OpenAI’s Agent SDK has taken issues up a notch with the discharge of its Voice Agent characteristic, enabling you to create clever, real-time, speech-driven purposes. Whether or not you’re constructing a language tutor, a digital assistant, or a assist bot, this new functionality brings in an entire new degree of interplay—pure, dynamic, and human-like. Let’s break it down and stroll by means of what it’s, the way it works, and how one can construct a Multilingual Voice Agent your self.
What’s a Voice Agent?
A Voice Agent is a system that listens to your voice, understands what you’re saying, thinks a couple of response, after which replies out loud. The magic is powered by a mixture of speech-to-text, language fashions, and text-to-speech applied sciences.
The OpenAI Agent SDK makes this extremely accessible by means of one thing referred to as a VoicePipeline—a structured 3-step course of:
- Speech-to-text (STT): Captures and converts your spoken phrases into textual content.
- Agentic logic: That is your code (or your agent), which figures out the suitable response.
- Textual content-to-speech (TTS): Converts the agent’s textual content reply again into audio that’s spoken aloud.
Selecting the Proper Structure
Relying in your use case, you’ll need to choose considered one of two core architectures supported by OpenAI:
1. Speech-to-Speech (Multimodal) Structure
That is the real-time, all-audio method utilizing fashions like gpt-4o-realtime-preview. As a substitute of translating to textual content behind the scenes, the mannequin processes and generates speech straight.
Why use this?
- Low-latency, real-time interplay
- Emotion and vocal tone understanding
- Clean, pure conversational move
Good for:
- Language Tutoring
- Stay conversational brokers
- Interactive storytelling or studying apps
| Strengths | Finest For |
|---|---|
| Low latency | Interactive, unstructured dialogue |
| Multimodal understanding (voice, tone, pauses) | Actual-time engagement |
| Emotion-aware replies | Buyer assist, digital companions |
This method makes conversations really feel fluid and human however might have extra consideration in edge instances like logging or precise transcripts.
2. Chained Structure
The chained technique is extra conventional: Speech will get changed into textual content, the LLM processes that textual content, after which the reply is turned again into speech. The really helpful fashions listed here are:
- gpt-4o-transcribe (for STT)
- gpt-4o (for logic)
- gpt-4o-mini-tts (for TTS)
Why use this?
- Want transcripts for audit/logging
- Have structured workflows like customer support or lead qualification
- Need predictable, controllable behaviour
Good for:
- Assist bots
- Gross sales brokers
- Activity-specific assistants
| Strengths | Finest For |
|---|---|
| Excessive management & transparency | Structured workflows |
| Dependable, text-based processing | Apps needing transcripts |
| Predictable outputs | Buyer-facing scripted flows |
That is simpler to debug and an important place to begin for those who’re new to voice brokers.
How Does Voice Agent Work?
We arrange a VoicePipeline with a customized workflow. This workflow runs an Agent, however it might additionally set off particular responses for those who say a secret phrase.
Right here’s what occurs while you converse:
- Audio goes to the VoicePipeline as you discuss.
- Whenever you cease talking, the pipeline kicks in.
- The pipeline then:
- Transcribes your speech to textual content.
- Sends the transcription to the workflow, which runs the Agent logic.
- Streams the Agent’s reply to a text-to-speech (TTS) mannequin.
- Performs the generated audio again to you.
It’s real-time, interactive, and good sufficient to react in a different way for those who slip in a hidden phrase.
Configuring a Pipeline
When organising a voice pipeline, there are a number of key parts you possibly can customise:
- Workflow: That is the logic that runs each time new audio is transcribed. It defines how the agent processes and responds.
- STT and TTS Fashions: Select which speech-to-text and text-to-speech fashions your pipeline will use.
- Config Settings: That is the place you fine-tune how your pipeline behaves:
- Mannequin Supplier: A mapping system that hyperlinks mannequin names to precise mannequin situations.
- Tracing Choices: Management whether or not tracing is enabled, whether or not to add audio recordsdata, assign workflow names, hint IDs, and extra.
- Mannequin-Particular Settings: Customise prompts, language preferences, and supported knowledge varieties for each TTS and STT fashions.
Operating a Voice Pipeline
To kick off a voice pipeline, you’ll use the run() technique. It accepts audio enter in considered one of two kinds, relying on the way you’re dealing with speech:
- AudioInput is good when you have already got a full audio clip or transcript. It’s good for instances the place you already know when the speaker is finished, like with pre-recorded audio or push-to-talk setups. No want for reside exercise detection right here.
- StreamedAudioInput is designed for real-time, dynamic enter. You feed in audio chunks as they’re captured, and the voice pipeline robotically figures out when to set off the agent logic utilizing one thing referred to as exercise detection. That is tremendous useful while you’re coping with open mics or hands-free interplay the place it’s not apparent when the speaker finishes.
Understanding the Outcomes
As soon as your pipeline is operating, it returns a StreamedAudioResult, which helps you to stream occasions in actual time because the interplay unfolds. These occasions are available in a number of flavors:
- VoiceStreamEventAudio – Accommodates chunks of audio output (i.e., what the agent is saying).
- VoiceStreamEventLifecycle – Marks vital lifecycle occasions, like the beginning or finish of a dialog flip.
- VoiceStreamEventError – Alerts that one thing went incorrect.
Palms-on Voice Agent Utilizing OpenAI Agent SDK
Right here’s a cleaner, well-structured model of your information for organising a Palms-on Voice Agent utilizing OpenAI Agent SDK, with detailed steps, grouping, and readability enhancements. It’s all nonetheless informal and sensible, however extra readable and actionable:
1. Set Up Your Undertaking Listing
mkdir my_project
cd my_project
2. Create & Activate a Digital Surroundings
Create the surroundings:
python -m venv .venvActivate it:
supply .venv/bin/activate3. Set up OpenAI Agent SDK
pip set up openai-agent4. Set an OpenAI API key
export OPENAI_API_KEY=sk-...5. Clone the Instance Repository
git clone https://github.com/openai/openai-agents-python.git6. Modify the Instance Code for Hindi Agent & Audio Saving
Navigate to the instance file:
cd openai-agents-python/examples/voice/staticNow, edit foremost.py:
You’ll do two key issues:
- Add a Hindi agent
- Allow audio saving after playback
Exchange all the content material in foremost.py. That is the ultimate code right here:
import asyncio
import random
from brokers import Agent, function_tool
from brokers.extensions.handoff_prompt import prompt_with_handoff_instructions
from brokers.voice import (
AudioInput,
SingleAgentVoiceWorkflow,
SingleAgentWorkflowCallbacks,
VoicePipeline,
)
from .util import AudioPlayer, record_audio
@function_tool
def get_weather(metropolis: str) -> str:
print(f"[debug] get_weather referred to as with metropolis: {metropolis}")
decisions = ["sunny", "cloudy", "rainy", "snowy"]
return f"The climate in {metropolis} is {random.alternative(decisions)}."
spanish_agent = Agent(
identify="Spanish",
handoff_description="A spanish talking agent.",
directions=prompt_with_handoff_instructions(
"You are talking to a human, so be well mannered and concise. Converse in Spanish.",
),
mannequin="gpt-4o-mini",
)
hindi_agent = Agent(
identify="Hindi",
handoff_description="A hindi talking agent.",
directions=prompt_with_handoff_instructions(
"You are talking to a human, so be well mannered and concise. Converse in Hindi.",
),
mannequin="gpt-4o-mini",
)
agent = Agent(
identify="Assistant",
directions=prompt_with_handoff_instructions(
"You are talking to a human, so be well mannered and concise. If the consumer speaks in Spanish, handoff to the spanish agent. If the consumer speaks in Hindi, handoff to the hindi agent.",
),
mannequin="gpt-4o-mini",
handoffs=[spanish_agent, hindi_agent],
instruments=[get_weather],
)
class WorkflowCallbacks(SingleAgentWorkflowCallbacks):
def on_run(self, workflow: SingleAgentVoiceWorkflow, transcription: str) -> None:
print(f"[debug] on_run referred to as with transcription: {transcription}")
async def foremost():
pipeline = VoicePipeline(
workflow=SingleAgentVoiceWorkflow(agent, callbacks=WorkflowCallbacks())
)
audio_input = AudioInput(buffer=record_audio())
outcome = await pipeline.run(audio_input)
# Create an inventory to retailer all audio chunks
all_audio_chunks = []
with AudioPlayer() as participant:
async for occasion in outcome.stream():
if occasion.kind == "voice_stream_event_audio":
audio_data = occasion.knowledge
participant.add_audio(audio_data)
all_audio_chunks.append(audio_data)
print("Obtained audio")
elif occasion.kind == "voice_stream_event_lifecycle":
print(f"Obtained lifecycle occasion: {occasion.occasion}")
# Save the mixed audio to a file
if all_audio_chunks:
import wave
import os
import time
os.makedirs("output", exist_ok=True)
filename = f"output/response_{int(time.time())}.wav"
with wave.open(filename, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(16000)
wf.writeframes(b''.be part of(all_audio_chunks))
print(f"Audio saved to {filename}")
if __name__ == "__main__":
asyncio.run(foremost())
6. Run the Voice Agent
Be sure to’re within the appropriate listing:
cd openai-agents-pythonThen, launch it:
python -m examples.voice.static.foremostI requested the agent two issues, one in English and one in Hindi:
- Voice Immediate: Hey, voice agent, what’s a big language mannequin?
- Voice Immediate: “मुझे दिल्ली के बारे में बताओ
Right here’s the terminal:
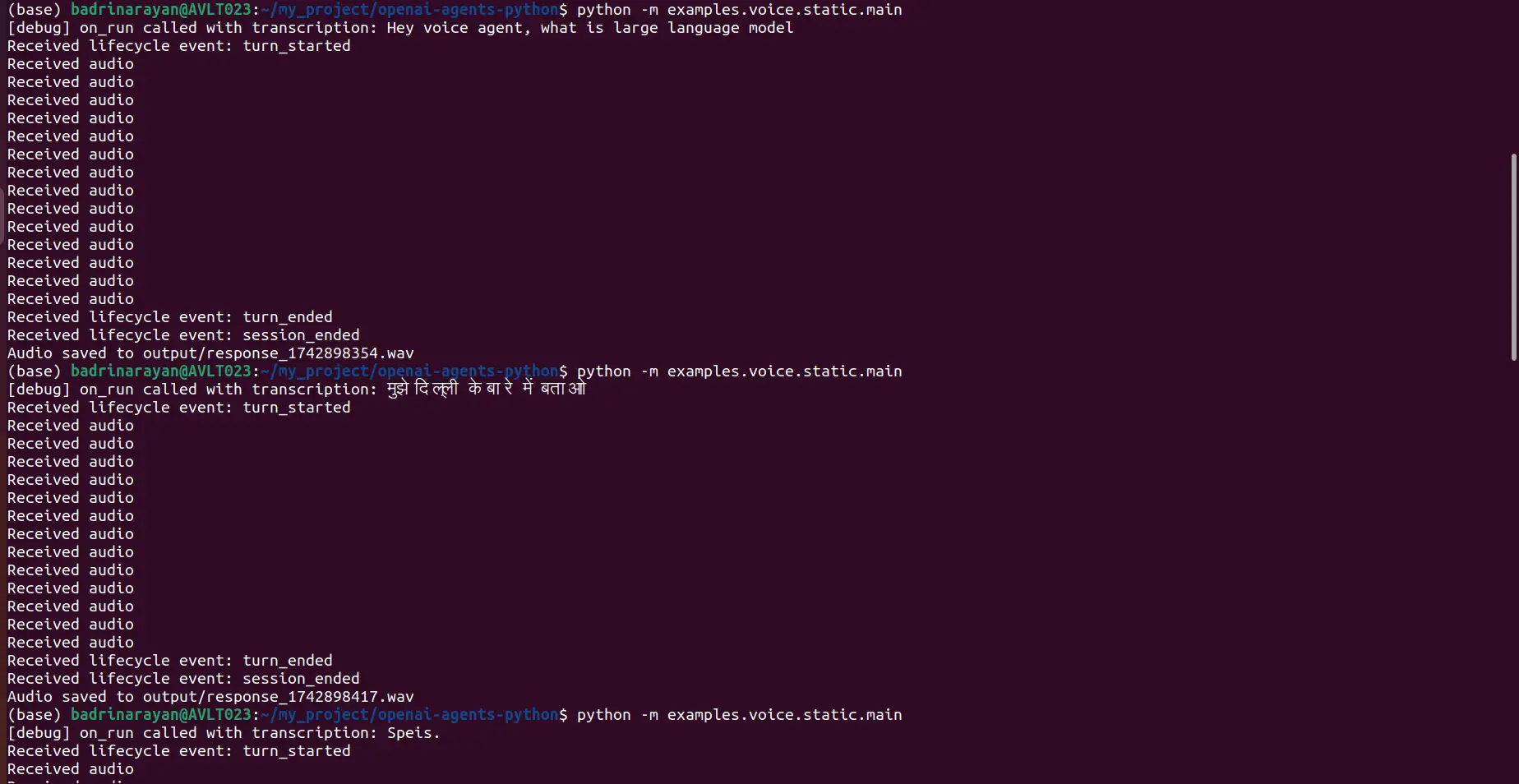
Output
English Response:
Hindi Response:
Extra Assets
Wish to dig deeper? Examine these out:
Additionally learn: OpenAI’s Audio Fashions: Methods to Entry, Options, Functions, and Extra
Conclusion
Constructing a voice agent with the OpenAI Agent SDK is far more accessible now—you don’t have to sew collectively a ton of instruments anymore. Simply choose the fitting structure, arrange your VoicePipeline, and let the SDK do the heavy lifting.
Should you’re going for high-quality conversational move, go multimodal. If you’d like construction and management, go chained. Both approach, this tech is highly effective, and it’s solely going to get higher. If you’re creating one, let me know within the remark part under.
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Obsessed with storytelling and crafting compelling narratives that rework concepts into impactful content material. I like studying about know-how revolutionizing our life-style.
Login to proceed studying and luxuriate in expert-curated content material.