PaliGemma 2 is the subsequent evolution in tunable vision-language fashions launched by Google based mostly on the success of PaliGemma, and the brand new capabilities of the Gemma 2 mannequin. Gemma is a household of light-weight, state-of-the-art open fashions constructed from the identical analysis and expertise used to create the Gemini fashions. PaliGemma 2 builds upon the performant Gemma 2 fashions, including the facility of imaginative and prescient and making it simpler than ever to fine-tune and adapt to totally different eventualities.
PaliGemma 2 can see, perceive, and work together with visible and language enter. The Gemma household of fashions is rising bigger and bigger, with an enormous number of fashions to adapt and use. PaliGemma 2 specifically is a robust mannequin with a number of sizes for various use instances. On this article, we’ll discover the potential of PaliGemma 2 by diving deep into its structure, capabilities and limitations, efficiency, and a code information for inferring the mannequin.
Understanding PaliGemma 2
PaliGemma 2 represents a big development in vision-language fashions (VLMs), constructed by combining the highly effective open-source SigLIP imaginative and prescient encoder and the dimensions variations of Gemma 2 language fashions. What makes this mannequin household notably fascinating is its multi-resolution method, providing fashions at three distinct resolutions and three distinct sizes. PaliGemma 2 is educated with 3 resolutions 224px², 448px², and 896px². The Google researchers practice the fashions in a number of levels to equip them with broad data for switch by way of fine-tuning.
The three totally different sizes come from the parameter variation of Gemma 2 language fashions, coming at 3B, 10B, and 28B parameters. This flexibility permits builders and researchers to optimize for his or her particular use instances, balancing between computational necessities and mannequin efficiency. Now, let’s dive deeper into the structure of this mannequin.
Structure
The entire Gemma household of fashions relies on Transformers structure, PaliGemma 2 for instance combines a Imaginative and prescient Transformer encoder and a Transformer decoder. The imaginative and prescient encoder makes use of SigLIP-400m/14, which processes pictures utilizing a patch measurement of 14px². At 224px² decision, this yields 256 picture tokens, at 448px² it produces 1024 tokens, and at 896px² decision, it generates 4096 tokens. These visible tokens then go via a linear projection layer earlier than being mixed with enter textual content tokens. The textual content decoder, initialized from the Gemma 2 fashions (2B, 9B, or 27B), processes this mixed enter to generate textual content outputs autoregressively.
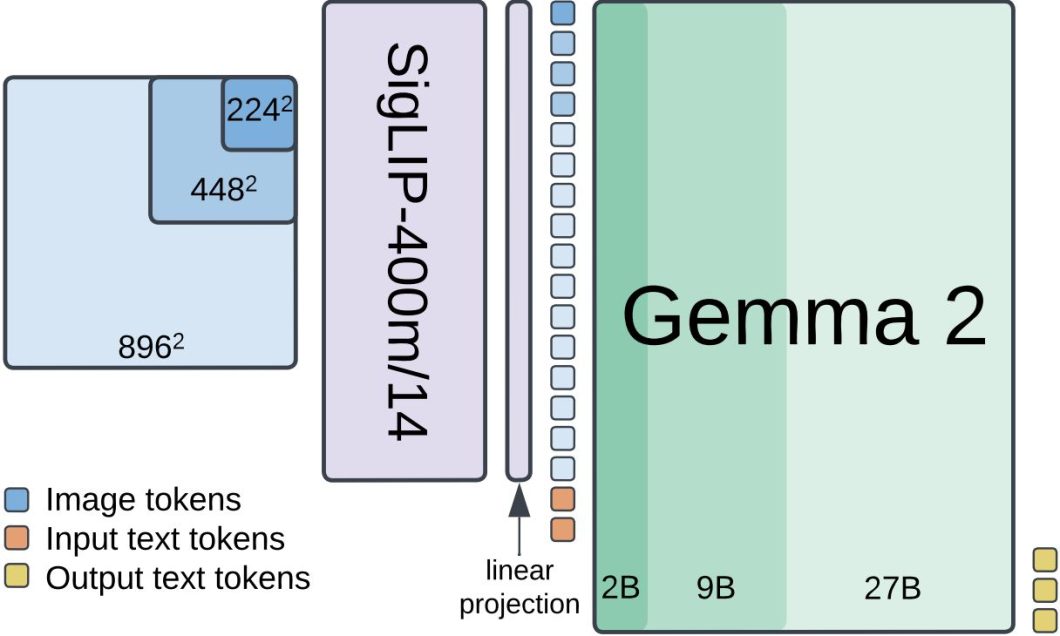
The mannequin undergoes a three-stage coaching course of. Stage 0 corresponds to the unimodal pretraining of particular person elements. In Stage 1, the pre-trained SigLIP and Gemma 2 checkpoints are mixed and collectively educated on a multimodal job combination of 1 billion examples at 224px² decision. Stage 2 continues coaching with 50 million examples at 448px² decision, adopted by 10 million examples at 896px². Lastly, stage 3 fine-tunes the checkpoints from stage 1 or 2 (relying on the decision) to the goal job.
Duties benefiting from larger decision are given extra weight in stage 2. The output sequence size is elevated for duties like OCR for lengthy textual content sequences. The mannequin applies logits soft-capping to consideration and output logits throughout Levels 1 and a pair of, utilizing the Adam optimizer with studying charges adjusted based mostly on mannequin measurement. The coaching knowledge combination consists of various duties: captioning, grounded captioning, OCR, machine-generated visible query answering, object detection, and occasion segmentation.
Capabilities and Limitations
PaliGemma 2 as a vision-language mannequin (VLM) has each visible and textual processing capabilities. The mannequin excels in duties requiring detailed visible evaluation, from fundamental picture captioning to advanced visible query answering, and even segmentation and OCR. It demonstrates state-of-the-art efficiency in specialised domains like molecular construction recognition, optical music rating recognition, and long-form picture captioning. A key power of PaliGemma 2 is its scalability and adaptability.
The totally different mannequin sizes and resolutions enable for optimization and switch studying based mostly on particular wants. For instance, the 896px² decision considerably improves efficiency on duties requiring positive element recognition, equivalent to textual content detection and doc evaluation. Equally, bigger mannequin sizes (10B, 28B) present notable enhancements in duties requiring superior language understanding and world data.
Nevertheless, PaliGemma 2 does face sure limitations. The mannequin’s efficiency exhibits various levels of enchancment with elevated measurement. Whereas scaling from 3B to 10B parameters sometimes yields substantial positive aspects, the bounce to 28B usually ends in extra modest enhancements. Moreover, larger resolutions and bigger mannequin sizes include important computational prices. The coaching price per instance will increase considerably with decision. Listed here are a number of different issues to think about about PaliGemma 2 limitations.
- PaliGemma 2 was designed at first to function a common pre-trained mannequin for fine-tuning specialised duties. Therefore, its “out of the field” or “zero-shot” efficiency may lag behind fashions designed particularly for general-purpose use.
- PaliGemma 2 isn’t a multi-turn chatbot. It’s designed for a single spherical of picture and textual content enter.
- Pure language is inherently advanced. VLMs usually may battle to know delicate nuances, sarcasm, or figurative language.
PaliGemma 2 Efficiency and Benchmarks
The PaliGemma 2 efficiency is spectacular in comparison with a lot bigger VLMs. The Google researchers upgraded PaliGemma to PaliGemma 2 by changing its language mannequin part with the more moderen and extra succesful language fashions from the Gemma 2 household. PaliGemma 2 showcased important enhancements upon its predecessor in response to benchmark evaluations throughout varied duties and domains. When evaluating fashions of the identical measurement (3B parameters) PaliGemma 2 constantly outperforms the unique PaliGemma by a median of 0.65 at 224px² and 0.85 factors at 448px².
PaliGemma 2 actual power lies in its bigger variants. By leveraging the extra succesful Gemma 2 language fashions (10B and 28B parameters), PaliGemma 2 achieves substantial enhancements over each its predecessor and different state-of-the-art fashions. These enhancements are notably noticeable in duties requiring superior language understanding or fine-grained visible evaluation. Let’s dive deeper into the efficiency throughout totally different domains and look at how mannequin measurement and determination have an effect on varied duties.
Normal Imaginative and prescient-Language Duties
The researchers evaluated PaliGemma 2 on over 30 tutorial benchmarks protecting a broad vary of vision-language duties. These benchmarks embody visible query answering (VQA), picture captioning, referring expression duties, and extra. efficiency patterns, duties usually fall into three classes based mostly on how they profit from mannequin enhancements.
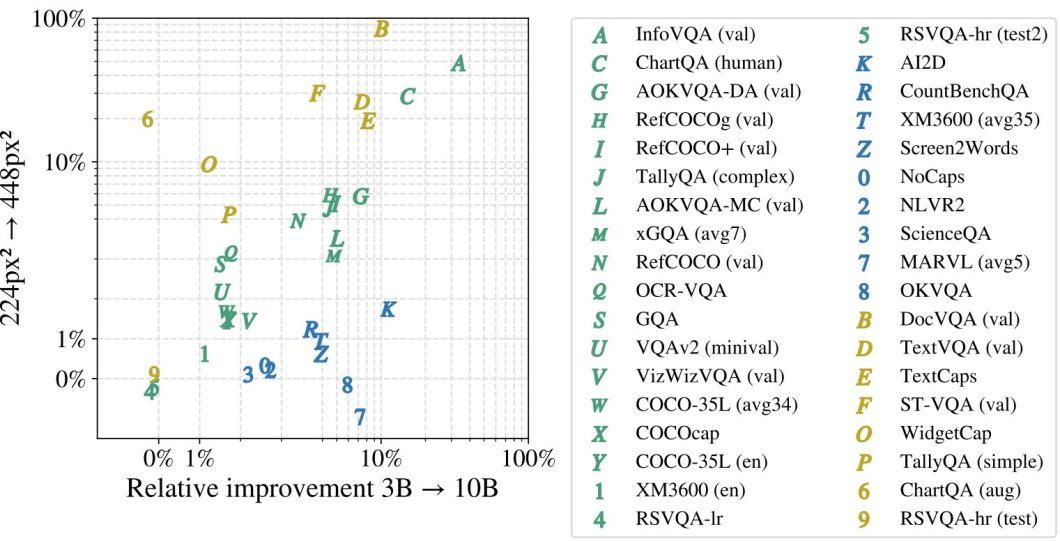
The duties within the above graph are grouped into duties delicate to each mannequin measurement and determination (Inexperienced), delicate to mannequin measurement (Blue), and delicate to decision (Yellow). Duties that profit equally from elevated decision and bigger mannequin sizes embody InfoVQA, ChartQA, and AOKVQA. These duties sometimes require each fine-grained visible understanding and powerful language capabilities. For instance, AOKVQA-DA improved by 10.2% when transferring from the 3B to 10B mannequin, and confirmed comparable positive aspects with elevated decision. Some duties are extra delicate to decision will increase.
Doc and text-focused duties like DocVQA and TextVQA confirmed dramatic enhancements with larger resolutions – DocVQA’s efficiency jumped by 33.7 factors when transferring from 224px² to 448px². This makes intuitive sense as these duties require studying positive textual content particulars. Different duties profit primarily from bigger language fashions. Duties involving multilingual processing (like XM3600) or superior reasoning (like AI2D and NLVR2) confirmed larger enhancements from mannequin measurement will increase than decision will increase. An fascinating discovering is that whereas scaling from 3B to 10B parameters sometimes yields substantial positive aspects, the bounce to 28B usually ends in extra modest enhancements. This implies a possible “candy spot” within the mannequin measurement/efficiency trade-off for a lot of functions.
Specialised Area Efficiency
PaliGemma 2 showcased nice versatility in specialised domains, usually matching or exceeding the efficiency of purpose-built fashions. For instance, PaliGemma 2 3B at 896px² decision outperforms the state-of-the-art HTS mannequin on the ICDAR’15 and Whole-Textual content benchmarks in textual content detection and recognition. The mannequin achieves this efficiency with out implementing task-specific structure elements frequent in OCR analysis.
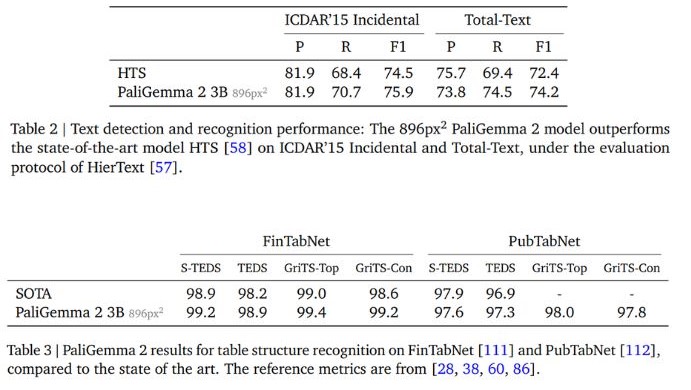
PaliGemma 2 additionally units a brand new state-of-the-art benchmark for desk construction recognition. When examined on the FinTabNet and PubTabNet datasets, the mannequin achieves nice accuracy in cell textual content content material and structural evaluation. Past doc processing, PaliGemma 2 exhibits robust efficiency in scientific domains. In molecular construction recognition, the 10B parameter mannequin at 448px² decision achieves a 94.8% actual match price on ChemDraw knowledge, exceeding the specialised MolScribe system. Moreover, in optical music rating recognition, PaliGemma 2 reduces error charges throughout a number of metrics in comparison with earlier strategies.
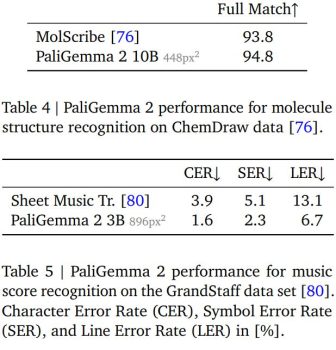
These outcomes are spectacular as they display PaliGemma 2’s potential to deal with extremely specialised duties with out requiring domain-specific architectural modifications. Lastly, the mannequin presents state-of-the-art efficiency for lengthy captioning after fine-tuning it on the DOCCI (Descriptions of Related and Contrasting Photographs). Outperforming fashions like LLaVA-1.5 and MiniGPT-4 in factual inaccuracies, that are measured utilizing Non-Entailment Sentences (NES).
Actual-World Functions
PaliGemma 2 is a flexible mannequin with spectacular performances on over 30 benchmarks, nonetheless, its true worth lies in sensible functions. PaliGemma 2 is made to be tunable, this ease of fine-tuning the mannequin makes it appropriate for a lot of real-world functions throughout totally different industries. Following are some key functions the place PaliGemma 2 exhibits important potential.
- Medical Imaging Evaluation
- Doc Processing and OCR
- Scientific Analysis Instruments
- Music Rating Digitization
- Visible High quality Management
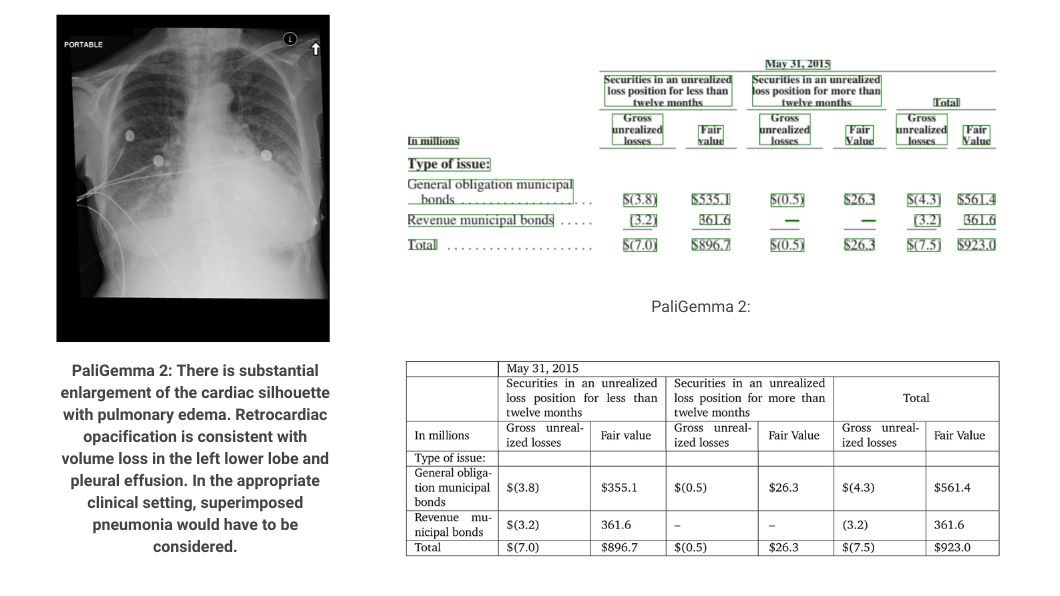
A major instance is in medical imaging, the place the mannequin has been examined on the MIMIC-CXR dataset for automated chest X-ray report technology. The mannequin achieves a RadGraph F1-score of 29.5% (10B mannequin at 896px²), surpassing earlier state-of-the-art methods like Med-Gemini-2D.
Moreover, for sensible deployment, PaliGemma 2 provides versatile choices for CPU inference. The researchers examined CPU-only inference utilizing totally different architectures and located viable efficiency even with out accelerators. The mannequin’s potential to run effectively on totally different {hardware} configurations, and its robust efficiency throughout various duties, make it appropriate for real-world implementations.
Getting Began with PaliGemma 2: Fingers-On Information
PaliGemma and PaliGemma 2 have been extensively accessible and simple to make use of and fine-tune since their introduction. The Implementation of PaliGemma 2 is obtainable via the Hugging Face Transformers library, with just some strains of Python code. On this part, we’ll discover find out how to correctly immediate and infer PaliGemma 2 utilizing a Kaggle pocket book atmosphere. We will probably be utilizing the Transformers inference implementation as a result of it permits for an easier code. The Kaggle pocket book will present us with the wanted computational assets and Python libraries to run the mannequin.
Correct prompting is essential for getting the most effective outcomes from PaliGemma 2. The mannequin was educated with particular immediate codecs for various duties, and following these codecs will assist in getting the optimum efficiency. Not like chat-based fashions, PaliGemma 2 is designed for single-turn interactions the place the enter format considerably impacts the standard of outputs. Earlier than diving into the inference implementation, let’s first discover these prompting finest practices that will help you get probably the most out of the mannequin.
Prompting Information
PaliGemma 2 has particular immediate key phrases to make use of when attempting to carry out particular duties. So, to totally make the most of PaliGemma 2’s capabilities, it’s important to know the totally different mannequin sorts and their corresponding prompting methods. PaliGemma 2 is available in three classes.
- Base Fashions: Pre-trained fashions that take empty prompts and are advisable for fine-tuning particular duties.
- Nice-tuned (FT) Fashions: Specialised fashions educated for particular duties that solely assist syntax for his or her goal job.
- Combine Fashions: Versatile fashions that assist all job key phrases and prompting methods.
For our implementation, we’ll make the most of the bottom mannequin kind for ease of implementation and uncooked efficiency. Nevertheless, listed below are the important thing prompting codecs supported by Combine fashions.
- Picture Captioning:
cap {lang}nGenerates transient, uncooked captionscaption {lang}nProduces COCO-style concise captionsdescribe ennCreates detailed, descriptive captions
- Evaluation Duties:
- “ocr”: Performs textual content recognition’
reply en the place is the cow standing?nSolutions questions on picture contentsreply {lang} {query}nQuery answering concerning the picture contentsquery {lang} {reply}nQuery technology for a given reply
- Object Detection:
detect {object} ; {object}nReturns bounding bins for a listing of specified objectsphase {object}nCreates segmentation masks for specified objects
Essential: When working with PaliGemma 2, the picture knowledge should at all times be supplied earlier than the textual content immediate. This order is essential for producing usable responses.
Setup PaliGemma 2 with Transformers
To get began on inferring PaliGemma 2, open up a Kaggle pocket book and use an accelerator. Subsequent, be sure to go to the PaliGemma 2 mannequin card right here, and settle for the settlement to make use of the mannequin.
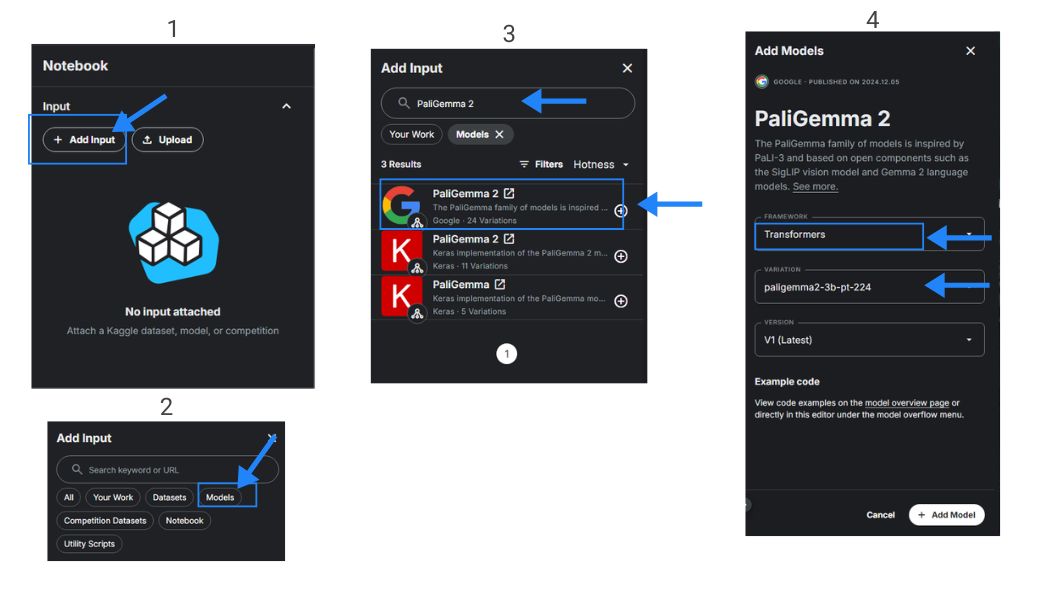
To make use of the mannequin inside the pocket book, on the best panel select so as to add enter, then select fashions, and seek for PaliGemma 2. On this information, we will probably be utilizing the Transformers framework and the 3B parameter variant. Be sure to have accepted the phrases and restart the pocket book. Now, let’s import and set up the wanted libraries.
pip set up --upgrade transformers
It will set up the transformers library with the newest model which is required for this implementation.
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration from PIL import Picture from transformers import BitsAndBytesConfig import torch
These strains of code merely import the wanted libraries from transformers the Pillow library for picture processing in addition to Pytorch.
Inference PaliGemma 2 Base Mannequin
Now, we’re able to load the mannequin into the code with a number of easy strains.
model_id = "/kaggle/enter/paligemma-2/transformers/paligemma2-3b-pt-224/1"
mannequin = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
mannequin = mannequin.to("cuda")
processor = AutoProcessor.from_pretrained(model_id)
This code masses the PaliGemma 2 3B parameter mannequin and 224×224 picture measurement. The code first defines the mannequin path (copy from the best panel), initializes the mode, strikes it to the GPU(cuda), and defines the processor. Lastly, we might want to outline the immediate and cargo our picture.
immediate = "<picture>ocrn" image_file = "/kaggle/enter/paligemma2-examples/Seize.JPG" raw_image = Picture.open(image_file)
The code above defines the immediate with the correct formatting for the pre-trained base mannequin, we outline the picture path and cargo it utilizing the Pillow library. Now, let’s course of the picture and provides it to the mannequin.
inputs = processor(immediate, raw_image, return_tensors="pt").to("cuda")
output = mannequin.generate(**inputs, max_new_tokens=200)
What this does is it makes use of the pre-defined processor from Transformers to course of the immediate and picture and strikes them into the GPU with the mannequin. Then the output is generated merely utilizing mannequin.generate() the generate methodology takes within the enter as a parameter and the utmost output tokens. Now, let’s show the output.
input_len = inputs["input_ids"].form[-1] print(processor.decode(output[0][input_len:], skip_special_tokens=True))
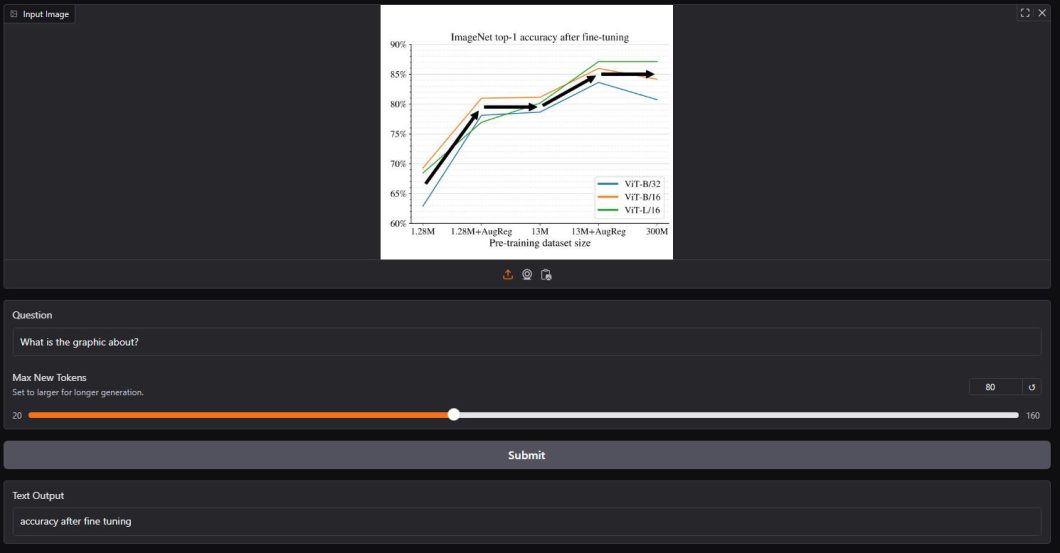
This code processes the output to show usually. Here’s a take a look at the few outcomes I attempted from accessible datasets.
The Way forward for Imaginative and prescient-Language Fashions: PaliGemma 2 and Past
PaliGemma 2 represents a big step ahead in making vision-language fashions extra accessible and versatile for real-world functions. Via its varied mannequin sizes and resolutions, it provides builders and researchers the flexibleness to stability efficiency with computational necessities. The mannequin’s potential to deal with duties starting from easy picture captioning to advanced molecular construction recognition demonstrates its potential as a foundational mannequin for varied industries.
What makes PaliGemma 2 notably noteworthy is its design philosophy specializing in ease of use and adaptableness. This accessibility, paired with its robust efficiency throughout various duties, positions it as a invaluable software for each analysis and sensible functions.
Wanting forward, PaliGemma 2’s structure and coaching method might affect the event of future vision-language fashions. Its success in combining a robust imaginative and prescient encoder with various sizes of language fashions suggests a promising course for scaling and optimizing multimodal AI methods. As the sphere continues to evolve, PaliGemma 2’s emphasis on switch studying and fine-tuning capabilities will doubtless stay essential for advancing the sensible functions of vision-language fashions throughout industries.
FAQs
Q1: What assets do I have to run PaliGemma 2?
To run PaliGemma 2, you want a GPU with ample VRAM (the quantity depends upon the mannequin measurement). For the 3B parameter mannequin, an ordinary GPU with 8GB VRAM is ample.
Q2: How do I select between totally different PaliGemma 2 mannequin sizes?
The selection depends upon your particular wants. Fewer parameters imply sooner however much less high quality efficiency. Extra parameters imply slower extra useful resource intensive, however larger high quality outcomes.
Q3: Can I fine-tune PaliGemma 2 for my particular use case?
Sure, PaliGemma 2 is designed to be fine-tuned. The method requires a dataset related to the use case. Google gives complete documentation for fine-tuning with Keras.