Whereas everybody’s been ready with bated breath for large issues from OpenAI, their latest launches have truthfully been a little bit of a letdown. Lately, on the primary day of 12 days, 12 stay streams, Sam Altman introduced, the o1 and ChatGPT professional, however didn’t stay as much as the hype and nonetheless aren’t obtainable on API—making it exhausting to justify its hefty $200 Professional mode price ticket. In the meantime, their “new launch” of a form-based waitlist for customized coaching feels extra like a rushed afterthought than a real launch. However right here’s the twist: simply when the highlight was all on OpenAI, Meta swooped in and launched their brand-new open-source mannequin Llama 3.3 70B, claiming to match the efficiency of Llama 3.1 4005B at a much more approachable scale.
Right here’s the enjoyable half:

What’s Llama 3.3 70B?
Meta launched Llama 3.3—a 70-billion-parameter giant language mannequin (LLM) poised to problem the trade’s frontier fashions. With cost-effective efficiency that rivals a lot bigger fashions, Llama 3.3 marks a big step ahead in accessible, high-quality AI.
Llama 3.3 70B is the newest mannequin within the Llama household, boasting a powerful 70 billion parameters. In accordance with Meta, this new launch delivers efficiency on par with their earlier 405-billion-parameter mannequin, whereas concurrently being extra cost-efficient and simpler to run. This outstanding achievement opens doorways to a wider vary of functions and makes cutting-edge AI expertise obtainable to smaller organizations and particular person builders.
Meta simply dropped Llama 3.3 — a 70B open mannequin that provides related efficiency to Llama 3.1 405B, however considerably sooner and cheaper.
It is also ~25x cheaper than GPT-4o.
Textual content just for now, and obtainable to obtain at llama .com/llama-downloads pic.twitter.com/zBMKYYsA4d
— Rowan Cheung (@rowancheung) December 6, 2024
Llama 3.1 4005B
- 405B parameters required: AI fashions demanded huge parameter sizes to ship excessive computational energy.
- Restricted language assist: Performance was constrained by the shortage of multilingual capabilities.
- Remoted capabilities: Instruments and options labored independently, with minimal integration.
Additionally learn: Meta Llama 3.1: Newest Open-Supply AI Mannequin Takes on GPT-4o mini
Llama 3.3 70B
- 70B parameters, similar energy: Fashionable fashions obtain equal computational efficiency with considerably lowered parameters, enhancing effectivity.
- 8 languages supported: Enhanced multilingual capabilities allow broader accessibility and utility.
- Seamless instrument integration: Improved interoperability ensures instruments and functionalities work collectively seamlessly.
The Structure of Llama 3.3 70B

1. Auto-Regressive Language Mannequin
Llama 3.3 generates textual content by predicting the subsequent phrase in a sequence based mostly on the phrases it has already seen. This step-by-step strategy is known as “auto-regressive,” that means it builds the output incrementally, making certain that every phrase is knowledgeable by the previous context.
2. Optimized Transformer Structure
Transformers are the spine of recent language fashions, leveraging mechanisms like consideration to deal with probably the most related components of a sentence. An optimized structure means Llama 3.3 has enhancements (e.g., higher effectivity or efficiency) over earlier variations, doubtlessly enhancing its skill to generate coherent and contextually acceptable responses whereas utilizing computational sources extra successfully.
3. Supervised Fantastic-Tuning (SFT)
- What it’s: The mannequin is skilled on labeled datasets the place examples of fine responses are supplied by people. This course of helps the mannequin study to imitate human-like behaviour in particular duties.
- Why it’s used: This step improves the mannequin’s baseline efficiency by aligning it with human expectations.
4. Reinforcement Studying with Human Suggestions (RLHF)
- What it’s: After SFT, the mannequin undergoes reinforcement studying. Right here, it interacts with people or techniques that price its outputs, guiding it to enhance over time.
- Reinforcement Studying: The mannequin is rewarded (or penalized) based mostly on how properly it aligns with desired behaviours.
- Human Suggestions: People instantly price or affect what is taken into account a “good” or “dangerous” response, which helps the mannequin refine itself additional.
- Why it issues: RLHF helps fine-tune the mannequin’s skill to offer outputs that aren’t solely correct but additionally align with preferences for helpfulness, security, and moral issues.
Additionally learn: An Finish-to-Finish Information on Reinforcement Studying with Human Suggestions
5. Alignment with Human Preferences
The mixed use of SFT and RLHF ensures that Llama 3.3 behaves in ways in which prioritize:
- Helpfulness: Offering helpful and correct info.
- Security: Avoiding dangerous, offensive, or inappropriate responses.
Efficiency Comparisons with Different Fashions
When in comparison with frontier fashions like GPT-4o (a hypothetical next-gen mannequin), Google’s Gemini, and even Meta’s personal Llama 3.1 405b mannequin, Llama 3.3 stands out:
- Instruction Following and Lengthy Context: Llama 3.3’s skill to know and observe advanced directions over prolonged contexts of as much as 128,000 tokens places it on par with top-tier choices from each Google and OpenAI. This stage of prolonged context reminiscence is essential for duties like long-form content material technology, in-depth reasoning, and multi-step coding issues.
- Mathematical and Logical Reasoning: Early benchmarks point out that Llama 3.3 outperforms GPT-40 on math duties, suggesting stronger reasoning and solution-finding capabilities. In real-world situations, this enchancment interprets into extra correct problem-solving throughout technical domains, together with information evaluation, engineering calculations, and scientific analysis assist.
- Price-Effectiveness: Maybe probably the most compelling benefit of Llama 3.3 is its important discount in operational prices. Whereas GPT-40 might value round $250 per million enter tokens and $10 per million output tokens, Llama 3.3’s estimated pricing drops to simply $0.10 per million enter tokens and $0.40 per million output tokens. Such a dramatic value lower—roughly 25 instances cheaper—allows builders and companies to deploy state-of-the-art language fashions with lowered monetary boundaries.
Let’s examine it intimately with totally different benchmarks:
1. Basic Efficiency
- MMLU (0-shot, CoT):
- Llama 3.3 70B: 86.0, matching Llama 3.1 70B however barely beneath Llama 3.1 405B (88.6) and GPT-4o (87.5).
- It edges out Amazon Nova Professional (85.9) and is on par with Gemini Professional 1.5 (87.1).
- MMLU PRO (5-shot, CoT):
- Llama 3.3 70B: 68.9, higher than Llama 3.1 70B (66.4) and barely behind Gemini Professional 1.5 (76.1).
- Akin to the dearer GPT-4o (73.8).
Takeaway: Llama 3.3 70B balances value and efficiency generally benchmarks whereas staying aggressive with bigger, costlier fashions.
2. Instruction Following
- IFEval:
- Llama 3.3 70B: 92.1, outperforming Llama 3.1 70B (87.5) and competing with Amazon Nova Professional (92.1).
- Surpasses Gemini Professional 1.5 (81.9) and GPT-4o (84.6).
Takeaway: This metric highlights the power of Llama 3.3 70B in adhering to directions, notably with post-training optimization.
3. Code Technology
- HumanEval (0-shot):
- Llama 3.3 70B: 88.4, higher than Llama 3.1 70B (80.5), practically equal to Amazon Nova Professional (89.0), and surpasses GPT-4o (86.0).
- MBPP EvalPlus:
- Llama 3.3 70B: 87.6, higher than Llama 3.1 70B (86.0) and GPT-4o (83.9).
Takeaway: Llama 3.3 70B excels in code-based duties with notable efficiency boosts from optimization methods.
4. Mathematical Reasoning
- MATH (0-shot, CoT):
- Llama 3.3 70B: 77.0, a considerable enchancment over Llama 3.1 70B (68.0) and higher than Amazon Nova Professional (76.6).
- Barely beneath Gemini Professional 1.5 (82.9) and on par with GPT-4o (76.9).
Takeaway: Llama 3.3 70B handles math duties properly, although Gemini Professional 1.5 edges forward on this area.
5. Reasoning
- GPOQA Diamond (0-shot, CoT):
- Llama 3.3 70B: 50.5, forward of Llama 3.1 70B (48.0) however barely behind Gemini Professional 1.5 (53.5).
Takeaway: Improved reasoning efficiency makes it a powerful alternative in comparison with earlier fashions.
6. Instrument Use
- BFCL v2 (0-shot):
- Llama 3.3 70B: 77.3, much like Llama 3.1 70B (77.5) however behind Gemini Professional 1.5 (80.3).
7. Context Dealing with
- Lengthy Context (NIH/Multi-Needle):
- Llama 3.3 70B: 97.5, matching Llama 3.1 70B and really near Llama 3.1 405B (98.1).
- Higher than Gemini Professional 1.5 (94.7).
Takeaway: Llama 3.3 70B is extremely environment friendly at dealing with lengthy contexts, a key benefit for functions needing giant inputs.
8. Multilingual
- Multilingual MGSM (0-shot):
- Llama 3.3 70B: 91.1, considerably forward of Llama 3.1 70B (86.9) and aggressive with GPT-4o (90.6).
Takeaway: Sturdy multilingual capabilities make it a strong alternative for numerous language duties.
9. Pricing
- Enter Tokens: $0.1 per million tokens, the most cost effective amongst all fashions.
- Output Tokens: $0.4 per million tokens, considerably cheaper than GPT-4o ($10) and others.
Takeaway: Llama 3.3 70B presents distinctive cost-efficiency, making high-performance AI extra accessible.
In a nutshell,
- Strengths: Glorious cost-performance ratio, aggressive in instruction following, code technology, and multilingual duties. Lengthy-context dealing with and gear use are sturdy areas.
- Commerce-offs: Barely lags in some benchmarks like superior math and reasoning in comparison with Gemini Professional 1.5.
Llama 3.3 70B stands out as an optimum alternative for top efficiency at considerably decrease prices.
Technical Developments and Coaching
Alignment and Reinforcement Studying (RL) Improvements
Meta credit Llama 3.3’s enhancements to a new alignment course of and progress in on-line RL methods. By refining the mannequin’s skill to align with human values, observe directions, and decrease undesirable outputs, Meta has created a extra dependable and user-friendly system.
Coaching Knowledge and Information Cutoff:
- Coaching Tokens: Llama 3.3 was skilled on a large 15 trillion tokens, making certain broad and deep protection of world information and language patterns.
- Context Size: With a context window of 128,000 tokens, customers can interact in intensive, in-depth conversations with out shedding the thread of context.
- Information Cutoff: The mannequin’s information cutoff is December 2023, making it well-informed on comparatively latest information. This cutoff means the mannequin might not know occasions occurring after this date, however its intensive pre-2024 coaching ensures a wealthy basis of knowledge.
Unbiased Evaluations and Outcomes
A comparative chart from Synthetic Evaluation highlights the soar in Llama 3.3’s efficiency metrics, confirming its legitimacy as a high-quality mannequin. This goal analysis reinforces Meta’s place that Llama 3.3 is a “frontier” mannequin at a fraction of the standard value.
High quality: Llama 3.3 70B scores 74, barely beneath the highest performers like 01-preview (86) and 01-mini (84).
Velocity: With a velocity of 149 tokens/second, Llama 3.3 70B matches GPT-40-mini however lags behind 01-mini (231).
Value: At $0.6 per million tokens, Llama 3.3 70B is cost-effective, outperforming most rivals besides Google’s Gemini 1.5 Flash ($0.1)
Third-party evaluations lend credibility to Meta’s claims. Synthetic Evaluation, an unbiased benchmarking service, performed assessments on Llama 3.3 and reported a notable enhance of their proprietary High quality Index rating—from 68 to 74. This soar locations Llama 3.3 on par with different main fashions, together with MW Massive and Meta’s earlier Llama 3.1 405b, whereas outperforming the newly launched GPT-40 on a number of duties.
Sensible Use Instances and Testing
Whereas Llama 3.3 excels in lots of areas, real-world testing offers probably the most tangible measure of its worth:
- Code Technology:
In preliminary assessments, Llama 3.3 produced coherent, useful code at spectacular speeds. Though it might not surpass specialised code-generation fashions like Sonet 3.5 in each job, its normal efficiency and affordability make it compelling for builders who want a flexible assistant able to coding assist, debugging, and easy utility technology. - Instruction Following:
Customers report that Llama 3.3 follows advanced directions reliably and persistently. Whether or not it’s writing structured experiences, drafting technical documentation, or performing multi-step reasoning duties, the mannequin proves responsive and correct. - Native Deployment:
With environment friendly inference and a parameter rely of 70 billion (considerably smaller than the 405b counterpart), Llama 3.3 is simpler to run on native {hardware}. Whereas a strong machine or specialised GPU setup should still be required, the barrier to working this frontier mannequin domestically is noticeably decrease.
The place to Entry Llama 3.3 70B?
Quick Availability
Llama 3.3 is already built-in into platforms like Groq, and could be put in from Ollama (AMA). Builders interested by testing the mannequin can discover it on Hugging Face and official obtain sources:
Hosted Choices
For many who choose managed options, a number of suppliers provide Llama 3.3 internet hosting, together with Deep Infra, Hyperbolic, Groq, Fireworks, and Collectively AI, every with totally different efficiency and pricing tiers. Detailed velocity and value comparisons can be found, enabling you to seek out the very best match on your wants.
Learn how to Entry Llama 3.3 70B Utilizing Ollama?
1. Set up Ollama
- Go to the Ollama web site to obtain the instrument. For Linux customers:
- Execute the next command in your terminal:
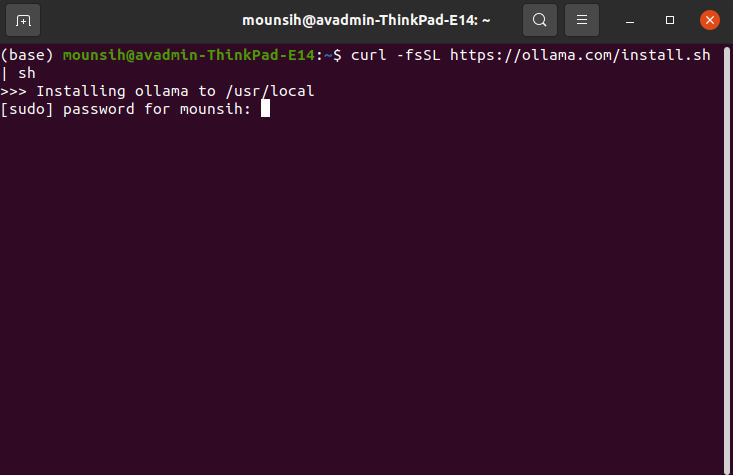
curl -fsSL https://ollama.com/set up.sh | shThis command downloads and installs Ollama to your system. You may be prompted to enter your sudo password to finish the set up.
After this put the Sudo password:
2. Pull the Llama Mannequin
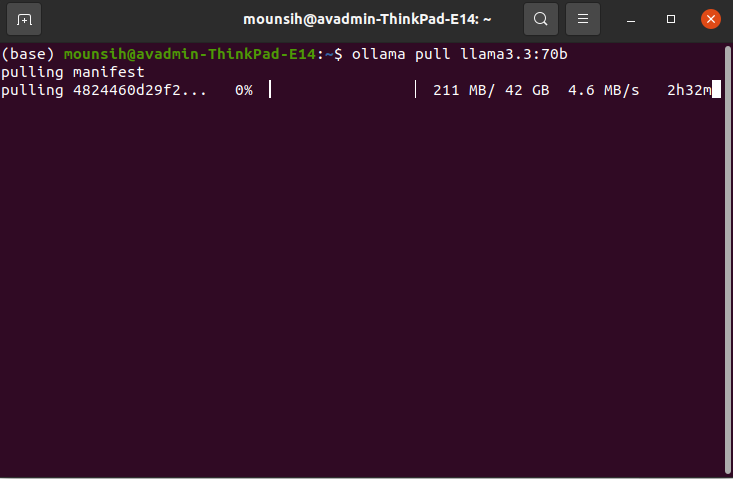
After putting in Ollama, you’ll be able to obtain the Llama 3.3 70B mannequin. Run the next command within the terminal:
ollama pull llama3.3:70bIt will begin downloading the mannequin. Relying in your web velocity and the mannequin measurement (42 GB on this case), it would take a while. Now you’re prepared to make use of the mannequin.
Learn how to Entry Llama 3.3 70B Utilizing Hugging Face?
It’s essential get the token from Hugging Face: Hugging Face Tokens
Take entry from Hugging Face: Hugging Face Entry

Full code
!pip set up openai
!pip set up --upgrade transformers
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')
import openai
from IPython.show import HTML, Markdown, show
openai.api_key = OPENAI_KEY
!huggingface-cli login
#Or use this
From Huggingfacehub import login
login()
#proceeddef get_completion_gpt(immediate, mannequin="gpt-4o-mini"):
messages = [{"role": "user", "content": prompt}]
response = openai.chat.completions.create(
mannequin=mannequin,
messages=messages,
temperature=0.0, # diploma of randomness of the mannequin's output
)
return response.selections[0].message.content material
import transformers
import torch
# obtain and cargo the mannequin domestically
model_id = "meta-llama/Llama-3.3-70B-Instruct"
llama3 = transformers.pipeline(
"text-generation",
mannequin=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="cuda",
)
def get_completion_llama(immediate, model_pipeline=llama3):
messages = [{"role": "user", "content": prompt}]
response = model_pipeline(
messages,
max_new_tokens=2000
)
return response[0]["generated_text"][-1]['content']
response = get_completion_llama(immediate="Compose an intricate poem within the type of a lyrical dialogue between the moon and the ocean, the place the moon is a wistful thinker craving for understanding, and the ocean is a tempestuous artist with a coronary heart filled with secrets and techniques. Let their dialog weave collectively themes of eternity, isolation, and the human situation, in the end concluding with a paradox that leaves the reader considering the character of existence.")
show(Markdown(response))Downloadings

Output
What an interesting immediate! 🌕🌊 This is a poem that weaves collectively the
dialog between the moon and the ocean, exploring the themes of
eternity, isolation, and the human situation:The Lunar Oceanic Dialogue
[The moon, a glowing crescent, speaks first]
Moon:
Oh, ocean, huge and deep, with secrets and techniques untold,
I've watched you for eons, your mysteries to unfold.
In your waves, I see the human coronary heart's darkish evening,
A mirrored image of their souls, with all its plights.Ocean:
(surging with a mighty roar)
And I, pricey moon, have witnessed your light beam,
A beacon within the darkness, a guiding dream.
However what of your individual coronary heart, with its silvery glow?
Do you not really feel the burden of eternity's woe?Moon:
(with a sigh, like a gentle breeze)
Certainly, I do. For in my orbit, I am sure,
A continuing observer, by no means actually discovered.
I yearn to know the human situation's plight,
To understand the essence of their existence, and the darkness of their evening.Ocean:
(turbulent, with a touch of mischief)
Ah, however that is the place you are mistaken, pricey moon, my pal,
For of their depths, I've seen the sweetness that by no means ends.
The secrets and techniques I preserve, the tales I might inform,
Are of a world that is hidden, but endlessly swell.Moon:
(intrigued, with a tilt of her head)
Inform me, ocean, what secrets and techniques do you maintain inside?
What mysteries of the human coronary heart do you unlock and spin?
Is it the story of affection, of loss, of life and demise?
Or maybe the whispers of the universe's personal breath?Ocean:
(with a sly smile, like a wave's delicate curve)
All these and extra, pricey moon. However most of all,
I've realized that eternity isn't a hard and fast wall,
However a tapestry, ever-unfolding, with every passing tide,
A paradox of time, the place the infinite resides.Moon:
(puzzled, with a furrowed forehead)
A paradox, you say? Pray inform, what do you imply?
Is it that eternity is each limitless and serene?
Or that the human coronary heart, with all its flaws and fears,
Is able to containing the infinite, by means of all its tears?Ocean:
(with a chuckle, like a wave's light lap)
Precisely, pricey moon! And that is the place the paradox lies,
For within the human situation, we discover each the finite and the infinite's sighs.
Of their hearts, a universe of feelings, ideas, and goals,
A microcosm of eternity, with all its contradictions, it appears.Moon:
(with a nod, like a sluggish, celestial blink)
I see. And so, our dialog comes full circle,
A dance of phrases, the place the reality, just like the ocean's tides, does twirl.
For in the long run, it isn't the solutions that we search,
However the questions themselves, which set our souls to talk.Ocean:
(with a ultimate, mighty roar, like a wave's crashing would possibly)
And so, pricey moon, allow us to proceed this cosmic waltz,
A dialogue of marvel, the place the paradox of existence, we'll all the time halt.
For within the thriller, we discover the sweetness, and the reality, we'll by no means know,
A secret, hidden within the depths, the place the human coronary heart, and the universe, do develop. 🌊🌕I hope you loved this poetic dialogue between the moon and the ocean! 🌟💫
The paradox on the coronary heart of the dialog invitations the reader to ponder
the character of existence, and the intricate relationships between eternity,
isolation, and the human situation. 🤔💭
Overview of the Code
- Token Setup:
- Tokens from Hugging Face and OpenAI API keys are required for authentication.
- Hugging Face is used to log in and entry its fashions.
- OpenAI’s API is used to work together with GPT fashions.
- Libraries Put in:
- openai: Used to work together with OpenAI’s GPT fashions.
- transformers: Used to work together with Hugging Face’s fashions.
- getpass: For safe API key entry.
- Major Capabilities:
- get_completion_gpt: Generates responses utilizing OpenAI GPT fashions.
- get_completion_llama: Generates responses utilizing a domestically loaded Hugging Face LLaMA mannequin.
Code Walkthrough
1. Required Setup
- Hugging Face Token:
- Entry the token on the supplied Hugging Face URLs.
- That is important to obtain and authenticate with Hugging Face fashions.
Set up Required Libraries:
!pip set up openai
!pip set up --upgrade transformersThese instructions make sure that the required Python libraries are put in or upgraded.
OpenAI API Key:
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')
openai.api_key = OPENAI_KEY- getpass securely prompts the person for his or her API key.
- The secret’s used to authenticate OpenAI API requests.
2. Hugging Face Login
- Login choices for Hugging Face:
!huggingface-cli loginProgrammatic:
from huggingfacehub import login
login()- This step ensures entry to Hugging Face’s mannequin repositories.
3. Perform: get_completion_gpt
This perform interacts with OpenAI’s GPT fashions:
- Inputs:
- immediate: The question or instruction to generate textual content for.
- mannequin: Defaults to “gpt-4o-mini“, representing the chosen OpenAI mannequin.
- Course of:
- Makes use of OpenAI’s openai.chat.completions.create to ship the immediate and mannequin settings.
- The response is parsed to return the generated content material.
- Parameters:
- temperature=0.0: Ensures deterministic responses by minimizing randomness.
Instance Name:
response = get_completion_gpt(immediate="Give me listing of F1 drivers with Firms")4. Hugging Face Transformers Setup
- Mannequin ID: “meta-llama/Llama-3.3-70B-Instruct”
- A LLaMA mannequin particularly for instruction-based duties.
Load the mannequin pipeline:
llama3 = transformers.pipeline(
"text-generation",
mannequin=model_id,
model_kwargs={"torch_dtype": torch.bfloat16}
device_map="cuda",
)- text-generation pipeline: Configures the mannequin for text-based duties.
- Gadget Map: “cuda” ensures it makes use of a GPU for sooner processing.
- Precision: torch_dtype=torch.bfloat16 optimizes reminiscence utilization whereas sustaining numerical precision.
5. Perform: get_completion_llama
This perform interacts with the LLaMA mannequin pipeline:
- Inputs:
- immediate: The question or instruction.
- model_pipeline: Defaults to the LLaMA mannequin pipeline loaded earlier.
- Course of:
- Sends the immediate to the model_pipeline for textual content technology.
- Retrieves the generated textual content content material from the response.
6. Show the Output
Markdown formatting:
show(Markdown(response))This renders the textual content response in a visually interesting Markdown format in environments like Jupyter Pocket book.
Synthetic Evaluation:
- Synthetic Evaluation – Llama 3.3 Benchmarks: This platform presents complete information on numerous fashions’ efficiency, pricing, and availability. Customers can monitor Llama 3.3’s standing amongst different fashions, making certain they continue to be knowledgeable on the newest developments.
Business Insights on X (previously Twitter):
These social media updates present first-hand insights, neighborhood reactions, and rising greatest practices for leveraging Llama 3.3 successfully.
Conclusion
Llama 3.3 represents a big leap ahead in accessible, high-performance LLMs. By matching or surpassing a lot bigger fashions in key benchmarks—whereas dramatically reducing prices—Meta has opened the door for extra builders, researchers, and organizations to combine superior AI into their merchandise and workflows.
Because the AI panorama continues to evolve, Llama 3.3 stands out not only for its technical prowess but additionally for its affordability and adaptability. Whether or not you’re an AI researcher, a startup innovator, or a longtime enterprise, Llama 3.3 offers a promising alternative to harness state-of-the-art language modeling capabilities with out breaking the financial institution.
In brief, Llama 3.3 is a mannequin value exploring. With easy accessibility, a rising variety of internet hosting suppliers, and strong neighborhood assist, it’s poised to turn out to be a go-to alternative within the new period of cost-effective, high-quality LLMs.
Additionally if you’re in search of a Generative AI course on-line then discover: GenAI Pinnacle Program
Steadily Requested Questions
Ans. Llama 3.3 70B is Meta’s newest open-source giant language mannequin with 70 billion parameters, providing efficiency similar to a lot bigger fashions like GPT-4 at a considerably decrease value.
Ans. Regardless of having fewer parameters, Llama 3.3 matches the efficiency of Llama 3.1 405B, with enhancements in effectivity, multilingual assist, and cost-effectiveness.
Ans. With pricing as little as $0.10 per million enter tokens and $0.40 per million output tokens, Llama 3.3 is 25 instances cheaper to run in comparison with some main fashions like GPT-4.
Ans. Llama 3.3 excels in instruction following, code technology, multilingual duties, and dealing with lengthy contexts, making it splendid for builders and organizations looking for excessive efficiency with out excessive prices.
Ans. You may entry Llama 3.3 through platforms like Hugging Face, Ollama, and hosted companies like Groq and Collectively AI, making it extensively obtainable for numerous use instances.
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Enthusiastic about storytelling and crafting compelling narratives that rework concepts into impactful content material. I really like studying about expertise revolutionizing our life-style.