Net scraping has lengthy been an important method for extracting data from the web, enabling builders to collect insights from varied domains. With the mixing of Giant Language Fashions (LLMs) like ChatGroq, internet scraping turns into much more highly effective, providing enhanced flexibility and precision. This text explores tips on how to implement scraping with LLMs to fetch structured information from webpages successfully.

Studying Goals
- Perceive tips on how to combine Giant Language Fashions (LLMs) like ChatGroq with internet scraping instruments.
- Learn to extract structured information from webpages utilizing Playwright and LLMs.
- Achieve sensible information of establishing an atmosphere for internet scraping with LLMs.
- Discover strategies for processing and changing internet content material into structured codecs like Markdown.
- Learn to automate and scale internet scraping duties for environment friendly information extraction.
Setting Up the Atmosphere
Earlier than diving into internet scraping, guarantee your atmosphere is correctly configured. Set up the required libraries:
!pip set up -Uqqq pip --progress-bar off # Updates the Python package deal installer to the newest model
!pip set up -qqq playwright==1.46.0 --progress-bar off # Playwright for browser automation and internet scraping
!pip set up -qqq html2text==2024.2.26 --progress-bar off # Converts HTML content material to plain textual content or Markdown format
!pip set up -qqq langchain-groq==0.1.9 --progress-bar off # LangChain Groq for leveraging LLMs in information extraction workflows
!playwright set up chromiumThis code units up the atmosphere by updating pip, putting in instruments like playwright for browser automation, html2text for HTML-to-text conversion, langchain-groq for LLM-based information extraction, and downloading Chromium for Playwright’s use.
Import the Mandatory Modules
Beneath we’ll import needed modules one after the other.
import re
from pprint import pprint
from typing import Listing, Optionally available
import html2text
import nest_asyncio
import pandas as pd
from google.colab import userdata
from langchain_groq import ChatGroq
from playwright.async_api import async_playwright
from pydantic import BaseModel, Area
from tqdm import tqdm
nest_asyncio.apply()Fetching Net Content material as Markdown
Step one in scraping entails fetching the net content material. Utilizing Playwright, we load the webpage and retrieve its HTML content material:
USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
playwright = await async_playwright().begin()
browser = await playwright.chromium.launch()
context = await browser.new_context(user_agent=USER_AGENT)
web page = await context.new_page()
await web page.goto("https://playwright.dev/")
content material = await web page.content material()
await browser.shut()
await playwright.cease()
print(content material)
This code fetches the HTML content material of a webpage utilizing Playwright. It begins a Chromium browser occasion, units a customized person agent for the looking context, navigates to the desired URL (https://playwright.dev/), and retrieves the web page’s HTML content material. After fetching, the browser and Playwright are cleanly closed to launch assets.
To simplify textual content processing, convert the HTML content material to Markdown format utilizing the html2text library:
markdown_converter = html2text.HTML2Text()
markdown_converter.ignore_links = False
markdown_content = markdown_converter.deal with(content material)
print(markdown_content)
Setting Up Giant Language Fashions (LLMs)
Subsequent, configure the LLM to course of and extract structured data. Use ChatGroq, a flexible LLM designed for structured information extraction:
MODEL = "llama-3.1-70b-versatile"
llm = ChatGroq(temperature=0, model_name=MODEL, api_key=userdata.get("GROQ_API_KEY"))
SYSTEM_PROMPT = """
You are an knowledgeable textual content extractor. You extract data from webpage content material.
All the time extract information with out altering it and some other output.
"""
def create_scrape_prompt(page_content: str) -> str:
return f"""
Extract the knowledge from the next internet web page:
```
{page_content}
```
""".strip()This code units up the ChatGroq LLM for extracting structured information from webpage content material. It initializes the mannequin (`llama-3.1-70b-versatile`) with particular parameters and a system immediate instructing it to extract data precisely with out altering the content material. A perform generates prompts for processing webpage textual content dynamically.
Scraping Touchdown Pages
Outline the information construction for touchdown web page extraction utilizing Pydantic fashions:
class ProjectInformation(BaseModel):
"""Details about the challenge"""
title: str = Area("Title of the challenge e.g. Excel")
tagline: str = Area(
description="What this challenge is about e.g. Get deep insights out of your numbers",
)
advantages: Listing[str] = Area(
description="""An inventory of most important advantages of the challenge together with 3-5 phrases to summarize each.
e.g. [
'Your spreadshits everywhere you go - cloud-backed files with your account',
'Accuracy without manual calculations - vast amount of built-in formulas ready to use'
]
"""
)Invoke the LLM with structured output:
page_scraper_llm = llm.with_structured_output(ProjectInformation)
extraction = page_scraper_llm.invoke(
[("system", SYSTEM_PROMPT), ("user", create_scrape_prompt(markdown_content))]
)
pprint(extraction.__dict__, sort_dicts=False, width=120)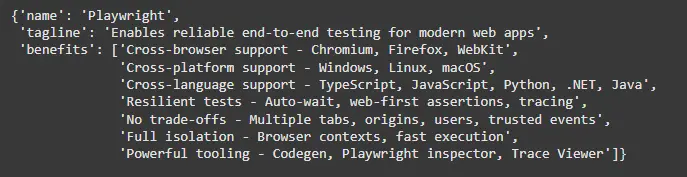
You may prolong this course of to a number of URLs:
Fetching the Net Web page
async def fetch_page(url, user_agent=USER_AGENT) -> str:
# Launch browser and navigate to the URL
async with async_playwright() as playwright:
browser = await playwright.chromium.launch()
context = await browser.new_context(user_agent=user_agent)
web page = await context.new_page()
await web page.goto(url)
content material = await web page.content material()
await browser.shut()
# Convert HTML to Markdown
markdown_converter = html2text.HTML2Text()
markdown_converter.ignore_links = False
return markdown_converter.deal with(content material)This perform launches a headless browser utilizing Playwright, hundreds the desired URL, extracts its HTML content material, after which converts it to Markdown utilizing html2text. It ensures the browser begins and stops correctly, and transforms the HTML content material into Markdown format, together with hyperlinks.
Processing A number of URLs
urls = [
"https://videogen.io/",
"https://blaze.today/aiblaze/",
"https://www.insightpipeline.com/",
"https://apps.apple.com/us/app/today-app-to-do-list-habits/id6461726826",
"https://brainybear.ai/",
]
Right here, an inventory of URLs is outlined to be processed.
Extracting Content material
extractions = []
for url in tqdm(urls):
content material = await fetch_page(url)
extractions.append(
page_scraper_llm.invoke(
[("system", SYSTEM_PROMPT), ("user", create_scrape_prompt(content))]
)
)
A loop is used to undergo every URL, fetch the web page content material, after which move it to a language mannequin (page_scraper_llm) for additional processing. The outcomes are saved within the extractions listing.
Save the Outcomes to a DataFrame
rows = []
for extraction, url in zip(extractions, urls):
row = extraction.__dict__
row["url"] = url
rows.append(row)
projects_df = pd.DataFrame(rows)
projects_df

projects_df.iloc[0].advantages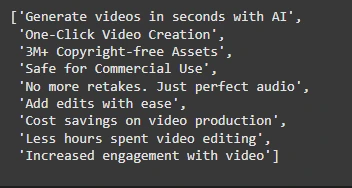
projects_df.to_csv("tasks.csv", index=None)Scraping Automobile Listings
For extra complicated information, outline extra fashions like CarListing and CarListings:
url = "https://www.autoscout24.com/lst?atype=C&cy=Dpercent2CApercent2CBpercent2CEpercent2CFpercent2CIpercent2CLpercent2CNL&desc=0&fregfrom=2018&gear=M&powerfrom=309&powerto=478&powertype=hp&search_id=1tih4oks815&type=commonplace&ustate=Npercent2CU"
auto_content = await fetch_page(url)
print(auto_content)
class CarListing(BaseModel):
"""Details about a automotive itemizing"""
make: str = Area("Make of the automotive e.g. Toyota")
mannequin: str = Area("Mannequin of the automotive, most 3 phrases e.g. Land Cruiser")
horsepower: int = Area("Horsepower of the engine e.g. 231")
value: int = Area("Value in euro e.g. 34000")
mileage: Optionally available[int] = Area("Variety of kilometers on the odometer e.g. 73400")
12 months: Optionally available[int] = Area("12 months of registration (if out there) e.g. 2015")
url: str = Area(
"Url to the itemizing e.g. https://www.autoscout24.com/presents/lexus-rc-f-advantage-coupe-gasoline-grey-19484ec1-ee56-4bfd-8769-054f03515792"
)
class CarListings(BaseModel):
"""Listing of automotive listings"""
vehicles: Listing[CarListing] = Area("Listing of vehicles on the market.")
car_listing_scraper_llm = llm.with_structured_output(CarListings)
extraction = car_listing_scraper_llm.invoke(
[("system", SYSTEM_PROMPT), ("user", create_scrape_prompt(auto_content))]
)
extraction.vehicles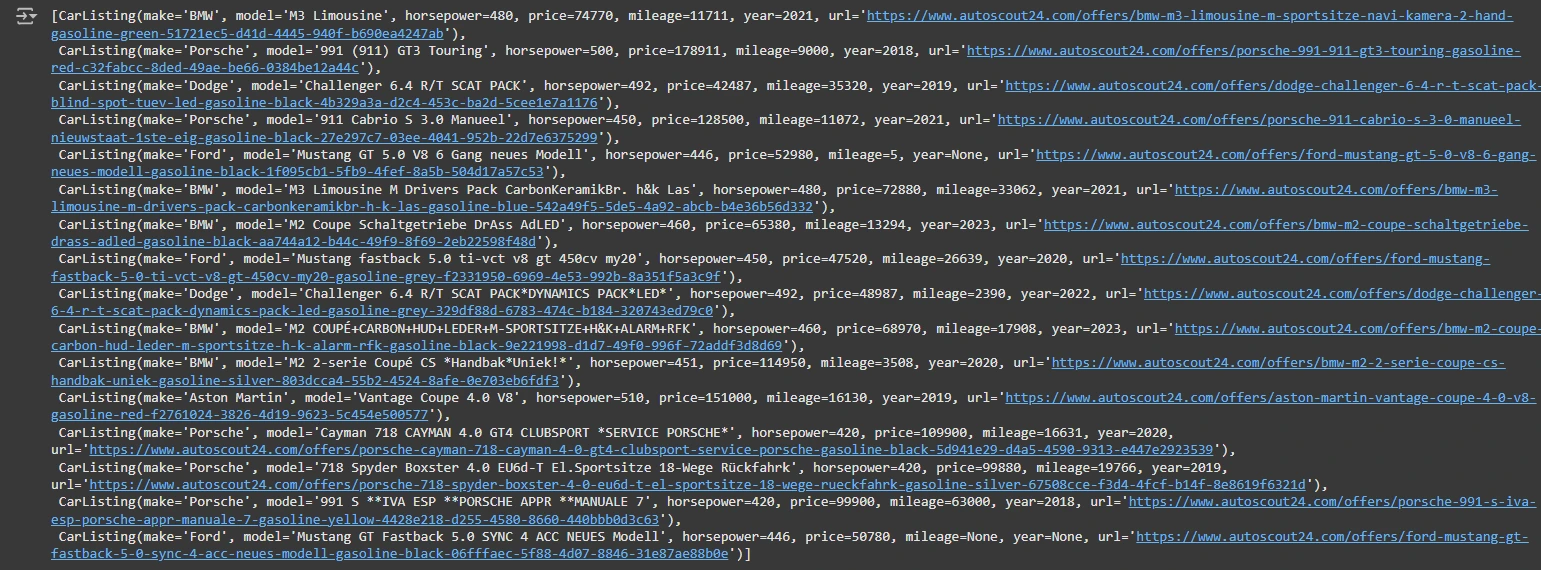
def filter_model(row):
row = re.sub("[^0-9a-zA-Z]+", " ", row)
components = row.break up(" ")
return " ".be a part of(components[:3])
rows = [listing.__dict__ for listing in extraction.cars]
listings_df = pd.DataFrame(rows)
listings_df["model"] = listings_df.mannequin.apply(filter_model)
listings_df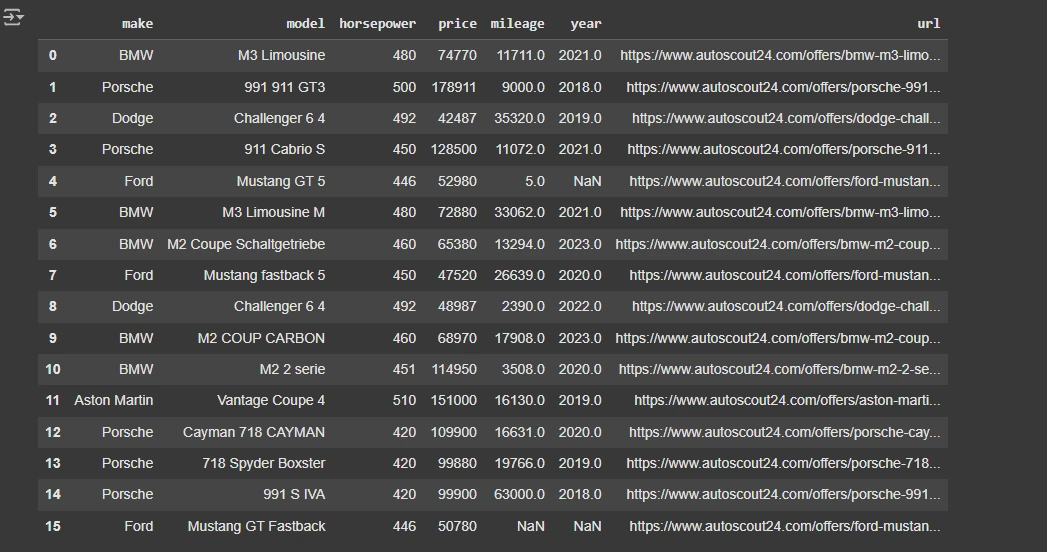
listings_df.to_csv("car-listings.csv", index=None)This code defines two Pydantic fashions, CarListing and CarListings, for representing particular person automotive particulars (e.g., make, mannequin, value, mileage) and an inventory of such vehicles. It makes use of an LLM to extract structured automotive itemizing information from a webpage. The extracted information is transformed right into a pandas DataFrame and saved as a CSV file (car-listings.csv) for additional use.
Conclusion
Combining the ability of LLMs with conventional scraping instruments like Playwright unlocks new prospects for structured information extraction. Whether or not extracting challenge particulars or automotive listings, this strategy ensures accuracy and scalability, paving the way in which for superior information workflows. Comfortable scraping!
Key Takeaways
- LLMs like ChatGroq improve internet scraping by offering exact and structured information extraction.
- Playwright automates browser interactions, permitting for efficient content material retrieval.
- Markdown conversion simplifies textual content processing for higher information extraction.
- Structured information fashions (e.g., Pydantic) guarantee organized and clear output.
- Combining LLMs with conventional scraping instruments improves scalability and accuracy.
Often Requested Questions
A. Playwright automates browser interactions, enabling you to load and retrieve dynamic content material from webpages effectively.
A. ChatGroq, a big language mannequin, processes webpage content material and extracts structured data precisely, bettering information extraction precision.
A. Changing HTML to Markdown simplifies textual content processing by stripping pointless tags, making it simpler to extract related data.
A. Structured information fashions make sure the extracted information is organized and validated, making it simpler to course of and analyze.
A. Sure, by combining Playwright for automation and LLMs for information extraction, this technique can deal with massive datasets effectively, making certain scalability.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.
Hello! I’m a eager Information Science scholar who likes to discover new issues. My ardour for information science stems from a deep curiosity about how information will be remodeled into actionable insights. I take pleasure in diving into varied datasets, uncovering patterns, and making use of machine studying algorithms to unravel real-world issues. Every challenge I undertake is a chance to reinforce my abilities and study new instruments and strategies within the ever-evolving subject of knowledge science.