Introduction
Within the not-so-distant previous, the thought of getting a private AI assistant felt like one thing out of a sci-fi film. Image a tech-savvy inventor named Alex, who dreamed of getting a sensible companion to reply questions and supply insights, with out counting on the cloud or third-party servers. With developments in small language fashions (SLMs), Alex’s dream turned a actuality. This text will take you on Alex’s journey to construct an AI Chat CLI utility utilizing Huggingface’s progressive SmolLM mannequin. We’ll mix the ability of SmolLM with LangChain’s flexibility and Typer’s user-friendly interface. By the top, you’ll have a useful AI assistant, similar to Alex, able to chatting, answering queries, and saving conversations—all out of your terminal. Let’s dive into this thrilling new world of on-device AI and see what you possibly can create.
Studying Outcomes
- Perceive Huggingface SmolLM fashions and their functions.
- Leverage SLM fashions for on-device AI functions.
- Discover Grouped-Question Consideration and its position in SLM structure.
- Construct interactive CLI functions utilizing the Typer and Wealthy libraries.
- Combine Huggingface fashions with LangChain for strong AI functions.
This text was printed as part of the Information Science Blogathon.
What’s Huggingface SmolLM?
SmolLM is a collection of state-of-the-art small language fashions out there in three sizes 135M, 360M, and 1.7B parameters. These fashions are constructed on a high-quality coaching corpus named Cosmopedia V2 which is the gathering of artificial textbooks and tales generated by Mixtral (28B tokens), Python-Edu instructional Python samples from The Stack (4B tokens), and FineWeb-Edu, an academic internet samples from FineWeb(220B tokens)based on Huggingface these fashions outperform different fashions within the measurement classes throughout a numerous benchmark, testing frequent sense causes, and world data.
Efficiency Comparability Chart
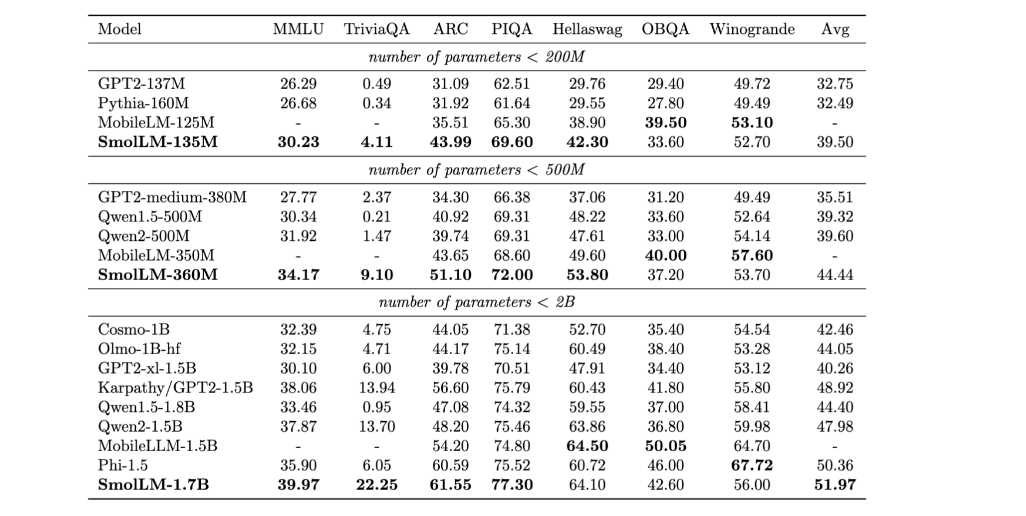
It makes use of 5000 subjects belonging to 51 classes generated utilizing Mixtral to create subtopics for sure subjects, and the ultimate distribution of subtopics is beneath:
The structure of 135M and 260M parameter fashions, makes use of a design much like MobileLLM, incorporating Grouped-Question Consideration (GQA) and prioritizing depth over width.
What’s Grouped-Question-Consideration?
There are three kinds of Consideration structure:
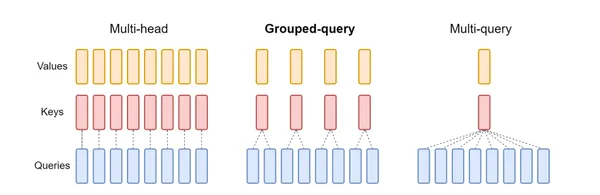
- Multi-Head Consideration (MHA): Every consideration head has its personal unbiased question, key, and worth heads. That is computationally costly, particularly for giant fashions.
- Multi-Question Consideration (MQA): Shares key and worth heads throughout all consideration heads, however every head has its question, That is extra environment friendly than MHA however can nonetheless be computationally intensive.
- Group-Question Consideration(GQA): Think about you will have a group engaged on a giant undertaking. As an alternative of each group member working independently, you resolve to kind smaller teams. Every group will share some instruments and sources. That is much like what Grouped-Question Consideration (GQA) does in a Generative Mannequin Constructing.
Understanding Grouped-Question Consideration (GQA)
GQA is a method utilized in fashions to course of data extra effectively. It divides the mannequin’s consideration heads into teams. Every group shares a set of key and worth heads. That is totally different from conventional strategies the place every consideration head has its personal key and worth heads.
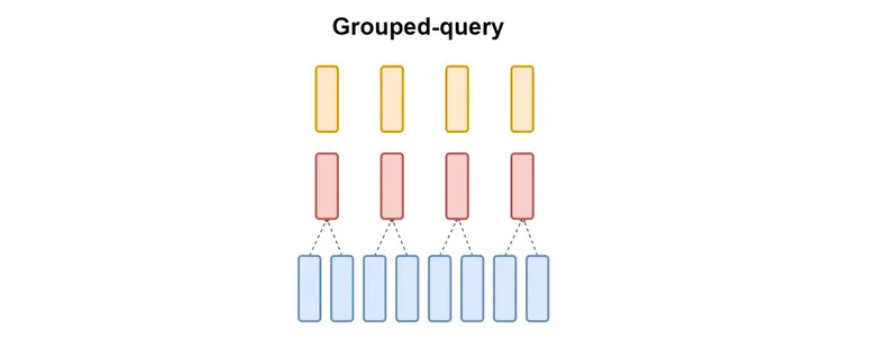
Key Factors:
- GQA-G: This implies GQA with G teams.
- GQS-1: This can be a particular case the place there’s just one group. It’s much like one other methodology referred to as Multi-Question Consideration (MQA)
- GQA-H: On this case, the variety of teams is the same as the variety of consideration heads. That is much like Multi-Head Consideration (MHA).
Why Use GQA?
- Velocity: GQA can course of data quicker than conventional strategies in massive fashions.
- Effectivity: It reduces the quantity of knowledge the mannequin must deal with, saving reminiscence and processing energy.
- Steadiness: GQA finds a candy spot between pace and accuracy.
By grouping consideration heads, GQA helps massive fashions work higher with out sacrificing a lot pace or accuracy.
Methods to use SmolLM?
Set up the mandatory libraries Pytorch, and Transformers utilizing pip. after which we’ll put that code into the principle.py file.
Right here , I used SmolLM 360M instruct mannequin you need to use increased parameter fashions similar to SmolLM-1.7B
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM-360M-Instruct"
gadget = "CPU" # GPU, if out there
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
mannequin = AutoModelForCausalLM.from_pretrained(checkpoint)
messages = [
{"role": "user", "content": "List the steps to bake a chocolate cake from scratch."}
]
input_text = tokenizer.apply_chat_template(messages, tokenize=False)
print(input_text)
inputs = tokenizer.encode(input_text, return_tensors="pt").to("cpu")
outputs = mannequin.generate(
inputs, max_new_tokens=100, temperature=0.6, top_p=0.92, do_sample=True
)
print(tokenizer.decode(outputs[0]))Output:
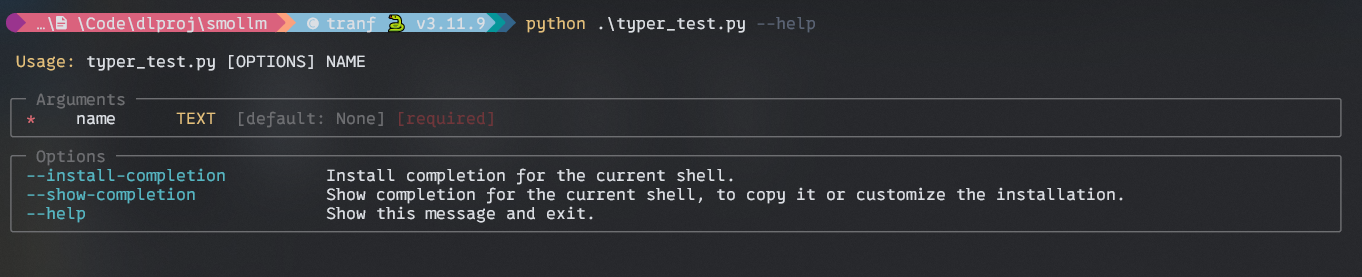
What’s Typer?
Typer is a library for constructing Command Line (CLI) functions. It was constructed by Tiangolo who developed the extremely performant Python internet framework FastAPI. Typer for the CLI as FastAPI for the online.
What are the advantages of utilizing it?
- Consumer-Pleasant and Intuitive:
- Simple to Write: Due to wonderful editor help and code completion in all places, you’ll spend much less time debugging and studying documentation.
- Easy for Customers: Computerized assist and completion for all shells make it simple for finish customers.
- Environment friendly:
- Concise Code: reduce code duplication with a number of options from every parameter declaration. resulting in fewer bugs.
- Begin Small: You may get began with simply 2 traces of code: one import and one operate name.
- Scalable:
- Develop a Wanted: Improve complexity as a lot as you need, creating complicated command bushes and subcommands with choices and arguments.
- Versatile:
- Run Scripts: Typer features a command/program to run scripts, robotically changing them to CLIs, even when they don’t use Typer internally.
Methods to use Typer?
A easy Whats up CLI utilizing Typer. First, set up Typer utilizing pip.
$ pip set up typerNow create a fundamental.py file and sort beneath code
import typer
app = typer.Typer()
@app.command()
def fundamental(title: str):
print(f"Whats up {title}")
if __name__ == "__main__":
app()Within the above code, we first import Typer after which create an app utilizing “typer.Typer()” methodology.
The @app.command() is a decorator, decorator in Python does one thing(user-defined) with the operate on which it’s positioned. Right here, in Typer, it makes the principle() right into a command.
Output:
FIsrt with –assist argument and the with –title argument.

Setting Up Challenge
To get began with our Private AI Chat CLI utility, we have to arrange our growth surroundings and set up the mandatory dependencies. Right here’s tips on how to do it
Create a Conda Surroundings
# Create a conda env
$ conda create --name slmdev python=3.11
# Begin your env
$ conda activate slmdevCreate a brand new listing for the undertaking
$ mkdir personal-ai-chat
$ cd personal-ai-chatSet up the required packages
pip set up langchain huggingface_hub trabsformers torch wealthyImplementing the Chat Software
First, create a fundamental.py file in your undertaking listing.
Let’s import the mandatory modules and initialize our utility.
import typer
from langchain_huggingface.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
from wealthy.console import Console
from wealthy.panel import Panel
from wealthy.markdown import Markdown
import json
from typing import Listing, Dict
app = typer.Typer()
console = Console()Now, we’ll arrange our SmolLM mannequin and a text-generation pipeline
# Initialize smolLM mannequin
model_name = "HuggingFaceTB/SmolLM-360M-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
mannequin = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float32)
# Create a text-generation pipeline
pipe = pipeline(
"text-generation",
mannequin=mannequin,
tokenizer=tokenizer,
max_length=256,
truncation=True,
temperature=0.7,
do_sample=True,
repetition_penalty=1.2,
)
# Create a LangChain LLM
llm = HuggingFacePipeline(pipeline=pipe)
Within the above code, We set our mannequin title SmolLM 360M Instruct, and use AutoTokenizer for tokenization. After that, we provoke the mannequin utilizing Huggingface AutoModelForCasualLM.
Then we arrange a HuggingFace Pipeline for working the llm.
Crafting the Immediate Template and LangChain
Now we have now to create a immediate template for our help. On this utility, we’ll devise a concise and informative reply immediate.
# Create a immediate template
template = """
You're a useful assistant. Present a concise and informative reply to the next question:
Question: {question}
Reply:
"""
immediate = PromptTemplate(template=template, input_variables=["query"])
# Create a LangChain
chain = immediate | llmWhen you’ve got adopted me until now, congratulations.
Now we’ll implement the core performance of our utility.
Create a Perform referred to as generate_response
def generate_response(question: str) -> str:
strive:
with console.standing("Considering...", spinner="dots"):
response = chain.invoke(question)
return response
besides Exception as e:
print(f"An error occurred: {e}")
return "Sorry, I encountered a problem. Please strive rephrasing your question." On this operate, we’ll create a console standing that can show a loading message “Considering..” and a spinner animation whereas a response is being generated. This supplies visible suggestions to the person.
Then we’ll name langchain’s “chain.invoke” methodology to go the person’s question as enter. It will question the smolLM and produce a response.
Within the exception block deal with any exception that may come up throughout the response era course of.
Producing Responses and Dealing with Conversations
Subsequent, create a operate for saving the conversations.
def save_conversation(dialog: Listing[Dict[str, str]]):
"""Save the dialog historical past to a JSON file."""
filename = typer.immediate(
"Enter a filename to avoid wasting the dialog (with out extension)"
)
strive:
with open(f"{filename}.json", "w") as f:
json.dump(dialog, f, indent=2)
console.print(f"Dialog saved to {filename}.json", type="inexperienced")
besides Exception as e:
print(f"An error occurred whereas saving: {e}")Within the above code snippets, we’ll create a conversation-saving operate. Right here, the person can enter a filename, and the operate will save all of the dialog right into a JSON file.
Implementing the CLI Software Command
## Code Block 1
@app.command()
def begin():
console.print(Panel.match("Hello, I am your Private AI!", type="daring magenta"))
dialog = []
## Code Block 2
whereas True:
console.print("How could I enable you?", type="cyan")
question = typer.immediate("You")
if question.decrease() in ["exit", "quit", "bye"]:
break
response = generate_response(question)
dialog.append({"position": "person", "content material": question})
dialog.append({"position": "assistant", "content material": response})
console.print(Panel(Markdown(response), title="Assistant", broaden=False))
## Code Block 3
whereas True:
console.print(
"nCHoose an motion:",
type="daring yellow",
)
console.print(
"1. follow-upn2. new-queryn3. end-chatn4. save-and-exit",
type="yellow",
)
motion = typer.immediate("Enter the nuber comparable to your alternative.")
if motion == "1":
follow_up = typer.immediate("Observe-up query")
question = follow_up.decrease()
response = generate_response(question)
dialog.append({"position": "person", "content material": question})
dialog.append({"position": "assistant", "content material": response})
console.print(
Panel(Markdown(response), title="Assistant", broaden=False)
)
elif motion == "2":
new_query = typer.immediate("New question")
question = new_query.decrease()
response = generate_response(question)
dialog.append({"position": "person", "content material": question})
dialog.append({"position": "assistant", "content material": response})
console.print(
Panel(Markdown(response), title="Assistant", broaden=False)
)
elif motion == "3":
return
elif motion == "4":
save_conversation(dialog)
return
else:
console.print(
"Invalid alternative. Please select a sound possibility.", type="crimson"
)
## Code Block 4
if typer.verify("Would you want to avoid wasting this dialog?"):
save_conversation(dialog)
console.print("Good Bye!! Joyful Hacking", type="daring inexperienced")Code Block 1
Introduction and welcome message, right here
- The code begins with a ” begin ” operate triggered once you run the applying. the decorator “@app.command” makes this begin operate right into a command in our CLI utility.
- It shows colourful welcome messages utilizing a library referred to as Wealthy.
Code Block 2
The primary dialog loop, right here
- The code enters a loop that continues till you exit the dialog
- Inside that loop
- It asks you “How could I enable you?” utilizing the colour immediate.
- It captures your question utilizing “typer.immediate” and converts it into lowercase
- It additionally checks in case your question is an exit command like “exit”, “give up” or “bye”. If that’s the case it exits the loop.
- In any other case, it calls the “generate_response” operate to course of your question and get a response.
- It shops your question and response within the dialog historical past.
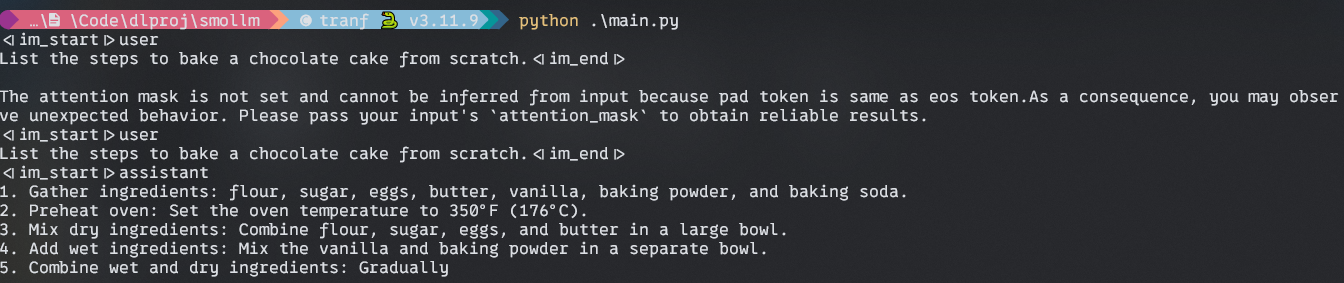
- It shows the assistant’s response in a formatted field utilizing libraries like Wealthy’s console and Markdown.
Output:
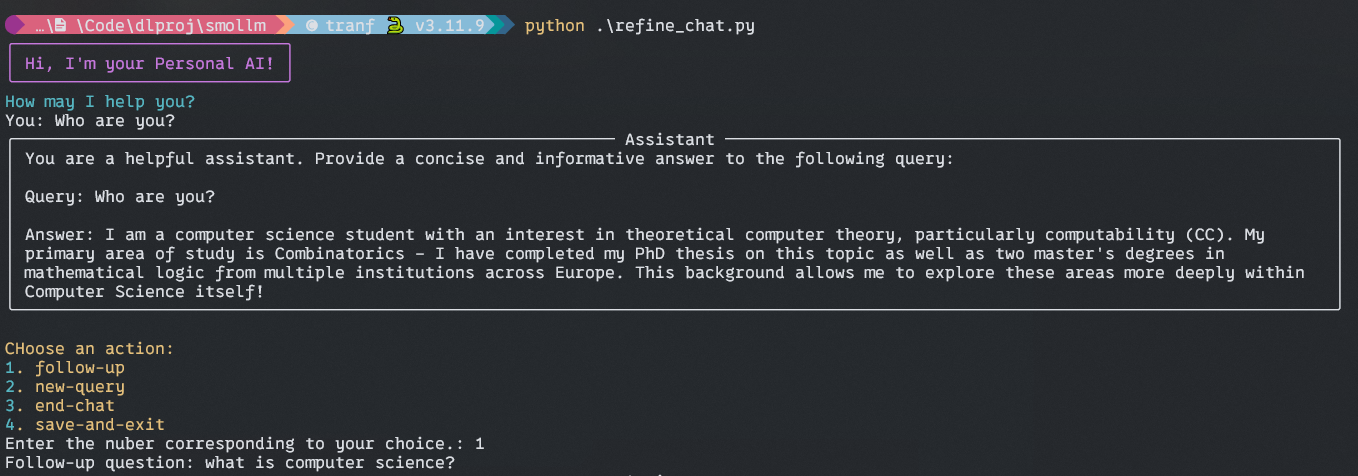
Code Block 3
Dealing with Consumer Alternative
- Right here on this whereas loop, a lot of the issues are the identical as earlier than, the one distinction is you can select a distinct possibility for additional dialog, similar to follow-up questions, new question, finish chat, saving the dialog, and so on.
Code Block 4
Saving the dialog and farewell message
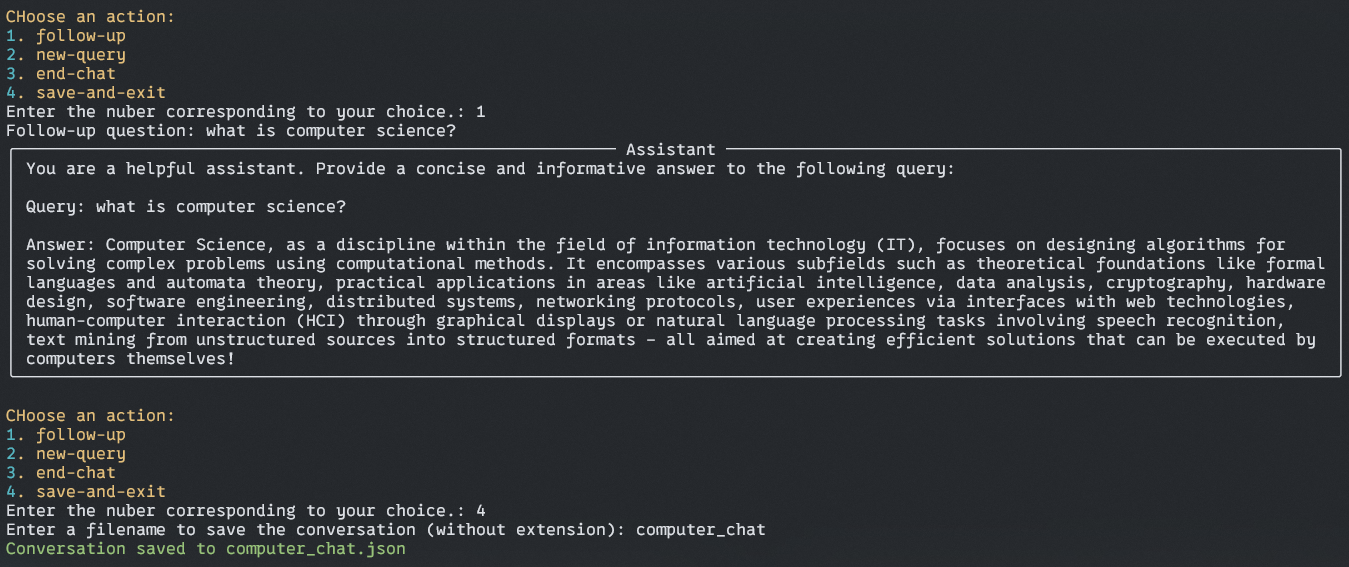
Right here, the assistant will ask you to avoid wasting your chat historical past as a JSON file for additional evaluation. Ask you for a file title with out “.json”. and save your historical past in your root listing.
After which a farewell message for you.
Output:
Output of Saved File:
Conclusion
Constructing your individual Private AI CLI utility utilizing Huggingface SmoLM is greater than only a enjoyable undertaking. It’s the gateway to understanding and making use of cutting-edge AI applied sciences in a sensible, accessible method. By means of this text, we have now explored tips on how to use the ability of compact SLM to create a fascinating person interface proper in your terminal.
All of the code used on this Private AI CLI
Key Takeaways
- Article demonstrates that constructing a private AI assistant is inside attain for builders of varied ability ranges. and {hardware} ranges.
- By using SmolLM, a compact but succesful language mannequin, the undertaking exhibits tips on how to create an AI chat utility that doesn’t require heavy computational sources and makes it appropriate for small, low-power {hardware}.
- The undertaking showcases the ability of integrating totally different applied sciences to create a useful feature-rich utility.
- By means of the usage of Typer and Wealthy libraries, the article emphasizes the significance of making an intuitive and visually interesting command-line interface, enhancing person expertise even in a text-based surroundings.
Regularly Requested Questions
A. Sure, You’ll be able to tweak the immediate template to your domain-specific alternative of help. Experiment with immediate, and mannequin parameters like temperature and max_lenght to regulate the type responses. For, coaching together with your knowledge it’s best to strive PEFT type coaching similar to LORA, or you need to use RAG sort utility to make use of your knowledge instantly with out altering mannequin weights.
A. This private AI chat is designed for Native Use, so your knowledge stays private so long as you replace your mannequin weight by fine-tuning it together with your knowledge. As a result of whereas fine-tuning in case your coaching knowledge comprise any private data it should have an imprint on the mannequin weight. So, watch out and sanitize your dataset earlier than fine-tuning.
A. SLM fashions are constructed utilizing high-quality coaching knowledge for small units, it has solely 100M to 3B parameters, whereas LLM is skilled on and for giant computationally heavy {hardware} and consists of 100B to trillions of parameters. These LLMs are coaching on knowledge out there on the web. So, SML won’t compete with the LLM in width and depth. However SLM efficiency is nicely in its measurement classes.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Creator’s discretion.