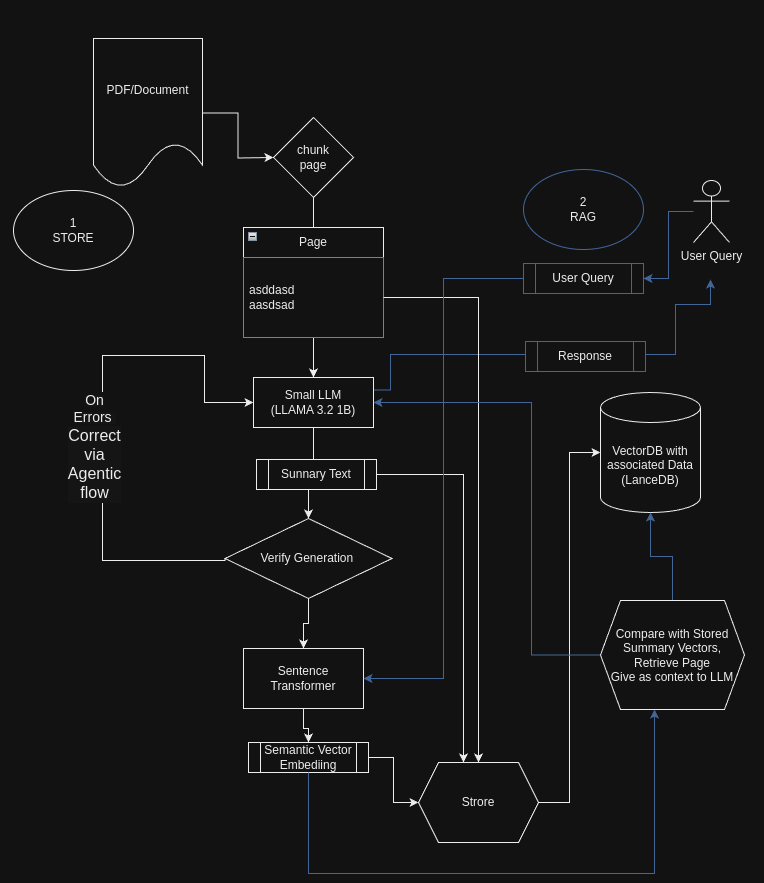
Llama-3.2–1 B-Instruct and LanceDB
Summary: Retrieval-augmented technology (RAG) combines giant language fashions with exterior information sources to provide extra correct and contextually related responses. This text explores how smaller language fashions (LLMs), just like the lately opensourced Meta 1 Billion mannequin, may be successfully utilized to summarize and index giant paperwork, thereby enhancing the effectivity and scalability of RAG programs. We offer a step-by-step information, full with code snippets, on summarize chunks of textual content from a product documentation PDF and retailer them in a LanceDB database for environment friendly retrieval.
Introduction
Retrieval-Augmented Era is a paradigm that enhances the capabilities of language fashions by integrating them with exterior information bases. Whereas giant LLMs like GPT-4 have demonstrated exceptional capabilities, they arrive with vital computational prices. Small LLMs supply a extra resource-efficient different, particularly for duties like textual content summarization and key phrase extraction, that are essential for indexing and retrieval in RAG programs.
On this article, we’ll display use a small LLM to:
- Extract and summarize textual content from a PDF doc.
- Generate embeddings for summaries and key phrases.
- Retailer the information effectively in a LanceDB database.
- Use this for efficient RAG
- Additionally a Agentic workflow for self correcting errors from the LLM
Utilizing a smaller LLM drastically reduces the fee for some of these conversions on big data-sets and will get related advantages for easier duties because the bigger parameter LLMs and might simply be hosted within the Enterprise or from the Cloud with minimal price.
We are going to use LLAMA 3.2 1 Billion parameter mannequin, the smallest state-of-the-art LLM as of now.
The Drawback with Embedding Uncooked Textual content
Earlier than diving into the implementation, it’s important to know why embedding uncooked textual content from paperwork may be problematic in RAG programs.
Ineffective Context Seize
Embedding uncooked textual content from a web page with out summarization typically results in embeddings that are:
- Excessive-dimensional noise: Uncooked textual content might comprise irrelevant data, formatting artefacts, or boilerplate language that doesn’t contribute to understanding the core content material.
- Diluted key ideas: Essential ideas could also be buried inside extraneous textual content, making the embeddings much less consultant of the essential data.
Retrieval Inefficiency
When embeddings don’t precisely symbolize the important thing ideas of the textual content, the retrieval system might fail to:
- Match person queries successfully: The embeddings may not align nicely with the question embeddings, resulting in poor retrieval of related paperwork.
- Present appropriate context: Even when a doc is retrieved, it might not supply the exact data the person is looking for as a result of noise within the embedding.
Resolution: Summarization Earlier than Embedding
Summarizing the textual content earlier than producing embeddings addresses these points by:
- Distilling Key Info: Summarization extracts the important factors and key phrases, eradicating pointless particulars.
- Bettering Embedding High quality: Embeddings generated from summaries are extra centered and consultant of the primary content material, enhancing retrieval accuracy.
Conditions
Earlier than we start, guarantee you could have the next put in:
- Python 3.7 or larger
- PyTorch
- Transformers library
- SentenceTransformers
- PyMuPDF (for PDF processing)
- LanceDB
- A laptop computer with GPU Min 6 GB or Colab (T4 GPU will likely be enough) or related
Step 1: Setting Up the Setting
First, import all the required libraries and arrange logging for debugging and monitoring.
import pandas as pd
import fitz # PyMuPDF
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import lancedb
from sentence_transformers import SentenceTransformer
import json
import pyarrow as pa
import numpy as np
import re
Step 2: Defining Helper Capabilities
Creating the Immediate
We outline a operate to create prompts suitable with the LLAMA 3.2 mannequin.
def create_prompt(query):
"""
Create a immediate as per LLAMA 3.2 format.
"""
system_message = "You're a useful assistant for summarizing textual content and lead to JSON format"
prompt_template = f'''
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_message}<|eot_id|><|start_header_id|>person<|end_header_id|>
{query}<|eot_id|><|start_header_id|>assistant1231231222<|end_header_id|>
'''
return prompt_template
Processing the Immediate
This operate processes the immediate utilizing the mannequin and tokenizer. We’re setting the temperature to 0.1 to make the mannequin much less artistic (much less hallucinating)
def process_prompt(immediate, mannequin, tokenizer, gadget, max_length=500):
"""
Processes a immediate, generates a response, and extracts the assistant's reply.
"""
prompt_encoded = tokenizer(immediate, truncation=True, padding=False, return_tensors="pt")
mannequin.eval()
output = mannequin.generate(
input_ids=prompt_encoded.input_ids.to(gadget),
max_new_tokens=max_length,
attention_mask=prompt_encoded.attention_mask.to(gadget),
temperature=0.1 # Extra deterministic
)
reply = tokenizer.decode(output[0], skip_special_tokens=True)
elements = reply.break up("assistant1231231222", 1)
if len(elements) > 1:
words_after_assistant = elements[1].strip()
return words_after_assistant
else:
print("The assistant's response was not discovered.")
return "NONE"
Step 3: Loading the Mannequin
We use the LLAMA 3.2 1B Instruct mannequin for summarization. We’re loading the mannequin with bfloat16 to scale back the reminiscence and working in NVIDIA laptop computer GPU (NVIDIA GeForce RTX 3060 6 GB/ Driver NVIDIA-SMI 555.58.02/Cuda compilation instruments, launch 12.5, V12.5.40) in a Linux OS.
Higher can be to host through vLLM or higher exLLamaV2
model_name_long = "meta-llama/Llama-3.2-1B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_long)
gadget = torch.gadget("cuda" if torch.cuda.is_available() else "cpu")
log.information(f"Loading the mannequin {model_name_long}")
bf16 = False
fp16 = True
if torch.cuda.is_available():
main, _ = torch.cuda.get_device_capability()
if main >= 8:
log.information("Your GPU helps bfloat16: speed up coaching with bf16=True")
bf16 = True
fp16 = False
# Load the mannequin
device_map = {"": 0} # Load on GPU 0
torch_dtype = torch.bfloat16 if bf16 else torch.float16
mannequin = AutoModelForCausalLM.from_pretrained(
model_name_long,
torch_dtype=torch_dtype,
device_map=device_map,
)
log.information(f"Mannequin loaded with torch_dtype={torch_dtype}")
Step 4: Studying and Processing the PDF Doc
We extract textual content from every web page of the PDF doc.
file_path = './knowledge/troubleshooting.pdf'
dict_pages = {}
# Open the PDF file
with fitz.open(file_path) as pdf_document:
for page_number in vary(pdf_document.page_count):
web page = pdf_document.load_page(page_number)
page_text = web page.get_text()
dict_pages[page_number] = page_text
print(f"Processed PDF web page {page_number + 1}")
Step 5: Setting Up LanceDB and SentenceTransformer
We initialize the SentenceTransformer mannequin for producing embeddings and arrange LanceDB for storing the information. We’re utilizing PyArrow primarily based Schema for the LanceDB tables
Observe that key phrases are usually not used now however can be utilized for hybrid search, that’s vector similarity search in addition to textual content search if wanted.
# Initialize the SentenceTransformer mannequin
sentence_model = SentenceTransformer('all-MiniLM-L6-v2')
# Hook up with LanceDB
db = lancedb.join('./knowledge/my_lancedb')
# Outline the schema utilizing PyArrow
schema = pa.schema([
pa.field("page_number", pa.int64()),
pa.field("original_content", pa.string()),
pa.field("summary", pa.string()),
pa.field("keywords", pa.string()),
pa.field("vectorS", pa.list_(pa.float32(), 384)), # Embedding size of 384
pa.field("vectorK", pa.list_(pa.float32(), 384)),
])
# Create or connect with a desk
desk = db.create_table('summaries', schema=schema, mode='overwrite')
Step 6: Summarizing and Storing Information
We loop by means of every web page, generate a abstract and key phrases, and retailer them together with embeddings within the database.
# Loop by means of every web page within the PDF
for page_number, textual content in dict_pages.objects():
query = f"""For the given passage, present a protracted abstract about it, incorporating all the primary key phrases within the passage.
Format needs to be in JSON format like beneath:
{{
"abstract": <textual content abstract>,
"key phrases": <a comma-separated listing of most important key phrases and acronyms that seem within the passage>,
}}
Ensure that JSON fields have double quotes and use the right closing delimiters.
Passage: {textual content}"""
immediate = create_prompt(query)
response = process_prompt(immediate, mannequin, tokenizer, gadget)
# Error dealing with for JSON decoding
attempt:
summary_json = json.masses(response)
besides json.decoder.JSONDecodeError as e:
exception_msg = str(e)
query = f"""Appropriate the next JSON {response} which has {exception_msg} to correct JSON format. Output solely JSON."""
log.warning(f"{exception_msg} for {response}")
immediate = create_prompt(query)
response = process_prompt(immediate, mannequin, tokenizer, gadget)
log.warning(f"Corrected '{response}'")
attempt:
summary_json = json.masses(response)
besides Exception as e:
log.error(f"Didn't parse JSON: '{e}' for '{response}'")
proceed
key phrases = ', '.be a part of(summary_json['keywords'])
# Generate embeddings
vectorS = sentence_model.encode(summary_json['summary'])
vectorK = sentence_model.encode(key phrases)
# Retailer the information in LanceDB
desk.add([{
"page_number": int(page_number),
"original_content": text,
"summary": summary_json['summary'],
"key phrases": key phrases,
"vectorS": vectorS,
"vectorK": vectorK
}])
print(f"Information for web page {page_number} saved efficiently.")
Utilizing LLMs to Appropriate Their Outputs
When producing summaries and extracting key phrases, LLMs might generally produce outputs that aren’t within the anticipated format, similar to malformed JSON.
We will leverage the LLM itself to appropriate these outputs by prompting it to repair the errors. That is proven within the code above
# Use the Small LLAMA 3.2 1B mannequin to create abstract
for page_number, textual content in dict_pages.objects():
query = f"""For the given passage, present a protracted abstract about it, incorporating all the primary key phrases within the passage.
Format needs to be in JSON format like beneath:
{{
"abstract": <textual content abstract> instance "Some Abstract textual content",
"key phrases": <a comma separated listing of most important key phrases and acronyms that seem within the passage> instance ["keyword1","keyword2"],
}}
Ensure that JSON fields have double quotes, e.g., as a substitute of 'abstract' use "abstract", and use the closing and ending delimiters.
Passage: {textual content}"""
immediate = create_prompt(query)
response = process_prompt(immediate, mannequin, tokenizer, gadget)
attempt:
summary_json = json.masses(response)
besides json.decoder.JSONDecodeError as e:
exception_msg = str(e)
# Use the LLM to appropriate its personal output
query = f"""Appropriate the next JSON {response} which has {exception_msg} to correct JSON format. Output solely the corrected JSON.
Format needs to be in JSON format like beneath:
{{
"abstract": <textual content abstract> instance "Some Abstract textual content",
"key phrases": <a comma separated listing of key phrases and acronyms that seem within the passage> instance ["keyword1","keyword2"],
}}"""
log.warning(f"{exception_msg} for {response}")
immediate = create_prompt(query)
response = process_prompt(immediate, mannequin, tokenizer, gadget)
log.warning(f"Corrected '{response}'")
# Attempt parsing the corrected JSON
attempt:
summary_json = json.masses(response)
besides json.decoder.JSONDecodeError as e:
log.error(f"Didn't parse corrected JSON: '{e}' for '{response}'")
proceed
On this code snippet, if the LLM’s preliminary output can’t be parsed as JSON, we immediate the LLM once more to appropriate the JSON. This self-correction sample improves the robustness of our pipeline.
Suppose the LLM generates the next malformed JSON:
{
'abstract': 'This web page explains the set up steps for the product.',
'key phrases': ['installation', 'setup', 'product']
}
Making an attempt to parse this JSON ends in an error resulting from using single quotes as a substitute of double quotes. We catch this error and immediate the LLM to appropriate it:
exception_msg = "Anticipating property title enclosed in double quotes"
query = f"""Appropriate the next JSON {response} which has {exception_msg} to correct JSON format. Output solely the corrected JSON."""
The LLM then gives the corrected JSON:
{
"abstract": "This web page explains the set up steps for the product.",
"key phrases": ["installation", "setup", "product"]
}
By utilizing the LLM to appropriate its personal output, we make sure that the information is within the appropriate format for downstream processing.
Extending Self-Correction through LLM Brokers
This sample of utilizing the LLM to appropriate its outputs may be prolonged and automatic by means of using LLM Brokers. LLM Brokers can:
- Automate Error Dealing with: Detect errors and autonomously resolve appropriate them with out express directions.
- Enhance Effectivity: Cut back the necessity for guide intervention or extra code for error correction.
- Improve Robustness: Constantly be taught from errors to enhance future outputs.
LLM Brokers act as intermediaries that handle the stream of data and deal with exceptions intelligently. They are often designed to:
- Parse outputs and validate codecs.
- Re-prompt the LLM with refined directions upon encountering errors.
- Log errors and corrections for future reference and mannequin fine-tuning.
Approximate Implementation:
As an alternative of manually catching exceptions and re-prompting, an LLM Agent might encapsulate this logic:
def generate_summary_with_agent(textual content):
agent = LLMAgent(mannequin, tokenizer, gadget)
query = f"""For the given passage, present a abstract and key phrases in correct JSON format."""
immediate = create_prompt(query)
response = agent.process_and_correct(immediate)
return response
The LLMAgent class would deal with the preliminary processing, error detection, re-prompting, and correction internally.
Now lets see how we will use the Embeddings for an efficient RAG sample once more utilizing the LLM to assist in rating.
Retrieval and Era: Processing the Consumer Question
That is the standard stream. We take the person’s query and seek for probably the most related summaries.
# Instance utilization
user_question = "Not capable of handle new gadgets"
outcomes = search_summary(user_question, sentence_model)
Getting ready the Retrieved Summaries
We compile the retrieved summaries into a listing, associating every abstract with its web page quantity for reference.
summary_list = []
for idx, lead to enumerate(outcomes):
summary_list.append(f"{consequence['page_number']}# {consequence['summary']}")
Rating the Summaries
We immediate the language mannequin to rank the retrieved summaries primarily based on their relevance to the person’s query and choose probably the most related one. That is once more utilizing the LLM in rating the summaries than the Ok-Nearest Neighbour or Cosine distance or different rating algorithms alone for the contextual embedding (vector) match.
query = f"""From the given listing of summaries {summary_list}, rank which abstract may have
the reply to the query '{user_question}'. Return solely that abstract from the listing."""
log.information(query)
Extracting the Chosen Abstract and Producing the Remaining Reply
We retrieve the unique content material related to the chosen abstract and immediate the language mannequin to generate an in depth reply to the person’s query utilizing this context.
for idx, lead to enumerate(outcomes):
if int(page_number) == consequence['page_number']:
web page = consequence['original_content']
query = f"""Are you able to reply the question: '{user_question}'
utilizing the context beneath?
Context: '{web page}'
"""
log.information(query)
immediate = create_prompt(
query,
"You're a useful assistant that may undergo the given question and context, suppose in steps, after which attempt to reply the question
with the knowledge within the context."
)
response = process_prompt(immediate, mannequin, tokenizer, gadget, temperature=0.01) # Much less freedom to hallucinate
log.information(response)
print("Remaining Reply:")
print(response)
break
Clarification of the Workflow
- Consumer Question Vectorization: The person’s query is transformed into an embedding utilizing the identical SentenceTransformer mannequin used throughout indexing.
- Similarity Search: The question embedding is used to look the vector database (LanceDB) for probably the most related summaries and return Prime 3
>> From the VectorDB Cosine search and Prime 3 nearest neighbour search consequence,
prepended by linked web page numbers
07:04:00 INFO:From the given listing of abstract [[
'112# Cannot place newly discovered device in managed state',
'113# The passage discusses the troubleshooting steps for managing newly discovered devices on the NSF platform, specifically addressing issues with device placement, configuration, and deployment.',
'116# Troubleshooting Device Configuration Backup Issue']] rank which abstract may have the doable reply to the query Not capable of handle new gadgets. Return solely that abstract from the listing
3. Abstract Rating: The retrieved summaries are handed to the language mannequin, which ranks them primarily based on relevance to the person’s query.
>> Asking LLM to Choose from the Prime N primarily based on context
07:04:01 INFO:Chosen Abstract ''113# The passage discusses the troubleshooting steps for managing newly found gadgets on the NSF (Community Methods and Useful Necessities) platform, particularly addressing points with gadget placement, configuration, and deployment.''
4. Context Retrieval: The unique content material related to probably the most related abstract is retrieved by parsing out the web page quantity and getting the related web page from the LanceDB
07:04:01 INFO:Web page quantity: 113
07:04:01 INFO:Are you able to reply the query or question or present extra deatils question:'Not capable of handle new gadgets' Utilizing the context beneath
context:'3
Examine that the server and shopper platforms are appropriately sized. ...
Failed SNMP communication between the server and managed gadget.
SNMP traps from managed gadgets are arriving at one server,
or no SNMP traps are ....
'
5. Reply Era: The language mannequin generates an in depth reply to the person’s query utilizing the retrieved context.
Here’s a pattern output from a pattern PDF I’ve used
07:04:08 INFO:I'll undergo the steps and supply extra particulars to reply the question.
The question is: "Not capable of handle new gadgets"
Right here's my step-by-step evaluation:
**Step 1: Examine that the server and shopper platforms are appropriately sized**
The context mentions that the NSP Planning Information is obtainable, which suggests that the NSP (Community Service Supplier) has a planning course of to make sure that the server and shopper platforms are sized accurately. This implies that the NSP has a course of in place to judge the efficiency and capability of the server and shopper platforms to find out if they're appropriate for managing new gadgets.
**Step 2: Examine for resynchronization issues between the managed community and the NFM-P**
The context additionally mentions that resynchronization issues between the managed community and the NFM-P could cause points with managing new gadgets. This means that there could also be an issue with the communication between the server and shopper platforms, which may forestall new gadgets from being efficiently managed.
**Step 3: Examine for failed SNMP communication between the server and managed gadget**
The context particularly mentions that failed SNMP communication between the server and managed gadget could cause points with managing new gadgets. This implies that there could also be an issue with the communication between the server and the managed gadget, which may forestall new gadgets from being efficiently managed.
**Step 4: Examine for failed deployment of the configuration request**
The context additionally mentions that failed deployment of the configuration request could cause points with managing new gadgets. This means that there could also be an issue with the deployment course of, which may forestall new gadgets from being efficiently managed.
**Step 5: Carry out the next steps**
The context instructs the person to carry out the next steps:
1. Select Administration→NE Upkeep→Deployment from the XXX most important menu.
2. The Deployment type opens, itemizing incomplete deployments, deployer, tag, state, and different data.
Based mostly on the context, it seems that the person must evaluate the deployment historical past to establish any points that could be stopping the deployment of recent gadgets.
**Reply**
Based mostly on the evaluation, the person must:
1. Examine that the server and shopper platforms are appropriately sized.
2. Examine for resynchronization issues between the managed community and the NFM-P.
3. Examine for failed SNMP communication between the server and managed gadget.
4. Examine for failed deployment of the configuration request.
By following these steps, the person ought to be capable of establish and resolve the problems stopping the administration of
Conclusion
We will effectively summarise and extract key phrases from giant paperwork utilizing a small LLM like LLAMA 3.2 1B Instruct. These summaries and key phrases may be embedded and saved in a database like LanceDB, enabling environment friendly retrieval for RAG programs utilizing the LLM within the workflow and never simply in technology
References
- Meta LLAMA 3.2 1B Instruct Mannequin
- SentenceTransformers
- LanceDB
- PyMuPDF Documentation
Leveraging Smaller LLMs for Enhanced Retrieval-Augmented Era (RAG) was initially revealed in In direction of Information Science on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.