Introduction
Operate calling in massive language fashions (LLMs) has remodeled how AI brokers work together with exterior methods, APIs, or instruments, enabling structured decision-making primarily based on pure language prompts. By utilizing JSON schema-defined capabilities, these fashions can autonomously choose and execute exterior operations, providing new ranges of automation. This text will display how perform calling might be applied utilizing Mistral 7B, a state-of-the-art mannequin designed for instruction-following duties.
Studying Outcomes
- Perceive the function and varieties of AI brokers in generative AI.
- Learn the way perform calling enhances LLM capabilities utilizing JSON schemas.
- Arrange and cargo Mistral 7B mannequin for textual content era.
- Implement perform calling in LLMs to execute exterior operations.
- Extract perform arguments and generate responses utilizing Mistral 7B.
- Execute real-time capabilities like climate queries with structured output.
- Increase AI agent performance throughout numerous domains utilizing a number of instruments.
This text was printed as part of the Information Science Blogathon.
What are AI Brokers?
Within the scope of Generative AI (GenAI), AI brokers characterize a major evolution in synthetic intelligence capabilities. These brokers use fashions, akin to massive language fashions (LLMs), to create content material, simulate interactions, and carry out complicated duties autonomously. The AI brokers improve their performance and applicability throughout numerous domains, together with buyer assist, schooling, and medical area.
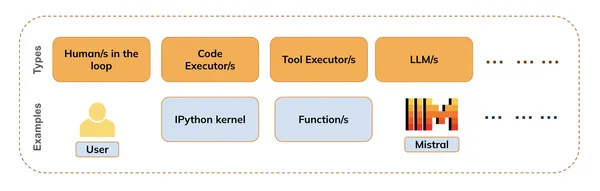
They are often of a number of varieties (as proven within the determine beneath) together with :
- People within the loop (e.g. for offering suggestions)
- Code executors (e.g. IPython kernel)
- Instrument Executors (e.g. Operate or API executions )
- Fashions (LLMs, VLMs, and many others)
Operate Calling is the mix of Code execution, Instrument execution, and Mannequin Inference i.e. whereas the LLMs deal with pure language understanding and era, the Code Executor can execute any code snippets wanted to satisfy person requests.
We will additionally use the People within the loop, to get suggestions in the course of the course of, or when to terminate the method.
What’s Operate Calling in Giant Language Fashions?
Builders outline capabilities utilizing JSON schemas (that are handed to the mannequin), and the mannequin generates the mandatory arguments for these capabilities primarily based on person prompts. For instance: It may well name climate APIs to offer real-time climate updates primarily based on person queries (We’ll see the same instance on this pocket book). With perform calling, LLMs can intelligently choose which capabilities or instruments to make use of in response to a person’s request. This functionality permits brokers to make autonomous choices about how one can finest fulfill a activity, enhancing their effectivity and responsiveness.
This text will display how we used the LLM (right here, Mistral) to generate arguments for the outlined perform, primarily based on the query requested by the person, particularly: The person asks concerning the temperature in Delhi, the mannequin extracts the arguments, which the perform makes use of to get the real-time info (right here, we’ve set to return a default worth for demonstration functions), after which the LLM generates the reply in easy language for the person.
Constructing a Pipeline for Mistral 7B: Mannequin and Textual content Technology
Let’s import the mandatory libraries and import the mannequin and tokenizer from huggingface for inference setup. The Mannequin is accessible right here.
Importing Mandatory Libraries
from transformers import pipeline ## For sequential textual content era
from transformers import AutoModelForCausalLM, AutoTokenizer # For main the mannequin and tokenizer from huggingface repository
import warnings
warnings.filterwarnings("ignore") ## To take away warning messages from outputOffering the huggingface mannequin repository identify for mistral 7B
model_name = "mistralai/Mistral-7B-Instruct-v0.3"Downloading the Mannequin and Tokenizer
- Since this LLM is a gated mannequin, it’ll require you to enroll on huggingface and settle for their phrases and circumstances first. After signing up, you possibly can observe the directions on this web page to generate your person entry token to obtain this mannequin in your machine.
- After producing the token by following the above-mentioned steps, go the huggingface token (in hf_token) for loading the mannequin.
mannequin = AutoModelForCausalLM.from_pretrained(model_name, token = hf_token, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained(model_name, token = hf_token)Implementing Operate Calling with Mistral 7B
Within the quickly evolving world of AI, implementing perform calling with Mistral 7B empowers builders to create refined brokers able to seamlessly interacting with exterior methods and delivering exact, context-aware responses.
Step 1 : Specifying instruments (perform) and question (preliminary immediate)
Right here, we’re defining the instruments (perform/s) whose info the mannequin can have entry to, for producing the perform arguments primarily based on the person question.
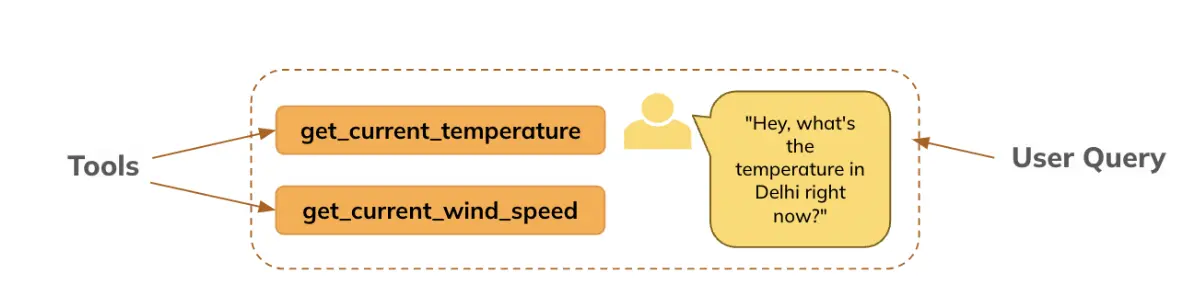
Instrument is outlined beneath:
def get_current_temperature(location: str, unit: str) -> float:
"""
Get the present temperature at a location.
Args:
location: The situation to get the temperature for, within the format "Metropolis, Nation".
unit: The unit to return the temperature in. (decisions: ["celsius", "fahrenheit"])
Returns:
The present temperature on the specified location within the specified items, as a float.
"""
return 30.0 if unit == "celsius" else 86.0 ## We're setting a default output only for demonstration objective. In actual life it could be a working performThe immediate template for Mistral must be within the particular format beneath for Mistral.
Question (the immediate) to be handed to the mannequin
messages = [
{"role": "system", "content": "You are a bot that responds to weather queries. You should reply with the unit used in the queried location."},
{"role": "user", "content": "Hey, what's the temperature in Delhi right now?"}
]Step 2: Mannequin Generates Operate Arguments if Relevant
Total, the person’s question together with the details about the accessible capabilities is handed to the LLM, primarily based on which the LLM extracts the arguments from the person’s question for the perform to be executed.

- Making use of the precise chat template for mistral perform calling
- The mannequin generates the response which comprises which perform and which arguments have to be specified.
- The LLM chooses which perform to execute and extracts the arguments from the pure language offered by the person.
inputs = tokenizer.apply_chat_template(
messages, # Passing the preliminary immediate or dialog context as an inventory of messages.
instruments=[get_current_temperature], # Specifying the instruments (capabilities) accessible to be used in the course of the dialog. These might be APIs or helper capabilities for duties like fetching temperature or wind pace.
add_generation_prompt=True, # Whether or not so as to add a system era immediate to information the mannequin in producing applicable responses primarily based on the instruments or enter.
return_dict=True, # Return the leads to dictionary format, which permits simpler entry to tokenized knowledge, inputs, and different outputs.
return_tensors="pt" # Specifies that the output needs to be returned as PyTorch tensors. That is helpful if you happen to're working with fashions in a PyTorch-based setting.
)
inputs = {ok: v.to(mannequin.system) for ok, v in inputs.objects()} # Strikes all of the enter tensors to the identical system (CPU/GPU) because the mannequin.
outputs = mannequin.generate(**inputs, max_new_tokens=128)
response = tokenizer.decode(outputs[0][len(inputs["input_ids"][0]):], skip_special_tokens=True)# Decodes the mannequin's output tokens again into human-readable textual content.
print(response)Output : [{“name”: “get_current_temperature”, “arguments”: {“location”: “Delhi, India”, “unit”: “celsius”}}]
Step 3:Producing a Distinctive Instrument Name ID (Mistral-Particular)
It’s used to uniquely determine and match instrument calls with their corresponding responses, guaranteeing consistency and error dealing with in complicated interactions with exterior instruments
import json
import random
import string
import reGenerate a random tool_call_id
It’s used to uniquely determine and match instrument calls with their corresponding responses, guaranteeing consistency and error dealing with in complicated interactions with exterior instruments.
tool_call_id = ''.be a part of(random.decisions(string.ascii_letters + string.digits, ok=9))Append the instrument name to the dialog
messages.append({"function": "assistant", "tool_calls": [{"type": "function", "id": tool_call_id, "function": response}]})print(messages)Output :

Step 4: Parsing Response in JSON Format
attempt :
tool_call = json.masses(response)[0]
besides :
# Step 1: Extract the JSON-like half utilizing regex
json_part = re.search(r'[.*]', response, re.DOTALL).group(0)
# Step 2: Convert it to an inventory of dictionaries
tool_call = json.masses(json_part)[0]
tool_callOutput : {‘identify’: ‘get_current_temperature’, ‘arguments’: {‘location’: ‘Delhi, India’, ‘unit’: ‘celsius’}}
[Note] : In some circumstances, the mannequin might produce some texts as nicely alongwith the perform info and arguments. The ‘besides’ block takes care of extracting the precise syntax from the output
Step 5: Executing Capabilities and Acquiring Outcomes
Based mostly on the arguments generated by the mannequin, you go them to the respective perform to execute and acquire the outcomes.
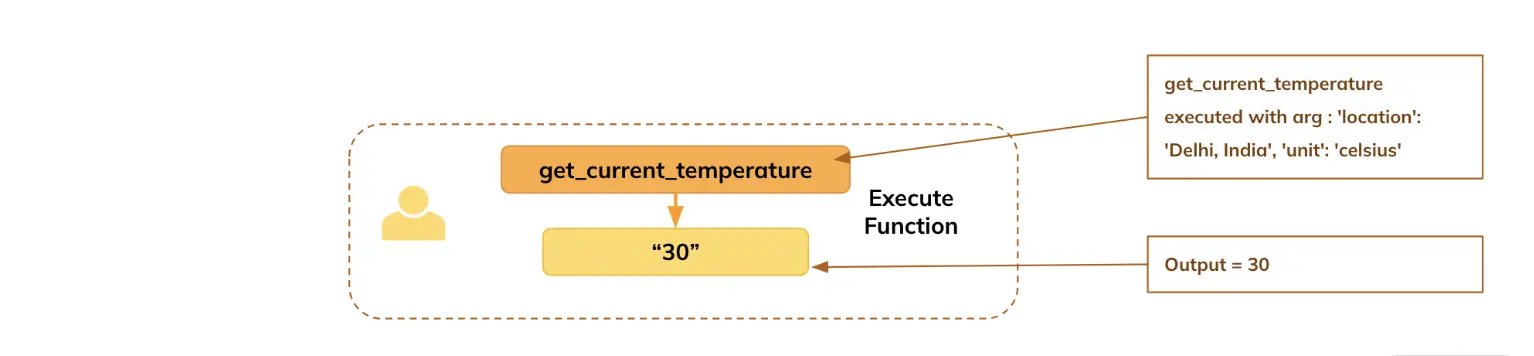
function_name = tool_call["name"] # Extracting the identify of the instrument (perform) from the tool_call dictionary.
arguments = tool_call["arguments"] # Extracting the arguments for the perform from the tool_call dictionary.
temperature = get_current_temperature(**arguments) # Calling the "get_current_temperature" perform with the extracted arguments.
messages.append({"function": "instrument", "tool_call_id": tool_call_id, "identify": "get_current_temperature", "content material": str(temperature)})Step 6: Producing the Ultimate Reply Based mostly on Operate Output
## Now this listing comprises all the knowledge : question and performance particulars, perform execution particulars and the output of the perform
print(messages)Output

Getting ready the immediate for passing complete info to the mannequin
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = {ok: v.to(mannequin.system) for ok, v in inputs.objects()}Mannequin Generates Ultimate Reply
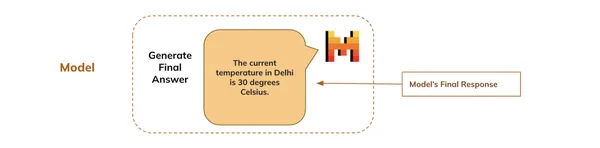
Lastly, the mannequin generates the ultimate response primarily based on the complete dialog that begins with the person’s question and exhibits it to the person.
- inputs : Unpacks the enter dictionary, which comprises tokenized knowledge the mannequin must generate textual content.
- max_new_tokens=128: Limits the generated response to a most of 128 new tokens, stopping the mannequin from producing excessively lengthy responses
outputs = mannequin.generate(**inputs, max_new_tokens=128)
final_response = tokenizer.decode(outputs[0][len(inputs["input_ids"][0]):],skip_special_tokens=True)
## Ultimate response
print(final_response)Output: The present temperature in Delhi is 30 levels Celsius.
Conclusion
We constructed our first agent that may inform us real-time temperature statistics throughout the globe! After all, we used a random temperature as a default worth, however you possibly can join it to climate APIs that fetch real-time knowledge.
Technically talking, primarily based on the pure language question by the person, we have been capable of get the required arguments from the LLM to execute the perform, get the outcomes out, after which generate a pure language response by the LLM.
What if we needed to know the opposite components like wind pace, humidity, and UV index? : We simply have to outline the capabilities for these components and go them within the instruments argument of the chat template. This fashion, we will construct a complete Climate Agent that has entry to real-time climate info.
Key Takeaways
- AI brokers leverage LLMs to carry out duties autonomously throughout various fields.
- Integrating perform calling with LLMs allows structured decision-making and automation.
- Mistral 7B is an efficient mannequin for implementing perform calling in real-world functions.
- Builders can outline capabilities utilizing JSON schemas, permitting LLMs to generate crucial arguments effectively.
- AI brokers can fetch real-time info, akin to climate updates, enhancing person interactions.
- You possibly can simply add new capabilities to broaden the capabilities of AI brokers throughout numerous domains.
Often Requested Questions
A. Operate calling in LLMs permits the mannequin to execute predefined capabilities primarily based on person prompts, enabling structured interactions with exterior methods or APIs.
A. Mistral 7B excels at instruction-following duties and might autonomously generate perform arguments, making it appropriate for functions that require real-time knowledge retrieval.
A. JSON schemas outline the construction of capabilities utilized by LLMs, permitting the fashions to grasp and generate crucial arguments for these capabilities primarily based on person enter.
A. You possibly can design AI brokers to deal with numerous functionalities by defining a number of capabilities and integrating them into the agent’s toolset.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.