
On this article we’ll kind a radical understanding of the neural community, a cornerstone expertise underpinning just about all leading edge AI methods. We’ll first discover neurons within the human mind, after which discover how they fashioned the basic inspiration for neural networks in AI. We’ll then discover back-propagation, the algorithm used to coach neural networks to do cool stuff. Lastly, after forging a radical conceptual understanding, we’ll implement a Neural Community ourselves from scratch and practice it to resolve a toy downside.
Who’s this handy for? Anybody who desires to kind an entire understanding of the state-of-the-art of AI.
How superior is that this publish? This text is designed to be accessible to newbies, and likewise accommodates thorough info which can function a helpful refresher for extra skilled readers.
Pre-requisites: None
Inspiration From the Mind
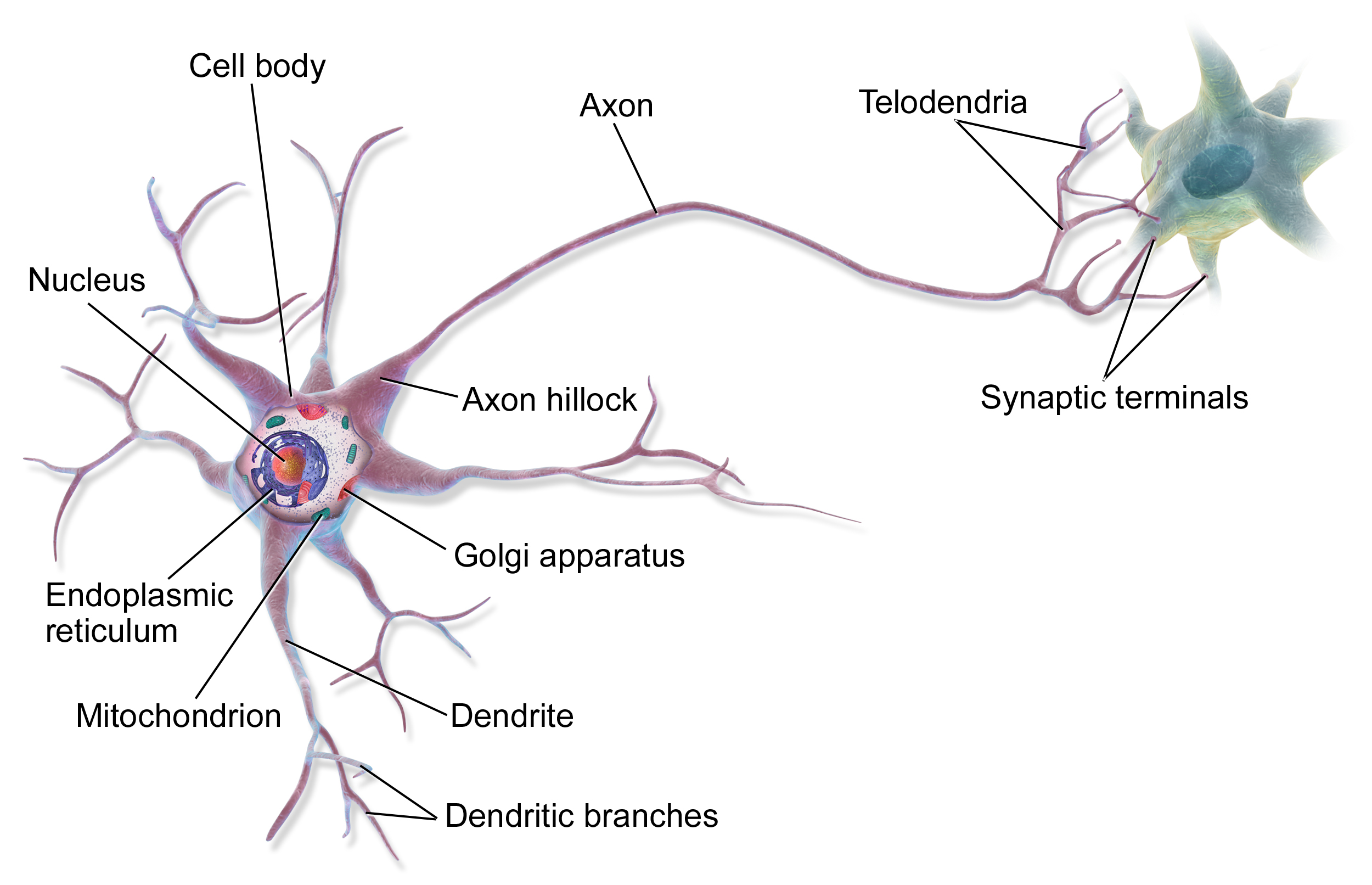
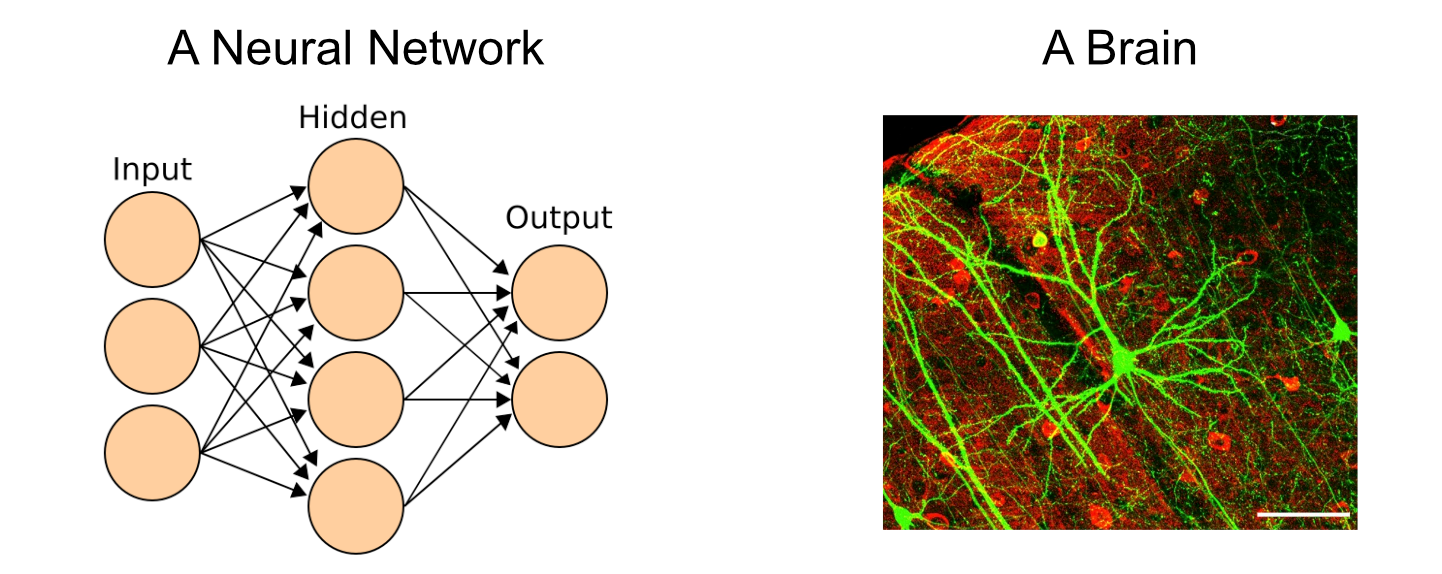
Neural networks take direct inspiration from the human mind, which is made up of billions of extremely complicated cells referred to as neurons.
{kind=link}
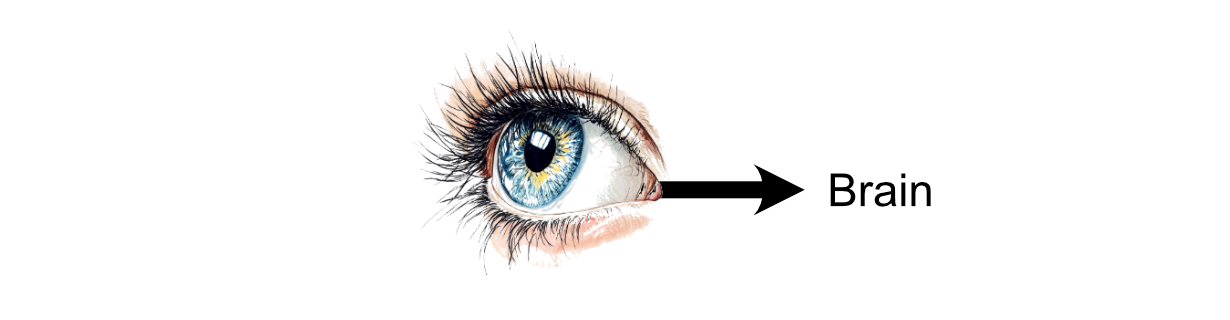
The method of pondering inside the human mind is the results of communication between neurons. You may obtain stimulus within the type of one thing you noticed, then that info is propagated to neurons within the mind by way of electrochemical indicators.
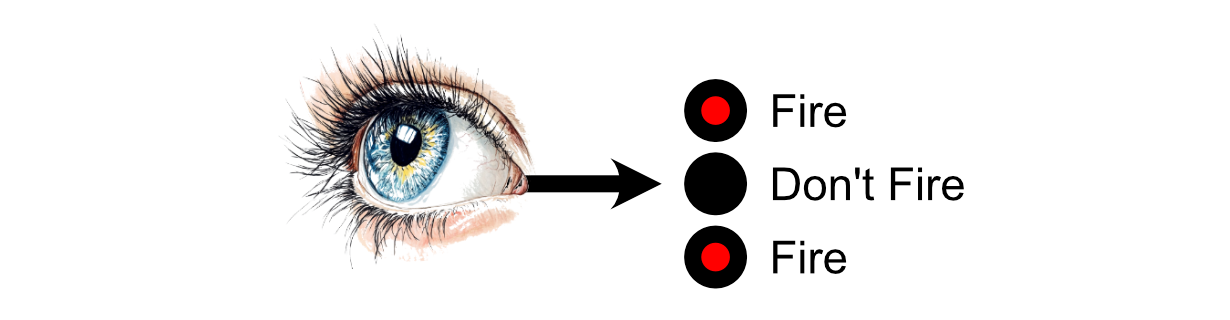
The primary neurons within the mind obtain that stimulus, then every neuron might select whether or not or to not “fireplace” primarily based on how a lot stimulus it obtained. “Firing”, on this case, is a neurons resolution to ship indicators to the neurons it’s linked to.
Then the neurons which these Neurons are linked to might or might not select to fireside.
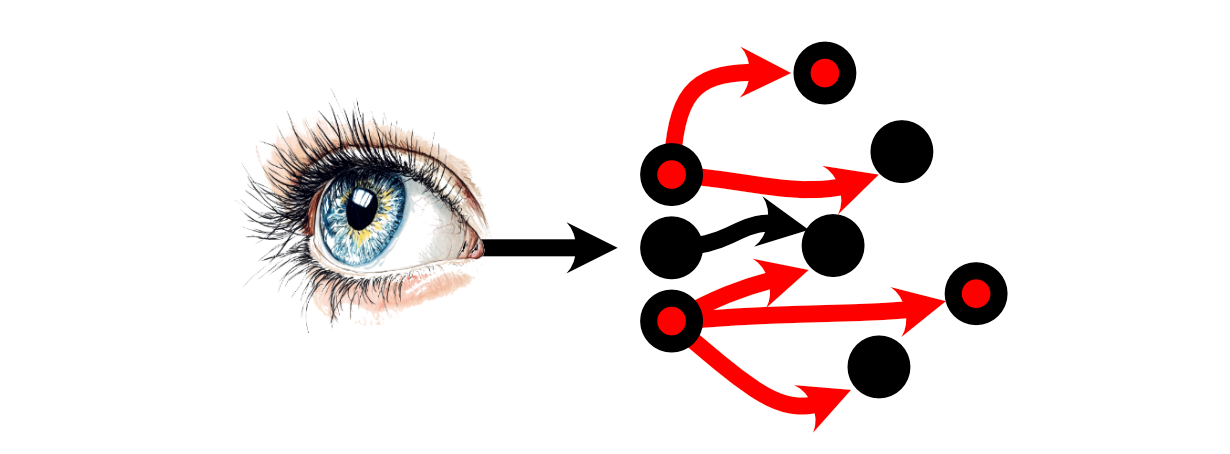
Thus, a “thought” may be conceptualized as numerous neurons selecting to, or to not fireplace primarily based on the stimulus from different neurons.
As one navigates all through the world, one might need sure ideas greater than one other individual. A cellist may use some neurons greater than a mathematician, as an illustration.

Once we use sure neurons extra ceaselessly, their connections turn into stronger, rising the depth of these connections. Once we don’t use sure neurons, these connections weaken. This normal rule has impressed the phrase “Neurons that fireside collectively, wire collectively”, and is the high-level high quality of the mind which is answerable for the educational course of.
I’m not a neurologist, so after all this can be a tremendously simplified description of the mind. Nevertheless, it’s sufficient to grasp the basic concept of a neural community.
The Instinct of Neural Networks
Neural networks are, primarily, a mathematically handy and simplified model of neurons inside the mind. A neural community is made up of parts referred to as “perceptrons”, that are straight impressed by neurons.
 1, source 2](https://towardsdatascience.com/wp-content/uploads/2025/02/1Vp3uVTyAcixfAlwcZWTTbQ.png)
 1](https://commons.wikimedia.org/wiki/File:ArtificialNeuronModel_english.png){kind=link}
Perceptrons soak up knowledge, like a neuron does,

combination that knowledge, like a neuron does,

then output a sign primarily based on the enter, like a neuron does.

A neural community may be conceptualized as a giant community of those perceptrons, similar to the mind is a giant community of neurons.
{kind=link}
When a neuron within the mind fires, it does in order a binary resolution. Or, in different phrases, neurons both fireplace or they don’t. Perceptrons, then again, don’t “fireplace” per-se, however output a spread of numbers primarily based on the perceptrons enter.

Neurons inside the mind can get away with their comparatively easy binary inputs and outputs as a result of ideas exist over time. Neurons primarily pulse at completely different charges, with slower and quicker pulses speaking completely different info.
So, neurons have easy inputs and outputs within the type of on or off pulses, however the fee at which they pulse can talk complicated info. Perceptrons solely see an enter as soon as per cross by means of the community, however their enter and output could be a steady vary of values. In the event you’re acquainted with electronics, you may replicate on how that is just like the connection between digital and analogue indicators.
The best way the mathematics for a perceptron truly shakes out is fairly easy. A regular neural community consists of a bunch of weights connecting the perceptron’s of various layers collectively.
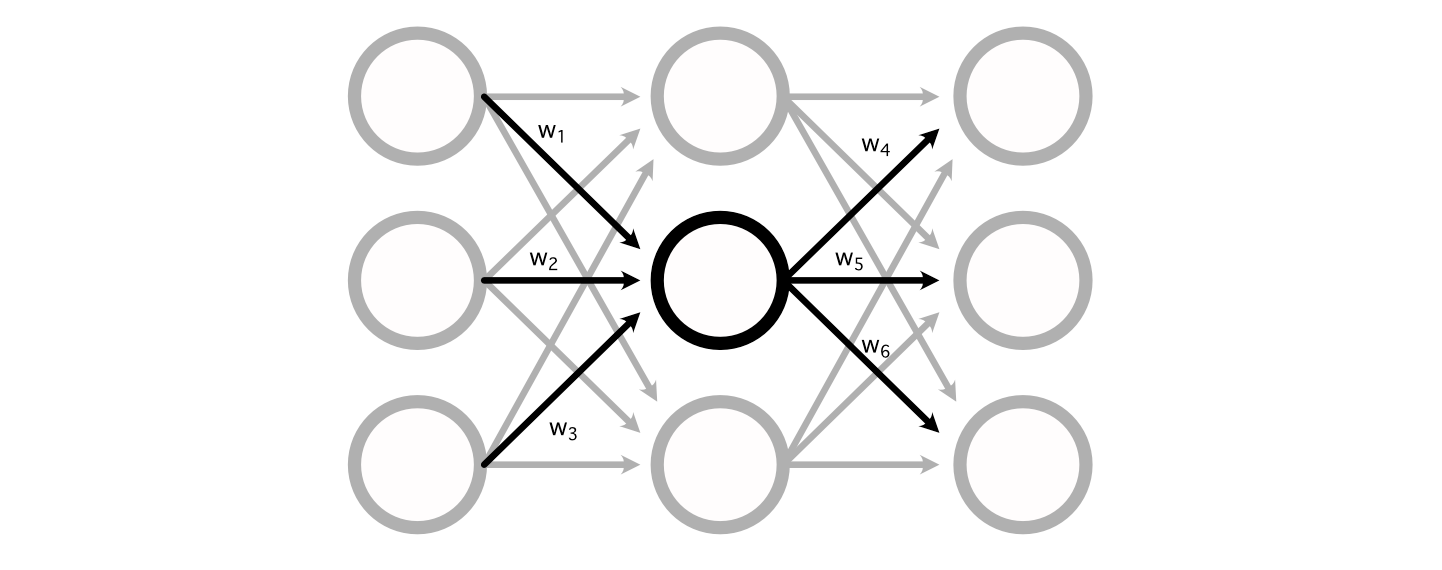
You possibly can calculate the worth of a specific perceptron by including up all of the inputs, multiplied by their respective weights.
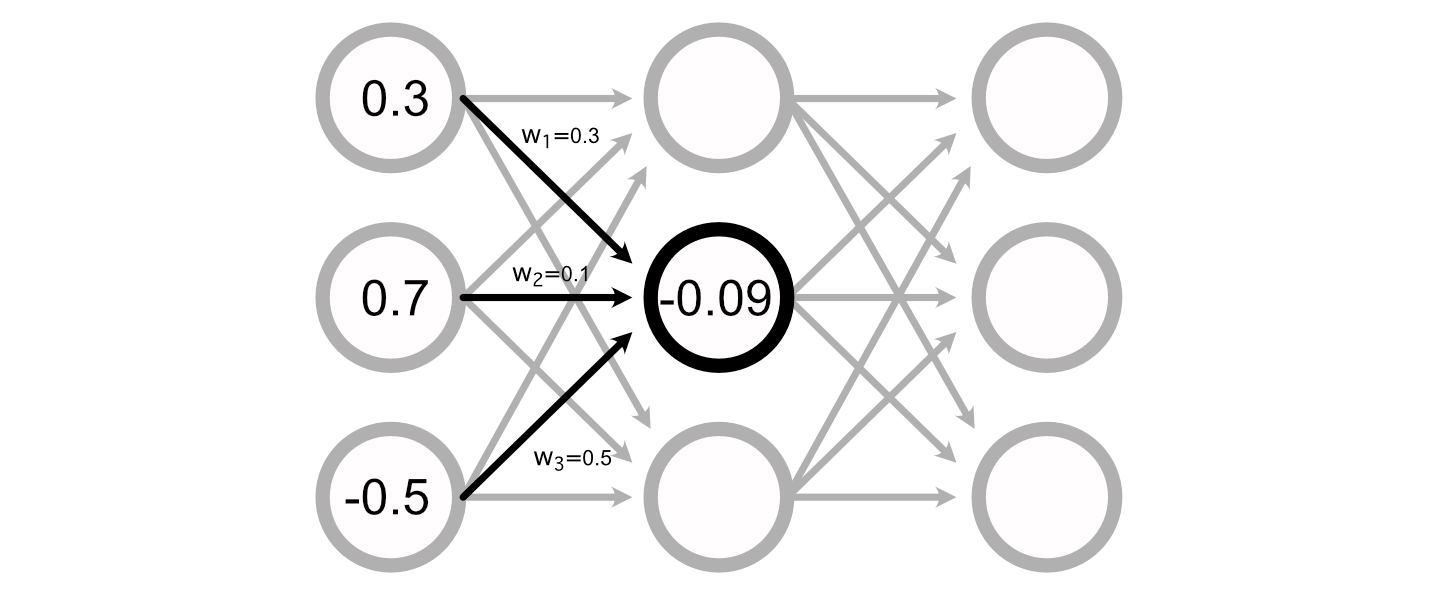
Many Neural Networks even have a “bias” related to every perceptron, which is added to the sum of the inputs to calculate the perceptron’s worth.
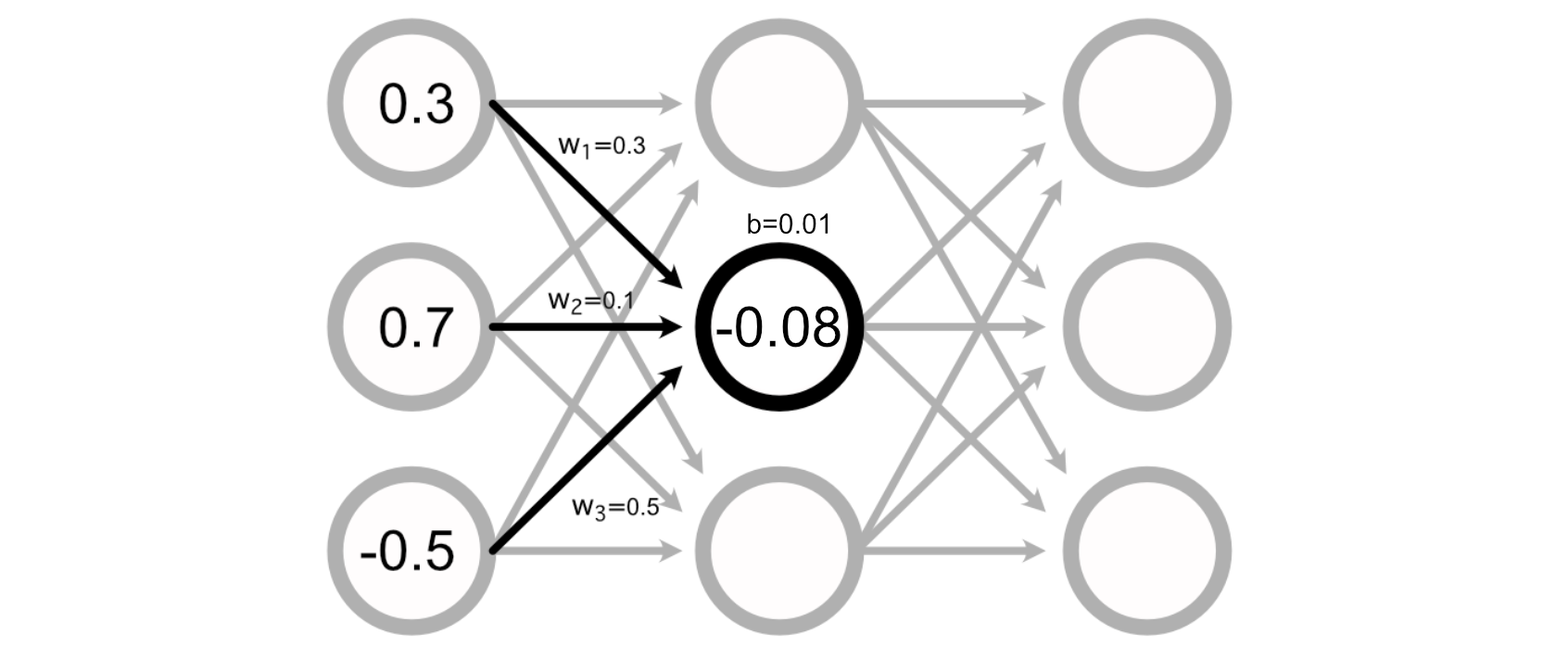
Calculating the output of a neural community, then, is simply doing a bunch of addition and multiplication to calculate the worth of all of the perceptrons.
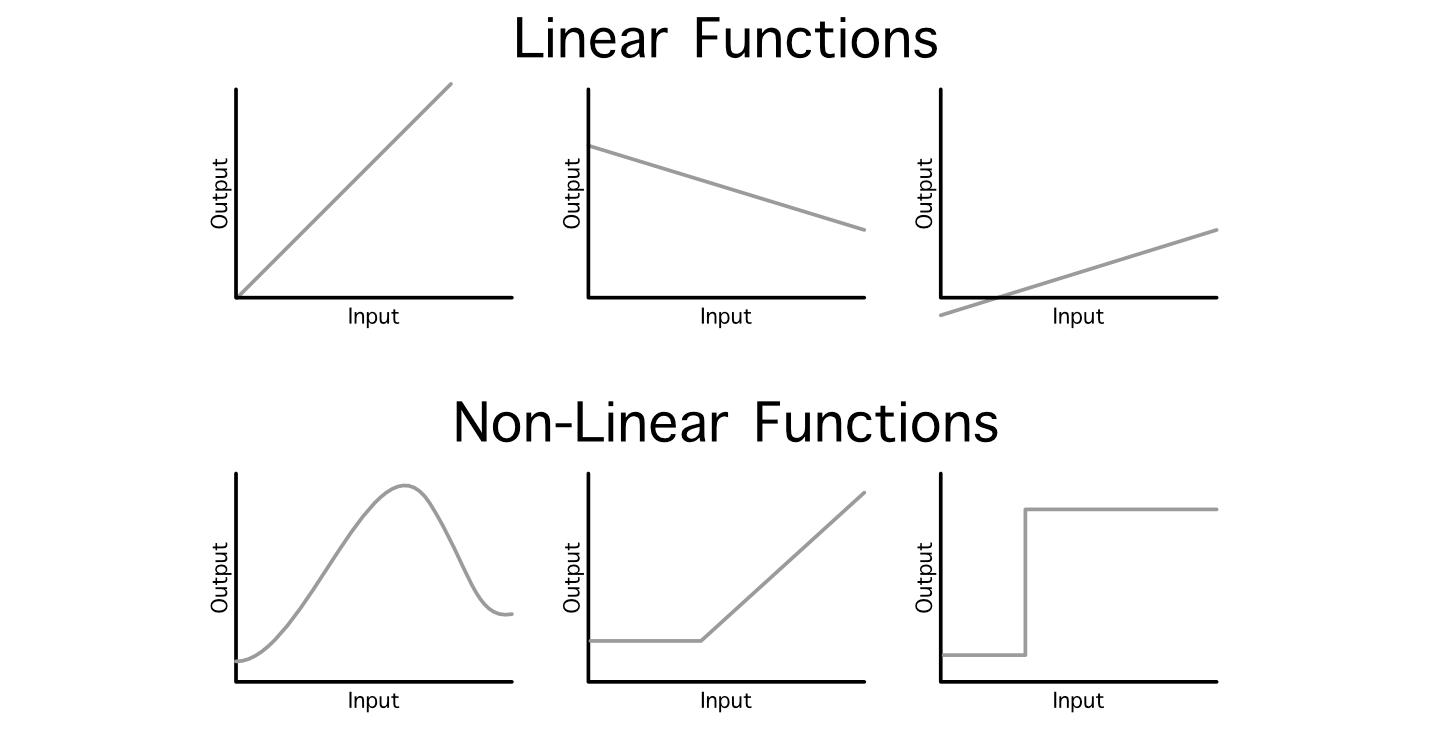
Generally knowledge scientists discuss with this normal operation as a “linear projection”, as a result of we’re mapping an enter into an output by way of linear operations (addition and multiplication). One downside with this strategy is, even when you daisy chain a billion of those layers collectively, the ensuing mannequin will nonetheless simply be a linear relationship between the enter and output as a result of it’s all simply addition and multiplication.
It is a major problem as a result of not all relationships between an enter and output are linear. To get round this, knowledge scientists make use of one thing referred to as an “activation operate”. These are non-linear capabilities which may be injected all through the mannequin to, primarily, sprinkle in some non-linearity.
by interweaving non-linear activation capabilities between linear projections, neural networks are able to studying very complicated capabilities,
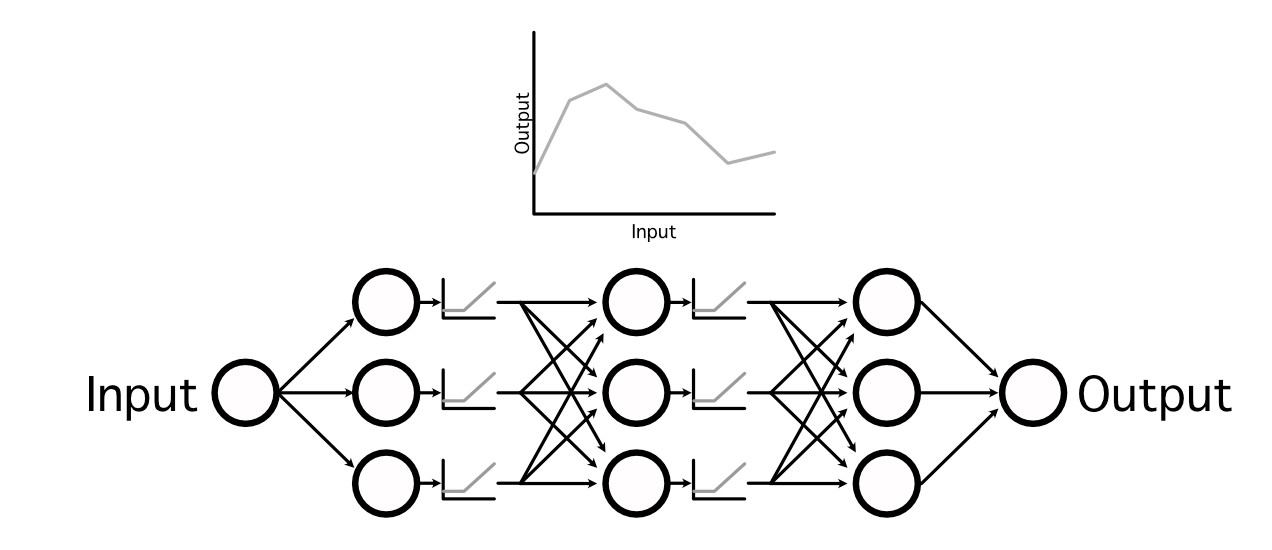
In AI there are lots of fashionable activation capabilities, however the business has largely converged on three fashionable ones: ReLU, Sigmoid, and Softmax, that are utilized in a wide range of completely different functions. Out of all of them, ReLU is the most typical as a consequence of its simplicity and skill to generalize to imitate nearly another operate.
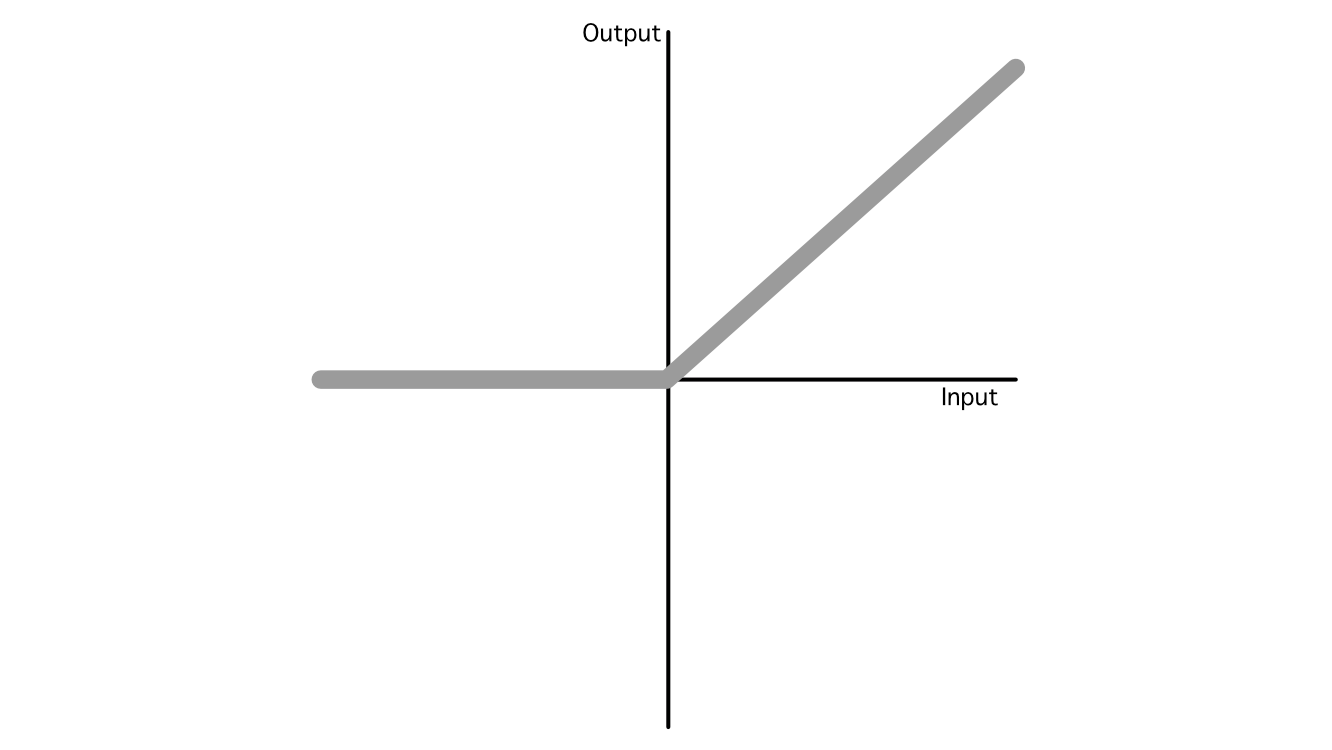
So, that’s the essence of how AI fashions make predictions. It’s a bunch of addition and multiplication with some nonlinear capabilities sprinkled in between.
One other defining attribute of neural networks is that they are often educated to be higher at fixing a sure downside, which we’ll discover within the subsequent part.
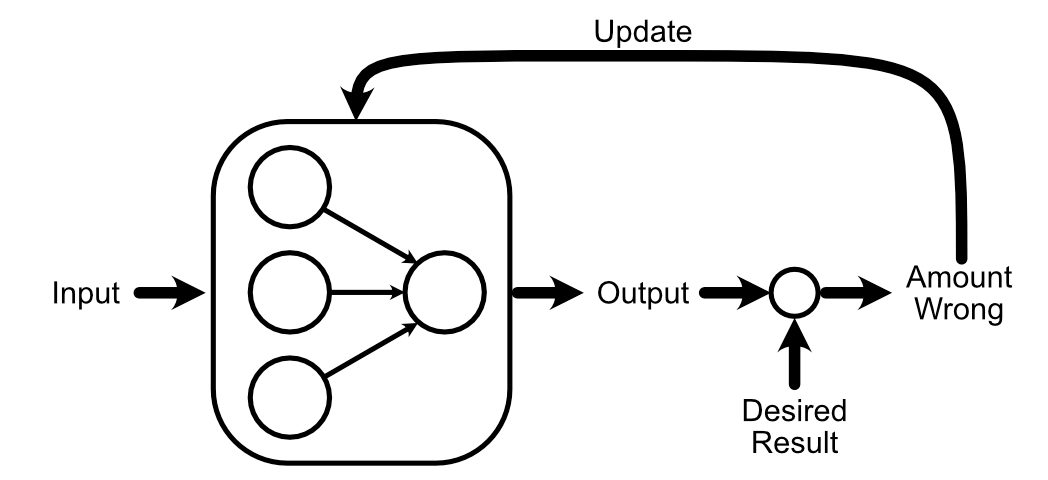
Again Propagation
One of many basic concepts of AI is you could “practice” a mannequin. That is carried out by asking a neural community (which begins its life as a giant pile of random knowledge) to do some activity. Then, you by some means replace the mannequin primarily based on how the mannequin’s output compares to a identified good reply.
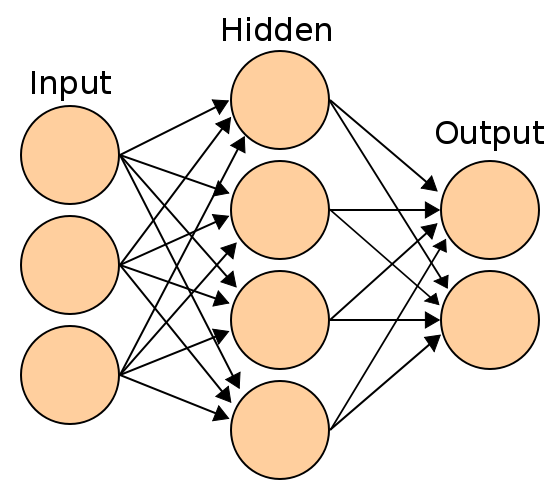
For this part, let’s think about a neural community with an enter layer, a hidden layer, and an output layer.
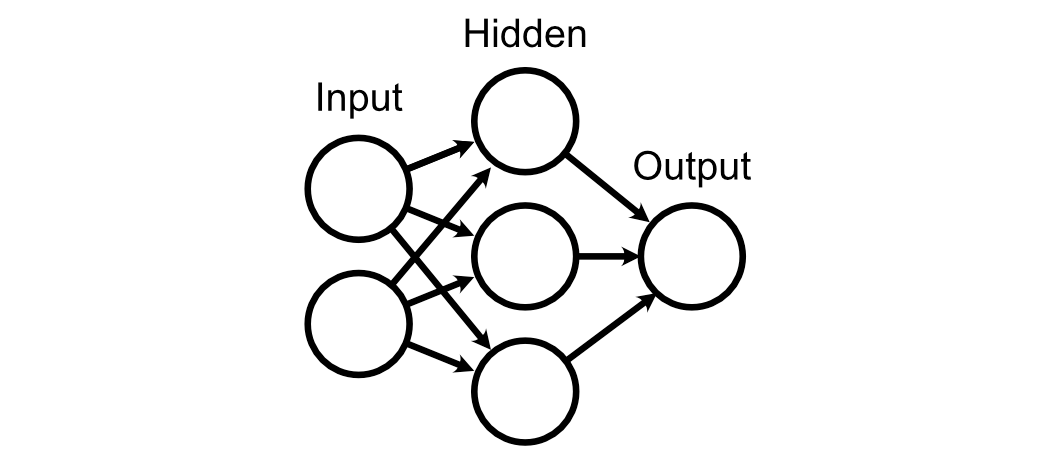
Every of those layers are linked along with, initially, utterly random weights.
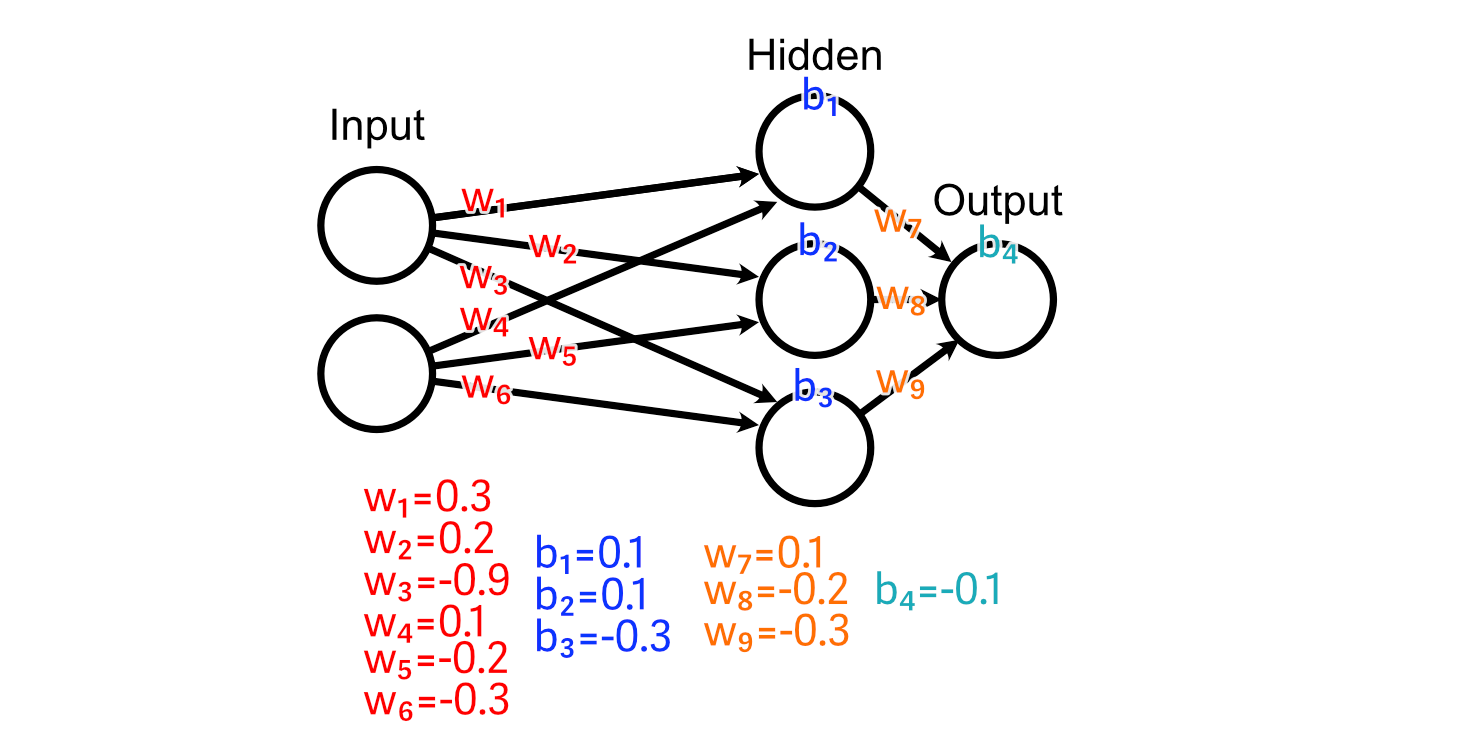
And we’ll use a ReLU activation operate on our hidden layer.
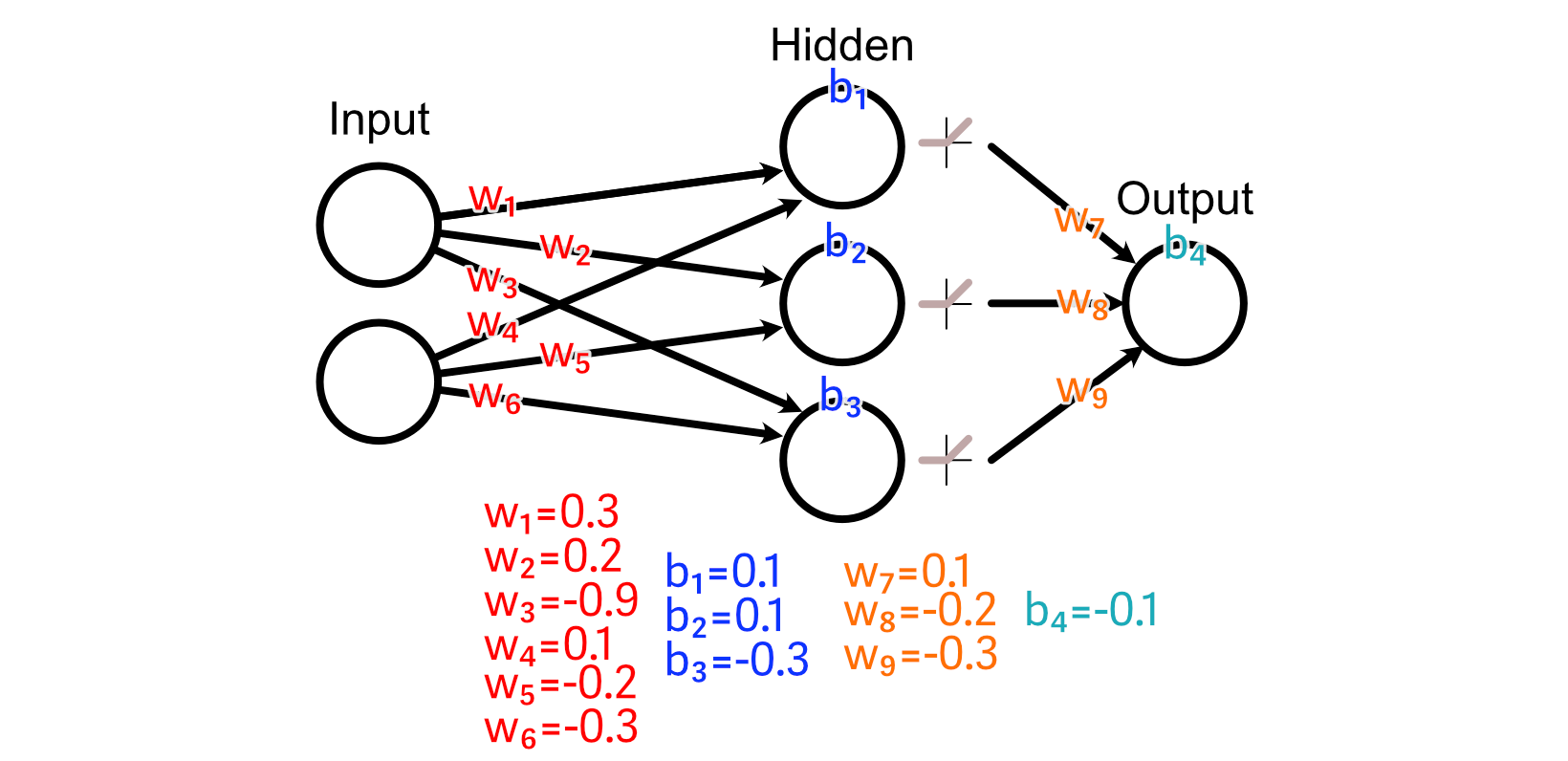
Let’s say we’ve got some coaching knowledge, wherein the specified output is the common worth of the enter.
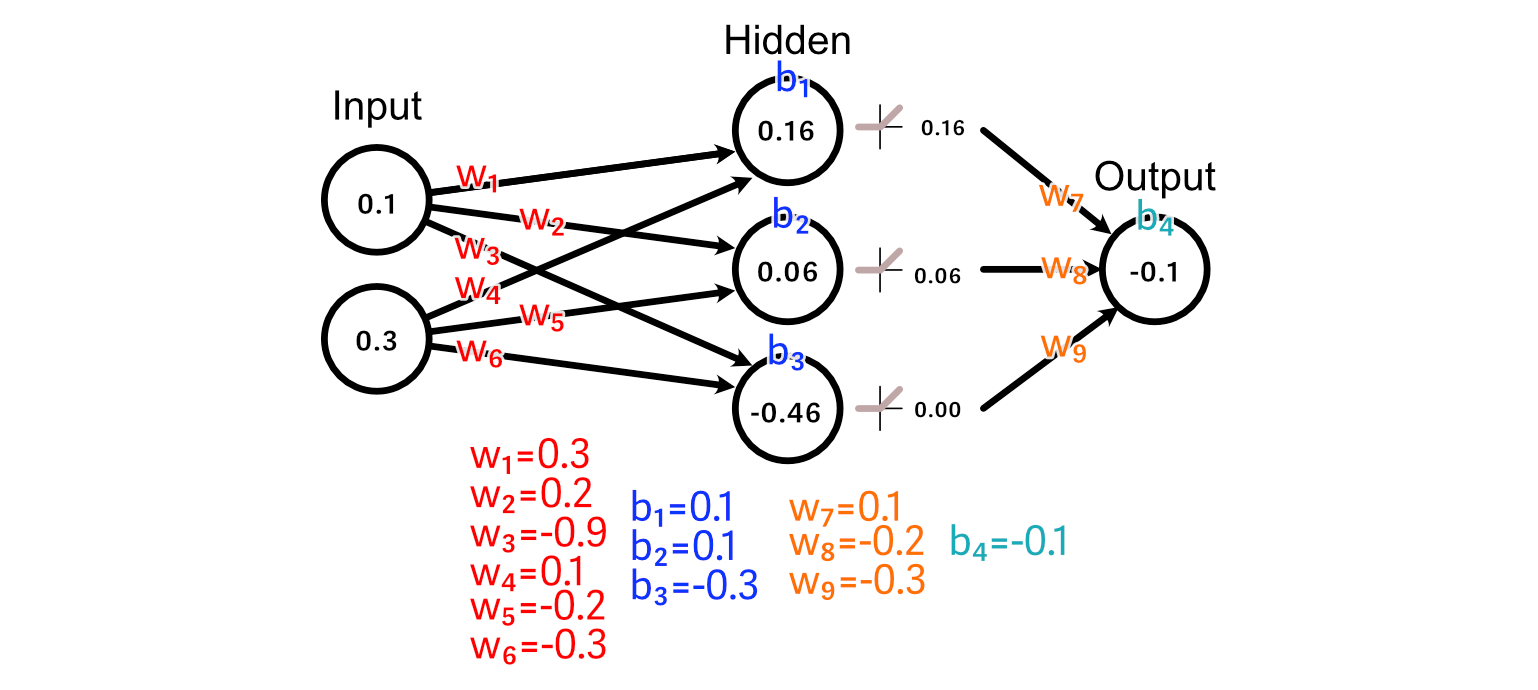
And we cross an instance of our coaching knowledge by means of the mannequin, producing a prediction.
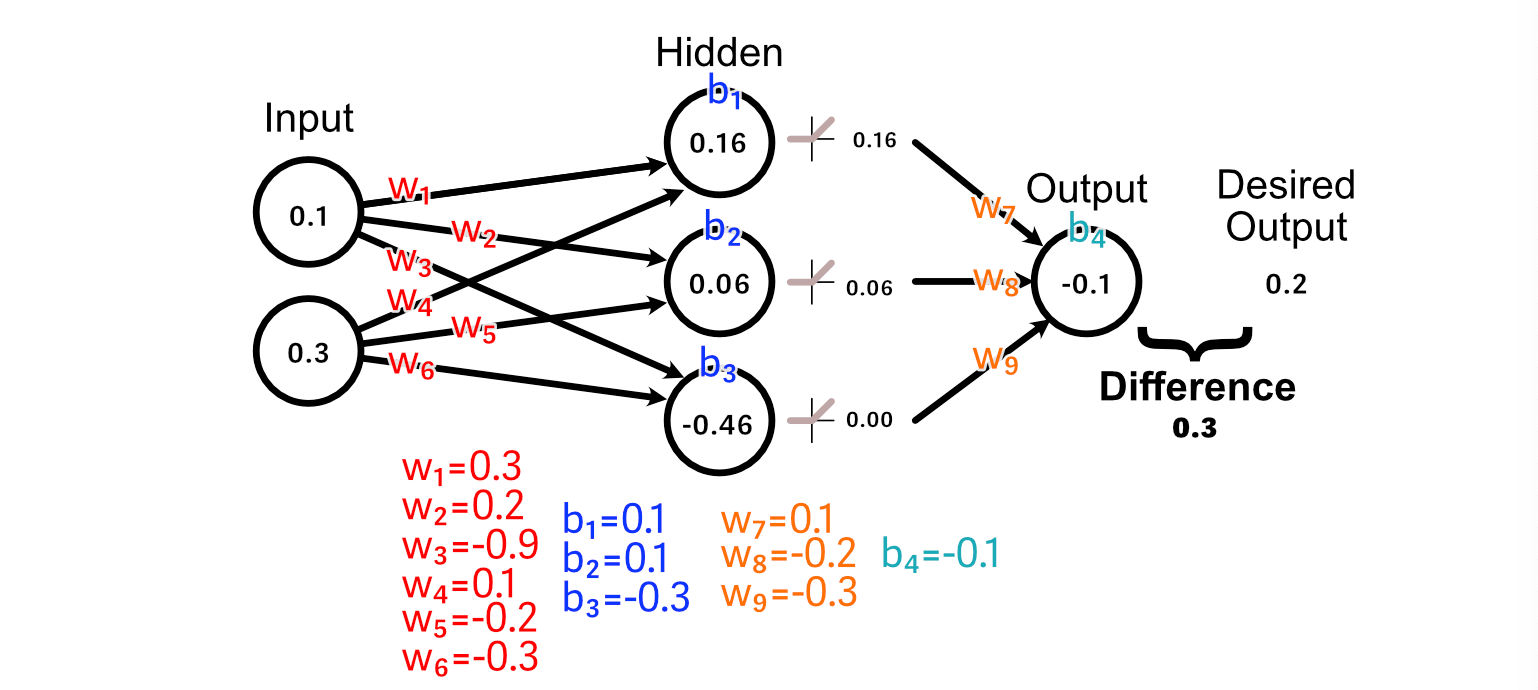
To make our neural community higher on the activity of calculating the common of the enter, we first evaluate the anticipated output to what our desired output is.
Now that we all know that the output ought to improve in measurement, we are able to look again by means of the mannequin to calculate how our weights and biases may change to advertise that change.
First, let’s have a look at the weights main instantly into the output: w₇, w₈, w₉. As a result of the output of the third hidden perceptron was -0.46, the activation from ReLU was 0.00.
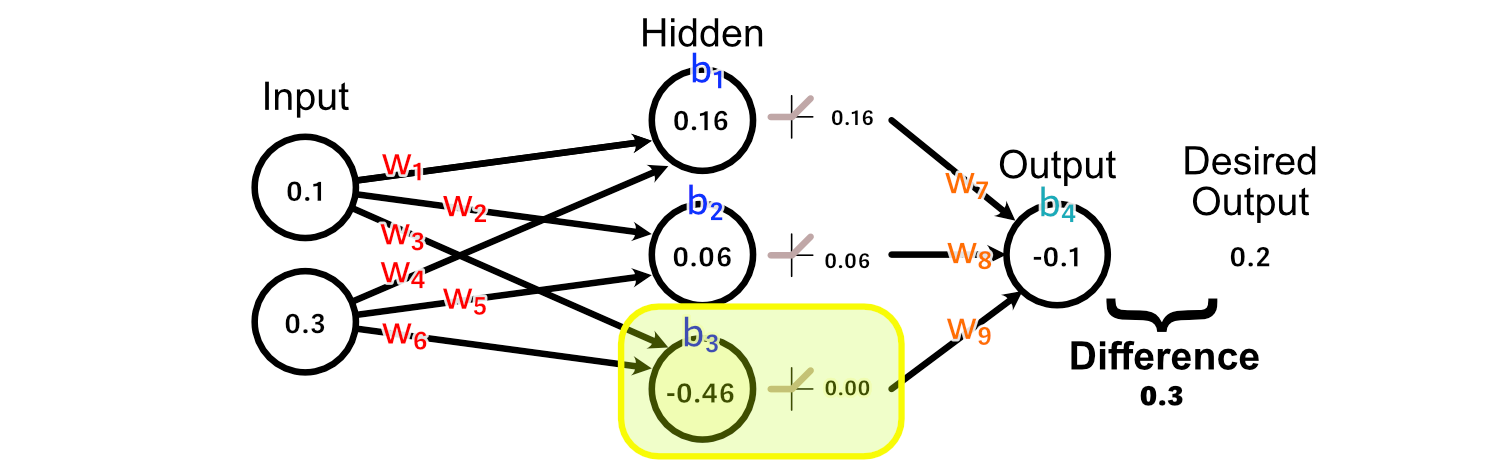
Because of this, there’s no change to w₉ that might outcome us getting nearer to our desired output, as a result of each worth of w₉ would end in a change of zero on this specific instance.
The second hidden neuron, nevertheless, does have an activated output which is bigger than zero, and thus adjusting w₈ will have an effect on the output for this instance.

The best way we truly calculate how a lot w₈ ought to change is by multiplying how a lot the output ought to change, occasions the enter to w₈.
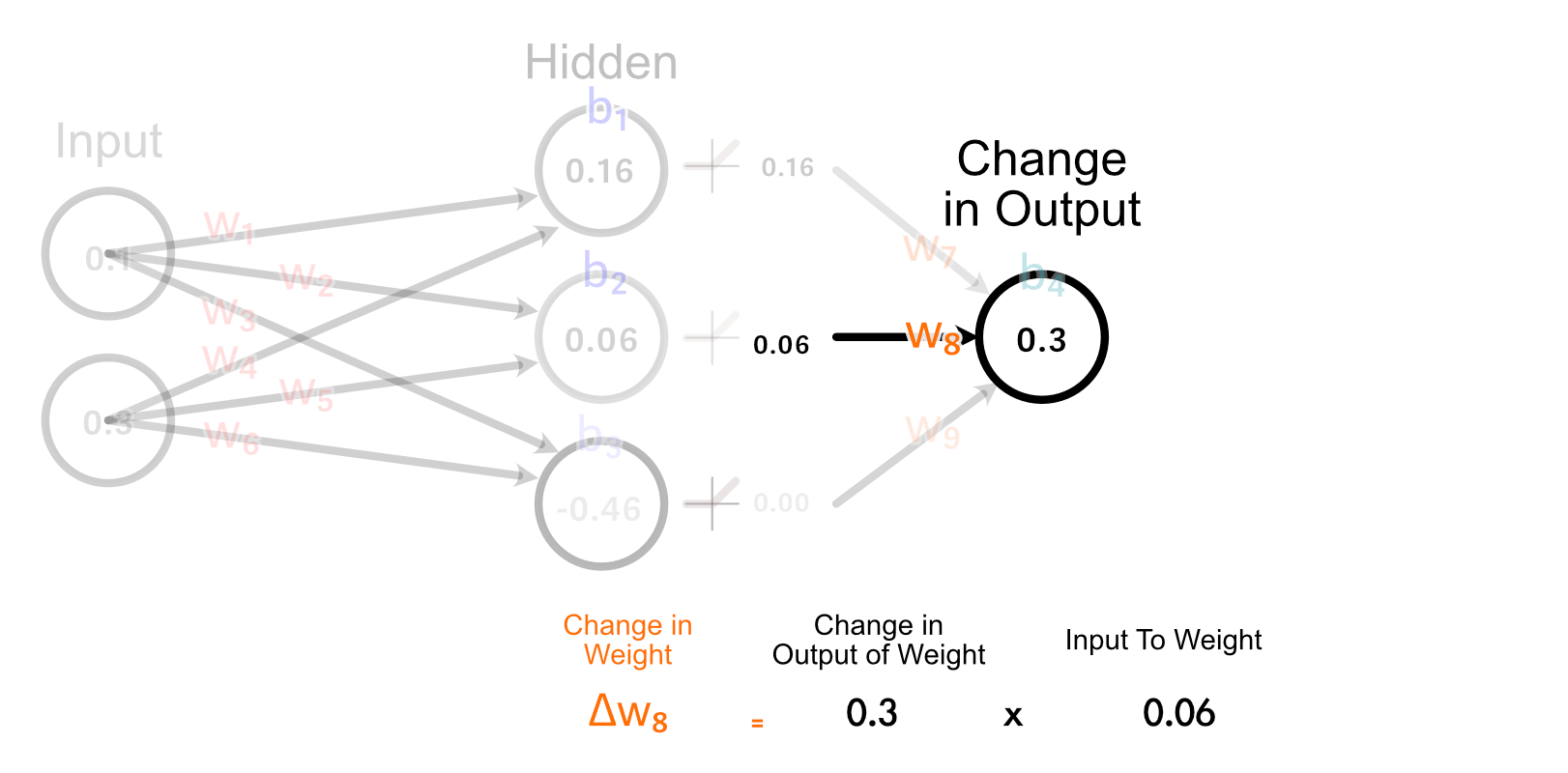
The simplest rationalization of why we do it this fashion is “as a result of calculus”, but when we have a look at how all weights get up to date within the final layer, we are able to kind a enjoyable instinct.
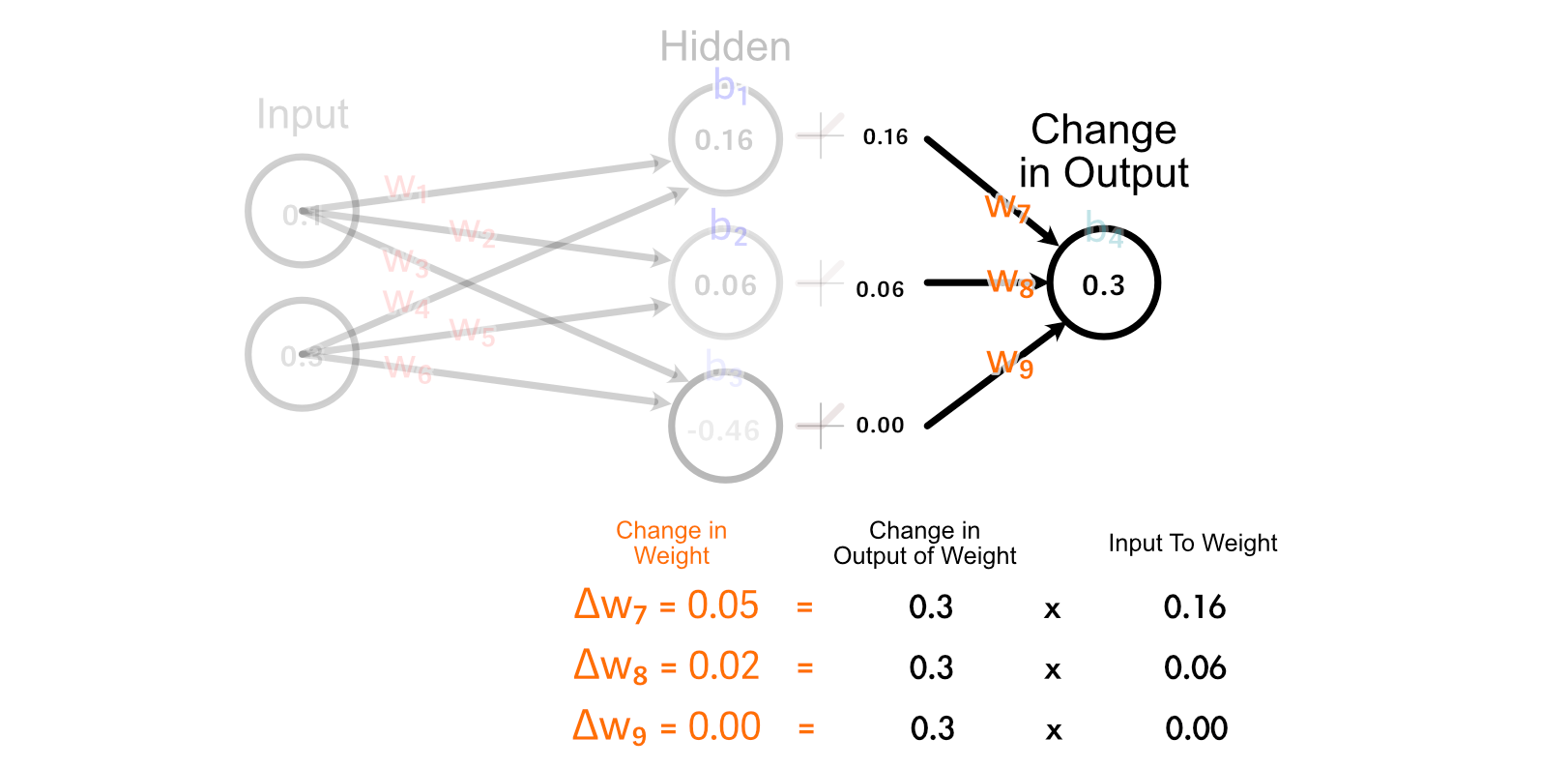
Discover how the 2 perceptrons that “fireplace” (have an output better than zero) are up to date collectively. Additionally, discover how the stronger a perceptrons output is, the extra its corresponding weight is up to date. That is considerably just like the concept that “Neurons that fireside collectively, wire collectively” inside the human mind.
Calculating the change to the output bias is tremendous simple. Actually, we’ve already carried out it. As a result of the bias is how a lot a perceptrons output ought to change, the change within the bias is simply the modified within the desired output. So, Δb₄=0.3
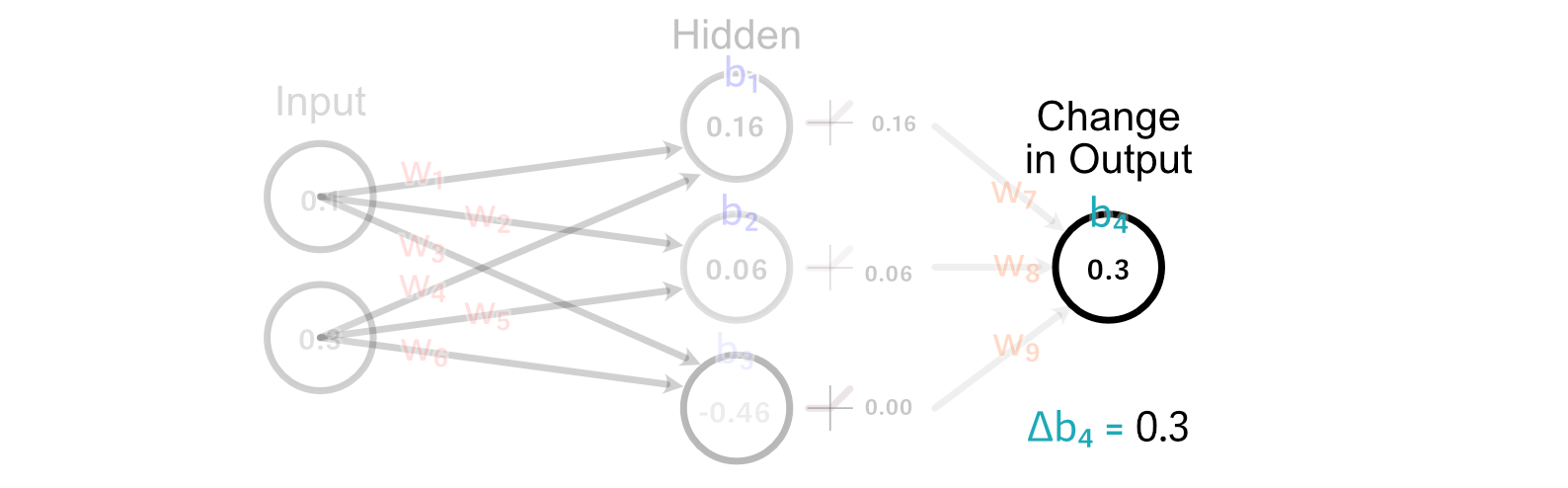
Now that we’ve calculated how the weights and bias of the output perceptron ought to change, we are able to “again propagate” our desired change in output by means of the mannequin. Let’s begin with again propagating so we are able to calculate how we must always replace w₁.
First, we calculate how the activated output of the of the primary hidden neuron ought to change. We try this by multiplying the change in output by w₇.
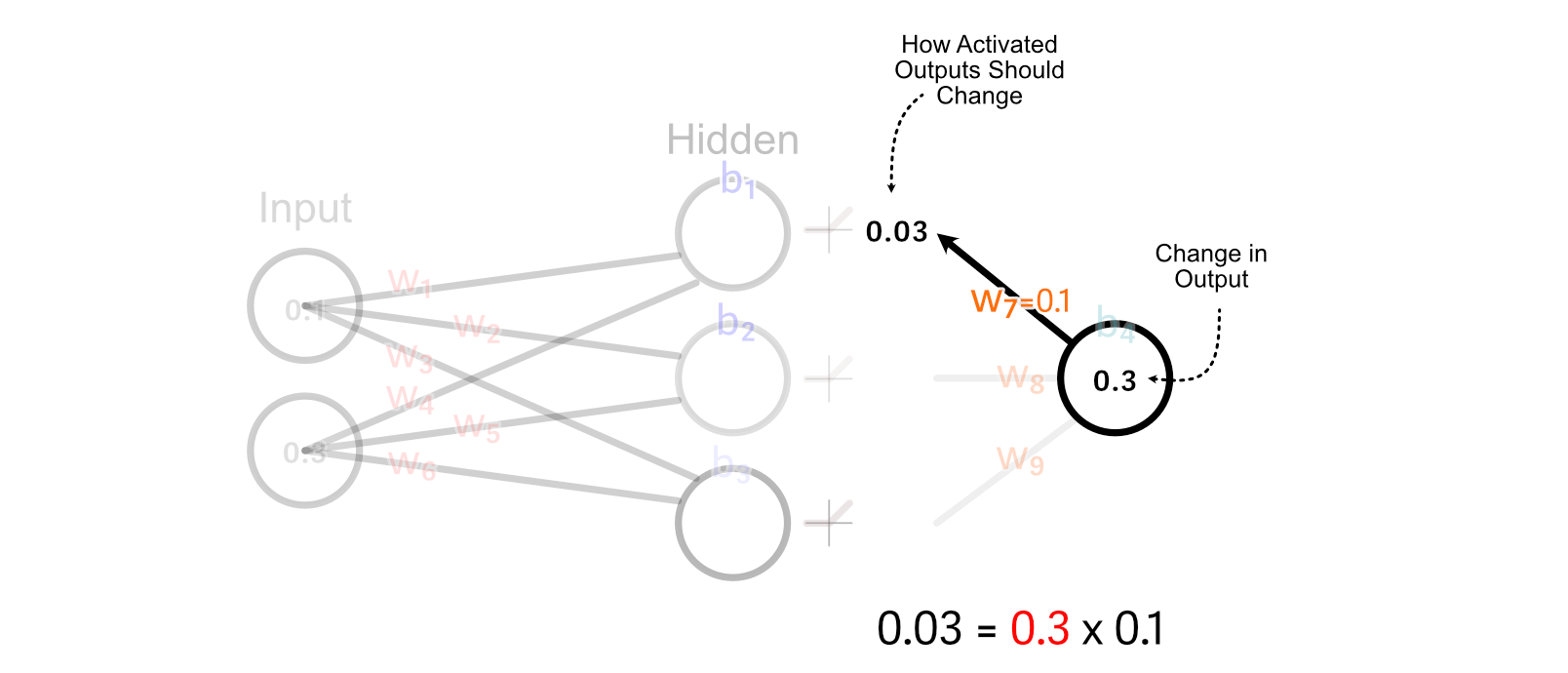
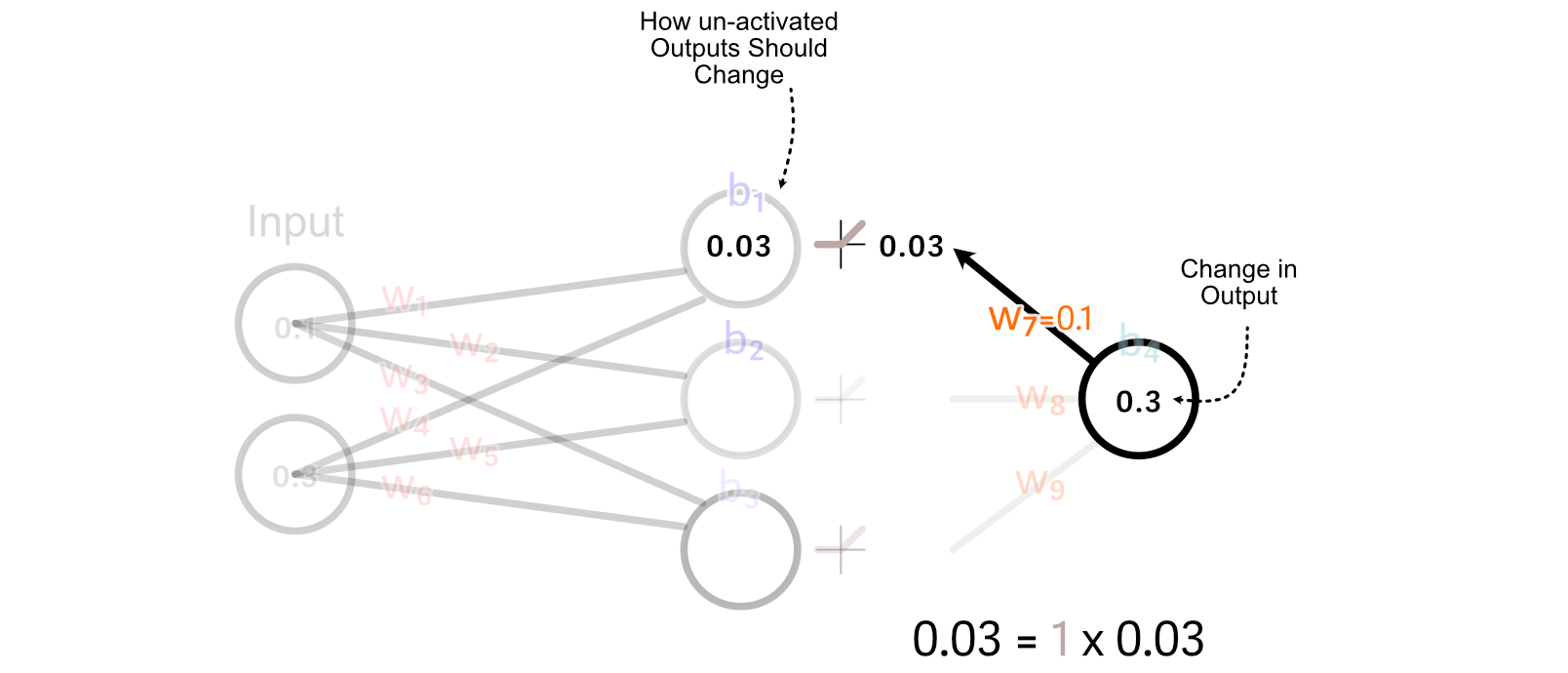
For values which might be better than zero, ReLU merely multiplies these values by 1. So, for this instance, the change we wish the un-activated worth of the primary hidden neuron is the same as the specified change within the activated output
Recall that we calculated methods to replace w₇ primarily based on multiplying it’s enter by the change in its desired output. We will do the identical factor to calculate the change in w₁.
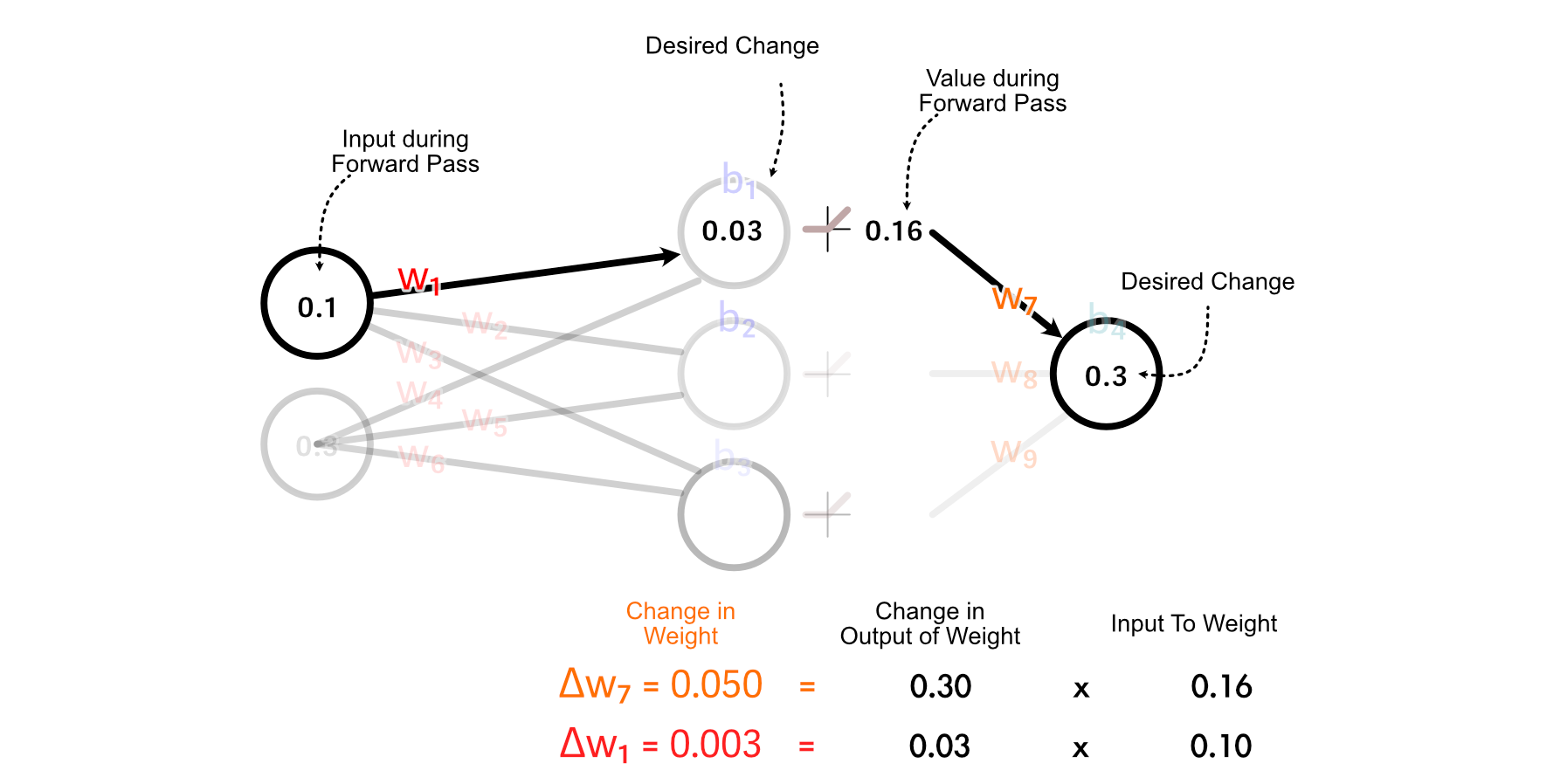
It’s essential to notice, we’re not truly updating any of the weights or biases all through this course of. Fairly, we’re taking a tally of how we must always replace every parameter, assuming no different parameters are up to date.
So, we are able to do these calculations to calculate all parameter adjustments.
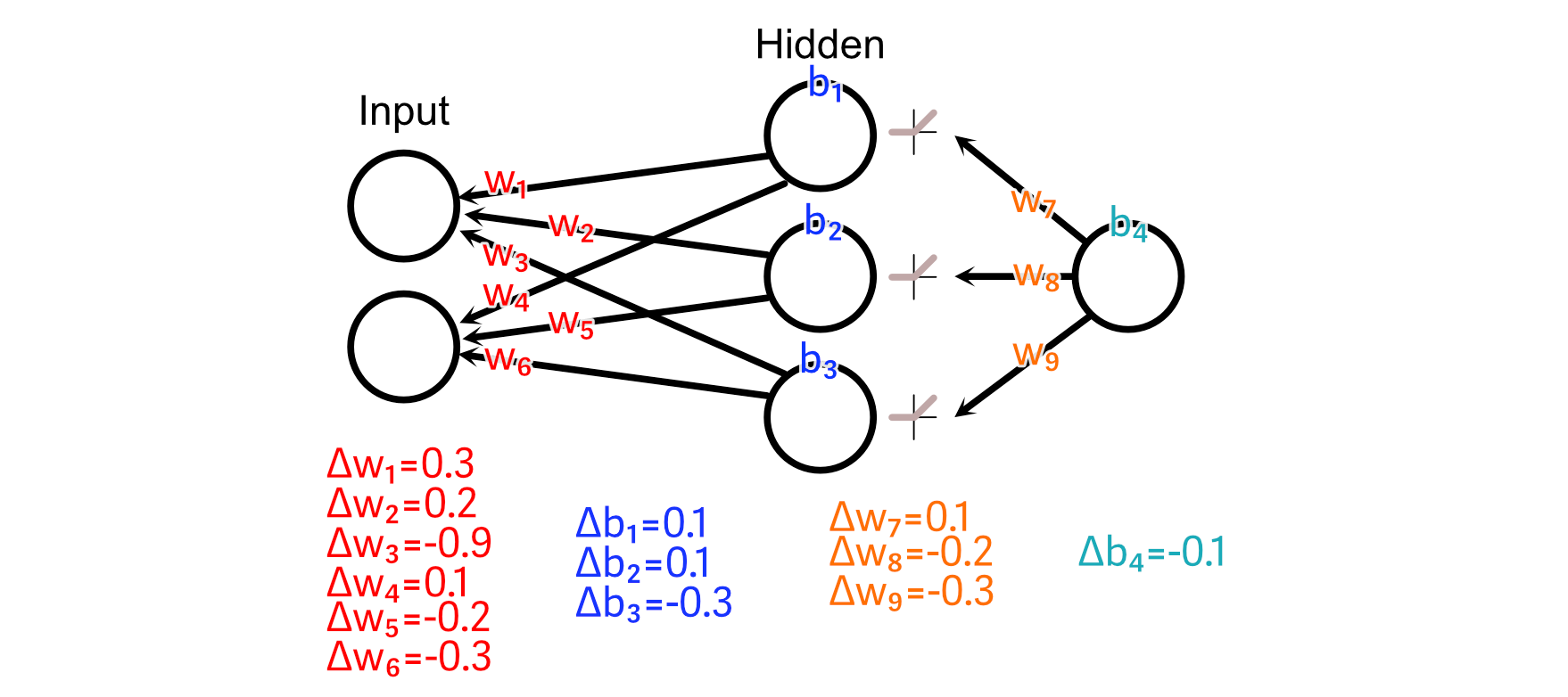
A basic concept of again propagation is named “Studying Charge”, which considerations the scale of the adjustments we make to neural networks primarily based on a specific batch of knowledge. To clarify why that is essential, I’d like to make use of an analogy.
Think about you went outdoors in the future, and everybody carrying a hat gave you a humorous look. You in all probability don’t need to bounce to the conclusion that carrying hat = humorous look , however you is likely to be a bit skeptical of individuals carrying hats. After three, 4, 5 days, a month, or perhaps a 12 months, if it looks like the overwhelming majority of individuals carrying hats are supplying you with a humorous look, you might start thinking about {that a} sturdy pattern.
Equally, once we practice a neural community, we don’t need to utterly change how the neural community thinks primarily based on a single coaching instance. Fairly, we wish every batch to solely incrementally change how the mannequin thinks. As we expose the mannequin to many examples, we might hope that the mannequin would study essential developments inside the knowledge.
After we’ve calculated how every parameter ought to change as if it have been the one parameter being up to date, we are able to multiply all these adjustments by a small quantity, like 0.001 , earlier than making use of these adjustments to the parameters. This small quantity is usually known as the “studying fee”, and the precise worth it ought to have relies on the mannequin we’re coaching on. This successfully scales down our changes earlier than making use of them to the mannequin.
At this level we coated just about every part one would want to know to implement a neural community. Let’s give it a shot!

Implementing a Neural Community from Scratch
Usually, an information scientist would simply use a library like PyTorch to implement a neural community in a couple of strains of code, however we’ll be defining a neural community from the bottom up utilizing NumPy, a numerical computing library.
First, let’s begin with a strategy to outline the construction of the neural community.
"""Blocking out the construction of the Neural Community
"""
import numpy as np
class SimpleNN:
def __init__(self, structure):
self.structure = structure
self.weights = []
self.biases = []
# Initialize weights and biases
np.random.seed(99)
for i in vary(len(structure) - 1):
self.weights.append(np.random.uniform(
low=-1, excessive=1,
measurement=(structure[i], structure[i+1])
))
self.biases.append(np.zeros((1, structure[i+1])))
structure = [2, 64, 64, 64, 1] # Two inputs, two hidden layers, one output
mannequin = SimpleNN(structure)
print('weight dimensions:')
for w in mannequin.weights:
print(w.form)
print('nbias dimensions:')
for b in mannequin.biases:
print(b.form)
Whereas we usually draw neural networks as a dense internet in actuality we symbolize the weights between their connections as matrices. That is handy as a result of matrix multiplication, then, is equal to passing knowledge by means of a neural community.
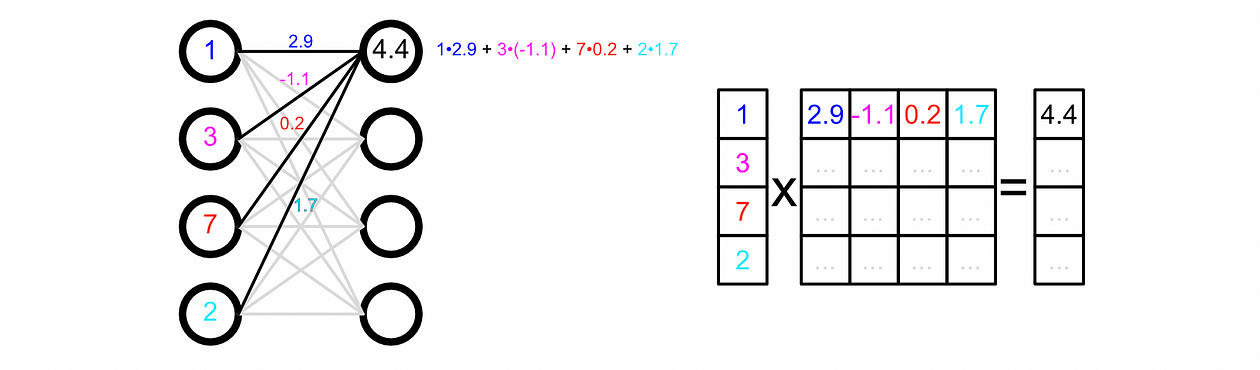
We will make our mannequin make a prediction primarily based on some enter by passing the enter by means of every layer.
"""Implementing the Ahead Go
"""
import numpy as np
class SimpleNN:
def __init__(self, structure):
self.structure = structure
self.weights = []
self.biases = []
# Initialize weights and biases
np.random.seed(99)
for i in vary(len(structure) - 1):
self.weights.append(np.random.uniform(
low=-1, excessive=1,
measurement=(structure[i], structure[i+1])
))
self.biases.append(np.zeros((1, structure[i+1])))
@staticmethod
def relu(x):
#implementing the relu activation operate
return np.most(0, x)
def ahead(self, X):
#iterating by means of all layers
for W, b in zip(self.weights, self.biases):
#making use of the burden and bias of the layer
X = np.dot(X, W) + b
#doing ReLU for all however the final layer
if W shouldn't be self.weights[-1]:
X = self.relu(X)
#returning the outcome
return X
def predict(self, X):
y = self.ahead(X)
return y.flatten()
#defining a mannequin
structure = [2, 64, 64, 64, 1] # Two inputs, two hidden layers, one output
mannequin = SimpleNN(structure)
# Generate predictions
prediction = mannequin.predict(np.array([0.1,0.2]))
print(prediction)
We want to have the ability to practice this mannequin, and to do this we’ll first want an issue to coach the mannequin on. I outlined a random operate that takes in two inputs and leads to an output:
"""Defining what we wish the mannequin to study
"""
import numpy as np
import matplotlib.pyplot as plt
# Outline a random operate with two inputs
def random_function(x, y):
return (np.sin(x) + x * np.cos(y) + y + 3**(x/3))
# Generate a grid of x and y values
x = np.linspace(-10, 10, 100)
y = np.linspace(-10, 10, 100)
X, Y = np.meshgrid(x, y)
# Compute the output of the random operate
Z = random_function(X, Y)
# Create a 2D plot
plt.determine(figsize=(8, 6))
contour = plt.contourf(X, Y, Z, cmap='viridis')
plt.colorbar(contour, label='Operate Worth')
plt.title('2D Plot of Goal Operate')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.present()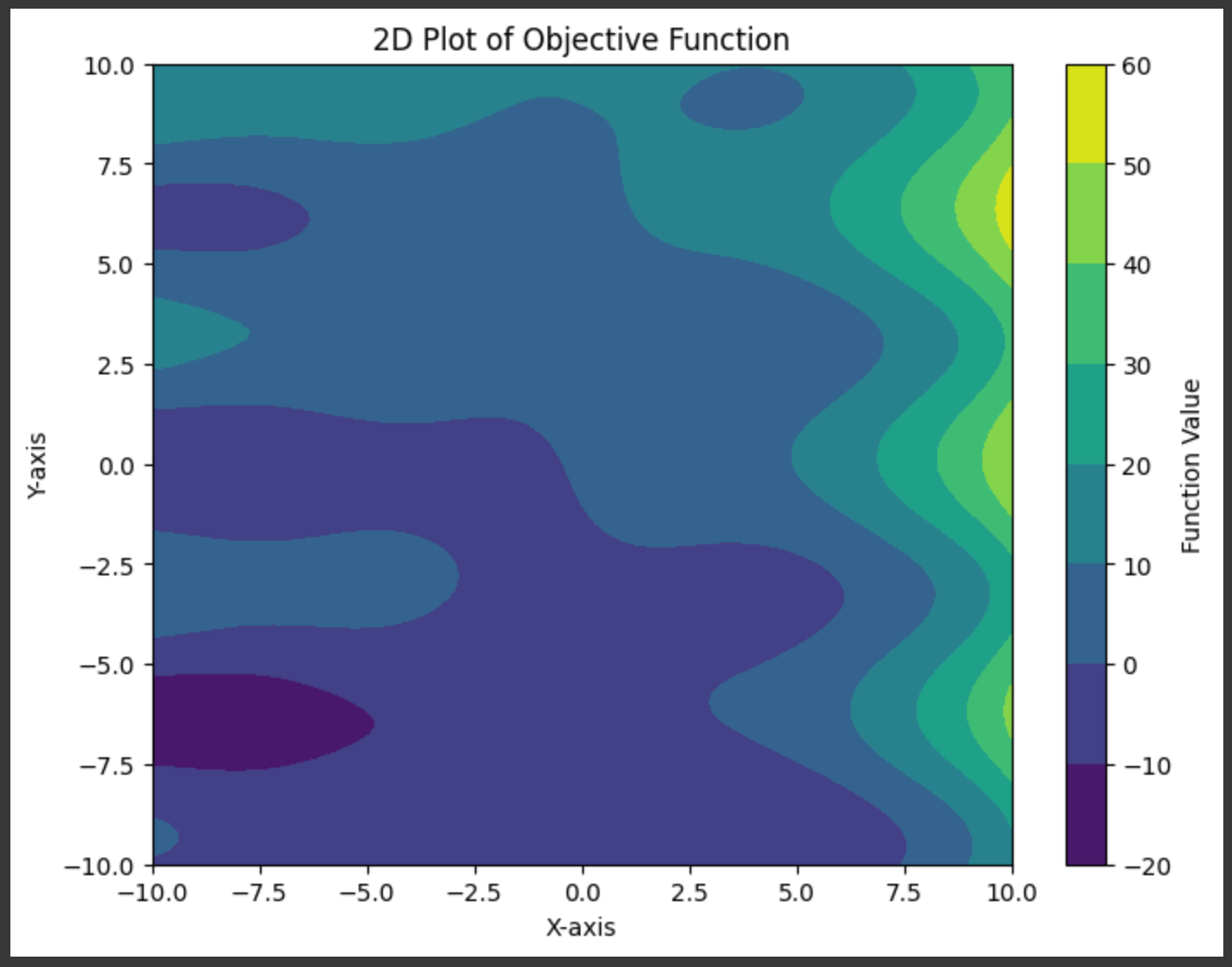
In the actual world we wouldn’t know the underlying operate. We will mimic that actuality by making a dataset consisting of random factors:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Outline a random operate with two inputs
def random_function(x, y):
return (np.sin(x) + x * np.cos(y) + y + 3**(x/3))
# Outline the variety of random samples to generate
n_samples = 1000
# Generate random X and Y values inside a specified vary
x_min, x_max = -10, 10
y_min, y_max = -10, 10
# Generate random values for X and Y
X_random = np.random.uniform(x_min, x_max, n_samples)
Y_random = np.random.uniform(y_min, y_max, n_samples)
# Consider the random operate on the generated X and Y values
Z_random = random_function(X_random, Y_random)
# Create a dataset
dataset = pd.DataFrame({
'X': X_random,
'Y': Y_random,
'Z': Z_random
})
# Show the dataset
print(dataset.head())
# Create a 2D scatter plot of the sampled knowledge
plt.determine(figsize=(8, 6))
scatter = plt.scatter(dataset['X'], dataset['Y'], c=dataset['Z'], cmap='viridis', s=10)
plt.colorbar(scatter, label='Operate Worth')
plt.title('Scatter Plot of Randomly Sampled Information')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.present()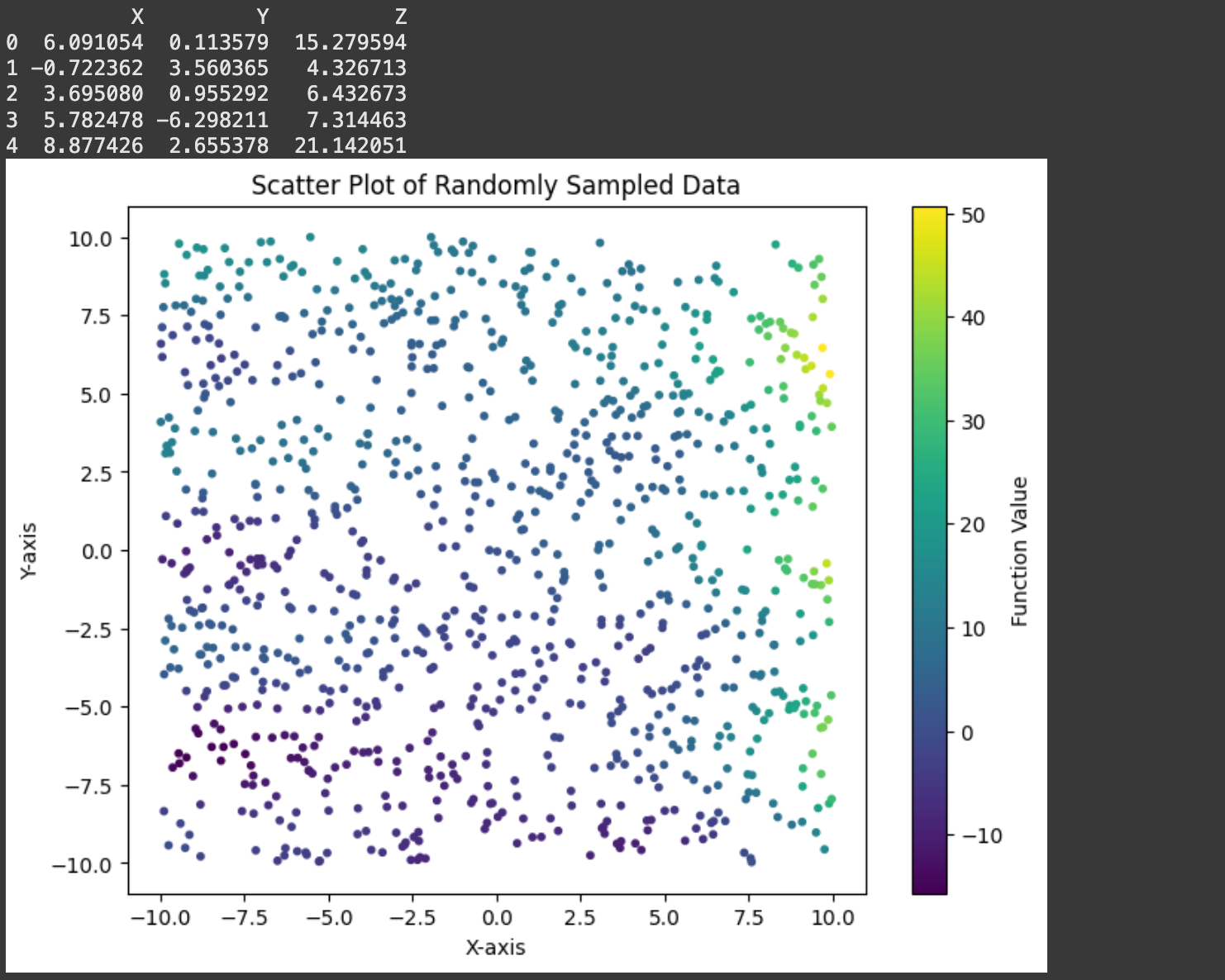
Recall that the again propagation algorithm updates parameters primarily based on what occurs in a ahead cross. So, earlier than we implement backpropagation itself, let’s maintain observe of some essential values within the ahead cross: The inputs and outputs of every perceptron all through the mannequin.
import numpy as np
class SimpleNN:
def __init__(self, structure):
self.structure = structure
self.weights = []
self.biases = []
#holding observe of those values on this code block
#so we are able to observe them
self.perceptron_inputs = None
self.perceptron_outputs = None
# Initialize weights and biases
np.random.seed(99)
for i in vary(len(structure) - 1):
self.weights.append(np.random.uniform(
low=-1, excessive=1,
measurement=(structure[i], structure[i+1])
))
self.biases.append(np.zeros((1, structure[i+1])))
@staticmethod
def relu(x):
return np.most(0, x)
def ahead(self, X):
self.perceptron_inputs = [X]
self.perceptron_outputs = []
for W, b in zip(self.weights, self.biases):
Z = np.dot(self.perceptron_inputs[-1], W) + b
self.perceptron_outputs.append(Z)
if W is self.weights[-1]: # Final layer (output)
A = Z # Linear output for regression
else:
A = self.relu(Z)
self.perceptron_inputs.append(A)
return self.perceptron_inputs, self.perceptron_outputs
def predict(self, X):
perceptron_inputs, _ = self.ahead(X)
return perceptron_inputs[-1].flatten()
#defining a mannequin
structure = [2, 64, 64, 64, 1] # Two inputs, two hidden layers, one output
mannequin = SimpleNN(structure)
# Generate predictions
prediction = mannequin.predict(np.array([0.1,0.2]))
#trying by means of crucial optimization values
for i, (inpt, outpt) in enumerate(zip(mannequin.perceptron_inputs, mannequin.perceptron_outputs[:-1])):
print(f'layer {i}')
print(f'enter: {inpt.form}')
print(f'output: {outpt.form}')
print('')
print('Last Output:')
print(mannequin.perceptron_outputs[-1].form)
Now that we’ve got a document saved of crucial middleman worth inside the community, we are able to use these values, together with the error of a mannequin for a specific prediction, to calculate the adjustments we must always make to the mannequin.
import numpy as np
class SimpleNN:
def __init__(self, structure):
self.structure = structure
self.weights = []
self.biases = []
# Initialize weights and biases
np.random.seed(99)
for i in vary(len(structure) - 1):
self.weights.append(np.random.uniform(
low=-1, excessive=1,
measurement=(structure[i], structure[i+1])
))
self.biases.append(np.zeros((1, structure[i+1])))
@staticmethod
def relu(x):
return np.most(0, x)
@staticmethod
def relu_as_weights(x):
return (x > 0).astype(float)
def ahead(self, X):
perceptron_inputs = [X]
perceptron_outputs = []
for W, b in zip(self.weights, self.biases):
Z = np.dot(perceptron_inputs[-1], W) + b
perceptron_outputs.append(Z)
if W is self.weights[-1]: # Final layer (output)
A = Z # Linear output for regression
else:
A = self.relu(Z)
perceptron_inputs.append(A)
return perceptron_inputs, perceptron_outputs
def backward(self, perceptron_inputs, perceptron_outputs, goal):
weight_changes = []
bias_changes = []
m = len(goal)
dA = perceptron_inputs[-1] - goal.reshape(-1, 1) # Output layer gradient
for i in reversed(vary(len(self.weights))):
dZ = dA if i == len(self.weights) - 1 else dA * self.relu_as_weights(perceptron_outputs[i])
dW = np.dot(perceptron_inputs[i].T, dZ) / m
db = np.sum(dZ, axis=0, keepdims=True) / m
weight_changes.append(dW)
bias_changes.append(db)
if i > 0:
dA = np.dot(dZ, self.weights[i].T)
return record(reversed(weight_changes)), record(reversed(bias_changes))
def predict(self, X):
perceptron_inputs, _ = self.ahead(X)
return perceptron_inputs[-1].flatten()
#defining a mannequin
structure = [2, 64, 64, 64, 1] # Two inputs, two hidden layers, one output
mannequin = SimpleNN(structure)
#defining a pattern enter and goal output
enter = np.array([[0.1,0.2]])
desired_output = np.array([0.5])
#doing ahead and backward cross to calculate adjustments
perceptron_inputs, perceptron_outputs = mannequin.ahead(enter)
weight_changes, bias_changes = mannequin.backward(perceptron_inputs, perceptron_outputs, desired_output)
#smaller numbers for printing
np.set_printoptions(precision=2)
for i, (layer_weights, layer_biases, layer_weight_changes, layer_bias_changes)
in enumerate(zip(mannequin.weights, mannequin.biases, weight_changes, bias_changes)):
print(f'layer {i}')
print(f'weight matrix: {layer_weights.form}')
print(f'weight matrix adjustments: {layer_weight_changes.form}')
print(f'bias matrix: {layer_biases.form}')
print(f'bias matrix adjustments: {layer_bias_changes.form}')
print('')
print('The burden and weight change matrix of the second layer:')
print('weight matrix:')
print(mannequin.weights[1])
print('change matrix:')
print(weight_changes[1])
That is in all probability essentially the most complicated implementation step, so I need to take a second to dig by means of a number of the particulars. The basic concept is precisely as we described in earlier sections. We’re iterating over all layers, from again to entrance, and calculating what change to every weight and bias would end in a greater output.
# calculating output error
dA = perceptron_inputs[-1] - goal.reshape(-1, 1)
#a scaling issue for the batch measurement.
#you need adjustments to be a mean throughout all batches
#so we divide by m as soon as we have aggregated all adjustments.
m = len(goal)
for i in reversed(vary(len(self.weights))):
dZ = dA #simplified for now
# calculating change to weights
dW = np.dot(perceptron_inputs[i].T, dZ) / m
# calculating change to bias
db = np.sum(dZ, axis=0, keepdims=True) / m
# holding observe of required adjustments
weight_changes.append(dW)
bias_changes.append(db)
...Calculating the change to bias is fairly straight ahead. In the event you have a look at how the output of a given neuron ought to have impacted all future neurons, you possibly can add up all these values (that are each constructive and unfavourable) to get an concept of if the neuron must be biased in a constructive or unfavourable path.
The best way we calculate the change to weights, by utilizing matrix multiplication, is a little more mathematically complicated.
dW = np.dot(perceptron_inputs[i].T, dZ) / mPrincipally, this line says that the change within the weight must be equal to the worth going into the perceptron, occasions how a lot the output ought to have modified. If a perceptron had a giant enter, the change to its outgoing weights must be a big magnitude, if the perceptron had a small enter, the change to its outgoing weights will likely be small. Additionally, if a weight factors in direction of an output which ought to change so much, the burden ought to change so much.
There’s one other line we must always talk about in our again propagation implement.
dZ = dA if i == len(self.weights) - 1 else dA * self.relu_as_weights(perceptron_outputs[i])On this specific community, there are activation capabilities all through the community, following all however the closing output. Once we do again propagation, we have to back-propagate by means of these activation capabilities in order that we are able to replace the neurons which lie earlier than them. We do that for all however the final layer, which doesn’t have an activation operate, which is why dZ = dA if i == len(self.weights) - 1 .
In fancy math communicate we might name this a by-product, however as a result of I don’t need to get into calculus, I referred to as the operate relu_as_weights . Principally, we are able to deal with every of our ReLU activations as one thing like a tiny neural community, who’s weight is a operate of the enter. If the enter of the ReLU activation operate is lower than zero, then that’s like passing that enter by means of a neural community with a weight of zero. If the enter of ReLU is bigger than zero, then that’s like passing the enter by means of a neural netowork with a weight of 1.
That is precisely what the relu_as_weights operate does.
def relu_as_weights(x):
return (x > 0).astype(float)Utilizing this logic we are able to deal with again propagating by means of ReLU similar to we again propagate by means of the remainder of the neural community.
Once more, I’ll be overlaying this idea from a extra strong mathematical potential quickly, however that’s the important concept from a conceptual perspective.
Now that we’ve got the ahead and backward cross carried out, we are able to implement coaching the mannequin.
import numpy as np
class SimpleNN:
def __init__(self, structure):
self.structure = structure
self.weights = []
self.biases = []
# Initialize weights and biases
np.random.seed(99)
for i in vary(len(structure) - 1):
self.weights.append(np.random.uniform(
low=-1, excessive=1,
measurement=(structure[i], structure[i+1])
))
self.biases.append(np.zeros((1, structure[i+1])))
@staticmethod
def relu(x):
return np.most(0, x)
@staticmethod
def relu_as_weights(x):
return (x > 0).astype(float)
def ahead(self, X):
perceptron_inputs = [X]
perceptron_outputs = []
for W, b in zip(self.weights, self.biases):
Z = np.dot(perceptron_inputs[-1], W) + b
perceptron_outputs.append(Z)
if W is self.weights[-1]: # Final layer (output)
A = Z # Linear output for regression
else:
A = self.relu(Z)
perceptron_inputs.append(A)
return perceptron_inputs, perceptron_outputs
def backward(self, perceptron_inputs, perceptron_outputs, y_true):
weight_changes = []
bias_changes = []
m = len(y_true)
dA = perceptron_inputs[-1] - y_true.reshape(-1, 1) # Output layer gradient
for i in reversed(vary(len(self.weights))):
dZ = dA if i == len(self.weights) - 1 else dA * self.relu_as_weights(perceptron_outputs[i])
dW = np.dot(perceptron_inputs[i].T, dZ) / m
db = np.sum(dZ, axis=0, keepdims=True) / m
weight_changes.append(dW)
bias_changes.append(db)
if i > 0:
dA = np.dot(dZ, self.weights[i].T)
return record(reversed(weight_changes)), record(reversed(bias_changes))
def update_weights(self, weight_changes, bias_changes, lr):
for i in vary(len(self.weights)):
self.weights[i] -= lr * weight_changes[i]
self.biases[i] -= lr * bias_changes[i]
def practice(self, X, y, epochs, lr=0.01):
for epoch in vary(epochs):
perceptron_inputs, perceptron_outputs = self.ahead(X)
weight_changes, bias_changes = self.backward(perceptron_inputs, perceptron_outputs, y)
self.update_weights(weight_changes, bias_changes, lr)
if epoch % 20 == 0 or epoch == epochs - 1:
loss = np.imply((perceptron_inputs[-1].flatten() - y) ** 2) # MSE
print(f"EPOCH {epoch}: Loss = {loss:.4f}")
def predict(self, X):
perceptron_inputs, _ = self.ahead(X)
return perceptron_inputs[-1].flatten()The practice operate:
- iterates by means of all the information some variety of occasions (outlined by
epoch) - passes the information by means of a ahead cross
- calculates how the weights and biases ought to change
- updates the weights and biases, by scaling their adjustments by the educational fee (
lr)
And thus we’ve carried out a neural community! Let’s practice it.
Coaching and Evaluating the Neural Community.
Recall that we outlined an arbitrary 2D operate we wished to learn to emulate,
and we sampled that area with some variety of factors, which we’re utilizing to coach the mannequin.

Earlier than feeding this knowledge into our mannequin, it’s important that we first “normalize” the information. Sure values of the dataset are very small or very giant, which may make coaching a neural community very tough. Values inside the neural community can shortly develop to absurdly giant values, or diminish to zero, which may inhibit coaching. Normalization squashes all of our inputs, and our desired outputs, right into a extra affordable vary averaging round zero with a standardized distribution referred to as a “regular” distribution.
# Flatten the information
X_flat = X.flatten()
Y_flat = Y.flatten()
Z_flat = Z.flatten()
# Stack X and Y as enter options
inputs = np.column_stack((X_flat, Y_flat))
outputs = Z_flat
# Normalize the inputs and outputs
inputs_mean = np.imply(inputs, axis=0)
inputs_std = np.std(inputs, axis=0)
outputs_mean = np.imply(outputs)
outputs_std = np.std(outputs)
inputs = (inputs - inputs_mean) / inputs_std
outputs = (outputs - outputs_mean) / outputs_stdIf we need to get again predictions within the precise vary of knowledge from our authentic dataset, we are able to use these values to primarily “un-squash” the information.
As soon as we’ve carried out that, we are able to outline and practice our mannequin.
# Outline the structure: [input_dim, hidden1, ..., output_dim]
structure = [2, 64, 64, 64, 1] # Two inputs, two hidden layers, one output
mannequin = SimpleNN(structure)
# Prepare the mannequin
mannequin.practice(inputs, outputs, epochs=2000, lr=0.001)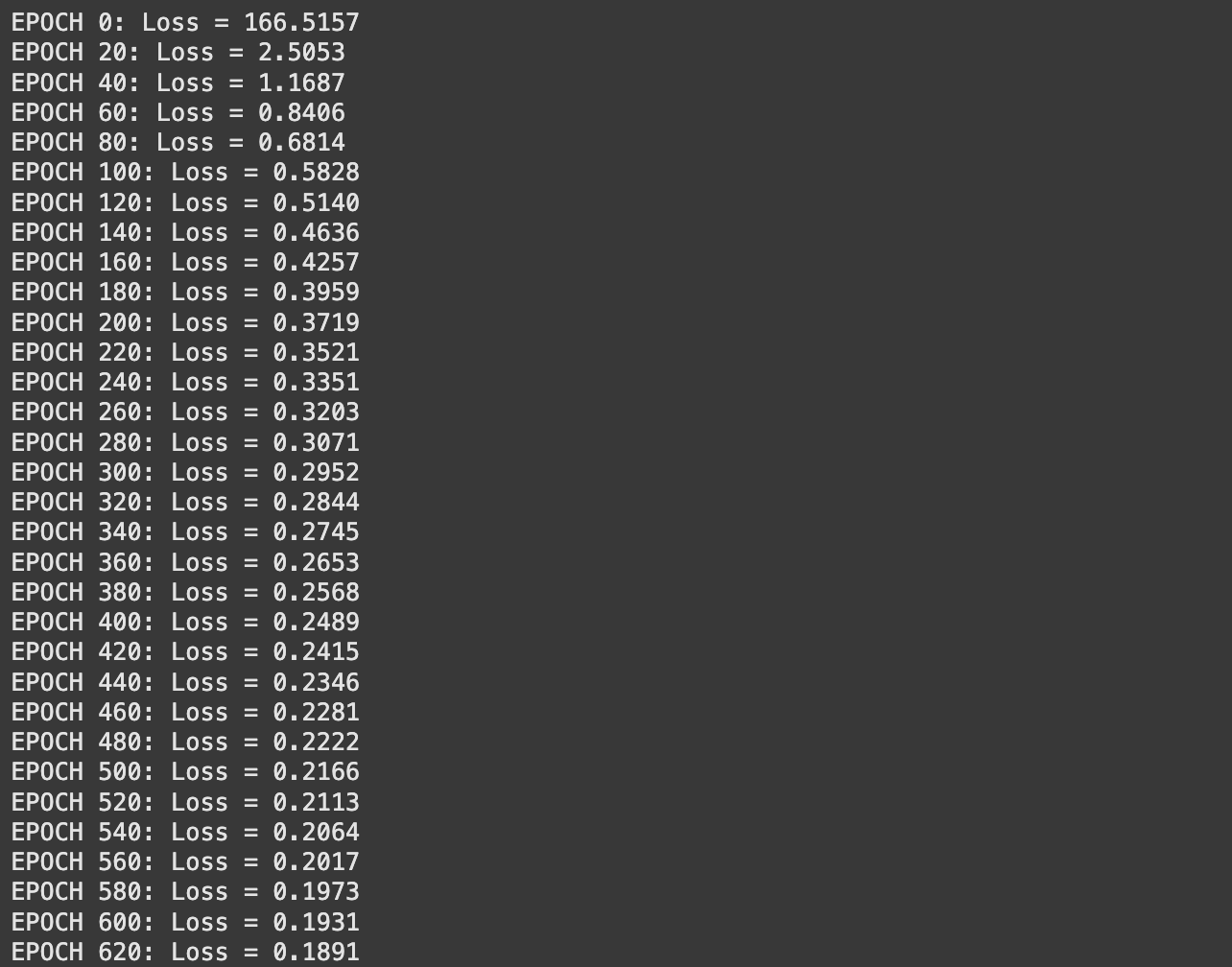
Then we are able to visualize the output of the neural community’s prediction vs the precise operate.
import matplotlib.pyplot as plt
# Reshape predictions to grid format for visualization
Z_pred = mannequin.predict(inputs) * outputs_std + outputs_mean
Z_pred = Z_pred.reshape(X.form)
# Plot comparability of the true operate and the mannequin predictions
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Plot the true operate
axes[0].contourf(X, Y, Z, cmap='viridis')
axes[0].set_title("True Operate")
axes[0].set_xlabel("X-axis")
axes[0].set_ylabel("Y-axis")
axes[0].colorbar = plt.colorbar(axes[0].contourf(X, Y, Z, cmap='viridis'), ax=axes[0], label="Operate Worth")
# Plot the anticipated operate
axes[1].contourf(X, Y, Z_pred, cmap='plasma')
axes[1].set_title("NN Predicted Operate")
axes[1].set_xlabel("X-axis")
axes[1].set_ylabel("Y-axis")
axes[1].colorbar = plt.colorbar(axes[1].contourf(X, Y, Z_pred, cmap='plasma'), ax=axes[1], label="Operate Worth")
plt.tight_layout()
plt.present()
This did an okay job, however not as nice as we would like. That is the place plenty of knowledge scientists spend their time, and there are a ton of approaches to creating a neural community match a sure downside higher. Some apparent ones are:
- use extra knowledge
- mess around with the educational fee
- practice for extra epochs
- change the construction of the mannequin
It’s fairly simple for us to crank up the quantity of knowledge we’re coaching on. Let’s see the place that leads us. Right here I’m sampling our dataset 10,000 occasions, which is 10x extra coaching samples than our earlier dataset.

After which I educated the mannequin similar to earlier than, besides this time it took so much longer as a result of every epoch now analyses 10,000 samples slightly than 1,000.
# Outline the structure: [input_dim, hidden1, ..., output_dim]
structure = [2, 64, 64, 64, 1] # Two inputs, two hidden layers, one output
mannequin = SimpleNN(structure)
# Prepare the mannequin
mannequin.practice(inputs, outputs, epochs=2000, lr=0.001)
I then rendered the output of this mannequin, the identical manner I did earlier than, nevertheless it didn’t actually appear like the output acquired a lot better.

Trying again on the loss output from coaching, it looks like the loss continues to be steadily declining. Perhaps I simply want to coach for longer. Let’s attempt that.
# Outline the structure: [input_dim, hidden1, ..., output_dim]
structure = [2, 64, 64, 64, 1] # Two inputs, two hidden layers, one output
mannequin = SimpleNN(structure)
# Prepare the mannequin
mannequin.practice(inputs, outputs, epochs=4000, lr=0.001)
The outcomes appear to be a bit higher, however they aren’t’ superb.

I’ll spare you the main points. I ran this a couple of occasions, and I acquired some respectable outcomes, however by no means something 1 to 1. I’ll be overlaying some extra superior approaches knowledge scientists use, like annealing and dropout, in future articles which is able to end in a extra constant and higher output. Nonetheless, although, we made a neural community from scratch and educated it to do one thing, and it did an honest job! Fairly neat!
Conclusion
On this article we averted calculus just like the plague whereas concurrently forging an understanding of Neural Networks. We explored their concept, a bit bit concerning the math, the thought of again propagation, after which carried out a neural community from scratch. We then utilized a neural community to a toy downside, and explored a number of the easy concepts knowledge scientists make use of to truly practice neural networks to be good at issues.
In future articles we’ll discover a couple of extra superior approaches to Neural Networks, so keep tuned! For now, you is likely to be excited about a extra thorough evaluation of Gradients, the basic math behind again propagation.
You may also have an interest on this article, which covers coaching a neural community utilizing extra typical Information Science instruments like PyTorch.
AI for the Absolute Novice – Intuitively and Exhaustively Defined
Be a part of Intuitively and Exhaustively Defined
At IAEE you could find:
- Lengthy kind content material, just like the article you simply learn
- Conceptual breakdowns of a number of the most cutting-edge AI matters
- By-Hand walkthroughs of crucial mathematical operations in AI
- Sensible tutorials and explainers
