You’ve heard the well-known quote “Information is the brand new Oil” by British mathematician Clive Humby it’s the most influential quote that describes the significance of information within the twenty first century however, after the explosive improvement of the Giant Language Mannequin and its coaching what we don’t have proper is the information. as a result of the event pace and coaching pace of the LLM mannequin practically surpass the information era pace of people. The answer is making the information extra refined and particular to the duty or the Artificial knowledge era. The previous is the extra area skilled loaded duties however the latter is extra outstanding to the massive starvation of right this moment’s issues.
The high-quality coaching knowledge stays a important bottleneck. This weblog put up explores a sensible method to producing artificial knowledge utilizing LLama 3.2 and Ollama. It’s going to exhibit how we will create structured academic content material programmatically.
Studying Outcomes
- Perceive the significance and methods of Native Artificial Information Era for enhancing machine studying mannequin coaching.
- Discover ways to implement Native Artificial Information Era to create high-quality datasets whereas preserving privateness and safety.
- Acquire sensible information of implementing sturdy error dealing with and retry mechanisms in knowledge era pipelines.
- Study JSON validation, cleansing methods, and their position in sustaining constant and dependable outputs.
- Develop experience in designing and using Pydantic fashions for guaranteeing knowledge schema integrity.
What’s Artificial Information?
Artificial knowledge refers to artificially generated info that mimics the traits of real-world knowledge whereas preserving important patterns and statistical properties. It’s created utilizing algorithms, simulations, or AI fashions to deal with privateness considerations, increase restricted knowledge, or check methods in managed eventualities. In contrast to actual knowledge, artificial knowledge could be tailor-made to particular necessities, guaranteeing variety, stability, and scalability. It’s broadly utilized in fields like machine studying, healthcare, finance, and autonomous methods to coach fashions, validate algorithms, or simulate environments. Artificial knowledge bridges the hole between knowledge shortage and real-world purposes whereas lowering moral and compliance dangers.
Why We Want Artificial Information Right this moment?
The demand for artificial knowledge has grown exponentially as a result of a number of elements
- Information Privateness Laws: With GDPR and comparable rules, artificial knowledge affords a secure different for improvement and testing
- Price Effectivity: COllecting and annotating actual knowledge is dear and time-consuming.
- Scalabilities: Artificial knowledge could be generated in Giant portions with managed variations
- Edge Case Protection: We are able to generate knowledge for uncommon eventualities that is perhaps troublesome to gather naturally
- Fast Prototyping: Fast iteration on ML fashions with out ready for actual knowledge assortment.
- Much less Biased: The info collected from the true world could also be error inclined and filled with gender biases, racistic textual content, and never secure for youngsters’s phrases so to make a mannequin with the sort of knowledge, the mannequin’s habits can also be inherently with these biases. With artificial knowledge, we will management these behaviors simply.
Impression on LLM and Small LM Efficiency
Artificial knowledge has proven promising leads to enhancing each massive and small language fashions
- Tremendous-tuning Effectivity: Fashions fine-tuned on high-quality artificial knowledge typically present comparable efficiency to these skilled on actual knowledge
- Area Adaptation: Artificial knowledge helps bridge area gaps in specialised purposes
- Information Augmentation: Combining artificial and actual knowledge typically yields higher outcomes utilizing both alone.
Undertaking Construction and Atmosphere Setup
Within the following part, we’ll break down the mission structure and information you thru configuring the required atmosphere.
mission/
├── predominant.py
├── necessities.txt
├── README.md
└── english_QA_new.jsonNow we are going to arrange our mission atmosphere utilizing conda. Comply with under steps
Create Conda Atmosphere
$conda create -n synthetic-data python=3.11
# activate the newly created env
$conda activate synthetic-dataSet up Libraries in conda env
pip set up pydantic langchain langchain-community
pip set up langchain-ollamaNow we’re all set as much as begin the code implementation
Undertaking Implementation
On this part, we’ll delve into the sensible implementation of the mission, overlaying every step intimately.
Importing Libraries
Earlier than beginning the mission we are going to create a file title predominant.py within the mission root and import all of the libraries on that file:
from pydantic import BaseModel, Discipline, ValidationError
from langchain.prompts import PromptTemplate
from langchain_ollama import OllamaLLM
from typing import Checklist
import json
import uuid
import re
from pathlib import Path
from time import sleepNow it’s time to proceed the code implementation half on the principle.py file
First, we begin with implementing the Information Schema.
EnglishQuestion knowledge schema is a Pydantic mannequin that ensures our generated knowledge follows a constant construction with required fields and automated ID era.
Code Implementation
class EnglishQuestion(BaseModel):
id: str = Discipline(
default_factory=lambda: str(uuid.uuid4()),
description="Distinctive identifier for the query",
)
class: str = Discipline(..., description="Query Sort")
query: str = Discipline(..., description="The English language query")
reply: str = Discipline(..., description="The proper reply to the query")
thought_process: str = Discipline(
..., description="Rationalization of the reasoning course of to reach on the reply"
)Now, that we have now created the EnglishQuestion knowledge class.
Second, we are going to begin implementing the QuestionGenerator class. This class is the core of mission implementation.
QuestionGenerator Class Construction
class QuestionGenerator:
def __init__(self, model_name: str, output_file: Path):
go
def clean_json_string(self, textual content: str) -> str:
go
def parse_response(self, consequence: str) -> EnglishQuestion:
go
def generate_with_retries(self, class: str, retries: int = 3) -> EnglishQuestion:
go
def generate_questions(
self, classes: Checklist[str], iterations: int
) -> Checklist[EnglishQuestion]:
go
def save_to_json(self, query: EnglishQuestion):
go
def load_existing_data(self) -> Checklist[dict]:
goLet’s step-by-step implement the important thing strategies
Initialization
Initialize the category with a language mannequin, a immediate template, and an output file. With this, we are going to create an occasion of OllamaLLM with model_name and arrange a PromptTemplate for producing QA in a strict JSON format.
Code Implementation:
def __init__(self, model_name: str, output_file: Path):
self.llm = OllamaLLM(mannequin=model_name)
self.prompt_template = PromptTemplate(
input_variables=["category"],
template="""
Generate an English language query that checks understanding and utilization.
Concentrate on {class}.Query might be like fill within the blanks,One liner and mut not be MCQ sort. write Output on this strict JSON format:
{{
"query": "<your particular query>",
"reply": "<the right reply>",
"thought_process": "<Clarify reasoning to reach on the reply>"
}}
Don't embrace any textual content exterior of the JSON object.
""",
)
self.output_file = output_file
self.output_file.contact(exist_ok=True)JSON Cleansing
Responses we are going to get from the LLM throughout the era course of could have many pointless further characters which can poise the generated knowledge, so you have to go these knowledge via a cleansing course of.
Right here, we are going to repair the frequent formatting problem in JSON keys/values utilizing regex, changing problematic characters comparable to newline, and particular characters.
Code implementation:
def clean_json_string(self, textual content: str) -> str:
"""Improved model to deal with malformed or incomplete JSON."""
begin = textual content.discover("{")
finish = textual content.rfind("}")
if begin == -1 or finish == -1:
increase ValueError(f"No JSON object discovered. Response was: {textual content}")
json_str = textual content[start : end + 1]
# Take away any particular characters which may break JSON parsing
json_str = json_str.exchange("n", " ").exchange("r", " ")
json_str = re.sub(r"[^x20-x7E]", "", json_str)
# Repair frequent JSON formatting points
json_str = re.sub(
r'(?<!)"([^"]*?)(?<!)":', r'"1":', json_str
) # Repair key formatting
json_str = re.sub(
r':s*"([^"]*?)(?<!)"(?=s*[,}])', r': "1"', json_str
) # Repair worth formatting
return json_strResponse Parsing
The parsing methodology will use the above cleansing course of to scrub the responses from the LLM, validate the response for consistency, convert the cleaned JSON right into a Python dictionary, and map the dictionary to an EnglishQuestion object.
Code Implementation:
def parse_response(self, consequence: str) -> EnglishQuestion:
"""Parse the LLM response and validate it towards the schema."""
cleaned_json = self.clean_json_string(consequence)
parsed_result = json.hundreds(cleaned_json)
return EnglishQuestion(**parsed_result)Information Persistence
For, persistent knowledge era, though we will use some NoSQL Databases(MongoDB, and so on) for this, right here we use a easy JSON file to retailer the generated knowledge.
Code Implementation:
def load_existing_data(self) -> Checklist[dict]:
"""Load present questions from the JSON file."""
attempt:
with open(self.output_file, "r") as f:
return json.load(f)
besides (FileNotFoundError, json.JSONDecodeError):
return []Sturdy Era
On this knowledge era part, we have now two most necessary strategies:
- Generate with retry mechanism
- Query Era methodology
The aim of the retry mechanism is to drive automation to generate a response in case of failure. It tries producing a query a number of occasions(the default is thrice) and can log errors and add a delay between retries. It’s going to additionally increase an exception if all makes an attempt fail.
Code Implementation:
def generate_with_retries(self, class: str, retries: int = 3) -> EnglishQuestion:
for try in vary(retries):
attempt:
consequence = self.prompt_template | self.llm
response = consequence.invoke(enter={"class": class})
return self.parse_response(response)
besides Exception as e:
print(
f"Try {try + 1}/{retries} failed for class '{class}': {e}"
)
sleep(2) # Small delay earlier than retry
increase ValueError(
f"Did not course of class '{class}' after {retries} makes an attempt."
)The Query era methodology will generate a number of questions for an inventory of classes and save them within the storage(right here JSON file). It’s going to iterate over the classes and name generating_with_retries methodology for every class. And within the final, it’s going to save every efficiently generated query utilizing save_to_json methodology.
def generate_questions(
self, classes: Checklist[str], iterations: int
) -> Checklist[EnglishQuestion]:
"""Generate a number of questions for an inventory of classes."""
all_questions = []
for _ in vary(iterations):
for class in classes:
attempt:
query = self.generate_with_retries(class)
self.save_to_json(query)
all_questions.append(query)
print(f"Efficiently generated query for class: {class}")
besides (ValidationError, ValueError) as e:
print(f"Error processing class '{class}': {e}")
return all_questionsDisplaying the outcomes on the terminal
To get some concept of what are the responses producing from LLM right here is a straightforward printing perform.
def display_questions(questions: Checklist[EnglishQuestion]):
print("nGenerated English Questions:")
for query in questions:
print("n---")
print(f"ID: {query.id}")
print(f"Query: {query.query}")
print(f"Reply: {query.reply}")
print(f"Thought Course of: {query.thought_process}")Testing the Automation
Earlier than operating your mission create an english_QA_new.json file on the mission root.
if __name__ == "__main__":
OUTPUT_FILE = Path("english_QA_new.json")
generator = QuestionGenerator(model_name="llama3.2", output_file=OUTPUT_FILE)
classes = [
"word usage",
"Phrasal Ver",
"vocabulary",
"idioms",
]
iterations = 2
generated_questions = generator.generate_questions(classes, iterations)
display_questions(generated_questions)
Now, Go to the terminal and kind:
python predominant.pyOutput:

These questions might be saved in your mission root. Saved Query seem like:
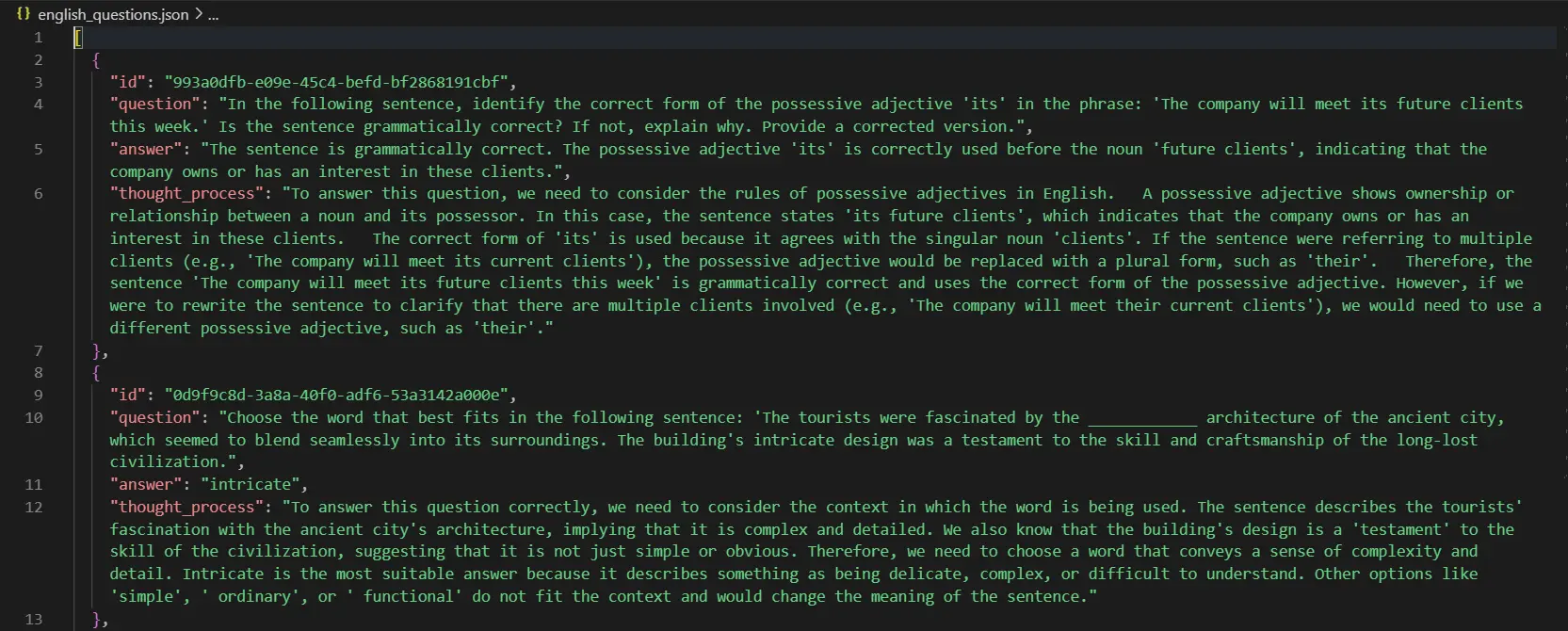
All of the code used on this mission is right here.
Conclusion
Artificial knowledge era has emerged as a strong answer to deal with the rising demand for high-quality coaching datasets within the period of fast developments in AI and LLMs. By leveraging instruments like LLama 3.2 and Ollama, together with sturdy frameworks like Pydantic, we will create structured, scalable, and bias-free datasets tailor-made to particular wants. This method not solely reduces dependency on expensive and time-consuming real-world knowledge assortment but in addition ensures privateness and moral compliance. As we refine these methodologies, artificial knowledge will proceed to play a pivotal position in driving innovation, enhancing mannequin efficiency, and unlocking new potentialities in numerous fields.
Key Takeaways
- Native Artificial Information Era allows the creation of numerous datasets that may enhance mannequin accuracy with out compromising privateness.
- Implementing Native Artificial Information Era can considerably improve knowledge safety by minimizing reliance on real-world delicate knowledge.
- Artificial knowledge ensures privateness, reduces biases, and lowers knowledge assortment prices.
- Tailor-made datasets enhance adaptability throughout numerous AI and LLM purposes.
- Artificial knowledge paves the best way for moral, environment friendly, and revolutionary AI improvement.
Often Requested Questions
A. Ollama offers native deployment capabilities, lowering value and latency whereas providing extra management over the era course of.
A. To take care of high quality, The implementation makes use of Pydantic validation, retry mechanisms, and JSON cleansing. Extra metrics and keep validation could be carried out.
A. Native LLMs might need lower-quality output in comparison with bigger fashions, and era pace could be restricted by native computing assets.
A. Sure, artificial knowledge ensures privateness by eradicating identifiable info and promotes moral AI improvement by addressing knowledge biases and lowering the dependency on real-world delicate knowledge.
A. Challenges embrace guaranteeing knowledge realism, sustaining area relevance, and aligning artificial knowledge traits with real-world use instances for efficient mannequin coaching.
A self-taught, project-driven learner, like to work on advanced tasks on deep studying, Laptop imaginative and prescient, and NLP. I at all times attempt to get a deep understanding of the subject which can be in any area comparable to Deep studying, Machine studying, or Physics. Like to create content material on my studying. Attempt to share my understanding with the worlds.