Tremendous-tuning giant language fashions (LLMs) is a necessary approach for customizing LLMs for particular wants, resembling adopting a specific writing type or specializing in a selected area. OpenAI and Google AI Studio are two main platforms providing instruments for this goal, every with distinct options and workflows. On this article, we are going to study how these platforms carry out in fine-tuning duties, utilizing my beforehand written articles as coaching information. We are going to consider the flexibility of OpenAI Platform and Google AI Studio to fine-tune LLMs to generate content material that mirrors my writing type.
OpenAI Platform
The OpenAI platform presents a complete resolution for fine-tuning fashions, permitting customers to customise and optimize them for particular duties. This platform helps quite a lot of fashions, together with GPT-4o and GPT-4o-mini. OpenAI additionally supplies steering for information preparation, mannequin coaching, and analysis. By leveraging the OpenAI platform, customers can improve the efficiency of fashions in particular domains. This makes them more practical and environment friendly for focused purposes.
The price of fine-tuning is as follows:
| Mannequin | Pricing |
|---|---|
| gpt-4o-2024-08-06 | $3.750 / 1M enter tokens $15.000 / 1M output tokens $25.000 / 1M coaching tokens |
| gpt-4o-mini-2024-07-18 | $0.300 / 1M enter tokens $1.200 / 1M output tokens $3.000 / 1M coaching tokens |
The price of inference for fine-tuned fashions is double that of pre-existing fashions.
Information Preparation
LLMs want information to be in a selected format for fine-tuning. Right here’s an instance format for GPT-4o and GPT-4o-mini fashions.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}After we fine-tune the mannequin, it should be taught to provide responses much like assistant position content material for a given person position content material.
Since we wish the mannequin to provide content material much like ours, we must always use our content material instead of assistant content material.
Let’s take into account this content material from certainly one of my articles:
“So, moderately than traversing all of the nodes utilizing a graph utilizing HNSW, we’re localising the search area utilizing dynamic vantage level tree on this algorithm.
This mixture of utilizing each tree and graph makes it one of many quickest and most correct algorithms.”
Since we wish the LLM to generate content material just like the one above, it needs to be added because the assistant content material like this:
{"position": "assistant", "content material": "So, moderately than traversing all of the nodes utilizing a graph utilizing HNSW, we're localising the search area utilizing dynamic vantage level tree on this algorithm.This mixture of utilizing each tree and graph makes it one of many quickest and most correct algorithms."}For the LLM to generate content material like this, it wants person content material (i.e. immediate). As we don’t have it, we are able to generate the person content material utilizing an LLM. The person content material could be as follows:
{"position": "person", "content material": "Are you able to clarify how the mixture of dynamic vantage level bushes and hierarchical navigable small world (HNSW) graphs improves search effectivity and accuracy in algorithms?"}We additionally embody an appropriate system immediate the instance for our fine-tuning will probably be as follows
{"messages": [{"role": "system", "content": "You are an assistant who writes in a clear, informative, and engaging style."}, {"role": "user", "content": "Can you explain how the combination of dynamic vantage point trees and hierarchical navigable small world (HNSW) graphs improves search efficiency and accuracy in algorithms?"}, {"role": "assistant", "content": "So, rather than traversing all the nodes using a graph using HNSW, we are localising the search space using dynamic vantage point tree in this algorithm.n This combination of using both tree and graph makes it one of the fastest and most accurate algorithms."}]}If we use a small dimension of content material, it’s attainable that the mannequin may miss the context. We have to maintain this in thoughts whereas information preparation. I’m solely utilizing 38 examples right here, however 100 to 500 can be significantly better. I’ve created a ‘my content material.csv’ file the place every row has the content material written by me beneath the column title ‘content material’.
Now let’s undergo the code to create the required information in the correct format.
Code Implementation
OpenAI model 1.57.0 is used right here.
1. Import the libraries.
from dotenv import load_dotenv
load_dotenv('/.env')
import pandas as pd
import tiktoken
from openai import OpenAI
# Initialize the openai shopper
shopper = OpenAI()
2. Test token dimension.
df = pd.read_csv('my content material.csv')
encoding = tiktoken.get_encoding('o200k_base')
total_token_count = 0
for i in df['content']:
token_count = len(encoding.encode(i))
total_token_count += token_countCounting tokens will assist us to estimate the price of fine-tuning.
3. Generate person content material for the LLM.
def generate_user_content(assistant_response):
# system_message = {"position": "system", "content material": "You're a useful assistant. Your process is to generate person question primarily based on the assistant's response."}
system_message = {"position": "system", "content material": """Given the assistant's response, create a person question or
assertion that may logically result in that response.
The person content material could be within the type of a query or a request for clarification that prompts the
assistant to provide the offered reply"""}
assistant_message = {"position": "assistant", "content material": assistant_response}
messages = [system_message, assistant_message]
response = shopper.chat.completions.create(
messages=messages,
mannequin="gpt-4o-mini",
temperature=1
)
user_content = response.selections[0].message.content material
return user_contentAs we are able to see, I’ve offered the content material I wrote as assistant content material and requested the LLM to generate person content material.
user_contents = []
for i in df['content']:
user_content = generate_user_content(i)
user_contents.append(user_content)
df['user_content'] = user_contentsWe are able to add the generated person content material to the dataframe as a column. The info will seem like this:

Right here, content material is written by me and user_content is generated by the LLM to make use of as a person position content material (immediate) whereas fine-tuning.
We are able to save the file now.
df.to_csv('user_content.csv', index=False)4. Create Jsonl file.
Now we are able to use the above csv file to create jsonl file as wanted for fine-tuning.
messages = pd.read_csv('user_content.csv')
messages.rename(columns={'content material': 'assistant_content'}, inplace=True)
with open('messages_dataset.jsonl', 'w', encoding='utf-8') as jsonl_file:
for _, row in messages.iterrows():
user_content = row['user_content']
assistant_content = row['assistant_content']
jsonl_entry = {
"messages": [
{"role": "system", "content": "You are an assistant who writes in a clear, informative, and engaging style."},
{"role": "user", "content": user_content},
{"role": "assistant", "content": assistant_content}]
}
jsonl_file.write(json.dumps(jsonl_entry) + 'n')
As proven above, we are able to iterate by the dataframe to create the jsonl file.
Tremendous-tuning in OpenAI Platform
Now, we are able to use ‘messages_dataset.jsonl’ to fine-tune OpenAI LLMs.
Go to the web site and register if not signed in already.
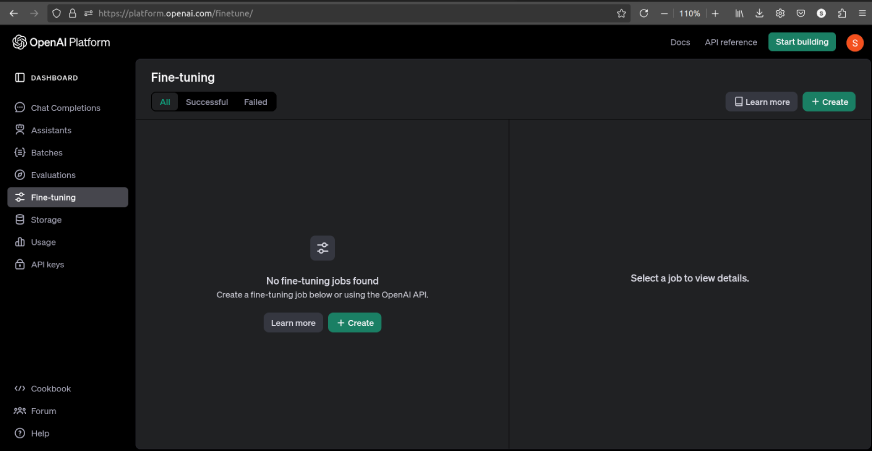
If there aren’t any fine-tuning jobs, the interface will probably be as follows:
We are able to click on on ‘Study extra’ to be taught all of the particulars wanted for fine-tuning, together with the tuneable hyper-parameters.
Now let’s discover ways to fine-tune a mannequin on OpenAI Platform.
- Click on on ‘Create’. A small window will open.
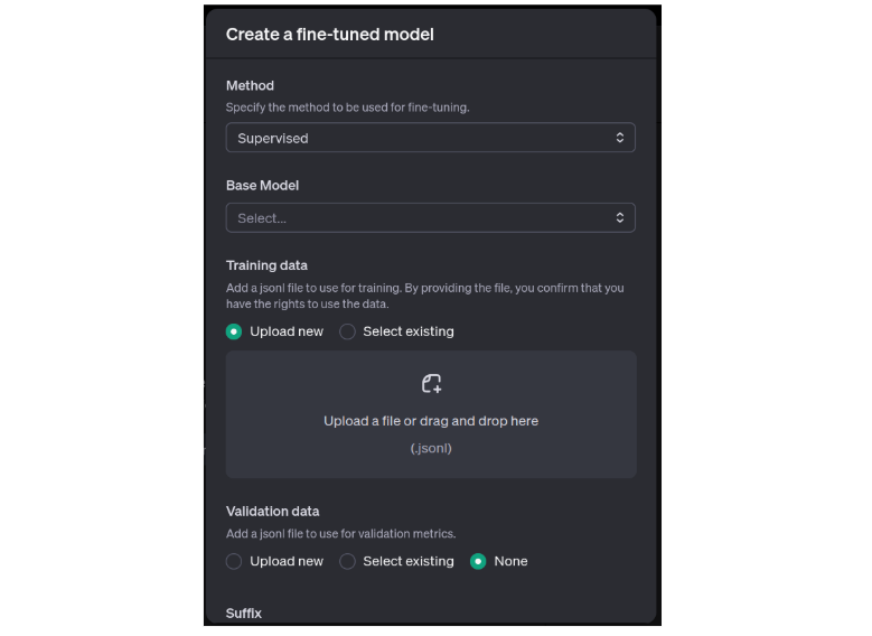
- Choose the tactic as ‘Supervised’
- Choose the Base Mannequin as both ‘gpt-4o’ or ‘gpt-4o-mini’. I bought an error whereas utilizing gpt-4o-mini so I’ve used gpt-4o.
- Add the jsonl file.
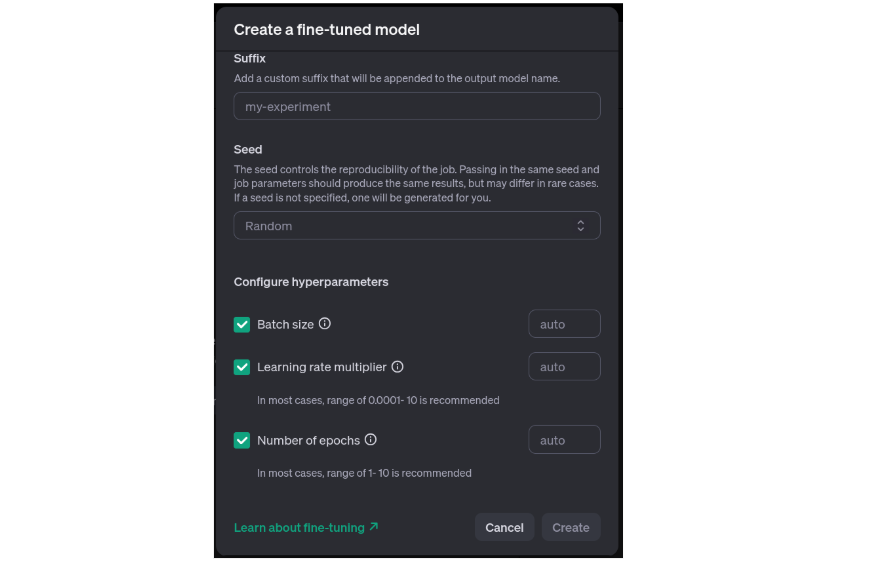
- Add ‘Suffix’ which is related to the fine-tuning job
- Use any quantity as ‘Seed’ for reproducibility.
- Select the hyper-parameters and depart them to make use of the default values. Seek advice from the above-mentioned documentation for pointers on selecting them.
Now, we are able to click on on ‘Create’ to start out the fine-tuning.
As soon as the positive tuning is accomplished, will probably be displayed as follows:
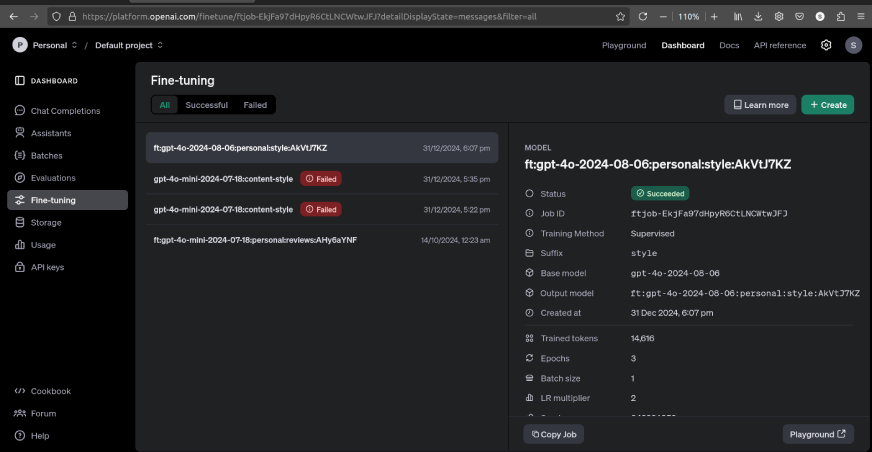
We are able to examine the fine-tuned mannequin to pre-existing mannequin responses within the playground by clicking the button on the right-bottom nook.
Right here’s an instance of responses evaluating each fashions:
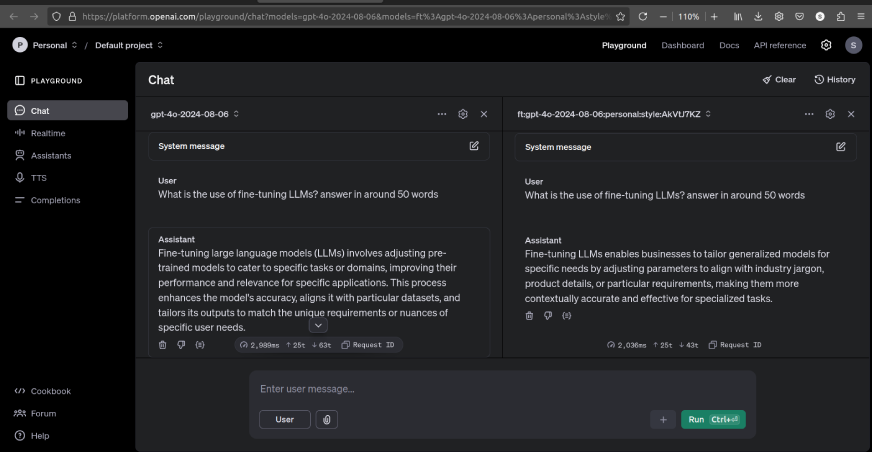
As we are able to see, there may be vital distinction between the responses of each fashions.
If we use extra examples, then the outcomes might enhance.
Now let’s study Google AI Studio.
Google AI Studio
Google AI Studio is a web-based device for constructing purposes utilizing Gemini LLMs. It additionally permits customers to fine-tune LLMs utilizing their very own information. This customization enhances the mannequin’s efficiency for particular duties or industries, making it extra related and efficient. Tremendous-tuning characteristic for Gemini fashions is newly launched and at present out there for Gemini 1.5 Flash solely. The tuning is freed from cost as of January 2025 and the price of inference is similar as pre-existing fashions.
Study Extra: Google’s AI Studio: Your Gateway to Gemini’s Inventive Universe!
Information Add
For Gemini fashions, the info format needs to be as follows:
training_data = [{"text_input": "1", "output": "2"},
{"text_input": "3", "output": "4"},]
Google AI Studio supplies a GUI (Graphical Person Interface) to add the info from a csv file. To do that:
- Open https://aistudio.google.com/prompts/new_data
- Click on on ‘Actions’, then ‘Import examples’.
- Then add the csv file. The display screen will seem like this:
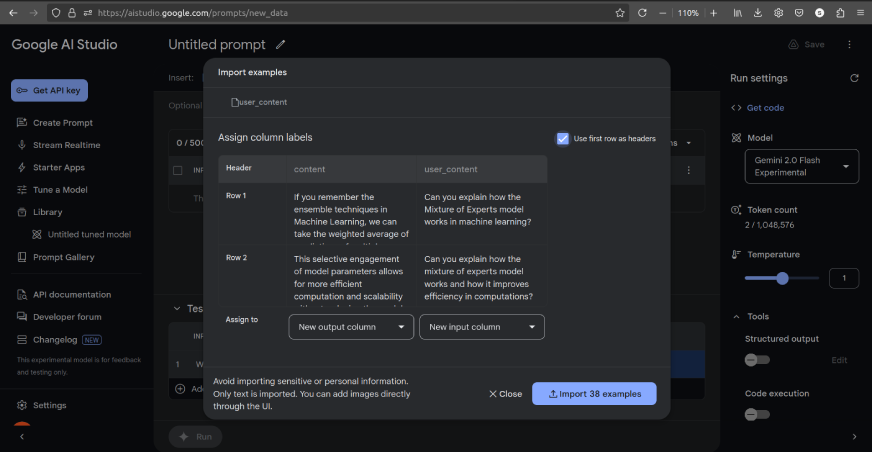
- Assign user_content as enter column and content material as output column.
- Then, import the examples. We are able to delete any pointless columns after which save the info utilizing the ‘Save’ button within the top-right nook.
Tremendous-tuning in AI Studio
To fine-tune a mannequin, go to https://aistudio.google.com/tune.
The display screen will seem like this:
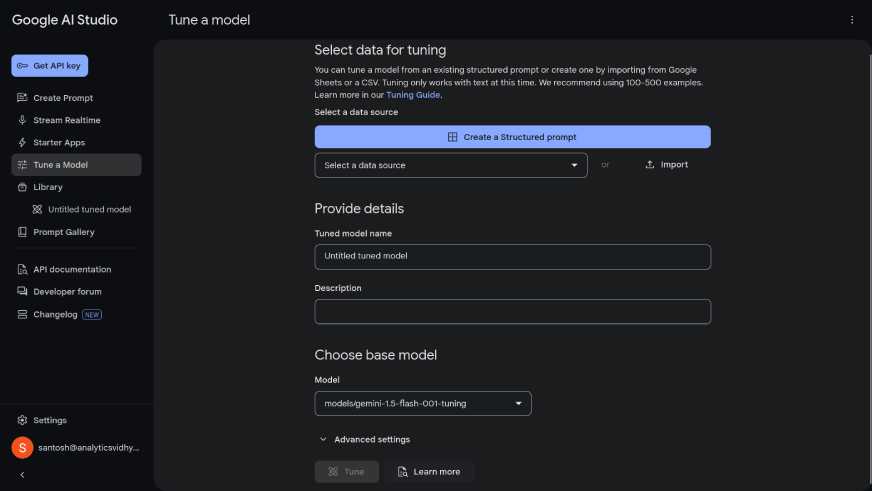
Now, comply with the beneath steps:
- Choose the imported information from the dropdown menu.
- Give the tuned mannequin a reputation.
- To be taught extra about superior settings, seek advice from https://ai.google.dev/gemini-api/docs/model-tuning.
- As soon as executed, click on on ‘Tune’.
You’ll find the tuned fashions within the ‘Library’ as follows:
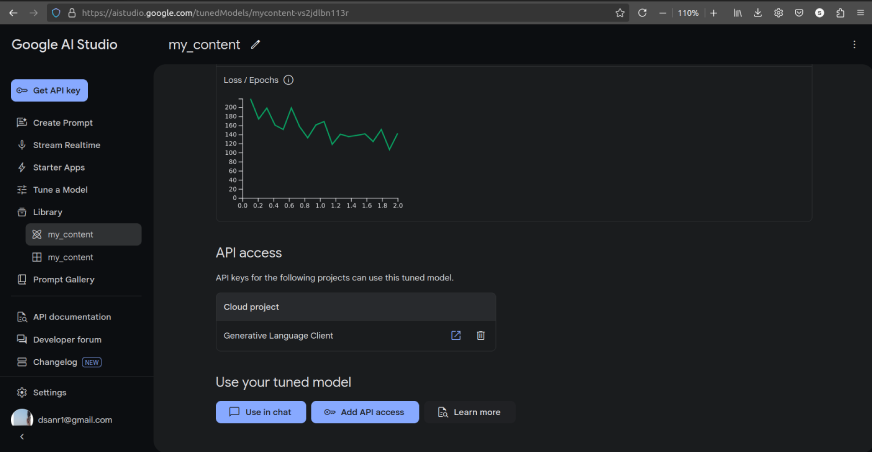
We are able to additionally use the mannequin within the chat as proven within the above picture.
Conclusion
Tremendous-tuning giant language fashions utilizing OpenAI Platform and Google AI Studio permits customers to tailor fashions to particular wants. This may very well be to make the LLM undertake distinctive writing types or enhance its domain-specific efficiency. Each platforms present intuitive workflows for information preparation and coaching, supporting structured codecs to optimize mannequin habits. With accessible instruments and clear documentation, they empower customers to unlock the total potential of LLMs by aligning them intently with desired duties and targets.
Incessantly Requested Questions
A. Tremendous-tuning is the method of coaching a pre-trained language mannequin on customized information to adapt its behaviour to particular duties, types, or domains. It includes offering examples of input-output pairs to information the mannequin’s responses in alignment with person necessities.
A. OpenAI Platform requires information in a structured JSONL format, usually with roles resembling “system,” “person,” and “assistant.” Google AI Studio makes use of a less complicated format with `text_input` and `output` fields, the place the enter and desired output are clearly outlined.
A. Whereas small datasets with 30–50 examples could present some outcomes, bigger datasets with 100–500 examples usually yield higher efficiency by offering the mannequin with numerous and context-rich situations.
A. OpenAI fees for fine-tuning primarily based on token utilization throughout coaching, with increased prices for bigger fashions. Google AI Studio at present presents free fine-tuning for Gemini 1.5 Flash fashions, making it a cheap alternative for experimentation.
A. Tremendous-tuning permits customers to customise a mannequin to align with particular necessities, resembling producing content material in a specific tone or type, enhancing accuracy for domain-specific duties, and enhancing the general person expertise by making the mannequin extra related to the supposed use case.
I’m working as an Affiliate Information Scientist at Analytics Vidhya, a platform devoted to constructing the Information Science ecosystem. My pursuits lie within the fields of Pure Language Processing (NLP), Deep Studying, and AI Brokers.