On this tutorial, you’ll learn to assemble iterate replace and practice a CNN mannequin utilizing JAX, Flax, and Optax on the MNIST dataset. This tutorial begins from methods to arrange the atmosphere and preprocess the information to methods to outline the CNN construction and the ultimate step is to check the mannequin. It would additionally point out how the core parts of JAX’s sturdy numerical efficiency, Flax’s versatile neural community, and Optax’s refined optimization instruments practice and consider a state-of-the-art deep studying mannequin effectively. The aim of this information is to elucidate how all these instruments might be helpful in direction of optimizing deep studying procedures and making fashions higher.
Studying Aims
- Discover ways to combine JAX, Flax, and Optax for environment friendly neural community building.
- Perceive the method of preprocessing and loading datasets utilizing TensorFlow Datasets (TFDS).
- Implement a Convolutional Neural Community (CNN) for efficient picture classification.
- Visualize coaching progress with metrics like loss and accuracy.
- Consider and take a look at the mannequin on customized pictures for real-world functions.
This text was printed as part of the Information Science Blogathon.
JAX, Flax, and Optax: A Highly effective Trio
For deep studying fashions to be extremely environment friendly and simply scalable, builders search for some helpful instruments which assist in computation, mannequin designing and optimization. Guess what? Even with that assumption, there’s nonetheless the query of how the three; JAX, Flax and Optax collectively tackle the challenges inherent within the improvement of advanced ML fashions; nicely, let’s discover out.
JAX: The Spine of Numerical Computing
JAX is a high-performance numerical computing library with a well-recognized NumPy-like syntax. It excels in situations requiring {hardware} acceleration or computerized differentiation. Key options embrace:
- Autograd: Automated differentiation for advanced features.
- JIT Compilation: Accelerates execution on CPUs, GPUs, or TPUs.
- Vectorization: Simplifies batch operations with instruments like vmap.
- {Hardware} Integration: Optimized for GPUs and TPUs out of the field.
Flax: A Versatile Neural Community Library
Flax is a JAX-based library for constructing neural networks. It’s designed to be each user-friendly and customizable:
- Stateful Modules: Simplifies managing parameters and state.
- Compact API: Intuitive mannequin definitions with the @nn.compact decorator.
- Customizability: Appropriate for something from easy to advanced architectures.
- Seamless JAX Integration: Leverages JAX’s highly effective options effortlessly.
Optax: A Complete Optimization Library
Optax simplifies gradient processing and optimization, providing:
- Optimizers: A variety, together with SGD, Adam, and RMSProp.
- Gradient Processing: Instruments for clipping, scaling, and normalization.
- Modularity: Simple composition of gradient transformations and optimizers.
Collectively, these libraries supply a strong, modular ecosystem for constructing and coaching deep studying fashions effectively.

Getting Began with JAX: Set up and Setup
Nonetheless, to study extra about JAX and all of its capabilities, one should first begin by implementing the construction on the system. Right here, you’re going to get a quick overview of how one can simply set up JAX and get on with utilizing these superior options of JAX.
!pip set up --upgrade -q pip jax jaxlib flax optax tensorflow-datasetsInstalls the required libraries:
- jax and jaxlib: Numerical computations on GPUs/TPUs.
- flax: Neural community library.
- optax: For optimization features.
- tensorflow-datasets: Simplifies dataset loading.
Importing Important Libraries for JAX, Flax, and Optax
To harness the facility of JAX, Flax, and Optax, step one is to import the mandatory libraries into your improvement atmosphere. This part will information you thru the method of importing these key libraries, making certain that you’ve every thing arrange for the environment friendly execution of machine studying duties. By accurately importing JAX, Flax, and Optax, you’re laying the inspiration for creating high-performance fashions that may leverage superior options like GPU/TPU acceleration and computerized differentiation. Let’s get began with the important imports!
import jax
import jax.numpy as jnp # JAX NumPy
from flax import linen as nn # The Linen API
from flax.coaching import train_state
import optax # The Optax gradient processing and optimization library
import numpy as np # Atypical NumPy
import tensorflow_datasets as tfds # TFDS for MNIST- JAX: For GPU-accelerated computations.
- Flax: To outline and practice the CNN.
- Optax: Supplies optimizers like SGD.
- TFDS: Masses datasets like MNIST.
- Matplotlib: For visualizing coaching/testing metrics.
Information Preparation: Loading and Preprocessing MNIST
On this part, we are going to carry out loading and preprocessing of the MNIST dataset which is being a normal dataset utilized in machine studying. MNIST dataset includes of handwritten digits, by making ready this accurately, we be certain that the mannequin is able to study from the information. We can even describe methods to import the dataset, resize the photographs and correctly construction the information for coaching and evaluation.
def get_datasets():
ds_builder = tfds.builder('mnist')
ds_builder.download_and_prepare()
# Break up into coaching/take a look at units
train_ds = tfds.as_numpy(ds_builder.as_dataset(cut up="practice", batch_size=-1))
test_ds = tfds.as_numpy(ds_builder.as_dataset(cut up="take a look at", batch_size=-1))
# Convert to floating-points
train_ds['image'] = jnp.float32(train_ds['image']) / 255.0
test_ds['image'] = jnp.float32(test_ds['image']) / 255.0
return train_ds, test_dstrain_ds, test_ds = get_datasets()We use TFDS to load and preprocess the MNIST dataset:
- The dataset consists of 28×28 grayscale pictures of digits 0–9.
- Photographs are normalized by dividing pixel values by 255 to scale them between 0 and 1. This improves convergence throughout coaching.
The perform returns train_ds and test_ds dictionaries with keys ‘picture’ and ‘label’.

Constructing the Convolutional Neural Community (CNN)
CNNs is the structure of selection for picture classification issues, and on this part we are going to create a CNN within the jax + flax + optax stack. CNNs are anticipated to study spatial hierarchies of picture information by themselves as a result of layers of convolutions. This manner, we are going to clarify methods to outline layers, activation perform’s layers, and the final layer which is the output layer for recognizing the digits within the MNIST information set.
class CNN(nn.Module):
@nn.compact
# Present a constructor to register a brand new parameter
# and return its preliminary worth
def __call__(self, x):
x = nn.Conv(options=32, kernel_size=(3, 3))(x)
x = nn.relu(x)
x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2))
x = nn.Conv(options=64, kernel_size=(3, 3))(x)
x = nn.relu(x)
x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2))
x = x.reshape((x.form[0], -1)) # Flatten
x = nn.Dense(options=256)(x)
x = nn.relu(x)
x = nn.Dense(options=10)(x) # There are 10 courses in MNIST
return x- Convolution Layers: Extract options utilizing nn.Conv. And add non-linearity utilizing nn.relu.
- Pooling Layers: Carry out dimensionality discount utilizing nn.avg_pool.
- Flatten Layer: Convert characteristic maps right into a 1D vector.
- Dense Layers: A completely linked layer with 256 neurons for characteristic studying. An output layer with 10 neurons for MNIST classification.
Mannequin Analysis: Metrics and Efficiency Monitoring
After our Convolutional Neural Community (CNN) has been skilled correctly, we have to consider its efficiency and achieve this utilizing the proper measures. Now we are going to focus on concerning the main observations concerning the mannequin accuracy, loss, and so forth., particularly on the coaching and validation set.
def compute_metrics(logits, labels):
loss = jnp.imply(optax.softmax_cross_entropy(logits, jax.nn.one_hot(labels, num_classes=10)))
accuracy = jnp.imply(jnp.argmax(logits, -1) == labels)
metrics = {
'loss': loss,
'accuracy': accuracy
}
return metricsWe outline metrics to guage mannequin efficiency:
- Loss: Calculated utilizing optax.softmax_cross_entropy. It measures the distinction between predicted and precise labels.
- Accuracy: Measures the fraction of accurately predicted labels utilizing jnp.argmax.
The perform returns train_ds and test_ds dictionaries with keys ‘picture’ and ‘label’.
Coaching and Analysis Capabilities
We outline the features accountable for coaching the mannequin on the dataset and evaluating its efficiency. These features deal with the ahead cross, loss calculation, backpropagation, and monitoring the mannequin’s accuracy throughout each coaching and validation phases.
@jax.jit
def train_step(state, batch):
def loss_fn(params):
logits = CNN().apply({'params': params}, batch['image'])
loss = jnp.imply(optax.softmax_cross_entropy(
logits=logits,
labels=jax.nn.one_hot(batch['label'], num_classes=10)))
return loss, logits
grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
(_, logits), grads = grad_fn(state.params)
state = state.apply_gradients(grads=grads)
metrics = compute_metrics(logits, batch['label'])
return state, metrics
@jax.jit
def eval_step(params, batch):
logits = CNN().apply({'params': params}, batch['image'])
return compute_metrics(logits, batch['label'])Coaching Step:
- Computes the loss and gradients with respect to mannequin parameters utilizing jax.value_and_grad().
- Updates the mannequin parameters utilizing the optimizer.
- Returns the up to date state and metrics for monitoring efficiency.
Analysis Step:
- Evaluates the mannequin utilizing the given batch.
- Computes the metrics (loss and accuracy) utilizing the skilled parameters.
Each features are JIT-compiled for sooner efficiency execution.
Implementing the Coaching Loop
We combine the coaching course of right into a loop that iteratively trains the mannequin over a number of epochs. Throughout every iteration, the mannequin is up to date based mostly on the computed gradients, and efficiency metrics are tracked to make sure regular progress in direction of optimization.
def train_epoch(state, train_ds, batch_size, epoch, rng):
train_ds_size = len(train_ds['image'])
steps_per_epoch = train_ds_size // batch_size
perms = jax.random.permutation(rng, len(train_ds['image']))
perms = perms[:steps_per_epoch * batch_size] # Skip an incomplete batch
perms = perms.reshape((steps_per_epoch, batch_size))
batch_metrics = []
for perm in perms:
batch = {ok: v[perm, ...] for ok, v in train_ds.objects()}
state, metrics = train_step(state, batch)
batch_metrics.append(metrics)
training_batch_metrics = jax.device_get(batch_metrics)
training_epoch_metrics = {
ok: np.imply([metrics[k] for metrics in training_batch_metrics])
for ok in training_batch_metrics[0]}
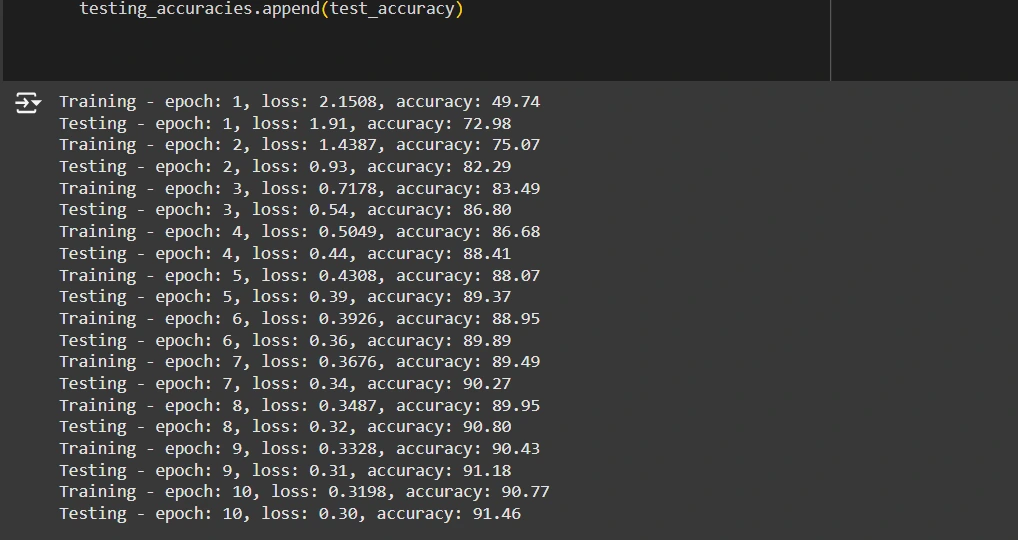
print('Coaching - epoch: %d, loss: %.4f, accuracy: %.2f' % (epoch, training_epoch_metrics['loss'], training_epoch_metrics['accuracy'] * 100))
return state, training_epoch_metrics- Computes the variety of coaching steps based mostly on the batch dimension.
- Shuffles the dataset and prepares batches utilizing jax.random.permutation.
- For every batch, train_step known as to replace the mannequin.
- On the finish of every epoch, it calculates and logs the typical coaching loss and accuracy.
Consider the Mannequin
def eval_model(mannequin, test_ds):
metrics = eval_step(mannequin, test_ds)
metrics = jax.device_get(metrics)
eval_summary = jax.tree.map(lambda x: x.merchandise(), metrics)
return eval_summary['loss'], eval_summary['accuracy']- Computes the loss and accuracy on the take a look at information utilizing eval_step.
- Returns the analysis end result(loss and accuracy).
Executing the Coaching and Analysis Course of
This step entails working the coaching loop and through every epoch the mannequin efficiency must be examined. By checking the coaching and validation metrics, we guarantee that the mannequin studying course of is happening and, furthermore, the mannequin’s capability to generalize information that it has by no means encountered earlier than.
rng = jax.random.PRNGKey(0)
rng, init_rng = jax.random.cut up(rng)
cnn = CNN()
params = cnn.init(init_rng, jnp.ones([1, 28, 28, 1]))['params']
nesterov_momentum = 0.9
learning_rate = 0.001
tx = optax.sgd(learning_rate=learning_rate, nesterov=nesterov_momentum)
state = train_state.TrainState.create(apply_fn=cnn.apply, params=params, tx=tx)
# Initialize lists to retailer metrics for graph visualization
training_losses = []
training_accuracies = []
testing_losses = []
testing_accuracies = []
num_epochs = 10
batch_size = 64
for epoch in vary(1, num_epochs + 1):
# Use a separate PRNG key to permute picture information throughout shuffling
rng, input_rng = jax.random.cut up(rng)
# Run an optimization step over a coaching batch
state, train_metrics = train_epoch(state, train_ds, batch_size, epoch, input_rng)
# Consider on the take a look at set after every coaching epoch
test_loss, test_accuracy = eval_model(state.params, test_ds)
print('Testing - epoch: %d, loss: %.2f, accuracy: %.2f' % (epoch, test_loss, test_accuracy * 100))
# Retailer metrics for graph visualization
training_losses.append(train_metrics['loss'])
training_accuracies.append(train_metrics['accuracy'])
testing_losses.append(test_loss)
testing_accuracies.append(test_accuracy)
- RNG Initialization: Arrange a random quantity generator (rng) for reproducibility and randomness in information shuffling and parameter initialization.
- Mannequin Initialization: Create the CNN mannequin and initialize its parameters utilizing a dummy enter.
- Optimizer and Coaching State:
- Use optax.sgd because the optimizer with a studying fee of 0.001 and Nesterov momentum of 0.9.
- Retailer the mannequin parameters and optimizer within the TrainState.
- Coaching Loop:
- Shuffle the coaching information utilizing a brand new random key (input_rng).
- Practice the mannequin utilizing train_epoch for one full cross by means of the dataset.
- Consider the mannequin on the take a look at dataset utilizing eval_step.
- Print Metrics: Log the take a look at loss and accuracy after every epoch.
Visualizing Coaching and Testing Metrics
On this step, we visualize the coaching and testing metrics comparable to accuracy and loss over time. This helps to establish traits, diagnose potential points like overfitting or underfitting, and assess the general efficiency of the mannequin throughout coaching.
import matplotlib.pyplot as plt
# Graph visualization for coaching/testing loss and accuracy
epochs = vary(1, num_epochs + 1)
plt.determine(figsize=(14, 5))
# Plot for Loss
plt.subplot(1, 2, 1)
plt.plot(epochs, training_losses, label="Coaching Loss", marker="o")
plt.plot(epochs, testing_losses, label="Testing Loss", marker="o")
plt.title('Loss Over Epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)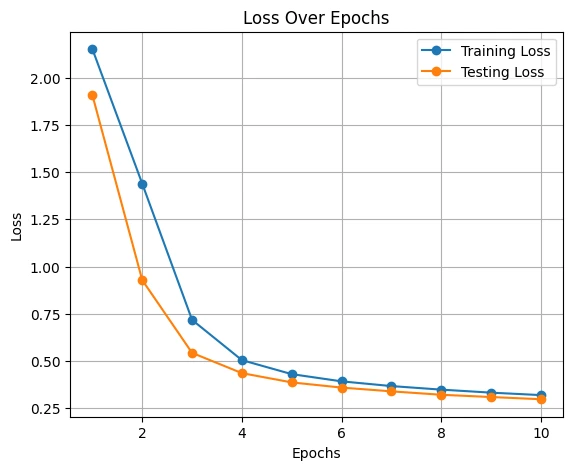
Predicting Customized Photographs
We are going to now display methods to use the skilled mannequin to make predictions on customized pictures. This lets you consider the mannequin’s efficiency on unseen information and take a look at its capability to generalize to new, real-world examples.
from google.colab import information
from PIL import Picture
import numpy as np
# Step 1: Add the picture file
uploaded = information.add()
# Step 2: Course of the uploaded picture
def load_and_preprocess_image(file_path):
img = Picture.open(file_path).convert('L') # Convert to grayscale
img = img.resize((28, 28)) # Resize to 28x28
img = np.array(img) / 255.0 # Normalize pixel values to [0, 1]
img = img.reshape(1, 28, 28, 1) # Add batch and channel dimensions
return img
# Step 3: Load and preprocess every uploaded picture
for file_name in uploaded.keys():
test_image = load_and_preprocess_image(file_name)
print(f"Processed picture from {file_name}.")
import jax.numpy as jnp
# Convert to JAX array
test_image_jax = jnp.array(test_image, dtype=jnp.float32)
# Step 4: Use your skilled mannequin for predictions
logits = state.apply_fn({'params': state.params}, test_image_jax)
prediction = jnp.argmax(logits, axis=-1)
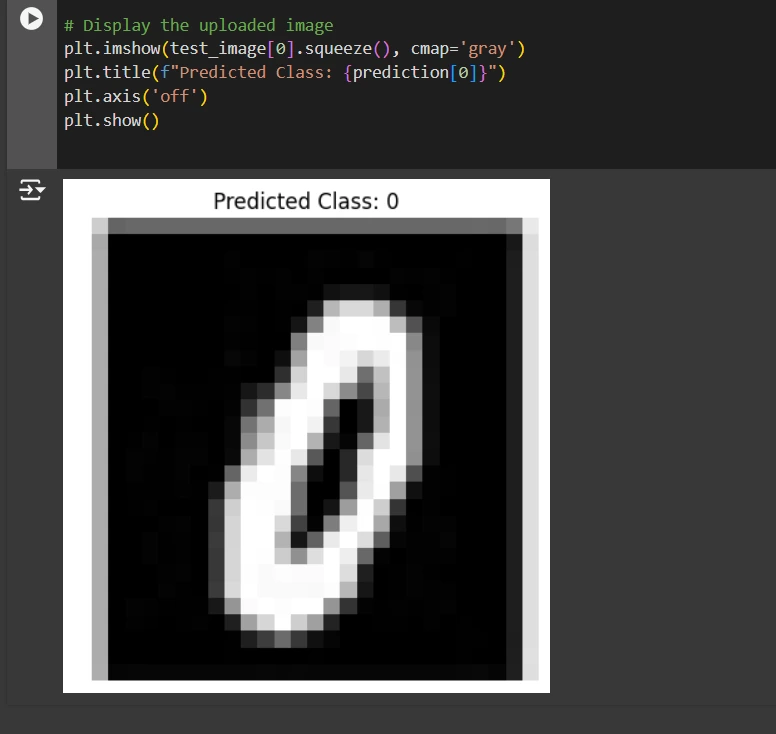
print(f"Predicted class: {prediction[0]}")
# Show the uploaded picture
plt.imshow(test_image[0].squeeze(), cmap='grey')
plt.title(f"Predicted Class: {prediction[0]}")
plt.axis('off')
plt.present()Importing Photographs
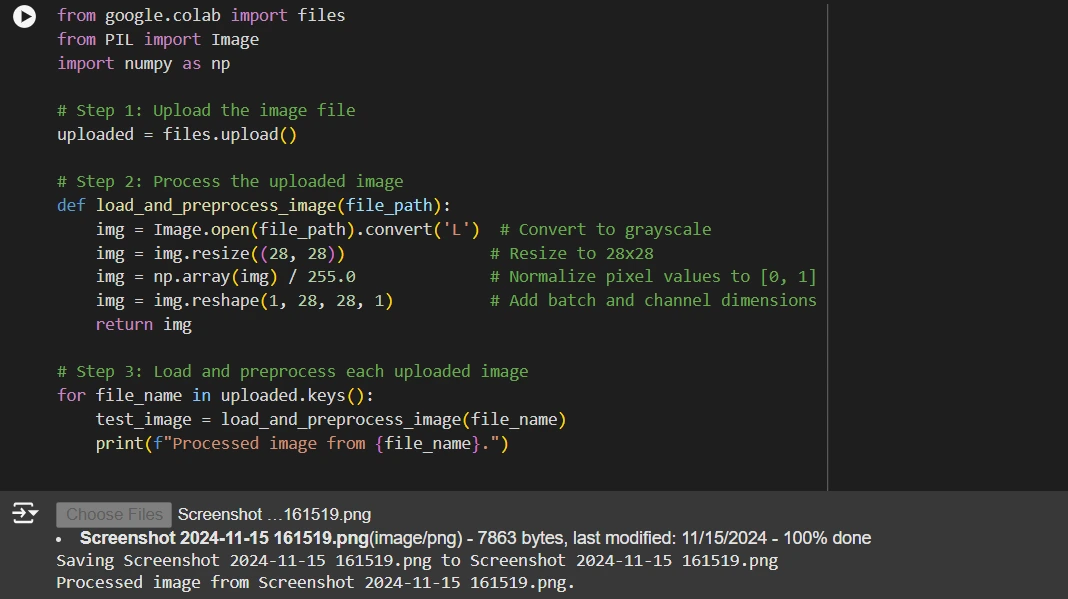
- Step one is to add the customized handwritten digit pictures.
- The information.add() perform opens a file add interface within the Colab atmosphere to allow importing.
- It permits customers to pick out a number of pictures from their native machine in a supported format (e.g., PNG, JPG).
- As soon as uploaded, the information are accessible for additional processing within the code.
Preprocessing
After importing, the mannequin processes the photographs to match the anticipated enter format.
- Convert to Grayscale: We convert the picture to grayscale utilizing `Picture.convert(‘L’)`, as MNIST pictures are single-channel.
- Resize to twenty-eight×28 Pixels: The picture is resized to the usual MNIST dimensions utilizing Picture.resize((28, 28)).
- Normalize Pixel Values: We scale the pixel values to the vary [0, 1] by dividing by 255.0 to make sure constant enter values.
- Reshape for Mannequin Enter: We reshape the picture right into a tensor with dimensions [1, 28, 28, 1] to incorporate the batch dimension and channel dimensions.
Prediction
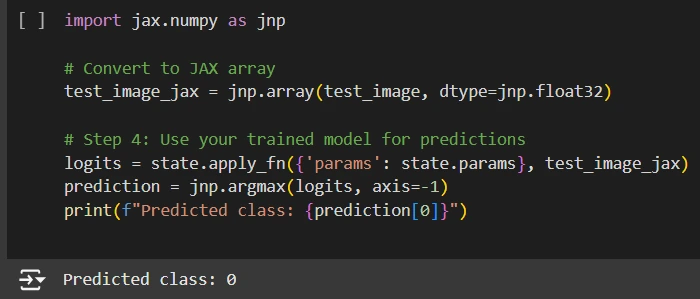
- We convert the preprocessed picture right into a JAX-compatible array (jnp.array), optimizing it for environment friendly computation.
- We cross this array by means of the skilled mannequin utilizing the apply_fn perform, which computes the logits (uncooked output scores for every class).
- We use jnp.argmax to seek out the index of the utmost logit worth, which corresponds to the category with the very best confidence.
Visualization
- The processed picture is displayed utilizing Matplotlib to offer a visible reference for the consumer.
- The expected class is displayed because the picture’s title for simple interpretation of the outcomes.
- This visualization step helps validate the mannequin’s predictions and makes the classification course of intuitive and user-friendly.
Conclusion
This step-by-step information demonstrated the facility and suppleness of JAX, Flax, and Optax in constructing a strong deep studying pipeline for picture classification. By leveraging their distinctive options like environment friendly {hardware} acceleration, modular design, and superior optimization capabilities, we skilled a Convolutional Neural Community (CNN) on the dataset with ease. The mixing with TensorFlow Datasets (TFDS) simplified information loading and preprocessing, whereas visualizing metrics offered helpful insights into the mannequin’s efficiency.
The pipeline culminated in testing the mannequin on customized pictures, showcasing its sensible utility. This method shouldn’t be solely scalable for extra advanced datasets but in addition serves as a basis for exploring cutting-edge deep studying methods.
Right here is the collab hyperlink: Click on Right here.
Key Takeaways
- JAX, Flax, and Optax present highly effective instruments for environment friendly deep studying mannequin constructing and optimization.
- Information preprocessing and augmentation are important for enhancing mannequin efficiency on real-world datasets.
- Convolutional Neural Networks (CNNs) are efficient for picture classification duties like MNIST.
- Evaluating mannequin efficiency with applicable metrics helps observe enhancements and establish areas for refinement.
- Visualizing coaching and testing metrics offers helpful insights into mannequin habits and progress throughout coaching.
Often Requested Questions
A. JAX is a high-performance numerical computing library that gives options like computerized differentiation and GPU/TPU acceleration. We use it right here to effectively compute gradients and execute deep studying operations seamlessly on {hardware} accelerators.
A. Flax is a light-weight, modular library constructed on JAX, designed for flexibility and scalability. Its @compact API simplifies mannequin definitions, making it simpler to experiment with totally different architectures whereas leveraging JAX’s highly effective options.
A. Optax affords a complete suite of optimization algorithms and instruments for gradient processing, comparable to SGD with momentum, which effectively trains the CNN.
A. TFDS simplifies dataset dealing with by offering pre-built datasets like MNIST, together with instruments for computerized downloading, preprocessing, and splitting into coaching and testing units.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Writer’s discretion.
My identify is Nilesh Dwivedi, and I am excited to hitch this vibrant group of bloggers and readers. I am presently in my first yr of BTech, specializing in Information Science and Synthetic Intelligence at IIIT Dharwad. I am obsessed with expertise and information science and looking out ahead to jot down extra blogs.