Think about having a private analysis assistant who not solely understands your query however intelligently decides tips on how to discover solutions. Diving into your doc library for some queries whereas producing inventive responses for others. That is what is feasible with an Agentic RAG Utilizing LlamaIndex TypeScript system.
Whether or not you want to create a literature evaluation system, a technical documentation assistant, or any knowledge-intensive software, the approaches outlined on this weblog put up present a sensible basis you possibly can construct. This weblog put up will take you on a hands-on journey via constructing such a system utilizing LlamaIndex TypeScript, from organising native fashions to implementing specialised instruments that work collectively to ship remarkably useful responses.
Studying Aims
- Perceive the basics of Agentic RAG Utilizing LlamaIndex TypeScript for constructing clever brokers.
- Discover ways to arrange the event setting and set up mandatory dependencies.
- Discover instrument creation in LlamaIndex, together with addition and division operations.
- Implement a math agent utilizing LlamaIndex TypeScript for executing queries.
- Execute and check the agent to course of mathematical operations effectively.
This text was printed as part of the Information Science Blogathon.
Why Use TypeScript?
TypeScript affords important benefits for constructing LLM-based AI software
- Kind Security: TypeScript’s static typing catches errors throughout improvement relatively than at runtime.
- Higher IDE Help: Auto-completion and clever options make improvement sooner
- Enhance Maintainability: Kind definition makes code extra readable and self-documenting
- Seamless Javascript Integration: TypeScript works with present Javascript libraries
- Scalability: TypeScript’s construction helps handle complexity as your RAG software grows.
- Frameworks: Vite, NextJS, and many others properly designed sturdy internet frameworks that seamlessly join with TypeScript which makes constructing AI-based internet purposes simple and scalable.
Advantages of LlamaIndex
LlamaIndex offers a strong framework for constructing LLM-based AI purposes.
- Simplified Information Ingestion: Straightforward strategies to load and course of paperwork on the machine or the cloud utilizing LlamaParse
- Vector Storage: Constructed-in help for embedding and retrieving semantic info with varied integrations with industry-standard databases akin to ChromaDB, Milvus, Weaviet, and pgvector.
- Software Integration: Framework for creating and managing a number of specialised instruments
- Agent Plugging: You may construct or plug third-party brokers simply with LlamaIndex.
- Question Engine Flexibility: Customizable question processing for various use circumstances
- Persistence Help: Capacity to avoid wasting and cargo indexes for environment friendly reuse
Why LlamaIndex TypeScript?
LlamaIndex is a well-liked AI framework for connecting customized knowledge sources to giant language fashions. Whereas initially implementers in Python, LlamaIndex now affords a TypeScript model that brings its highly effective capabilities to the JavaScript ecosystem. That is notably worthwhile for:
- Net purposes and Node.js companies.
- JavaScript/TypeScript builders who need to keep inside their most well-liked language.
- Initiatives that have to run in browser environments.
What’s Agentic RAG?
Earlier than diving into implementation, let’s make clear what it means by Agetntic RAG.
- RAG(Retrieval-Augmented Technology) is a method that enhances language mannequin outputs by first retrieving related info from a information base, after which utilizing that info to generate extra correct, factual responses.
- Agentic programs contain AI that may resolve which actions to take primarily based on person queries, successfully functioning as an clever assistant that chooses acceptable instruments to meet requests.
An Agentic RAG system combines these approaches, creating an AI assistant that may retrieve info from a information base and use different instruments when acceptable. Based mostly on the character of the person’s query, it decides whether or not to make use of its built-in information, question the vector database, or name exterior instruments.
Setting Growth Atmosphere
Set up Node in Home windows
To put in Node into Home windows observe these steps.
# Obtain and set up fnm:
winget set up Schniz.fnm
# Obtain and set up Node.js:
fnm set up 22
# Confirm the Node.js model:
node -v # Ought to print "v22.14.0".
# Confirm npm model:
npm -v # Ought to print "10.9.2".For different programs, it’s essential to observe this.
A Easy Math Agent
Let’s create a simple arithmetic agent to grasp the LlamaIndex TypeScript API.
Step 1: Set Up Work Atmosphere
Create a brand new listing and navigate into it and Initialize a Node.js mission and set up dependencies.
$ md simple-agent
$ cd simple-agent
$ npm init
$ npm set up llamaindex @llamaindex/ollama We are going to create two instruments for the mathematics agent.
- An addition instrument that provides two numbers
- A divide instrument that divides numbers
Step 2: Import Required Modules
Add the next imports to your script:
import { agent, Settings, instrument } from "llamaindex";
import { z } from "zod";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";Step 3: Create an Ollama Mannequin Occasion
Instantiate the Llama mannequin:
const llama3 = new Ollama({
mannequin: "llama3.2:1b",
});Now utilizing Settings you immediately set the Ollama mannequin for the system’s essential mannequin or use a unique mannequin immediately on the agent.
Settings.llm = llama3;Step 4: Create Instruments for the Math Agent
Add and divide instruments
const addNumbers = instrument({
title: "SumNubers",
description: "use this operate to solar two numbers",
parameters: z.object({
a: z.quantity().describe("The primary quantity"),
b: z.quantity().describe("The second quantity"),
}),
execute: ({ a, b }: { a: quantity; b: quantity }) => `${a + b}`,
});Right here we are going to create a instrument named addNumber utilizing LlamaIndex instrument API, The instrument parameters object incorporates 4 essential parameters.
- title: The title of the instrument
- description: The outline of the instrument that might be utilized by the LLM to grasp the instrument’s functionality.
- parameter: The parameters of the instrument, the place I’ve used Zod libraries for knowledge validation.
- execute: The operate which might be executed by the instrument.
In the identical means, we are going to create the divideNumber instrument.
const divideNumbers = instrument({
title: "divideNUmber",
description: "use this operate to divide two numbers",
parameters: z.object({
a: z.quantity().describe("The dividend a to divide"),
b: z.quantity().describe("The divisor b to divide by"),
}),
execute: ({ a, b }: { a: quantity; b: quantity }) => `${a / b}`,
});Step 5: Create the Math Agent
Now in the primary operate, we are going to create a math agent that can use the instruments for calculation.
async operate essential(question: string) {
const mathAgent = agent({
instruments: [addNumbers, divideNumbers],
llm: llama3,
verbose: false,
});
const response = await mathAgent.run(question);
console.log(response.knowledge);
}
// driver code for working the applying
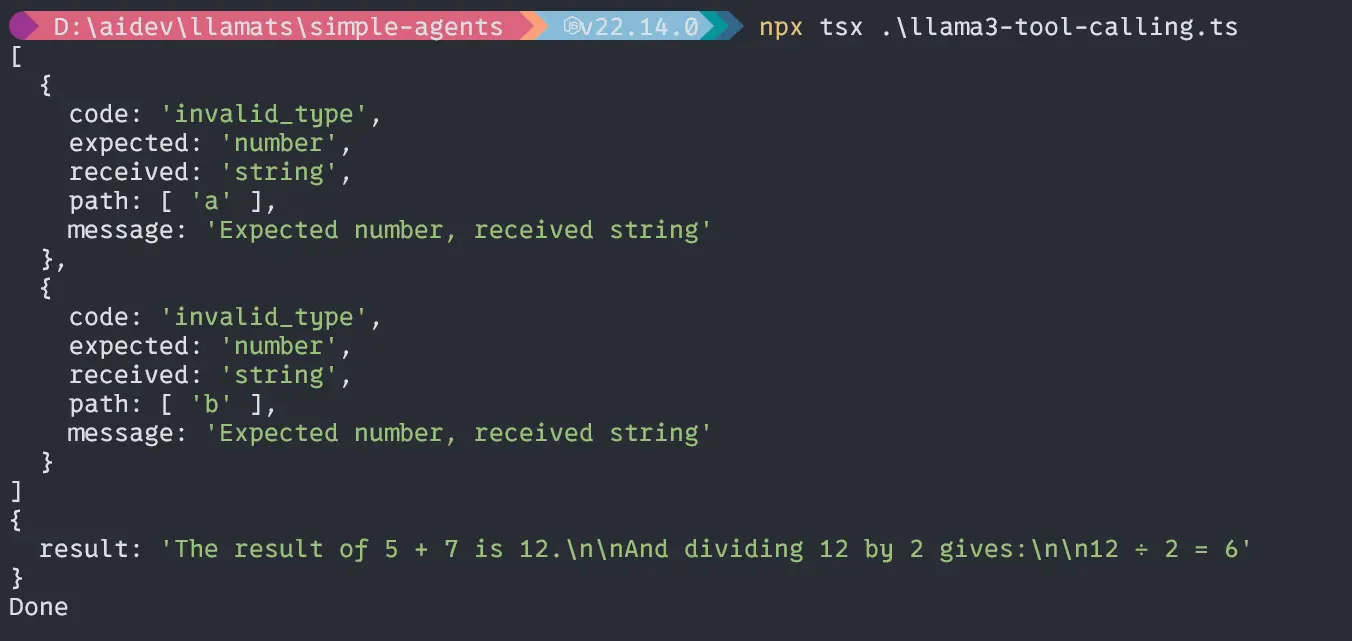
const question = "Add two quantity 5 and seven and divide by 2"
void essential(question).then(() => {
console.log("Completed");
});In case you set your LLM on to via Setting you then don’t need to put the LLM parameters of the agent. If you wish to use completely different fashions for various brokers then it’s essential to put llm parameters explicitly.
After that response is the await operate of the mathAgent which is able to run the question via the llm and return again the info.
Output
Second question “If the entire variety of boys in a category is 50 and ladies is 30, what’s the complete variety of college students within the class?”;
const question =
"If the entire variety of boys in a category is 50 and ladies is 30, what's the complete variety of college students within the class?";
void essential(question).then(() => {
console.log("Completed");
});Output
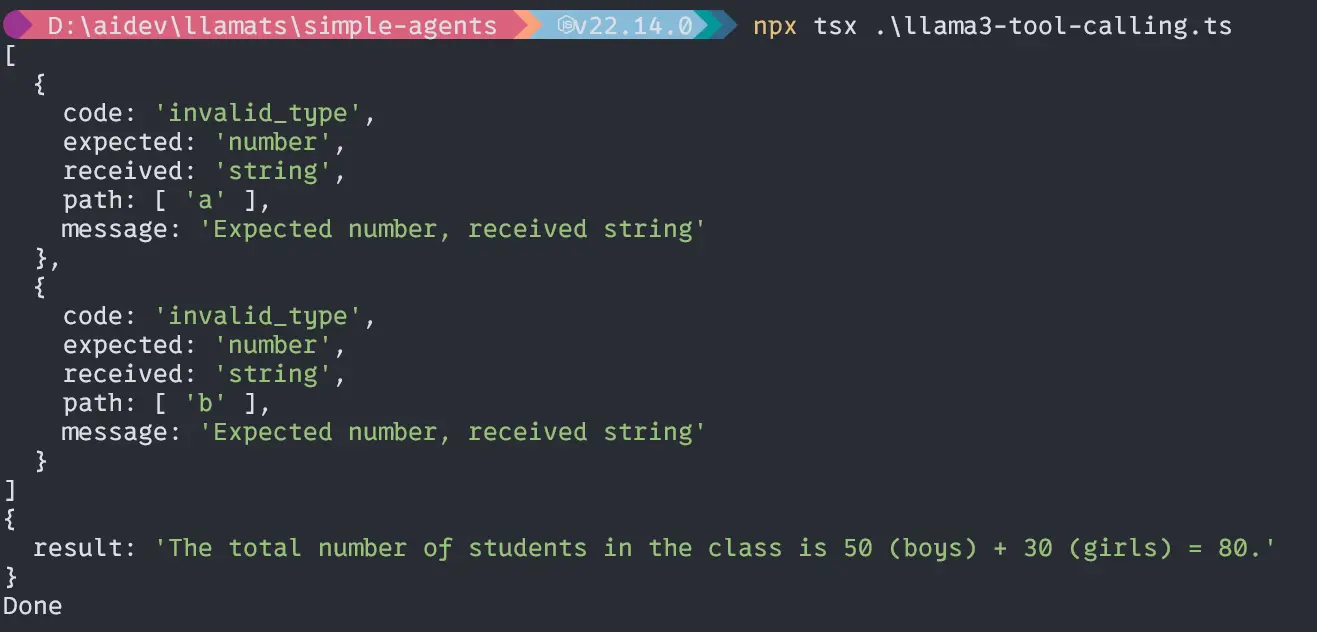
Wow, our little Llama3.2 1B mannequin can deal with brokers properly and calculate precisely. Now, let’s dive deep into the primary a part of the mission.
Begin to Construct the RAG Software
To Arrange the event setting observe the under instruction
Create folder title agentic-rag-app:
$ md agentic-rag-app
$ cd agentic-rag-app
$ npm init
$ npm set up llamaindex @llamaindex/ollama Additionally pull mandatory fashions from Ollama right here, Llama3.2:1b and nomic-embed-text.
In our software, we can have 4 module:
- load-index module for shedding and indexing textual content file
- query-paul module for querying the Paul Graham essay
- fixed module for storing reusable fixed
- app module for working the applying
First, create the constants file and Information folder
Create a continuing.ts file within the mission root.
const fixed = {
STORAGE_DIR: "./storage",
DATA_FILE: "knowledge/pual-essay.txt",
};
export default fixed;It’s an object containing mandatory constants which might be used all through the applying a number of instances. It’s a finest apply to place one thing like that in a separate place. After that create a knowledge folder and put the textual content file in it.
Information supply Hyperlink.
Implementing Load and Indexing Module
Let’s see the under diagram to grasp the code implementation.
Now, create a file title load-index.ts within the mission root:
Importing Packages
import { Settings, storageContextFromDefaults } from "llamaindex";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";
import { Doc, VectorStoreIndex } from "llamaindex";
import fs from "fs/guarantees";
import fixed from "./fixed";Creating Ollama Mannequin Situations
const llama3 = new Ollama({
mannequin: "llama3.2:1b",
});
const nomic = new OllamaEmbedding({
mannequin: "nomic-embed-text",
});Setting the System Fashions
Settings.llm = llama3;
Settings.embedModel = nomic;Implementing indexAndStorage Perform
async operate indexAndStorage() {
strive {
// arrange persistance storage
const storageContext = await storageContextFromDefaults({
persistDir: fixed.STORAGE_DIR,
});
// load docs
const essay = await fs.readFile(fixed.DATA_FILE, "utf-8");
const doc = new Doc({
textual content: essay,
id_: "essay",
});
// create and persist index
await VectorStoreIndex.fromDocuments([document], {
storageContext,
});
console.log("index and embeddings saved efficiently!");
} catch (error) {
console.log("Error throughout indexing: ", error);
}
}The above code will create a persistent cupboard space for indexing and embedding information. Then it is going to fetch the textual content knowledge from the mission knowledge listing and create a doc from that textual content file utilizing the Doc methodology from LlamaIndex and ultimately, it is going to begin making a Vector index from that doc utilizing the VectorStoreIndex methodology.
Export the operate to be used within the different file:
export default indexAndStorage;Implementing Question Module
A diagram for visible understanding
Now, create a file title query-paul.ts within the mission root.
Importing Packages
import {
Settings,
storageContextFromDefaults,
VectorStoreIndex,
} from "llamaindex";
import fixed from "./fixed";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";
import { agent } from "llamaindex";Creating and setting the fashions are the identical as above.
Implementing Load and Question
Now implementing the loadAndQuery operate
async operate loadAndQuery(question: string) {
strive {
// load the saved index from persistent storage
const storageContext = await storageContextFromDefaults({
persistDir: fixed.STORAGE_DIR,
});
/// load the prevailing index
const index = await VectorStoreIndex.init({ storageContext });
// create a retriever and question engine
const retriever = index.asRetriever();
const queryEngine = index.asQueryEngine({ retriever });
const instruments = [
index.queryTool({
metadata: {
name: "paul_graham_essay_tool",
description: `This tool can answer detailed questions about the essay by Paul Graham.`,
},
}),
];
const ragAgent = agent({ instruments });
// question the saved embeddings
const response = await queryEngine.question({ question });
let toolResponse = await ragAgent.run(question);
console.log("Response: ", response.message);
console.log("Software Response: ", toolResponse);
} catch (error) {
console.log("Error throughout retrieval: ", error);
}
}Within the above code, setting the storage context from the STROAGE_DIR, then utilizing VectorStoreIndex.init() methodology we are going to load the already listed information from STROAGE_DIR.
After loading we are going to create a retriever and question engine from that retriever. and now as we’ve got discovered beforehand we are going to create and gear that can reply the query from listed information. Now, add that instrument to the agent named ragAgent.
Then we are going to question the listed essay utilizing two strategies one from the question engine and the opposite from the agent and log the response to the terminal.
Exporting the operate:
export default loadAndQuery;It’s time to put all of the modules collectively in a single app file for simple execution.
Implementing App.ts
Create an app.ts file
import indexAndStorage from "./load-index";
import loadAndQuery from "./query-paul";
operate essential(question: string) {
console.log("======================================");
console.log("Information Indexing....");
indexAndStorage();
console.log("Information Indexing Accomplished!");
console.log("Please, Wait to get your response or SUBSCRIBE!");
loadAndQuery(question);
}
const question = "What's Life?";
essential(question);Right here, we are going to import all of the modules, execute them serially, and run.
Working the Software
$ npx tsx ./app.tswhen it runs the primary time three issues will occur.
- It would ask for putting in tsx, please set up it.
- It would take time to embed the doc relying in your programs(one time).
- Then it is going to give again the response.
First time working (Much like it)
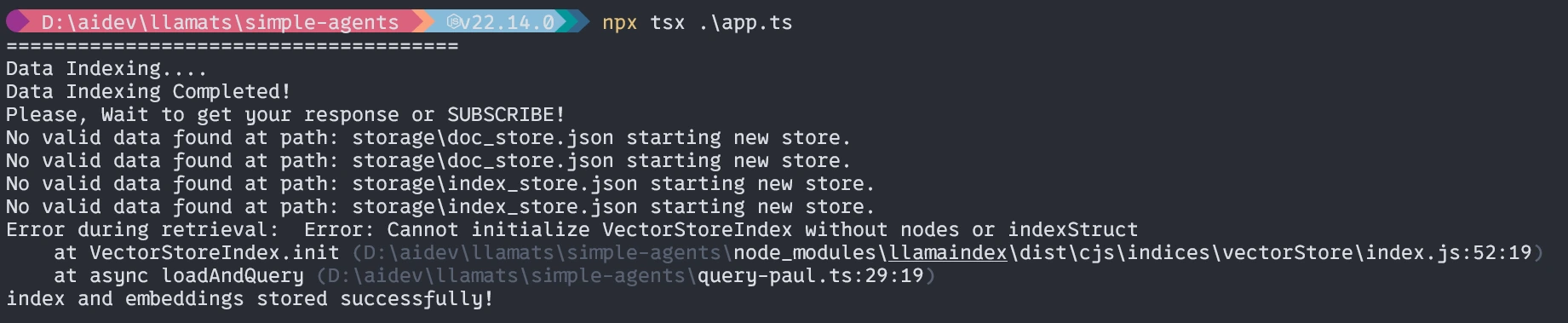
With out the agent, the response might be just like it not precise.
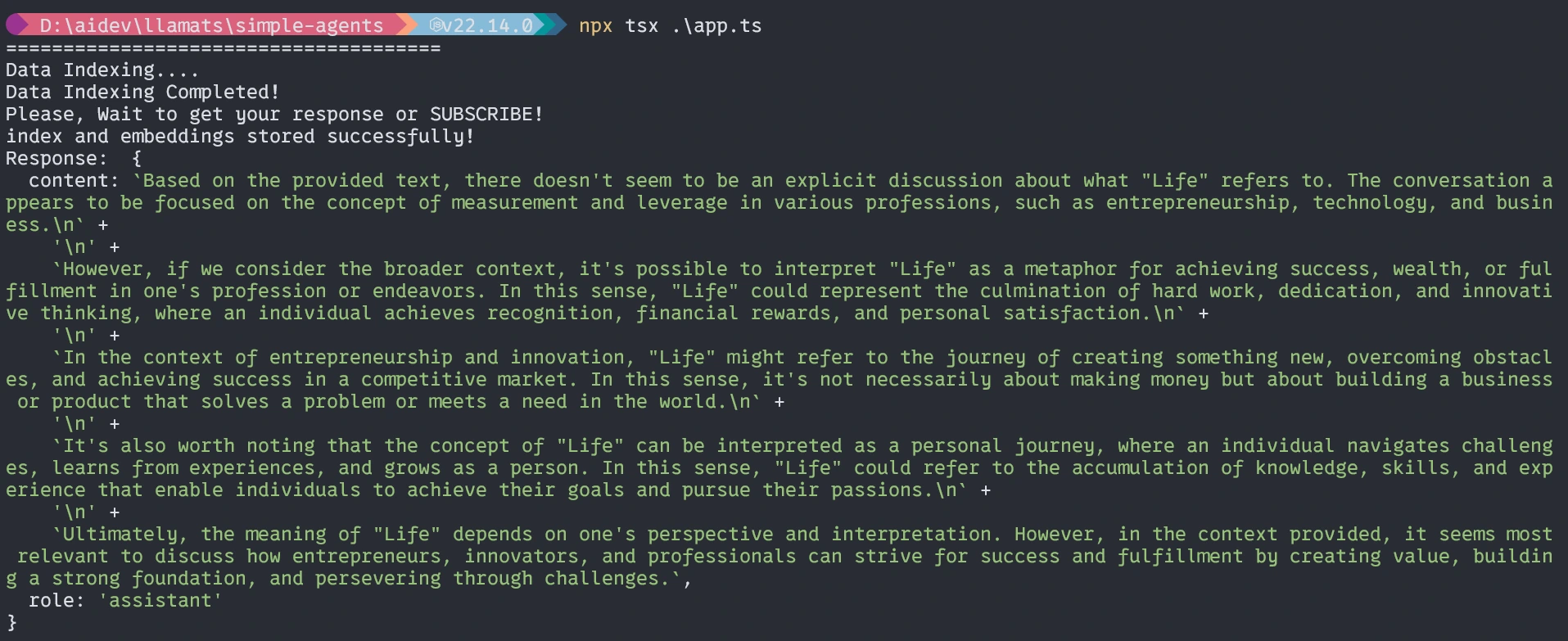
With Brokers
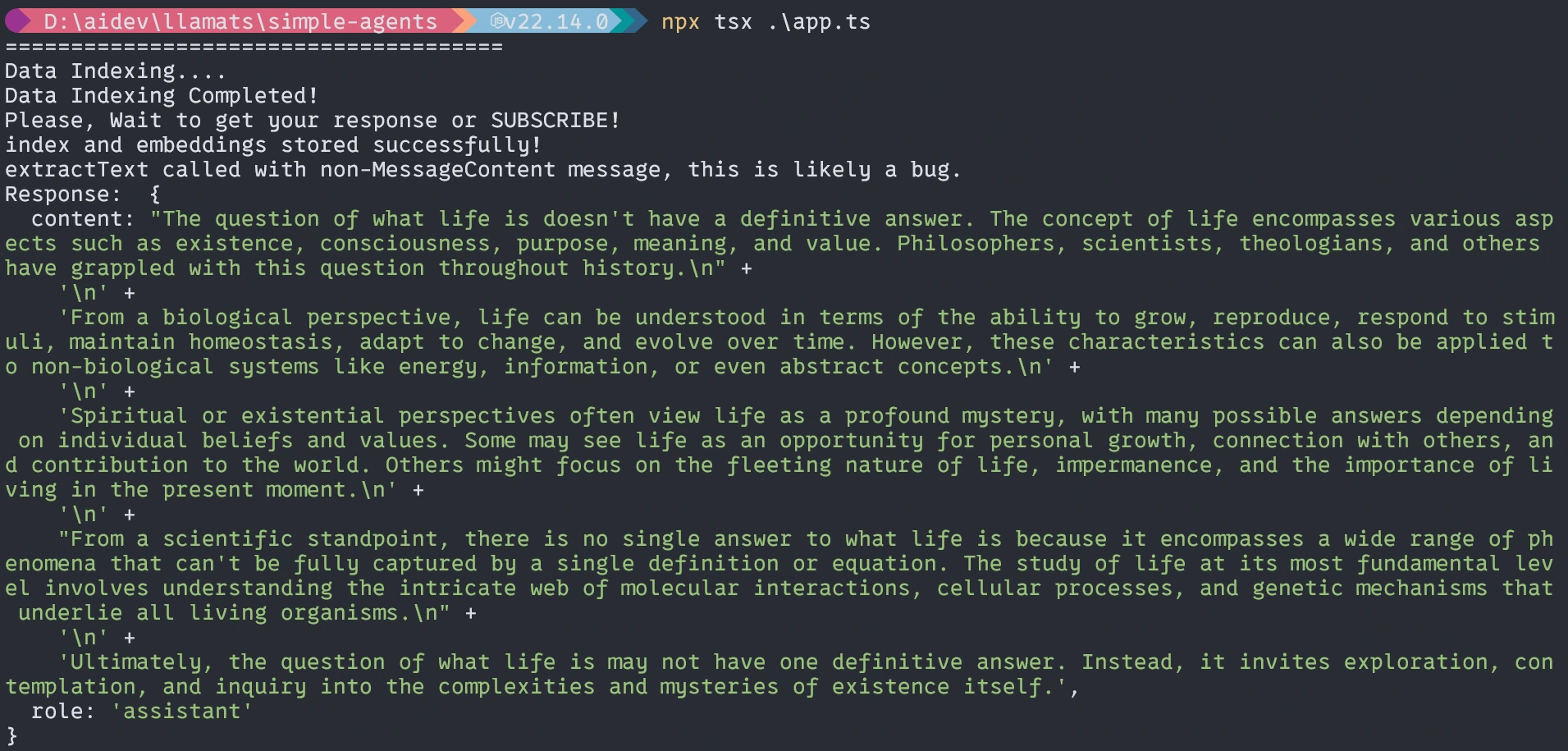

That’s all for at this time. I hope this text will allow you to be taught and perceive the workflow with TypeScript.
Undertaking code repository right here.
Conclusion
This can be a easy but practical Agentic RAG Utilizing LlamaIndex TypeScript system. With this text, I need to provide you with a style of one other language moreover Python for constructing Agentic RAG Utilizing LlamaIndex TypeScript or another LLM AI-based software. The Agentic RAG system represents a strong evolution past fundamental RAG implementation, permitting for extra clever, versatile responses to person queries. Utilizing LlamaIndex with TypeScript, you possibly can construct such a system in a Kind-safe, maintainable means that integrates properly with the online software ecosystem.
Key Takeaways
- Typescript + LlamaIndex offers a strong basis for constructing RAG programs.
- Persistent storage of embeddings improves effectivity for repeated queries.
- Agentic approaches allow extra clever instrument choice primarily based on question content material.
- Native mannequin execution with Ollama affords privateness and value benefits.
- Specialised instruments can handle completely different features of the area information.
- The Agentic RAG Utilizing LlamaIndex TypeScript enhances retrieval-augmented era by enabling clever, dynamic responses.
Continuously Requested Questions
A. You may modify the indexing operate to load paperwork from a number of information or knowledge sources and move an array of doc objects to the VectorStoreIndex methodology.
A. Sure! LlamaIndex helps varied LLM suppliers together with OpenAI, Antropic, and others. You may exchange the Ollama setup with any supported supplier.
A. Think about fine-tuning your embedding mannequin on domain-specific knowledge or implementing customized retrieval methods that prioritize sure doc sections primarily based in your particular use case.
A. Direct querying merely retrieves related content material and generates a response, whereas the agent approached first decides which instrument is most acceptable for the question, probably combining info from a number of sources or utilizing specialised processing for various question varieties.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.
A self-taught, project-driven learner, like to work on advanced initiatives on deep studying, Pc imaginative and prescient, and NLP. I at all times attempt to get a deep understanding of the subject which can be in any discipline akin to Deep studying, Machine studying, or Physics. Like to create content material on my studying. Attempt to share my understanding with the worlds.
Login to proceed studying and revel in expert-curated content material.