Introduction
In an period the place info is at our fingertips, the power to ask a query and obtain a exact reply has turn into essential. Think about having a system that understands the intricacies of language and delivers correct responses to your queries immediately. This text explores methods to construct such a strong question-answer mannequin utilizing the Common Sentence Encoder and the WikiQA dataset. By leveraging superior embedding fashions, we goal to bridge the hole between human curiosity and machine intelligence, making a seamless interplay that may revolutionize how we search and acquire info.
Studying Aims
- Achieve proficiency in utilizing embedding fashions just like the Common Sentence Encoder to rework textual information into high-dimensional vector representations.
- Perceive the challenges and methods concerned in choosing and fine-tuning pre-trained fashions.
- By means of hands-on expertise, learners will implement a question-answering system that makes use of embedding fashions and cosine similarity.
- Perceive the rules behind cosine similarity and its software in measuring the similarity between vectorized textual content representations.
This text was revealed as part of the Knowledge Science Blogathon.
Leveraging Embedding Fashions in NLP
We will use embedded fashions that are one kind of machine studying mannequin extensively utilized in pure language processing (NLP). This method transforms texts into numerical codecs that seize their meanings. Phrases, phrases or sentences are transformed into numerical vectors termed as embeddings. Algorithms make use of those embeddings to grasp and manipulate the textual content in some ways.
Understanding Embedding Fashions
Phrase embeddings signify phrases effectively in a dense numerical format, the place related phrases obtain related encodings. In contrast to manually setting these encodings, the mannequin learns embeddings as trainable parameters—floating level values that it adjusts throughout coaching, just like the way it learns weights in a dense layer. Embeddings vary from 300 for smaller fashions and datasets to bigger dimensions like 1024 for bigger fashions and datasets, permitting them to seize relationships between phrases. This increased dimensionality allows embeddings to encode detailed semantic relationships.
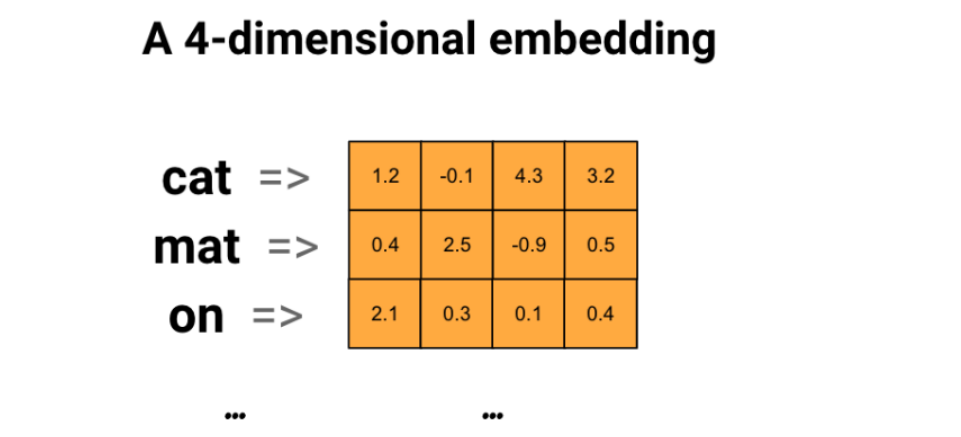
In a phrase embedding diagram, we painting every phrase as a four-dimensional vector of floating level values. We will consider embeddings as a “lookup desk,” the place we retailer every phrase’s dense vector after coaching, permitting fast encoding and retrieval based mostly on its corresponding vector illustration.
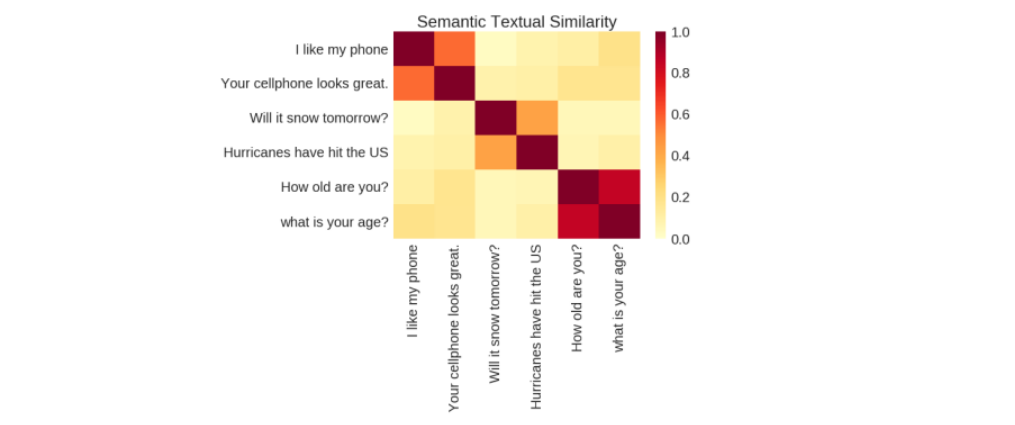
Semantic Similarity: Measuring Which means in Textual content
Semantic similarity is the measure of how carefully two items of textual content convey the identical that means. It’s useful as a result of it helps methods perceive the assorted methods folks articulate concepts in language with out requiring express definitions for every variation.
Common Sentence Encoder for Enhanced Textual content Processing
On this mission we will likely be making use of the Common Sentence Encoder which transforms textual content into high-dimensional vectors helpful for duties like textual content classification, semantic similarity, and clustering amongst others. It’s optimized for processing textual content longer than single phrases . It’s educated on numerous datasets and adapts to numerous pure language duties. Inputting variable-length English textual content yields a 512-dimensional vector as output.
The next are instance embedding output of 512 dimensions per sentence:
!pip set up tensorflow tensorflow-hub
import tensorflow as tf
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
sentences = [
"The quick brown fox jumps over the lazy dog.",
"I am a sentence for which I would like to get its embedding"
]
embeddings = embed(sentences)
print(embeddings)
print(embeddings.numpy())Output:

This encoder employs a deep averaging community (DAN) for coaching, distinguishing itself from word-level embedding fashions by specializing in understanding the that means of sequences of phrases, not simply particular person phrases. For extra on textual content embeddings, seek the advice of TensorFlow’s Embeddings documentation. Additional technical particulars may be discovered within the paper “Common Sentence Encoder” right here.
The module preprocesses textual content enter as greatest as it will probably, so that you don’t must preprocess the information earlier than making use of it.

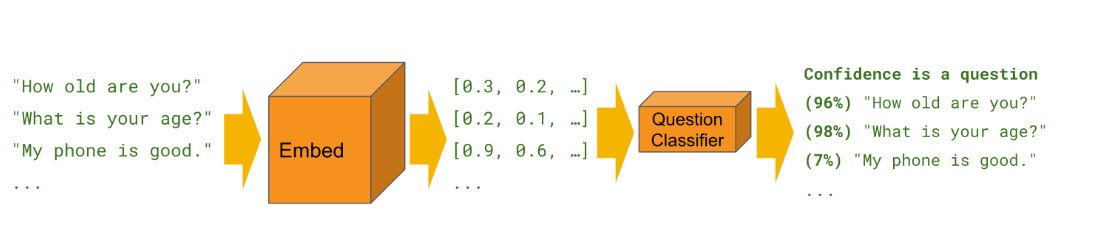
Builders partially educated the Common Sentence Encoder with customized textual content classification duties in thoughts. We will prepare these classifiers to carry out all kinds of classification duties, typically with a really small quantity of labeled examples.
Code Implementation for a Query-Reply Generator
The dataset used for this code is from the WikiQA Dataset .
import pandas as pd
import tensorflow_hub as hub #offers pre-trained fashions and modules just like the USE.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# Load dataset (regulate the trail accordingly)
df = pd.read_csv('/content material/prepare.csv')
questions = df['question'].tolist()
solutions = df['answer'].tolist()
# Load Common Sentence Encoder
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
# Compute embeddings
question_embeddings = embed(questions)
answer_embeddings = embed(solutions)
# Calculate similarity scores
similarity_scores = cosine_similarity(question_embeddings, answer_embeddings)
# Predict solutions
predicted_indices = np.argmax(similarity_scores, axis=1) # finds the index of the reply with the very best similarity rating.
predictions = [answers[idx] for idx in predicted_indices]
# Print questions and predicted solutions
for i, query in enumerate(questions):
print(f"Query: {query}")
print(f"Predicted Reply: {predictions[i]}n")

Let’s modify the code to ask customized questions print essentially the most related query and the expected reply:
def ask_question(new_question):
new_question_embedding = embed([new_question])
similarity_scores = cosine_similarity(new_question_embedding, question_embeddings)
most_similar_question_idx = np.argmax(similarity_scores)
most_similar_question = questions[most_similar_question_idx]
predicted_answer = solutions[most_similar_question_idx]
return most_similar_question, predicted_answer
# Instance utilization
new_question = "When was Apple Pc based?"
most_similar_question, predicted_answer = ask_question(new_question)
print(f"New Query: {new_question}")
print(f"Most Related Query: {most_similar_question}")
print(f"Predicted Reply: {predicted_answer}")Output:

New Query: When was Apple Pc based?
Most Related Query: When was Apple Pc based.
Predicted Reply: Apple Inc., previously Apple Pc, Inc., designs, develops, and sells client electronics, pc software program, and private computer systems. This American multinational company is headquartered in Cupertino, California.
Benefits of Utilizing Embedding Fashions in NLP Duties
- Many embedding fashions, just like the Common Sentence Encoder come pre-trained on huge quantities of knowledge this reduces the necessity for in depth coaching on particular datasets and permitting faster deployment thus saving computational assets.
- By representing textual content in a high-dimensional house embedding methods can acknowledge and match semantically related phrases, even when they use completely different phrases comparable to synonyms and paraphrased questions.
- We will prepare many embedding fashions to work with a number of languages, making it simpler to develop multilingual question-answering methods.
- Embedding methods simplify the method of function engineering wanted for machine studying fashions course of by robotically studying the options from the information.
Challenges in Query-Reply Generator
- Selecting the best pre-trained mannequin and fine-tuning parameters for particular use circumstances may be difficult.
- Dealing with giant volumes of knowledge effectively in real-time functions requires cautious optimization and may be difficult.
- Nuances, intricate element and context misinterpretation in language that will result in wrongly generated outcomes.
Conclusion
Embedding fashions can thus enhance question-answering methods. Changing the textual content into embeddings and calculating similarity scores helps the system precisely determine and predict related solutions to person questions. This method enhances the use circumstances of embedded fashions in NLP associated duties which contain human interplay.
Key Learnings
- Embedding fashions just like the Common Sentence Encoder gives instruments for changing textual content into numerical representations.
- Utilizing embedding based mostly query answering system improves person interplay by delivering correct and related responses.
- We face challenges like semantic ambiguity, numerous queries, and sustaining computational effectivity.
Steadily Requested Questions
A. Embedding fashions, just like the Common Sentence Encoder, flip textual content into detailed numerical varieties known as embeddings. These assist methods perceive and provides correct solutions to person questions.
A. Many embedding fashions can work with a number of languages. We will use them in methods that reply questions in numerous languages, making these methods very versatile.
A. Embedding methods are good at recognizing and matching phrases comparable to synonyms and understanding various kinds of language duties.
A. Selecting the best mannequin and setting it up for particular duties may be tough. Additionally, managing giant quantities of knowledge shortly, particularly in real-time conditions, wants cautious planning.
A. By turning textual content into embeddings and checking how related they’re, embedding fashions may give very correct solutions to person questions. This makes customers happier as a result of they get solutions that match precisely what they requested.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.