Video body interpolation (VFI) is an open downside in generative video analysis. The problem is to generate intermediate frames between two present frames in a video sequence.
Click on to play. The FILM framework, a collaboration between Google and the College of Washington, proposed an efficient body interpolation methodology that continues to be widespread in hobbyist {and professional} spheres. On the left, we are able to see the 2 separate and distinct frames superimposed; within the center, the ‘finish body’; and on the correct, the ultimate synthesis between the frames. Sources: https://film-net.github.io/ and https://arxiv.org/pdf/2202.04901
Broadly talking, this method dates again over a century, and has been utilized in conventional animation since then. In that context, grasp ‘keyframes’ can be generated by a principal animation artist, whereas the work of ‘tweening’ intermediate frames can be carried out as by different staffers, as a extra menial job.
Previous to the rise of generative AI, body interpolation was utilized in tasks equivalent to Actual-Time Intermediate Circulation Estimation (RIFE), Depth-Conscious Video Body Interpolation (DAIN), and Google’s Body Interpolation for Massive Movement (FILM – see above) for functions of accelerating the body charge of an present video, or enabling artificially-generated slow-motion results. That is achieved by splitting out the prevailing frames of a clip and producing estimated intermediate frames.
VFI can also be used within the growth of higher video codecs, and, extra typically, in optical movement-based techniques (together with generative techniques), that make the most of advance data of coming keyframes to optimize and form the interstitial content material that precedes them.
Finish Frames in Generative Video Techniques
Trendy generative techniques equivalent to Luma and Kling enable customers to specify a begin and an finish body, and might carry out this job by analyzing keypoints within the two photos and estimating a trajectory between the 2 photos.
As we are able to see within the examples beneath, offering a ‘closing’ keyframe higher permits the generative video system (on this case, Kling) to keep up facets equivalent to id, even when the outcomes usually are not good (notably with massive motions).
Click on to play. Kling is considered one of a rising variety of video mills, together with Runway and Luma, that enable the person to specify an finish body. Usually, minimal movement will result in probably the most life like and least-flawed outcomes. Supply: https://www.youtube.com/watch?v=8oylqODAaH8
Within the above instance, the individual’s id is constant between the 2 user-provided keyframes, resulting in a comparatively constant video era.
The place solely the beginning body is offered, the generative techniques window of consideration just isn’t normally massive sufficient to ‘bear in mind’ what the individual seemed like at the beginning of the video. Quite, the id is more likely to shift a bit bit with every body, till all resemblance is misplaced. Within the instance beneath, a beginning picture was uploaded, and the individual’s motion guided by a textual content immediate:
Click on to play. With no finish body, Kling solely has a small group of instantly prior frames to information the era of the subsequent frames. In circumstances the place any important motion is required, this atrophy of id turns into extreme.
We are able to see that the actor’s resemblance just isn’t resilient to the directions, for the reason that generative system doesn’t know what he would appear to be if he was smiling, and he isn’t smiling within the seed picture (the one obtainable reference).
Nearly all of viral generative clips are rigorously curated to de-emphasize these shortcomings. Nonetheless, the progress of temporally constant generative video techniques could depend upon new developments from the analysis sector in regard to border interpolation, for the reason that solely doable various is a dependence on conventional CGI as a driving, ‘information’ video (and even on this case, consistency of texture and lighting are at present tough to attain).
Moreover, the slowly-iterative nature of deriving a brand new body from a small group of current frames makes it very tough to attain massive and daring motions. It’s because an object that’s shifting quickly throughout a body could transit from one aspect to the opposite within the area of a single body, opposite to the extra gradual actions on which the system is more likely to have been skilled.
Likewise, a big and daring change of pose could lead not solely to id shift, however to vivid non-congruities:
Click on to play. On this instance from Luma, the requested motion doesn’t seem like well-represented within the coaching knowledge.
Framer
This brings us to an fascinating current paper from China, which claims to have achieved a brand new state-of-the-art in authentic-looking body interpolation – and which is the primary of its variety to supply drag-based person interplay.
Framer permits the person to direct movement utilizing an intuitive drag-based interface, although it additionally has an ‘computerized’ mode. Supply: https://www.youtube.com/watch?v=4MPGKgn7jRc
Drag-centric purposes have grow to be frequent in the literature these days, because the analysis sector struggles to supply instrumentalities for generative system that aren’t primarily based on the pretty crude outcomes obtained by textual content prompts.
The brand new system, titled Framer, can’t solely comply with the user-guided drag, but additionally has a extra typical ‘autopilot’ mode. Apart from typical tweening, the system is able to producing time-lapse simulations, in addition to morphing and novel views of the enter picture.

Interstitial frames generated for a time-lapse simulation in Framer. Supply: https://arxiv.org/pdf/2410.18978
In regard to the manufacturing of novel views, Framer crosses over a bit into the territory of Neural Radiance Fields (NeRF) – although requiring solely two photos, whereas NeRF typically requires six or extra picture enter views.
In checks, Framer, which is based on Stability.ai’s Steady Video Diffusion latent diffusion generative video mannequin, was capable of outperform approximated rival approaches, in a person research.
On the time of writing, the code is about to be launched at GitHub. Video samples (from which the above photos are derived) can be found on the mission web site, and the researchers have additionally launched a YouTube video.
The new paper is titled Framer: Interactive Body Interpolation, and comes from 9 researchers throughout Zhejiang College and the Alibaba-backed Ant Group.
Technique
Framer makes use of keypoint-based interpolation in both of its two modalities, whereby the enter picture is evaluated for fundamental topology, and ‘movable’ factors assigned the place vital. In impact, these factors are equal to facial landmarks in ID-based techniques, however generalize to any floor.
The researchers fine-tuned Steady Video Diffusion (SVD) on the OpenVid-1M dataset, including an extra last-frame synthesis functionality. This facilitates a trajectory-control mechanism (prime proper in schema picture beneath) that may consider a path towards the end-frame (or again from it).
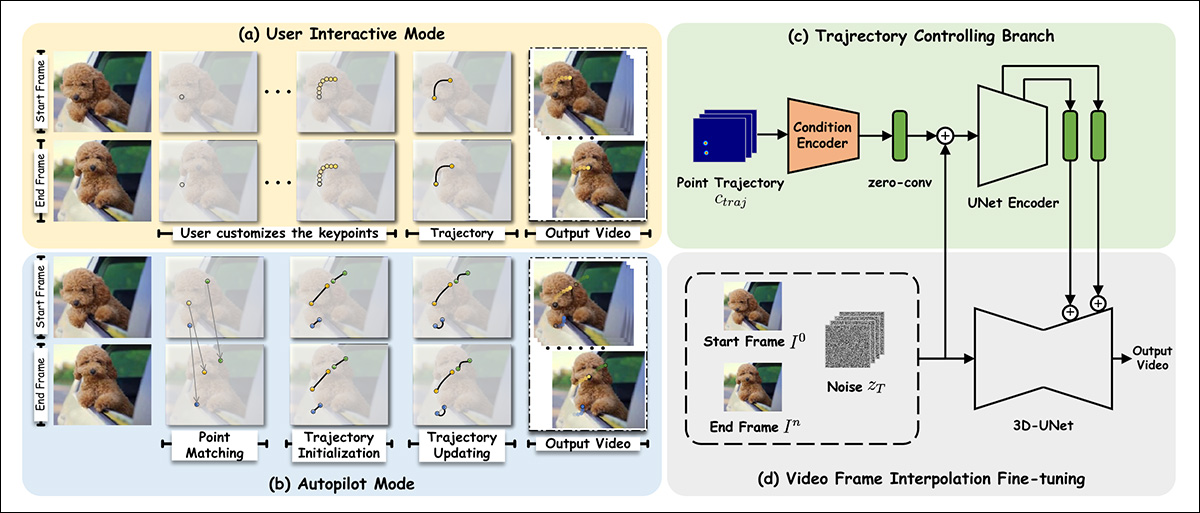
Schema for Framer.
Relating to the addition of last-frame conditioning, the authors state:
‘To protect the visible prior of the pre-trained SVD as a lot as doable, we comply with the conditioning paradigm of SVD and inject end-frame situations within the latent area and semantic area, respectively.
‘Particularly, we concatenate the VAE-encoded latent function of the primary [frame] with the noisy latent of the primary body, as did in SVD. Moreover, we concatenate the latent function of the final body, zn, with the noisy latent of the top body, contemplating that the situations and the corresponding noisy latents are spatially aligned.
‘As well as, we extract the CLIP picture embedding of the primary and final frames individually and concatenate them for cross-attention function injection.’
For drag-based performance, the trajectory module leverages the Meta Ai-led CoTracker framework, which evaluates profuse doable paths forward. These are slimmed all the way down to between 1-10 doable trajectories.
The obtained level coordinates are then reworked by means of a strategy impressed by the DragNUWA and DragAnything architectures. This obtains a Gaussian heatmap, which individuates the goal areas for motion.
Subsequently, the information is fed to the conditioning mechanisms of ControlNet, an ancillary conformity system initially designed for Steady Diffusion, and since tailored to different architectures.
For autopilot mode, function matching is initially achieved by way of SIFT, which interprets a trajectory that may then be handed to an auto-updating mechanism impressed by DragGAN and DragDiffusion.
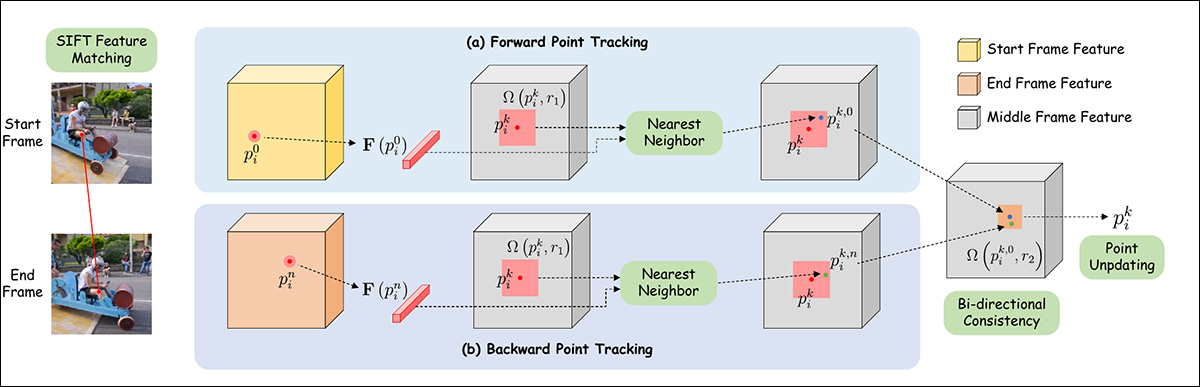
Schema for level trajectory estimation in Framer.
Information and Exams
For the fine-tuning of Framer, the spatial consideration and residual blocks had been frozen, and solely the temporal consideration layers and residual blocks had been affected.
The mannequin was skilled for 10,000 iterations below AdamW, at a studying charge of 1e-4, and a batch measurement of 16. Coaching befell throughout 16 NVIDIA A100 GPUs.
Since prior approaches to the issue don’t supply drag-based modifying, the researchers opted to check Framer’s autopilot mode to the usual performance of older choices.
The frameworks examined for the class of present diffusion-based video era techniques had been LDMVFI; Dynamic Crafter; and SVDKFI. For ‘conventional’ video techniques, the rival frameworks had been AMT; RIFE; FLAVR; and the aforementioned FILM.
Along with the person research, checks had been carried out over the DAVIS and UCF101 datasets.
Qualitative checks can solely be evaluated by the target colleges of the analysis workforce and by person research. Nonetheless, the paper notes, conventional quantitative metrics are largely unsuited to the proposition at hand:
‘[Reconstruction] metrics like PSNR, SSIM, and LPIPS fail to seize the standard of interpolated frames precisely, since they penalize different believable interpolation outcomes that aren’t pixel-aligned with the unique video.
‘Whereas era metrics equivalent to FID supply some enchancment, they nonetheless fall brief as they don’t account for temporal consistency and consider frames in isolation.’
Despite this, the researchers carried out qualitative checks with a number of widespread metrics:
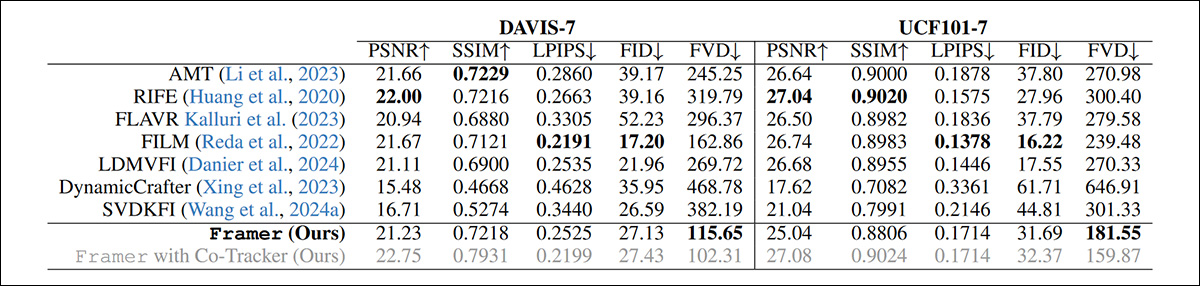
Quantitative outcomes for Framer vs. rival techniques.
The authors word that regardless of having the percentages stacked towards them, Framer nonetheless achieves the very best FVD rating among the many strategies examined.
Under are the paper’s pattern outcomes for a qualitative comparability:

Qualitative comparability towards former approaches. Please seek advice from the paper for higher decision, in addition to video outcomes at https://www.youtube.com/watch?v=4MPGKgn7jRc.
The authors remark:
‘[Our] methodology produces considerably clearer textures and pure movement in comparison with present interpolation strategies. It performs particularly effectively in situations with substantial variations between the enter frames, the place conventional strategies typically fail to interpolate content material precisely.
‘In comparison with different diffusion-based strategies like LDMVFI and SVDKFI, Framer demonstrates superior adaptability to difficult circumstances and provides higher management.’
For the person research, the researchers gathered 20 individuals, who assessed 100 randomly-ordered video outcomes from the assorted strategies examined. Thus, 1000 scores had been obtained, evaluating probably the most ‘life like’ choices:
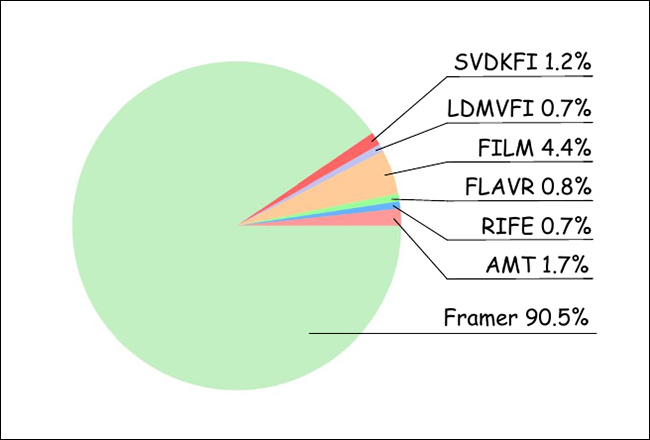
Outcomes from the person research.
As might be seen from the graph above, customers overwhelmingly favored outcomes from Framer.
The mission’s accompanying YouTube video outlines among the potential different makes use of for framer, together with morphing and cartoon in-betweening – the place the complete idea started.
Conclusion
It’s onerous to over-emphasize how necessary this problem at present is for the duty of AI-based video era. So far, older options equivalent to FILM and the (non-AI) EbSynth have been used, by each novice {and professional} communities, for tweening between frames; however these options include notable limitations.
Due to the disingenuous curation of official instance movies for brand new T2V frameworks, there’s a vast public false impression that machine studying techniques can precisely infer geometry in movement with out recourse to steering mechanisms equivalent to 3D morphable fashions (3DMMs), or different ancillary approaches, equivalent to LoRAs.
To be trustworthy, tweening itself, even when it could possibly be completely executed, solely constitutes a ‘hack’ or cheat upon this downside. Nonetheless, since it’s typically simpler to supply two well-aligned body photos than to impact steering by way of text-prompts or the present vary of options, it’s good to see iterative progress on an AI-based model of this older methodology.
First revealed Tuesday, October 29, 2024

