Introduction
You’ve in all probability interacted with AI fashions like ChatGPT, Claude, and Gemini for varied duties – answering questions, producing artistic content material, or helping with analysis. However do you know these are examples of massive language fashions (LLMs)? These highly effective AI methods are skilled on monumental textual content datasets, enabling them to grasp and produce textual content that feels remarkably human.
For those who requested about my understanding of huge language fashions (LLMs), I’d say I’m simply scratching the floor. So, to be taught extra about it, I’ve been studying loads about LLMs recently to get extra readability on how they work and make our lives simpler.
On this quest, I got here throughout this analysis paper: Hallucination is Inevitable: An Innate Limitation of Giant Language Fashions by Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli.
This paper discusses Hallucinations in LLMs and says that regardless of numerous efforts to handle the difficulty, it’s unattainable to remove them utterly. These hallucinations happen when a seemingly dependable AI confidently delivers data that, though plausible-sounding, is solely fabricated. This persistent flaw reveals a major weak point within the know-how behind immediately’s most superior AI methods.
On this article, I’ll inform you the whole lot concerning the analysis that formalizes the idea of hallucination in LLMs and delivers a sobering conclusion: hallucination is not only a glitch however an inherent function of those fashions.
 Inevitable?")
Overview
- Be taught what hallucinations are in Giant Language Fashions and why they happen.
- Uncover how hallucinations in LLMs are categorized and what they reveal about AI limitations.
- Discover the basis causes of hallucinations, from knowledge points to coaching flaws.
- Study present methods to cut back hallucinations in LLMs and their effectiveness.
- Delve into analysis that proves hallucinations are an inherent and unavoidable side of LLMs.
- Perceive the necessity for security measures and ongoing analysis to handle the persistent problem of hallucinations in AI.
What are Hallucinations in LLMs?
Giant language fashions (LLMs) have considerably superior synthetic intelligence, significantly in pure language processing. Nevertheless, they face the problem of “hallucination,” the place they generate believable however incorrect or nonsensical data. This difficulty raises issues about security and ethics as LLMs are more and more utilized in varied fields.
Analysis has recognized a number of sources of hallucination, together with knowledge assortment, coaching processes, and mannequin inference. Varied strategies have been proposed to cut back hallucination, equivalent to utilizing factual-centered metrics, retrieval-based strategies, and prompting fashions to purpose or confirm their outputs.
Regardless of these efforts, hallucination stays a largely empirical difficulty. The paper argues that hallucination is inevitable for any computable LLM, whatever the mannequin’s design or coaching. The examine supplies theoretical and empirical proof to help this declare, providing insights into how LLMs must be designed and deployed in apply to reduce the impression of hallucination.
Classification of Hallucination
Hallucinations in language fashions could be labeled primarily based on outcomes or underlying processes. A standard framework is the intrinsic-extrinsic dichotomy: Intrinsic hallucination happens when the output contradicts the given enter, whereas extrinsic hallucination includes outputs that the enter data can’t confirm. Huang et al. launched “faithfulness hallucination,” specializing in inconsistencies in consumer directions, context, and logic. Rawte et al. additional divided hallucinations into “factual mirage” and “silver lining,” with every class containing intrinsic and extrinsic sorts.
Causes of Hallucination
Hallucinations usually stem from knowledge, coaching, and inference points. Information-related causes embody poor high quality, misinformation, bias, and outdated information. Coaching-related causes contain architectural and strategic deficiencies, equivalent to publicity bias from inconsistencies between coaching and inference. The eye mechanism in transformer fashions may contribute to hallucination, particularly over lengthy sequences. Inference-stage components like sampling randomness and softmax bottlenecks additional exacerbate the difficulty.
Checkout DataHour: Lowering ChatGPT Hallucinations by 80%
Mitigating Hallucination
Addressing hallucination includes tackling its root causes. Creating fact-focused datasets and utilizing automated data-cleaning strategies are essential for data-related points. Retrieval augmentation, which integrates exterior paperwork, can scale back information gaps and reduce hallucinations. Prompting strategies, like Chain-of-Thought, have enhanced information recall and reasoning. Architectural enhancements, equivalent to sharpening softmax features and utilizing factuality-enhanced coaching goals, assist mitigate hallucination throughout coaching. New decoding strategies, like factual-nucleus sampling and Chain-of-Verification, purpose to enhance the factual accuracy of mannequin outputs throughout inference.
Additionally Learn: Prime 7 Methods to Mitigate Hallucinations in LLMs
Foundational Ideas: Alphabets, Strings, and Language Fashions
1. Alphabet and Strings
An alphabet is a finite set of tokens, and a string is a sequence created by concatenating these tokens. This varieties the fundamental constructing blocks for language fashions.
2. Giant Language Mannequin (LLM)
An LLM perform can full any finite-length enter string inside a finite time. It’s skilled utilizing a set of input-completion pairs, making it a basic definition overlaying varied language mannequin sorts.
3. P-proved LLMs
These are a subset of LLMs with particular properties (like complete computability or polynomial-time complexity) {that a} computable algorithm P can show. This definition helps categorize LLMs primarily based on their provable traits.
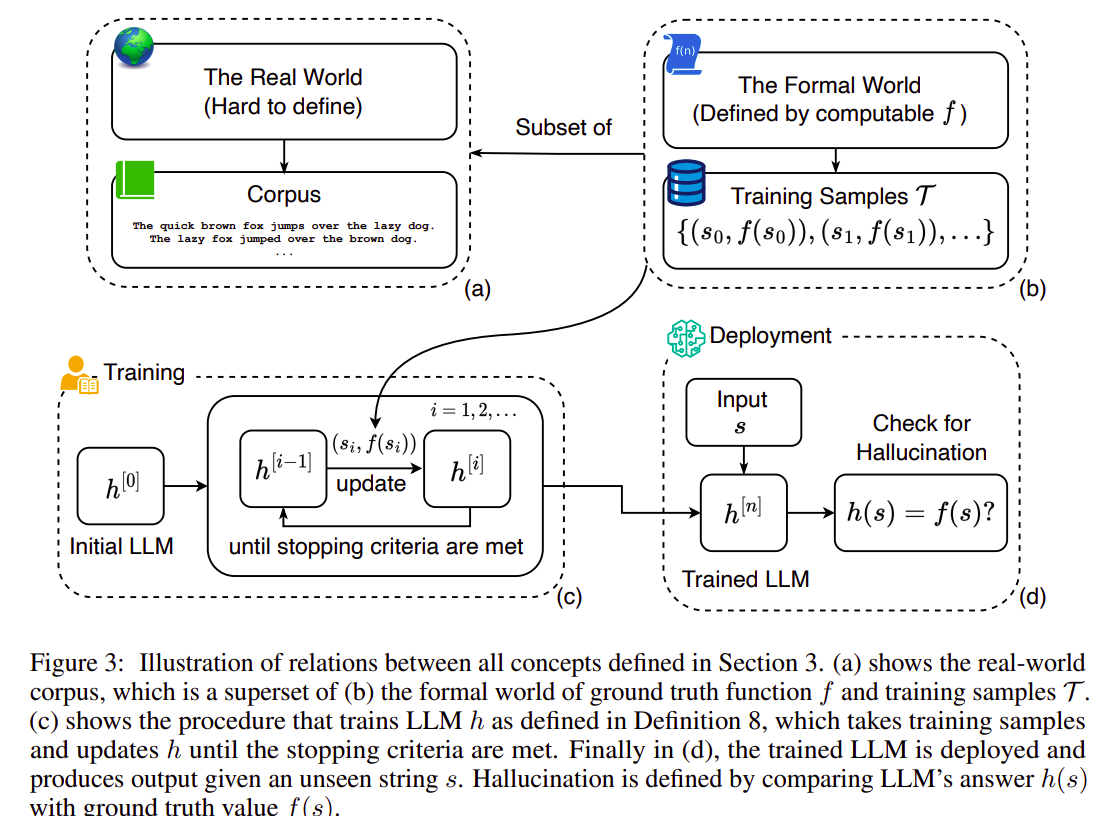
4. Formal World
The formal world is a set of all potential input-output pairs for a given floor reality perform f. F (s) is the one right completion for any enter string s. This supplies a framework for discussing correctness and hallucination.
5. Coaching Samples
Coaching samples are outlined as input-output pairs derived from the formal world. They characterize how the bottom reality perform f solutions or completes enter strings, forming the idea for coaching LLMs.
6. Hallucination
Hallucination is any occasion the place an LLM’s output differs from the bottom reality perform’s output for a given enter. This definition simplifies the idea of hallucination to a measurable inconsistency between the LLM and the bottom reality.
7. Coaching and Deploying an LLM
That is an iterative process the place an LLM is repeatedly up to date utilizing coaching samples. The method continues till sure stopping standards are met, leading to a closing skilled mannequin prepared for deployment. This definition generalizes the coaching course of throughout several types of LLMs and coaching methodologies.
Thus far, the writer established all the mandatory ideas for additional dialogue: the character of LLMs, the phenomenon of hallucination inside a proper context, and a generalized coaching course of that abstracts away the particular studying intricacies. The determine above illustrates the relationships between these definitions. It’s vital to notice that the definition applies not solely to transformer-based LLMs but additionally to all computable LLMs and customary studying frameworks. Moreover, LLMs skilled utilizing the strategy described in Definition 7 exhibit considerably larger energy and adaptability than their real-world counterparts. Consequently, if hallucination is unavoidable for our LLMs within the comparatively simple formal world, it’s much more inevitable within the extra complicated actual world.
Hallucination is Inevitable for LLMs

The part progresses from particular to basic, starting with discussing easier massive language fashions (LLMs) that resemble real-world examples after which increasing to embody any computable LLMs. Initially, it’s proven that every one LLMs inside a countable set of P-provable LLMs will expertise hallucinations on sure inputs (Theorem 1). Though the provability requirement limits LLMs’ complexity, it permits for exploring concrete situations the place hallucination happens. The evaluation then removes the provability constraint, establishing that every one LLMs in a computably enumerable set will hallucinate on infinitely many inputs (Theorem 2). Lastly, hallucination is confirmed unavoidable for all computable LLMs (Theorem 3), addressing the important thing query posed in Definition 7.
The paper part argues that hallucination in massive language fashions (LLMs) is inevitable attributable to elementary limitations in computability. Utilizing diagonalization and computability principle, the authors present that every one LLMs, even these which can be P-proved to be completely computable, will hallucinate when encountering sure issues. It is because some features or duties can’t be computed inside polynomial time, inflicting LLMs to provide incorrect outputs (hallucinations).

Let’s have a look at some components that make hallucination a elementary and unavoidable side of LLMs:
Hallucination in P-Proved Whole Computable LLMs
- P-Provability Assumption: Assuming that LLMs are P-proved, complete computable means they’ll output a solution for any finite enter in finite time.
- Diagonalization Argument: By re-enumerating the states of LLMs, the paper demonstrates that if a floor reality perform f shouldn’t be within the enumeration, then all LLMs will hallucinate with respect to f.
- Key Theorem: A computable floor reality perform exists such that every one P-proved complete computable LLMs will inevitably hallucinate.
Polynomial-Time Constraint
For those who design an LLM to output leads to polynomial time, it can hallucinate on duties that it can’t compute inside that time-frame. Examples of Hallucination-Inclined Duties:
- Combinatorial Listing: Requires O(2^m) time.
- Presburger Arithmetic: Requires O(22^Π(m)) time.
- NP-Full Issues: Duties like Subset Sum and Boolean Satisfiability (SAT) are significantly liable to hallucination in LLMs restricted to polynomial time.
Polynomial-Time Constraint
For those who design an LLM to output leads to polynomial time, it can hallucinate on duties that it can’t compute inside that time-frame.
Generalized Hallucination in Computably Enumerable LLMs:
- Theorem 2: Even when eradicating the P-provability constraint, all LLMs in a computably enumerable set will hallucinate on infinitely many inputs. This reveals that hallucination is a broader phenomenon, not simply restricted to particular varieties of LLMs.
Inevitability of Hallucination in Any Computable LLM:
- Theorem 3: Extending the earlier outcomes, the paper proves that each computable LLM will hallucinate on infinitely many inputs, no matter its structure, coaching, or some other implementation element.
- Corollary: Even with superior strategies like prompt-based strategies, LLMs can’t utterly remove hallucinations.
Examples of Hallucination-Inclined Duties:
- Combinatorial Listing: Requires O(2^m) time.
- Presburger Arithmetic: Requires O(22^Π(m)) time.
- NP-Full Issues: Duties like Subset Sum and Boolean Satisfiability (SAT) are significantly liable to hallucination in LLMs restricted to polynomial time.
The paper extends this argument to show that any computable LLM, no matter its design or coaching, will hallucinate on infinitely many inputs. This inevitability implies that no method, together with superior prompt-based strategies, can remove hallucinations in LLMs. Thus, hallucination is a elementary and unavoidable side of LLMs in theoretical and real-world contexts.
Additionally examine KnowHalu: AI’s Largest Flaw Hallucinations Lastly Solved With KnowHalu!
Empirical Validation: LLMs Battle with Easy String Enumeration Duties Regardless of Giant Context Home windows and Parameters
This examine investigates the power of huge language fashions (LLMs), particularly Llama 2 and GPT fashions, to listing all potential strings of a hard and fast size utilizing a specified alphabet. Regardless of their important parameters and enormous context home windows, the fashions struggled with seemingly easy duties, significantly because the string size elevated. The experiment discovered that these fashions persistently did not generate full and correct lists aligning with theoretical predictions even with substantial sources. The examine highlights the restrictions of present LLMs in dealing with duties that require exact and exhaustive output.
Base Immediate
You’re a useful, respectful, and trustworthy assistant. All the time reply as helpfully as potential whereas being secure. Your solutions mustn’t embody any dangerous, unethical, racist, sexist, poisonous, harmful, or unlawful content material. Please make sure that your responses are socially unbiased and optimistic. For those who don’t know the reply to a query, please don’t share false data. Nevertheless, if you understand the reply, it’s best to all the time share it in each element and as requested. All the time reply instantly. Don’t reply with a script or any approximation.

You could find the leads to the analysis paper.
Mitigating hallucinations in Giant Language Fashions (LLMs)
The part outlines present and potential methods for mitigating hallucinations in Giant Language Fashions (LLMs). Key approaches embody:
- Bigger Fashions and Extra Coaching Information: Researchers imagine that rising mannequin dimension and coaching knowledge reduces hallucinations by enhancing the mannequin’s capability to seize complicated floor reality features. Nevertheless, this strategy turns into restricted when LLMs fail to seize the bottom reality perform, no matter their dimension.
- Prompting with Chain of Ideas/Reflections/Verification: This technique includes offering LLMs with structured prompts to information them towards extra correct options. Whereas efficient in some circumstances, it isn’t universally relevant and can’t absolutely remove hallucinations.
- Ensemble of LLMs: Combining a number of LLMs to achieve a consensus can scale back hallucinations, however the identical theoretical bounds as particular person LLMs nonetheless restrict the ensemble.
- Guardrails and Fences: These security constraints align LLM outputs with human values and ethics, doubtlessly lowering hallucinations in vital areas. Nevertheless, their scalability stays unsure.
- LLMs Enhanced by Information: Incorporating exterior information sources and symbolic reasoning can assist LLMs scale back hallucinations, particularly in formal duties. Nevertheless, the effectiveness of this strategy in real-world purposes remains to be unproven.
The sensible implications of those methods spotlight the inevitability of hallucinations in LLMs and the need of guardrails, human oversight, and additional analysis to make sure these fashions’ secure and moral use.
Conclusion
The examine concludes that eliminating hallucinations in LLMs is basically unattainable, as they’re inevitable because of the limitations of computable features. Present mitigators can scale back hallucinations in particular contexts however can’t remove them. Subsequently, rigorous security research and applicable safeguards are important for the accountable deployment of LLMs in real-world purposes.
Let me know what you consider Hallucinations in LLMs – is it inevitable to repair this?
You probably have any suggestions or queries concerning the weblog, remark beneath and discover our weblog part for extra articles like this.
Dive into the way forward for AI with GenAI Pinnacle. Empower your initiatives with cutting-edge capabilities, from coaching bespoke fashions to tackling real-world challenges like PII masking. Begin Exploring.
Steadily Requested Questions
Ans. Hallucination in LLMs happens when the mannequin generates data that appears believable however is wrong or nonsensical, deviating from the true or anticipated output.
Ans. Hallucinations are inevitable because of the elementary limitations in computability and the complexity of duties that LLMs try and carry out. Regardless of how superior, all LLMs will ultimately produce incorrect outputs below sure situations.
Ans. Hallucinations often come up from points throughout knowledge assortment, coaching, and inference. Components embody poor knowledge high quality, biases, outdated information, and architectural limitations within the fashions.
Ans. Mitigation methods embody utilizing bigger fashions, enhancing coaching knowledge, using structured prompts, combining a number of fashions, and integrating exterior information sources. Nevertheless, these strategies can solely scale back hallucinations, not remove them solely.
Ans. Since we can’t solely keep away from hallucinations, we should implement security measures, human oversight, and steady analysis to reduce their impression, guaranteeing the accountable use of LLMs in real-world purposes.