Massive language fashions reply questions utilizing the data they realized throughout coaching. This fastened data base limits them. They’ll’t provide you with present or extremely particular info. Retrieval-Augmented Era (RAG) helps by letting LLMs pull in exterior information, however even RAG wants assist with complicated questions. Adaptive RAG provides an answer. It picks the most effective method for answering a query. This may very well be a direct reply from the LLM, a single information lookup, or a number of information lookups or perhaps a internet search. A classifier appears to be like on the query’s complexity and decides the most effective methodology.
Listed below are the three answering methods Adaptive RAG makes use of:
- Straight ahead Response: For straightforward questions, the LLM makes use of its personal saved data. This offers quick solutions with no need to lookup exterior info.
- Single-step Strategy: For questions which might be a bit more durable, the system will get info from one exterior supply. This retains the reply fast but additionally well-informed.
- Multi-step Strategy: For probably the most complicated questions, the system appears to be like at a number of sources. This builds an in depth and full reply.
Why Adaptive-RAG Works So Effectively
Adaptive-RAG is versatile. It handles every query effectively, utilizing solely the sources wanted. This protects computing energy and makes customers happier as a result of they get exact solutions shortly. Adaptive-RAG additionally updates itself primarily based on query complexity. As a result of it adapts, it reduces the possibility of previous or too-general solutions. It provides present, particular and dependable solutions.
Bettering Accuracy
Adaptive-RAG could be very correct. It understands the complexity of every query and adapts. By matching the retrieval methodology to the query, Adaptive-RAG makes certain solutions are related. It additionally makes use of the most recent accessible info. This adaptability significantly reduces the possibility of getting previous or generic solutions. Adaptive-RAG units a brand new commonplace for correct automated query answering.
The picture from the analysis paper compares completely different RAG approaches. Adaptive RAG excels in each pace and efficiency.
What’s Adaptive RAG?
Adaptive Retrieval-Augmented Era (Adaptive-RAG) is a sophisticated RAG method that improves how massive language fashions reply to person queries.It adjusts its method primarily based on the complexity of every question. This methodology helps keep away from the pitfalls of conventional techniques which will both complicate easy questions or fail to deal with complicated ones successfully.
Key Options of Adaptive RAG
- Adaptive-RAG makes use of a classifier, which can also be a language mannequin, to judge the complexity of incoming queries. This classifier helps the system select the most effective retrieval technique. For easy questions, the LLM can present direct solutions. For extra complicated questions, the system can collect further info as wanted.
- The framework understands that person queries can fluctuate extensively. By adapting its response technique, Adaptive-RAG ensures that easy questions obtain fast solutions, whereas extra complicated queries profit from thorough info retrieval. This method saves time and improves accuracy.
- Adaptive-RAG leverages the exterior databases (like Net Search or offered paperwork) to entry a variety of knowledge. This characteristic is important for offering correct solutions, particularly in open-domain question-answering duties. Through the use of exterior data, the system can ship well timed and related responses.
Stream of Adaptive RAG
- Person Question: The person submits a question, which may be easy or complicated.
- Complexity Evaluation: The classifier analyzes the question to find out its complexity. It appears to be like at the kind of query and the depth of knowledge wanted.
- Technique Choice: Primarily based on the complexity evaluation, Adaptive-RAG chooses an acceptable response technique. For easy queries, it could reply immediately. For complicated queries, it prepares to collect extra info.
- Info Retrieval: If the question is complicated, the system prompts its retrieval modules. These modules search exterior databases for related info. Like on offered paperwork it performs RAG
- Retrieval Grader: The system retrieves chunks of knowledge from the offered paperwork after which grades it, if the retrieved info isn’t discovered to be related then it performs an online seek for extra related info.
- Response Era: After gathering the required info, the LLM creates a transparent and related response.
- Hallucination Grader: After producing the reply, the reply with the query is offered to the hallucination grader, it checks for hallucinated solutions and if it discovered the reply to be not related, it rephrases the query for creating it extra semantic significant and once more sends the rephrased query for Info retrieval.
Picture Rationalization
The picture from the analysis paper defines the adaptive RAG method as follows:
- The system classifies incoming queries as simple, easy, or complicated to find out the suitable processing path.
- Retrieval adapts primarily based on question complexity: direct solutions for easy queries, single doc retrieval for easy queries, and a number of retrievals for complicated queries.
- Easy queries obtain direct solutions with out in depth database searches.
- Easy queries retrieve paperwork after which extract the reply from these paperwork.
- Advanced queries contain iterative retrieval and will generate intermediate solutions to unravel the issue in phases.
Let’s construct a RAG utility utilizing the Adaptive-RAG technique. Our utility sends person inquiries to the most effective information supply. Right here’s the setup:
- Net Search: For questions on latest occasions, we use the Tavily Search API. This pulls in real-time info.
- Self-Corrective RAG: For specialised questions on our personal information, we use a self-correcting system. This makes use of our personal data base.
Implementation Steps
Right here’s a breakdown of how we construct the appliance utilizing the LangGraph framework:
- Indexing Paperwork: We begin by indexing paperwork with ChromaDB, a vector database in LangChain. This lets us shortly discover related paperwork for a person’s query.
- Routing: The important thing a part of our utility is sending every query to the suitable place. This may very well be our internet search or our inside vector database.
- Retrieval Grader: We use a retrieval grader to test if the retrieved paperwork are related. It provides a easy “sure” or “no” rating.
- Era: To create solutions, we mix the immediate, the language mannequin (LLM), and the information from the vector database or internet search. This builds a transparent and related response.
- Hallucination Grader: To verify the data is right, a hallucination grader checks if the reply is predicated on info. It additionally provides a “sure” or “no” rating.
- Reply Grader: A solution grader checks if the response absolutely solutions the person’s query.
- Query Rewriter: This half improves the query. It rewrites the query to make it work higher with the vector database.
- Net Search: The system finds related info on-line with the paraphrased query.
- Graph Illustration utilizing LangGraph: Lastly, we use LangGraph to indicate how the appliance works. We outline nodes and construct a graph that exhibits the entire course of.
Constructing an Adaptive RAG System with Self-Reflection
We can be implementing the Adaptive RAG System now we have mentioned thus far utilizing LangGraph. We can be loading a few of our weblog contents utilizing PyPDFLoader into our vector database, the ChromaDB vector database. and likewise utilizing the Tavily Search device for internet search. Connections to LLMs and prompting can be made with LangChain, and the agent can be constructed utilizing LangGraph. For our LLM, we can be utilizing ChatGPT GPT-4o, which is a strong LLM that has native help for device calling. Though, we will use another LLM, it’s advisable to make use of LLM finetuned for device calling.
Workflow of Adaptive RAG
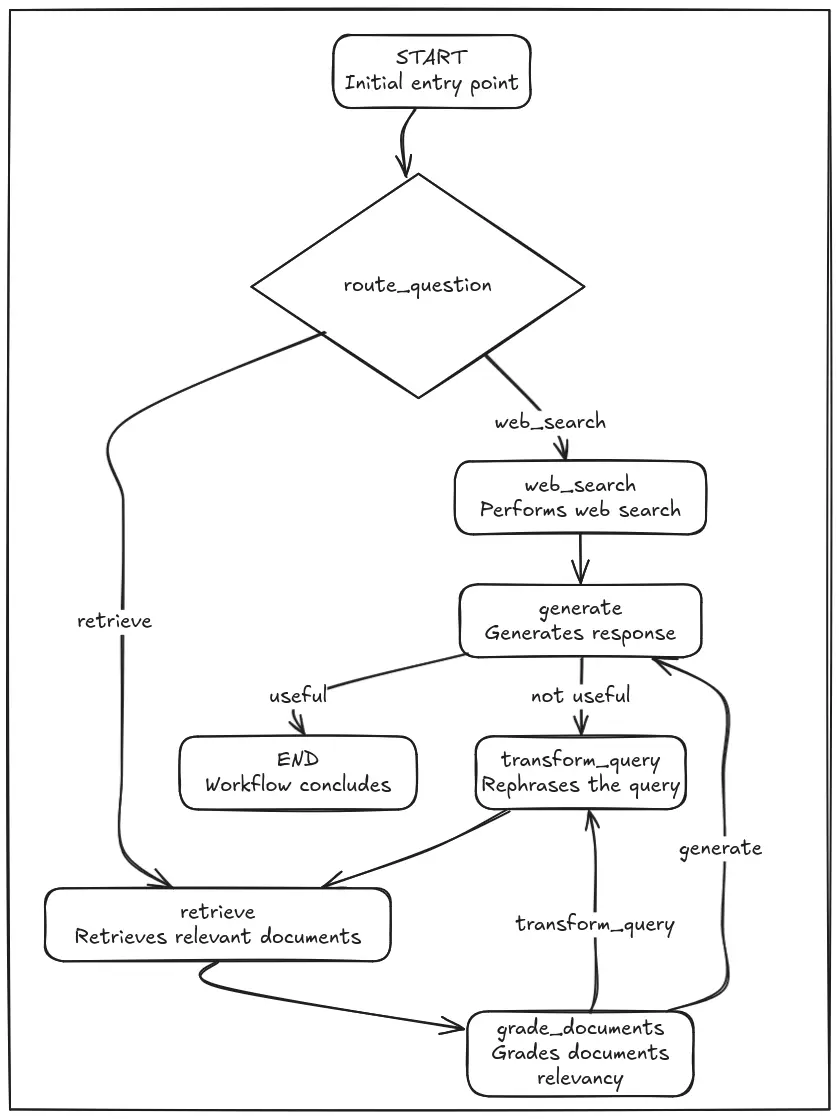
This picture explains the workflow of the adaptive rag system.
Set up OpenAI, ChromaDB, LangGraph and LangChain Dependencies
!pip set up -U langchain_community tiktoken langchain-openai langchainhub langchain_chroma langchain langgraph tavily-python pypdfArrange OpenAI and Tavily API
from getpass import getpassOPENAI_KEY = getpass('Enter Open AI API Key: ')
TAVILY_API_KEY = getpass('Enter Tavily Search API Key: ')
Organising atmosphere variables
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEY
os.environ['TAVILY_API_KEY'] = TAVILY_API_KEYArrange OpenAI embeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
openai_embed_model = OpenAIEmbeddings(mannequin="text-embedding-3-small")Load Information Base
We’ve got downloaded the blogs PDFs and made the pdfs paperwork accessible in a folder named “pdf” on Google Drive, you’ll be able to obtain it from right here.
Now add the “pdf” folder within the colab.
After loading the pdfs, docs_list incorporates the paperwork loaded from the PDFs within the listing
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import PyPDFLoader
pdf_directory = "/content material/pdf"
# Create a DirectoryLoader with PyPDFLoader because the loader
loader = DirectoryLoader(pdf_directory, glob="**/*.pdf", loader_cls=PyPDFLoader)
docs_list = loader.load()
# Now, docs_list incorporates the paperwork loaded from the PDFs within the listing
print(f"Loaded {len(docs_list)} paperwork.")
# Instance: Print the primary few pages of the primary doc (if it has pages)
if docs_list:
first_doc = docs_list[0]
if hasattr(first_doc, 'page_content'):
print(first_doc.page_content[:500]) # Print the primary 500 characters of the primary web pageOutput
Loaded 60 paperwork. 5 Forms of AI Brokers that you just Should Know About Introduction What if machines might make their very own choices, remedy issues, and adapt to new conditions similar to wedo? This may doubtlessly result in a world the place synthetic intelligence turns into not only a device however acollaborator. That’s precisely what AI brokers intention to attain! These sensible techniques are designed tounderstand their environment, course of info, and act independently to perform particular duties.
Let’s take into consideration your every day life—w
Performing the Chunking utilizing RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=300)
chunked_docs = splitter.split_documents(docs_list)
chunked_docs[67].page_contentOutput
# Instantiate instruments docs_tool =
DirectoryReadTool(listing='/residence/xy/VS_Code/Ques_Ans_Gen/blog-posts')nfile_tool =
FileReadTool() search_tool = SerperDevTool() web_rag_tool =
WebsiteSearchTool()nExplanationsndocs_tool: Reads recordsdata from the required
listing(/residence/badrinarayan/VS_Code/Ques_Ans_Gen/blog-posts). This may very well be used
for studying previous blogposts to assist in writing new ones.nfile_tool: Reads
particular person recordsdata, which might turn out to be useful for retrieving analysis supplies or
drafts.nsearch_tool: Performs internet searches utilizing the Serper API to collect information on
market tendencies in AI.nweb_rag_tool: Searches for particular web site content material to help
in analysis.n# Create brokers researcher = Agent( function="Market Analysis Analyst"
, objective="Present 2024 market evaluation of thenAI business", backstory='An knowledgeable
analyst with a eager eye for market tendencies.', instruments=[search_tool,nweb_rag_tool],
verbose=True )nExplanationsnResearcher: This agent conducts market analysis. It
makes use of the search_too
Making a Vector Retailer utilizing Chroma
Storing vectors in Chroma DB utilizing hnsw index for a greater retrieval.
from langchain_chroma import Chroma
chroma_db = Chroma.from_documents(paperwork=chunked_docs,
collection_name="rag_db",
embedding=openai_embed_model,
# must set the space operate to cosine else it makes use of Euclidean by default
# test https://docs.trychroma.com/guides#changing-the-distance-function
collection_metadata={"hnsw:house": "cosine"},
persist_directory="./rag_db")Right here we arrange a similarity_threshold_retriever that extracts the most effective chunks utilizing a threshold worth for similarity between person question and chunks.
similarity_threshold_retriever = chroma_db.as_retriever(search_type="similarity_score_threshold",
search_kwargs={"ok": 3,
"score_threshold": 0.3})Lets Take a look at our Retriever
question = "what's AI brokers?"
top3_docs = similarity_threshold_retriever.invoke(question)
top3_docsOutput
[Document(id='f808a58f-69b9-4442-86b4-fdf3247bdffa', metadata={'creationdate':
'2025-03-06T11:05:04+00:00', 'creator': 'Chromium', 'moddate': '2025-03-
06T11:05:04+00:00', 'page': 0, 'page_label': '1', 'producer': 'Skia/PDF m83',
'source': '/content/pdf/Understanding LangChain Agent Framework.pdf',
'total_pages': 9}, page_content="AI Agent TermsnHere’s the list of AI Agent
terms:n1. AI AgentnAn AI agent is a type of digital assistant or robot that
perceives its environment, processes it, and performsactions to accomplish
particular goals. An example is a self-driving vehicle that has cameras and
sensorsto drive on the road. It is an AI that is working to keep you safe in real
time.n2. Autonomous AgentnAn autonomous agent is an AI that operates on its own
and does not require human supervision. Anexample would be a package delivery drone
that decides on a specific route, avoids obstacles, and makesthe delivery without
any help.nA I A G E N T SnA R T I F I C I A L I N T E L L I G E N C EnB E G I N
N E R"),
Document(id='eef333a4-e2b4-4876-924a-e02ab77052a9', metadata={'creationdate': '2025-
03-06T11:05:04+00:00', 'creator': 'Chromium', 'moddate': '2025-03-
06T11:05:04+00:00', 'page': 0, 'page_label': '1', 'producer': 'Skia/PDF m83',
'source': '/content/pdf/Understanding LangChain Agent Framework.pdf', 'total_pages':
9}, page_content="AI Agent TermsnHere’s the list of AI Agent terms:n1. AI
AgentnAn AI agent is a type of digital assistant or robot that perceives its
environment, processes it, and performsactions to accomplish particular goals. An
example is a self-driving vehicle that has cameras and sensorsto drive on the road.
It is an AI that is working to keep you safe in real time.n2. Autonomous AgentnAn
autonomous agent is an AI that operates on its own and does not require human
supervision. Anexample would be a package delivery drone that decides on a specific
route, avoids obstacles, and makesthe delivery without any help.nA I A G E N T
SnA R T I F I C I A L I N T E L L I G E N C EnB E G I N N E R"),
Document(id='2a9a3be4-2a61-4bed-8e46-804f34dc624c', metadata={'creationdate': '2024-
07-10T10:50:06+00:00', 'creator': 'Chromium', 'moddate': '2024-07-
10T10:50:06+00:00', 'page': 1, 'page_label': '2', 'producer': 'Skia/PDF m83',
'source': '/content/pdf/Build a Customized AI Agent Without Code Using
Relevance.ai.pdf', 'total_pages': 11}, page_content="Frequently Asked
QuestionsnUnderstanding AI AgentsnAI agents are self-governing creatures that
employ sensors to keep an eye on their environment, processinformation, and
accomplish predefined goals. They can be anything from basic bots to
sophisticatedsystems that can adjust and learn over time. Typical instances include
recommendation engines likeNetflix and Amazon’s, chatbots like Siri and Alexa, and
self-driving cars from Tesla and Waymo.nAlso essential in a number of sectors are these agents: UiPath and Blue Prism are examples of roboticprocess automation (RPA)
programs that automate repetitive processes. DeepMind and IBM Watson Healthare
examples of healthcare diagnostics systems that help diagnose diseases and recommend
treatments.In their domains, AI agents greatly improve productivity, precision, and
customisation.nWhy AI Agents are Important?nThese agents play a critical role in
improving our daily lives and accomplishing particular objectives.nAI agents are
significant because they can:nlowering the amount of human labor required to
complete routine operations, resulting in increasedproduction and
efficiency.nanalyzing enormous volumes of data to offer conclusions and suggestions that support decision-making.nutilizing chatbots and virtual assistants
to provide individualized interactions and assistance.nenabling complex
applications in industries like as banking, transportation, and healthcare.nIn
essence, AI agents are pivotal in driving the next wave of technological
advancements, making systemssmarter and more responsive to user
needs.nApplications and Use Cases of AI AgentsnAI agents have a wide range of
applications across various industries. Here are some notable use cases:nCustomer
Service: AI agents in the form of chatbots and virtual assistants handle customer
inquiries,resolve issues, and provide personalized support. They can operate 24/7,
offering consistent andefficient service.")]
question = "what's the capital of USA?"
top3_docs = similarity_threshold_retriever.invoke(question)
top3_docsLet’s now strive a query that’s out of context, such that no context paperwork associated to the query are there within the vector database.
Output
[]
We are able to see that our RAG system is working effectively.
Creating Router
It is going to route the person question primarily based on the character of the question to Net Search or Vector Retailer
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Discipline
from langchain_openai import ChatOpenAI
# Knowledge mannequin
class RouteQuery(BaseModel):
"""Route a person question to probably the most related datasource."""
datasource: Literal["vectorstore", "web_search"] = Discipline(
description="Given a person query select to route it to internet search or a vectorstore.",
)
# LLM with operate name
llm = ChatOpenAI(mannequin="gpt-4o", temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)
# Immediate
system = """You might be an knowledgeable at routing a person query to a vectorstore or internet search.
The vectorstore incorporates paperwork associated to AI brokers, Agentic Patterns and Forms of AI brokers.
Use the vectorstore for questions on these matters. In any other case, use web-search."""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
question_router = route_prompt | structured_llm_router
print(question_router.invoke({"query": "Who received the IPL 2024?"}))
print(question_router.invoke({"query": "What are the sorts of AI brokers?"}))Output
datasource="web_search"datasource="vectorstore"
Retriever Grader
It signifies whether or not the question is related to retrieved paperwork or not by easy “sure” or “no” output.
# Knowledge mannequin
class GradeDocuments(BaseModel):
"""Binary rating for relevance test on retrieved paperwork."""
binary_score: str = Discipline(
description="Paperwork are related to the query, 'sure' or 'no'"
)
# LLM with operate name
llm = ChatOpenAI(mannequin="gpt-4o", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Immediate
system = """You're a grader assessing the relevance of a retrieved doc to a person query. n
If the doc incorporates key phrase(s) or semantic that means associated to the person query, grade it as related. n
It doesn't should be a stringent take a look at. The objective is to filter out faulty retrievals. n
Give a binary rating 'sure' or 'no' rating to point whether or not the doc is related to the query."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: nn {document} nn User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
query = "agentic patterns"
docs = similarity_threshold_retriever.invoke(query)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"query": query, "doc": doc_txt})Output
binary_score="sure"
Era Node
This piece of code is fetching rag immediate from Langchain hub after which producing reply utilizing LLM
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Immediate
immediate = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# Put up-processing
def format_docs(docs):
return "nn".be part of(doc.page_content for doc in docs)
# Chain
rag_chain = immediate | llm | StrOutputParser()
# Run
technology = rag_chain.invoke({"context": docs, "query": query})
print(technology)Output
Agentic patterns in AI design confer with methods that improve AI techniques' autonomy
and effectiveness. The important thing agentic design patterns embody the Reflection Sample,
which focuses on self-evaluation and refinement of outputs, Device Use, Planning, and
Multi-Agent Collaboration. These patterns allow AI fashions to carry out complicated duties
by encouraging self-evaluation, device integration, strategic considering, and collaboration.
Hallucination Grader
Right here we’re checking if the generated reply incorporates hallucination or not which is a self reflection step:
# Knowledge mannequin
class GradeHallucinations(BaseModel):
"""Binary rating for hallucination current in generated reply."""
binary_score: str = Discipline(
description="Reply is grounded within the info, 'sure' or 'no'"
)
# LLM with operate name
llm = ChatOpenAI(mannequin="gpt-4o", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Immediate
system = """You're a grader assessing whether or not an LLM technology is grounded in / supported by a set of retrieved info. n
Give a binary rating 'sure' or 'no'. 'Sure' implies that the reply is grounded in / supported by the set of info."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: nn {documents} nn LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"paperwork": docs, "technology": technology})Output
GradeHallucinations(binary_score="sure")
Reply Grader
It denotes whether or not the offered reply is legit or not in accordance with the query requested
# Knowledge mannequin
class GradeAnswer(BaseModel):
"""Binary rating to evaluate reply addresses query."""
binary_score: str = Discipline(
description="Reply addresses the query, 'sure' or 'no'"
)
# LLM with operate name
llm = ChatOpenAI(mannequin="gpt-4o", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# Immediate
system = """You're a grader assessing whether or not a solution addresses / resolves a query n
Give a binary rating 'sure' or 'no'. Sure' implies that the reply resolves the query."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: nn {question} nn LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"query": query, "technology": technology})Output
GradeAnswer(binary_score="no")
Query Re-Author
It rewrites the query which incorporates extra semantic info which is used if the reply grader tags the reply as not related.
# LLM
llm = ChatOpenAI(mannequin="gpt-4o", temperature=0)
# Immediate
system = """You a query re-writer that converts an enter query to a greater model that's optimized n
for vectorstore retrieval. Have a look at the enter and attempt to cause in regards to the underlying semantic intent / that means."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: nn {question} n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"query": query})Output
‘What are agentic patterns and the way do they affect conduct or decision-making?’
Defining Search Device
Right here Tavily search device is outlined which can be used to look the online
from langchain_community.instruments.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(ok=3)Setting up the Graph utilizing LangGraph
Capturing the circulation in as a graph.
Defining the GraphState
- query: question of the person
- technology: LLM generated reply
- paperwork: record of retrieved paperwork
from typing import Checklist
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
query: query
technology: LLM technology
paperwork: record of paperwork
"""
query: str
technology: str
paperwork: Checklist[str]Creating capabilities for the graphs node.
- retrieve: Provides the retrieved paperwork to the graph state
- generate: Provides the generated reply to the graph state
- grade_documents: It updates the doc key with solely related paperwork
- transform_query: Rephrases the question which seize extra semantic that means
- web_search: It searches the online for the up to date reply and updates the doc key accordingly
from langchain.schema import Doc
def retrieve(state):
"""
Retrieve paperwork
Args:
state (dict): The present graph state
Returns:
state (dict): New key added to state, paperwork, that incorporates retrieved paperwork
"""
print("---RETRIEVE---")
query = state["question"]
# Retrieval
paperwork = similarity_threshold_retriever.invoke(query)
return {"paperwork": paperwork, "query": query}
def generate(state):
"""
Generate reply
Args:
state (dict): The present graph state
Returns:
state (dict): New key added to state, technology, that incorporates LLM technology
"""
print("---GENERATE---")
query = state["question"]
paperwork = state["documents"]
# RAG technology
technology = rag_chain.invoke({"context": paperwork, "query": query})
return {"paperwork": paperwork, "query": query, "technology": technology}
def grade_documents(state):
"""
Determines whether or not the retrieved paperwork are related to the query.
Args:
state (dict): The present graph state
Returns:
state (dict): Updates paperwork key with solely filtered related paperwork
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
query = state["question"]
paperwork = state["documents"]
# Rating every doc
filtered_docs = []
for d in paperwork:
rating = retrieval_grader.invoke(
{"query": query, "doc": d.page_content}
)
grade = rating.binary_score
if grade == "sure":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
proceed
return {"paperwork": filtered_docs, "query": query}
def transform_query(state):
"""
Rework the question to provide a greater query.
Args:
state (dict): The present graph state
Returns:
state (dict): Updates query key with a re-phrased query
"""
print("---TRANSFORM QUERY---")
query = state["question"]
paperwork = state["documents"]
# Re-write query
better_question = question_rewriter.invoke({"query": query})
return {"paperwork": paperwork, "query": better_question}
def web_search(state):
"""
Net search primarily based on the re-phrased query.
Args:
state (dict): The present graph state
Returns:
state (dict): Updates paperwork key with appended internet outcomes
"""
print("---WEB SEARCH---")
query = state["question"]
# Net search
docs = web_search_tool.invoke({"question": query})
web_results = "n".be part of([d["content"] for d in docs])
web_results = Doc(page_content=web_results)
return {"paperwork": web_results, "query": query}Creating Edges Capabilities
- route_question: It directs the query to RAG or internet search
- decide_to_generate: It denotes whether or not to generate the reply or rephrase it
- grade_generation_v_documents_and_question: It determines whether or not the generated reply is related to the query
def route_question(state):
"""
Route query to internet search or RAG.
Args:
state (dict): The present graph state
Returns:
str: Subsequent node to name
"""
print("---ROUTE QUESTION---")
query = state["question"]
supply = question_router.invoke({"query": query})
if supply.datasource == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif supply.datasource == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether or not to generate a solution, or re-generate a query.
Args:
state (dict): The present graph state
Returns:
str: Binary choice for subsequent node to name
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All paperwork have been filtered check_relevance
# We are going to re-generate a brand new question
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We've got related paperwork, so generate reply
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether or not the technology is grounded within the doc and solutions query.
Args:
state (dict): The present graph state
Returns:
str: Resolution for subsequent node to name
"""
print("---CHECK HALLUCINATIONS---")
query = state["question"]
paperwork = state["documents"]
technology = state["generation"]
rating = hallucination_grader.invoke(
{"paperwork": paperwork, "technology": technology}
)
grade = rating.binary_score
# Test hallucination
if grade == "sure":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Test question-answering
print("---GRADE GENERATION vs QUESTION---")
rating = answer_grader.invoke({"query": query, "technology": technology})
grade = rating.binary_score
if grade == "sure":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "helpful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not helpful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
Defining the Graph Structure
We are going to look into the workflow Stream Description beneath:
Preliminary Routing:
- The workflow begins on the START node.
- The route_question operate determines whether or not to proceed with a web_search or a retrieve operation primarily based on the incoming query.
Knowledge Acquisition and Processing:
- If web_search is chosen, the system performs an online search after which strikes to the generate node.
- If retrieve is chosen, the system retrieves related paperwork from a vector retailer, that are then handed to the grade_documents node.
- The grade_documents node then determines if the circulation ought to go to transform_query or to generate.
- If the circulation goes to transform_query, then the question is reworked, and despatched to the retrieve node.
Content material Era and Analysis:
- The generate node creates a response primarily based on the data gathered.
- The grade_generation_v_documents_and_question operate assesses the generated content material.
Resolution and Termination:
- If the generated content material is deemed helpful, the workflow reaches the END node, concluding the method.
- If the generated content material is deemed not helpful, the workflow goes to transform_query node.
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Outline the nodes
workflow.add_node("web_search", web_search) # internet search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade paperwork
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Construct graph
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
# "not supported": "generate",
"helpful": END,
"not helpful": "transform_query",
},
)
# Compile
app = workflow.compile()Workflow Graph
Printing the workflow graph utilizing draw_mermaid :
from IPython.show import Picture, show, Markdown
show(Picture(app.get_graph().draw_mermaid_png()))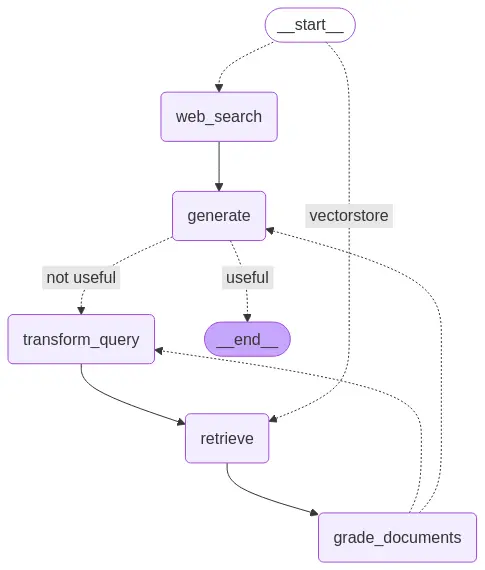
This picture depicts the workflow of Adaptive RAG
Testing the Agent
from pprint import pprint
# Run
inputs = {
"query": "What are the sorts of Agentic Patterns?"
}
for output in app.stream(inputs):
for key, worth in output.gadgets():
# Node
pprint(f"Node '{key}':")
# Non-compulsory: print full state at every node
# pprint.pprint(worth["keys"], indent=2, width=80, depth=None)
pprint("n---n")
# Remaining technology
pprint(worth["generation"])Output
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
"Node 'retrieve':"
'n---n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'n---n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'n---n'
('The sorts of Agentic Patterns are Reflection, Device Use, Planning, and '
'Multi-Agent Collaboration.')from pprint import pprint
# Run
inputs = {
"query": "What participant on the IPL 2024 hit most sixes?"
}
for output in app.stream(inputs):
for key, worth in output.gadgets():
# Node
pprint(f"Node '{key}':")
# Non-compulsory: print full state at every node
# pprint.pprint(worth["keys"], indent=2, width=80, depth=None)
pprint("n---n")
# Remaining technology
pprint(worth["generation"])Output:
---ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
"Node 'web_search':"
'n---n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'n---n'
('Abhishek Sharma from Sunrisers Hyderabad hit the utmost sixes in IPL 2024, '
'with a complete of 42 sixes.')Therefore, we will see that our Adaptive RAG is working very effectively using its self reflection capabilities to cause in regards to the relevancy of output generated by LLM, Additionally using the online search device when retrieved paperwork will not be that good.
Conclusion
Adaptive RAG Programs with LangGraph is a vital development in creating clever question-answering techniques. It selects the most effective retrieval methodology primarily based on how complicated a query is, which helps enhance each pace and accuracy. This methodology overcomes the constraints present in conventional language fashions and fundamental retrieval-augmented technology techniques. It supplies customers with related, present, and reliable info.
The examples and code sources accessible present find out how to implement Adaptive RAG Programs with LangGraph. This makes it simpler to develop more practical and user-friendly AI functions. As AI know-how progresses, strategies like Adaptive RAG can be important for constructing techniques that may perceive and reply to human questions extra successfully.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Captivated with GenAI, NLP, and making machines smarter (in order that they don’t exchange him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.