its innermost, extant rings exceeding 4862 years of age.
>> rag-sequence-nq: prometheus, rag-token-nq: prometheus, rag (dummy): 4862
Usually, rag-token is right extra usually than rag-sequence, (although each are sometimes right), and rag-sequence is extra usually proper than RAG utilizing a retriever with a dummy dataset.
“What kind of context does the retriever present?” You could surprise. To seek out out, we will deconstruct the era course of. Utilizing the seq_retriever and seq_model instantiated as above, we question “What’s the identify of the oldest tree on Earth”
question = "what's the identify of the oldest tree on Earth?"
inputs = tokenizer(question, return_tensors="pt")
input_ids = inputs["input_ids"]
question_hidden_states = seq_model.question_encoder(input_ids)[0]
docs_dict = seq_retriever(input_ids.numpy(),
question_hidden_states.detach().numpy(),
return_tensors="pt")
doc_scores = torch.bmm(
question_hidden_states.unsqueeze(1),
docs_dict["retrieved_doc_embeds"]
.float().transpose(1, 2)).squeeze(1)
generated = mannequin.generate(
context_input_ids=docs_dict["context_input_ids"],
context_attention_mask=
docs_dict["context_attention_mask"],
doc_scores=doc_scores)
generated_string = tokenizer.batch_decode(
generated,
skip_special_tokens=True)
contexts = tokenizer.batch_decode(
docs_dict["context_input_ids"],
attention_mask=docs_dict["context_attention_mask"],
skip_special_tokens=True)
best_context = contexts[doc_scores.argmax()]
We are able to code our mannequin to print the variable “finest context” to see what was captured
print(f" based mostly on the retrieved context"
f":nnt {best_context}: n")
based mostly on the retrieved context:
Prometheus (tree) / In a clonal organism, nevertheless, the person clonal stems aren't almost so previous, and no a part of the organism is especially previous at any given time. Till 2012, Prometheus was thus the oldest "non-clonal" organism but found, with its innermost, extant rings exceeding 4862 years of age. Within the Fifties dendrochronologists have been making energetic efforts to search out the oldest residing tree species in an effort to use the evaluation of the rings for numerous analysis functions, such because the analysis of former climates, the courting of archaeological ruins, and addressing the essential scientific query of most potential lifespan. Bristlecone pines // what's the identify of the oldest tree on earth?
print(f" rag-sequence-nq solutions '{question}'"
f" with '{generated_string[0]}'")
We are able to additionally print the reply by calling the generated_string variable. The rag-sequence-nq solutions ‘what’s the identify of the oldest tree on Earth?’ with ‘Prometheus’.
What Can You Do with RAG?
Within the final yr and a half, there was a veritable explosion in LLMs and LLM instruments. The BART base mannequin utilized in Lewis et al. was solely 400 million parameters, a far cry from the present crop of LLMs, which usually begin within the billion parameter vary for “lite” variants. Additionally, many fashions being skilled, merged, and fine-tuned at this time are multimodal, combining textual content inputs and outputs with photographs or different tokenized knowledge sources. Combining RAG with different instruments can construct complicated capabilities, however the underlying fashions gained’t be resistant to widespread LLM shortcomings. The issues of sycophancy, hallucination, and reliability in LLMs all stay and run the danger of rising simply as LLM use grows.
The obvious purposes for RAG are variations on conversational semantic search, however maybe in addition they embody incorporating multimodal inputs or picture era as a part of the output. For instance, RAG in LLMs with area data could make software program documentation you’ll be able to chat with. Or RAG could possibly be used to maintain interactive notes in a literature assessment for a analysis venture or thesis.
Incorporating a ‘chain-of-thought’ reasoning functionality, you could possibly take a extra agentic method to empower your fashions to question RAG system and assemble extra complicated traces of inquiry or reasoning.
It’s also essential to remember that RAG doesn’t clear up the widespread LLM pitfalls (hallucination, sycophancy, and so on.) and serves solely as a method to alleviate or information your LLM to a extra area of interest response. The endpoints that in the end matter, are particular to your use case, the data you feed your mannequin, and the way the mannequin is finetuned.
Kevin Vu manages Exxact Corp weblog and works with a lot of its proficient authors who write about totally different elements of Deep Studying.